diff --git a/product_demos/streaming-sessionization/01-Delta-session-BRONZE (Confluent).py b/product_demos/streaming-sessionization/01-Delta-session-BRONZE (Confluent).py
new file mode 100644
index 00000000..bbf4ae33
--- /dev/null
+++ b/product_demos/streaming-sessionization/01-Delta-session-BRONZE (Confluent).py
@@ -0,0 +1,205 @@
+# Databricks notebook source
+dbutils.widgets.dropdown("reset_all_data", "false", ["true", "false"], "Reset all data")
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Streaming on Databricks with Spark and Delta Lake
+# MAGIC
+# MAGIC Streaming on Databricks is greatly simplified using Delta Live Table (DLT).
+# MAGIC DLT lets you write your entire data pipeline, supporting streaming transformation using SQL or python and removing all the technical challenges.
+# MAGIC
+# MAGIC We strongly recommend implementing your pipelines using DLT as this will allow for much robust pipelines, enforcing data quality and greatly accelerating project delivery.
+# MAGIC *For a DLT example, please install `dbdemos.install('dlt-loans')` or the C360 Lakehouse demo: `dbdemos.install('lakehouse-retail-churn')`*
+# MAGIC
+# MAGIC Spark Streaming API offers lower-level primitive offering more advanced control, such as `foreachBatch` and custom streaming operation with `applyInPandasWithState`.
+# MAGIC
+# MAGIC Some advanced use-case can be implemented using these APIs, and this is what we'll focus on.
+# MAGIC
+# MAGIC ## Building a sessionization stream with Delta Lake and Spark Streaming
+# MAGIC
+# MAGIC ### What's sessionization?
+# MAGIC
+# MAGIC
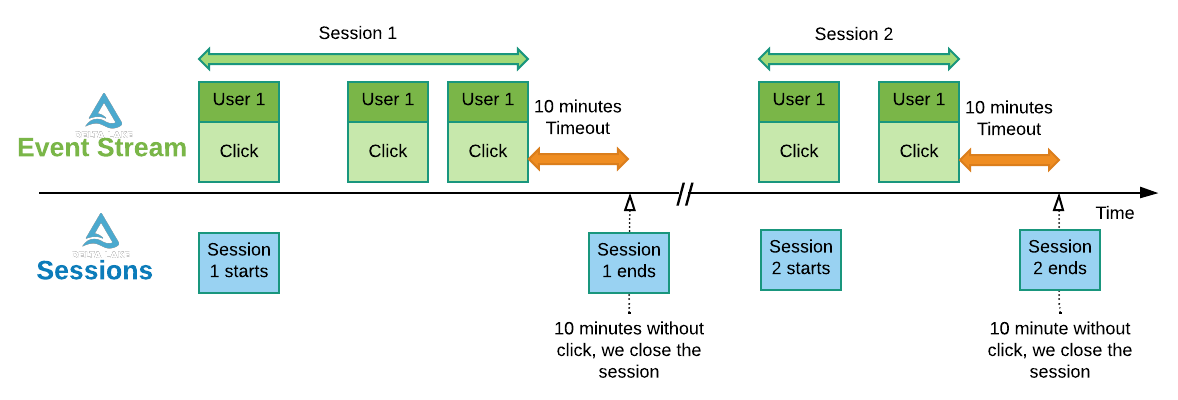
+# MAGIC Sessionization is the process of finding time-bounded user session from a flow of event, grouping all events happening around the same time (ex: number of clicks, pages most view etc)
+# MAGIC
+# MAGIC When there is a temporal gap greater than X minute, we decide to split the session in 2 distinct sessions
+# MAGIC
+# MAGIC ### Why is that important?
+# MAGIC
+# MAGIC Understanding sessions is critical for a lot of use cases:
+# MAGIC
+# MAGIC - Detect cart abandonment in your online shot, and automatically trigger marketing actions as follow-up to increase your sales
+# MAGIC - Build better attribution model for your affiliation, based on the user actions during each session
+# MAGIC - Understand user journey in your website, and provide better experience to increase your user retention
+# MAGIC - ...
