diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/00-get-started-with-SQL.ipynb b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/00-get-started-with-SQL.ipynb
new file mode 100644
index 00000000..d045340b
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/00-get-started-with-SQL.ipynb
@@ -0,0 +1,211 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "a555ed11-89b5-4e6f-ac55-9c19e0a6cbe7",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "# Databricks SQL\n",
+ "
\n",
+ "\n",
+ "\n",
+ "

\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "368abc59-295a-46ff-a327-49b356f0fc47",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "# Migrate a Healthcare Data Warehouse and Build a Star Schema with Databricks\n",
+ "\n",
+ "## **🎯 Scenario**\n",
+ "\n",
+ "A hospital is migrating its legacy data warehouse to the **Databricks Lakehouse Platform** to modernize analytics and reduce operational complexity.\n",
+ "\n",
+ "Two personas lead the effort:\n",
+ "\n",
+ "- 🏗️ **Data Architect**:\n",
+ " - Design data models (star or snowflake schema), considering performance and reporting.\n",
+ " - Map source data, defining types and transformations.\n",
+ " - Collaborate with stakeholders to translate business needs (KPIs, reporting) into logical and physical models.\n",
+ " - Establish data governance and quality rules.\n",
+ " - Ensure scalability.\n",
+ "- 🔧 **Data Engineer**:\n",
+ " - Build and maintain data pipelines to ingest, transform, and load data into the data warehouse.\n",
+ " - Design and develop ETL/ELT processes for efficient data flow.\n",
+ " - Monitor and troubleshoot data pipelines for performance and reliability.\n",
+ " - Implement data quality checks and validation processes.\n",
+ " - Manage and optimize data warehouse infrastructure.\n",
+ " - Automate data-related tasks and workflows.\n",
+ " - Collaborate with data architects and analysts to understand data requirements.\n",
+ " - Deploy and manage data pipelines in production environments.\n",
+ "\n",
+ "This demo covers **Step 1**: creating and populating the patient\\_dim dimension table. **Step 2** will involve building the full star schema and powering BI reports."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "6008ccf2-cb0b-43fe-b747-5065cce504c7",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "# End-to-End Data Warehousing Solution\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "

\n",
+ "\n",
+ "
+-- MAGIC
+-- MAGIC NOTE
+-- MAGIC - Ensure that the Catalog and Schema exist.
+-- MAGIC - Ensure that the user running the demo has CREATE TABLE and CREATE VOLUME privileges in the above schema.
+
+-- COMMAND ----------
+
+-- Name of catalog under which to create the demo schema
+DECLARE OR REPLACE VARIABLE catalog_name STRING = 'main';
+
+-- Name of the demo schema under which to create tables, volume
+DECLARE OR REPLACE VARIABLE schema_name STRING = 'dbdemos_sql_etl';
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Configure Predictive Optimization (PO)**
+-- MAGIC
+-- MAGIC Specify (true/false) whether to enable Predictive Optimization (PO) for the DW schema
+
+-- COMMAND ----------
+
+-- Enable PO prodictive optimization at schema level / else inherit from account setting
+-- User needs to have ALTER SCHEMA privilege
+DECLARE OR REPLACE VARIABLE enable_po_for_schema BOOLEAN = false;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Configure Volume**
+-- MAGIC
+-- MAGIC A folder named "patient" will be created in this volume, and used to stage the source data files that comprise the demo.
+-- MAGIC
+-- MAGIC Please note, the code removes any existing folder named "patient" from this volume.
+
+-- COMMAND ----------
+
+-- Name of the UC volume where patient source data will be staged
+-- Created in the demo schema
+DECLARE OR REPLACE VARIABLE volume_name STRING = 'staging';
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Additional global variables**
+
+-- COMMAND ----------
+
+-- Path of the UC volume where patient source data will be staged
+DECLARE OR REPLACE VARIABLE staging_path STRING
+ = '/Volumes/' || catalog_name || "/" || schema_name || "/" || volume_name;
+
+-- COMMAND ----------
+
+SELECT staging_path;
+
+-- COMMAND ----------
+
+-- Two-level schema name
+DECLARE OR REPLACE VARIABLE full_schema_name STRING
+ = catalog_name || '.' || schema_name;
+
+-- COMMAND ----------
+
+-- Three-level name of ETL Log Table
+DECLARE OR REPLACE VARIABLE run_log_table STRING
+ = full_schema_name || '.' || 'etl_run_log';
+
+-- Three-level name of Code Master Table
+DECLARE OR REPLACE VARIABLE code_table STRING
+ = full_schema_name || '.' || 'code_m';
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/01-Setup/01.2-setup.sql b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/01-Setup/01.2-setup.sql
new file mode 100644
index 00000000..8afc3e24
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/01-Setup/01.2-setup.sql
@@ -0,0 +1,49 @@
+-- Databricks notebook source
+-- MAGIC %run ./01.1-initialize
+
+-- COMMAND ----------
+
+DECLARE OR REPLACE VARIABLE sqlstr STRING; -- Variable to hold any SQL statement for EXECUTE IMMEDIATE
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC -- To CREATE Catalog
+-- MAGIC -- This option is disabled
+-- MAGIC
+-- MAGIC SET VARIABLE sqlstr = "CREATE CATALOG IF NOT EXISTS " || catalog_name;
+-- MAGIC EXECUTE IMMEDIATE sqlstr;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC -- To CREATE Catalog
+-- MAGIC -- This option is disabled
+-- MAGIC
+-- MAGIC EXECUTE IMMEDIATE 'CREATE SCHEMA IF NOT EXISTS IDENTIFIER(?)' USING full_schema_name;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Enable/disable Predictive Optimization for schema**
+
+-- COMMAND ----------
+
+BEGIN
+ DECLARE sqlstr STRING;
+
+ IF enable_po_for_schema THEN
+ SET sqlstr = "ALTER SCHEMA " || full_schema_name || ' ENABLE PREDICTIVE OPTIMIZATION';
+ EXECUTE IMMEDIATE sqlstr;
+ END IF;
+END
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Create Volume for staging source data files**
+
+-- COMMAND ----------
+
+DECLARE OR REPLACE full_volume_name = full_schema_name || '.' || volume_name;
+EXECUTE IMMEDIATE "CREATE VOLUME IF NOT EXISTS IDENTIFIER(?)" USING full_volume_name;
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/01-patient-dimension-ETL-introduction.sql b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/01-patient-dimension-ETL-introduction.sql
new file mode 100644
index 00000000..f500edea
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/01-patient-dimension-ETL-introduction.sql
@@ -0,0 +1,138 @@
+-- Databricks notebook source
+-- MAGIC %md-sandbox
+-- MAGIC # Running SQL-based ETL on Databricks - Data Warehousing Migration
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
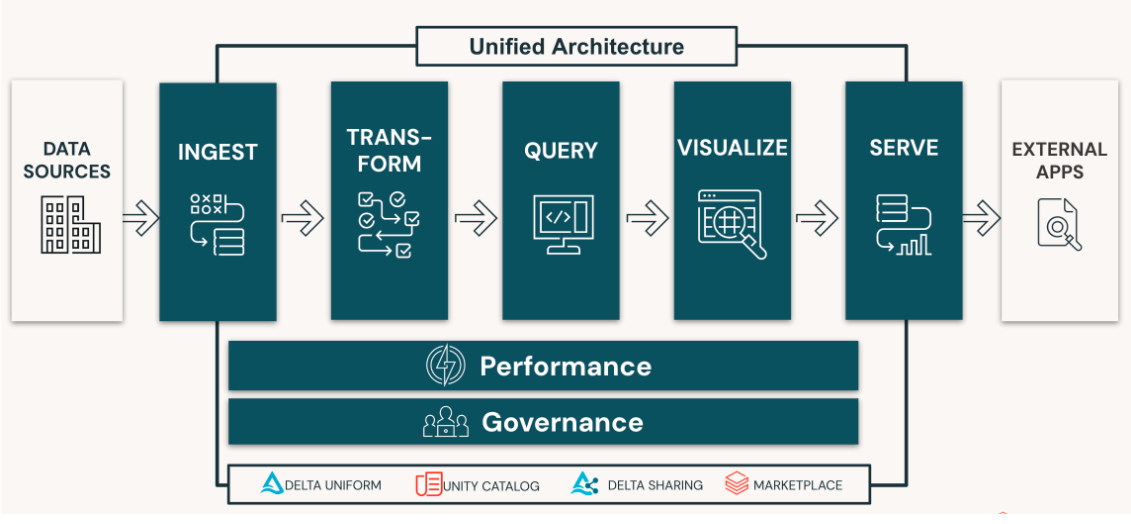
+-- MAGIC The demo illustrate how to create a SQL-first data architecture and data workflow to a classic Star Schema.
