Chat with BC Laws
-Technical presentation
-What we will cover
--
-
- Introduction -
- High level architecture -
- Technologies used -
- Preprocessing (HPC) -
- MLOps -
- Analytics -
- Active Feedback -
- Challenges -
- Q&A -
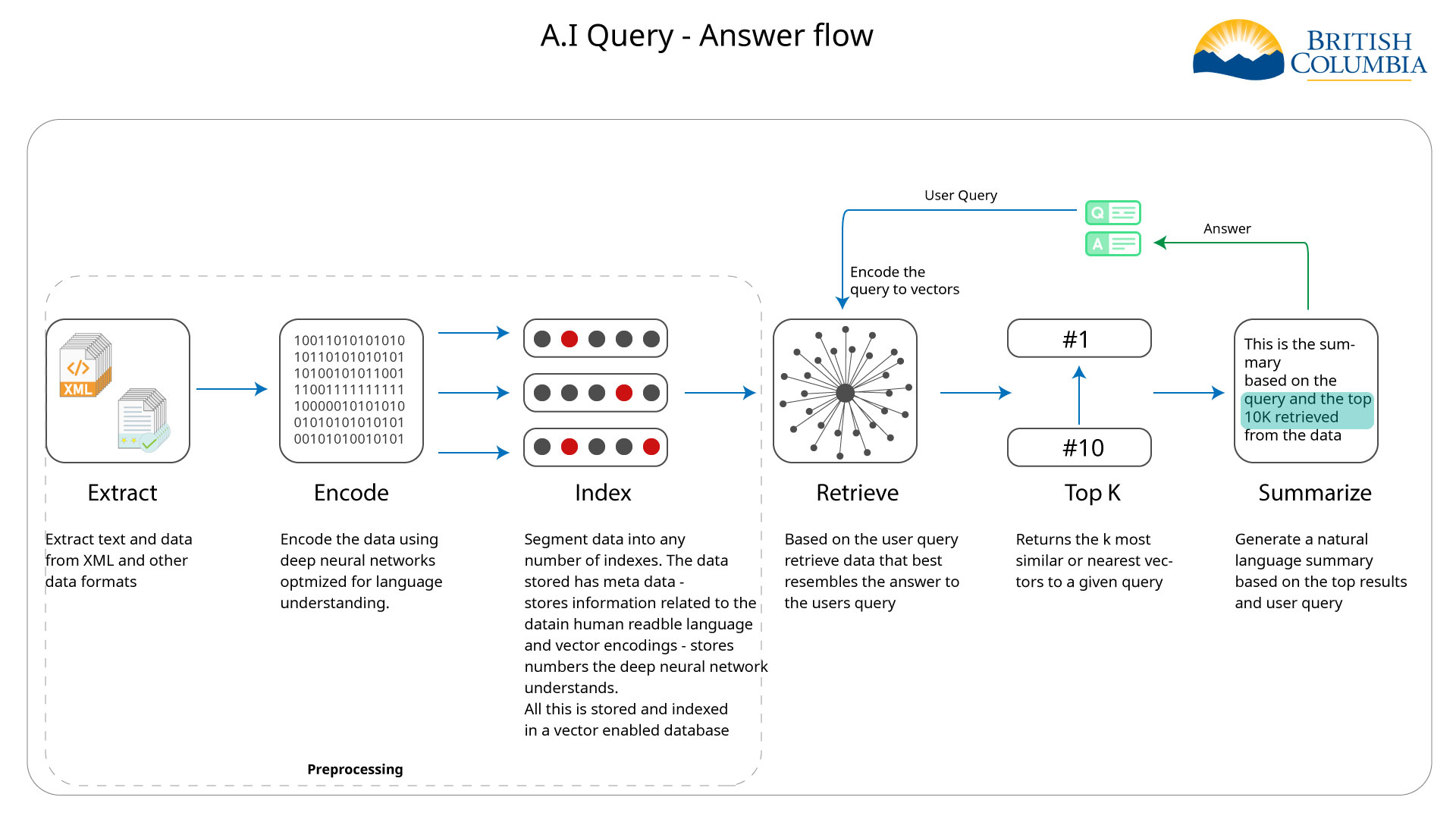 -
- 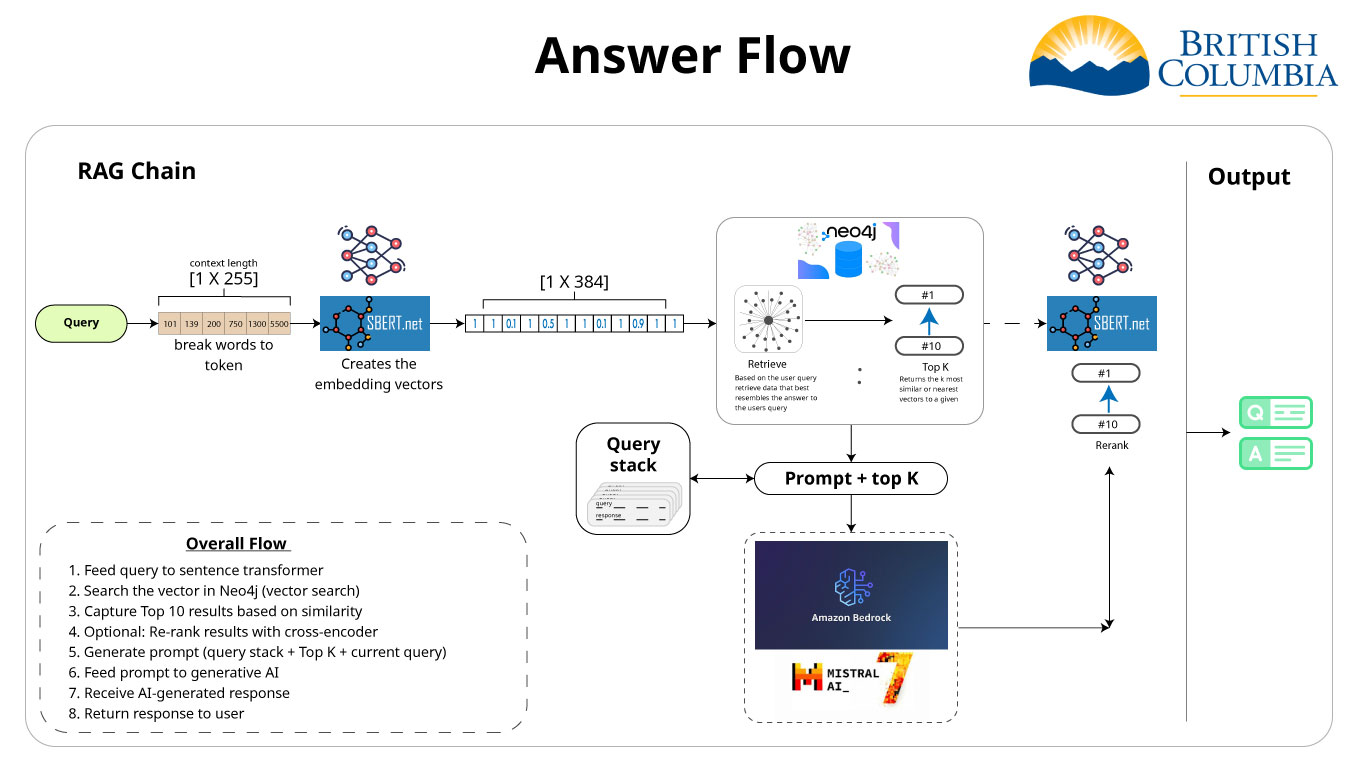 -
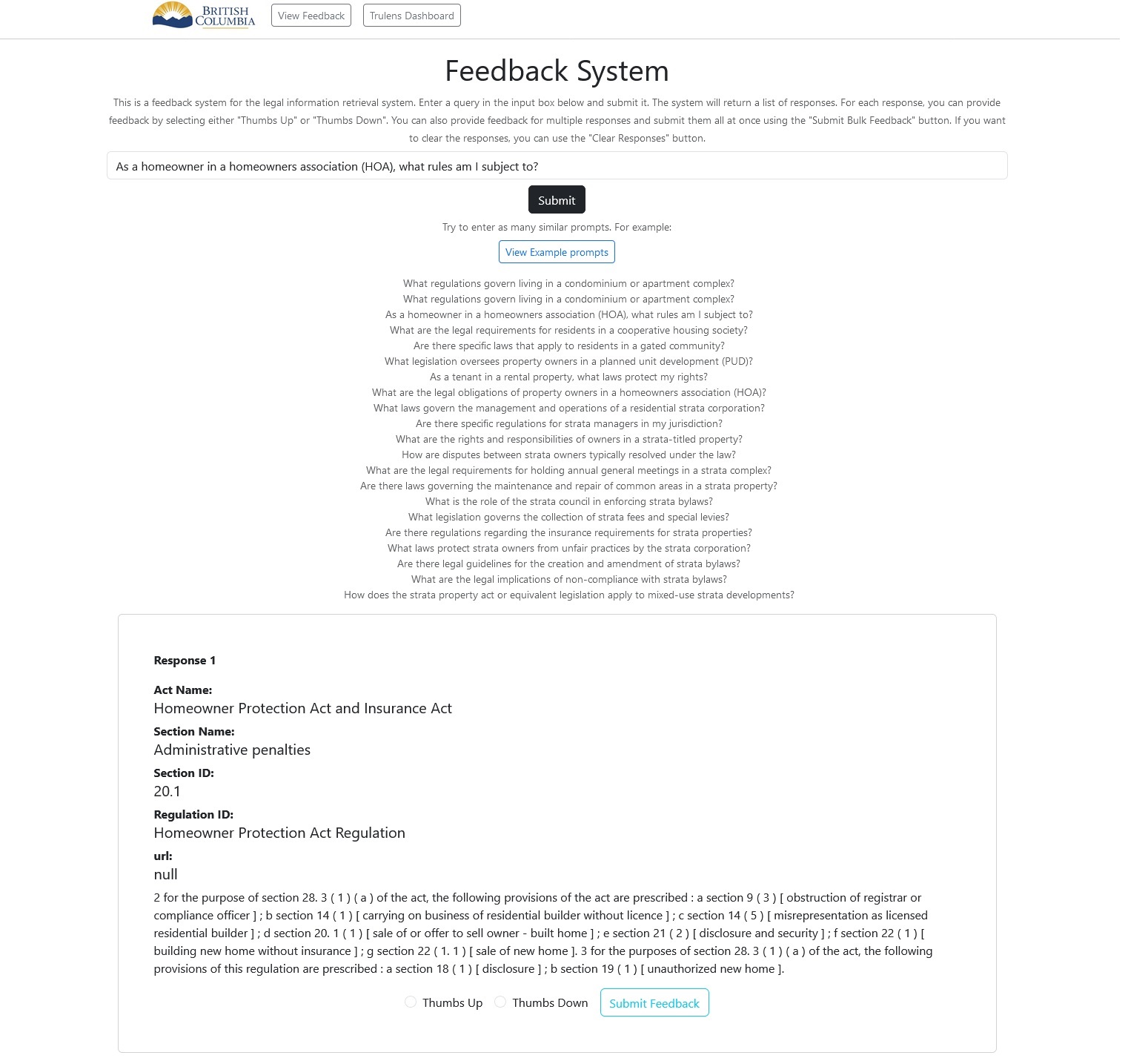
- RAG Pipeline
--
-
- Feed query to sentence transformer -
- Search the vector in Neo4j (vector search) -
