You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
In this dashboard, there are five sections. Each section has [metrics](https://aws-observability.github.io/observability-best-practices/guides/operational/adot-at-scale/operating-adot-collector/#collecting-health-metrics-from-the-collector) relevant to the various [components](https://opentelemetry.io/docs/demo/collector-data-flow-dashboard/#data-flow-overview) of the AWS Distro for OpenTelemetry (ADOT) collector :
13
14
@@ -17,22 +18,24 @@ Shows the receiver’s accepted and refused rate/count of spans and metric point
17
18
### Processors
18
19
Shows the accepted and refused rate/count of spans and metric points pushed into next component in the pipeline. The batch metrics can help to understand how often metrics are sent to exporter and the batch size.
Shows the exporter’s accepted and refused rate/count of spans and metric points that are pushed to any of the destinations. It also shows the size and capacity of the retry queue. These metrics can be used to understand if the collector is having issues in sending trace or metric data to the destination configured.
To read more about the metrics and the dashboard used, visit the upstream documentation [here](https://opentelemetry.io/docs/demo/collector-data-flow-dashboard/).
Copy file name to clipboardExpand all lines: docs/container-insights/eks.md
+1-2Lines changed: 1 addition & 2 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -46,8 +46,7 @@ terraform apply
46
46
47
47
After apply, open your Amazon CloudWatch console in the same region as your EKS cluster, then from the left hand side choose `Insights -> Container Insights`, there choose the `Performance montoring` from the drop down, choose the `cluster name` and you will see the metrics shown on the dashboard:
