案例:The physical traits that define men & women in literature (文学作品中定义男性和女性的身体特征) #110
Sara-0707
started this conversation in
Show and tell
Replies: 2 comments
-
|
Looking Back How do I wrap this up? I don’t really know! Maybe with some lessons learned:
https://pudding.cool/process/pitching-gendered-descriptions/ |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
The physical traits that define men & women in literature (文学作品中定义男性和女性的身体特征)
作品链接:https://pudding.cool/2020/07/gendered-descriptions/
第五小组成员:刘雨辰 吕翔新 谭相伶 何雨馨 王竞翊
一、作品简介
1. 作品背景
The Physical Traits that Define Men and Women in Literature是由美国一家专门从事数据叙事的电子刊物The Pudding报送The Sigma Awards(2021)的参赛作品,入选奖项的最终候选名单。该作品源于Erin Davis——一位业余数据可视化爱好者的投稿,她与相识18年的好友、一位专业的插画家Liana Sposto合作完成了这件数据新闻作品。
这件作品挖掘了2000本书的文本,以找到用来描述男性和女性身体部位的形容词。通过繁复的数据收集与处理,文章从数量上证实了女性平日里所察觉到的现象,那就是:女性常常被使用典型的性别歧视方式来描述。
2. 作品内容
这是一件非典型的数据新闻作品。作者首先从自身的生活体验引入:在读书会的阅读书目中,大家发现有一段长达35页、有关迷人的仙女身体特征的描述插在平淡的情节之中。这引起了她对书籍中有关男性、女性身体特征刻板描述的注意。在简单介绍数据来源及处理方式之后,作者设计了一个互动板块,请读者猜测选段所描述对象的性别,意在促使人们反思自己对于男性和女性身体特征描述的区分之中,是否存在固有的思维模式。
在文章主体的第一部分,作者通过动态人体插画呈现了男性和女性身体部位被提及的频率。数据显示,女性角色被提到头发的可能性是男性角色的两倍,作者认为这与由来已久的重视女性头发的历史和文化传统有关。传统观念认为男性的价值在于力量和权力,数据也证实了这一点:拳头、指关节、胸部和下巴这样的身体部位被提及的频率较高。
在文章主体的第二部分,作者统计了文学作品中描述男性、女性身体特征的形容词,并制作了一个迷你数据库,以坐标系的方式进行比较。作者以“bushy”一词为例,联系《哈利·波特》系列中作者对赫敏头发的描述,认为文学作品中这些有关性别的话语实质也塑造着我们的审美与行动。文末,作者将文学与现实生活中的性别形象进行对比:在现实生活中,女性形象显然比柔软、性感的角色更立体;男性形象比肌肉发达的笨蛋要复杂得多。最后,作者提出倡议,男性、女性的媒介形象应当摆脱刻板印象,变得丰满起来,这也有助于我们进一步认知自我与他人。
二、数据处理
1. 数据来源
这项分析的数据集包括1008年至2020年间出版的2000本书;大多数是1900年以后出版的。其中,大约35%的书至少有一位女性作者。
同时,作者根据文化相关性选择书籍:选择范围包括《纽约时报》畅销书、普利策奖提名和获奖者、布克奖入围书籍和获奖者、美国高中和大学经常教授的书籍以及经常出现在最佳名单上的书籍。
2. 数据处理
每本书都是用spaCy自然语言处理器处理的。作者以此来识别以下模式。
作者使用下面的公式来计算身体部位出现频率的倾斜情况。
作者使用下面的公式来计算身体部位的形容词出现频率的倾斜情况。
3. 技术方法
3.1 PARSER
PARSER模块可以将文本解析为抽象语法树(AST),把Java源码转换成 JavaParser定义的Statement对象。
parse方法能够将FILE_PATH所定义的类文件编译成CompilationUnit(可以理解为AST树的根节点,存有被编译的源代码的一切信息),接下来就可以通过遍历CompilationUnit来获得想要得到的信息。
3.2 CoreNLP
作者在另一篇博文中提到,这篇文章的数据是用CoreNLP处理的。
https://corenlp.run/