+-- MAGIC
+-- MAGIC You'll discover how to run classic SQL / DBA workflow, making it ideal to migrate your existing Datawarehouse scripts to Databricks, with minimum effort:
+-- MAGIC
+-- MAGIC * Parameterize your job to support different environments.
+-- MAGIC * Load the raw staging data
+-- MAGIC * Apply transformations
+-- MAGIC * Create star schema with FK/PK
+-- MAGIC * Leverage Databricks Workflow to chain your operation
+-- MAGIC * Incremental data loading
+-- MAGIC * Data validation
+-- MAGIC * SCD2 dimention
+-- MAGIC
+-- MAGIC
+-- MAGIC Note: The ETL assumes that the source data is extracted to cloud storage as incremental CSV files.
+-- MAGIC
+-- MAGIC ## A note on DLT
+-- MAGIC With Lakeflow DLT Databricks, provides a higher level of abstraction that we recommend for new pipelines, as it simplify the operations. We're looking to add a DLT version of this demo to outline the difference in the future.
+-- MAGIC
+-- MAGIC For more details on DLT, you can install `dbdemos.install('dbt-loans)`.
+-- MAGIC
+-- MAGIC
+-- MAGIC
+
+-- COMMAND ----------
+
+-- MAGIC %md-sandbox
+-- MAGIC # Analytics Architecture
+-- MAGIC
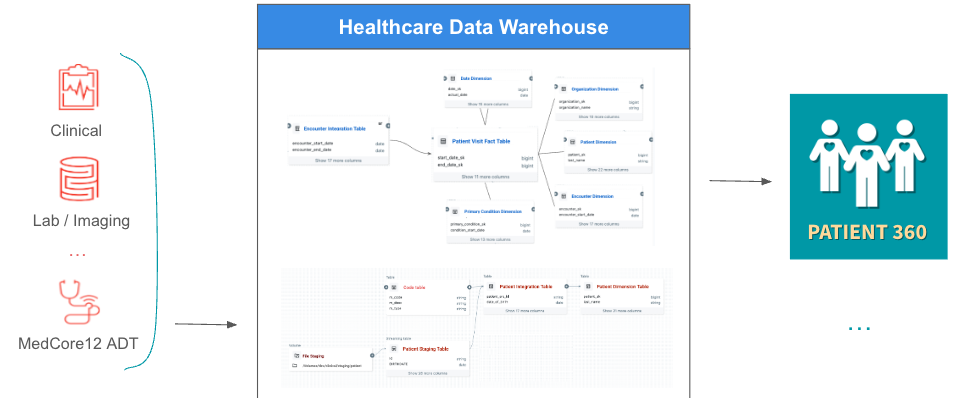
+-- MAGIC #### Integrating patient data to cater to analytics applications such as Patient 360
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC a) Global Configuration
+-- MAGIC
+-- MAGIC - **ETL Log table**: This table captures the runtime metadata for a table that includes the table name, load start time and load end time.
+-- MAGIC
+-- MAGIC _See [Create Log Table notebook]($./02-Create/02.2-create-ETL-log-table) to review._
+-- MAGIC
+-- MAGIC b) Standardization
+-- MAGIC - **Codes table**: Master table initialized with standardized codes used for coded attributes in the schema.
+-- MAGIC
+-- MAGIC _See [Create Code Table notebook]($./02-Create/02.1-create-code-table) to review._
+-- MAGIC
+-- MAGIC c) Patient tables
+-- MAGIC - **Patient Staging table**
+-- MAGIC - **Patient Integration table**
+-- MAGIC - **Patient Dimension table**
+-- MAGIC
+-- MAGIC
+-- MAGIC _See [Create Patient Tables notebook]($./02-Create/02.3-create-patient-tables) to review._
+-- MAGIC
+-- MAGIC #### 2. Stage Initial Data
+-- MAGIC This task will copy / upload an initial CSV file with patient data onto a staging Volume.
+-- MAGIC
+-- MAGIC ####3. Patient load
+-- MAGIC This will initiate the ETL which will read new files from the staging Volume and populate the staging, integration, and patient dimension tables.
+-- MAGIC
+-- MAGIC ####4. Stage Incremental Data
+-- MAGIC This task will copy / upload two incremental CSV files with patient data onto the staging Volume.
+-- MAGIC
+-- MAGIC ####5. Patient load
+-- MAGIC This will initiate the ETL which will read new files from the staging Volume and populate the staging, integration, and patient dimension tables.
+-- MAGIC
+-- MAGIC _See [Patient Dimension ETL notebook]($./03-Populate/03.1-patient-dimension-ETL) to review._
+-- MAGIC
+-- MAGIC
+-- MAGIC You can also browse the results of each ETL run. This will show the data that is present in the log table and patient tables, as it appears at the end of the initial load and each incremental load. Click on each of demo_BrowseResultInit and demo_BrowseResultIncr tasks after navigating to the job run page.
