|
| 1 | +--- |
| 2 | +date: 2024-11-23 15:20:18 |
| 3 | +title: k8s笔记 |
| 4 | +createdTime: 23-05-21 (星期日) 21:17 |
| 5 | +updateTime: 25-01-03 (星期五) 17:28 |
| 6 | +--- |
| 7 | + |
| 8 | + |
| 9 | +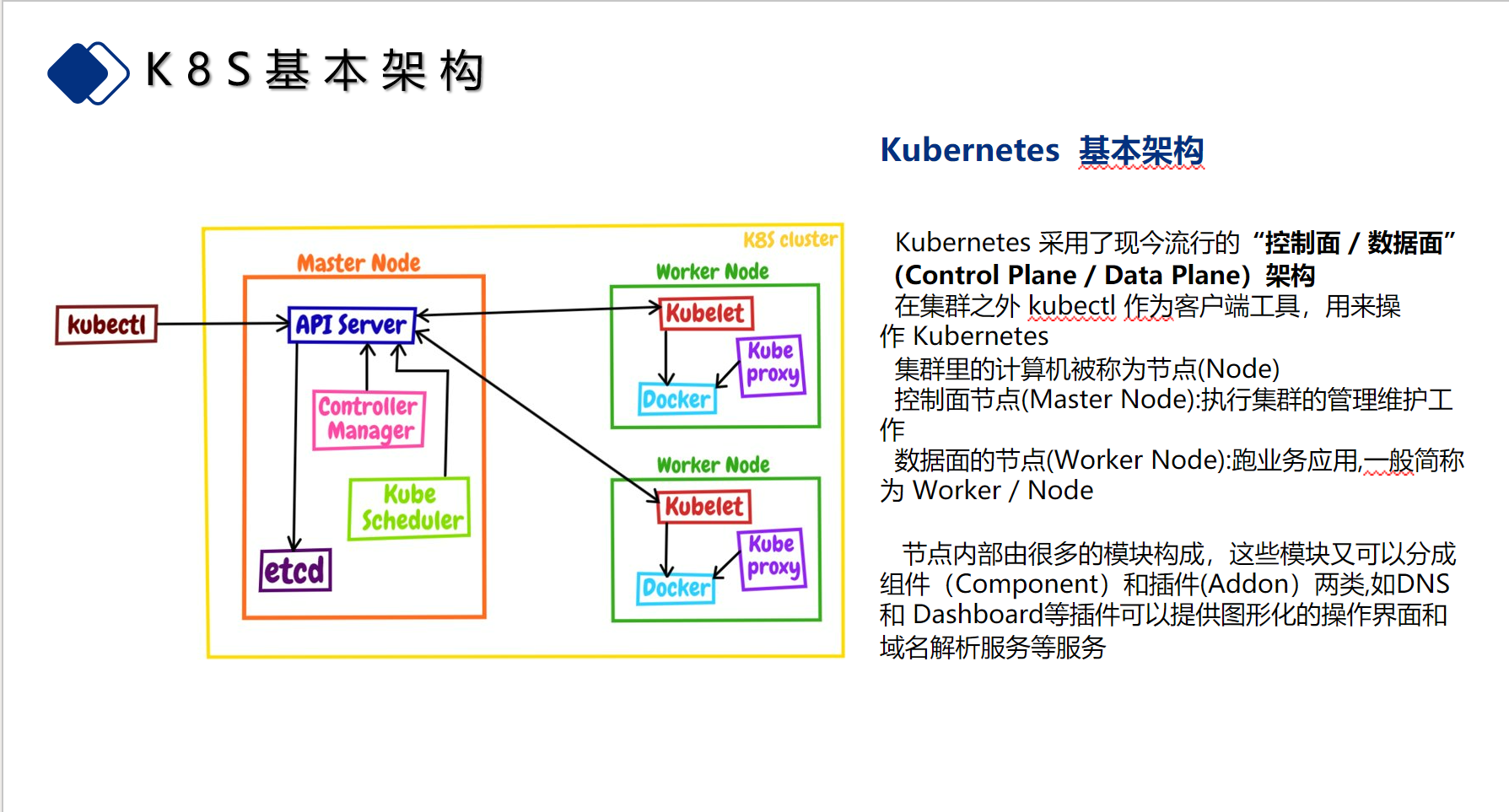 |
| 10 | + |
| 11 | +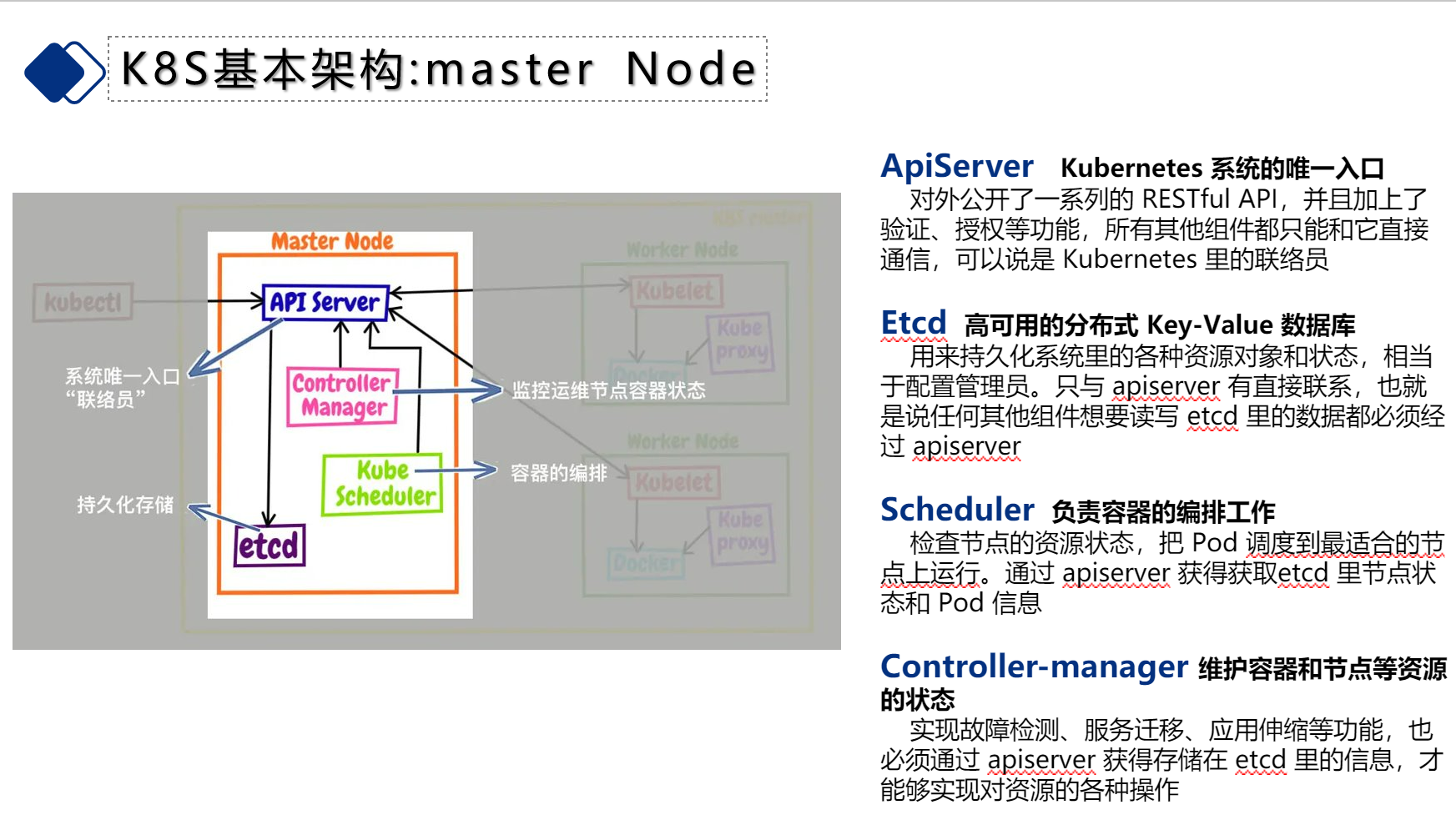 |
| 12 | + |
| 13 | +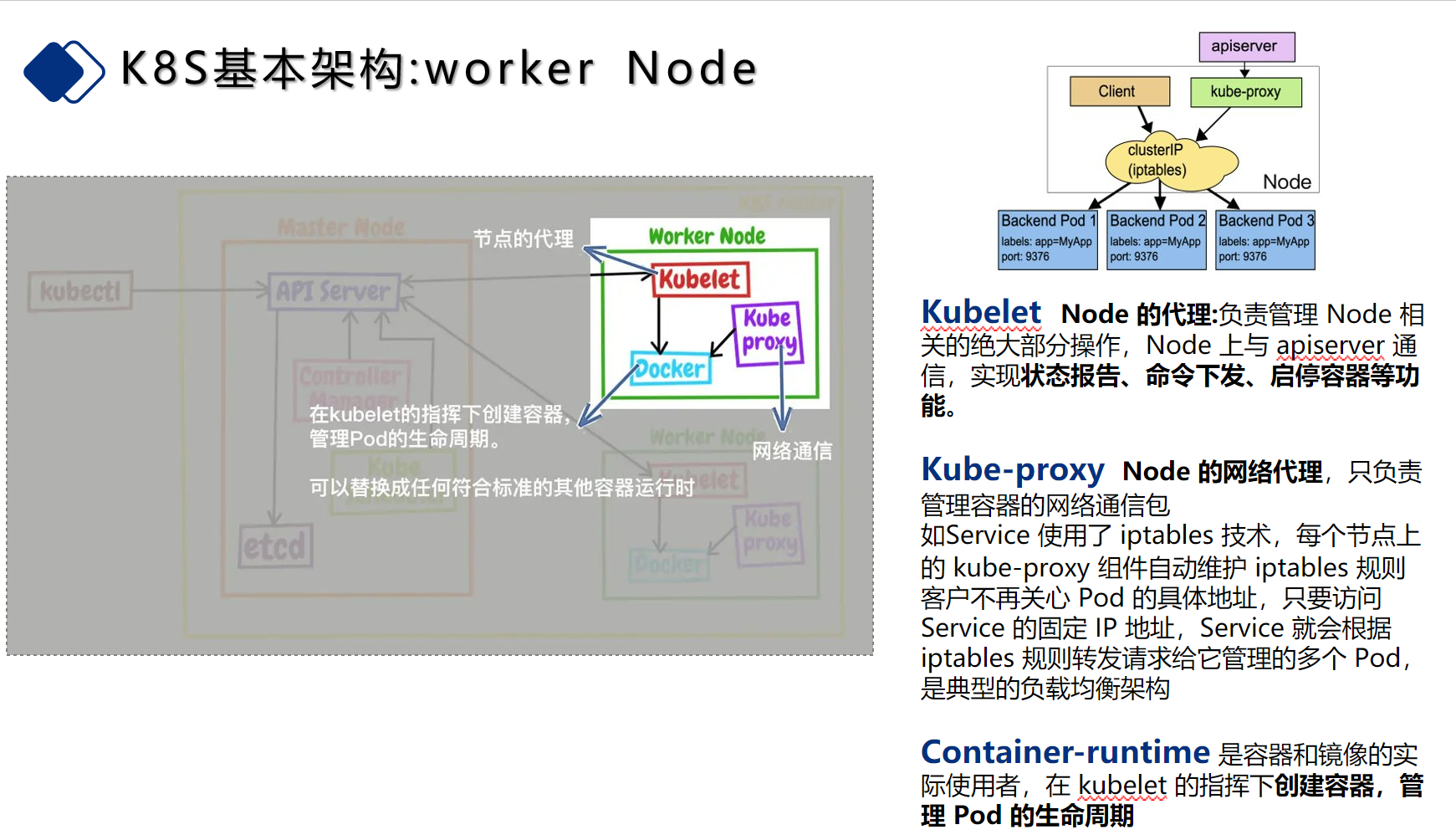 |
| 14 | + |
| 15 | + |
| 16 | + |
| 17 | +## K8S的对象 |
| 18 | + |
| 19 | +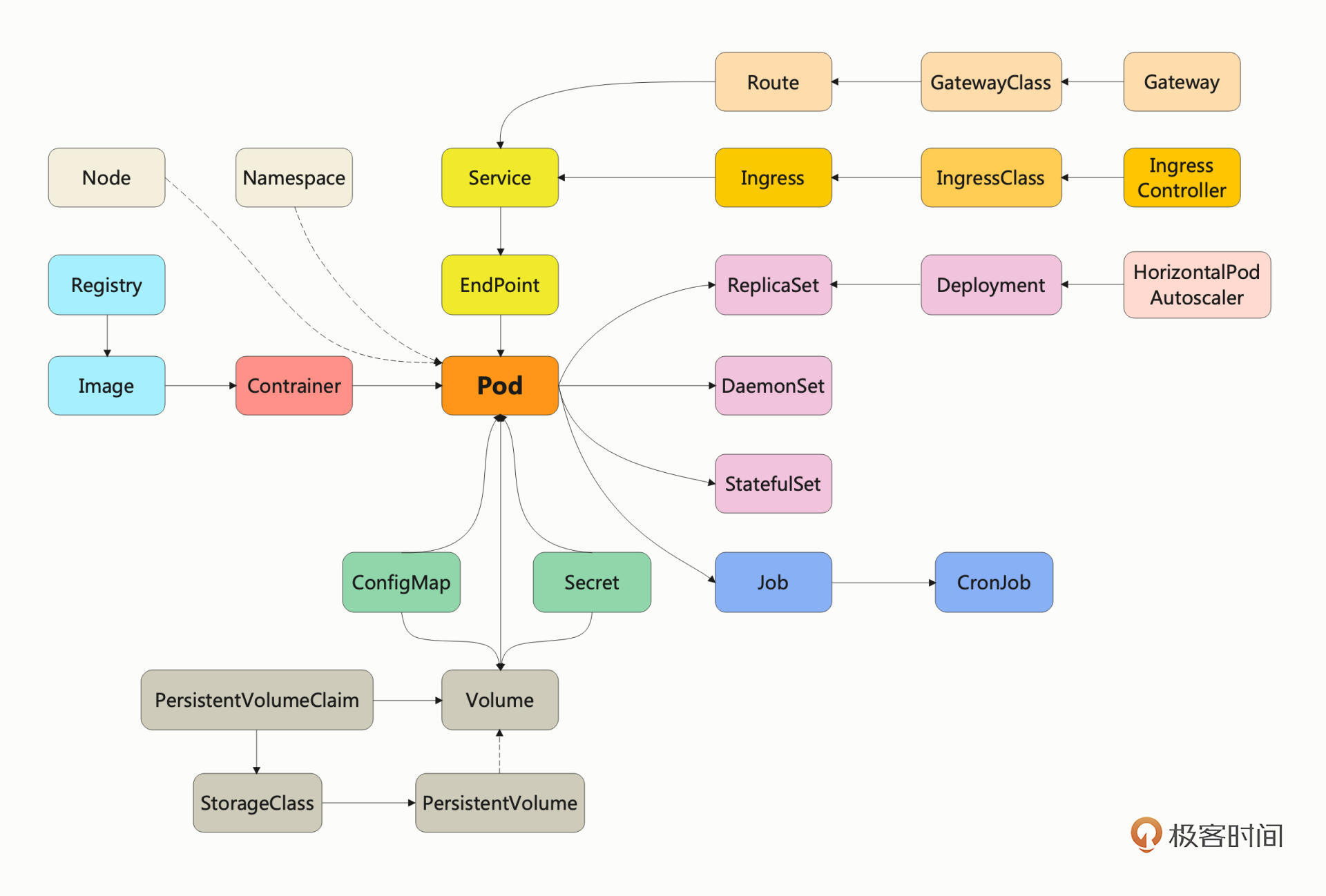 |
| 20 | + |
| 21 | +### 离线业务->临时任务->只跑一次:job,定时任务:cronjob |
| 22 | + |
| 23 | +**一些字段** |