- Capture Top 10 results based on similarity -
- - Optional: Re-rank results with cross-encoder - -
- - Generate prompt (query stack + Top K + current query) - -
- Feed prompt to generative AI -
- Receive AI-generated response -
- Return response to user -
 -
-  -
-  -
- 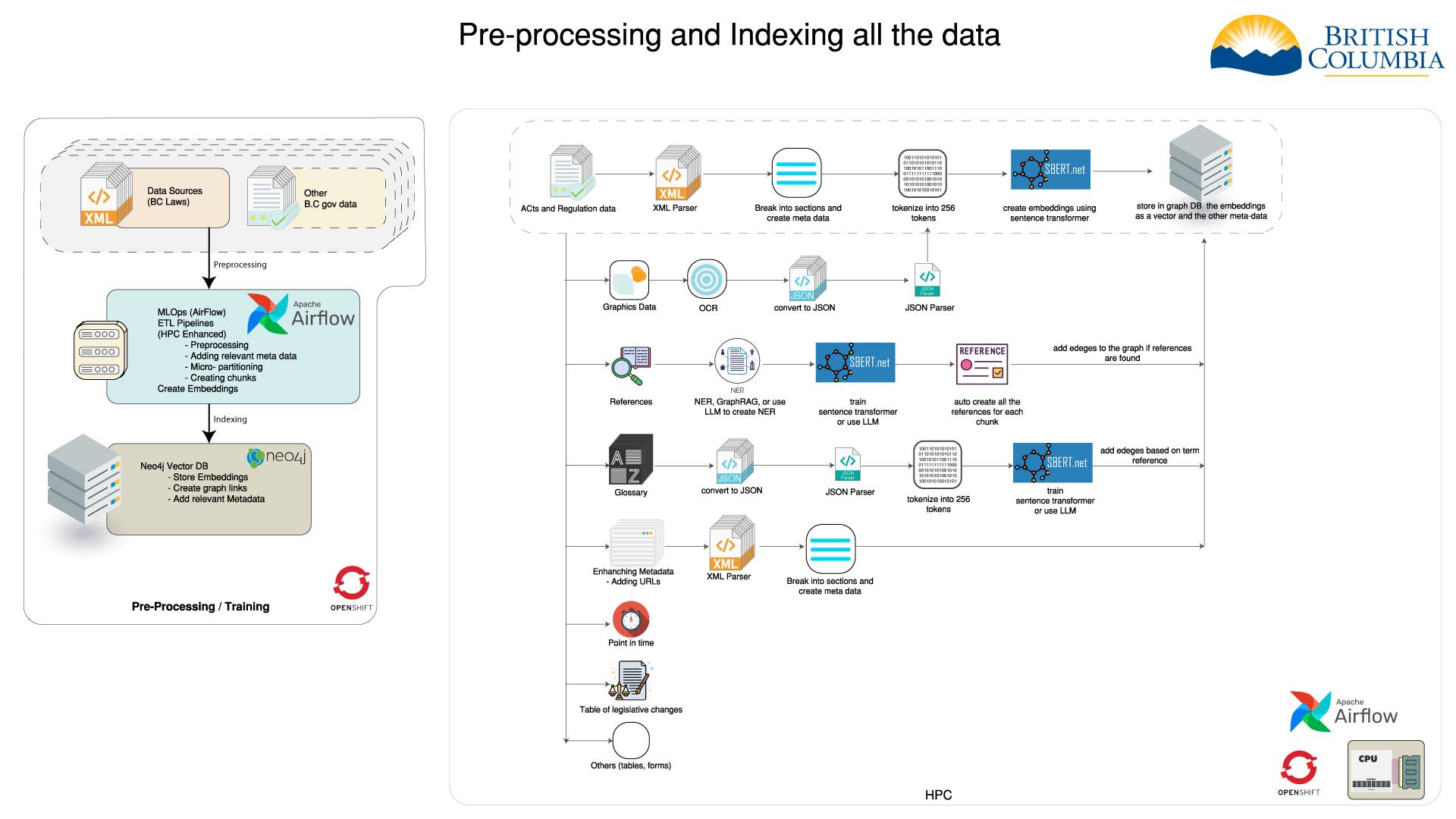 -
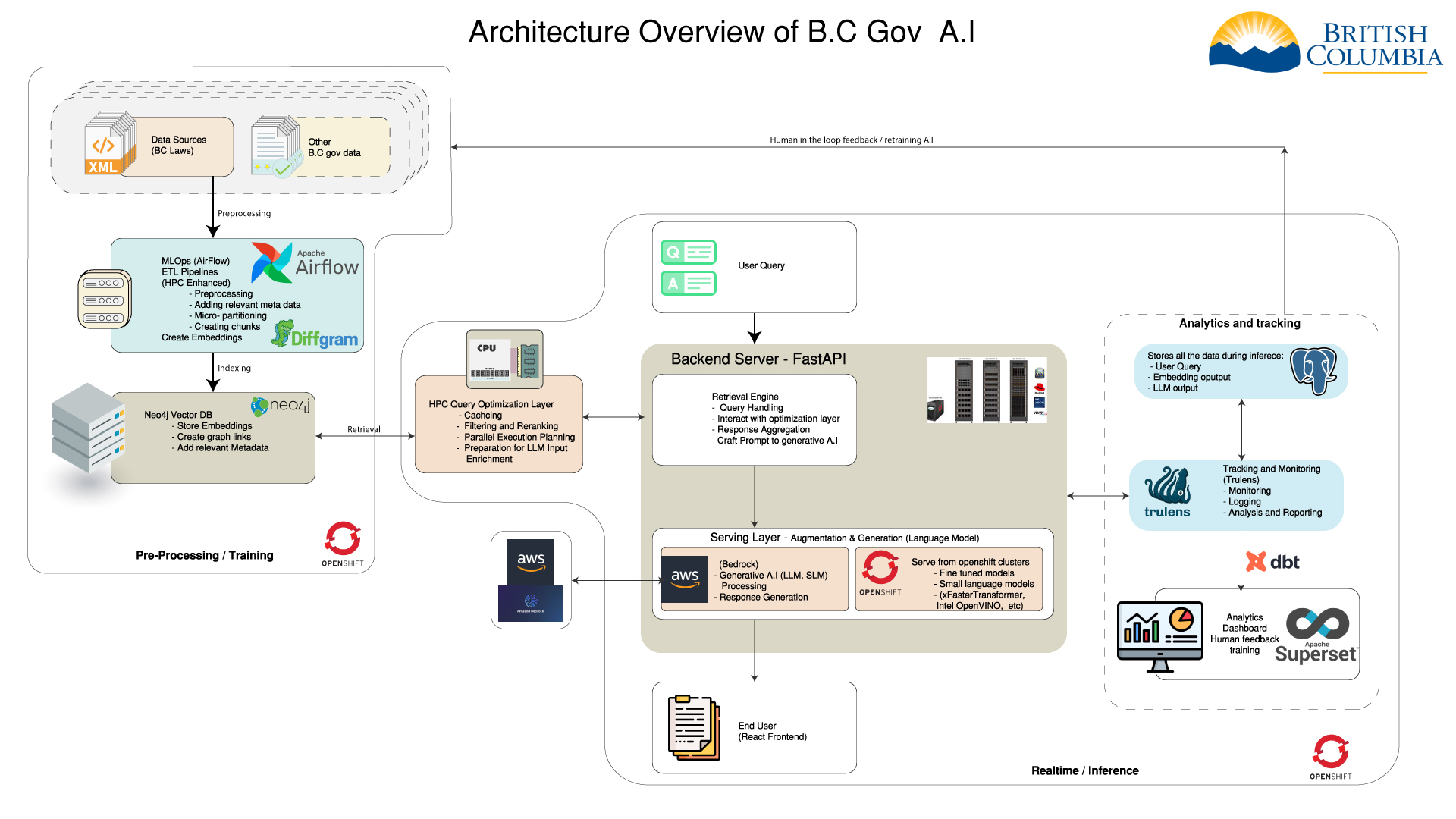
- How we index the acts and regulations
- -
- How data is stored in Neo4j
-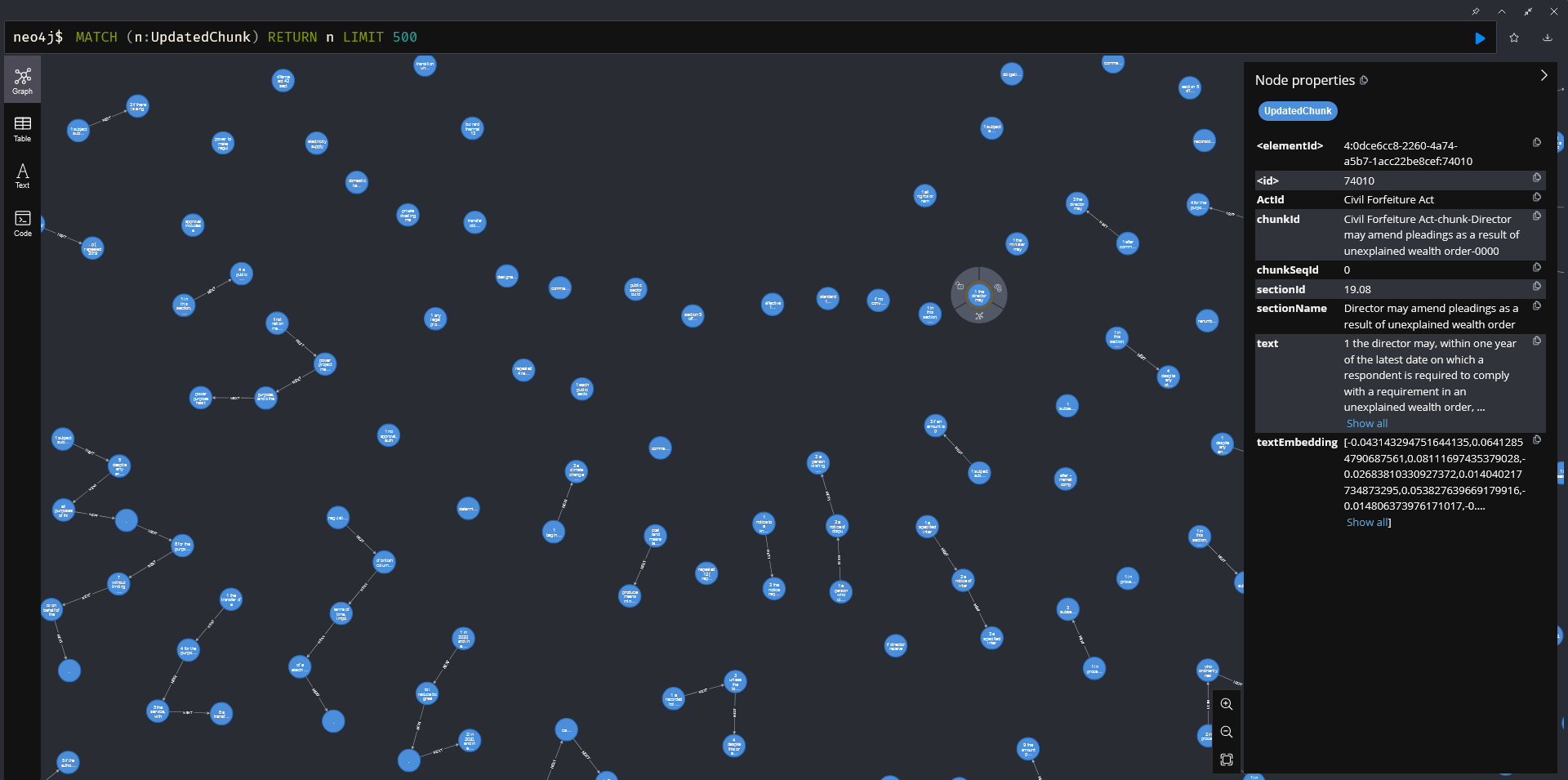 -