+
+-- COMMAND ----------
+
+-- MAGIC %md-sandbox
+-- MAGIC # Table Definitions
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC

+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC
+-- MAGIC

+-- MAGIC
+-- MAGIC
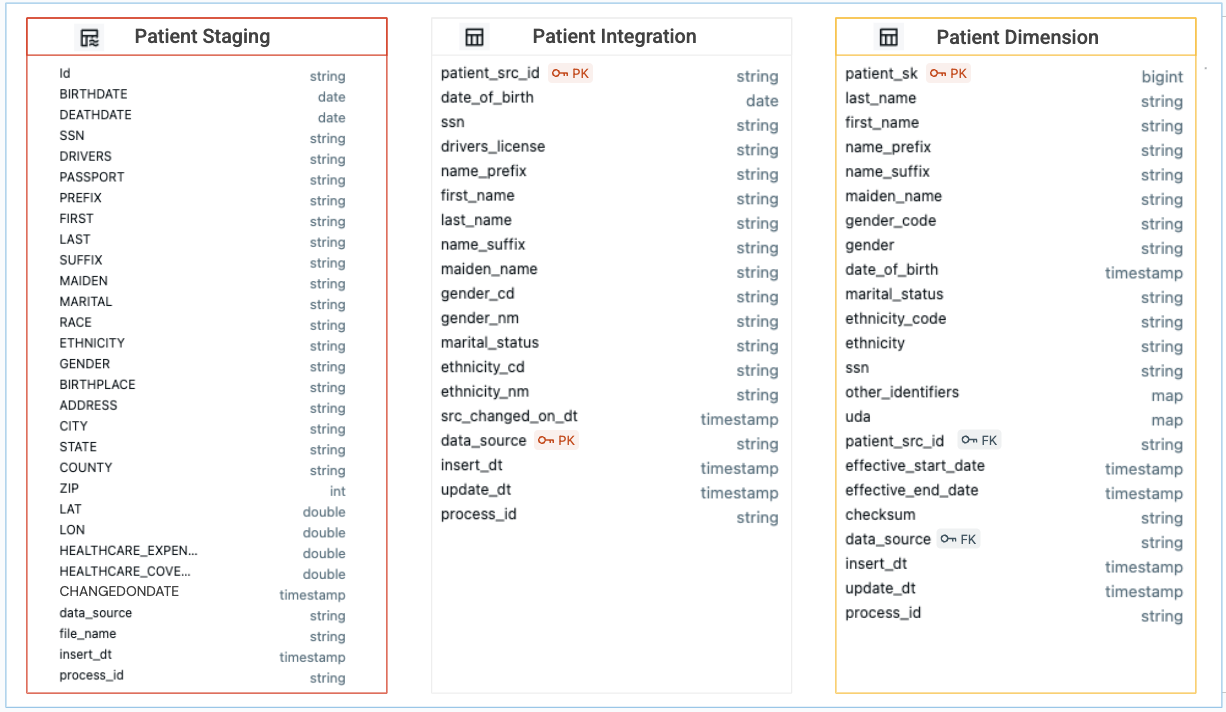
+-- MAGIC The patient dimension is part of the clinical data warehouse (star schema), similar to a customer dimension in a Sales Data Warehouse.
+-- MAGIC
+-- MAGIC NOTE: By default, the tables are created in the **catalog main** and **schema dbdemos_sql_etl**. To change this, or specify an existing catalog / schema, please see [01.1-initialize notebook]($../01-Setup/01.1-initialize) for more context.
+
+-- COMMAND ----------
+
+-- Set the current schema
+USE IDENTIFIER(full_schema_name);
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Create Staging Table for Patient
+-- MAGIC The schema for the staging table will be derived from the source data file(s)
+
+-- COMMAND ----------
+
+DROP TABLE IF EXISTS patient_stg;
+
+CREATE TABLE patient_stg
+COMMENT 'Patient staging table ingesting initial and incremental master data from csv files';
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Create Integration Table for Patient
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC Potential clustering columns include (data_source, patient_src_id)
+-- MAGIC Also, column src_changed_on_dt will be naturally ordered (ingestion-time clustering) AND data_source will typically be the same for all records in a source file.
+-- MAGIC
+-- MAGIC **Note: Predictive Optimization** intelligently optimizes your table data layouts for faster queries and reduced storage costs.
+-- MAGIC
+-- MAGIC
+-- MAGIC
+
+-- COMMAND ----------
+
+DROP TABLE IF EXISTS patient_int;
+
+CREATE TABLE patient_int (
+ patient_src_id STRING NOT NULL COMMENT 'ID of the record in the source',
+ date_of_birth DATE COMMENT 'Date of birth',
+ ssn STRING COMMENT 'Social Security Number',
+ first_name STRING COMMENT 'First Name of patient',
+ last_name STRING NOT NULL COMMENT 'Last Name of patient',
+ name_suffix STRING COMMENT 'Name suffix',
+ gender_cd STRING COMMENT 'Code for patient\'s gender',
+ gender_nm STRING COMMENT 'Description of patient\'s gender',
+ src_changed_on_dt TIMESTAMP COMMENT 'Date of last change to record in source',
+ -- system columns
+ data_source STRING NOT NULL COMMENT 'Source System for record',
+ insert_dt TIMESTAMP COMMENT 'Date record inserted',
+ update_dt TIMESTAMP COMMENT 'Date record updated',
+ process_id STRING COMMENT 'Process ID for run',
+ CONSTRAINT c_int_pk PRIMARY KEY (patient_src_id, data_source) RELY
+)
+COMMENT 'Curated integration table for patient data'
+TBLPROPERTIES (delta.enableChangeDataFeed = true);
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Create Dimension Table for Patient
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Note:**
+-- MAGIC For the dimension table, take advantage of **Predictive Optimization** and **Auto clustering**.
+-- MAGIC
+-- MAGIC Auto Clustering can be used to automatically cluster your tables based on your evolving workload!
+-- MAGIC
+-- MAGIC Auto Clustering is enabled via **CLUSTER BY AUTO** clause.
+
+-- COMMAND ----------
+
+DROP TABLE IF EXISTS patient_dim;
+
+CREATE TABLE patient_dim (
+ patient_sk BIGINT GENERATED ALWAYS AS IDENTITY COMMENT 'Primary Key (ID)',
+ last_name STRING NOT NULL COMMENT 'Last name of the person',
+ first_name STRING COMMENT 'First name of the person',
+ name_suffix STRING COMMENT 'Suffix of person name',
+ gender_code STRING COMMENT 'Gender code',
+ gender STRING COMMENT 'Gender description',
+ date_of_birth TIMESTAMP COMMENT 'Birth date and time',
+ ssn STRING COMMENT 'Patient SSN',
+ other_identifiers MAP COMMENT 'Identifier type (passport number, license number except mrn, ssn) and value',
+ patient_src_id STRING NOT NULL COMMENT 'Unique reference to the source record',
+ -- system columns
+ effective_start_date TIMESTAMP NOT NULL COMMENT 'SCD2 effective start date for version',
+ effective_end_date TIMESTAMP COMMENT 'SCD2 effective start date for version',
+ checksum STRING COMMENT 'Checksum for the record',
+ data_source STRING NOT NULL COMMENT 'Code for source system',
+ insert_dt TIMESTAMP COMMENT 'Record inserted time',
+ update_dt TIMESTAMP COMMENT 'Record updated time',
+ process_id STRING COMMENT 'Process ID for run',
+ CONSTRAINT c_d_pk PRIMARY KEY (patient_sk) RELY
+)
+CLUSTER BY AUTO
+COMMENT 'Patient dimension'
+TBLPROPERTIES (
+ delta.deletedFileRetentionDuration = 'interval 30 days'
+);
+
+-- COMMAND ----------
+
+-- FK to integration table
+SET VARIABLE sqlstr = 'ALTER TABLE patient_dim ADD CONSTRAINT
+ c_d_int_source_fk FOREIGN KEY (patient_src_id, data_source) REFERENCES ' || full_schema_name || '.' || 'patient_int(patient_src_id, data_source) NOT ENFORCED RELY';
+
+EXECUTE IMMEDIATE sqlstr;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ### What's next after you finish this notebook?
+-- MAGIC
+-- MAGIC This notebook highlights the design of dimensional entities in your Data Warehouse while following all best practices.
+-- MAGIC
+-- MAGIC You can carry this forward to all your Dimension and Fact tables.
