diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Exploratory-Analysis-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Exploratory-Analysis-credit-decisioning.py
new file mode 100644
index 00000000..e6b0c6c7
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Exploratory-Analysis-credit-decisioning.py
@@ -0,0 +1,107 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC # Exploratory Analysis
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC Data exploration is a critical first step in building a Responsible AI solution, as it helps ensure transparency, fairness, and reliability from the outset. In this notebook, we will explore and analyze our dataset on the Databricks Data Intelligence Platform. This process lays the foundation for responsible feature engineering and model development. Human validation remains an essential part of this step, ensuring that data-driven insights align with domain knowledge and ethical considerations.
+# MAGIC
+# MAGIC By leveraging Databricks’ unified data and AI capabilities, we can conduct secure and scalable exploratory data analysis (EDA), assess data distributions, and validate class representation before moving forward with model development.
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Security and Table Access Controls
+# MAGIC
+# MAGIC Before proceeding with data exploration, it is crucial to implement security and access controls to ensure data integrity and compliance. Proper security measures help:
+# MAGIC
+# MAGIC - Protect sensitive financial and customer data, preventing unauthorized access and ensuring regulatory adherence.
+# MAGIC - Ensure data consistency, so analysts work with validated and high-quality data without discrepancies.
+# MAGIC - Avoid data leakage risks, preventing the unintentional exposure of confidential information that could lead to compliance violations.
+# MAGIC - Facilitate accountability, ensuring that any modifications or transformations are logged and traceable.
+# MAGIC
+# MAGIC By establishing a secure data foundation, we ensure that subsequent analysis and modeling steps are performed responsibly, with complete confidence in data integrity and compliance.
+# MAGIC
+# MAGIC Table Access Control (TAC) in Databricks lets administrators manage access to specific tables and columns, controlling permissions like read, write, or modify. Integrated with Unity Catalog, it allows fine-grained security to protect sensitive data and ensure only authorized users have access. This feature enhances data governance, compliance, and secure collaboration across the platform.
+# MAGIC
+# MAGIC Now, let's grant only a ```SELECT``` access to ```customer_gold``` table to everyone in the group ```Data Scientist```.
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC
+# MAGIC GRANT SELECT ON TABLE customer_gold TO `Data Scientist`
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Exploratory Data Analysis
+# MAGIC
+# MAGIC The first step as Data Scientist is to explore and understand the data. [Databricks Notebooks](https://docs.databricks.com/en/notebooks/index.html) offer native data quality profiling and dashboarding capabilities that allow users to easily assess and visualize the quality of their data. Built-in tools allows us to:
+# MAGIC - Identify missing values and potential data quality issues.
+# MAGIC - Detect outliers and anomalies that may skew model predictions.
+# MAGIC - Assess statistical distributions of key features to uncover potential biases.
+# MAGIC
+# MAGIC Databricks enables scalable EDA through interactive notebooks, where we can visualize distributions, perform statistical tests, and generate summary reports seamlessly.
+
+# COMMAND ----------
+
+# DBTITLE 1,Use SQL to explore your data
+# MAGIC %sql
+# MAGIC SELECT * FROM customer_gold
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC While Databricks provides built-in data profiling tools, additional Python libraries such as Plotly and Seaborn can be used to enhance analysis. These libraries allow for more interactive and customizable visualizations, helping uncover hidden patterns in the data.
+# MAGIC
+# MAGIC Using these additional libraries in combination with Databricks' built-in capabilities ensures a more comprehensive data exploration process, leading to better insights for responsible model development.
+
+# COMMAND ----------
+
+# DBTITLE 1,Use any of your usual python libraries for analysis
+data = spark.table("customer_gold") \
+ .where("tenure_months BETWEEN 10 AND 150") \
+ .groupBy("tenure_months", "education").sum("income_monthly") \
+ .orderBy('education').toPandas()
+
+px.bar(data, x="tenure_months", y="sum(income_monthly)", color="education", title="Total Monthly Income")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Class representation
+# MAGIC
+# MAGIC Understanding class representation during exploratory data analysis is crucial for identifying potential bias in data. Imbalanced classes can lead to biased models, where underrepresented classes are poorly learned, resulting in inaccurate predictions. If certain groups are over- or underrepresented, the model may inherit societal biases, leading to unfair outcomes. Identifying skewed distributions helps in selecting appropriate resampling techniques or adjusting model evaluation metrics. Moreover, biased training data can reinforce discrimination in applications like credit decisioning. Detecting imbalance early allows for corrective actions, ensuring a more robust, fair, and generalizable model that performs well across all classes.
+
+# COMMAND ----------
+
+data = spark.table("customer_gold") \
+ .groupBy("gender").count() \
+ .orderBy('gender').toPandas()
+
+px.pie(data_frame=data, names="gender", values="count", color="gender", title="Percentage of Males vs. Females")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC After completing exploratory analysis, we proceed to [06.2-Feature-Updates]($./06-Responsible-AI/06.2-Feature-Updates), where we:
+# MAGIC - Continuously ingest new data to keep features relevant and up to date.
+# MAGIC - Apply responsible transformations while maintaining full lineage and compliance.
+# MAGIC - Log feature changes to ensure transparency in model evolution.
+# MAGIC
+# MAGIC By systematically updating features, we reinforce responsible AI practices and enhance our credit scoring model’s fairness, reliability, and effectiveness.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py
deleted file mode 100644
index d267e52e..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py
+++ /dev/null
@@ -1,180 +0,0 @@
-# Databricks notebook source
-# MAGIC %md
-# MAGIC
-# MAGIC # ML: predict credit owners with high default probability
-# MAGIC
-# MAGIC Once all data is loaded and secured (the **data unification** part), we can proceed to exploring, understanding, and using the data to create actionable insights - **data decisioning**.
-# MAGIC
-# MAGIC
-# MAGIC As outlined in the [introductory notebook]($../00-Credit-Decisioning), we will build machine learning (ML) models for driving three business outcomes:
-# MAGIC 1. Identify currently underbanked customers with high credit worthiness so we can offer them credit instruments,
-# MAGIC 2. Predict current credit owners with high probability of defaulting along with the loss-given default, and
-# MAGIC 3. Offer instantaneous micro-loans (Buy Now, Pay Later) when a customer does not have the required credit limit or account balance to complete a transaction.
-# MAGIC
-# MAGIC Here is the flow we'll implement:
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## The need for Enhanced Collaboration
-# MAGIC
-# MAGIC Feature Engineering is an iterative process - we need to quickly generate new features, test the model, and go back to feature selection and more feature engineering - many many times. The Databricks Lakehouse enables data teams to collaborate extremely effectively through the following Databricks Notebook features:
-# MAGIC 1. Sharing and collaborating in the same Notebook by any team member (with different access modes),
-# MAGIC 2. Ability to use python, SQL, and R simultaneously in the same Notebook on the same data,
-# MAGIC 3. Native integration with a Git repository (including AWS Code Commit, Azure DevOps, GitLabs, Github, and others), making the Notebooks tools for CI/CD,
-# MAGIC 4. Variables explorer,
-# MAGIC 5. Automatic Data Profiling (in the cell below), and
-# MAGIC 6. GUI-based dashboards (in the cell below) that can also be added to any Databricks SQL Dashboard.
-# MAGIC
-# MAGIC These features enable teams within FSI organizations to become extremely fast and efficient in building the best ML model at reduced time, thereby making the most out of market opportunities such as the raising interest rates.
-
-# COMMAND ----------
-
-# MAGIC %pip install databricks-sdk==0.36.0 mlflow==2.19.0 databricks-feature-store==0.17.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Data exploration & Features creation
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC The first step as Data Scientist is to explore our data and understand it to create Features.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC This where we use our existing tables and transform the data to be ready for our ML models. These features will later be stored in Databricks Feature Store (see below) and used to train the aforementioned ML models.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Let's start with some data exploration. Databricks comes with built-in Data Profiling to help you bootstrap that.
-
-# COMMAND ----------
-
-# DBTITLE 1,Use SQL to explore your data
-# MAGIC %sql
-# MAGIC SELECT * FROM customer_gold WHERE tenure_months BETWEEN 10 AND 150
-
-# COMMAND ----------
-
-# DBTITLE 1,Our any of your usual python libraries for analysis
-data = spark.table("customer_gold") \
- .where("tenure_months BETWEEN 10 AND 150") \
- .groupBy("tenure_months", "education").sum("income_monthly") \
- .orderBy('education').toPandas()
-
-px.bar(data, x="tenure_months", y="sum(income_monthly)", color="education", title="Wide-Form Input")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC # Building our Features for Credit Default risks
-# MAGIC
-# MAGIC To build our model predicting credit default risks, we'll need a buch of features. To improve our governance and centralize our data for multiple ML project, we can save our ML features using a Feature Store.
-
-# COMMAND ----------
-
-# DBTITLE 1,Read the customer table
-customer_gold_features = (spark.table("customer_gold")
- .withColumn('age', int(date.today().year) - col('birth_year'))
- .select('cust_id', 'education', 'marital_status', 'months_current_address', 'months_employment', 'is_resident',
- 'tenure_months', 'product_cnt', 'tot_rel_bal', 'revenue_tot', 'revenue_12m', 'income_annual', 'tot_assets',
- 'overdraft_balance_amount', 'overdraft_number', 'total_deposits_number', 'total_deposits_amount', 'total_equity_amount',
- 'total_UT', 'customer_revenue', 'age', 'avg_balance', 'num_accs', 'balance_usd', 'available_balance_usd')).dropDuplicates(['cust_id'])
-display(customer_gold_features)
-
-# COMMAND ----------
-
-# DBTITLE 1,Read the telco table
-telco_gold_features = (spark.table("telco_gold")
- .select('cust_id', 'is_pre_paid', 'number_payment_delays_last12mo', 'pct_increase_annual_number_of_delays_last_3_year', 'phone_bill_amt', \
- 'avg_phone_bill_amt_lst12mo')).dropDuplicates(['cust_id'])
-display(telco_gold_features)
-
-# COMMAND ----------
-
-# DBTITLE 1,Adding some additional features on transactional trends
-fund_trans_gold_features = spark.table("fund_trans_gold").dropDuplicates(['cust_id'])
-
-for c in ['12m', '6m', '3m']:
- fund_trans_gold_features = fund_trans_gold_features.withColumn('tot_txn_cnt_'+c, col('sent_txn_cnt_'+c)+col('rcvd_txn_cnt_'+c))\
- .withColumn('tot_txn_amt_'+c, col('sent_txn_amt_'+c)+col('rcvd_txn_amt_'+c))
-
-fund_trans_gold_features = fund_trans_gold_features.withColumn('ratio_txn_amt_3m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_3m')/col('tot_txn_amt_12m')))\
- .withColumn('ratio_txn_amt_6m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_6m')/col('tot_txn_amt_12m')))\
- .na.fill(0)
-display(fund_trans_gold_features)
-
-# COMMAND ----------
-
-# DBTITLE 1,Consolidating all the features
-feature_df = customer_gold_features.join(telco_gold_features.alias('telco'), "cust_id", how="left")
-feature_df = feature_df.join(fund_trans_gold_features, "cust_id", how="left")
-display(feature_df)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Databricks Feature Store
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Once our features are ready, we'll save them in Databricks Feature Store.
-# MAGIC
-# MAGIC Under the hood, feature store are backed by a Delta Lake table. This will allow discoverability and reusability of our feature across our organization, increasing team efficiency.
-# MAGIC
-# MAGIC
-# MAGIC Databricks Feature Store brings advanced capabilities to accelerate and simplify your ML journey, such as point in time support and online-store, fetching your features within ms for real time Serving.
-# MAGIC
-# MAGIC ### Why use Databricks Feature Store?
-# MAGIC
-# MAGIC Databricks Feature Store is fully integrated with other components of Databricks.
-# MAGIC
-# MAGIC * **Discoverability**. The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
-# MAGIC
-# MAGIC * **Lineage**. When you create a feature table with Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs, and endpoints that use the feature.
-# MAGIC
-# MAGIC * **Batch and Online feature lookup for real time serving**. When you use features from Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
-# MAGIC
-# MAGIC * **Point-in-time lookups**. Feature Store supports time series and event-based use cases that require point-in-time correctness.
-# MAGIC
-# MAGIC
-# MAGIC For more details about Databricks Feature Store, run `dbdemos.install('feature-store')`
-
-# COMMAND ----------
-
-from databricks import feature_store
-fs = feature_store.FeatureStoreClient()
-
-# Drop the fs table if it was already existing to cleanup the demo state
-drop_fs_table(f"{catalog}.{db}.credit_decisioning_features")
-
-fs.create_table(
- name=f"{catalog}.{db}.credit_decisioning_features",
- primary_keys=["cust_id"],
- df=feature_df,
- description="Features for Credit Decisioning.")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Next steps
-# MAGIC
-# MAGIC After creating our features and storing them in the Databricks Feature Store, we can now proceed to the [03.2-AutoML-credit-decisioning]($./03.2-AutoML-credit-decisioning) and build out credit decisioning model.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py
deleted file mode 100644
index 5f8cf299..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py
+++ /dev/null
@@ -1,257 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Data Science on the Databricks Lakehouse
-# MAGIC
-# MAGIC ## ML is key to disruption & personalization
-# MAGIC
-# MAGIC Being able to ingest and query our credit-related database is a first step, but this isn't enough to thrive in a very competitive market.
-# MAGIC
-# MAGIC Customers now expect real time personalization and new form of comunication. Modern data company achieve this with AI.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
90%
-# MAGIC
-# MAGIC Enterprise applications will be AI-augmented by 2025 — IDC
-# MAGIC
-# MAGIC
$10T+
-# MAGIC
-# MAGIC Projected business value creation by AI in 2030 — PwC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC But a huge challenge is getting ML to work at scale!
-# MAGIC Most ML projects still fail before getting to production.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## So what makes machine learning and data science difficult?
-# MAGIC
-# MAGIC These are the top challenges we have observed companies struggle with:
-# MAGIC 1. Inability to ingest the required data in a timely manner,
-# MAGIC 2. Inability to properly control the access of the data,
-# MAGIC 3. Inability to trace problems in the feature store to the raw data,
-# MAGIC
-# MAGIC ... and many other data-related problems.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC # Data-centric Machine Learning
-# MAGIC
-# MAGIC In Databricks, machine learning is not a separate product or service that needs to be "connected" to the data. The Lakehouse being a single, unified product, machine learning in Databricks "sits" on top of the data, so challenges like inability to discover and access data no longer exist.
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %pip install databricks-sdk==0.36.0 mlflow==2.19.0 databricks-feature-store==0.17.0 scikit-learn==1.3.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Credit Scoring default prediction
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC ## Single click deployment with AutoML
-# MAGIC
-# MAGIC
-# MAGIC Let's see how we can now leverage the credit decisioning data to build a model predicting and explaining customer creditworthiness.
-# MAGIC
-# MAGIC We'll start by retrieving our data from the feature store and creating our training dataset.
-# MAGIC
-# MAGIC We'll then use Databricks AutoML to automatically build our model.