- Graph Database and vector store
-| Data storage | -Neo4j Integration | -Advanced Querying | -
|---|---|---|
| We use a graph database to store the data. | -- Neo4J is leveraged for both the graph database and the - vector store. - | -- Neo4J enables advanced queries, such as clustering the data - and finding communities. - | -
| Vector store is utilized for storing embeddings. | -- | - These tasks are more efficient and easier to implement using - a graph database. - | -
HPC
-High Performance Computing for pre-processing the data
-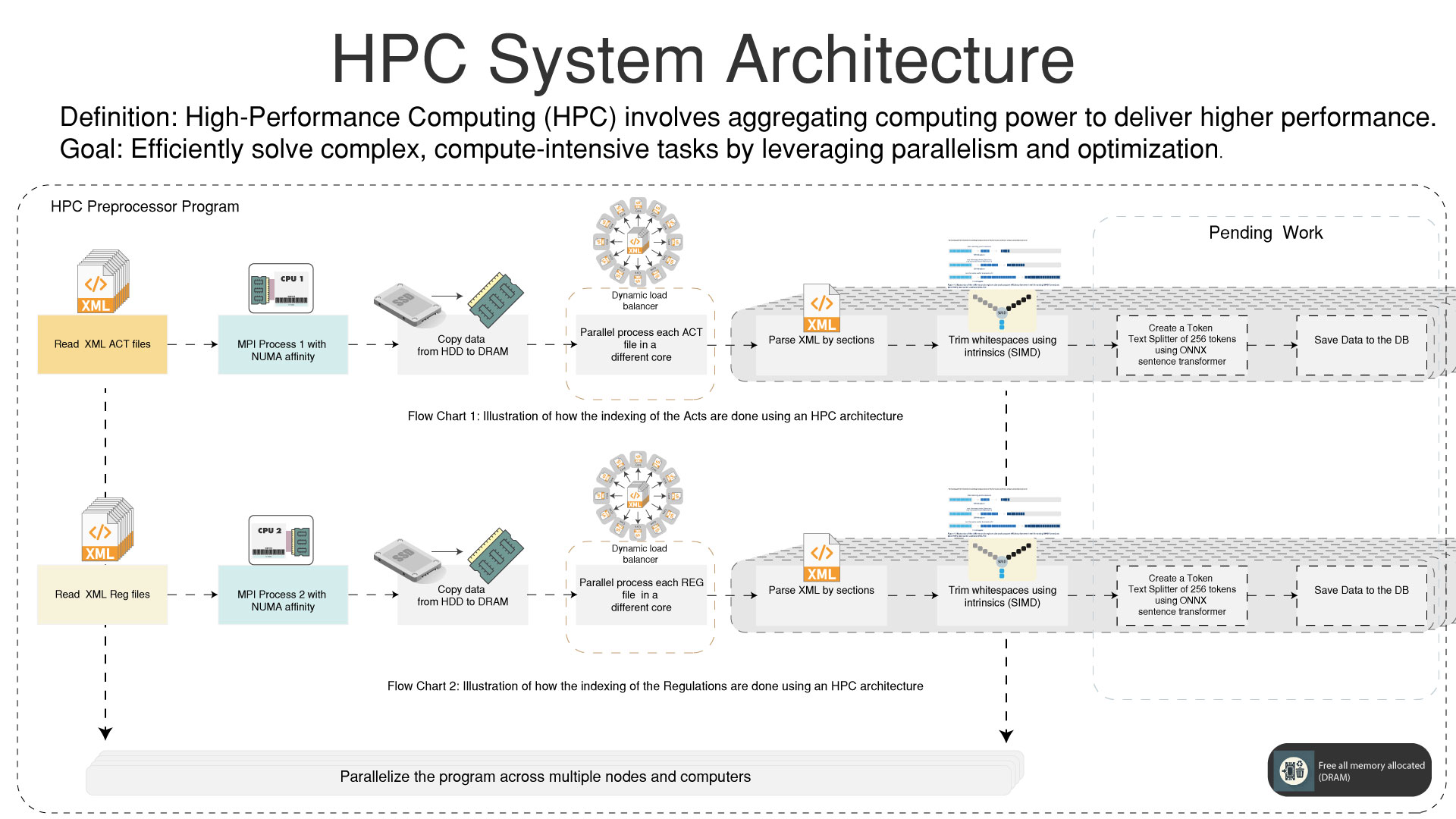 -
- MLOps & Analytics
--
-
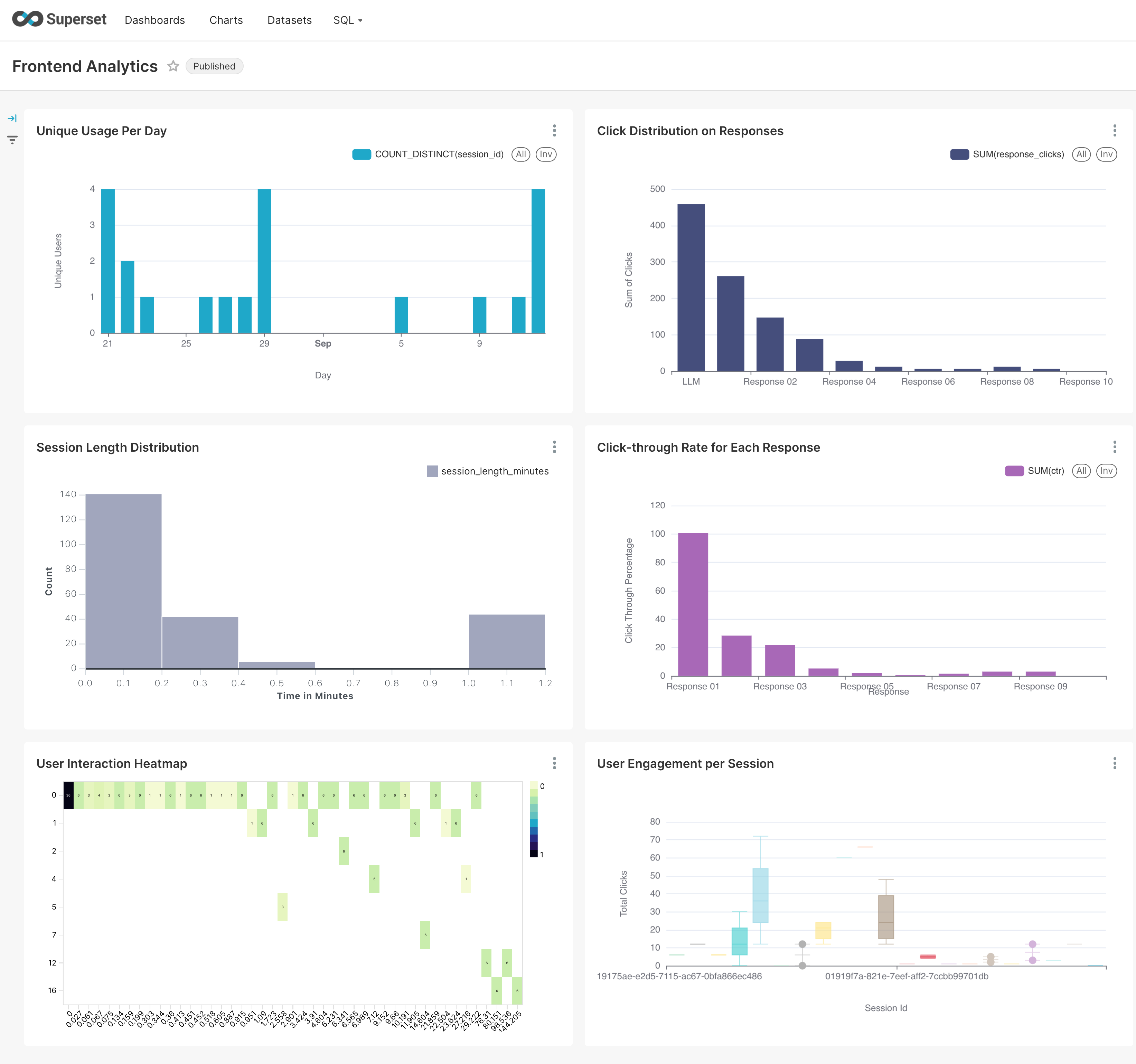
- Frontend analytics data -
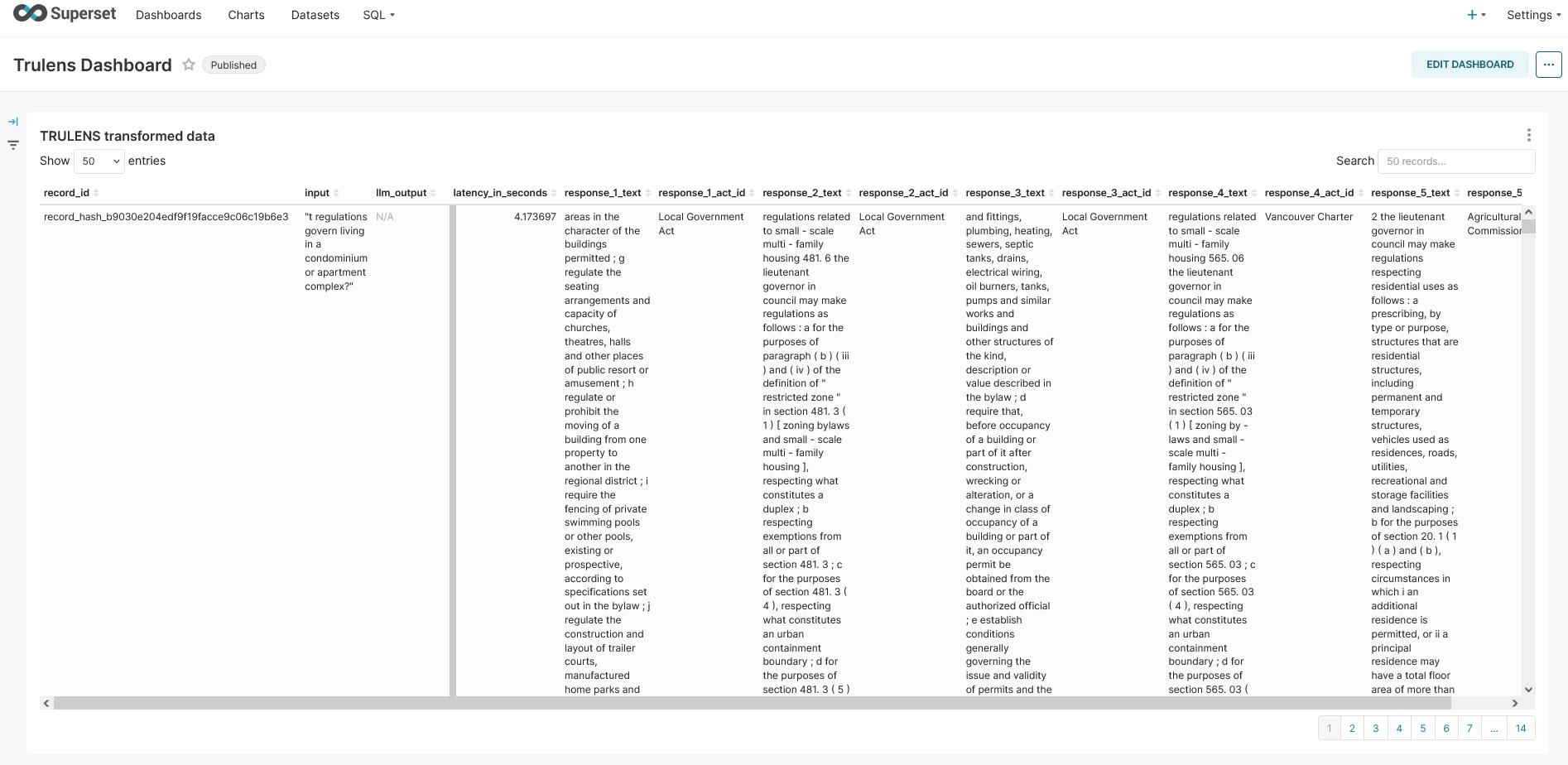
- Backend RAG Chain tracking -
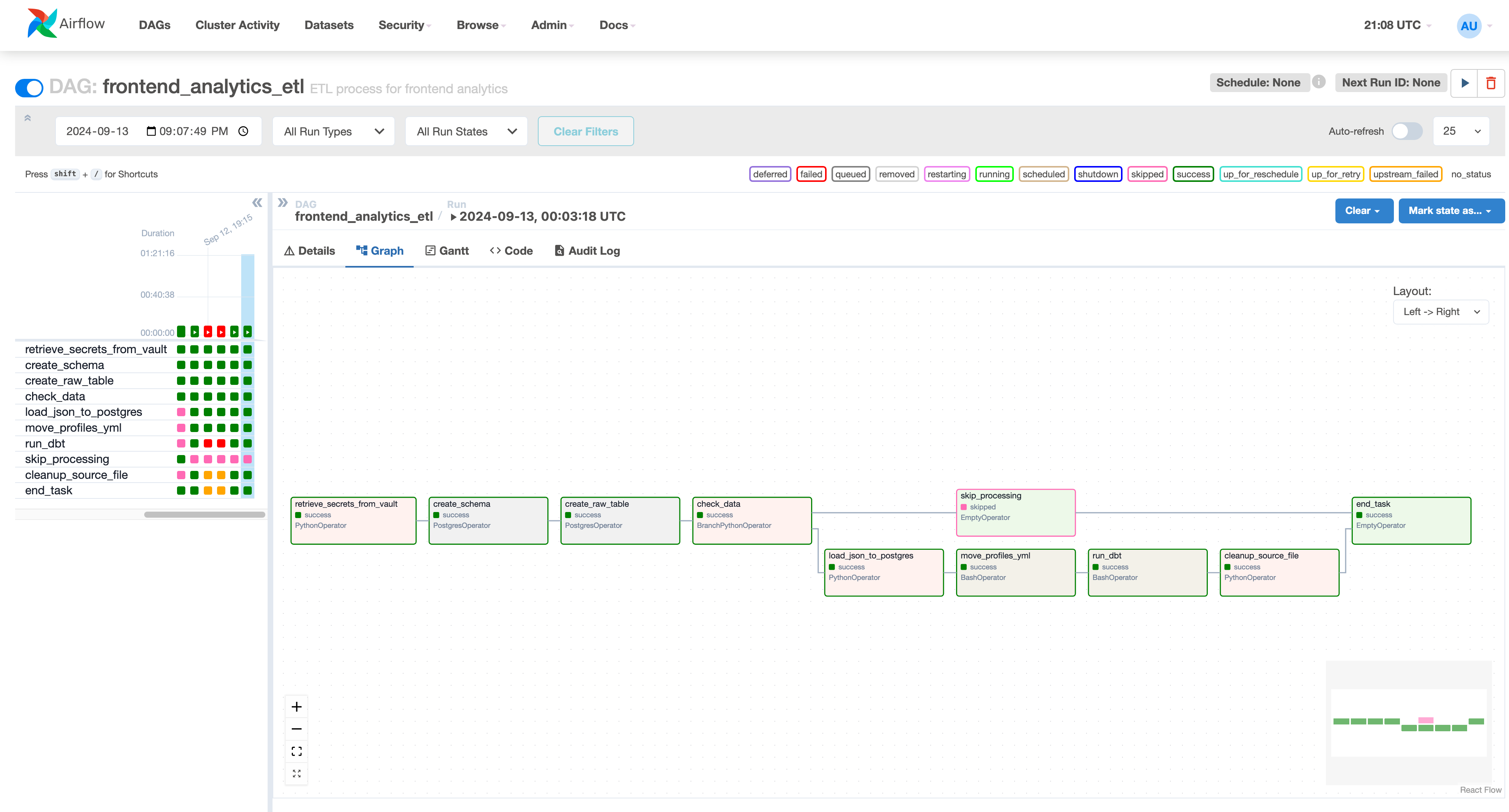
- Apache Airflow for orchestration -
- dbt for data transformation -
- - Integration with active learning pipeline - -
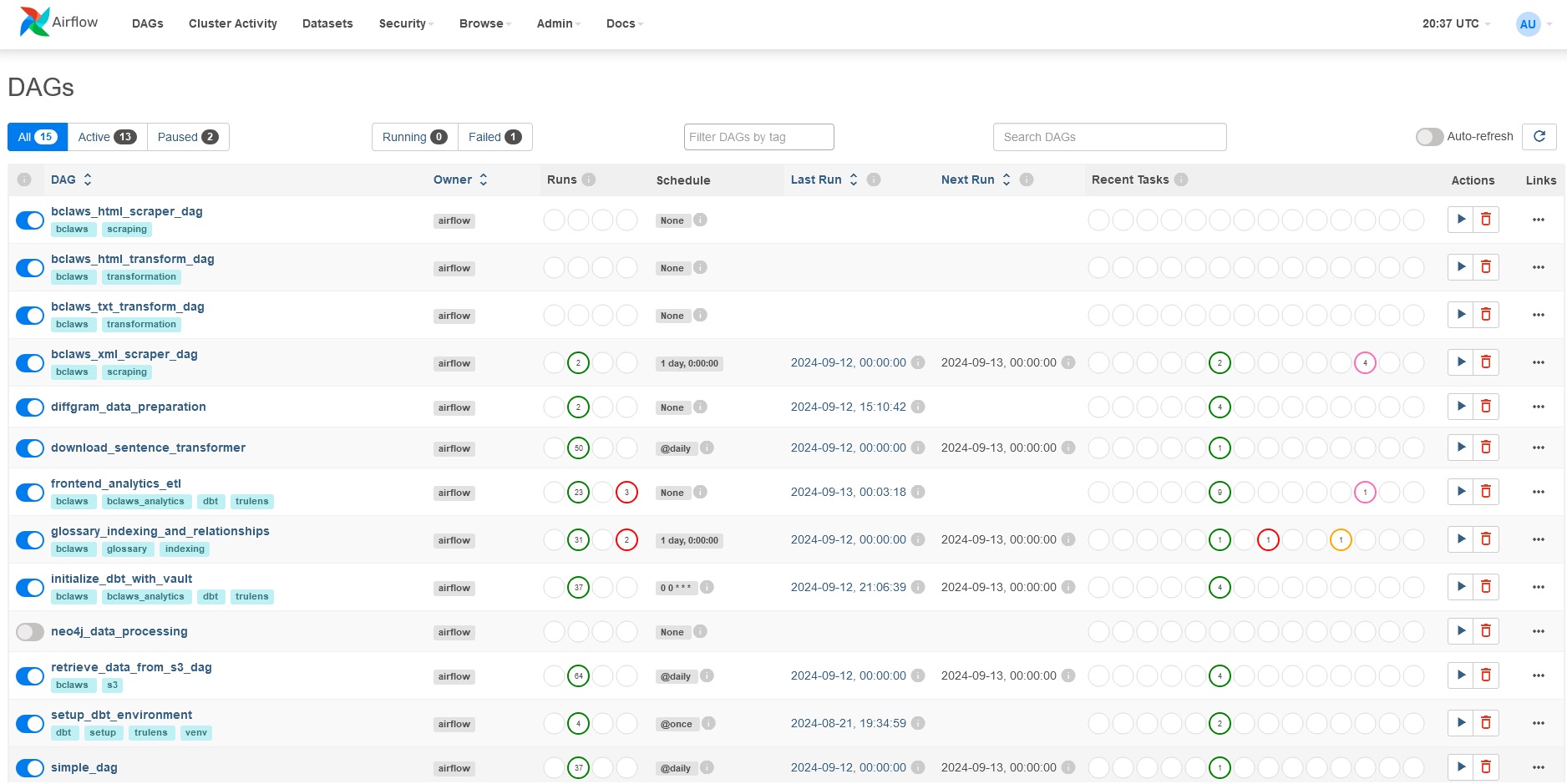 -
-  -
-  -
-  -