+-- MAGIC
+-- MAGIC See Also: [Star Schema Data Modeling Best Practices on Databricks SQL](https://medium.com/dbsql-sme-engineering/star-schema-data-modeling-best-practices-on-databricks-sql-8fe4bd0f6902)
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/03-Populate/03.1-patient-dimension-ETL.sql b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/03-Populate/03.1-patient-dimension-ETL.sql
new file mode 100644
index 00000000..43c8db31
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/03-Populate/03.1-patient-dimension-ETL.sql
@@ -0,0 +1,419 @@
+-- Databricks notebook source
+-- MAGIC %md-sandbox
+-- MAGIC # Patient Dimension ETL
+-- MAGIC This notebook contains the code to load the patient dimension which is part of the clinical star schema.
+-- MAGIC The same pattern can be used to load any of your business dimensions.
+-- MAGIC
+-- MAGIC The notebook performs the following tasks:
+-- MAGIC -> Load staging table
+-- MAGIC -> Curate and load integration table
+-- MAGIC -> Transform and load dimension table using SCD2
+-- MAGIC
+-- MAGIC The staging table is loaded from files extracted to cloud storage.
+-- MAGIC These files contain incremental data extracts.
+-- MAGIC Zero, one, or more new files loaded during each run.
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC Staging table name => **patient_stg**
+-- MAGIC Integration table name => **patient_int**
+-- MAGIC Dimension table name => **patient_dim**
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **The code incorporates the following design elements:**
+-- MAGIC - Incremental load
+-- MAGIC - Versioning of data (SCD Type 2)
+-- MAGIC - Checksum
+-- MAGIC - Code standardization
+-- MAGIC
+-- MAGIC Simply re-run Job to recover from a runtime error.
+-- MAGIC
+-- MAGIC
+-- MAGIC _The code uses temporary views and single DML for each of the tables._
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC # Configuration and Settings
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ##Initialize
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC Include variables such as full_schema_name, code_table, staging_path, etc.
+
+-- COMMAND ----------
+
+-- MAGIC %run ../01-Setup/01.1-initialize
+
+-- COMMAND ----------
+
+-- to capture load start time for each table
+DECLARE OR REPLACE VARIABLE table_load_start_time TIMESTAMP;
+
+-- COMMAND ----------
+
+DECLARE OR REPLACE VARIABLE data_source STRING DEFAULT 'MedCore12 ADT'; -- Source system of record
+DECLARE OR REPLACE VARIABLE process_id STRING; -- A process ID to associate with the load, for e.g., session ID, run ID
+
+-- COMMAND ----------
+
+DECLARE OR REPLACE VARIABLE sqlstr STRING; -- Variable to hold any SQL statement for EXECUTE IMMEDIATE
+
+-- COMMAND ----------
+
+-- (Optional) Set Proceess Id for observability, debugging
+-- Pass Workflows {{job.id}}-{{job.run_id}} to notebook parameter
+SET VARIABLE process_id = :p_process_id;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ##Set Current Schema
+
+-- COMMAND ----------
+
+-- Set the current schema
+USE IDENTIFIER(full_schema_name);
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ##Set Variables for Incremental Load
+-- MAGIC Determine the last load date for Integration and Dimension tables.
+-- MAGIC
+
+-- COMMAND ----------
+
+-- get last load timestamp from target table (metadata-only query!)
+-- if table is empty, fallback to initial load
+
+DECLARE OR REPLACE VARIABLE int_last_load_date TIMESTAMP default '1990-01-01';
+SET VARIABLE int_last_load_date = COALESCE((SELECT MAX(update_dt) FROM patient_int), session.int_last_load_date);
+
+DECLARE OR REPLACE VARIABLE dim_last_load_date TIMESTAMP default '1990-01-01';
+SET VARIABLE dim_last_load_date = COALESCE((SELECT MAX(update_dt) FROM patient_dim), session.dim_last_load_date);
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC # Load staging table
+-- MAGIC **Load the incremental (cdc) source files to staging table**
+-- MAGIC
+-- MAGIC The initial and incremental source CSV files are uploaded to a staging location.
+-- MAGIC
+-- MAGIC The staging table is insert-only.
+-- MAGIC
+
+-- COMMAND ----------
+
+-- Record load start time for staging table
+-- This is used to populate the ETL Run Table
+SET VARIABLE table_load_start_time = CURRENT_TIMESTAMP();
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## COPY INTO staging table
+-- MAGIC
+-- MAGIC For more information, see [Easy Ingestion to Lakehouse With COPY INTO](https://www.databricks.com/blog/easy-ingestion-lakehouse-copy)
+-- MAGIC
+-- MAGIC Note that Streaming Tables provide advanced capabilities to load from additional sources. See [Load data using streaming tables in Databricks SQL](https://docs.databricks.com/aws/en/tables/streaming).
+
+-- COMMAND ----------
+
+-- Staging path is path to "staging" volume
+DECLARE OR REPLACE VARIABLE staging_location STRING = session.staging_path || "/patient";
+
+-- COMMAND ----------
+
+SET VARIABLE sqlstr = "
+ COPY INTO patient_stg
+ FROM (
+ SELECT
+ *,
+ session.data_source AS data_source,
+ _metadata.file_name AS file_name,
+ CURRENT_TIMESTAMP() AS insert_dt,
+ session.process_id AS process_id
+ FROM '" || session.staging_location || "'
+ )
+ FILEFORMAT = CSV
+ FORMAT_OPTIONS ('header' = 'true', 'inferSchema' = 'true', 'mergeSchema' = 'true')
+ COPY_OPTIONS ('mergeSchema' = 'true')";
+
+-- Load staging table
+EXECUTE IMMEDIATE sqlstr;
+
+-- COMMAND ----------
+
+-- Optionally log the ETL run for easy reporting, monitoring, and alerting
+INSERT INTO IDENTIFIER(run_log_table)
+WITH op_metrics AS (
+ SELECT
+ -- For the COPY command,
+ -- if no new files are present, then a) no operation is performed and b) new table version is not registered
+ -- Check if a new table version was created by the COPY command
+ CASE WHEN `timestamp` > table_load_start_time THEN COALESCE(operationMetrics.numTargetRowsInserted, operationMetrics.numOutputRows) ELSE 0 END AS num_inserted,
+ operationMetrics.numTargetRowsUpdated AS num_updated
+ FROM (DESCRIBE HISTORY patient_stg) WHERE operation IN ('MERGE', 'WRITE', 'COPY INTO') LIMIT 1
+)
+SELECT session.data_source, session.full_schema_name || '.' || 'patient_stg', table_load_start_time, CURRENT_TIMESTAMP(), num_inserted, num_updated, session.process_id FROM op_metrics;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC # Populate integration table
+-- MAGIC Validate, curate, and load incremental data into the integration table.
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## _Placeholder_
+-- MAGIC
+-- MAGIC _Validate incoming data
+-- MAGIC Handle errors in the newly inserted data, before populating the curated data in the integration table._
+-- MAGIC _Exception records (refs) can be captured in common table error table elt_error_table._
+-- MAGIC
+-- MAGIC
+-- MAGIC _Steps would involve:_
+-- MAGIC - _Checking business rules / mandatory data, and quarantining records_
+-- MAGIC
+-- MAGIC _For e.g.,_
+-- MAGIC - _ID is null_
+-- MAGIC - _CHANGEDONDATE is null_
+-- MAGIC - _LAST (name) is null_
+-- MAGIC - _Older version in source_
+
+-- COMMAND ----------
+
+-- Record load start time for integration table
+-- This is used to populate the ETL Run Table
+SET VARIABLE table_load_start_time = CURRENT_TIMESTAMP();
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Transform incoming rows from staging table
+-- MAGIC The temporary view curates the data as follows:
+-- MAGIC - Transforms columns
+-- MAGIC - Standardizes code description for gender and ethnicity
+-- MAGIC
+-- MAGIC The integration table is being treated as insert only.