| 24 | +activeDeadlineSeconds,设置 Pod 运行的超时时间。 |
| 25 | + |
| 26 | +backoffLimit,设置 Pod 的失败重试次数。 |
| 27 | + |
| 28 | +completions,Job 完成需要运行多少个 Pod,默认是 1 个。 |
| 29 | + |
| 30 | +parallelism,它与 completions 相关,表示允许并发运行的 Pod 数量,避免过多占用资源。 |
| 31 | + |
| 32 | + |
| 33 | + |
| 34 | + |
| 35 | + |
| 36 | +### ConfigMap/Secret:明文/秘文配置信息 |
| 37 | + |
| 38 | +> 不是容器 不需要spec字段说明允许规格 |
| 39 | +> |
| 40 | +> containers”里有一个“env”,它定义了 Pod 里容器能够看到的环境变量 |
| 41 | +> |
| 42 | +> 可以使用了简单的“value”,把环境变量的值写“死”在了 YAML 里 |
| 43 | +> |
| 44 | +> 实际上它还可以使用另一个“valueFrom”字段,从 ConfigMap 或者 Secret 对象里获取值 |
| 45 | +> |
| 46 | +> * name”字段是 API 对象的名字,而不是 Key-Value 的名字。 |
| 47 | +
|
| 48 | +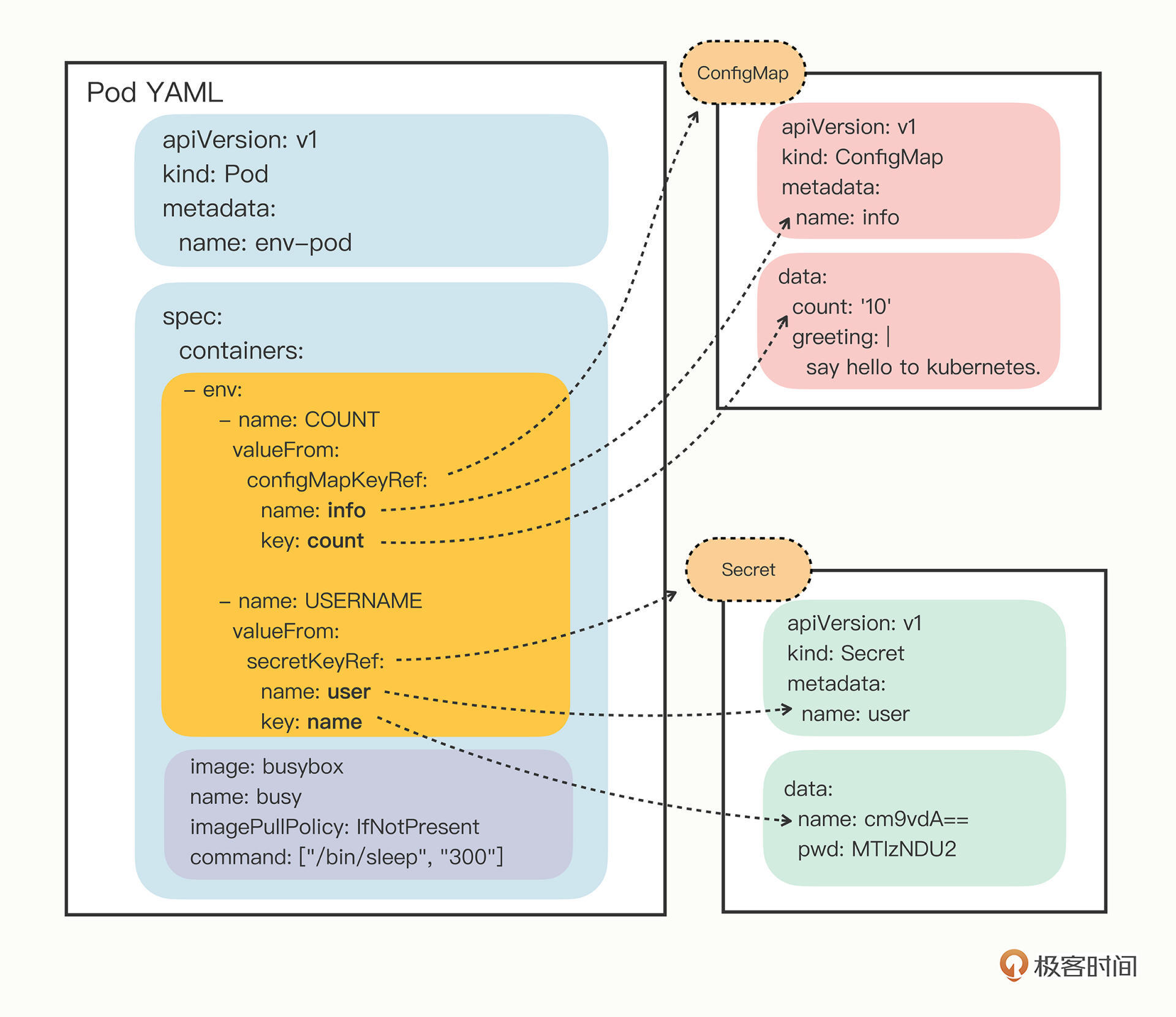 |
| 49 | + |
| 50 | +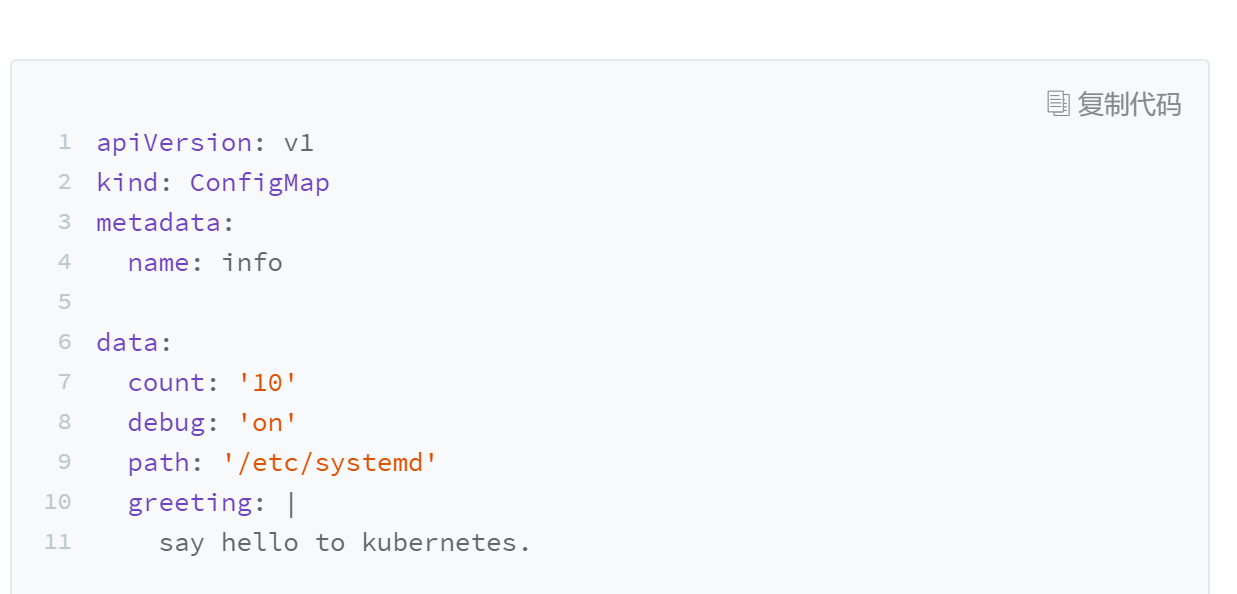 |
| 51 | + |
| 52 | + |
| 53 | + |
| 54 | +### Deployment:管理pod->pod管理container |
| 55 | + |
| 56 | +#### DaemonSet (spec 里没有 replicas 字段)在**每个节点上只创建出一个 Pod 实例** |
| 57 | + |
| 58 | +如需要运行在master node上 需要设置污点/容忍度 taint:tolerations |
| 59 | + |
| 60 | +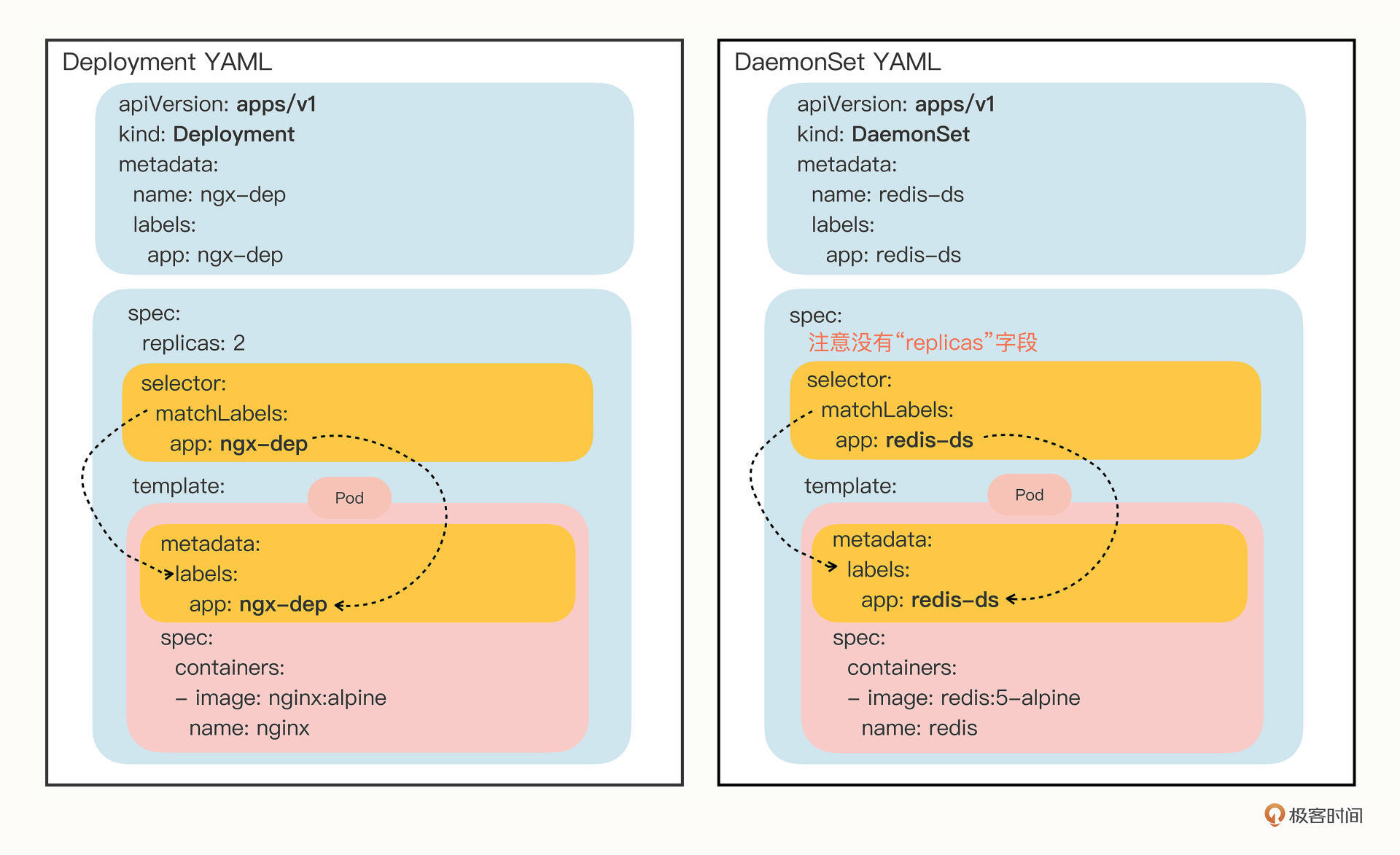 |
| 61 | +#### StatefulSet |
| 62 | + |