+# MAGIC
+# MAGIC
+# MAGIC ### Sessionization with Spark & Delta
+# MAGIC
+# MAGIC Sessionization can be done in many ways. SQL windowing is often used but quickly become too restricted for complex use-case.
+# MAGIC
+# MAGIC Instead, we'll be using the following Delta Architecture:
+# MAGIC
+# MAGIC  +# MAGIC
+# MAGIC Being able to process and aggregate your sessions in a Batch and Streaming fashion can be a real challenge, especially when updates are required in your historical data!
+# MAGIC
+# MAGIC Thankfully, Delta and Spark can simplify our job, using Spark Streaming function with a custom stateful operation (`flatMapGroupsWithState` operator), in a streaming and batch fashion.
+# MAGIC
+# MAGIC Let's build our Session job to detect cart abandonment !
+# MAGIC
+# MAGIC
+# MAGIC *Note: again, this is an advanced demo - if you're starting with Databricks and are looking for a simple streaming pipeline we recommand going with DLT instead.*
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC Being able to process and aggregate your sessions in a Batch and Streaming fashion can be a real challenge, especially when updates are required in your historical data!
+# MAGIC
+# MAGIC Thankfully, Delta and Spark can simplify our job, using Spark Streaming function with a custom stateful operation (`flatMapGroupsWithState` operator), in a streaming and batch fashion.
+# MAGIC
+# MAGIC Let's build our Session job to detect cart abandonment !
+# MAGIC
+# MAGIC
+# MAGIC *Note: again, this is an advanced demo - if you're starting with Databricks and are looking for a simple streaming pipeline we recommand going with DLT instead.*
+# MAGIC
+# MAGIC
+# MAGIC  +
+# COMMAND ----------
+
+# MAGIC %md ## First, make sure events are published to your kafka queue
+# MAGIC
+# MAGIC Start the [_00-Delta-session-PRODUCER]($./_00-Delta-session-PRODUCER) notebook to send messages to your kafka queue.
+
+# COMMAND ----------
+
+# MAGIC %run ./_resources/00-setup $reset_all_data=$reset_all_data
+
+# COMMAND ----------
+
+# from pyspark.sql import SparkSession
+
+# spark = SparkSession.builder \
+# .appName("MyApp") \
+# .config("spark.jars.packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.4") \
+# .config("spark.jars.packages", "org.apache.kafka:kafka-clients:2.8.0") \
+# .config("spark.jars.packages", "io.confluent:kafka-avro-serializer:6.2.0") \
+# .config("spark.jars.packages", "io.confluent:kafka-schema-registry-client:6.2.0") \
+# .getOrCreate()
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ##  1/ Bronze table: store the stream as Delta Lake table
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %md ## First, make sure events are published to your kafka queue
+# MAGIC
+# MAGIC Start the [_00-Delta-session-PRODUCER]($./_00-Delta-session-PRODUCER) notebook to send messages to your kafka queue.
+
+# COMMAND ----------
+
+# MAGIC %run ./_resources/00-setup $reset_all_data=$reset_all_data
+
+# COMMAND ----------
+
+# from pyspark.sql import SparkSession
+
+# spark = SparkSession.builder \
+# .appName("MyApp") \
+# .config("spark.jars.packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.4") \
+# .config("spark.jars.packages", "org.apache.kafka:kafka-clients:2.8.0") \
+# .config("spark.jars.packages", "io.confluent:kafka-avro-serializer:6.2.0") \
+# .config("spark.jars.packages", "io.confluent:kafka-schema-registry-client:6.2.0") \
+# .getOrCreate()
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ##  1/ Bronze table: store the stream as Delta Lake table
+# MAGIC
+# MAGIC  +# MAGIC
+# MAGIC The first step is to consume data from our streaming engine (Kafka, Kinesis, Pulsar etc.) and save it in our Data Lake.