+
+-- COMMAND ----------
+
+-- Transform ingested source data
+CREATE OR REPLACE TEMPORARY VIEW stg_transform_temp_v
+AS
+WITH vars AS (SELECT session.int_last_load_date, session.code_table), -- SELECT the variables for use in later clauses
+patient_stg_cdc AS (
+ SELECT * FROM patient_stg stg
+ WHERE stg.insert_dt > session.int_last_load_date
+)
+SELECT
+ `Id` AS patient_src_id,
+ birthdate AS date_of_birth,
+ ssn AS ssn,
+ `FIRST` AS first_name,
+ `LAST` AS last_name,
+ INITCAP(suffix) AS name_suffix,
+ gender AS gender_cd,
+ IFNULL(code_gender.m_desc, gender) AS gender_nm,
+ CHANGEDONDATE AS src_changed_on_dt,
+ data_source,
+ CURRENT_TIMESTAMP() AS insert_dt,
+ CURRENT_TIMESTAMP() AS update_dt,
+ session.process_id AS process_id
+FROM patient_stg_cdc
+LEFT OUTER JOIN IDENTIFIER(session.code_table) code_gender ON code_gender.m_code = patient_stg_cdc.gender AND code_gender.m_type = 'GENDER'
+LEFT OUTER JOIN IDENTIFIER(session.code_table) code_ethn ON code_ethn.m_code = patient_stg_cdc.ethnicity AND code_ethn.m_type = 'ETHNICITY'
+WHERE
+ -- No error records
+ `Id` IS NOT NULL AND CHANGEDONDATE IS NOT NULL AND `LAST` IS NOT NULL -- These conditions could be part of exception handling
+;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Insert data
+-- MAGIC Insert data into the integration table using transformation view.
+-- MAGIC
+-- MAGIC Note: The design is to retain all versions of data, hence Insert. Else use Merge.
+
+-- COMMAND ----------
+
+-- Insert new and changed data
+INSERT INTO patient_int
+SELECT * FROM stg_transform_temp_v
+;
+
+-- COMMAND ----------
+
+-- Optionally log the ETL run for easy reporting, monitoring, and alerting
+INSERT INTO IDENTIFIER(run_log_table)
+WITH op_metrics AS (
+ SELECT COALESCE(operationMetrics.numTargetRowsInserted, operationMetrics.numOutputRows) AS num_inserted, operationMetrics.numTargetRowsUpdated AS num_updated FROM (DESCRIBE HISTORY patient_int) WHERE operation IN ('MERGE', 'WRITE', 'COPY INTO') LIMIT 1
+)
+SELECT session.data_source, session.full_schema_name || '.' || 'patient_int', table_load_start_time, CURRENT_TIMESTAMP(), num_inserted, num_updated, session.process_id FROM op_metrics;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC # Populate dimension table
+-- MAGIC The dimension table patient_dim is created as a SCD2 dimension.
+
+-- COMMAND ----------
+
+-- Record load start time for dimension table
+-- This is used to populate the ETL Run Table
+SET VARIABLE table_load_start_time = CURRENT_TIMESTAMP();
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Transform incoming rows from integration table
+-- MAGIC This view is used to **a)** transform incoming rows as required **b)** create checksum
+-- MAGIC
+-- MAGIC This view constitutes the new patients and new versions that are part of this batch.
+
+-- COMMAND ----------
+
+CREATE OR REPLACE TEMPORARY VIEW int_transform_temp_v
+AS
+WITH vars AS (SELECT session.dim_last_load_date) -- select the variables for use in later clauses
+SELECT
+ last_name,
+ first_name,
+ name_suffix,
+ gender_cd AS gender_code, gender_nm AS gender,
+ date_of_birth,
+ ssn,
+ NULL AS other_identifiers,
+ patient_src_id,
+ src_changed_on_dt AS effective_start_date,
+ hash(
+ last_name, ifnull(first_name, '#'), ifnull(name_suffix, '#'), ifnull(gender_cd, '#'), ifnull(gender_nm, '#'), ifnull(date_of_birth, '#'), ifnull(ssn, '#')
+ ) AS checksum,
+ data_source
+FROM patient_int
+WHERE patient_int.update_dt > session.dim_last_load_date
+;
+
+-- COMMAND ----------
+
+-- MAGIC %md-sandbox
+-- MAGIC ## Create view for merge
+-- MAGIC This view builds on the transformations and is used to **a)** handle new and changed instances **b)** handle multiple changes in a single batch **c)** ignore consecutive versions if no changes to business attributes of interest
+-- MAGIC
+-- MAGIC The view includes the following elements:
+-- MAGIC
+-- MAGIC 1. CTE curr_version
+-- MAGIC Identify the Current Versions of all Patient instances corresponding to incoming data in this run.
+-- MAGIC 3. CTE rows_for_merge
+-- MAGIC This CTE isolates new patients and new versions of existing patients for insert. This also identifies existing versions which need to be updated (potentially), to include an effective_end_date.
+-- MAGIC Finally there is-
+-- MAGIC 4. CTE no_dup_ver
+-- MAGIC This is used to eliminate any updated records from the source for which there are no changes to business attributes of interest. For e.g., drivers_license is not being populated in the dimension. Suppose the only update in the source is to drivers_license, it will simply turn out to be a duplicate record.
+
+-- COMMAND ----------
+
+CREATE OR REPLACE TEMPORARY VIEW dim_merge_temp_v
+AS
+WITH curr_version AS (
+ -- get current version records from dimension table, if any, corresponding to incoming data
+ SELECT * EXCEPT (effective_end_date, insert_dt, update_dt, process_id)
+ FROM patient_dim
+ WHERE effective_end_date IS NULL AND
+ EXISTS (SELECT 1 FROM int_transform_temp_v int_transform
+ WHERE int_transform.patient_src_id = patient_dim.patient_src_id AND int_transform.data_source = patient_dim.data_source)
+),
+rows_for_merge AS (
+ SELECT NULL AS patient_sk, * FROM int_transform_temp_v -- new patients and new versions to insert
+ UNION ALL
+ SELECT * FROM curr_version -- current versions for update (effective_end_date)
+),
+no_dup_ver AS (
+ -- ignore consecutive versions if no changes to any business attributes of interest
+ SELECT
+ *,
+ LAG(checksum, 1, NULL) OVER (PARTITION BY patient_src_id, data_source ORDER BY effective_start_date ASC) AS checksum_next
+ FROM rows_for_merge
+ QUALIFY checksum <> IFNULL(checksum_next, '#')
+)
+-- final set of records to be merged
+SELECT
+ *,
+ LEAD(effective_start_date, 1, NULL) OVER (PARTITION BY patient_src_id ORDER BY effective_start_date ASC) AS effective_end_date
+FROM no_dup_ver
+;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ## Merge data
+-- MAGIC Update the dimension table by:
+-- MAGIC - Merge new and changed records.
+-- MAGIC - Version existing patient records (by updating effective_end_date).