| 63 | +> 专门部署“有状态应用”的 API 对象 StatefulSet,它与 Deployment 非常相似,区别是由它管理的 Pod 会有固定的名字、启动顺序和网络标识,这些特性对于在集群里实施有主从、主备等关系的应用非常重要 |
| 64 | +
|
| 65 | +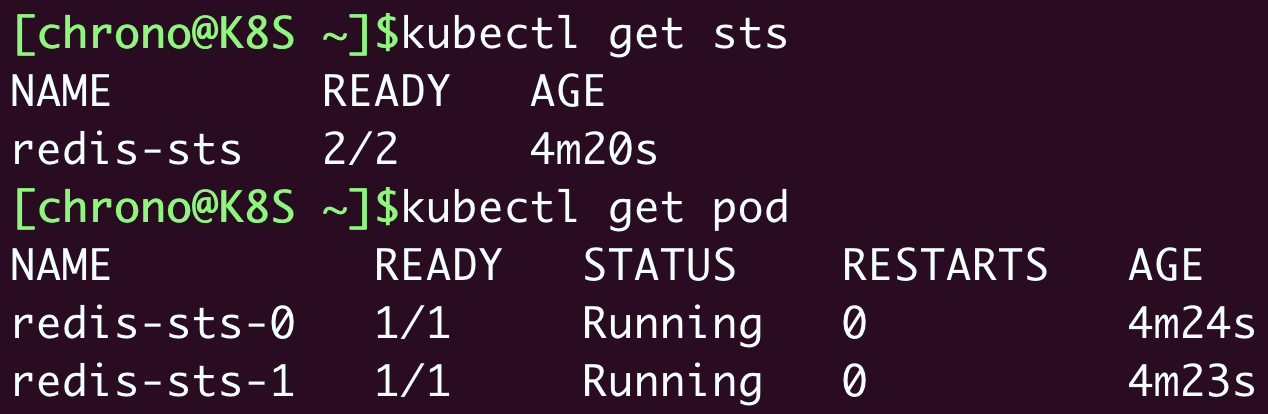 |
| 66 | + |
| 67 | +> **所管理的 Pod 不再是随机的名字了,而是有了顺序编号**,从 0 开始分别被命名为 redis-sts-0、redis-sts-1,Kubernetes 也会按照这个顺序依次创建(0 号比 1 号的 AGE 要长一点),这就解决了“**有状态应用”的第一个问题:启动顺序** |
| 68 | +> |
| 69 | +> **有了这个唯一的名字,应用就可以自行决定依赖关系了**, |
| 70 | +> |
| 71 | +> 如以 Redis 为例子里,就可以让先启动的 0 号 Pod 是主实例,后启动的 1 号 Pod 是从实例 |
| 72 | +> |
| 73 | +> Service 自己会有一个域名,格式是“对象名. 名字空间”,当我们把 Service 对象应用于 StatefulSet 的时候,**会为 Pod 再多创建出一个新的域名,格式是“Pod 名. 服务名. 名字空间.svc.cluster.local”/“Pod 名. 服务名**” |
