|
| 1 | +--- |
| 2 | +title: LLM RAG (大语言模型检索增强生成技术)的前世今生 |
| 3 | +date: 2024-10-08T14:53:54Z |
| 4 | +slug: post-21 |
| 5 | +author: chaseFunny:https://github.com/chaseFunny |
| 6 | +tags: ["AI","LLM","RAG"] |
| 7 | +--- |
| 8 | + |
| 9 | +标题: |
| 10 | + |
| 11 | +1. 我发现所有 AI 对话助手都使用了这项技术? |
| 12 | + |
| 13 | +> 整合资料,记录 LLM RAG 技术产生的背景,如何实现,解决了的问题 |
| 14 | +
|
| 15 | + |
| 16 | +## 什么是 LLM RAG ? |
| 17 | +LLM:Large Language Model (大型语言模型) |
| 18 | + |
| 19 | +RAG:Retrieval-Augmented Generation (检索增强生成) |
| 20 | + |
| 21 | +大语言模型的检索增强生成技术是一项通过结合外部知识库来**优化**大型语言模型的**输出**。这种技术的核心思想是从外部数据库中检索相关的信息,并将其与用户的查询一起输入到生成模块中,以生成更准确、更相关、更实时的响应回复 |
| 22 | + |
| 23 | +## 产生背景 |
| 24 | +其实 RAG 技术在 2020 年就被提出, Facebook 的一篇论文:《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 中首次引入了 RAG 的概念,这篇论文要解决的一个问题非常简单:如何让语言模型使用外部知识(external knowledge)进行生成。通常,预训练模型的知识存储在参数中,这就导致了模型不知道训练集之外的知识(例如搜索数据、行业的知识)。之前的做法是有新的知识就再重新在预训练的模型上进行**微调**。但是这样有两个问题: |
| 25 | + |
| 26 | +1. 每次有新的知识后都需要进行**微调** |
| 27 | +2. 训练模型的成本是很高的 |
| 28 | + |
| 29 | +于是就有了 RAG,它利用预训练模型能够学习理解新的知识的能力,通过在 prompt 输入需要的新知识来实现更加可靠的回复,最后我们来看一下 LLM 目前的问题, |
| 30 | + |
| 31 | + |
| 32 | + |
| 33 | +以上来源:[https://github.com/datawhalechina/llm-universe/blob/main/docs/C1/2.%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%20RAG%20%E7%AE%80%E4%BB%8B.md](https://github.com/datawhalechina/llm-universe/blob/main/docs/C1/2.%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%20RAG%20%E7%AE%80%E4%BB%8B.md) |