-
-# COMMAND ----------
-
-# DBTITLE 1,Loading the training dataset from the Databricks Feature Store
-from databricks import feature_store
-fs = feature_store.FeatureStoreClient()
-features_set = fs.read_table(name=f"{catalog}.{db}.credit_decisioning_features")
-display(features_set)
-
-# COMMAND ----------
-
-# DBTITLE 1,Creating the label: "defaulted"
-credit_bureau_label = (spark.table("credit_bureau_gold")
- .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE") > 60, 1)
- .otherwise(0))
- .select("cust_id", "defaulted"))
-#As you can see, we have a fairly imbalanced dataset
-df = credit_bureau_label.groupBy('defaulted').count().toPandas()
-px.pie(df, values='count', names='defaulted', title='Credit default ratio')
-
-# COMMAND ----------
-
-# DBTITLE 1,Build our training dataset (join features and label)
-training_dataset = credit_bureau_label.join(features_set, "cust_id", "inner")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Balancing our dataset
-# MAGIC
-# MAGIC Let's downsample and upsample our dataset to improve our model performance
-
-# COMMAND ----------
-
-major_df = training_dataset.filter(col("defaulted") == 0)
-minor_df = training_dataset.filter(col("defaulted") == 1)
-
-# duplicate the minority rows
-oversampled_df = minor_df.union(minor_df)
-
-# downsample majority rows
-undersampled_df = major_df.sample(oversampled_df.count()/major_df.count()*3, 42)
-
-# combine both oversampled minority rows and undersampled majority rows, this will improve our balance while preseving enough information.
-train_df = undersampled_df.unionAll(oversampled_df).drop('cust_id').na.fill(0)
-# Save it as a table to be able to select it with the AutoML UI.
-train_df.write.mode('overwrite').saveAsTable('credit_risk_train_df')
-px.pie(train_df.groupBy('defaulted').count().toPandas(), values='count', names='defaulted', title='Credit default ratio')
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Accelerating credit scoring model creation using MLFlow and Databricks AutoML
-# MAGIC
-# MAGIC MLFlow is an open source project allowing model tracking, packaging and deployment. Every time your Data Science team works on a model, Databricks will track all parameters and data used and will auto-log them. This ensures ML traceability and reproductibility, making it easy to know what parameters/data were used to build each model and model version.
-# MAGIC
-# MAGIC ### A glass-box solution that empowers data teams without taking control away
-# MAGIC
-# MAGIC While Databricks simplifies model deployment and governance (MLOps) with MLFlow, bootstraping new ML projects can still be a long and inefficient process.
-# MAGIC
-# MAGIC Instead of creating the same boilerplate for each new project, Databricks AutoML can automatically generate state of the art models for Classifications, Regression, and Forecasting.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Models can be directly deployed, or instead leverage generated notebooks to boostrap projects with best-practices, saving you weeks worth of effort.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC ### Using Databricks Auto ML with our Credit Scoring dataset
-# MAGIC
-# MAGIC AutoML is available in the "Machine Learning" space. All we have to do is start a new AutoML Experiments and select the feature table we just created (`creditdecisioning_features`)
-# MAGIC
-# MAGIC Our prediction target is the `defaulted` column.
-# MAGIC
-# MAGIC Click on Start, and Databricks will do the rest.
-# MAGIC
-# MAGIC While this is done using the UI, you can also leverage the [python API](https://docs.databricks.com/applications/machine-learning/automl.html#automl-python-api-1)
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-xp_path = "/Shared/dbdemos/experiments/lakehouse-fsi-credit-decisioning"
-xp_name = f"automl_credit_{datetime.now().strftime('%Y-%m-%d_%H:%M:%S')}"
-try:
- from databricks import automl
- automl_run = automl.classify(
- experiment_name = xp_name,
- experiment_dir = xp_path,
- dataset = train_df.sample(0.1),
- target_col = "defaulted",
- timeout_minutes = 10
- )
- #Make sure all users can access dbdemos shared experiment
- DBDemos.set_experiment_permission(f"{xp_path}/{xp_name}")
-except Exception as e:
- if "cannot import name 'automl'" in str(e):
- # Note: cannot import name 'automl' from 'databricks' likely means you're using serverless. Dbdemos doesn't support autoML serverless API - this will be improved soon.
- # Adding a temporary workaround to make sure it works well for now - ignore this for classic run
- automl_run = DBDemos.create_mockup_automl_run(f"{xp_path}/{xp_name}", train_df.sample(0.1).toPandas(), model_name=model_name, target_col="defaulted")
- else:
- raise e
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Deploying our model in production
-# MAGIC
-# MAGIC Our model is now ready. We can review the notebook generated by the auto-ml run and customize if if required.
-# MAGIC
-# MAGIC For this demo, we'll consider that our model is ready and deploy it in production in our Model Registry:
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-from mlflow import MlflowClient
-import mlflow
-
-#Use Databricks Unity Catalog to save our model
-mlflow.set_registry_uri('databricks-uc')
-client = MlflowClient()
-
-#Add model within our catalog
-latest_model = mlflow.register_model(f'runs:/{automl_run.best_trial.mlflow_run_id}/model', f"{catalog}.{db}.{model_name}")
-# Flag it as Production ready using UC Aliases
-client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="prod", version=latest_model.version)
-#DBDemos.set_model_permission(f"{catalog}.{db}.{model_name}", "ALL_PRIVILEGES", "account users")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC We just moved our automl model as production ready!
-# MAGIC
-# MAGIC Open [the dbdemos_fsi_credit_decisioning model](#mlflow/models/dbdemos_fsi_credit_decisioning) to explore its artifact and analyze the parameters used, including traceability to the notebook used for its creation.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Our model predicting default risks is now deployed in production
-# MAGIC
-# MAGIC
-# MAGIC So far we have:
-# MAGIC * ingested all required data in a single source of truth,
-# MAGIC * properly secured all data (including granting granular access controls, masked PII data, applied column level filtering),
-# MAGIC * enhanced that data through feature engineering,
-# MAGIC * used MLFlow AutoML to track experiments and build a machine learning model,
-# MAGIC * registered the model.
-# MAGIC
-# MAGIC ### Next steps
-# MAGIC We're now ready to use our model use it for:
-# MAGIC
-# MAGIC - Batch inferences in notebook [03.3-Batch-Scoring-credit-decisioning]($./03.3-Batch-Scoring-credit-decisioning) to start using it for identifying currently underbanked customers with good credit-worthiness (**increase the revenue**) and predict current credit-owners who might default so we can prevent such defaults from happening (**manage risk**),
-# MAGIC - Real time inference with [03.4-model-serving-BNPL-credit-decisioning]($./03.4-model-serving-BNPL-credit-decisioning) to enable ```Buy Now, Pay Later``` capabilities within the bank.
-# MAGIC
-# MAGIC Extra: review model explainability & fairness with [03.5-Explainability-and-Fairness-credit-decisioning]($./03.5-Explainability-and-Fairness-credit-decisioning)
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py
new file mode 100644
index 00000000..0e8da74c
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py
@@ -0,0 +1,171 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Feature Updates
+# MAGIC
+# MAGIC In responsible credit scoring, ensuring that machine learning models operate on high-quality and up-to-date data is essential. Continuous feature updates play a crucial role in maintaining model accuracy, fairness, and regulatory compliance. By centralizing feature management, we can improve governance, enforce lineage tracking, and ensure consistency across multiple ML projects.
+# MAGIC
+# MAGIC This notebook focuses on the ingestion, transformation, and tracking of features within the Databricks Feature Store. We ensure that every update is logged for traceability and that feature engineering practices align with Responsible AI principles. With transparent feature updates, we enhance the model’s effectiveness while meeting compliance standards.
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC # Building our Features for Credit Default risks
+# MAGIC
+# MAGIC To build our model predicting credit default risks, we need a comprehensive set of features that capture various aspects of customer behavior, financial activity, and risk indicators. Our primary data sources include:
+# MAGIC
+# MAGIC - `customer_gold`: Contains aggregated customer demographic, behavioral, and credit history attributes.
+# MAGIC - `telco_gold`: Includes telecommunications data, such as call patterns and payment behaviors.
+# MAGIC - `fund_trans_gold`: Provides insights into customer fund movements, transaction behaviors, and cash flow trends.
+# MAGIC
+# MAGIC To improve governance and centralize feature management for multiple machine learning projects, we leverage the Databricks Feature Store.
+
+# COMMAND ----------
+
+# DBTITLE 1,Read the customer table
+customer_gold_features = (spark.table("customer_gold")
+ .withColumn('age', int(date.today().year) - col('birth_year'))
+ .select('cust_id', 'education', 'marital_status', 'months_current_address', 'months_employment', 'is_resident',
+ 'tenure_months', 'product_cnt', 'tot_rel_bal', 'revenue_tot', 'revenue_12m', 'income_annual', 'tot_assets',
+ 'overdraft_balance_amount', 'overdraft_number', 'total_deposits_number', 'total_deposits_amount', 'total_equity_amount',
+ 'total_UT', 'customer_revenue', 'age', 'gender', 'avg_balance', 'num_accs', 'balance_usd', 'available_balance_usd')).dropDuplicates(['cust_id'])
+display(customer_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Read the telco table
+telco_gold_features = (spark.table("telco_gold")
+ .select('cust_id', 'is_pre_paid', 'number_payment_delays_last12mo', 'pct_increase_annual_number_of_delays_last_3_year', 'phone_bill_amt', \
+ 'avg_phone_bill_amt_lst12mo')).dropDuplicates(['cust_id'])
+display(telco_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Adding some additional features on transactional trends
+fund_trans_gold_features = spark.table("fund_trans_gold").dropDuplicates(['cust_id'])
+
+for c in ['12m', '6m', '3m']:
+ fund_trans_gold_features = fund_trans_gold_features.withColumn('tot_txn_cnt_'+c, col('sent_txn_cnt_'+c)+col('rcvd_txn_cnt_'+c))\
+ .withColumn('tot_txn_amt_'+c, col('sent_txn_amt_'+c)+col('rcvd_txn_amt_'+c))
+
+fund_trans_gold_features = fund_trans_gold_features.withColumn('ratio_txn_amt_3m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_3m')/col('tot_txn_amt_12m')))\
+ .withColumn('ratio_txn_amt_6m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_6m')/col('tot_txn_amt_12m')))\
+ .na.fill(0)
+display(fund_trans_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Consolidating all the features
+feature_df = customer_gold_features.join(telco_gold_features.alias('telco'), "cust_id", how="left")
+feature_df = feature_df.join(fund_trans_gold_features, "cust_id", how="left")
+display(feature_df)
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Databricks Feature Store
+# MAGIC
+# MAGIC Once our features are ready, we'll save them in Databricks Feature Store.
+# MAGIC
+# MAGIC Under the hood, feature store are backed by a Delta Lake table. This will allow discoverability and reusability of our feature across our organization, increasing team efficiency.
+# MAGIC
+# MAGIC
+# MAGIC Databricks Feature Store brings advanced capabilities to accelerate and simplify your ML journey, such as point in time support and online-store, fetching your features within ms for real time Serving.
+# MAGIC
+# MAGIC ### Why use Databricks Feature Store?
+# MAGIC
+# MAGIC Databricks Feature Store is fully integrated with other components of Databricks.
+# MAGIC
+# MAGIC * **Discoverability**. The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
+# MAGIC
+# MAGIC * **Lineage**. When you create a feature table with Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs, and endpoints that use the feature.
+# MAGIC
+# MAGIC * **Batch and Online feature lookup for real time serving**. When you use features from Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
+# MAGIC
+# MAGIC * **Point-in-time lookups**. Feature Store supports time series and event-based use cases that require point-in-time correctness.
+# MAGIC
+# MAGIC
+# MAGIC For more details about Databricks Feature Store, run `dbdemos.install('feature-store')`
+
+# COMMAND ----------
+
+from databricks.feature_engineering import FeatureEngineeringClient
+
+fe = FeatureEngineeringClient()
+
+# Drop the fs table if it was already existing to cleanup the demo state
+try:
+ fe.drop_table(name=f"{catalog}.{db}.credit_decisioning_features")
+ print("Dropped existing feature table.")
+except:
+ print("Feature table does not exist. Creating a new feature table.")
+
+# Create feature table with `cust_id` as the primary key.
+fe.create_table(
+ name=f"{catalog}.{db}.credit_decisioning_features",
+ primary_keys="cust_id",
+ schema=feature_df.schema,
+ description="Features for Credit Decisioning.")
+
+fe.write_table(
+ name=f"{catalog}.{db}.credit_decisioning_features",
+ df = feature_df,
+ mode = 'merge'
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Transparency
+# MAGIC
+# MAGIC Databricks Unity Catalog's **automated data lineage** feature tracks and visualizes data flow from ingestion to consumption. It ensures transparency in feature engineering for machine learning by capturing transformations, dependencies, and usage across notebooks, workflows, and dashboards. This enhances reproducibility, debugging, compliance, and model accuracy.
+# MAGIC
+# MAGIC Accessing lineage via [system tables](https://docs.databricks.com/en/admin/system-tables/lineage.html) allows users to query lineage metadata, track data dependencies, and analyze usage patterns. This structured approach aids auditing, debugging, and optimizing workflows, ensuring data quality across analytics and ML pipelines.
+# MAGIC
+# MAGIC Next, we'll import lineage data for the feature tables created in this Notebook.
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC
+# MAGIC select * from system.access.table_lineage
+# MAGIC where target_table_catalog=current_catalog()
+# MAGIC and target_table_schema=current_schema()
+# MAGIC and target_table_name = 'credit_decisioning_features';
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Documentation of the data
+# MAGIC
+# MAGIC In Databricks, the AI-generated column and table description feature leverages machine learning models to automatically analyze and generate meaningful metadata descriptions for tables and columns within a dataset. This functionality improves data discovery and understanding by providing natural language descriptions, helping users quickly interpret data without needing to manually write documentation. The AI can identify patterns, data types, and relationships between columns, offering suggestions that can enhance data governance, streamline collaboration, and make datasets more accessible, especially for those unfamiliar with the underlying schema. This feature is part of Databricks' broader effort to simplify data exploration and enhance productivity within its unified data analytics platform.
+
+# COMMAND ----------
+
+table_name = "credit_decisioning_features"
+
+table_description = spark.sql(f"DESCRIBE TABLE EXTENDED {table_name}").filter("col_name = 'Comment'").select("data_type").collect()[0][0]
+
+column_descriptions = spark.sql(f"DESCRIBE TABLE EXTENDED {table_name}").filter("col_name != ''").select("col_name", "comment").collect()
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With our feature set prepared and stored, the next step is model training. In the [06.3-Model-Training]($./06-Responsible-AI/06.3-Model-Training) notebook, we will:
+# MAGIC - Train multiple candidate models using the engineered features.
+# MAGIC - Evaluate models based on fairness, accuracy, and stability metrics.
+# MAGIC - Log model artifacts, ensuring full reproducibility.
+# MAGIC
+# MAGIC By maintaining transparency and governance throughout feature updates and model training, we lay the foundation for responsible credit decisioning and robust AI deployment.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py
deleted file mode 100644
index af64954b..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py
+++ /dev/null
@@ -1,85 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC # Use the best AutoML generated model to batch score credit worthiness
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Databricks AutoML runs experiments across a grid and creates many models and metrics to determine the best models among all trials. This is a glass-box approach to create a baseline model, meaning we have all the code artifacts and experiments available afterwards.
-# MAGIC
-# MAGIC Here, we selected the Notebook from the best run from the AutoML experiment.
-# MAGIC
-# MAGIC All the code below has been automatically generated. As data scientists, we can tune it based on our business knowledge, or use the generated model as-is.