+# MAGIC
+# MAGIC We won't be doing any transformation, the goal is to be able to re-process all the data and change/improve the downstream logic when needed
+# MAGIC
+# MAGIC #### Solving small files and compaction issues
+# MAGIC
+# MAGIC Everytime we capture kafka events, they'll be stored in our table and this will create new files. After several days, we'll endup with millions of small files leading to performance issues.
+# MAGIC
+# MAGIC The first step is to consume data from our streaming engine (Kafka, Kinesis, Pulsar etc.) and save it in our Data Lake.
+# MAGIC
+# MAGIC We won't be doing any transformation, the goal is to be able to re-process all the data and change/improve the downstream logic when needed
+# MAGIC
+# MAGIC #### Solving small files and compaction issues
+# MAGIC
+# MAGIC Everytime we capture kafka events, they'll be stored in our table and this will create new files. After several days, we'll endup with millions of small files leading to performance issues.
+# MAGIC Databricks solves that with autoOptimize & autoCompact, 2 properties to set at the table level.
+# MAGIC
+# MAGIC *Note that if the table isn't created with all the columns. The engine will automatically add the new column from kafka at write time, merging the schema gracefuly*
+
+# COMMAND ----------
+
+# DBTITLE 1,Create the table events_raw
+# MAGIC %sql
+# MAGIC CREATE TABLE IF NOT EXISTS events_raw (key string, value string) TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true, delta.autoOptimize.autoCompact = true);
+
+# COMMAND ----------
+
+kafka_bootstrap_servers_tls = "pkc-rgm37.us-west-2.aws.confluent.cloud:9092"
+
+sasl_username = "XXXXXXXXXXXXXXXX"
+sasl_password = "****************************************************************"
+
+# COMMAND ----------
+
+# MAGIC %fs ls /Users/hari.prasad@celebaltech.com/demos/retail/sessions/checkpoints/
+
+# COMMAND ----------
+
+from pyspark.sql.functions import col
+
+stream = (spark
+ .readStream
+ #=== Configurations for Kafka streams ===
+ .format("kafka")
+ .option("kafka.bootstrap.servers", kafka_bootstrap_servers_tls)
+ .option("kafka.security.protocol", "SASL_SSL")
+ .option("kafka.sasl.mechanism", "PLAIN")
+ .option("kafka.sasl.jaas.config", f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";')
+ .option("subscribe", "dbdemos-sessions1") #kafka topic
+ .option("startingOffsets", "latest") #Consume messages from the end
+ .option("maxOffsetsPerTrigger", "10000") # Control ingestion rate - backpressure
+ .option("ignoreChanges", "true")
+ .load()
+ .withColumn('key', col('key').cast('string'))
+ .withColumn('value', col('value').cast('string'))
+ .writeStream
+ # === Write to the delta table ===
+ .format("delta")
+ .trigger(processingTime="20 seconds")
+ .option("checkpointLocation", cloud_storage_path+"/checkpoints/bronze")
+ .option("mergeSchema", "true")
+ .outputMode("append")
+ .table("retail_hari_prasad.events_raw")
+)
+
+# Wait for the streaming query to start and process some data
+# stream.awaitTermination(timeout=60)
+
+wait_for_table("hive_metastore.retail_hari_prasad.events_raw")
+
+# COMMAND ----------
+
+# DBTITLE 1,Our table events_raw is ready and will contain all events
+# MAGIC %sql
+# MAGIC SELECT * FROM hive_metastore.retail_hari_prasad.events_raw;
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Our Raw events are now ready to be analyzed
+# MAGIC
+# MAGIC It's now easy to run queries in our events_raw table. Our data is saved as JSON, databricks makes it easy to query:
+
+# COMMAND ----------
+
+# DBTITLE 1,Action per platform
+# MAGIC %sql
+# MAGIC select count(*), value:platform as platform from events_raw group by platform;
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Searching for duplicate events
+# MAGIC
+# MAGIC As you can see, our producer sends incorrect messages.