+-- MAGIC
+-- MAGIC _Note: The Effective Start Date for a version is based on the CHANGEDONDATE as recieved from the source._
+
+-- COMMAND ----------
+
+MERGE INTO patient_dim d
+USING dim_merge_temp_v tr
+ON d.patient_sk = tr.patient_sk
+WHEN MATCHED THEN UPDATE
+ -- UPDATE end date FOR existing version OF patient
+ SET d.effective_end_date = tr.effective_end_date,
+ update_dt = CURRENT_TIMESTAMP(),
+ process_id = session.process_id
+WHEN NOT MATCHED THEN INSERT (
+ -- INSERT new version, new patient
+ last_name,
+ first_name,
+ name_suffix,
+ gender_code,
+ gender,
+ date_of_birth,
+ ssn,
+ patient_src_id,
+ effective_start_date,
+ effective_end_date,
+ checksum,
+ data_source,
+ insert_dt,
+ update_dt,
+ process_id)
+ VALUES (last_name, first_name, name_suffix, gender_code, gender, date_of_birth, ssn, patient_src_id,
+ effective_start_date, effective_end_date, checksum, data_source, CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP(), session.process_id)
+;
+
+-- COMMAND ----------
+
+-- Optionally log the ETL run for easy reporting, monitoring, and alerting
+INSERT INTO IDENTIFIER(run_log_table)
+WITH op_metrics AS (
+ SELECT COALESCE(operationMetrics.numTargetRowsInserted, operationMetrics.numOutputRows) AS num_inserted, operationMetrics.numTargetRowsUpdated AS num_updated FROM (DESCRIBE HISTORY patient_dim) WHERE operation IN ('MERGE', 'WRITE', 'COPY INTO') LIMIT 1
+)
+SELECT session.data_source, session.full_schema_name || '.' || 'patient_dim', table_load_start_time, CURRENT_TIMESTAMP(), num_inserted, num_updated, session.process_id FROM op_metrics;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC ### What's next after you finish this notebook?
+-- MAGIC
+-- MAGIC This notebook highlights the end-to-end SQL code for staging, integrating, and populating a dimensional entity. The same pattern can be followed for all SCD Type 2 dimensions in your Star Schema.
+-- MAGIC
+-- MAGIC SCD Type 1 dimensions will follow a simpler pattern when merging into the dimension table.
+-- MAGIC
+-- MAGIC Complete the ETL pipeline, populating your Fact Tables by looking up the dimension tables (and for SCD Type 2 dimensions be sure to factor in the effective dates in relation to the business process event time).
+-- MAGIC
+-- MAGIC The presentation layer is now ready for consumption using Databricks AI/BI or other enterprise BI tool.
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/README.ipynb b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/README.ipynb
new file mode 100644
index 00000000..281314de
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/README.ipynb
@@ -0,0 +1,42 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {},
+ "inputWidgets": {},
+ "nuid": "0704414a-6946-4b0c-ba3c-6f787f4c9830",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "## DBDemos asset\n",
+ "\n",
+ "The notebooks available under `_/resources` are technical demo resources.\n",
+ "\n",
+ "Do not edit these notebooks or try to run them directly. These notebooks will load data / download files / run some utility."
+ ]
+ }
+ ],
+ "metadata": {
+ "application/vnd.databricks.v1+notebook": {
+ "computePreferences": null,
+ "dashboards": [],
+ "environmentMetadata": null,
+ "language": "python",
+ "notebookMetadata": {
+ "pythonIndentUnit": 2
+ },
+ "notebookName": "README",
+ "widgets": {}
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/browse-load.sql b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/browse-load.sql
new file mode 100644
index 00000000..239b34a2
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/browse-load.sql
@@ -0,0 +1,56 @@
+-- Databricks notebook source
+-- MAGIC %run "../01-Setup/01.1-initialize"
+
+-- COMMAND ----------
+
+USE IDENTIFIER(full_schema_name)
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **ETL Log Table**
+
+-- COMMAND ----------
+
+SELECT * FROM IDENTIFIER(run_log_table) ORDER BY load_start_time;
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Patient Staging Table**
+
+-- COMMAND ----------
+
+-- DBTITLE 1,Bronze
+SELECT Id, CHANGEDONDATE, data_source, * EXCEPT(Id, CHANGEDONDATE, data_source)
+FROM patient_stg
+ORDER BY data_source, Id, CHANGEDONDATE
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Patient Integration Table**
+-- MAGIC
+-- MAGIC The integration process filters out records where the **Id is NULL or CHANGEDONDATE is NULL or Last Name is NULL**. These and other business errors can be part of the exception logging process.
+
+-- COMMAND ----------
+
+-- DBTITLE 1,Silver
+SELECT patient_src_id, src_changed_on_dt, data_source, * EXCEPT(patient_src_id, src_changed_on_dt, data_source)
+FROM patient_int
+ORDER BY data_source, patient_src_id, src_changed_on_dt
+
+-- COMMAND ----------
+
+-- MAGIC %md
+-- MAGIC **Patient Dimension Table**
+-- MAGIC
+-- MAGIC The MERGE process ignores **duplicate versions**.
+
+-- COMMAND ----------
+
+-- DBTITLE 1,Gold
+SELECT
+ patient_sk, patient_src_id, effective_start_date, effective_end_date, data_source, * EXCEPT(patient_sk, patient_src_id, effective_start_date, effective_end_date, data_source)
+FROM patient_dim
+ORDER BY data_source, patient_src_id, effective_start_date
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/bundle_config.py b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/bundle_config.py
new file mode 100644
index 00000000..587d1c6b
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/bundle_config.py
@@ -0,0 +1,305 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC ## Demo bundle configuration
+# MAGIC Please ignore / do not delete, only used to prep and bundle the demo
+
+# COMMAND ----------
+
+{
+ "name": "dbsql-for-dim-etl",
+ "category": "DBSQL",
+ "title": "DBSQL: Create & Populate Type 2 Patient Dimension",
+ "custom_schema_supported": True,
+ "default_catalog": "main",
+ "default_schema": "dbdemos_sql_etl",
+ "description": "The demo will illustrate the data architecture and data workflow that creates and populates a dimension in a Star Schema using Databricks SQL. This will utilize a Patient dimension in the Healthcare domain. The demo will illustrate all facets of an end-to-end ETL to transform, validate, and load an SCD2 dimension.",
+ "bundle": True,
+ "notebooks": [
+ {
+ "path": "00-get-started-with-SQL",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Get Started with Databricks SQL",
+ "description": "Start here to explore the demo."
+ },
+ {
+ "path": "01-patient-dimension-ETL-introduction",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Patient Dimension ETL Introduction",
+ "description": "Start here to explore the demo."
+ },
+ {
+ "path": "sql-centric-capabilities-examples",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "SQL Centric Capabilities Examples",
+ "description": "Start here to explore the SQL Scripting example."
+ },
+ {
+ "path": "01-Setup/01.1-initialize",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Configure and Initialize",
+ "description": "Configure demo catalog, schema, and initialize global variables."
+ },
+ {
+ "path": "01-Setup/01.2-setup",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Create demo Catalog/Schema/Volume",
+ "description": "Create demo Catalog/Schema/Volume."
+ },
+ {
+ "path": "02-Create/02.1-create-code-table",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Create Code Table",
+ "description": "Create the code master table and initialize with sample data."
+ },
+ {
+ "path": "02-Create/02.2-create-ETL-log-table",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Create ETL Log Table",
+ "description": "Create the ETL log table to log metadata on each ETL run."
+ },
+ {
+ "path": "02-Create/02.3-create-patient-tables",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Create Patient Tables",
+ "description": "Create the patient staging, patient integration, and patient dimension tables."