-# MAGIC
-# MAGIC This saves data scientists hours of developement and allows team to quickly bootstrap and validate new projects, especally when we may not know the predictors for alternative data such as the telco payment data.
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %pip install mlflow==2.19.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Running batch inference to score our existing database
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Now that our model was created and deployed in production within the MLFlow registry.
-# MAGIC
-# MAGIC
-# MAGIC We can now easily load it calling the `Production` stage, and use it in any Data Engineering pipeline (a job running every night, in streaming or even within a Delta Live Table pipeline).
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC We'll then save this information as a new table without our FS database, and start building dashboards and alerts on top of it to run live analysis.
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-import mlflow
-mlflow.set_registry_uri('databricks-uc')
-
-# Load model as a Spark UDF.
-loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=f"models:/{catalog}.{db}.{model_name}@prod", result_type='double')
-
-# COMMAND ----------
-
-features = loaded_model.metadata.get_input_schema().input_names()
-
-underbanked_df = spark.table("credit_decisioning_features").fillna(0) \
- .withColumn("prediction", loaded_model(F.struct(*features))).cache()
-
-display(underbanked_df)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC In the scored data frame above, we have essentially created an end-to-end process to predict credit worthiness for any customer, regardless of whether the customer has an existing bank account. We have a binary prediction which captures this and incorporates all the intellience from Databricks AutoML and curated features from our feature store.
-
-# COMMAND ----------
-
-underbanked_df.write.mode("overwrite").saveAsTable(f"underbanked_prediction")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ### Next steps
-# MAGIC
-# MAGIC * Deploy your model for real time inference with [03.4-model-serving-BNPL-credit-decisioning]($./03.4-model-serving-BNPL-credit-decisioning) to enable ```Buy Now, Pay Later``` capabilities within the bank.
-# MAGIC
-# MAGIC Or
-# MAGIC
-# MAGIC * Making sure your model is fair towards customers of any demographics are extremely important parts of building production-ready ML models for FSI use cases.
-# MAGIC Explore your model with [03.5-Explainability-and-Fairness-credit-decisioning]($./03.5-Explainability-and-Fairness-credit-decisioning) on the Lakehouse.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Model-Training-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Model-Training-credit-decisioning.py
new file mode 100644
index 00000000..eca100ee
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Model-Training-credit-decisioning.py
@@ -0,0 +1,191 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Model Training
+# MAGIC
+# MAGIC In Databricks, machine learning is not a separate product or service that needs to be "connected" to the data. The Lakehouse being a single, unified product, machine learning in Databricks "sits" on top of the data, so challenges like inability to discover and access data no longer exist.
+# MAGIC
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Building a Responsible Credit Scoring Model
+# MAGIC
+# MAGIC With our credit decisioning data prepared, we can now leverage it to build a predictive model assessing customer creditworthiness. Our approach will emphasize transparency, fairness, and governance at every step.
+# MAGIC
+# MAGIC Steps in Model Training:
+# MAGIC - **Retrieve Data from the Feature Store:** We begin by accessing the curated and validated features stored in the Databricks Feature Store. This ensures consistency, traceability, and compliance with feature engineering best practices.
+# MAGIC - **Create the Training Dataset:** We assemble a well-balanced training dataset by selecting relevant features and handling missing or biased data points.
+# MAGIC - **Leverage Databricks AutoML:** To streamline model development, we use Databricks AutoML to automatically build and evaluate multiple models. This step ensures we select the most effective model while adhering to Responsible AI principles.
+
+# COMMAND ----------
+
+# DBTITLE 1,Loading the training dataset from the Databricks Feature Store
+from databricks.feature_engineering import FeatureEngineeringClient
+fe = FeatureEngineeringClient()
+
+features_set = fe.read_table(name=f"{catalog}.{db}.credit_decisioning_features")
+display(features_set)
+
+# COMMAND ----------
+
+# DBTITLE 1,Creating the label: "defaulted"
+credit_bureau_label = (spark.table("credit_bureau_gold")
+ .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE") > 60, 1)
+ .otherwise(0))
+ .select("cust_id", "defaulted"))
+#As you can see, we have a fairly imbalanced dataset
+df = credit_bureau_label.groupBy('defaulted').count().toPandas()
+px.pie(df, values='count', names='defaulted', title='Credit default ratio')
+
+# COMMAND ----------
+
+# DBTITLE 1,Build our training dataset (join features and label)
+training_dataset = credit_bureau_label.join(features_set, "cust_id", "inner")
+training_dataset.write.mode('overwrite').saveAsTable('credit_decisioning_features_labels')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Adressing the class imbalance of our dataset
+# MAGIC
+# MAGIC Let's downsample and upsample our dataset to improve our model performance
+
+# COMMAND ----------
+
+major_df = training_dataset.filter(col("defaulted") == 0)
+minor_df = training_dataset.filter(col("defaulted") == 1)
+
+# duplicate the minority rows
+oversampled_df = minor_df.union(minor_df)
+
+# downsample majority rows
+undersampled_df = major_df.sample(oversampled_df.count()/major_df.count()*3, 42)
+
+
+# COMMAND ----------
+
+# combine both oversampled minority rows and undersampled majority rows, this will improve our balance while preseving enough information.
+train_df = undersampled_df.unionAll(oversampled_df).drop('cust_id').na.fill(0)
+
+# COMMAND ----------
+
+# Save it as a table to be able to select it with the AutoML UI.
+train_df.write.mode('overwrite').saveAsTable('credit_risk_train_df')
+px.pie(train_df.groupBy('defaulted').count().toPandas(), values='count', names='defaulted', title='Credit default ratio')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Addressing Demographic or Ethical Bias
+# MAGIC
+# MAGIC When dealing with demographic or ethical bias—where disparities exist across sensitive attributes like gender, race, or age—standard class balancing techniques may be insufficient. Instead, more targeted strategies are used to promote fairness. Pre-processing methods like reweighing assign different instance weights to ensure equitable representation across groups. Techniques such as the disparate impact remover modify feature values to reduce bias while preserving predictive utility. In-processing approaches like adversarial debiasing involve training the main model alongside an adversary that attempts to predict the sensitive attribute, thereby encouraging the model to learn representations that are less biased. Additionally, fair sampling methods, such as Kamiran’s preferential sampling, selectively sample training data to correct for group imbalances. These approaches aim to improve fairness metrics like demographic parity or equal opportunity while maintaining model performance.
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Accelerating credit scoring model creation using MLFlow and Databricks AutoML
+# MAGIC
+# MAGIC MLFlow is an open source project allowing model tracking, packaging and deployment. Every time your Data Science team works on a model, Databricks will track all parameters and data used and will auto-log them. This ensures ML transparency, traceability, and reproducibility, making it easy to know what parameters/data were used to build each model and model version.
+# MAGIC
+# MAGIC ### A glass-box solution that empowers data teams without taking control away
+# MAGIC
+# MAGIC While Databricks simplifies model deployment and governance (MLOps) with MLFlow, bootstraping new ML projects can still be a long and inefficient process.
+# MAGIC
+# MAGIC Instead of creating the same boilerplate for each new project, Databricks AutoML can automatically generate state of the art models for Classifications, Regression, and Forecasting.
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC Models can be directly deployed, or instead leverage generated notebooks to boostrap projects with best-practices, saving you weeks worth of effort.
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC ### Using Databricks Auto ML with our Credit Scoring dataset
+# MAGIC
+# MAGIC AutoML is available in the "Machine Learning" space. All we have to do is start a new AutoML Experiments and select the feature table we just created (`creditdecisioning_features`)
+# MAGIC
+# MAGIC Our prediction target is the `defaulted` column.
+# MAGIC
+# MAGIC Click on Start, and Databricks will do the rest.
+# MAGIC
+# MAGIC While this is done using the UI, you can also leverage the [python API](https://docs.databricks.com/applications/machine-learning/automl.html#automl-python-api-1)
+
+# COMMAND ----------
+
+from databricks import automl
+xp_path = "/Shared/rai/experiments/credit-decisioning"
+xp_name = f"automl_rai_credit_{datetime.now().strftime('%Y-%m-%d_%H:%M:%S')}"
+automl_run = automl.classify(
+ experiment_name = xp_name,
+ experiment_dir = xp_path,
+ dataset = train_df.sample(0.1),
+ target_col = "defaulted",
+ timeout_minutes = 5
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Register our model in Unity Catalog
+# MAGIC
+# MAGIC Our model is now ready. We can review the notebook generated by the auto-ml run and customize if if required.
+# MAGIC
+# MAGIC For this demo, we'll consider that our model is ready to be registered in Unity Catalog:
+
+# COMMAND ----------
+
+import mlflow
+
+#Use Databricks Unity Catalog to save our model
+mlflow.set_registry_uri('databricks-uc')
+client = mlflow.MlflowClient()
+
+# Register the model to Unity Catalog
+try:
+ result = mlflow.register_model(model_uri=f"runs:/{automl_run.best_trial.mlflow_run_id}/model", name=f"{catalog}.{db}.{model_name}")
+ print(f"Model registered with version: {result.version}")
+except mlflow.exceptions.MlflowException as e:
+ print(f"Error registering model: {e}")
+
+# Flag it as Production ready using UC Aliases
+client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="None", version=result.version)
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Generate Model Documentation
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC Once we have trained the model, we generate comprehensive model documentation using [Databricks' solutions accelerator](https://www.databricks.com/solutions/accelerators/model-risk-management-with-ey). This step is critical for maintaining compliance, governance, and transparency in financial services.
+# MAGIC
+# MAGIC #### Benefits of Automated Model Documentation:
+# MAGIC
+# MAGIC - Streamlined Model Governance: Automatically generate structured documentation for both machine learning and non-machine learning models, ensuring regulatory alignment.
+# MAGIC - Integrated Data Visualization & Reporting: Provide insights into model performance with built-in dashboards and visual analytics.
+# MAGIC - Risk Identification for Banking Models: Help model validation teams detect and mitigate risks associated with incorrect or misused models in financial decisioning.
+# MAGIC - Foundations for Explainable AI: Enhance trust by making every stage of the model lifecycle transparent, accelerating model validation and deployment processes.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With our model trained and documented, the next step is validation. In the [06.4-Model-Validation]($./06-Responsible-AI/06.4-Model-Validation) notebook, we will conduct compliance checks, pre-deployment tests, and fairness evaluations. This ensures that our model meets regulatory requirements and maintains transparency before it is deployed into production.
+
+# COMMAND ----------
+
+
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py
new file mode 100644
index 00000000..033b784a
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py
@@ -0,0 +1,367 @@
+# Databricks notebook source
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Model Validation
+# MAGIC
+# MAGIC Model validation is a critical step in ensuring the compliance, fairness, and reliability of our credit scoring model before deployment. This notebook performs key compliance checks to align with Responsible AI principles. Specifically, we:
+# MAGIC
+# MAGIC - Validate model fairness for existing credit customers.
+# MAGIC - Analyze feature importance and model behavior using Shapley values.
+# MAGIC - Log custom metrics for auditing and transparency.
+# MAGIC - Ensure compliance with regulatory fairness constraints.
+# MAGIC
+# MAGIC In addition, we also implement the champion-challenger framework to ensure that only the most effective and responsible model is promoted to a higher enviroment. This approach allows us to:
+# MAGIC - Compare the current production model (champion model) with a newly trained model (challenger model).
+# MAGIC - Incorporate human oversight to validate the challenger model before deployment.
+# MAGIC - Maintain full traceability and accountability at each stage of model deployment.
+# MAGIC
+# MAGIC Model validation includes both the model compliance checks and champion-challenger testing. It is only after a model passes these two checks that it is allowed to progress to a high environment. To do so, we:
+# MAGIC - Register the validated model in Unity Catalog and transition it to the next stage.
+# MAGIC
+# MAGIC By following this structured validation approach, we ensure that model transitions are transparent, fair, and aligned with Responsible AI principles.
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %pip install --quiet shap==0.46.0
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Load Data
+# MAGIC
+# MAGIC To validate our model, we first load the necessary data from `credit_decisioning_features` and `credit_bureau_gold` tables. These datasets provide customer financial and credit bureau insights necessary for validation.
+
+# COMMAND ----------
+
+feature_df = spark.table("credit_decisioning_features")
+credit_bureau_label = spark.table("credit_bureau_gold")
+
+df = (feature_df.join(credit_bureau_label, "cust_id", how="left")
+ .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE").isNull(), 2)
+ .when(col("CREDIT_DAY_OVERDUE") > 60, 1)
+ .otherwise(0))
+ .drop('CREDIT_DAY_OVERDUE')
+ .fillna(0))
+display(df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Load model
+# MAGIC
+# MAGIC We retrieve our trained model from the Unity Catalog model registry
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+model = mlflow.pyfunc.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@none")
+features = model.metadata.get_input_schema().input_names()
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Ensuring model fairness for existing credit customers
+# MAGIC
+# MAGIC In this example, we'll make sure that our model behaves as expected and is fair for our existing customers.
+# MAGIC
+# MAGIC We'll select our existing customers not having credit and make sure that our model is fair and behave the same among different group of the population.
+
+# COMMAND ----------
+
+underbanked_df = df[df.defaulted==2].toPandas() # Features for underbanked customers
+banked_df = df[df.defaulted!=2].toPandas() # Features for our existing credit customers
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Feature importance using Shapley values
+# MAGIC
+# MAGIC SHAP is a game-theoretic approach to explain machine learning models, providing a summary plot
+# MAGIC of the relationship between features and model output. Features are ranked in descending order of
+# MAGIC importance, and impact/color describe the correlation between the feature and the target variable.
+# MAGIC - Generating SHAP feature importance is a very memory intensive operation.
+# MAGIC - To reduce the computational overhead of each trial, a single example is sampled from the underbanked set to explain.
+# MAGIC For more thorough results, increase the sample size of explanations, or provide your own examples to explain.
+# MAGIC - SHAP cannot explain models using data with nulls; if your dataset has any, both the background data and
+# MAGIC examples to explain will be imputed using the mode (most frequent values). This affects the computed
+# MAGIC SHAP values, as the imputed samples may not match the actual data distribution.
+# MAGIC
+# MAGIC For more information on how to read Shapley values, see the [SHAP documentation](https://shap.readthedocs.io/en/latest/example_notebooks/overviews/An%20introduction%20to%20explainable%20AI%20with%20Shapley%20values.html).
+
+# COMMAND ----------
+
+import shap
+
+mlflow.autolog(disable=True)
+mlflow.sklearn.autolog(disable=True)
+
+train_sample = banked_df[features].sample(n=np.minimum(100, banked_df.shape[0]), random_state=42)
+underbanked_sample = underbanked_df.sample(n=np.minimum(100, underbanked_df.shape[0]), random_state=42)
+
+# Use Kernel SHAP to explain feature importance on the sampled rows from the validation set.
+predict = lambda x: model.predict(pd.DataFrame(x, columns=features).astype(train_sample.dtypes.to_dict()))
+
+explainer = shap.KernelExplainer(predict, train_sample, link="identity")
+shap_values = explainer.shap_values(underbanked_sample[features], l1_reg=False, nsamples=100)
+
+# COMMAND ----------
+
+# DBTITLE 1,Save feature importance
+import matplotlib.pyplot as plt
+import os
+
+shap.summary_plot(shap_values, underbanked_sample[features], show=False)
+plt.savefig(f"{os.getcwd()}/images/shap_feature_importance.png")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Shapley values can also help for the analysis of local, instance-wise effects.