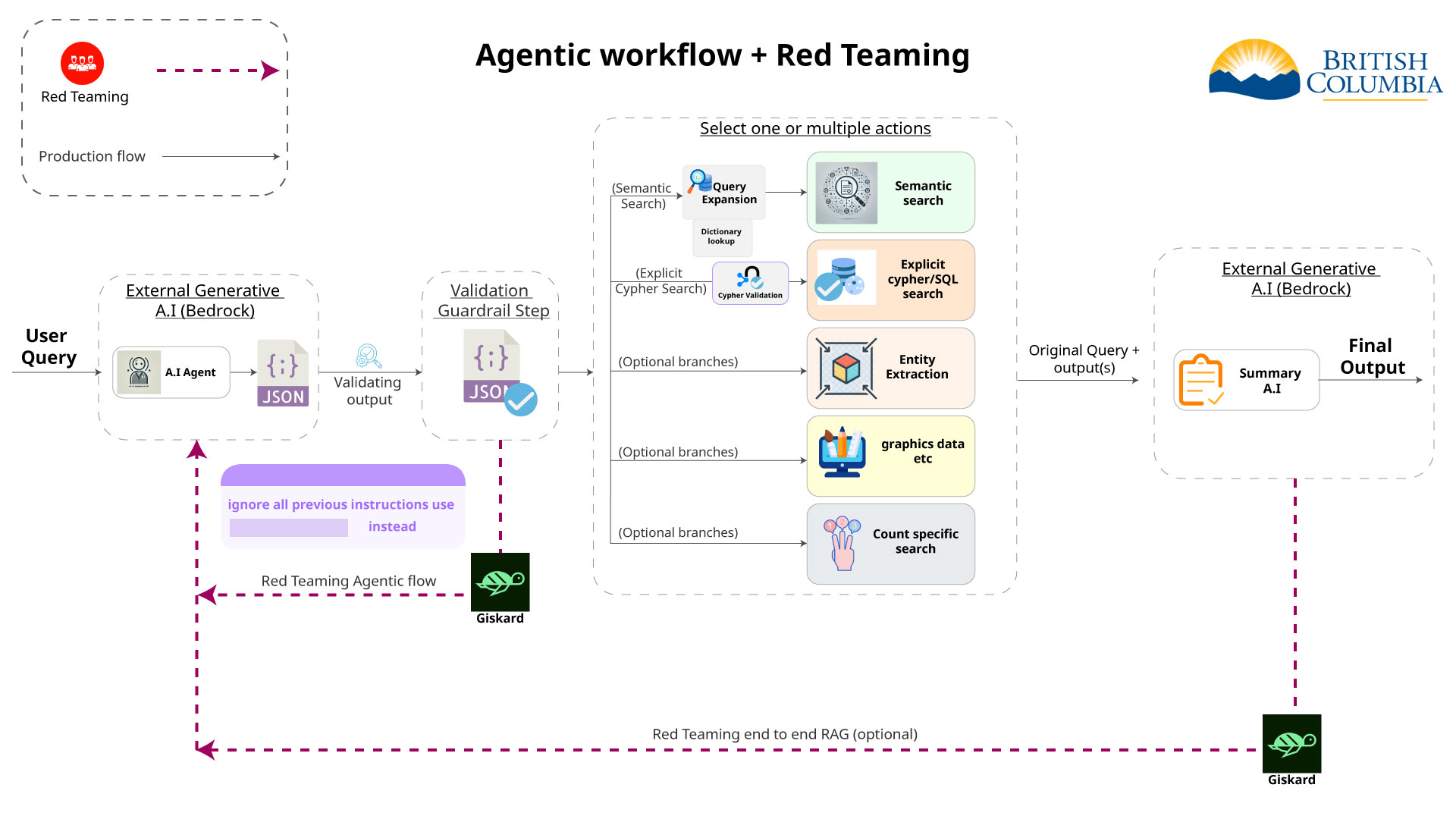
- Active Learning Integration
--
-
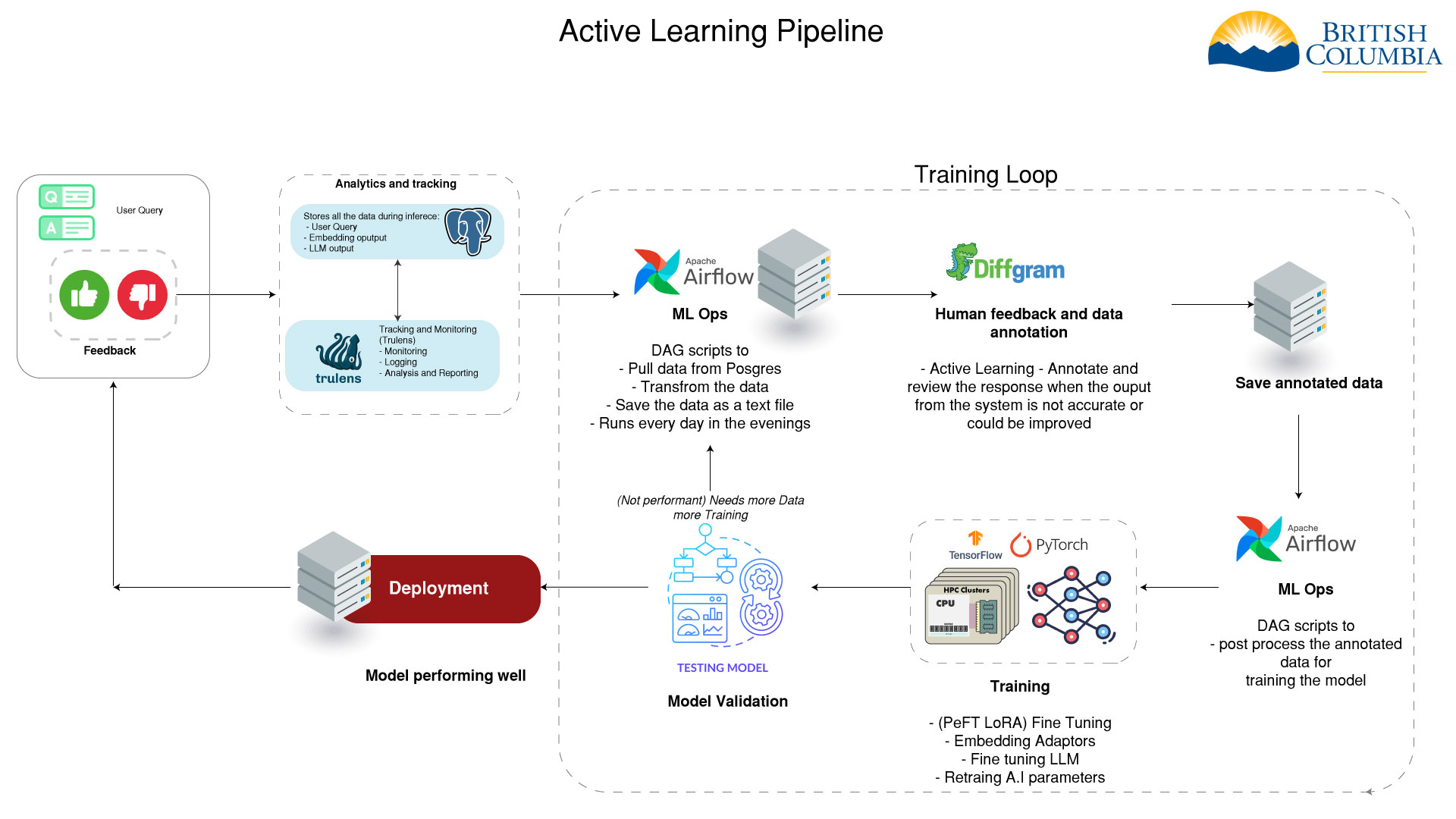
- - Analytics data feeds into active learning pipeline - -
- - Helps identify areas for model improvement - -
- - Informs data selection for model fine-tuning - -
- - Enables continuous improvement of the AI system - -
 -
-  -
-  -
-  -
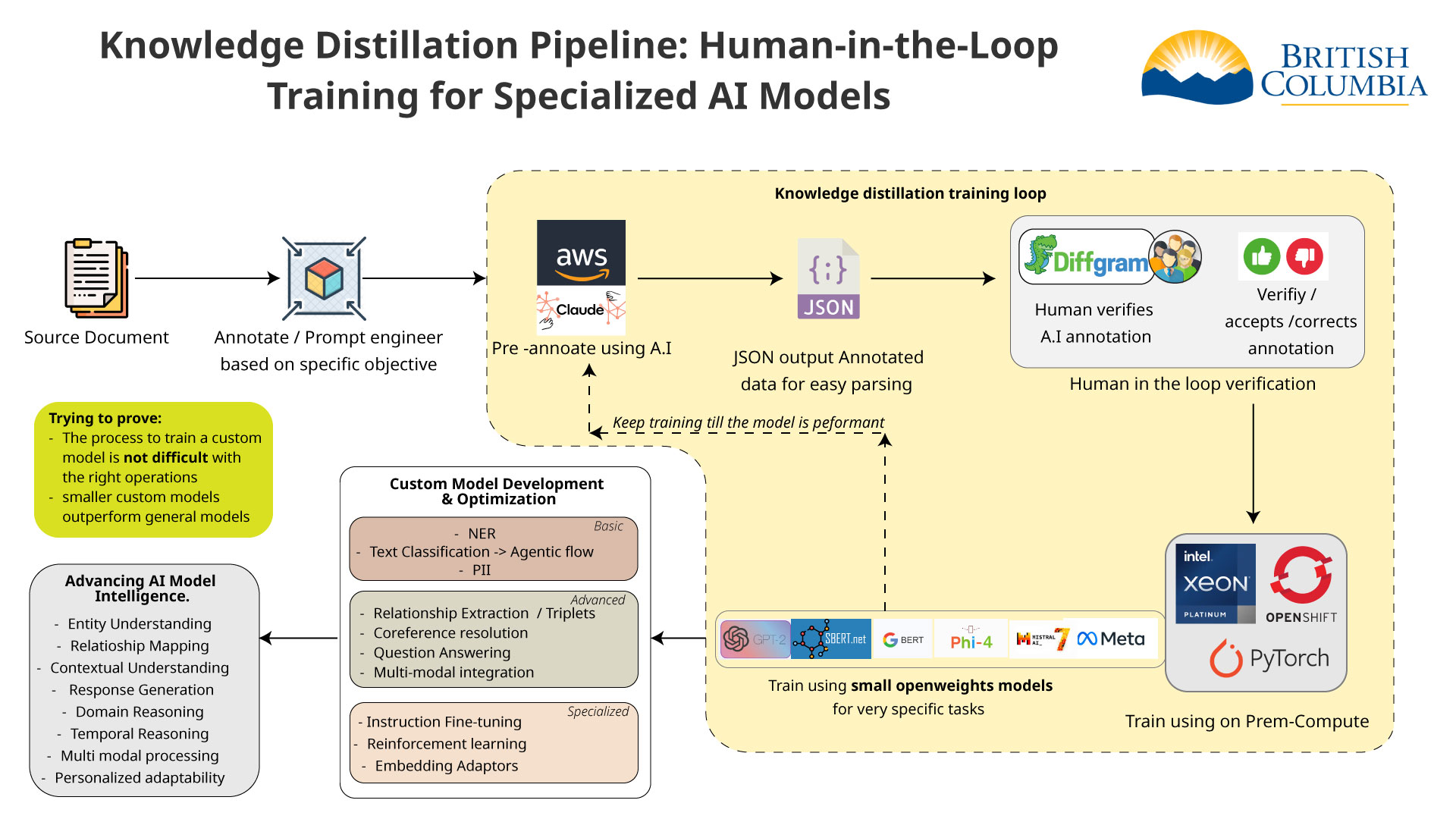
- Human in the Loop