| 74 | +> |
| 75 | +> 外部的客户端只要知道了 StatefulSet 对象,就**可以用固定的编号去访问某个具体的Pod了,虽然 Pod 的 IP 地址可能会变,但这个有编号的域名由 Service 对象维护,是稳定不变的** |
| 76 | +
|
| 77 | +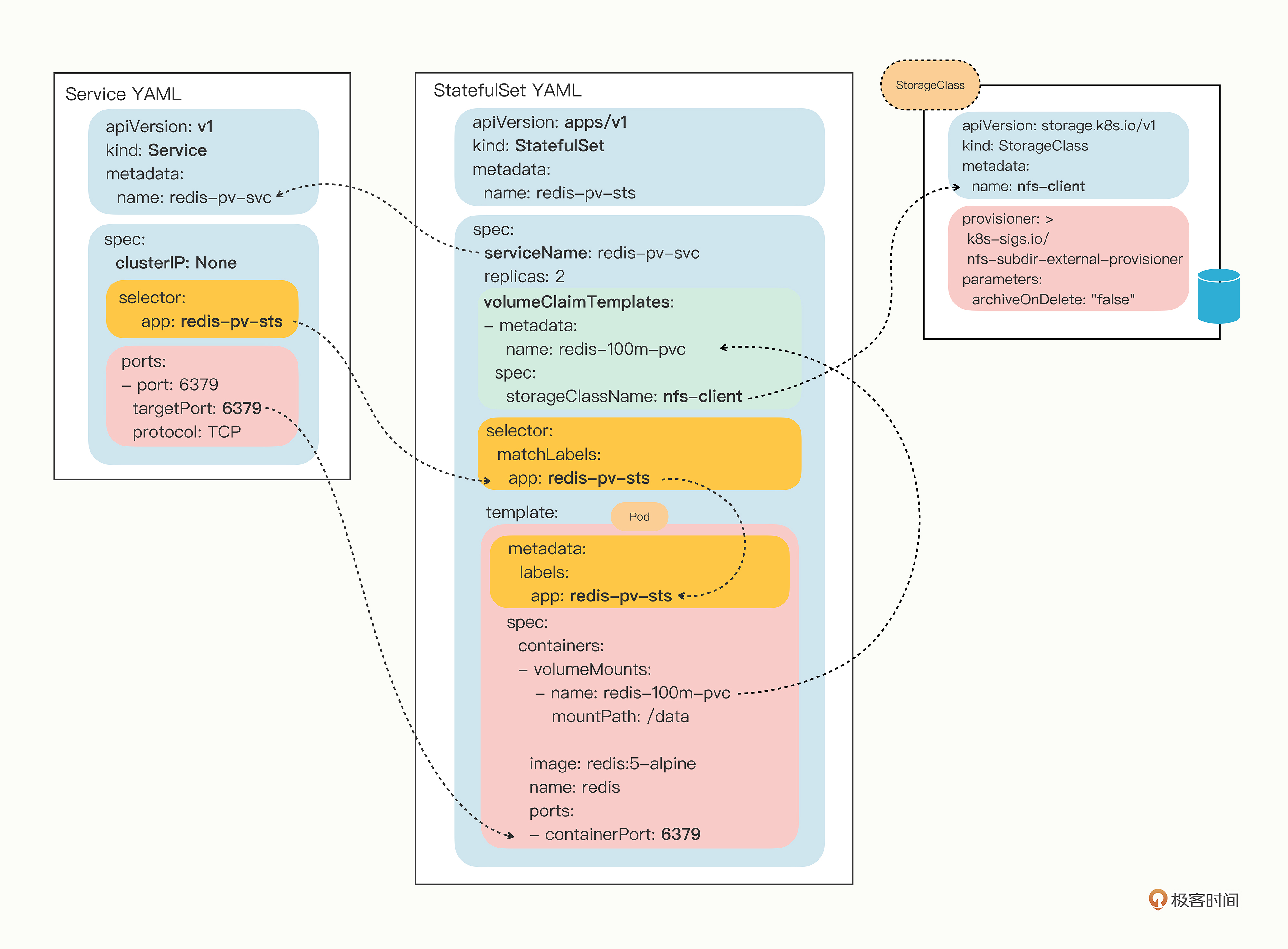 |
| 78 | + |
| 79 | +### Service与Ingress |
| 80 | + |
| 81 | +> 不再关心 Pod 的具体地址,只要访问 Service 的固定 IP 地址 |
| 82 | +
|
| 83 | +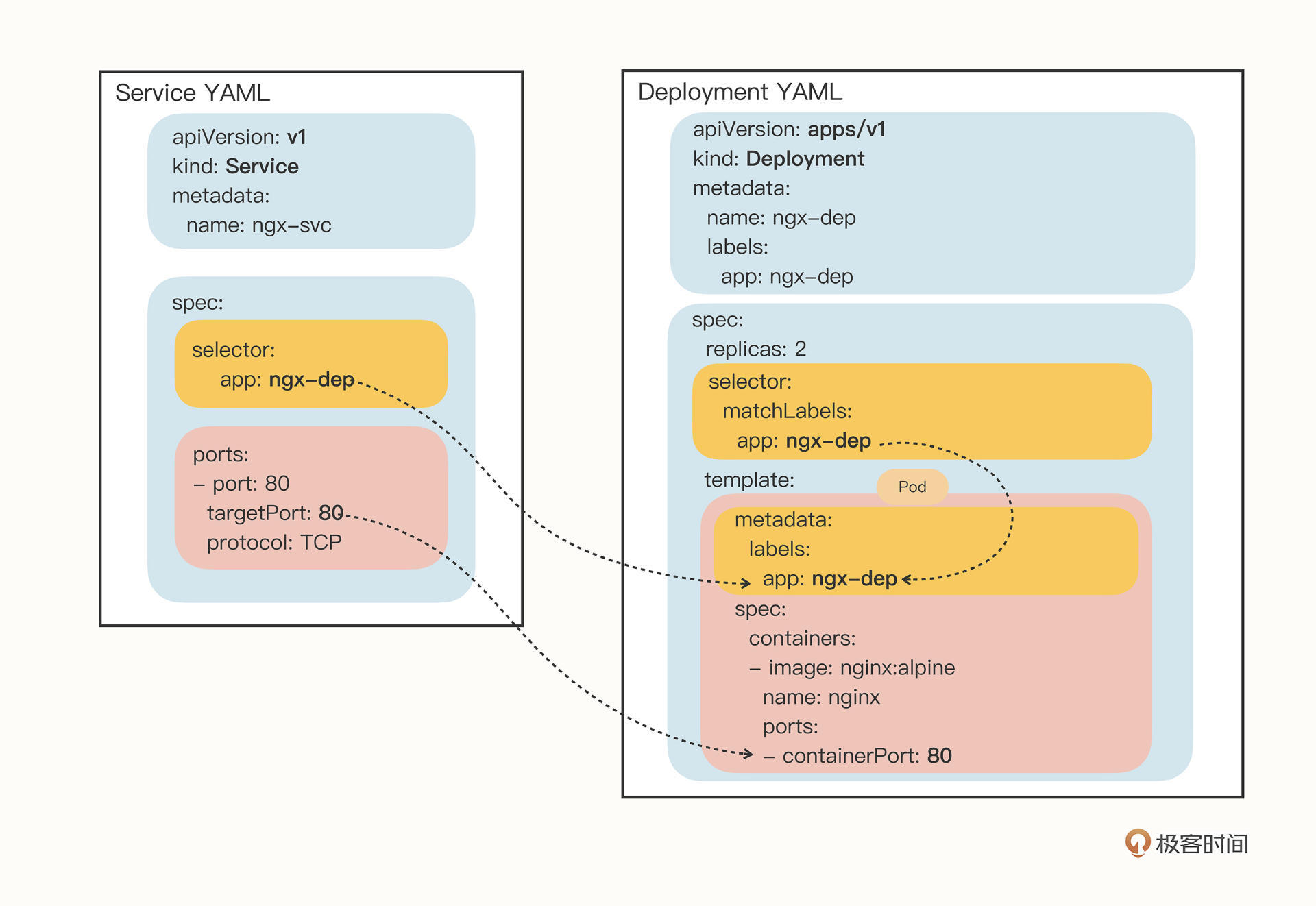 |
| 84 | + |
| 85 | +#### ingress:集群内外边界上的入口 |
| 86 | + |
| 87 | +> Ingress 的路由规则是 HTTP 协议,所以就不能用 IP 地址的方式访问,必须要用域名、URI |
| 88 | +
|