+ },
+ {
+ "path": "03-Populate/03.1-patient-dimension-ETL",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Populate Patient Dimension",
+ "description": "Populate the patient staging, patient integration, and patient dimension tables."
+ },
+ {
+ "path": "_resource/browse-load",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Browse Load",
+ "description": "Browse the data populated in the patient tables and log table."
+ },
+ {
+ "path": "_resource/stage-source-file-init",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Stage Source Data File - Initial Load",
+ "description": "Stage the source CSV file for initial load onto the staging volume and folder."
+ },
+ {
+ "path": "_resource/stage-source-file-incr",
+ "pre_run": False,
+ "publish_on_website": True,
+ "add_cluster_setup_cell": False,
+ "title": "Stage Source Data File - Incremental Load",
+ "description": "Stage the source CSV file for incremental load onto the staging volume and folder."
+ }
+ ],
+ "init_job": {
+ "settings": {
+ "name": "dbdemos_patient_dimension_etl_{{CATALOG}}_{{SCHEMA}}",
+ "email_notifications": {
+ "no_alert_for_skipped_runs": False
+ },
+ "webhook_notifications": {},
+ "timeout_seconds": 0,
+ "max_concurrent_runs": 1,
+ "tasks": [
+ {
+ "task_key": "INITIALIZE_AND_SETUP_SCHEMA",
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/01-Setup/01.2-setup",
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "CREATE_CODE_TABLE",
+ "depends_on": [
+ {
+ "task_key": "INITIALIZE_AND_SETUP_SCHEMA"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/02-Create/02.1-create-code-table",
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "CREATE_LOG_TABLE",
+ "depends_on": [
+ {
+ "task_key": "INITIALIZE_AND_SETUP_SCHEMA"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/02-Create/02.2-create-ETL-log-table",
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "CREATE_PATIENT_TABLES",
+ "depends_on": [
+ {
+ "task_key": "INITIALIZE_AND_SETUP_SCHEMA"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/02-Create/02.3-create-patient-tables",
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "demo_StgSrcFileInit",
+ "depends_on": [
+ {
+ "task_key": "INITIALIZE_AND_SETUP_SCHEMA"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/_resource/stage-source-file-init",
+ "source": "WORKSPACE"
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "INITIAL_LOAD_PATIENT",
+ "depends_on": [
+ {
+ "task_key": "CREATE_PATIENT_TABLES"
+ },
+ {
+ "task_key": "CREATE_CODE_TABLE"
+ },
+ {
+ "task_key": "CREATE_LOG_TABLE"
+ },
+ {
+ "task_key": "demo_StgSrcFileInit"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/03-Populate/03.1-patient-dimension-ETL",
+ "base_parameters": {
+ "p_process_id": "{{job.id}}-{{job.run_id}}"
+ },
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {},
+ "description": "Initial load of Patient Tables"
+ },
+ {
+ "task_key": "demo_BrowseResultInit",
+ "depends_on": [
+ {
+ "task_key": "INITIAL_LOAD_PATIENT"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/_resource/browse-load",
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {},
+ "description": "Browse results of the initial load"
+ },
+ {
+ "task_key": "demo_StgSrcFileIncr",
+ "depends_on": [
+ {
+ "task_key": "INITIAL_LOAD_PATIENT"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/_resource/stage-source-file-incr",
+ "source": "WORKSPACE"
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "INCREMENTAL_LOAD_PATIENT",
+ "depends_on": [
+ {
+ "task_key": "demo_StgSrcFileIncr"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/03-Populate/03.1-patient-dimension-ETL",
+ "base_parameters": {
+ "p_process_id": "{{job.id}}-{{job.run_id}}"
+ },
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ },
+ {
+ "task_key": "demo_BrowseResultIncr",
+ "depends_on": [
+ {
+ "task_key": "INCREMENTAL_LOAD_PATIENT"
+ }
+ ],
+ "run_if": "ALL_SUCCESS",
+ "notebook_task": {
+ "notebook_path": "{{DEMO_FOLDER}}/_resource/browse-load",
+ "source": "WORKSPACE",
+ "warehouse_id": ""
+ },
+ "timeout_seconds": 0,
+ "email_notifications": {}
+ }
+ ],
+ "format": "MULTI_TASK",
+ "queue": {
+ "enabled": True
+ }
+ },
+ },
+ "serverless_supported": True,
+ "cluster": {},
+ "pipelines": [],
+}
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/stage-source-file-incr.py b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/stage-source-file-incr.py
new file mode 100644
index 00000000..e5b93a65
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/stage-source-file-incr.py
@@ -0,0 +1,30 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC ## Stage the source file for incremental load
+# MAGIC
+# MAGIC This notebook simulates the uploading of new and incremental source data extracts to a data staging location for, to be ingested into the Data Warehouse.
+
+# COMMAND ----------
+
+# DBTITLE 1,initialize config for sgc
+# MAGIC %run "../01-Setup/01.1-initialize"
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Copy / upload _patients_incr1.csv, patients_incr2.csv_ to volume staging path (/Volumes/\/\/staging/patient)
+
+# COMMAND ----------
+
+vol_path = spark.sql("select staging_path").first()["staging_path"]
+
+# COMMAND ----------
+
+# DBTITLE 1,initial file name
+cloud_loc = "s3://dbdemos-dataset/dbsql/sql-etl-hls-patient"
+
+# COMMAND ----------
+
+# DBTITLE 1,stage the file for initial load
+dbutils.fs.cp(cloud_loc + "/patients_incr1.csv", vol_path + "/patient")
+dbutils.fs.cp(cloud_loc + "/patients_incr2.csv", vol_path + "/patient")
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/stage-source-file-init.py b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/stage-source-file-init.py
new file mode 100644
index 00000000..1daf0e01
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/_resource/stage-source-file-init.py
@@ -0,0 +1,37 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC ## Stage the source file for initial load
+# MAGIC
+# MAGIC This notebook simulates the uploading of source data file(s) to a data staging location, to be ingested into the Data Warehouse.