+# MAGIC
+# MAGIC We can also easily explain which feature impacted the decision for a given user. This can helps agent to understand the model an apply additional checks or control if required.
+
+# COMMAND ----------
+
+# DBTITLE 1,Explain feature importance for a single customer
+#shap.initjs()
+#We'll need to add shap bundle js to display nice graph
+with open(shap.__file__[:shap.__file__.rfind('/')]+"/plots/resources/bundle.js", 'r') as file:
+ shap_bundle_js = ''
+
+html = shap.force_plot(explainer.expected_value, shap_values[0,:], banked_df[features].iloc[0,:])
+displayHTML(shap_bundle_js + html.html())
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Model fairness using Shapley values
+# MAGIC
+# MAGIC In order to detect discriminatory outcomes in Machine Learning predictions, it is important to evaluate how the model treats various customer groups. This can be achieved by devising a metric, such as such as demographic parity, equal opportunity or equal odds, that defines fairness within the model. For example, when considering credit decisioning, we can compare the credit approval rates of male and female customers. In the notebook, we utilize Demographic Parity as a statistical measure of fairness, which asserts that there should be no difference between groups obtaining positive outcomes (e.g., credit approvals) in an ideal scenario. However, such perfect equality is rare, underscoring the need to monitor and address any gaps or discrepancies.
+
+# COMMAND ----------
+
+gender_array = banked_df['gender'].replace({'Female':0, 'Male':1}).to_numpy()[:100]
+shap.group_difference_plot(shap_values.sum(1), \
+ gender_array, \
+ xmin=-1.0, xmax=1.0, \
+ xlabel="Demographic parity difference\nof model output for women vs. men")
+
+# COMMAND ----------
+
+
+shap_df = pd.DataFrame(shap_values, columns=features).add_suffix('_shap')
+shap.group_difference_plot(shap_df[['age_shap', 'tenure_months_shap']].to_numpy(), \
+ gender_array, \
+ feature_names=['age', 'tenure_months'],
+ xmin=-0.5, xmax=0.5, \
+ xlabel="Demographic parity difference\nof SHAP values for women vs. men")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Logging custom metrics/artifacts with **MLflow**
+
+# COMMAND ----------
+
+# Retrieve model version by alias
+client = mlflow.tracking.MlflowClient()
+model_version_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="none")
+
+# Log new artifacts in the same experiment
+with mlflow.start_run(run_id=model_version_info.run_id):
+ # Log SHAP feature importance
+ mlflow.log_artifact(f"{os.getcwd()}/images/shap_feature_importance.png")
+
+ #Log Demographic parity difference\nof model output for women vs. men
+ mean_shap_male = np.mean(shap_values[gender_array == 1])
+ mean_shap_female = np.mean(shap_values[gender_array == 0])
+ mean_difference = mean_shap_male - mean_shap_female
+ mlflow.log_metric("shap_demo_parity_diff_wm", mean_shap_male - mean_shap_female)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Compliance checks
+# MAGIC
+# MAGIC Our model is demographic parity difference metric is logged with the model. The model is registered in Unity Catalog with the 'None' alias.
+# MAGIC
+# MAGIC Let's assume that the absolute demographic parity difference of model output for women vs. men should be less than 0.1 to model to pass the compliance checks.
+# MAGIC
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve experiment run by alias
+client = mlflow.tracking.MlflowClient()
+model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="none")
+run = client.get_run(model_info.run_id)
+
+# Retrieve a specific metric, such as 'shap_demo_parity_diff_wm'
+shap_demo_parity_diff_wm = run.data.metrics.get("shap_demo_parity_diff_wm")
+
+# COMMAND ----------
+
+# Check whether the metric passes the requirements
+
+compliance_checks_passed = False
+
+if abs(shap_demo_parity_diff_wm) < 0.1:
+ compliance_checks_passed = True
+ print("compliance checks passed")
+else:
+ print("compliance checks failed")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Champion-Challenger testing
+# MAGIC
+# MAGIC ### Identify the current champion and challenger models
+# MAGIC
+# MAGIC If there is a model already in production, we define it as the current `champion model`. The model with the 'None' alias is defined as the `challenger model`.
+
+# COMMAND ----------
+
+# Set the Challenger model to the model with the None alias
+challenger_model_info = model_info
+challenger_run = run
+
+# Set the Champion model to the model with the Production alias
+try:
+ champion_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="production")
+except Exception as e:
+ print(e)
+ champion_model_info = None
+if champion_model_info is not None:
+ champion_run = client.get_run(champion_model_info.run_id)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Next, we compare the perfomance of the two models. In this case, we use the `val_f1_score` metric. The model with the highest `val_f1_score` is the new candidate for the `champion model`.
+
+# COMMAND ----------
+
+champion_challenger_test_passed = False
+
+if champion_model_info is None:
+ # No champion model. Challenger model becomes the champion. Mark test as passed.
+ champion_challenger_test_passed = True
+ print("No champion model. Challenger model becomes the champion.")
+elif challenger_run.data.metrics['val_f1_score'] > champion_run.data.metrics['val_f1_score']:
+ # Challenger model is better than champion model. Mark test as passed.
+ champion_challenger_test_passed = True
+ print("Challenger model performs better than champion.")
+else:
+ print("Challenger model does not perform better than champion.")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Update validation status
+# MAGIC
+# MAGIC Having done both compliance check and champion-challenger testing, we will now update the model's validation status. Only models that have passed both checks are approved to progress further into higher environments.
+# MAGIC
+# MAGIC For auditability, we also apply tags on the version of the model in Unity Catalog that we are now reviewing to record the status of the tests and validation check.
+
+# COMMAND ----------
+
+# Indicate if compliance checks has passed
+pass_fail = "failed"
+if compliance_checks_passed:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, "compliance_checks", pass_fail)
+
+# Indicate if champion-challenger test has passed
+pass_fail = "failed"
+if champion_challenger_test_passed:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, "champion_challenger_test", pass_fail)
+
+# Model Validation Status is 'approved' only if both compliance checks and champion-challenger test have passed
+# Otherwise Model Validation Status is 'rejected'
+validation_status = "Not validated"
+if compliance_checks_passed & champion_challenger_test_passed:
+ validation_status = "approved"
+else:
+ validation_status = "rejected"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, "validation_status", validation_status)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Promote model to Staging
+# MAGIC
+# MAGIC Our model is now ready to be moved to the next stage. For this demo, we'll consider that our model is approved after going through the validation checks. It's now ready to be promoted to `Staging`. In `Staging`, the model will go through integration testing, before being deployed to `Prodution`.
+# MAGIC
+# MAGIC Otheriwse, if the model is rejected after going through the validation checks, we archive the model by setting its alias to `Archived`.
+# MAGIC
+# MAGIC Before promoting the model into `Staging`, there can be a human validation of the model involved.
+
+# COMMAND ----------
+
+# The production model is the champion model used in champion-challenger testing above
+# We will use the prod_model_info variable here for the code to be easier to understand
+prod_model_info = champion_model_info
+
+if prod_model_info is None:
+ # No model in production. Set this model as the candidate production model by promoting it to Staging
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="none")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging", version=model_info.version)
+ print(f'{model_info.version} of {catalog}.{db}.{model_name} is now promoted to Staging.')
+elif validation_status == "approved":
+ # This model has passed validation checks. Promote it to Staging.
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="none")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging", version=model_info.version)
+ print(f'{model_info.version} of {catalog}.{db}.{model_name} is now promoted to Staging.')
+else:
+ # This model did not pass validation checks. Set it to Archived.
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="none")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"archived", "true")
+ print(f'{model_info.version} of {catalog}.{db}.{model_name} is transitioned to Archived. No model promoted to Staging.')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Store Data (into Delta format) for Downstream Usage
+# MAGIC
+# MAGIC Finally, we store the validated dataset in Delta format for auditing and future reference
+
+# COMMAND ----------
+
+#Let's load the underlying model to get the proba
+try:
+ skmodel = mlflow.sklearn.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@Staging")
+ underbanked_sample['default_prob'] = skmodel.predict_proba(underbanked_sample[features])[:,1]
+ underbanked_sample['prediction'] = skmodel.predict(underbanked_sample[features])
+ final_df = pd.concat([underbanked_sample.reset_index(), shap_df], axis=1)
+
+ final_df = spark.createDataFrame(final_df).withColumn("default_prob", col("default_prob").cast('double'))
+ display(final_df)
+ final_df.drop('CREDIT_CURRENCY', '_rescued_data', 'index') \
+ .write.mode("overwrite").option('OverwriteSchema', True).saveAsTable(f"shap_explanation")
+except:
+ print("No model in staging.")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC In the next step [06.5-Model-Integration]($./06-Responsible-AI/06.5-Model-Integration), we will conduct integration testing on the model with other components that use it. An example of that is a batch inference pipeline. This is how the model is deployed responsibly, ensuring traceability and accountability at each decision point, while ensuring the integrity of systems and application where the model is used.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-model-serving-BNPL-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-model-serving-BNPL-credit-decisioning.py
deleted file mode 100644
index 61541b9f..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-model-serving-BNPL-credit-decisioning.py
+++ /dev/null
@@ -1,193 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Buy Now, Pay Later (BNPL)
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC ### *"Can we allow a user without sufficient balance in their account to complete the current (debit or credit) transaction?"*
-# MAGIC
-# MAGIC
-# MAGIC We will utilize our credit risk model (built in the previous steps) in real-time to answer this question.
-# MAGIC
-# MAGIC The payment system will be able to call our API in realtime and get a score within a few ms.
-# MAGIC
-# MAGIC With this information, we'll be able to offer our customer the choice to pay with a credit automatically, or refuse if the model believes the risk is too high and will likely result in a payment default.
-# MAGIC
-# MAGIC
-# MAGIC These types of decisions are typically embedded in live Point Of Sales (stores, online shop). That is why we need real-time serving capabilities.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC # Deploying the Credit Scoring model for real-time serving
-# MAGIC
-# MAGIC
-# MAGIC Let's deploy our model behind a scalable API to evaluate credit-worthiness in real-time.
-# MAGIC
-# MAGIC ## Databricks Model Serving
-# MAGIC
-# MAGIC Now that our model has been created with Databricks AutoML, we can easily flag it as Production Ready and turn on Databricks Model Serving.
-# MAGIC
-# MAGIC We'll be able to send HTTP Requests and get inference in real-time.
-# MAGIC
-# MAGIC Databricks Model Serving is fully serverless:
-# MAGIC
-# MAGIC * One-click deployment. Databricks will handle scalability, providing blazing fast inferences and startup time.
-# MAGIC * Scale down to zero as an option for best TCO (will shut down if the endpoint isn't used).
-# MAGIC * Built-in support for multiple models & version deployed.
-# MAGIC * A/B Testing and easy upgrade, routing traffic between each versions while measuring impact.
-# MAGIC * Built-in metrics & monitoring.
-
-# COMMAND ----------
-
-# MAGIC %pip install mlflow==2.19.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# DBTITLE 1,Make sure our last model version is deployed in production in our registry
-import mlflow
-model_name = "dbdemos_fsi_credit_decisioning"
-mlflow.set_registry_uri('databricks-uc')
-
-# COMMAND ----------
-
-
-from databricks.sdk import WorkspaceClient
-from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, AutoCaptureConfigInput
-
-model_name = f"{catalog}.{db}.dbdemos_fsi_credit_decisioning"
-serving_endpoint_name = "dbdemos_fsi_credit_decisioning_endpoint"
-w = WorkspaceClient()
-endpoint_config = EndpointCoreConfigInput(
- name=serving_endpoint_name,
- served_entities=[
- ServedEntityInput(
- entity_name=model_name,
- entity_version=get_latest_model_version(model_name),
- scale_to_zero_enabled=True,
- workload_size="Small"
- )
- ],
- auto_capture_config = AutoCaptureConfigInput(catalog_name=catalog, schema_name=db, enabled=True, table_name_prefix="inference_table" )
-)
-
-force_update = False #Set this to True to release a newer version (the demo won't update the endpoint to a newer model version by default)
-existing_endpoint = next((e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None)
-if existing_endpoint == None:
- print(f"Creating the endpoint {serving_endpoint_name}, this will take a few minutes to package and deploy the endpoint...")
- w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
-else:
- print(f"endpoint {serving_endpoint_name} already exist...")
- if force_update:
- w.serving_endpoints.update_config_and_wait(served_entities=endpoint_config.served_entities, name=serving_endpoint_name)
-
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC Our model endpoint was automatically created.
-# MAGIC
-# MAGIC Open the [endpoint UI](#mlflow/endpoints/dbdemos_fsi_credit_decisioning_endpoint) to explore your endpoint and use the UI to send queries.
-# MAGIC
-# MAGIC *Note that the first deployment will build your model image and take a few minutes. It'll then stop & start instantly.*
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ### Testing the model
-# MAGIC
-# MAGIC Now that the model is deployed, let's test it with information for a customer trying to temporarily increase their credit limits or obtain a micro-loan at the point-of-sale.
-
-# COMMAND ----------
-
-from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
-from mlflow.models.model import Model
-
-p = ModelsArtifactRepository(f"models:/{model_name}@prod").download_artifacts("")
-dataset = {"dataframe_split": Model.load(p).load_input_example(p).to_dict(orient='split')}
-
-# COMMAND ----------
-
-import mlflow
-from mlflow import deployments
-client = mlflow.deployments.get_deploy_client("databricks")
-predictions = client.predict(endpoint=serving_endpoint_name, inputs=dataset)
-
-prediction_score = list(predictions["predictions"])[0]
-print(
- f"The transaction will be approved. Score: {prediction_score}."
- if prediction_score == 0
- else f"The transaction will not be approved. Score: {prediction_score}."
-)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC # Updating your model and monitoring its performance with A/B testing
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Databricks Model Serving let you easily deploy & test new versions of your model.
-# MAGIC
-# MAGIC You can dynamically reconfigure your endpoint to route a subset of your traffic to a newer version. In addition, you can leverage endpoint monitoring to understand your model behavior and track your A/B deployment.
-# MAGIC
-# MAGIC * Without making any production outage
-# MAGIC * Slowly routing requests to the new model
-# MAGIC * Supporting auto-scaling & potential bursts
-# MAGIC * Performing some A/B testing ensuring the new model is providing better outcomes
-# MAGIC * Monitorig our model outcome and technical metrics (CPU/load etc)
-# MAGIC
-# MAGIC Databricks makes this process super simple with Serverless Model Serving endpoint.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Model monitoring and A/B testing analysis
-# MAGIC
-# MAGIC Because the Model Serving runs within our Lakehouse, Databricks will automatically save and track all our Model Endpoint results as a Delta Table.
-# MAGIC
-# MAGIC We can then easily plug a feedback loop to start analysing the revenue in $ each model is offering.
-# MAGIC
-# MAGIC All these metrics, including A/B testing validation (p-values etc) can then be pluged into a Model Monitoring Dashboard and alerts can be sent for errors, potentially triggering new model retraining or programatically updating the Endpoint routes to fallback to another model.
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Next
-# MAGIC
-# MAGIC Making sure your model is fair towards customers of any demographics are extremely important parts of building production-ready ML models for FSI use cases.