| 89 | +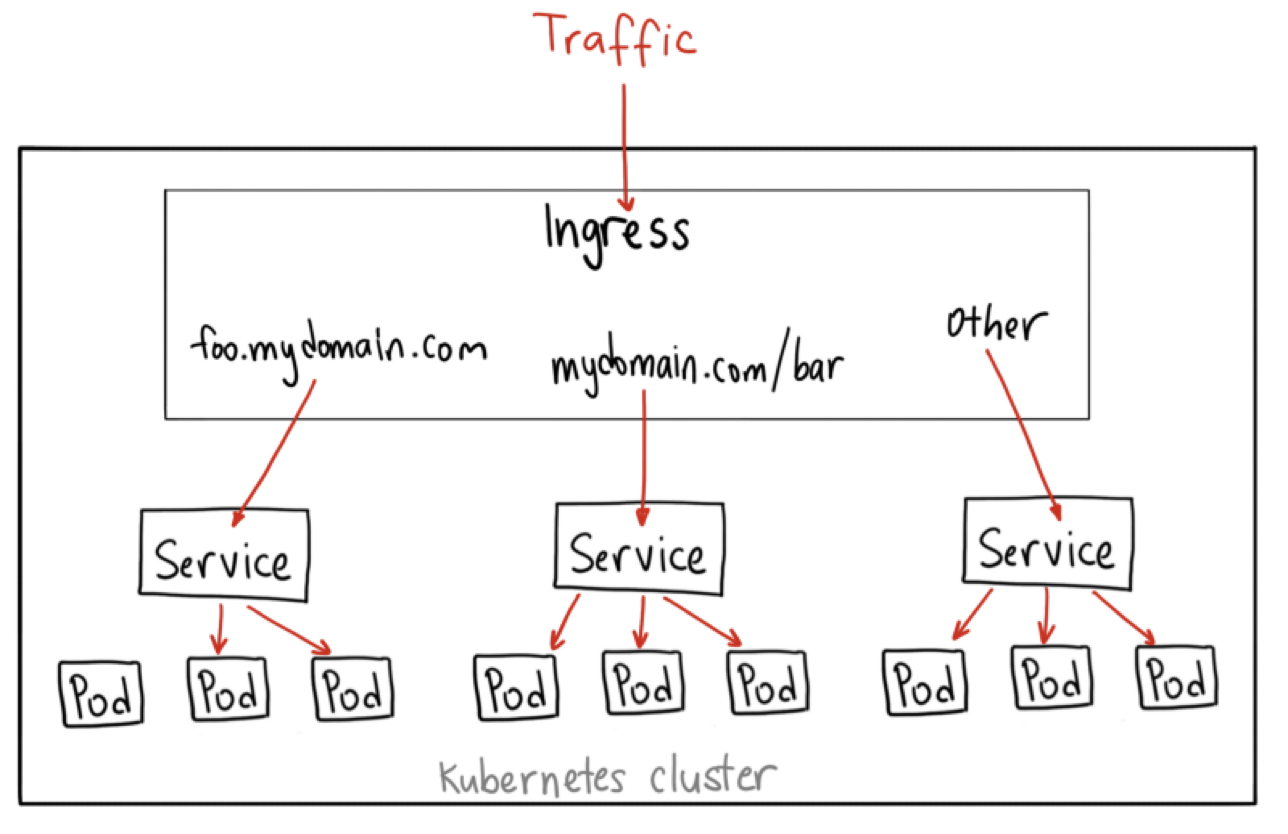 |
| 90 | + |
| 91 | +#### 四者联系 |
| 92 | + |
| 93 | +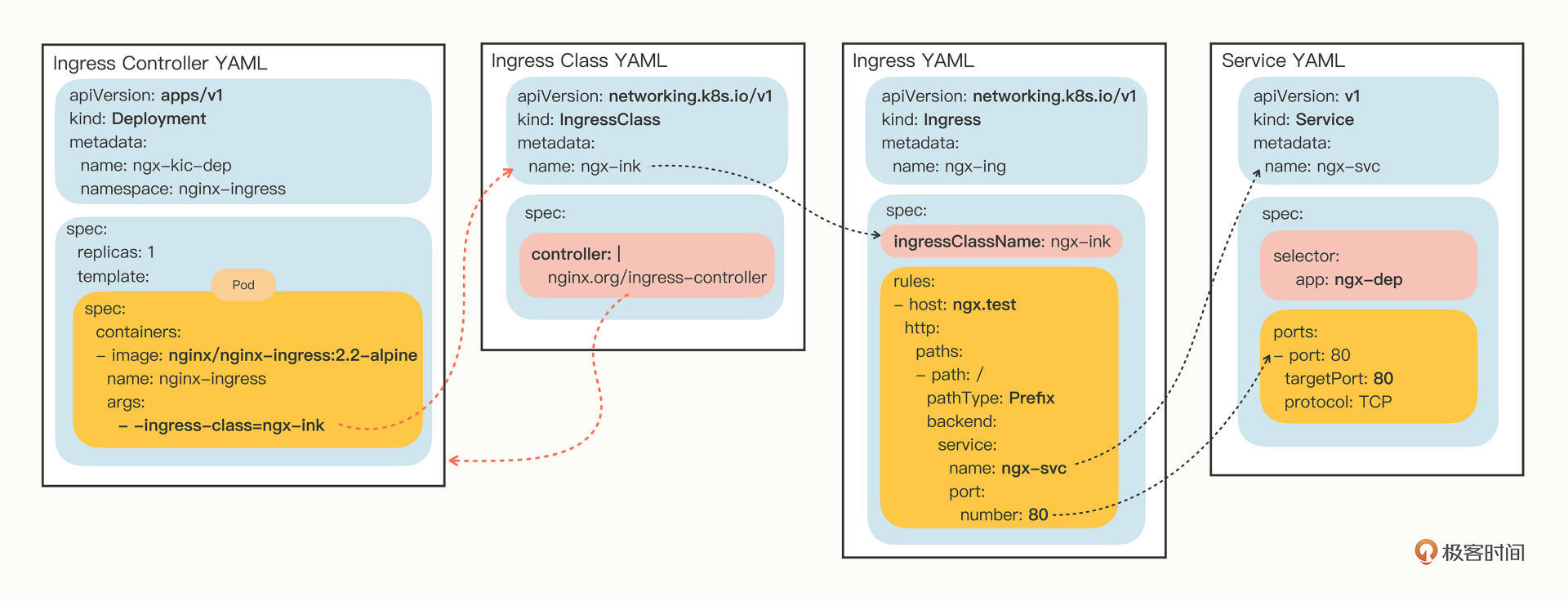 |
| 94 | + |
| 95 | + |
| 96 | + |
| 97 | +## 几种更新策略 |
| 98 | + |
| 99 | +> 普通部署 全部停掉 然后全部启动新的 |
| 100 | +> |
| 101 | +> 用时最短 |
| 102 | +
|
| 103 | +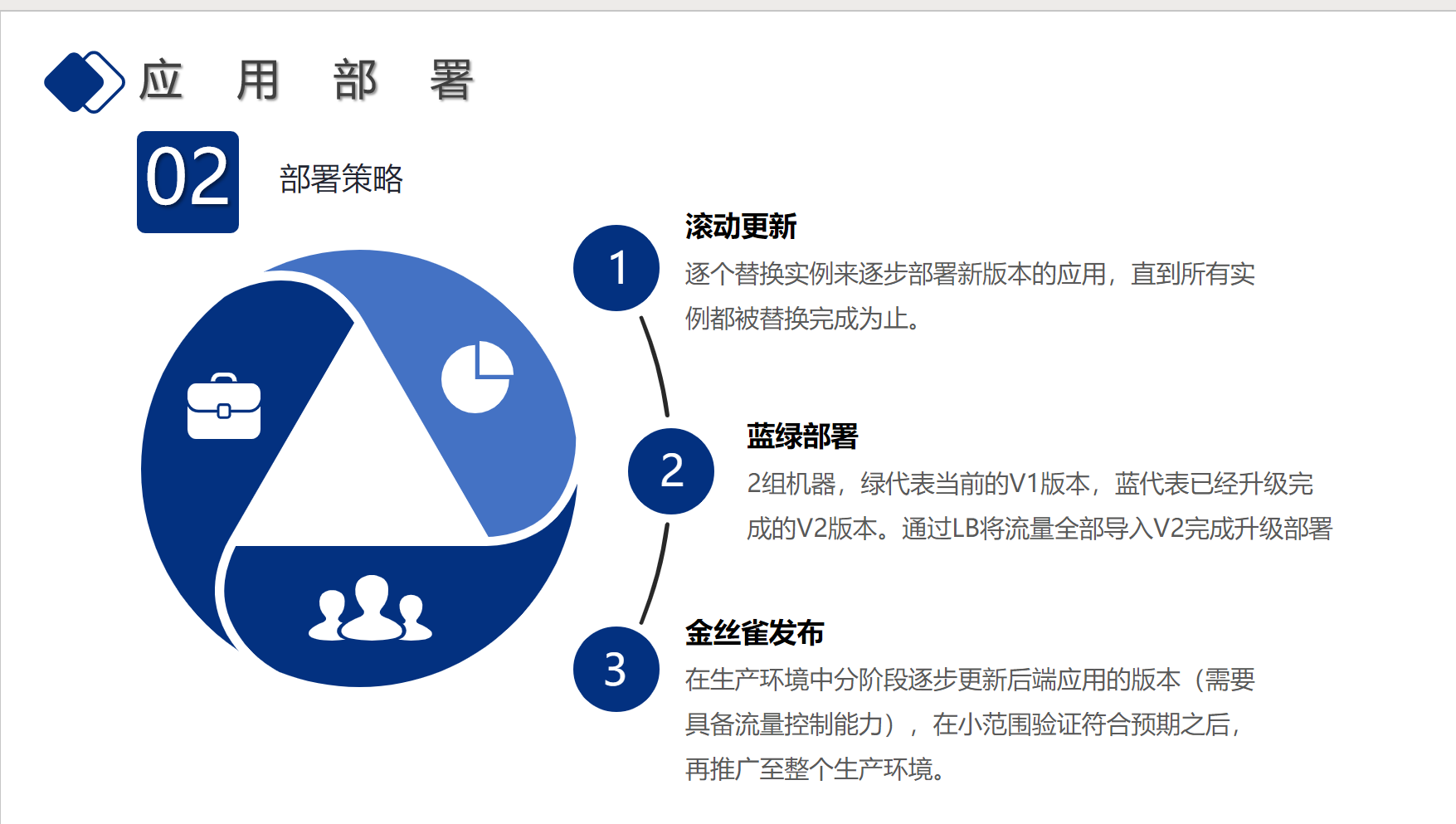 |
| 104 | + |
| 105 | +### 滚动更新 |
| 106 | + |
| 107 | + |
| 108 | + |
| 109 | +### 蓝绿部署 |
| 110 | + |
| 111 | + |
| 112 | + |
| 113 | +金丝雀发布 |
| 114 | + |
| 115 | + |
| 116 | + |
| 117 | +## 应用更健康 |
| 118 | + |