48
48
49
-
50
-
<imgwidth="1423"alt="Screenshot 2023-08-08 at 1.15.14 PM"src="https://github.com/RJrocks/terraform-aws-observability-accelerator/assets/5756583/4c5e4ed3-2e1f-4d41-b568-01976fbfd303">
AWS Distro of OpenTelemetry enables EKS API server monitoring by default and provides three Grafana dashboards:
3
+
AWS Distro for OpenTelemetry (ADOT) enables Amazon EKS API server monitoring by default and provides three Grafana dashboards:
4
4
5
5
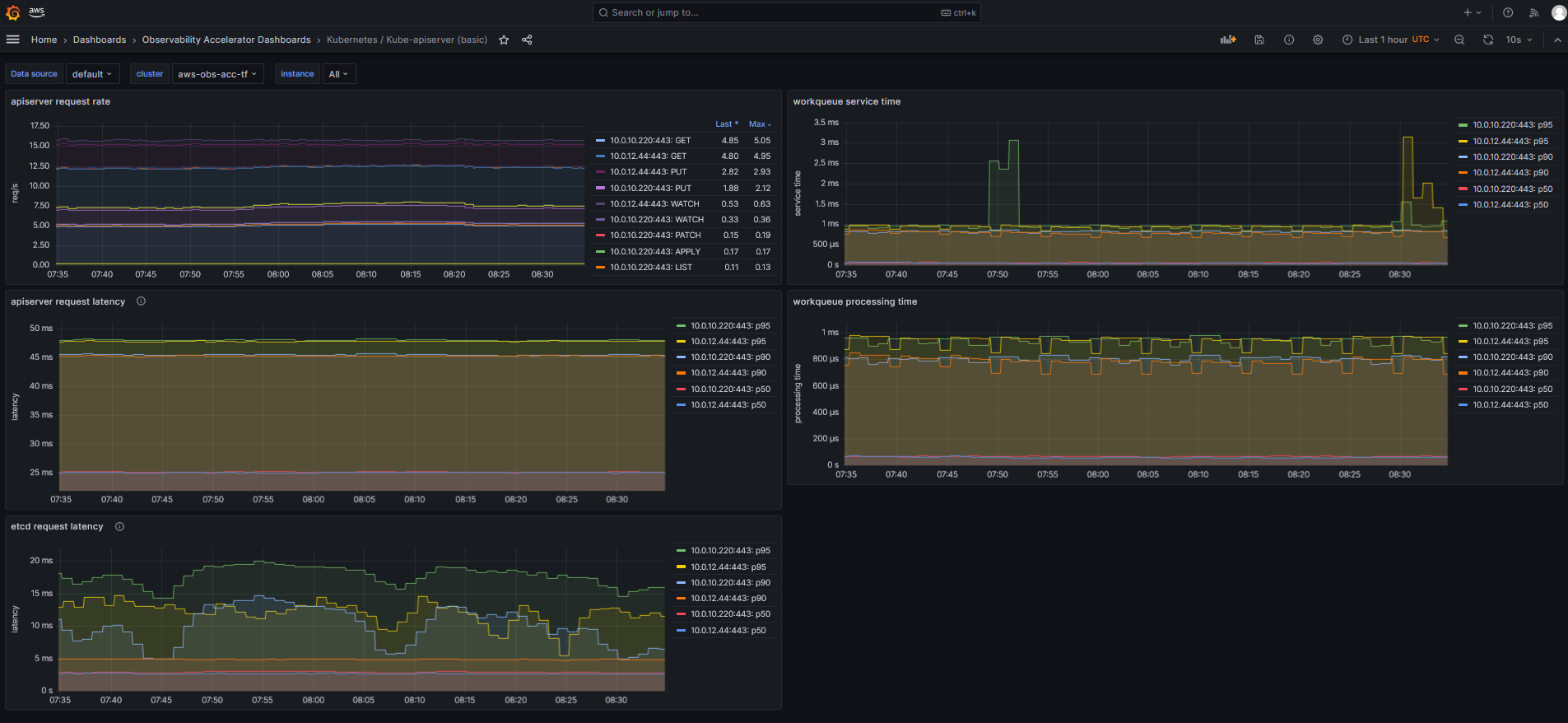
## Kube-apiserver (basic)
6
6
7
-
The basic dashboard shows metrics recommended in [EKS Best Practices Guides - Monitor Control Plane Metrics](https://aws.github.io/aws-eks-best-practices/reliability/docs/controlplane/#monitor-control-plane-metrics) and provides request rate and latency for API server, latency for ETCD server and overall workqueue sercice time and latency. It allows a drill-down per API server.
7
+
The basic dashboard shows metrics recommended in [EKS Best Practices Guides - Monitor Control Plane Metrics](https://aws.github.io/aws-eks-best-practices/reliability/docs/controlplane/#monitor-control-plane-metrics) and provides request rate and latency for API server, latency for ETCD server and overall workqueue service time and latency. It allows a drill-down per API server.
8
+
9
+
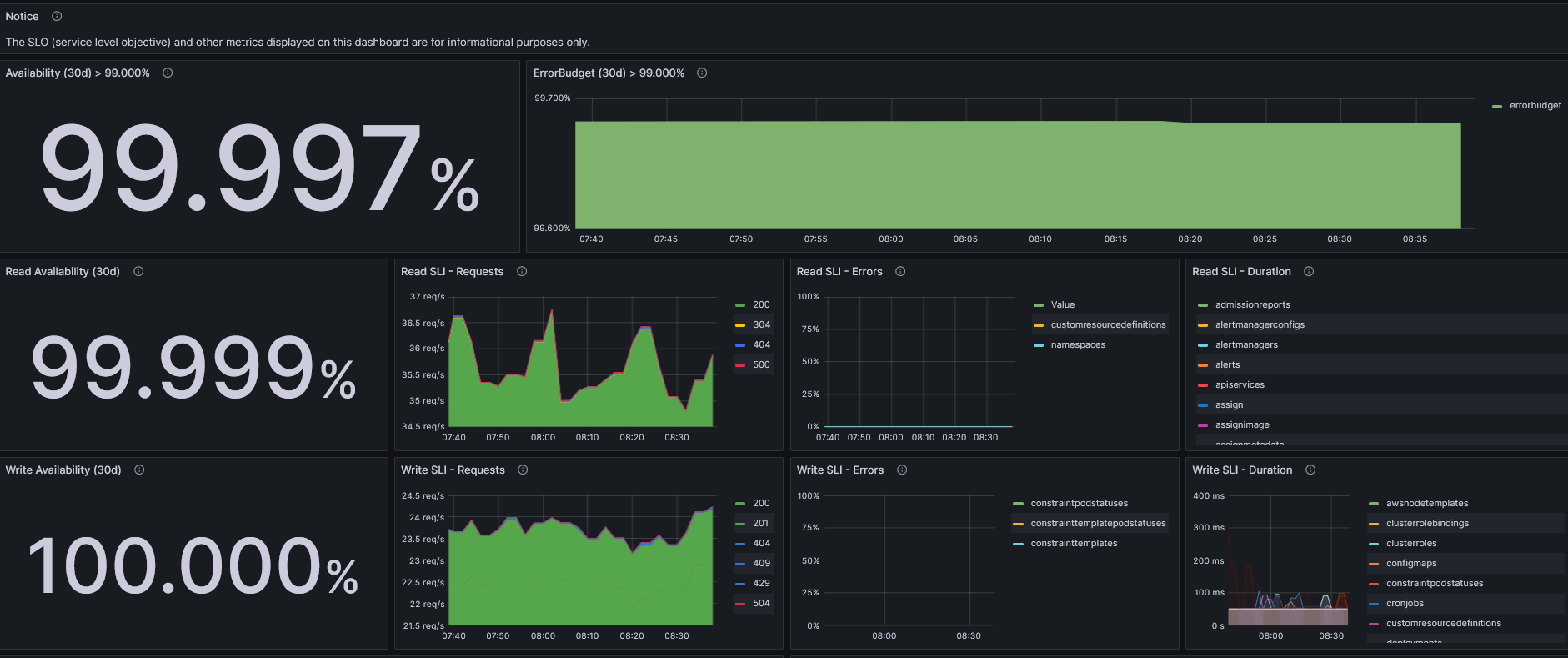
The advanced dashboard is derived from kube-prometheus-stack "Kubernetes / API server" dashboard and provides a detailed metrics drill-down for example per READ and WRITE operations per component (like deployments, configmaps etc.).