CoreNLP是使用Java进行自然语言处理的一站式服务。CoreNLP使用户能够导出文本的语言注释,包括标记和句子边界,词性,命名实体,数字和时间值,依存关系和选区解析,共指,情感,引用属性和关系。
CoreNLP的核心是管道。管道接收原始文本,在文本上运行一系列NLP注释器,并生成最终的注释集。
管道产生CoreDocuments,这些数据对象包含所有注释信息,可通过简单的API进行访问,并可序列化为Google Protocol Buffer。
CoreNLP生成各种语言注释,包括:词性、命名实体、依赖解析、共指。
3.3 spaCy
spaCy号称工业级Python自然语言处理(NLP)软件包,可以对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化等。
使用spaCy时,文本字符串的第一步是将其传递给NLP对象。这个对象本质上是由几个文本预处理操作组成的管道(什么是Pipeline),输入文本字符串必须通过这些操作。当你在一个文本上调用nlp时,spaCy首先通过Tokenizer(分词器)进行分词并生成一个doc对象,然后doc会经过几个不同的步骤进行处理。Pipeline通常包括一个标记器(tagger)、一个词法器(lemmatizer)、一个解析器(parser)和一个实体识别器(entity recognizer)。每个流水线组件都会返回经过处理的doc,然后将其传递给下一个组件,最后形成最终doc。
下图示例为:创建nlp对象。
三、可视化风格
本篇作品抛弃了大部分数据新闻中会出现的多张量化表格,长段文字等叙事说明方法,而将文字、数字与图像三者进行有机结合,其中最为突出的是风格化的卡通图像,这样的搭配能够为读者带来独特的阅读体验。
文章题目处,制作团队即绘制了一张各个人体部件附着在书本上的卡通图案,下方点出作品题目:“The physical traits that define men & women in literature(文学作品中定义男人和女人的身体特征)”。这样的搭配能够使作者省略其他冗余的介绍文字,也能够很好地将自己的文章主要内容传递给读者。这样画风个性且色彩丰富的图案能在很大程度上提高读者阅读下去的欲望。
在写作中,创作者将卡通图像也作为文字段之间的间隔,将文章的内容用图像语言描述出来。并且,图案中的文字并非一板一眼的排版,而是将文字部分进行字型变化,以搭配图案进行更好地展示,这样表现方式有效地减少读者的阅读疲劳,图文结合也使读者对文章内容更加理解。
在色彩配搭上,创作者以蓝、紫、绿为主要色调,同时在数据展示部分也使用了较温和的橙、绿作为坐标点。在图像中,蓝、紫、绿色体现了开头所提及的“This all started with a particularly sexy fairy.”相契合,符合Fairy的神秘气质。而数据部分,则使用较为温和橙、绿作为主色调,使读者将注意力放在数据上而非仅专注于图像。
在阅读后,我们认为在该文章的可视化风格上有以下亮点:
1. 文字可视化
例如在以下这个部分,创作者并非简单地讲述自己如何从书本中提取每个人的身体部件和用以形容这个部件的形容词,而是将其具象化为两个盒子,而自己利用机器从书中加工提取。这与传统的可视化风格不同,创作者没有使用复杂的3D等技术使之变得立体化,而是使用手绘漫画的形式,为整篇文章增添了趣味性。
比起使用文字,创作者更偏好将读者拉入到创作中去。在这里,作者邀请读者进行答题。读者在答题过程中接收到有关不同形容词去描述两性身体部件的信息,下方显示了读者答题的正确率,能够激起读者的好胜心,读者为了提高正确率则需要认真仔细地阅读题目中文字。这样的互动过程提升了参与感,也使读者对文章内容有更深刻的理解。
在文字描述中,创作者也贴心地为重点部分增加了高亮和下划线,强调重要的数据和表达,这样的小细节减少了读者的阅读疲劳。
2. 数据可视化
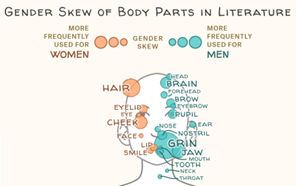
下图表示了“文学作品中身体部位的性别倾斜”,创作者将两性经常被描述的部位表示了平面的人脸上。鼠标悬浮在身体部位上时,则会出现有关该词词频的详细介绍(使用css中的.hover())。

此外,作者该将该数据创造性地转移到坐标轴中。以下图为例,图中的坐标图表示头发这个身体部件在文学作品中是被怎样描述的。更多地被用于形容女性头发的形容词设置在y轴的左边,颜色为橙色;更多地被用于形容男性头发的形容词设置在y轴的右边,颜色为蓝色。每个词的大小表现了是它在书本中的出现率,这个词越大,那么它在作者分析的书中出现的频率就越高。作者将坐标轴与词频表示相结合,以大小来表示词语出现频率,对于读者来说,阅读更加顺畅,也更易理解。