+
+# COMMAND ----------
+
+# DBTITLE 1,initialize config for sgc
+# MAGIC %run "../01-Setup/01.1-initialize"
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Copy / upload _patients50_init.csv_ to volume staging path (/Volumes/\/\/staging/patient)
+
+# COMMAND ----------
+
+vol_path = spark.sql("select staging_path").first()["staging_path"]
+
+# COMMAND ----------
+
+# clear source files (if existing)
+dbutils.fs.rm(vol_path + "/patient" + "/patients50_init.csv")
+dbutils.fs.rm(vol_path + "/patient" + "/patients_incr1.csv")
+dbutils.fs.rm(vol_path + "/patient" + "/patients_incr2.csv")
+
+# COMMAND ----------
+
+# create staging folder (if not existing)
+dbutils.fs.mkdirs(vol_path + "/patient")
+
+# COMMAND ----------
+
+# DBTITLE 1,stage the file for initial load
+cloud_loc = "s3://dbdemos-dataset/dbsql/sql-etl-hls-patient"
+dbutils.fs.cp(cloud_loc + "/patients50_init.csv", vol_path + "/patient")
diff --git a/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/sql-centric-capabilities-examples.ipynb b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/sql-centric-capabilities-examples.ipynb
new file mode 100644
index 00000000..b90a0bd9
--- /dev/null
+++ b/product_demos/DBSQL-Datawarehousing/sql-dimension-etl/sql-centric-capabilities-examples.ipynb
@@ -0,0 +1,328 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "1784d715-99b4-4e16-be09-4cde0a0dc70c",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "# SQL Centric Engine Capabilities\n",
+ "\n",
+ "**Below are examples of some Databricks SQL capabilities.**\n",
+ "\n",
+ "The examples include 1) Using SQL Variables 2) SQL Scripting and Dynamic SQL."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "2c783fcb-ff1f-4572-bf4c-ddf73e4df59a",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "%md \n",
+ "## 1. Declare Variable\n",
+ "\n",
+ "Variables are typed objects which store values that are private to a session. In Databricks variables are temporary and declared within a session using the DECLARE VARIABLE statement.\n",
+ "\n",
+ "Public Documentation: [AWS](https://docs.databricks.com/aws/en/sql/language-manual/sql-ref-syntax-ddl-declare-variable) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/sql-ref-syntax-ddl-declare-variable) | [GCP](https://docs.databricks.com/gcp/en/sql/language-manual/sql-ref-syntax-ddl-declare-variable)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "implicitDf": true,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "a22facfc-9b3b-4830-ae54-9f49df7a4a61",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "-- Storage location for demo sample files\n",
+ "DECLARE OR REPLACE VARIABLE cloud_loc STRING;\n",
+ "SET VARIABLE cloud_loc = \"s3://dbdemos-dataset/dbsql/sql-etl-hls-patient\";\n",
+ "\n",
+ "-- List of sample patient data file names\n",
+ "DECLARE OR REPLACE VARIABLE file_names ARRAY;\n",
+ "SET VARIABLE file_names = array('patients50_init.csv', 'patients_incr1.csv', 'patients_incr2.csv', 'NOTICE.txt');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "9bd241c8-d196-418f-b3ec-db7ac2bba482",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "%md \n",
+ "## 2. SQL Scripting\n",
+ "\n",
+ "- Write complex logic with Pure SQL\n",
+ "- Combine SQL Statements with Control Flow \n",
+ "- SQL/PSM standard\n",
+ "- Refer to Public Documentation: [AWS](https://docs.databricks.com/aws/en/sql/language-manual/sql-ref-scripting) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/sql-ref-scripting) | [GCP](https://docs.databricks.com/gcp/pt/sql/language-manual/sql-ref-scripting)\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "2bee861e-191b-4ed7-8bf1-d2387247ac22",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "%md-sandbox\n",
+ "### Example\n",
+ "\n",
+ "The SQL Script below does the following:
\n",
+ "\n",
+ "Loop through the 3 patient sample data files to-\n",
+ "1. Identify the headers\n",
+ "2. Create persistent views in the current schema\n",
+ "\n",
+ "NOTE:\n",
+ "The SQL script below will create or **replace** any existing views with the following names, in the current schema:\n",
+ "- dbdemos_patients50_init\n",
+ "- dbdemos_patients_incr1\n",
+ "- dbdemos_patients_incr2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "implicitDf": true,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "b475dd03-b0b1-4da1-a10e-67ff052cb767",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "-- Explore format of sample patient data files\n",
+ "BEGIN\n",
+ " DECLARE first_row STRING;\n",
+ " DECLARE result_arr ARRAY DEFAULT array();\n",
+ " DECLARE sqlstr STRING;\n",
+ " DECLARE view_name STRING;\n",
+ "\n",
+ " -- Drop the 3 views if existing\n",
+ " -- These are created in this script\n",
+ " DROP VIEW IF EXISTS dbdemos_patients50_init;\n",
+ " DROP VIEW IF EXISTS dbdemos_patients_incr1;\n",
+ " DROP VIEW IF EXISTS dbdemos_patients_incr2;\n",
+ "\n",
+ " lbl_for_loop:\n",
+ " FOR filelist AS (SELECT explode(file_names) AS file_name)\n",
+ " DO\n",
+ " -- For each file (name), do\n",
+ "\n",
+ " -- Read first line from file into variable\n",
+ " SET first_row = (SELECT * FROM read_files(cloud_loc || '/' || filelist.file_name, format=>'TEXT') LIMIT 1);\n",
+ "\n",
+ " IF (first_row IS NOT NULL)\n",
+ " THEN\n",
+ "\n",
+ " IF startswith(first_row, 'Id,')\n",
+ " THEN\n",
+ " -- First line of file starts with Id column\n",
+ " -- Record this in result_arr\n",
+ " SET result_arr = array_append(result_arr, filelist.file_name || ' header: \\n' || first_row);\n",
+ "\n",
+ " -- Create view for ease of data exploration\n",
+ " SET view_name = 'dbdemos_' || rtrim('.csv', filelist.file_name);\n",
+ "\n",
+ " -- Note: Any temp view is limited to current scope\n",
+ " -- Below EXECUTE will create persistent view in the CURRENT SCHEMA\n",
+ " SET sqlstr = 'CREATE VIEW ' || view_name ||\n",
+ " ' AS SELECT * FROM read_files(\\'' || cloud_loc || '/' || filelist.file_name || '\\')';\n",
+ " EXECUTE IMMEDIATE sqlstr;\n",
+ " ELSE\n",
+ " SET result_arr = array_append(result_arr, filelist.file_name || ': ' || 'Header not present');\n",
+ " END IF;\n",
+ " \n",
+ " ELSE\n",
+ " -- file empty\n",
+ " SET result_arr = array_append(result_arr, filelist.file_name || ': ' || 'File empty');\n",
+ " END IF;\n",
+ "\n",
+ " END FOR lbl_for_loop;\n",
+ "\n",
+ " -- Show results for csv file header\n",
+ " SELECT explode(result_arr) AS result;\n",
+ " END;"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "implicitDf": true,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "5e0f7fd3-8e38-49c7-a639-5fc60dacef9e",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "-- Browse data from the 3 views created in the script\n",
+ "SELECT * FROM dbdemos_patients50_init;\n",
+ "SELECT * FROM dbdemos_patients_incr1;\n",
+ "SELECT * FROM dbdemos_patients_incr2;"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "implicitDf": true,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "1cb26645-174c-459b-b339-4a7a5993f60c",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "-- Drop the 3 views created in the script\n",
+ "DROP VIEW IF EXISTS dbdemos_patients50_init;\n",
+ "DROP VIEW IF EXISTS dbdemos_patients_incr1;\n",
+ "DROP VIEW IF EXISTS dbdemos_patients_incr2;"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "fbe6a73e-79ad-4d5e-bfac-a37fae867edb",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "**Attach a SQL Warehouse and execute this notebook to see the code in action!**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "8041e5c9-00ad-46e8-9c7f-d53d0cacd9a1",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "source": [
+ "## Navigate to Patient Dimension demo\n",
+ "Start With: [Patient Dimension ETL Introduction]($./01-patient-dimension-ETL-introduction)."
+ ]
+ }
+ ],
+ "metadata": {
+ "application/vnd.databricks.v1+notebook": {
+ "computePreferences": null,
+ "dashboards": [],
+ "environmentMetadata": {
+ "base_environment": "",
+ "environment_version": "2"
+ },
+ "inputWidgetPreferences": null,
+ "language": "sql",
+ "notebookMetadata": {
+ "mostRecentlyExecutedCommandWithImplicitDF": {
+ "commandId": -1,
+ "dataframes": [
+ "_sqldf"
+ ]
+ },
+ "pythonIndentUnit": 2
+ },
+ "notebookName": "sql-centric-capabilities-examples",
+ "widgets": {}
+ },
+ "language_info": {
+ "name": "sql"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}