+# MAGIC
+# MAGIC Not only we have null event_id from time to time, but we also have duplicate events (identical events being send twice with the same ID and exact same content)
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC select count(*) event_count, value :event_id event_id, first(value) from events_raw
+# MAGIC group by event_id
+# MAGIC having event_count > 1
+# MAGIC order by event_id;
+
+# COMMAND ----------
+
+# DBTITLE 1,Stop all the streams
+stop_all_streams(sleep_time=120)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Next steps: Cleanup data and remove duplicates
+# MAGIC
+# MAGIC It looks like we have duplicate event in our dataset. Let's see how we can perform some cleanup.
+# MAGIC
+# MAGIC In addition, reading from JSON isn't super efficient, and what if our json changes over time ?
+# MAGIC
+# MAGIC While we can explore the dataset using spark json manipulation, this isn't ideal. For example is the json in our message changes after a few month, our request will fail.
+# MAGIC
+# MAGIC Futhermore, performances won't be great at scale: because all our data is stored as a unique, we can't leverage data skipping and a columnar format
+# MAGIC
+# MAGIC That's why we need another table: **[A Silver Table!]($./02-Delta-session-SILVER)**
\ No newline at end of file
diff --git a/product_demos/streaming-sessionization/_00-Delta-session-PRODUCER (Confluent).py b/product_demos/streaming-sessionization/_00-Delta-session-PRODUCER (Confluent).py
new file mode 100644
index 00000000..d47c7919
--- /dev/null
+++ b/product_demos/streaming-sessionization/_00-Delta-session-PRODUCER (Confluent).py
@@ -0,0 +1,159 @@
+# Databricks notebook source
+dbutils.widgets.text("produce_time_sec", "600", "How long we'll produce data (sec)")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC #Kafka producer
+# MAGIC
+# MAGIC Use this producer to create a stream of fake user in your website and sends the message to kafka, live.
+# MAGIC
+# MAGIC Run all the cells, once. Currently requires to run on a cluster with instance profile allowing kafka connection (one-env, aws).
+# MAGIC
+# MAGIC
+# MAGIC  +
+# COMMAND ----------
+
+# MAGIC %pip install faker kafka-python
+
+# COMMAND ----------
+
+dbutils.library.restartPython()
+
+# COMMAND ----------
+
+import json
+import logging
+import socket
+from kafka import KafkaProducer
+
+# COMMAND ----------
+
+# Enable logging to get more information about the connection process
+logging.basicConfig(level=logging.DEBUG)
+
+# COMMAND ----------
+
+# Check network connectivity to the Kafka broker
+def check_kafka_connectivity(host, port):
+ try:
+ socket.create_connection((host, port), timeout=10)
+ logging.info(f"Successfully connected to Kafka broker at {host}:{port}")
+ except Exception as e:
+ logging.error(f"Failed to connect to Kafka broker at {host}:{port}: {e}")
+
+# COMMAND ----------
+
+bootstrap_server = "pkc-rgm37.us-west-2.aws.confluent.cloud:9092"
+sasl_username = "XXXXXXXXXXXXXXXX"
+sasl_password = "****************************************************************"
+
+# COMMAND ----------
+
+# Extract host and port from the bootstrap_servers
+host, port = bootstrap_server.split(":")
+check_kafka_connectivity(host, int(port))
+
+# COMMAND ----------
+
+config = {
+ "bootstrap_servers": [bootstrap_server],
+ "security_protocol": "SASL_SSL",
+ "sasl_mechanism": "PLAIN",
+ "sasl_plain_username": sasl_username,
+ "sasl_plain_password": sasl_password,
+ # Serializers
+ "value_serializer": lambda v: json.dumps(v).encode("utf-8"),
+ # "key_serializer": lambda k: k.encode("utf-8"),
+ # Additional configurations for reliability
+ "request_timeout_ms": 45000,
+ "retry_backoff_ms": 500,