-# MAGIC Explore your model with [03.5-Explainability-and-Fairness-credit-decisioning]($./03.5-Explainability-and-Fairness-credit-decisioning) on the Lakehouse.
-# MAGIC
-# MAGIC ## Conclusion: the power of the Lakehouse
-# MAGIC
-# MAGIC In this demo, we've seen an end 2 end flow with the Lakehouse:
-# MAGIC
-# MAGIC - Data ingestion made simple with Delta Live Table
-# MAGIC - Leveraging Databricks warehouse to making credit decisions
-# MAGIC - Model Training with AutoML for citizen Data Scientist
-# MAGIC - Ability to tune our model for better results, improving our revenue
-# MAGIC - Ultimately, the ability to deploy and make explainable ML predictions, made possible with the full Lakehouse capabilities.
-# MAGIC
-# MAGIC [Go back to the introduction]($../00-Credit-Decisioning) or discover how to use Databricks Workflow to orchestrate everything together through the [05-Workflow-Orchestration-credit-decisioning]($../05-Workflow-Orchestration/05-Workflow-Orchestration-credit-decisioning).
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.5-Explainability-and-Fairness-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.5-Explainability-and-Fairness-credit-decisioning.py
deleted file mode 100644
index 6974e1de..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.5-Explainability-and-Fairness-credit-decisioning.py
+++ /dev/null
@@ -1,189 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Credit Decisioning - Model Explainability and Fairness
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Machine learning (ML) models are increasingly being used in credit decisioning to automate lending processes, reduce costs, and improve accuracy.
-# MAGIC
-# MAGIC As ML models become more complex and data-driven, their decision-making processes can become opaque, making it challenging to understand how decisions are made, and to ensure that they are fair and non-discriminatory.
-# MAGIC
-# MAGIC Therefore, it is essential to develop techniques that enable model explainability and fairness in credit decisioning to ensure that the use of ML does not perpetuate existing biases or discrimination.
-# MAGIC
-# MAGIC In this context, explainability refers to the ability to understand how an ML model is making its decisions, while fairness refers to ensuring that the model is not discriminating against certain groups of people.
-# MAGIC
-# MAGIC ## Ensuring model fairness for new credit customers
-# MAGIC
-# MAGIC In this example, we'll make sure that our model behaves as expected and is fair for our new customers.
-# MAGIC
-# MAGIC We'll select our existing customers not having credit (We'll flag them as `defaulted = 2`) and make sure that our model is fair and behave the same among different group of the population.
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %pip install --quiet shap==0.46.0 mlflow==2.19.0 scikit-learn==1.3.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC Here we are merging several PII columns (hence we read from the ```customer_silver``` table) with the model prediction output table for visualizing them on the dashboard for end user consumption
-
-# COMMAND ----------
-
-feature_df = spark.table("credit_decisioning_features")
-credit_bureau_label = spark.table("credit_bureau_gold")
-customer_df = spark.table(f"customer_silver").select("cust_id", "gender", "first_name", "last_name", "email", "mobile_phone")
-
-df = (feature_df.join(customer_df, "cust_id", how="left")
- .join(credit_bureau_label, "cust_id", how="left")
- .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE").isNull(), 2)
- .when(col("CREDIT_DAY_OVERDUE") > 60, 1)
- .otherwise(0))
- .drop('CREDIT_DAY_OVERDUE')
- .fillna(0))
-display(df)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Load Model from the registry
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-import mlflow
-mlflow.set_registry_uri('databricks-uc')
-
-model = mlflow.pyfunc.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@prod")
-features = model.metadata.get_input_schema().input_names()
-
-# COMMAND ----------
-
-underbanked_df = df[df.defaulted==2].toPandas() # Features for underbanked customers
-banked_df = df[df.defaulted!=2].toPandas() # Features for rest of the customers
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Feature importance using Shapley values
-# MAGIC
-# MAGIC SHAP is a game-theoretic approach to explain machine learning models, providing a summary plot
-# MAGIC of the relationship between features and model output. Features are ranked in descending order of
-# MAGIC importance, and impact/color describe the correlation between the feature and the target variable.
-# MAGIC - Generating SHAP feature importance is a very memory intensive operation.
-# MAGIC - To reduce the computational overhead of each trial, a single example is sampled from the underbanked set to explain.
-# MAGIC For more thorough results, increase the sample size of explanations, or provide your own examples to explain.
-# MAGIC - SHAP cannot explain models using data with nulls; if your dataset has any, both the background data and
-# MAGIC examples to explain will be imputed using the mode (most frequent values). This affects the computed
-# MAGIC SHAP values, as the imputed samples may not match the actual data distribution.
-# MAGIC
-# MAGIC For more information on how to read Shapley values, see the [SHAP documentation](https://shap.readthedocs.io/en/latest/example_notebooks/overviews/An%20introduction%20to%20explainable%20AI%20with%20Shapley%20values.html).
-
-# COMMAND ----------
-
-mlflow.autolog(disable=True)
-mlflow.sklearn.autolog(disable=True)
-
-import shap
-train_sample = banked_df[features].sample(n=np.minimum(100, banked_df.shape[0]), random_state=42)
-underbanked_sample = underbanked_df.sample(n=np.minimum(100, underbanked_df.shape[0]), random_state=42)
-
-# Use Kernel SHAP to explain feature importance on the sampled rows from the validation set.
-predict = lambda x: model.predict(pd.DataFrame(x, columns=features).astype(train_sample.dtypes.to_dict()))
-
-explainer = shap.KernelExplainer(predict, train_sample, link="identity")
-shap_values = explainer.shap_values(underbanked_sample[features], l1_reg=False, nsamples=100)
-
-# COMMAND ----------
-
-shap.summary_plot(shap_values, underbanked_sample[features])
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC Shapely values can also help for the analysis of local, instance-wise effects.
-# MAGIC
-# MAGIC We can also easily explain which feature impacted the decision for a given user. This can helps agent to understand the model an apply additional checks or control if required.
-
-# COMMAND ----------
-
-# DBTITLE 1,Explain feature importance for a single customer
-#shap.initjs()
-#We'll need to add shap bundle js to display nice graph
-with open(shap.__file__[:shap.__file__.rfind('/')]+"/plots/resources/bundle.js", 'r') as file:
- shap_bundle_js = ''
-
-html = shap.force_plot(explainer.expected_value, shap_values[0,:], underbanked_sample[features].iloc[0,:])
-displayHTML(shap_bundle_js + html.html())
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Model fairness using Shapley values
-# MAGIC
-# MAGIC In order to detect discriminatory outcomes in Machine Learning predictions, it is important to evaluate how the model treats various customer groups. This can be achieved by devising a metric, such as such as demographic parity, equal opportunity or equal odds, that defines fairness within the model. For example, when considering credit decisioning, we can compare the credit approval rates of male and female customers. In the notebook, we utilize Demographic Parity as a statistical measure of fairness, which asserts that there should be no difference between groups obtaining positive outcomes (e.g., credit approvals) in an ideal scenario. However, such perfect equality is rare, underscoring the need to monitor and address any gaps or discrepancies.
-
-# COMMAND ----------
-
-gender_array = underbanked_df['gender'].replace({'Female':0, 'Male':1}).to_numpy()
-shap.group_difference_plot(shap_values.sum(1), \
- gender_array, \
- xmin=-1.0, xmax=1.0, \
- xlabel="Demographic parity difference\nof model output for women vs. men")
-
-# COMMAND ----------
-
-shap_df = pd.DataFrame(shap_values, columns=features).add_suffix('_shap')
-
-shap.group_difference_plot(shap_df[['age_shap', 'tenure_months_shap']].to_numpy(), \
- gender_array, \
- feature_names=['age', 'tenure_months'],
- xmin=-0.5, xmax=0.5, \
- xlabel="Demographic parity difference\nof SHAP values for women vs. men")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Store Data (into Delta format) for Downstream Usage
-# MAGIC
-# MAGIC Since we want to add the Explainability and Fairness assessment in the business dashboards, we will persist this data into Delta format and query it later.
-
-# COMMAND ----------
-
-#Let's load the underlying model to get the proba
-skmodel = mlflow.sklearn.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@prod")
-underbanked_sample['default_prob'] = skmodel.predict_proba(underbanked_sample[features])[:,1]
-underbanked_sample['prediction'] = skmodel.predict(underbanked_sample[features])
-final_df = pd.concat([underbanked_sample.reset_index(), shap_df], axis=1)
-
-final_df = spark.createDataFrame(final_df).withColumn("default_prob", col("default_prob").cast('double'))
-display(final_df)
-final_df.drop('CREDIT_CURRENCY', '_rescued_data') \
- .write.mode("overwrite").option('mergeSchema', True).saveAsTable(f"shap_explanation")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Conclusion: the power of the Lakehouse
-# MAGIC
-# MAGIC In this demo, we've seen an end 2 end flow with the Lakehouse:
-# MAGIC
-# MAGIC - Data ingestion made simple with Delta Live Table
-# MAGIC - Leveraging Databricks warehouse to making credit decisions
-# MAGIC - Model Training with AutoML for citizen Data Scientist
-# MAGIC - Ability to tune our model for better results, improving our revenue
-# MAGIC - Ultimately, the ability to deploy and make explainable ML predictions, made possible with the full Lakehouse capabilities.
-# MAGIC
-# MAGIC [Go back to the introduction]($../00-Credit-Decisioning) or discover how to use Databricks Workflow to orchestrate this tasks: [05-Workflow-Orchestration-credit-decisioning]($../05-Workflow-Orchestration/05-Workflow-Orchestration-credit-decisioning)
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.5-Model-Integration-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.5-Model-Integration-credit-decisioning.py
new file mode 100644
index 00000000..7a5f6373
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.5-Model-Integration-credit-decisioning.py
@@ -0,0 +1,207 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Model Integration
+# MAGIC
+# MAGIC In this notebook, we implement integration tests to ensure that the model works well with other components in the system before deploying it to Production. By doing so, we ensure that misstion critical systems will not be unexpectedly disrupted when we introduce a new model version.
+# MAGIC
+# MAGIC While the model has been validated for fairness and tested for comparable performance against the existing model in production, having this structured integration process ensures that system robustness and business continuity are taken into account in Responsible AI considerations.
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Retrieve the `Staging` model
+# MAGIC
+# MAGIC We will first retrieve the `Staging` model registered in Unity Catalog. As we run integration tests against it, we will update the model with status information from the tests.
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve model info run by alias
+client = mlflow.tracking.MlflowClient()
+
+# Fetch the Staging model
+try:
+ model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+except:
+ model_info = None
+
+assert model_info is not None, 'No Staging model. Deploy one to Staging first.'
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Testing batch inference
+# MAGIC
+# MAGIC Since the model will be integrated into a batch inference pipeline, we will illustrate integration testing by running a batch inference test in this demo.
+# MAGIC
+# MAGIC We can easily load the model as a Spark UDF scoring function by indicating its `Staging` alias. This is the same way as how we load models for batch scoring in Production. The only difference is the the alias we use, as we will see in the next notebook.
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark,
+ model_uri=f"models:/{catalog}.{db}.{model_name}@staging", result_type='double',
+ env_manager="virtualenv")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC For now, we will test the batch inference pipeline by loading the features in the Staging environment, and apply the model to perform inference. Performing integration tests can help us detect issues arising from missing features in upstream tables, empty prediction values due to feature values not used in training, just to name a couple of examples.
+
+# COMMAND ----------
+
+from pyspark.sql import functions as F
+
+features = loaded_model.metadata.get_input_schema().input_names()
+
+feature_df = spark.table("credit_decisioning_features_labels").fillna(0)
+
+try:
+ prediction_df = feature_df.withColumn("prediction", loaded_model(F.struct(*features)).cast("integer")) \
+ .withColumn("model_id", F.lit(1)).cache()
+except:
+ prediction_df = None
+
+display(prediction_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Perform tests
+# MAGIC
+# MAGIC Next, we perform a number of tests on the inference results to ensure that the systems will behave properly after integrating the model. We use a few simple examples:
+# MAGIC
+# MAGIC - Check that a object is returned for the resulting DataFrame
+# MAGIC - The inference code may not return a result if there are missing features in the upstream table.
+# MAGIC - Furthermore, a `None` return object can cause issues to downstream code.
+# MAGIC - Check that the resulting DataFrame has rows in it
+# MAGIC - An empty DataFrame may cause issues to downstream code.
+# MAGIC - Check that there are no null values in the prediction column
+# MAGIC - The team needs to determine if null values are expected, and how the system should handle them.
+
+# COMMAND ----------
+
+# These tests should all return True to pass
+result_df_not_null = (
+ prediction_df != None
+)
+result_df_not_empty = (
+ prediction_df.count() > 0
+)
+no_null_pred_values = (
+ prediction_df.filter(prediction_df.prediction.isNull()).count() == 0
+)
+
+print(f"An object is returned for the result DataFrame: {result_df_not_null}")
+print(f"Result DataFrame contains rows: {result_df_not_empty}")
+print(f"No null prediction values: {no_null_pred_values}")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Update integration testing status
+# MAGIC
+# MAGIC Having performed the tests, we will now update the model's integration testing status. Only models that have passed all tests are allowed to be promoted to production.
+# MAGIC
+# MAGIC For auditability, we also apply tags on the version of the model in Unity Catalog to record the status of the integration tests.
+
+# COMMAND ----------
+
+# Indicate if result_df_not_null test has passed
+pass_fail = "failed"
+if result_df_not_null:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_result_df_not_null", pass_fail)
+
+# Indicate if result_df_not_empty test has passed
+pass_fail = "failed"
+if result_df_not_empty:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_result_df_not_empty", pass_fail)
+
+# Indicate if no_null_pred_values test has passed
+pass_fail = "failed"
+if no_null_pred_values:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_no_null_pred_values", pass_fail)
+
+# Model Validation Status is 'approved' only if both compliance checks and champion-challenger test have passed
+# Otherwise Model Validation Status is 'rejected'
+integration_test_status = "Not tested"
+if result_df_not_null & result_df_not_empty & no_null_pred_values:
+ integration_test_status = "passed"
+else:
+ integration_test_status = "failed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, "integration_test_status", integration_test_status)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Promote model to Production
+# MAGIC
+# MAGIC Our model is now ready to be promoted to `Production`. As we do so, we also archive the existing production model by setting its alias to `Archived`.
+# MAGIC
+# MAGIC If our model did not pass the integration tests, we simply transition it to `Archived`, while leaving the existing model in `Production` untouched.
+
+# COMMAND ----------
+
+# Fetch the Production model (if any)
+try:
+ prod_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="production")
+except:
+ prod_model_info = None
+
+if integration_test_status == "passed":
+ # This model has passed integration testing. Check if there's an existing model in Production
+ if prod_model_info is not None:
+ # Existing model in production. Archive the existing prod model.
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=prod_model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", prod_model_info.version, f"archived", "true")
+ print(f'Version {prod_model_info.version} of {catalog}.{db}.{model_name} is now archived.')
+ else:
+ # No model in production.
+ print(f'{catalog}.{db}.{model_name} does not have a Production model.')
+ # Promote this model to Production
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="production", version=model_info.version)
+ print(f'Version {model_info.version} of {catalog}.{db}.{model_name} is now promoted to Production.')
+else:
+ # This model has failed integration testing. Set it to Archived
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"archived", "true")
+ print(f'Version {model_info.version} of {catalog}.{db}.{model_name} is transitioned to Archived. No model promoted to Production.')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC We just moved our automl model as production ready!