14
+
The advanced dashboard is derived from kube-prometheus-stack `Kubernetes / API server` dashboard and provides a detailed metrics drill-down for example per READ and WRITE operations per component (like deployments, configmaps etc.).
15
+
16
+
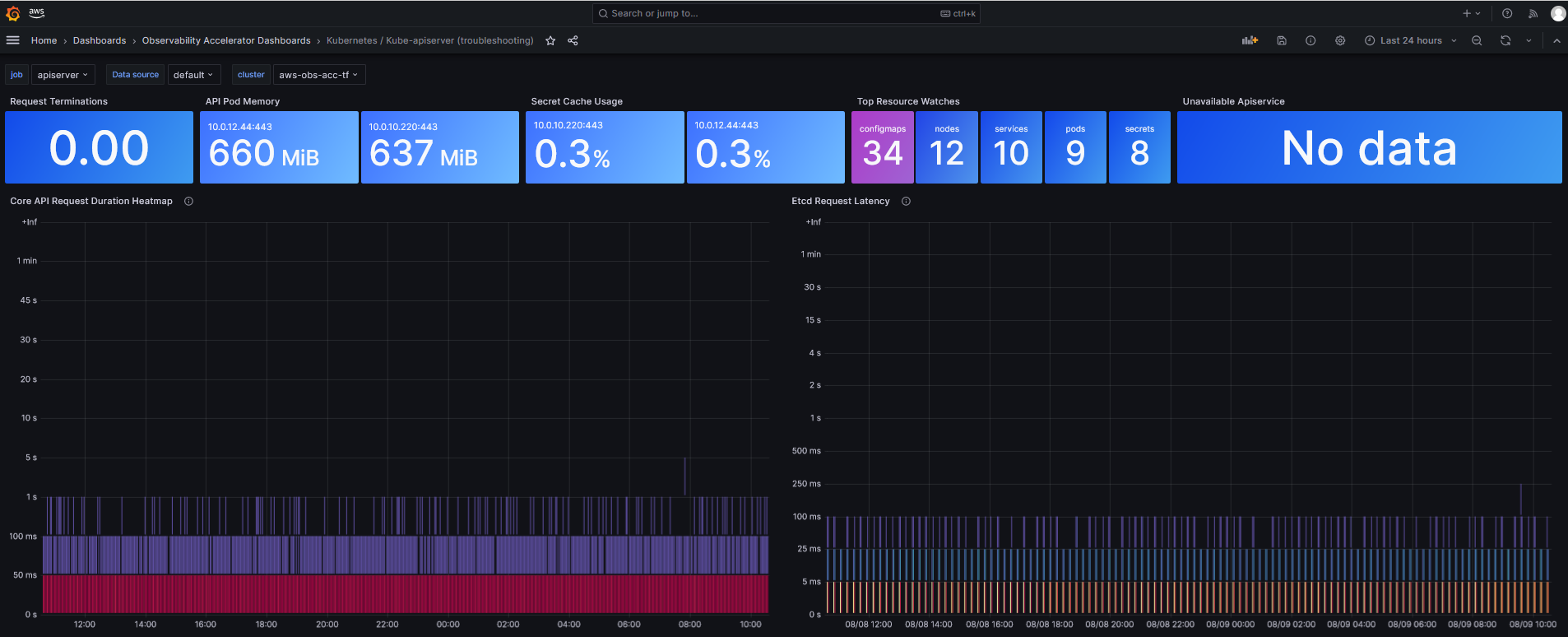
This dashboards can be used to troubleshoot API server problems like latency, errors etc.
21
+
This dashboard can be used to troubleshoot API server problems like latency, errors etc.
20
22
21
23
A detailed description for usage and background information regarding the dashboard can be found in AWS Containers blog post [Troubleshooting Amazon EKS API servers with Prometheus](https://aws.amazon.com/blogs/containers/troubleshooting-amazon-eks-api-servers-with-prometheus/).
0 commit comments