+ "max_block_ms": 120000, # Increase timeout to 2 minutes
+ "connections_max_idle_ms": 300000,
+ "api_version_auto_timeout_ms": 60000,
+}
+
+# Configuration for the Kafka producer
+try:
+ producer = KafkaProducer(**config)
+ logging.info("Kafka producer created successfully")
+except Exception as e:
+ logging.error(f"Failed to create Kafka producer: {e}")
+
+# COMMAND ----------
+
+import re
+from faker import Faker
+from collections import OrderedDict
+from random import randrange
+import time
+import uuid
+fake = Faker()
+import random
+import json
+
+platform = OrderedDict([("ios", 0.5),("android", 0.1),("other", 0.3),(None, 0.01)])
+action_type = OrderedDict([("view", 0.5),("log", 0.1),("click", 0.3),(None, 0.01)])
+
+def create_event(user_id, timestamp):
+ fake_platform = fake.random_elements(elements=platform, length=1)[0]
+ fake_action = fake.random_elements(elements=action_type, length=1)[0]
+ fake_uri = re.sub(r'https?:\/\/.*?\/', "https://databricks.com/", fake.uri())
+ #adds some noise in the timestamp to simulate out-of order events
+ timestamp = timestamp + randrange(10)-5
+ #event id with 2% of null event to have some errors/cleanup
+ fake_id = str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None
+ return {"user_id": user_id, "platform": fake_platform, "event_id": fake_id, "event_date": timestamp, "action": fake_action, "uri": fake_uri}
+
+print(create_event(str(uuid.uuid4()), int(time.time())))
+
+# COMMAND ----------
+
+def sendMessage(event):
+ event = json.dumps(event)
+ producer.send('dbdemos-sessions1', value=event)
+ #print(event)
+ #Simulate duplicate events to drop the duplication
+ if random.uniform(0, 1) > 0.96:
+ producer.send('dbdemos-sessions1', value=event)
+
+users = {}
+#How long it'll produce messages
+produce_time_sec = int(dbutils.widgets.get("produce_time_sec"))
+#How many new users join the website per second
+user_creation_rate = 2
+#Max duration a user stays in the website (after this time user will stop producing events)
+user_max_duration_time = 120
+
+for _ in range(produce_time_sec):
+ #print(len(users))
+ for id in list(users.keys()):
+ user = users[id]
+ now = int(time.time())
+ if (user['end_date'] < now):
+ del users[id]
+ #print(f"User {id} removed")
+ else:
+ #10% chance to click on something
+ if (randrange(100) > 80):
+ event = create_event(id, now)
+ sendMessage(event)
+ #print(f"User {id} sent event {event}")
+
+ #Re-create new users
+ for i in range(user_creation_rate):
+ #Add new user
+ user_id = str(uuid.uuid4())
+ now = int(time.time())
+ #end_date is when the user will leave and the session stops (so max user_max_duration_time sec and then leaves the website)
+ user = {"id": user_id, "creation_date": now, "end_date": now + randrange(user_max_duration_time) }
+ users[user_id] = user
+ #print(f"User {user_id} created")
+ time.sleep(1)
+
+print("closed")
+
+
+# COMMAND ----------
+
+
+# COMMAND ----------
+
+# MAGIC %pip install faker kafka-python
+
+# COMMAND ----------
+
+dbutils.library.restartPython()
+
+# COMMAND ----------
+
+import json
+import logging
+import socket
+from kafka import KafkaProducer
+
+# COMMAND ----------
+
+# Enable logging to get more information about the connection process
+logging.basicConfig(level=logging.DEBUG)
+
+# COMMAND ----------
+
+# Check network connectivity to the Kafka broker
+def check_kafka_connectivity(host, port):
+ try:
+ socket.create_connection((host, port), timeout=10)
+ logging.info(f"Successfully connected to Kafka broker at {host}:{port}")
+ except Exception as e:
+ logging.error(f"Failed to connect to Kafka broker at {host}:{port}: {e}")
+
+# COMMAND ----------
+