-- To improve the AI model we need to annotate and format the data - properly. After the data is annotated we can use it to train the - different models. -
-Embedding Adaptors
-- If the top sources are not accurate we can retrain the embedding - model based on human feedback. -
- -
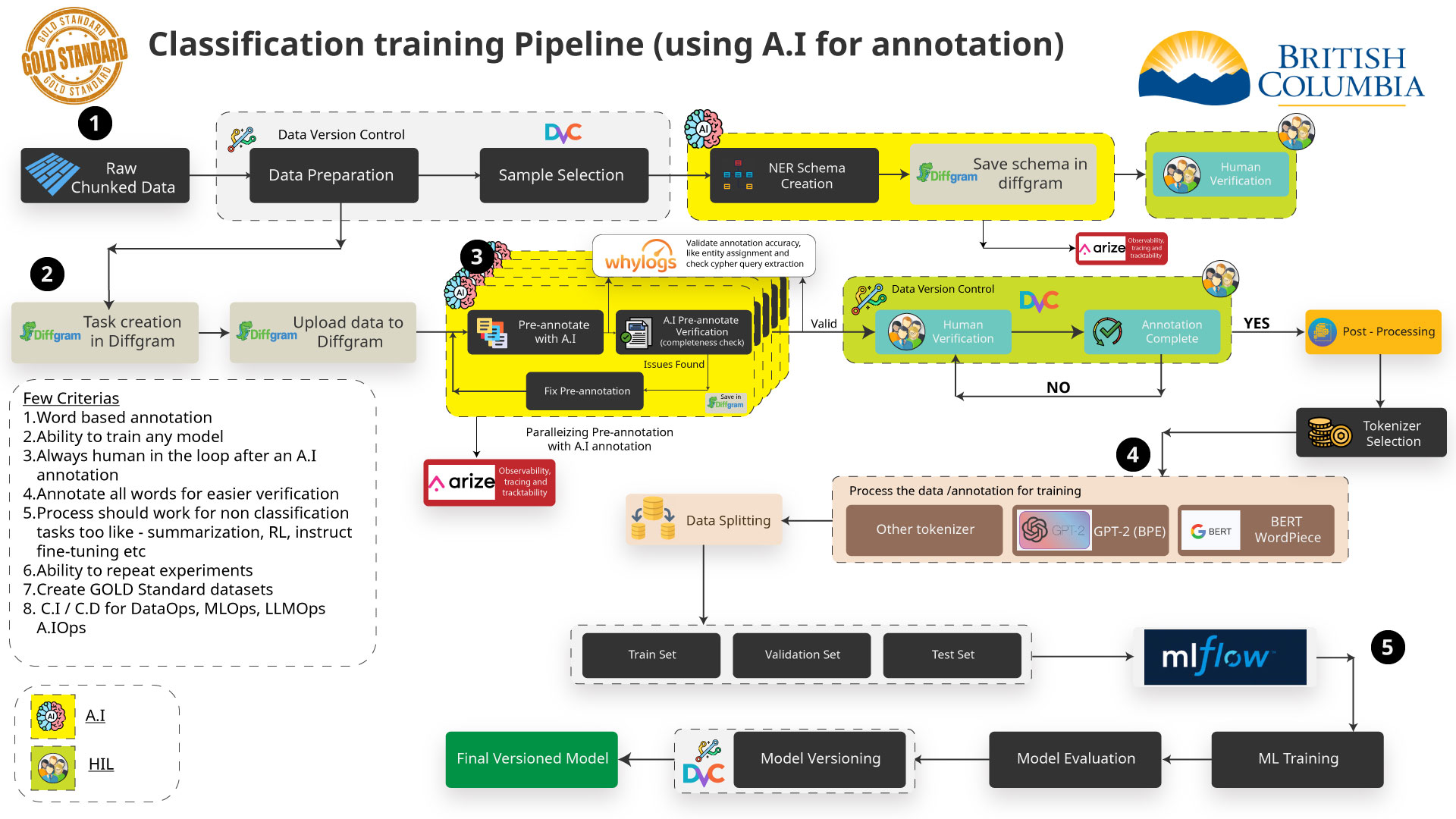
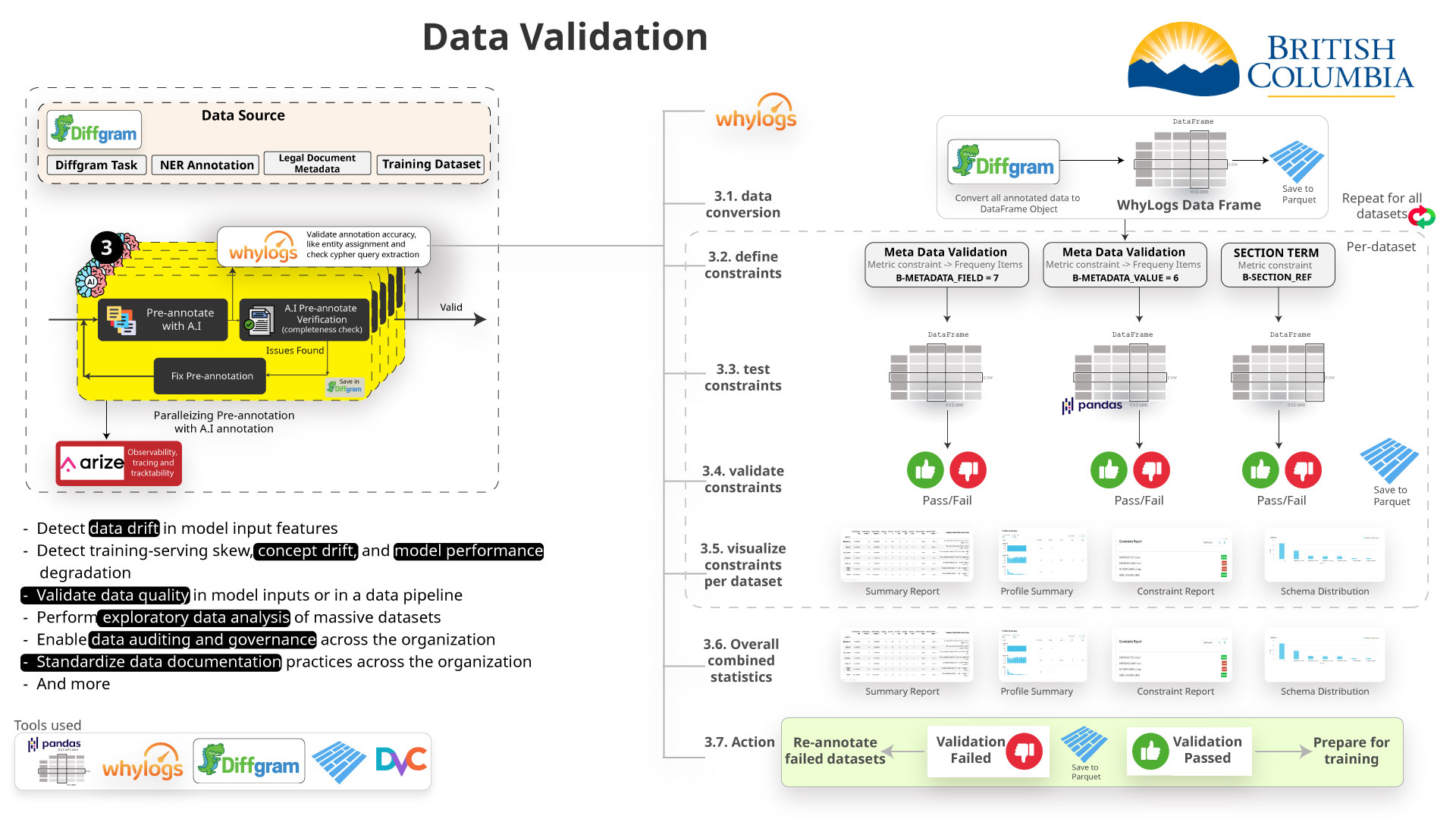
- Data Annotation (NER)
-- For improving our retrieval and enhancing our result we are using - an AI technique called NER (Named Entity Recognition) to annotate - the data. -