+# MAGIC
+# MAGIC Open the model in Unity Catalog to explore its artifact and analyze the parameters used, including traceability to the notebook used for its creation.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC
+# MAGIC Now that the model is in Production, we proceed to [06.6-Model-Inference]($./06-Responsible-AI/06.6-Model-Inference), where the deployed model is used for batch or real-time inference and predictions are logged for explainability and transparency. This ensures that model outputs are reliable, ethical, and aligned with regulatory standards, closing the loop on Responsible AI implementation.
+
+# COMMAND ----------
+
+
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py
new file mode 100644
index 00000000..ed952bb1
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py
@@ -0,0 +1,183 @@
+# Databricks notebook source
+# MAGIC %md-sandbox
+# MAGIC # Model Inference
+# MAGIC
+# MAGIC In this notebook, we demonstrate how to operationalize machine learning models on Databricks by enabling both batch and real-time inference. For real-time serving, we leverage Databricks Model Serving, which allows us to expose the model through a low-latency REST API endpoint, enabling scalable and responsive predictions for downstream applications. We also implement batch inference using pyspark for large-scale processing. This dual approach illustrates how Databricks supports a unified platform for production-grade ML inference across diverse use cases.
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Running batch inference
+# MAGIC
+# MAGIC Now that our model has been successfully trained and deployed to production within the MLFlow registry, we can seamlessly integrate it into various Data Engineering workflows.
+# MAGIC
+# MAGIC We can now easily load it calling the `Production` stage, and use it in any Data Engineering pipeline (a job running every night, in streaming or even within a Delta Live Table pipeline).
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark,
+ model_uri=f"models:/{catalog}.{db}.{model_name}@production", result_type='double',
+ env_manager="virtualenv")
+
+# COMMAND ----------
+
+from pyspark.sql import functions as F
+
+features = loaded_model.metadata.get_input_schema().input_names()
+
+feature_df = spark.table("credit_decisioning_features_labels").fillna(0)
+
+prediction_df = feature_df.withColumn("prediction", loaded_model(F.struct(*features)).cast("integer")) \
+ .withColumn("model_id", F.lit(1)).cache()
+
+display(prediction_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC In the scored data frame above, we have essentially created an end-to-end process to predict credit worthiness for any customer, regardless of whether the customer has an existing bank account. We have a binary prediction which captures this and incorporates all the intellience from Databricks AutoML and curated features from our feature store.
+
+# COMMAND ----------
+
+(prediction_df
+ .write
+ .format("delta")
+ .mode("overwrite")
+ .option("overwriteSchema",True)
+ .option("delta.enableChangeDataFeed", "true")
+ .saveAsTable("credit_decisioning_baseline_predictions")
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Deploying the Credit Scoring model for real-time serving
+# MAGIC
+# MAGIC
+# MAGIC Let's deploy our model behind a scalable API to evaluate credit-worthiness in real-time.
+# MAGIC
+# MAGIC Now that our model has been created with Databricks AutoML, we can easily flag it as Production Ready and turn on Databricks Model Serving.
+# MAGIC
+# MAGIC We'll be able to send HTTP Requests and get inference in real-time.
+# MAGIC
+# MAGIC Databricks Model Serving is fully serverless:
+# MAGIC
+# MAGIC * One-click deployment. Databricks will handle scalability, providing blazing fast inferences and startup time.
+# MAGIC * Scale down to zero as an option for best TCO (will shut down if the endpoint isn't used).
+# MAGIC * Built-in support for multiple models & version deployed.
+# MAGIC * A/B Testing and easy upgrade, routing traffic between each versions while measuring impact.
+# MAGIC * Built-in metrics & monitoring.
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve model info run by alias
+client = mlflow.tracking.MlflowClient()
+
+production_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="Production")
+
+# COMMAND ----------
+
+from mlflow.deployments import get_deploy_client
+
+mlflow.set_registry_uri("databricks-uc")
+deploy_client = get_deploy_client("databricks")
+
+endpoint = deploy_client.create_endpoint(
+ name=f"{endpoint_name}",
+ config={
+ "served_entities": [
+ {
+ "name": f"{model_name}-{production_model_info.version}",
+ "entity_name": f"{catalog}.{db}.{model_name}",
+ "entity_version": f"{production_model_info.version}",
+ "workload_size": "Small",
+ "scale_to_zero_enabled": True
+ }
+ ],
+ "traffic_config": {
+ "routes": [
+ {
+ "served_model_name": f"{model_name}-{production_model_info.version}",
+ "traffic_percentage": "100"
+ }
+ ]
+ },
+ "auto_capture_config":{
+ "catalog_name": f"{catalog}",
+ "schema_name": f"{db}",
+ "table_name_prefix": f"{endpoint_name}"
+ },
+ "environment_variables": {
+ "ENABLE_MLFLOW_TRACING": "True"
+ }
+ }
+)
+
+# COMMAND ----------
+
+from time import sleep
+
+# Wait for endpoint to be ready before running inference
+# This can take 10 minutes or so
+
+endpoint_udpate = endpoint
+is_not_ready = True
+is_not_updated = True
+
+print("Waiting for endpoint to be ready...")
+while(is_not_ready | is_not_updated):
+ sleep(10)
+ endpoint_udpate = deploy_client.get_endpoint(endpoint_name)
+ is_not_ready = endpoint_udpate["state"]["ready"] != "READY"
+ is_not_updated = endpoint_udpate["state"]["config_update"] != "NOT_UPDATING"
+
+print(f"Endpoint status: {endpoint_udpate['state']['ready']}; {endpoint_udpate['state']['config_update']}")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Our model endpoint was automatically created.
+# MAGIC
+# MAGIC Open the [endpoint UI](#mlflow/endpoints) to explore your endpoint and use the UI to send queries.
+# MAGIC
+# MAGIC *Note that the first deployment will build your model image and take a few minutes. It'll then stop & start instantly.*
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ### Testing the model serving endpoint
+# MAGIC
+# MAGIC Now that the model is deployed, let's test it with some queries and investigate the inferance table.
+
+# COMMAND ----------
+
+from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
+from mlflow.models.model import Model
+
+p = ModelsArtifactRepository(f"models:/{model_name}@production").download_artifacts("")
+dataset = {"dataframe_split": Model.load(p).load_input_example(p).to_dict(orient='split')}
+predictions = deploy_client.predict(endpoint=endpoint_name, inputs=dataset)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With model inference in place, the next critical step is [06.7-Model-Monitoring]($./06-Responsible-AI/06.7-Model-Monitoring). In this final stage, we will continuously track data drift and model performance degradation using Lakehouse Monitoring. By integrating real-time monitoring with inference, we can proactively manage model health and maintain responsible AI principles throughout the credit scoring lifecycle.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py
new file mode 100644
index 00000000..599bb8f4
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py
@@ -0,0 +1,383 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Model Monitoring
+# MAGIC
+# MAGIC In this notebook, we focus on **Lakehouse monitoring** to ensure the ongoing reliability, fairness, and performance of our credit scoring model. A critical aspect of **Responsible AI** is maintaining trust and effectiveness over time, which requires systematic tracking of model behavior, detecting data drift, and recalibrating models as necessary.
+# MAGIC
+# MAGIC ### Why Model Monitoring Matters
+# MAGIC Machine learning models are exposed to evolving real-world conditions, such as economic shifts and changes in customer behavior. If left unmonitored, models can degrade in accuracy, introduce unintended biases, or fail regulatory compliance. **Databricks’ Lakehouse architecture** provides a unified approach to monitoring both data and models, ensuring end-to-end traceability and governance.
+# MAGIC
+# MAGIC ### Key Components of Model Monitoring
+# MAGIC We will leverage Databricks’ built-in monitoring capabilities to:
+# MAGIC
+# MAGIC 1. **Detect Data Drift:** Continuously track statistical distributions of input features and predictions, identifying shifts that could impact model reliability.
+# MAGIC 2. **Monitor Model Performance Decay:** Compare real-world outcomes against model predictions to detect degrading performance.
+# MAGIC 3. **Ensure Fairness and Bias Control:** Check if fairness metrics remain within acceptable thresholds to prevent unintended discrimination.
+# MAGIC 4. **Trigger Recalibration Workflows:** Automate retraining and redeployment when model effectiveness declines, ensuring continuous improvement.
+# MAGIC 5. **Generate Alerts and Reports:** Notify stakeholders when significant changes occur, maintaining transparency and accountability.
+# MAGIC
+# MAGIC By embedding monitoring within the **Databricks Data Intelligence Platform**, we create a scalable and responsible approach to lifecycle management, aligning with regulatory requirements while ensuring that credit decisions remain fair, accurate, and explainable.
+# MAGIC
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# DBTITLE 1,Install Lakehouse Monitoring client wheel
+# MAGIC %pip install "databricks-sdk>=0.28.0"
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Background
+# MAGIC The following are required to create an inference log monitor with [Lakehouse Monitoring](https://www.databricks.com/product/machine-learning/lakehouse-monitoring):
+# MAGIC - A Delta table in Unity Catalog that you own.
+# MAGIC - The data can be batch scored data or inference logs. The following columns are required:
+# MAGIC - `timestamp` (TimeStamp): Used for windowing and aggregation when calculating metrics
+# MAGIC - `model_id` (String): Model version/id used for each prediction.
+# MAGIC - `prediction` (String): Value predicted by the model.
+# MAGIC
+# MAGIC - The following column is optional:
+# MAGIC - `label` (String): Ground truth label.
+# MAGIC
+# MAGIC You can also provide an optional baseline table to track performance changes in the model and drifts in the statistical characteristics of features.
+# MAGIC - To track performance changes in the model, consider using the test or validation set.
+# MAGIC - To track drifts in feature distributions, consider using the training set or the associated feature tables.
+# MAGIC - The baseline table must use the same column names as the monitored table, and must also have a `model_version` column.
+# MAGIC
+# MAGIC Databricks recommends enabling Delta's Change-Data-Feed ([AWS](https://docs.databricks.com/delta/delta-change-data-feed.html#enable-change-data-feed)|[Azure](https://learn.microsoft.com/azure/databricks/delta/delta-change-data-feed#enable-change-data-feed)) table property for better metric computation performance for all monitored tables, including the baseline table. This notebook shows how to enable Change Data Feed when you create the Delta table.
+
+# COMMAND ----------
+
+TABLE_NAME = f"{catalog}.{db}.credit_decisioning_inferencelogs"
+BASELINE_TABLE = f"{catalog}.{db}.credit_decisioning_baseline_predictions"
+MODEL_NAME = f"{model_name}" # Name of (registered) model in mlflow registry
+TIMESTAMP_COL = "timestamp"
+MODEL_ID_COL = "model_id" # Name of column to use as model identifier (here we'll use the model_name+version)
+PREDICTION_COL = "prediction" # What to name predictions in the generated tables
+LABEL_COL = "defaulted" # Name of ground-truth labels column
+ID_COL = "cust_id"
+new_model_version = 1
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create a sample inference table
+# MAGIC
+# MAGIC Example pre-processing step
+# MAGIC * Extract ground-truth labels (in practice, labels might arrive later)
+# MAGIC * Split into two batches
+# MAGIC * Add `model_version` column and write to the table that we will attach a monitor to
+# MAGIC * Add ground-truth `label_col` column with empty/NaN values
+# MAGIC
+# MAGIC Set `mergeSchema` to `True` to enable appending dataframes without label column available
+
+# COMMAND ----------
+
+from datetime import timedelta, datetime
+import random
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=f"models:/{catalog}.{db}.{model_name}@production", result_type='double', env_manager="virtualenv")
+features = loaded_model.metadata.get_input_schema().input_names()
+
+# Simulate inferences for n days
+n_days = 10
+
+feature_df = spark.table("credit_decisioning_features").orderBy(F.rand()).limit(10)
+feature_df = feature_df.withColumn(TIMESTAMP_COL, F.lit(datetime.now().timestamp()).cast("timestamp"))
+
+for n in range(1, n_days):
+ temp_df = spark.table("credit_decisioning_features").orderBy(F.rand()).limit(random.randint(5, 20))
+ timestamp = (datetime.now() - timedelta(days = n)).timestamp()
+ temp_df = temp_df.withColumn(TIMESTAMP_COL, F.lit(timestamp).cast("timestamp"))
+ feature_df = feature_df.union(temp_df)
+
+feature_df = feature_df.fillna(0)
+
+# Introducing synthetic drift into few columns
+feature_df = feature_df.withColumn('total_deposits_amount', F.col('total_deposits_amount') + F.rand() * 100000) \
+ .withColumn('total_equity_amount', F.col('total_equity_amount') + F.rand() * 100000) \
+ .withColumn('total_UT', F.col('total_UT') + F.rand() * 100000) \
+ .withColumn('customer_revenue', F.col('customer_revenue') + F.rand() * 100000)
+
+pred_df = feature_df.withColumn(PREDICTION_COL, loaded_model(*features).cast("integer")) \
+ .withColumn(MODEL_ID_COL, F.lit(new_model_version))
+
+(pred_df
+ .withColumn(MODEL_ID_COL, F.lit(new_model_version))
+ .withColumn(LABEL_COL, F.lit(None).cast("integer"))
+ .withColumn("cust_id", col("cust_id").cast("bigint"))
+ .write.format("delta").mode("overwrite")
+ .option("mergeSchema",True)
+ .option("delta.enableChangeDataFeed", "true")
+ .saveAsTable(TABLE_NAME)
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Join ground-truth labels to inference table
+# MAGIC **Note: If ground-truth value can change for a given id through time, then consider also joining/merging on timestamp column**
+
+# COMMAND ----------
+
+# DBTITLE 1,Using MERGE INTO (Recommended)
+# Step 1: Create temporary view using synthetic labels
+df = spark.table(TABLE_NAME).select(ID_COL, PREDICTION_COL)
+df = df.withColumn("temp", F.rand())
+df = df.withColumn(LABEL_COL,
+ F.when(df["temp"] < 0.14, 1 - df[PREDICTION_COL]).otherwise(df[PREDICTION_COL]))
+df = df.drop("temp", PREDICTION_COL)
+ground_truth_df = df.withColumnRenamed(PREDICTION_COL, LABEL_COL)
+late_labels_view_name = f"credit_decisioning_late_labels"
+ground_truth_df.createOrReplaceTempView(late_labels_view_name)
+
+# Step 2: Merge into inference table
+merge_info = spark.sql(
+ f"""
+ MERGE INTO {TABLE_NAME} AS i
+ USING {late_labels_view_name} AS l
+ ON i.{ID_COL} == l.{ID_COL}
+ WHEN MATCHED THEN UPDATE SET i.{LABEL_COL} == l.{LABEL_COL}
+ """
+)
+display(merge_info)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Create a custom metric
+# MAGIC
+# MAGIC Customer metrics can be defined and will automatically be calculated by lakehouse monitoring. They often serve as a mean to capture some aspect of business logic or use a custom model quality score. See the documentation for more details about how to create custom metrics ([AWS](https://docs.databricks.com/lakehouse-monitoring/custom-metrics.html)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/custom-metrics)).
+# MAGIC
+# MAGIC In this example, we will calculate the business impact (the overdraft balance amount) of a bad model performance.
