InducingPointKernel prediction scales with N^2? #1708
-
|
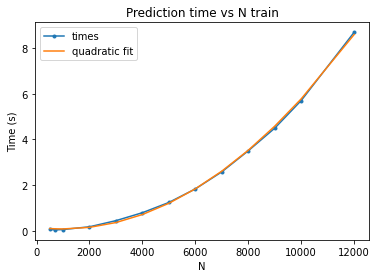
It seems to be that posterior prediction with the inducing point kernel scales with O(N^2) instead of O(N) like you would expect from reading the paper by Titsias et al, 2009. Is this intended behaviour? Edit: Update: I checked with GPy and it should scale linearly. They had a PR in 2019 that fixed this. Maybe gpytorch is doing the same thing... Edit 2: I wasn't on the latest version of gpytorch. I updated and it's a bit faster but the scaling is still quadratic (the plot looks the same qualitatively). Edit 3: I think the issue is here. SGPR prediction strategy overrides CodeI added the following cell to the end of SGPR_Regression_CUDA and got the following plot (without GPU on my machine): import datetime
import numpy as np
N_list = [500, 700, 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000, 12000,]
time_list = []
for N in N_list:
model.train(); likelihood.train()
# replace training data
model.set_train_data(train_x[:N], train_y[:N], strict=False)
# Get predictions
model.eval()
likelihood.eval()
start_time = datetime.datetime.now()
with gpytorch.settings.fast_computations(False, False, False), torch.no_grad():
preds = model(test_x)
mae = torch.mean(torch.abs(preds.mean - test_y)).item()
end_time = datetime.datetime.now()
time_list.append((end_time-start_time).total_seconds())
print(f'N={N} time={time_list[-1]:.1f} MAE={mae:.3f}')
# Plotting
poly_coeff = np.polyfit(N_list, time_list, deg=2)
poly_pred = np.polyval(poly_coeff, N_list)
plt.plot(N_list, time_list, ".-", label="times")
plt.plot(N_list, poly_pred, "-", label="quadratic fit")
plt.legend()
plt.xlabel("N")
plt.ylabel("Time (s)")
plt.title("Prediction time vs N train")
plt.show()Output showing clear quadratic scaling: |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 3 replies
-
|
My guess of what's going on in the predictive mean is that when you turn fast computations off, you end up evaluating and then computing something more like a dense cholesky decomposition of the |
Beta Was this translation helpful? Give feedback.
-
|
Good suggestion. If I turn fast computations on then the runtime is linear with |
Beta Was this translation helpful? Give feedback.
-
|
Yeah it certainly should do things smarter when it calls Cholesky. I suppose we could either override mean cache on the SGPR predictive strategy or do something on the lazy tensor whenever fast computations is off |
Beta Was this translation helpful? Give feedback.
-
|
Looked into this. The good news is, with fast computations on, it's already not using CG for SGPR, because So, the trivial way to fix this problem is to just not turn The bad news is that the The best news is that this is a trivial one line fix in |
Beta Was this translation helpful? Give feedback.
-
|
Was better to fix by modifying |
Beta Was this translation helpful? Give feedback.
-
|
Wow, neat solution! Thanks so much for this 😍 |
Beta Was this translation helpful? Give feedback.
@AustinT @wjmaddox #1709
Was better to fix by modifying
LowRankRootAddedDiagLazyTensoractually, just had to overrideinv_matmul. Thefast_computationssetting should now properly do nothing when either training or testing with SGPR -- it already did nothing for training.