| 34 | + |
| 35 | +## RAG 系统组成和工作原理 |
| 36 | +一个最小的 RAG 系统就是由 3 个部分组成的: |
| 37 | + |
| 38 | +1. 语言模型 |
| 39 | +2. 模型所需要的外部知识集合(以 vector 的形式存储) |
| 40 | +3. 当前场景下需要的外部知识 |
| 41 | + |
| 42 | +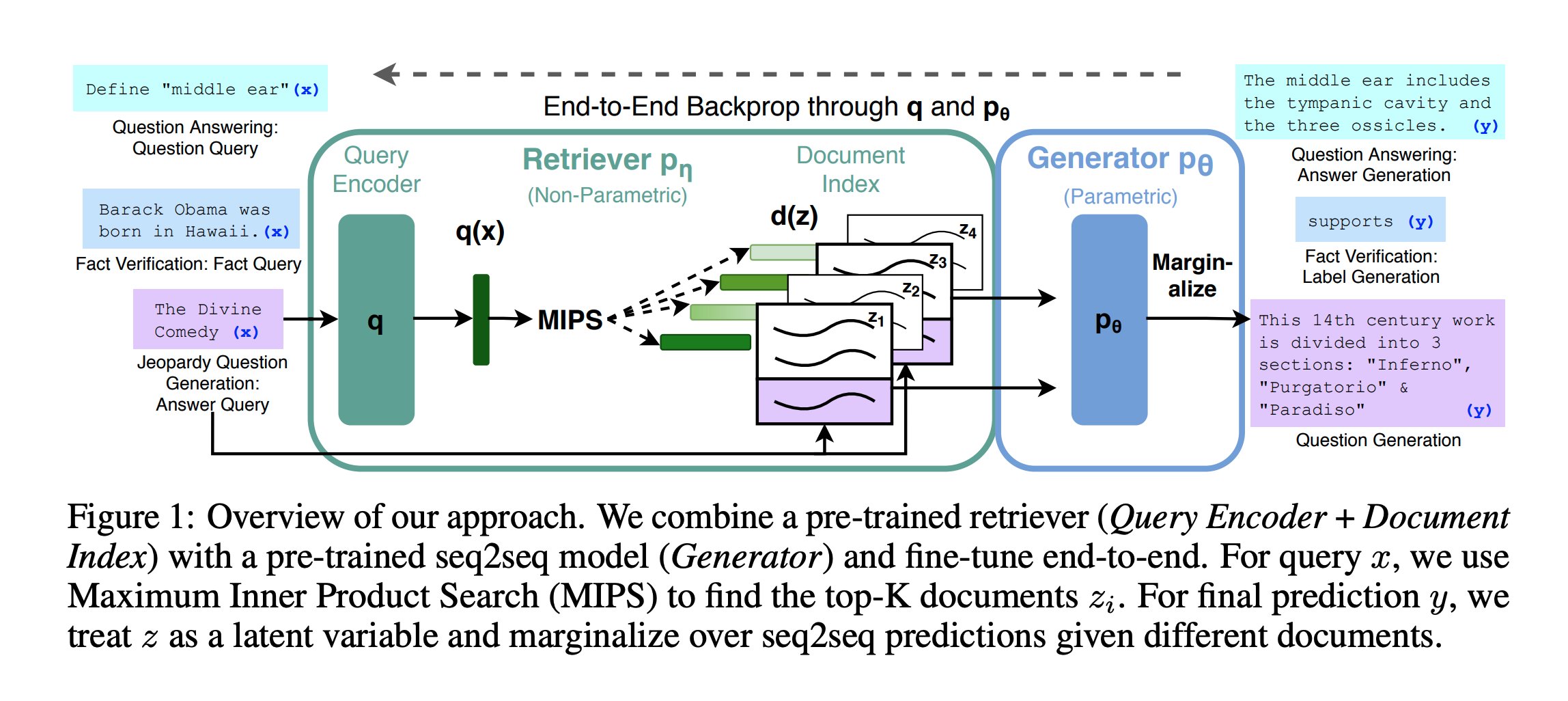 |
| 43 | + |
| 44 | +上图是 RAG 系统的组成图,简单介绍: |
| 45 | + |
| 46 | +1. 输入查询: 图的左侧显示了三种不同类型的输入查询: |
| 47 | + - 问答任务:例如"定义'中耳'" |
| 48 | + - 事实验证:例如"巴拉克·奥巴马出生于夏威夷" |
| 49 | + - Jeopardy(反向问答)问题生成:例如"神曲",AI 来给出对应的问题 |
| 50 | +2. 查询编码器(Query Encoder): 将输入查询编码为向量表示q(x)。 |
| 51 | +3. 检索器pη(Retriever): 这是一个非参数化模型,使用最大内积搜索(MIPS)在文档索引中查找与查询相关的文档。 |
| 52 | +4. 文档索引d(z): 存储了预先编码的文档向量(z1, z2, z3, z4等)。 |
| 53 | +5. 生成器pθ(Generator): 这是一个参数化模型,基于检索到的文档生成最终答案。 |
| 54 | +6. 边缘化(Marginalize): 对不同文档的seq2seq预测进行边缘化处理,得到最终输出。 |
| 55 | +7. 输出: 根据任务类型生成不同的输出: |
| 56 | + - 问答:生成答案,如"中耳包括鼓室和三块听小骨" |
| 57 | + - 事实验证:生成标签,如"支持" |
| 58 | + - 问题生成:生成问题,如"这部14世纪的作品分为3个部分:'地狱'、'炼狱'和'天堂'" |
| 59 | +8. 端到端反向传播: 整个过程通过q和pθ进行端到端的反向传播,以优化模型性能。 |
| 60 | +9. 方法概述: 该方法结合了预训练的检索器(查询编码器+文档索引)和预训练的seq2seq模型(生成器),并进行端到端的微调。对于查询x,使用MIPS找到top-K相关文档zi。在最终预测y时,将z视为潜在变量,并对不同文档的seq2seq预测进行边缘化。 |
| 61 | + |
| 62 | +这种方法的优势在于它能够处理多种 NLP(Natural Language Processing 也就是 自然语言处理) 任务,并通过结合检索和生成模型来提高性能。通过端到端的训练,系统可以学习更好地协调检索和生成过程,从而产生更准确的结果。 |
| 63 | + |
| 64 | +RAG 系统的工作流程如下: |
| 65 | + |
| 66 | + |
| 67 | + |
| 68 | +我们快速和宏观的看一下如何打造一个 RAG chat bot 的全流程: |
| 69 | + |
| 70 | +1. 加载数据 |
| 71 | + |
| 72 | +在真实项目,可能数据源的格式多种,例如 pdf、code、现存数据库、云数据库等等,我们需要将这些数据都加载进来,一般使用向量数据库 |