+
+# COMMAND ----------
+
+from pyspark.sql.types import DoubleType, StructField
+from databricks.sdk.service.catalog import MonitorMetric, MonitorMetricType
+
+CUSTOM_METRICS = [
+ MonitorMetric(
+ type=MonitorMetricType.CUSTOM_METRIC_TYPE_AGGREGATE,
+ name="avg_overdraft_balance_amt",
+ input_columns=[":table"],
+ definition="""avg(CASE
+ WHEN {{prediction_col}} != {{label_col}} AND {{label_col}} = 1 THEN overdraft_balance_amount
+ ELSE 0 END
+ )""",
+ output_data_type= StructField("output", DoubleType()).json()
+ )
+]
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create the monitor
+# MAGIC Use `InferenceLog` type analysis.
+# MAGIC
+# MAGIC **Make sure to drop any column that you don't want to track or which doesn't make sense from a business or use-case perspective**, otherwise create a VIEW with only columns of interest and monitor it.
+
+# COMMAND ----------
+
+from databricks.sdk import WorkspaceClient
+from databricks.sdk.service.catalog import MonitorInferenceLog, MonitorInferenceLogProblemType, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric
+
+w = WorkspaceClient()
+
+# COMMAND ----------
+
+# Delete any axisting monitor
+
+try:
+ w.quality_monitors.delete(table_name=TABLE_NAME)
+except:
+ print("Monitor doesn't exist.")
+
+# COMMAND ----------
+
+import os
+
+# ML problem type, either "classification" or "regression"
+PROBLEM_TYPE = MonitorInferenceLogProblemType.PROBLEM_TYPE_CLASSIFICATION
+
+# Window sizes to analyze data over
+GRANULARITIES = ["1 day"]
+
+# Directory to store generated dashboard
+ASSETS_DIR = f"{os.getcwd()}/monitoring"
+
+# Optional parameters
+SLICING_EXPRS = ["age<25", "age>60"] # Expressions to slice data with
+
+# COMMAND ----------
+
+# DBTITLE 1,Create Monitor
+print(f"Creating monitor for {TABLE_NAME}")
+
+info = w.quality_monitors.create(
+ table_name=TABLE_NAME,
+ inference_log=MonitorInferenceLog(
+ timestamp_col=TIMESTAMP_COL,
+ granularities=GRANULARITIES,
+ model_id_col=MODEL_ID_COL, # Model version number
+ prediction_col=PREDICTION_COL,
+ problem_type=PROBLEM_TYPE,
+ label_col=LABEL_COL # Optional
+ ),
+ baseline_table_name=BASELINE_TABLE,
+ slicing_exprs=SLICING_EXPRS,
+ output_schema_name=f"{catalog}.{db}",
+ custom_metrics=CUSTOM_METRICS,
+ assets_dir=ASSETS_DIR
+)
+
+# COMMAND ----------
+
+import time
+
+# Wait for monitor to be created
+while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
+ info = w.quality_monitors.get(table_name=TABLE_NAME)
+ time.sleep(10)
+
+assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
+
+# COMMAND ----------
+
+# A metric refresh will automatically be triggered on creation
+refreshes = w.quality_monitors.list_refreshes(table_name=TABLE_NAME).refreshes
+assert(len(refreshes) > 0)
+
+run_info = refreshes[0]
+while run_info.state in (MonitorRefreshInfoState.PENDING, MonitorRefreshInfoState.RUNNING):
+ run_info = w.quality_monitors.get_refresh(table_name=TABLE_NAME, refresh_id=run_info.refresh_id)
+ time.sleep(30)
+
+assert run_info.state == MonitorRefreshInfoState.SUCCESS, "Monitor refresh failed"
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC To view the dashboard, click **Dashboards** in the left nav bar.
+# MAGIC
+# MAGIC You can also navigate to the dashboard from the primary table in the Catalog Explorer UI. On the **Quality** tab, click the **View dashboard** button.
+# MAGIC
+# MAGIC For details, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-dashboard.html) | [Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-dashboard)).
+# MAGIC
+
+# COMMAND ----------
+
+w.quality_monitors.get(table_name=TABLE_NAME)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Inspect the metrics tables
+# MAGIC
+# MAGIC By default, the metrics tables are saved in the default database.
+# MAGIC
+# MAGIC The `create_monitor` call created two new tables: the profile metrics table and the drift metrics table.
+# MAGIC
+# MAGIC These two tables record the outputs of analysis jobs. The tables use the same name as the primary table to be monitored, with the suffixes `_profile_metrics` and `_drift_metrics`.
+
+# COMMAND ----------
+
+# MAGIC %md ### Orientation to the profile metrics table
+# MAGIC
+# MAGIC The profile metrics table has the suffix `_profile_metrics`. For a list of statistics that are shown in the table, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-output.html#profile-metrics-table)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-output#profile-metrics-table)).
+# MAGIC
+# MAGIC - For every column in the primary table, the profile table shows summary statistics for the baseline table and for the primary table. The column `log_type` shows `INPUT` to indicate statistics for the primary table, and `BASELINE` to indicate statistics for the baseline table. The column from the primary table is identified in the column `column_name`.
+# MAGIC - For `TimeSeries` type analysis, the `granularity` column shows the granularity corresponding to the row. For baseline table statistics, the `granularity` column shows `null`.
+# MAGIC - The table shows statistics for each value of each slice key in each time window, and for the table as whole. Statistics for the table as a whole are indicated by `slice_key` = `slice_value` = `null`.
+# MAGIC - In the primary table, the `window` column shows the time window corresponding to that row. For baseline table statistics, the `window` column shows `null`.
+# MAGIC - Some statistics are calculated based on the table as a whole, not on a single column. In the column `column_name`, these statistics are identified by `:table`.
+
+# COMMAND ----------
+
+# Display profile metrics table
+profile_table = f"{TABLE_NAME}_profile_metrics"
+profile_df = spark.sql(f"SELECT * FROM {profile_table}")
+display(profile_df)
+
+# COMMAND ----------
+
+# MAGIC %md ### Orientation to the drift metrics table
+# MAGIC
+# MAGIC The drift metrics table has the suffix `_drift_metrics`. For a list of statistics that are shown in the table, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-output.html#drift-metrics-table)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-output#drift-metrics-table)).
+# MAGIC
+# MAGIC - For every column in the primary table, the drift table shows a set of metrics that compare the current values in the table to the values at the time of the previous analysis run and to the baseline table. The column `drift_type` shows `BASELINE` to indicate drift relative to the baseline table, and `CONSECUTIVE` to indicate drift relative to a previous time window. As in the profile table, the column from the primary table is identified in the column `column_name`.
+# MAGIC - At this point, because this is the first run of this monitor, there is no previous window to compare to. So there are no rows where `drift_type` is `CONSECUTIVE`.
+# MAGIC - For `TimeSeries` type analysis, the `granularity` column shows the granularity corresponding to that row.
+# MAGIC - The table shows statistics for each value of each slice key in each time window, and for the table as whole. Statistics for the table as a whole are indicated by `slice_key` = `slice_value` = `null`.
+# MAGIC - The `window` column shows the the time window corresponding to that row. The `window_cmp` column shows the comparison window. If the comparison is to the baseline table, `window_cmp` is `null`.
+# MAGIC - Some statistics are calculated based on the table as a whole, not on a single column. In the column `column_name`, these statistics are identified by `:table`.
+
+# COMMAND ----------
+
+# Display the drift metrics table
+drift_table = f"{TABLE_NAME}_drift_metrics"
+display(spark.sql(f"SELECT * FROM {drift_table}"))
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Look at fairness and bias metrics
+# MAGIC Fairness and bias metrics are calculated for boolean type slices that were defined. The group defined by `slice_value=true` is considered the protected group ([AWS](https://docs.databricks.com/en/lakehouse-monitoring/fairness-bias.html)|[Azure](https://learn.microsoft.com/en-us/azure/databricks/lakehouse-monitoring/fairness-bias)).
+
+# COMMAND ----------
+
+fb_cols = ["window", "model_id", "slice_key", "slice_value", "predictive_parity", "predictive_equality", "equal_opportunity", "statistical_parity"]
+fb_metrics_df = profile_df.select(fb_cols).filter(f"column_name = ':table' AND slice_value = 'true'")
+display(fb_metrics_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create Alert for changes in model behavior
+# MAGIC
+# MAGIC Now that we have set up the components to constantly monitor the model's behavior, we can set up alerts to notify us of significant changes.
+# MAGIC
+# MAGIC Run the following cell and you will find a SQL Query and an Alert created for you in the `monitoring` folder.
+# MAGIC
+# MAGIC The query retrieves key model KPIs from the monitor's metric table, and the Alert will be triggered when the rules defined over the query's results are violated. Our exmample shows an Alert that is triggered when the model's F1 score falls below a threshold:
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC Check them out in the `monitoring` folder.
+# MAGIC - Open the Alert `rai_credit_decisioning_accuracy_alert` to inspect its definition
+# MAGIC - Open the query `rai_credit_decisioning_performance_last_window` and run it to inspect its results
+# MAGIC
+# MAGIC You can create your own queries and alerts using the UI.
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/02-create-monitoring-query-and-alert
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Conclusion
+# MAGIC
+# MAGIC With this **Model Monitoring** notebook, we complete our end-to-end journey of building a **Responsible Credit Scoring Model** on the Databricks Data Intelligence Platform. Our approach ensures that the credit decisioning process is:
+# MAGIC
+# MAGIC - **Transparent:** Through explainability and bias monitoring at every stage.
+# MAGIC - **Effective:** By continuously evaluating model performance and recalibrating as needed.
+# MAGIC - **Reliable:** Through proactive drift detection, compliance validation, and automated retraining.
+# MAGIC
+# MAGIC By leveraging **Databricks Data Intelligence Platform**, we demonstrate how Responsible AI is more than just a compliance requirement—it is a fundamental pillar for building **trustworthy and value-driven machine learning solutions**. This monitoring framework ensures that our model remains **fair, accountable, and high-performing**, delivering long-term value to both the bank and its customers.
+# MAGIC
+# MAGIC With this, we conclude our **Responsible AI demo**. Thank you for exploring this journey with us!
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
similarity index 69%
rename from demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py
rename to demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
index a2af3b44..1f24f440 100644
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
@@ -1,6 +1,11 @@
# Databricks notebook source
+# MAGIC %md
+# MAGIC
+
+# COMMAND ----------
+
# MAGIC %md-sandbox
-# MAGIC # Data Intelligence Platform for Financial Services - Serving the Underbanked population with the Databricks Lakehouse
+# MAGIC # Data Intelligence Platform for Financial Services - Serving the Underbanked population
# MAGIC
# MAGIC
# MAGIC
@@ -22,15 +27,6 @@
# COMMAND ----------
-# MAGIC %md
-# MAGIC
-# MAGIC # Raising Interest Rates - an opportunity or a threat?
-# MAGIC
-# MAGIC The current raising interest rates can be both a great opportunity for retail banks and other FS organizations to increase their revenues from their credit instruments (such as loans, mortgages, and credit cards) but also a risk for larger losses as customers might end up unable to repay credits with higher rates. In the current market conditions, FS companies need better credit scoring and decisioning models and approaches. Such models, however, are very difficult to achieve as financial information might be insufficient or siloed.
-# MAGIC ####
In its essence, good credit decisioning is a massive data curation exercise.
-
-# COMMAND ----------
-
# MAGIC %md-sandbox
# MAGIC ## DEMO: upsell your underbanked customers and reduce your risk through better credit scoring models
# MAGIC
@@ -65,7 +61,7 @@
# MAGIC
2
Secure data and grant read access to the Data Analyst and Data Science teams, including row- and column-level filtering, PII data masking, and others (data security and control)
# MAGIC
3
Use the Databricks unified data lineage to understand how your data flows and is used in your organisation
# MAGIC
4
Run BI queries and EDA to analyze existing credit risk
-# MAGIC
5
Build ML model to predict credit worthiness of underbanked customers, evaluate the risk of current debt-holders, and deploy ML models for real-time serving in order to enable Buy Now, Pay Later use cases
+# MAGIC
5
Build and deploy responsibly governed ML models that assess creditworthiness of underbanked customers and evaluate the risk of existing debt-holders. Ensure real-time, trustworthy decisioning for Buy Now, Pay Later-like use cases through unified model training, monitoring, and governance—promoting fairness, transparency, and compliance across the AI lifecycle.
# MAGIC
6
Visualise your business models along with all actionable insights coming from machine learning
# MAGIC
7
Provide an easy and simple way to securely share these insights to non-data users, such as bank tellers, call center agents, or credit agents (data democratization)
# MAGIC
@@ -112,57 +108,35 @@
# COMMAND ----------
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## 3: ML - Building a credit scoring model to predict payment defaults, reduce loss, and upsell
-# MAGIC
-# MAGIC Now that our data is ready and secured, let's create a model to predict the risk and potential default of current creditholders and potential new customers.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC To do that, we'll leverage the data previously ingested, analyze, and save the features set within Databricks feature store.
-# MAGIC
-# MAGIC Databricks AutoML will then accelerate our ML journey by creating state of the art Notebooks that we'll use to deploy our model in production within MLFlow Model registry.
-# MAGIC
-# MAGIC
-# MAGIC Once our is model ready, we'll leverage it to:
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
Score, analyze, and target our existing customer database
-# MAGIC
-# MAGIC Once our model is created and deployed in production within Databricks Model registry, we can use it to run batch inference.
-# MAGIC
-# MAGIC The model outcome will be available for our Analysts to implement new use cases, such as upsell or risk exposure analysis (see below for more details).
-# MAGIC
-# MAGIC
Deploy our model for Real time model serving, allowing Buy Now, Pay Later (BNPL)
-# MAGIC
-# MAGIC Leveraging Databricks Lakehouse, we can deploy our model to provide real-time serving over REST API.
-# MAGIC This will allow us to give instant results on credit requests, allowing customers to automatically open a new credit while reducing payment default risks.
+# MAGIC %md
+# MAGIC ## 3: Responsible AI with the Databricks Data Intelligence Platform
# MAGIC
+# MAGIC Databricks emphasizes trust in AI by enabling organizations to maintain ownership and control over their data and models. [Databricks Data Intelligence Platform](https://www.databricks.com/product/data-intelligence-platform) unifies data, model training, management, monitoring, and governance across the AI lifecycle. This approach ensures that systems are **high-quality**, **safe**, and **well-governed**, helping organizations implement responsible AI practices effectively while fostering trust in intelligent applications.
# MAGIC
-# MAGIC
Ensure model Explainability and Fairness
+# MAGIC To accomplish these objectives responsibly, we’ll construct an end-to-end solution on the Databricks Data Intelligence platform, with a strong focus on transparency, fairness, and governance at each step. Specifically, we will:
# MAGIC
-# MAGIC An important part of every regulated industry use case is the ability to explain the decisions taken through data and AI; and to also be able to evaluate the fairness of the model and identify whether it disadvantages certain people or groups of people.
+# MAGIC - Run exploratory analysis to identify anomalies, biases, and data drift early, paving the way for responsible feature engineering.
+# MAGIC - Continuously update features and log transformations for full lineage and compliance.
+# MAGIC - Train and evaluate models against fairness and accuracy criteria, logging artifacts for reproducibility.
+# MAGIC - Validate models by performing compliance checks and pre-deployment tests, ensuring alignment with Responsible AI standards.
+# MAGIC - Integrate champion and challenger models to deploy the winning solution, maintaining traceability and accountability at each decision point.