+bootstrap_server = "pkc-rgm37.us-west-2.aws.confluent.cloud:9092"
+sasl_username = "XXXXXXXXXXXXXXXX"
+sasl_password = "****************************************************************"
+
+# COMMAND ----------
+
+# Extract host and port from the bootstrap_servers
+host, port = bootstrap_server.split(":")
+check_kafka_connectivity(host, int(port))
+
+# COMMAND ----------
+
+config = {
+ "bootstrap_servers": [bootstrap_server],
+ "security_protocol": "SASL_SSL",
+ "sasl_mechanism": "PLAIN",
+ "sasl_plain_username": sasl_username,
+ "sasl_plain_password": sasl_password,
+ # Serializers
+ "value_serializer": lambda v: json.dumps(v).encode("utf-8"),
+ # "key_serializer": lambda k: k.encode("utf-8"),
+ # Additional configurations for reliability
+ "request_timeout_ms": 45000,
+ "retry_backoff_ms": 500,
+ "max_block_ms": 120000, # Increase timeout to 2 minutes
+ "connections_max_idle_ms": 300000,
+ "api_version_auto_timeout_ms": 60000,
+}
+
+# Configuration for the Kafka producer
+try:
+ producer = KafkaProducer(**config)
+ logging.info("Kafka producer created successfully")
+except Exception as e:
+ logging.error(f"Failed to create Kafka producer: {e}")
+
+# COMMAND ----------
+
+import re
+from faker import Faker
+from collections import OrderedDict
+from random import randrange
+import time
+import uuid
+fake = Faker()
+import random
+import json
+
+platform = OrderedDict([("ios", 0.5),("android", 0.1),("other", 0.3),(None, 0.01)])
+action_type = OrderedDict([("view", 0.5),("log", 0.1),("click", 0.3),(None, 0.01)])
+
+def create_event(user_id, timestamp):
+ fake_platform = fake.random_elements(elements=platform, length=1)[0]
+ fake_action = fake.random_elements(elements=action_type, length=1)[0]
+ fake_uri = re.sub(r'https?:\/\/.*?\/', "https://databricks.com/", fake.uri())
+ #adds some noise in the timestamp to simulate out-of order events
+ timestamp = timestamp + randrange(10)-5
+ #event id with 2% of null event to have some errors/cleanup
+ fake_id = str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None
+ return {"user_id": user_id, "platform": fake_platform, "event_id": fake_id, "event_date": timestamp, "action": fake_action, "uri": fake_uri}
+
+print(create_event(str(uuid.uuid4()), int(time.time())))
+
+# COMMAND ----------
+
+def sendMessage(event):
+ event = json.dumps(event)
+ producer.send('dbdemos-sessions1', value=event)
+ #print(event)
+ #Simulate duplicate events to drop the duplication
+ if random.uniform(0, 1) > 0.96:
+ producer.send('dbdemos-sessions1', value=event)
+
+users = {}
+#How long it'll produce messages
+produce_time_sec = int(dbutils.widgets.get("produce_time_sec"))
+#How many new users join the website per second
+user_creation_rate = 2
+#Max duration a user stays in the website (after this time user will stop producing events)
+user_max_duration_time = 120
+
+for _ in range(produce_time_sec):
+ #print(len(users))
+ for id in list(users.keys()):
+ user = users[id]
+ now = int(time.time())
+ if (user['end_date'] < now):
+ del users[id]
+ #print(f"User {id} removed")
+ else:
+ #10% chance to click on something
+ if (randrange(100) > 80):
+ event = create_event(id, now)
+ sendMessage(event)
+ #print(f"User {id} sent event {event}")
+
+ #Re-create new users
+ for i in range(user_creation_rate):
+ #Add new user
+ user_id = str(uuid.uuid4())
+ now = int(time.time())
+ #end_date is when the user will leave and the session stops (so max user_max_duration_time sec and then leaves the website)
+ user = {"id": user_id, "creation_date": now, "end_date": now + randrange(user_max_duration_time) }
+ users[user_id] = user
+ #print(f"User {user_id} created")
+ time.sleep(1)
+
+print("closed")
+
+
+# COMMAND ----------
+