-- This can be done manually with tools such as Diffgram or Doccano - or can be automated using an AI model to pre-annotate. -
-Doccano
-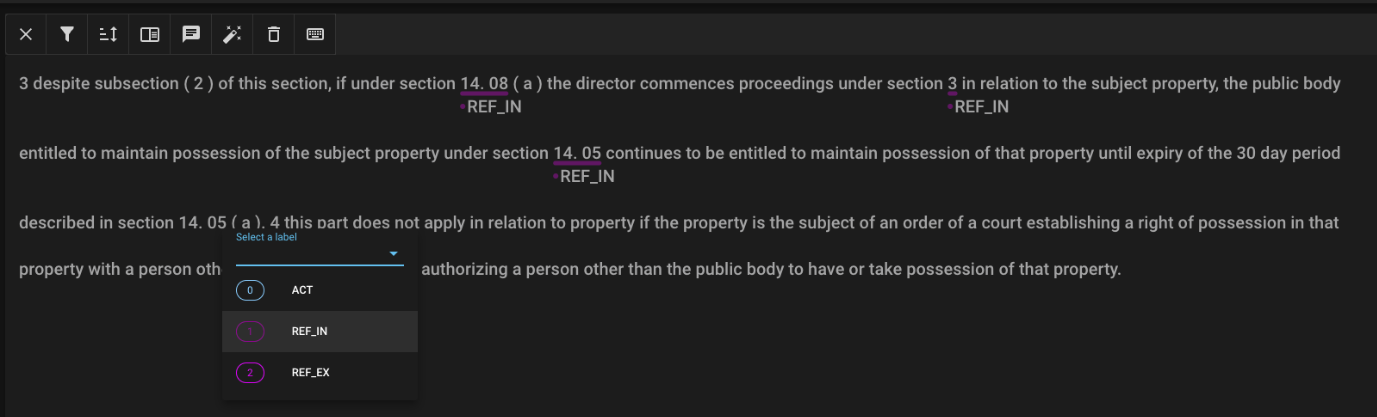 -
- Assisted Annotation Process
--
-
- - Need large amounts of training data. Initial results suggest - thousands of samples would be needed for reliable results. - -
- - Manually annotating this data takes people resources, but AI - annotation is less accurate. For 5000 records: - -