| 119 | +> 创建容器有三大隔离技术:namespace、cgroup、chroot。其中的 namespace 实现了独立的进程空间,chroot 实现了独立的文件系统,cgroup 的作用是管控 CPU、内存,保证容器不会无节制地占用基础资源,进而影响到系统里的其他应用 |
| 120 | +
|
| 121 | +### cgroup |
| 122 | + |
| 123 | +CPU、内存与存储卷,在 Pod 容器的描述部分添加一个新字段 resources 进行申请,它就相当于申请资源的 Claim |
| 124 | + |
| 125 | + |
| 126 | + |
| 127 | +> Kubernetes 里 CPU 的最小使用单位是 0.001,为了方便表示用了一个特别的单位 m,也就是“milli”“毫”的意思,比如说 500m 就相当于 0.5 |
| 128 | +
|
| 129 | +### 容器状态探针(Probe) |
| 130 | + |
| 131 | +> 除了保证崩溃重启,还必须要能够探查到 Pod 的内部运行状态,定时给应用做“体检”,让应用时刻保持“健康”,能够满负荷稳定工作 |
| 132 | +
|
| 133 | +* Startup,启动探针,用来检查应用是否已经启动成功,适合那些有大量初始化工作要做,启动很慢的应用。 |
| 134 | + |
| 135 | +* Liveness,存活探针,用来检查应用是否正常运行,是否存在死锁、死循环。 |
| 136 | +* Readiness,就绪探针,用来检查应用是否可以接收流量,是否能够对外提供服务 |
| 137 | + |
| 138 | +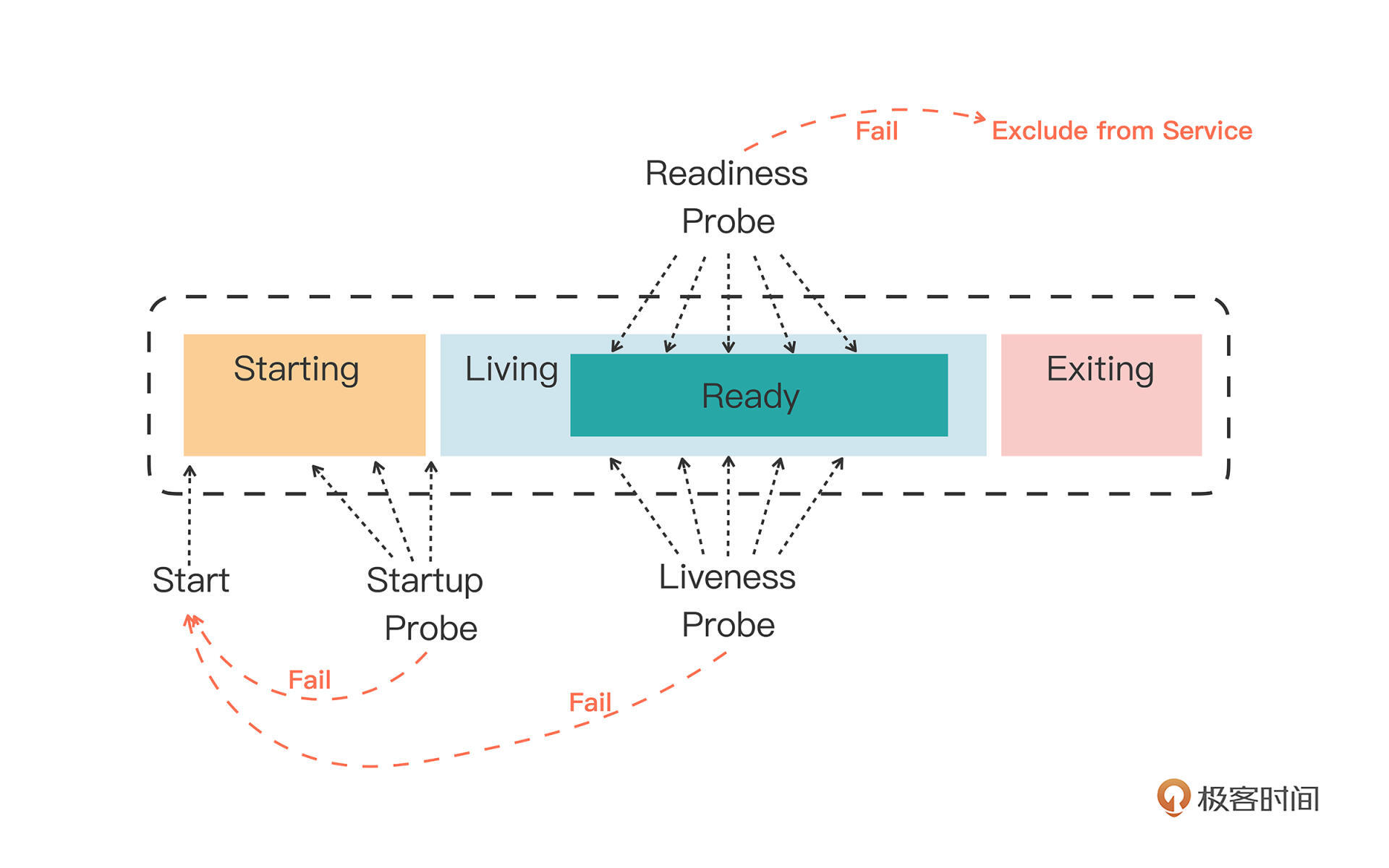 |
| 139 | + |
| 140 | +#### 探测方式 |
| 141 | + |
| 142 | + |
| 143 | + |
| 144 | +> 启用了 80 端口,然后用 location 指令定义了 HTTP 路径 /ready,它作为对外暴露的“检查口”,用来检测就绪状态,返回简单的 200 状态码和一个字符串表示工作正常 |
| 145 | +
|
| 146 | + |
| 147 | + |
| 148 | + |
| 149 | + |
| 150 | +### namespace:通过不同命名空间实现资源隔离 |
| 151 | + |
| 152 | +> 可以像管理容器一样,给名字空间设定配额,把整个集群的计算资源分割成不同的大小,按需分配给团队或项目使用 |
0 commit comments