3. 独具一格的风格图案
为了给整篇文章和议论的话题增加趣味性,创作者制作了各种各样的图案组合以夸张地表现书本中对人体部位的描写。以下的图像都是作者根据书中文字进行的漫画创作,可以看出这些带有刻板印象的描述被刻画到现实中会变得及其不自然。创作者以此为读者带来更大的视觉冲击感。
这也使该文章变得难以模仿。即使人们能够拿到相同的数据,进行相同的分析过程。但将这些内容和作者的观点表现出来的方法就各有不同。独特的图像和表现方式使该文章更加引人注目,为文章本身打上独特的烙印,形成类似于打造品牌的IP效应,提高作品的传播度。
四、作品意义及影响
1.用数据说话,证实经验所捕捉的社会性问题。
通过对1008至2020年间2000本具有文化相关度及代表性的书籍进行文本提取及数据分析,作者从数量上证实了女性平日里所察觉到的现象——女性常常被使用典型的性别歧视方式来描述,论证具备较强的说服力。
2.用数据说话,为性别形象的媒介建构提供建议与参考。
通过充分的数据呈现与生活感较强的叙事,这件作品使读者意识到文学作品中的性别刻板印象对人们性别认知与自我定位所造成的影响。作者提出倡议,男性、女性的媒介形象应当摆脱刻板印象,要多角度、更丰满地刻画人物,这也有助于我们进一步认知自我与他人。
五、值得借鉴之处
1. 独特的手绘风格打造媒体品牌
不同于传统的数据新闻作品,该创作团队用别具一格的手绘风格给读者带来新奇的体验,亮丽活泼宛如插画的手绘风格具有很高的辨识度,在文章叙事中随处可见的手写风格的强调下划线和高亮也很完美的适配整体的风格。当今的数据新闻作品,已经不局限于内容的亮点,打造一个媒体的品牌,强化媒体的品牌文化,激发读者的阅读兴趣也是十分重要但时常被忽视的一点。在严肃新闻赛道竞争已经白热化的阶段,小体量的团体也可以尝试错位竞争,在轻量化的题材上发挥自己的优势。
2. 形成自己独特的细节亮点
在之前的数据新闻作品分享中,滚动叙事,放大地图,三维建模等技术的运用十分普遍,但大量的使用同样的技术难免会造成千篇一律的观感。这个时候,如何更好的让技术服务于新闻的叙事就成为了打造细节亮点的关键。首先,本篇作品手绘随着叙事的展开而缓缓延伸,用了一个类似于印刷机器的插画调动了读者向下阅读的兴趣,也起到了承前启后的作用。随后的给出隐去性别的身体部位描写的猜测小游戏也让读者意识到性别刻板印象的顽固。随后呈现的一个人体的模型详细的展示了各个身体部位在男女性身体描写中出现的比例,配上左边的滚动叙事,还有后面出现的词云图,这些都是常用于数据新闻的技术,但是配上独特的手绘风格都呈现出了1+1>2的效果。
3. 软新闻用硬技术
本篇新闻在分类上可以认为属于文化新闻,无论在叙事还是可视化风格上都显得“不那么硬核”。并且在叙事中融入了大量的私人视角。抛去对于本篇作品的题材的评价,这篇作品给人带来的启发是,软新闻也可以用硬技术制作。无需担心这样的处理是否会让原本很“软”的新闻看起来很严肃,事实上,恰当的平衡能更好的提升读者的阅读体验。
六、可以改进之处
1. 风格对于题材的限制
手绘的插画一般的风格无疑是本篇的亮点所在,但是与之而来的是这样的风格很难在题材上有所突破,基本只能局限于文化新闻这种偏软的新闻体裁上,无法在更多更加宏大的叙事中呈现。
2. 新闻性不强,私人化叙事痕迹过重
开头作者即用一个自己看书时的经历来引入,在后文中又用了自己的浓密的头发的例子来证明对于不同性别的身体的刻板印象的存在。在一个新闻作品呈现如此多的私人叙述,在情感上的确能够更加容易的调动读者,让读者产生共鸣,但是是否有这样的必要去呈现这么多的私人叙事,这样的设置是否会削弱作品的新闻性,这些都是值得注意的。并且,私人化的叙事也仅仅停留在了感受的表面,并没有对于问题本身顺势更进一步的挖掘与探讨。让这篇报道成为浮光掠影式的读物,读者可能对这篇文章留下了印象,但因此带来的思考也遗憾的止步于此。
3. 缺乏历史的纬度和国家的经度
虽然本篇选取了两千多本书籍的文本进行分析,但在数据分析上仍旧很泛化并且扁平,如果作者能按照国家和出版的时间分类再进行分析,给出不同国家不同文化以及不同时间段中对于两性身体部位的描写,那我们对这个问题的认识将会更进一步,视野将会随着时空的呈现更加广阔,对于问题的探讨也能随之更加深入。
总而言之,这是一篇出发点和风格都十分鲜明的数据新闻作品,但其缺陷也十分明显,新闻性不足,对于一个好的选题也没有完全挖掘清楚。但是,它在数据处理、可视化制作方面仍给我们带来了许多启发。
Beta Was this translation helpful? Give feedback.
All reactions