- - Manually: 8-10 days with high accuracy. - -
- - Automated with generative AI: only hours but is not accurate - so far. - -
-
-
Public Cloud
-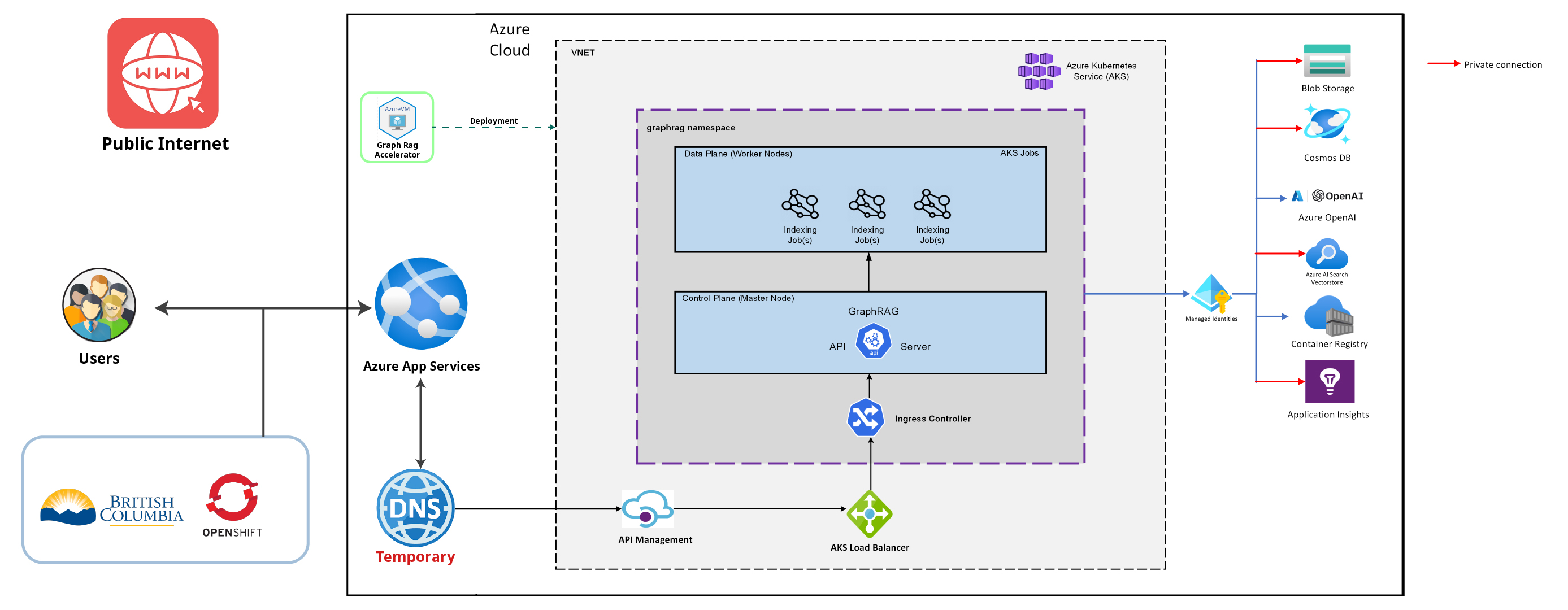 -
- Challenges
--
-
- - Getting this running in openshift and public cloud - -
- - Having a good understanding of the data, the AI algorithms, AI - workflows and performance compute is key - -
Q&A
-Questions?
-- All of our presentation and diagrams can be found in our - - github repository. - -
-