| 73 | + |
| 74 | +2. 切分数据 |
| 75 | + |
| 76 | +模型可接受的数据是有限的,这时候我们就需要把数据切分,但是数据源的多种多样和自然语言的特点,事实上切分函数的选择和参数的设定是非常难以控制的。理论上我们是希望每个文档块都是语意相关,并且相互独立的。 |
| 77 | + |
| 78 | +3. 嵌入 |
| 79 | + |
| 80 | +文本转为向量的过程,然后通过相似度匹配,来检索出我们想要的数据,同时解决了内容太大的问题 |
| 81 | + |
| 82 | +4. 检索数据 |
| 83 | + |
| 84 | +把问题转为向量,和向量数据库中向量进行检索得到想要的结果 |
| 85 | + |
| 86 | +这里还可以通过传统的关系形数据库 + Elasticsearch 来进行数据检索 |
| 87 | + |
| 88 | +5. 增强 prompt |
| 89 | + |
| 90 | +其实上面所有做的都是为增强 prompt,我们对检索的信息 + 用户提问进行整合得到增强的 prompt ,提交给 LLM |
| 91 | + |
| 92 | +6. 生成 |
| 93 | + |
| 94 | +把增强的 prompt 传递给生成结果模型,来生成答案 |
| 95 | + |
| 96 | + |
| 97 | + |
| 98 | +## 总结 |
| 99 | +有两个通俗理解 RAG 作用的方式 |
| 100 | + |
| 101 | +1. RAG 是给 LLM 开外挂 |
| 102 | +2. LLM 充当会思考的大脑角色,RAG 是获取相关知识的角色,通过 RAG 得到的知识集合,然后通过 LLM 来思考整理生成结果 |
| 103 | + |
| 104 | +## 参考 |
| 105 | +1. devv 如何构建高效 RAG 系统:[https://x.com/forrestzh_/status/1731478506465636749](https://x.com/forrestzh_/status/1731478506465636749?s=20) |
| 106 | +2. RAG 简介:[https://github.com/datawhalechina/llm-universe/blob/main/docs/C1/2.%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%20RAG%20%E7%AE%80%E4%BB%8B.md](https://github.com/datawhalechina/llm-universe/blob/main/docs/C1/2.%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90%20RAG%20%E7%AE%80%E4%BB%8B.md) |
| 107 | + |
| 108 | + |
| 109 | + |
| 110 | +--- |
| 111 | +此文自动发布于:<a href="https://github.com/coderPerseus/blog/issues/21" target="_blank">github issues</a> |
0 commit comments