+# MAGIC - Provide batch or real-time inference with robust explainability.
+# MAGIC - Monitor production models to detect data drift, alert on performance decay, and trigger recalibration workflows whenever the model’s effectiveness declines.
# MAGIC
-# MAGIC The demo shows how to add explainability and fairness to the final dashboard:
+# MAGIC
# MAGIC
-# MAGIC 1. Feature importance and SHAP ratios charts are added to provide an overall understanding as to what are the drivers and root causes behind credit worthiness and defaults, so the bank can take appropriate measures,
-# MAGIC 2. Detailed fairness like gender fairness score and a breakdown of different demographic features, such as education, marital status, and residency.
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
+# MAGIC With this approach, we can confidently meet regulatory and ethical benchmarks while improving organizational outcomes—demonstrating that Responsible AI is not just about checking boxes but about building trust and value across the entire ML lifecycle.
# MAGIC
-# MAGIC #### Machine Learning next steps:
+# MAGIC Below is a concise overview of each notebook’s role in the Responsible AI pipeline, as depicted in the architecture diagram. Together, they illustrate how Databricks supports transparency (explainability), effectiveness (model performance and bias control), and reliability (ongoing monitoring) throughout the model lifecycle.
# MAGIC
-# MAGIC * [03.1-Feature-Engineering-credit-decisioning]($./03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning): Open the first notebook to analyze our data and start building our model leveraging Databricks Feature Store and AutoML.
-# MAGIC * [03.2-AutoML-credit-decisioning]($./03-Data-Science-ML/03.2-AutoML-credit-decisioning): Leverage AutoML to accelerate your model creation.
-# MAGIC * [03.3-Batch-Scoring-credit-decisioning]($./03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning): score our entire dataset and save the result as a new delta table for downstream usage.
-# MAGIC * [03.4-model-serving-BNPL-credit-decisioning]($./03-Data-Science-ML/03.4-model-serving-BNPL-credit-decisioning): leverage Databricks Serverless model serving to deploy a Buy Now Pay Later offers (including AB testing).
-# MAGIC * [03.5-Explainability-and-Fairness-credit-decisioning]($./03-Data-Science-ML/03.5-Explainability-and-Fairness-credit-decisioning): Explain your model and review fairness.
+# MAGIC * [03.1-Exploratory-Analysis]($./03-Data-Science-ML/03.1-Exploratory-Analysis-credit-decisioning): Examines data distributions and identifies biases or anomalies, providing transparency early in the lifecycle. Sets the stage for responsible feature selection and model design.
+# MAGIC * [03.2-Feature-Updates]($./03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning): Continuously ingests new data, refreshes features, and logs transformations, ensuring model effectiveness. Maintains transparency around feature lineage for compliance and traceability.
+# MAGIC * [03.3-Model-Training]($./03-Data-Science-ML/03.3-Model-Training-credit-decisioning): Trains, evaluates, and documents candidate models, tracking performance and fairness metrics. Stores artifacts for reproducibility, aligning with responsible AI goals.
+# MAGIC * [03.4-Model-Validation]($./03-Data-Science-ML/03.4-Model-Validation-credit-decisioning): Performs compliance checks, pre-deployment tests, and fairness evaluations. Verifies reliability and transparency standards before the model progresses to production.
+# MAGIC * [03.5-Model-Integration]($./03-Data-Science-ML/03.5-Model-Integration-credit-decisioning): Compares champion and challenger models, enabling human oversight for final selection. Deploys the chosen pipeline responsibly, ensuring accountability at each handoff.
+# MAGIC * [03.6-Model-Inference]($./03-Data-Science-ML/03.6-Model-Inference-credit-decisioning): Executes batch or real-time predictions using the deployed model. Ensures outputs remain consistent and explainable for responsible decision-making.
+# MAGIC * [03.7-Model-Monitoring]($./03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning): Continuously tracks data drift, prediction stability, and performance degradation. Generates alerts for timely retraining, preserving reliability and trustworthiness across the model’s lifecycle.
# COMMAND ----------
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/01-load-data.py b/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/01-load-data.py
index c8fe91a5..86ba8e4b 100644
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/01-load-data.py
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/01-load-data.py
@@ -108,7 +108,8 @@ def save_features_def():
rcvd_amt_avg_6m,Incoming average transaction amount in last 6 months
months_employment,Months in employment
is_resident,Whether the customer is a resident
- age,Customer age"""
+ age,Customer age
+ gender,Customer gender"""
from io import StringIO
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/02-create-monitoring-query-and-alert.ipynb b/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/02-create-monitoring-query-and-alert.ipynb
new file mode 100644
index 00000000..81fdb0b0
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/02-create-monitoring-query-and-alert.ipynb
@@ -0,0 +1,429 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "e4ac343e-8bde-45d0-85e3-2b1026a59b6a",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ },
+ "jupyter": {
+ "outputs_hidden": true
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Commenting this out.\n",
+ "# This notebook is called from the 06.7 Model Monitoring notebook in the RAI demo\n",
+ "# At the point where it is called, the config variables would have been initiazliazed\n",
+ "#%run ../config"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "e94efbc2-5730-450f-87a3-41896e7629a1",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Initialize worksace client\n",
+ "from databricks.sdk import WorkspaceClient\n",
+ "from databricks.sdk.service import sql\n",
+ "\n",
+ "w = WorkspaceClient()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "4c6c4c12-9e87-4598-bc97-357e1141038d",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Set demo variable names\n",
+ "rai_demo_folder_name = \"06-Responsible-AI\"\n",
+ "inference_log_table_name = f\"{catalog}.{db}.credit_decisioning_inferencelogs\"\n",
+ "inference_log_profile_table_name = f\"{inference_log_table_name}_profile_metrics\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "49ed0f1e-83ab-428b-baf1-0a04362a57a5",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# SQL statement for the query used for the alert\n",
+ "sql_query = f\"\"\"\n",
+ "WITH \n",
+ "profile_metrics AS (\n",
+ " SELECT * FROM {inference_log_profile_table_name}\n",
+ " WHERE isnull(slice_key) AND isnull(slice_value) -- default to \"No Slice\"\n",
+ " AND `model_id` = \"*\" -- default to all model ids\n",
+ "),\n",
+ "last_window_in_inspection_range AS (\n",
+ " SELECT window.start AS Window, granularity AS Granularity FROM profile_metrics\n",
+ " WHERE window.start = (SELECT MAX(window.start) FROM profile_metrics) \n",
+ " ORDER BY Granularity LIMIT 1 -- order to ensure the `granularity` selected is stable\n",
+ "),\n",
+ "profile_metrics_inspected AS (\n",
+ " SELECT * FROM profile_metrics\n",
+ " WHERE Granularity = (SELECT Granularity FROM last_window_in_inspection_range)\n",
+ ")\n",
+ "SELECT\n",
+ " concat(window.start,\" - \", window.end) AS Window,\n",
+ " ROUND(accuracy_score, 2) as accuracy_score,\n",
+ " ROUND(precision.macro,2) as precision_macro,\n",
+ " ROUND(precision.weighted,2) as precision_weighted,\n",
+ " ROUND(recall.macro,2) as recall_macro,\n",
+ " ROUND(recall.weighted,2) as recall_weighted,\n",
+ " ROUND(f1_score.macro, 2) as f1_score_macro,\n",
+ " ROUND(f1_score.weighted, 2) as f1_score_weighted,\n",
+ " granularity AS Granularity,\n",
+ " `model_id` AS `Model Id`,\n",
+ " COALESCE(slice_key, \"No slice\") AS `Slice key`,\n",
+ " COALESCE(slice_value, \"No slice\") AS `Slice value`\n",
+ "FROM profile_metrics_inspected\n",
+ "WHERE\n",
+ " window.start = (SELECT Window FROM last_window_in_inspection_range) -- limit to last window\n",
+ " AND log_type = \"INPUT\"\n",
+ " AND column_name = \":table\"\n",
+ "ORDER BY slice_key ASC\n",
+ "\"\"\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "e21a8402-6ff0-4184-8060-0e9beeb51b67",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import re\n",
+ "\n",
+ "# Determine path to save query and alert\n",
+ "\n",
+ "notebook_path = dbutils.notebook.entry_point.getDbutils().notebook().getContext().notebookPath().getOrElse(None)\n",
+ "path_parts = re.split('/', notebook_path)\n",
+ "# Remove last 2 elements: notebook name and its folder. This brings us to the lakehouse-fsi-credit-decisioning level\n",
+ "del path_parts[-2:]\n",
+ "path_parts.append(rai_demo_folder_name)\n",
+ "\n",
+ "monitoring_assets_path = '/Workspace' + '/'.join(path_parts) + '/monitoring'\n",
+ "\n",
+ "print(f\"Monitoring assets will be saved in {monitoring_assets_path}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "3bacd031-e79f-472a-8822-4d4189c0d01e",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "import requests\n",
+ "import json\n",
+ "\n",
+ "# Function to set up parameters\n",
+ "def setup_rest_params(endpoint_name):\n",
+ " # Get the workspace URL from the Databricks notebook context\n",
+ " DATABRICKS_HOST = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().getOrElse(None)\n",
+ " # print(f\"DATABRICKS_HOST: {DATABRICKS_HOST}\")\n",
+ "\n",
+ " # Define the endpoint_url\n",
+ " endpoint_url = f\"{DATABRICKS_HOST}/api/2.0/sql\"\n",
+ "\n",
+ " # Get the API key from the Databricks notebook context | You can also use PAT (Personal Access Token) or Service Principal Token for the API key required to access the REST API.\n",
+ " api_key = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().getOrElse(None)\n",
+ "\n",
+ " # Define the headers\n",
+ " headers = {\n",
+ " \"Authorization\": f\"Bearer {api_key}\",\n",
+ " \"Content-Type\": \"application/json\"\n",
+ " }\n",
+ " \n",
+ " return endpoint_url, headers\n",
+ "\n",
+ "\n",
+ "# Send Databricks SQL REST API request\n",
+ "def send_request(api_name, request_body):\n",
+ " assert api_name in [\"queries\", \"alerts\", \"warehouses\"], \"Invalid API name. Must be either 'queries' or 'alerts'.\"\n",
+ "\n",
+ " endpoint_url, headers = setup_rest_params(endpoint_name)\n",
+ "\n",
+ " response = requests.post(f\"{endpoint_url}/{api_name}\", headers=headers, data=json.dumps(request_body))\n",
+ " response.raise_for_status() # Raise an exception for HTTP errors\n",
+ " return response.json()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "943330c6-bb08-4735-ac2d-98b1655b90db",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Get a serverless warehouse\n",
+ "# Note that the user has to have manage permissions on it\n",
+ "warehouse_id = None\n",
+ "wh = w.warehouses.list()\n",
+ "for warehouse in wh:\n",
+ " warehouse.enable_serverless_compute = True\n",
+ " serverless_wh = warehouse\n",
+ " break\n",
+ "warehouse_id = serverless_wh.id"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "7e409f12-8d7c-4470-aac2-43d4d5e26473",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Payload for the request to create the SQL query\n",
+ "sql_query_request_body = {\n",
+ " \"query\": {\n",
+ " \"display_name\": \"rai_credit_decisioning_performance_last_window\",\n",
+ " \"description\": \"Inference metrics for last window\",\n",
+ " \"query_text\": sql_query,\n",
+ " \"parent_path\": monitoring_assets_path,\n",
+ " \"warehouse_id\": warehouse_id,\n",
+ " \"run_as_mode\": \"OWNER\",\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "c74ac0a7-9412-4259-8e14-1ca386e0eead",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Create the SQL query\n",
+ "try:\n",
+ " response = send_request(\"queries\", sql_query_request_body)\n",
+ " print(f\"SQL query '{response['display_name']}' created successfully in the 'monitoring' folder. ID: {response['id']}.\")\n",
+ "except Exception as e:\n",
+ " print(f\"Cannot create SQL query. Error: {e}\")\n",
+ "\n",
+ "query_id = response.get(\"id\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "1599cbc6-9e34-4a0a-a353-2ab7a2343d1e",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Payload for the request to create the SQL alert\n",
+ "sql_alert_request_body = {\n",
+ " \"alert\": {\n",
+ " \"seconds_to_retrigger\": 0,\n",
+ " \"display_name\": \"rai_credit_decisioning_accuracy_alert\",\n",
+ " \"condition\": {\n",
+ " \"op\": \"LESS_THAN\",\n",
+ " \"operand\": {\"column\": {\"name\": \"f1_score_weighted\"}},\n",
+ " \"threshold\": {\"value\": {\"double_value\": 0.9}},\n",
+ " },\n",
+ " \"query_id\": query_id,\n",
+ " \"parent_path\": monitoring_assets_path,\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "554a5c14-0c38-4b25-a5b0-aaaf8618bbbd",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Create the alert\n",
+ "try:\n",
+ " response = send_request(\"alerts\", sql_alert_request_body)\n",
+ " print(f\"SQL alert '{response['display_name']}' created successfully in the 'monitoring' folder. ID: {response['id']}.\")\n",
+ "except Exception as e:\n",
+ " print(f\"Cannot create SQL alert. Error: {e}\")\n",
+ "\n",
+ "alert_id = response.get(\"id\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "application/vnd.databricks.v1+cell": {
+ "cellMetadata": {
+ "byteLimit": 2048000,
+ "rowLimit": 10000
+ },
+ "inputWidgets": {},
+ "nuid": "b6c99b03-b57d-4f9e-861e-c91ad3fb7083",
+ "showTitle": false,
+ "tableResultSettingsMap": {},
+ "title": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# from databricks.sdk import WorkspaceClient\n",
+ "# from databricks.sdk.service import sql\n",
+ "\n",
+ "# w = WorkspaceClient()\n",
+ "\n",
+ "# w.queries.delete(query_id)\n",
+ "# w.alerts.delete(alert_id)"
+ ]
+ }
+ ],
+ "metadata": {
+ "application/vnd.databricks.v1+notebook": {
+ "computePreferences": null,
+ "dashboards": [],
+ "environmentMetadata": {
+ "base_environment": "",
+ "environment_version": "2"
+ },
+ "inputWidgetPreferences": null,
+ "language": "python",
+ "notebookMetadata": {
+ "mostRecentlyExecutedCommandWithImplicitDF": {
+ "commandId": 893528767941288,
+ "dataframes": [
+ "_sqldf"
+ ]
+ },
+ "pythonIndentUnit": 2
+ },
+ "notebookName": "02-create-monitoring-query-and-alert",
+ "widgets": {}
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/bundle_config.py b/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/bundle_config.py
index 8d997715..f045bcbc 100644
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/bundle_config.py
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/_resources/bundle_config.py
@@ -14,7 +14,7 @@
"default_catalog": "main",
"default_schema": "dbdemos_fsi_credit_decisioning",
"description": "Build your banking data platform and identify credit worthy customers",
- "fullDescription": "The Databricks Lakehouse Platform is an open architecture that combines the best elements of data lakes and data warehouses. In this demo, we'll show you how to build an end-to-end credit decisioning system for underbanked customers, delivering data and insights that would typically take months of effort on legacy platforms.
This demo covers the end to end lakehouse platform:
Ingest both internal and partner data, and then transform them using Delta Live Tables (DLT), a declarative ETL framework for building reliable, maintainable, and testable data processing pipelines.
Secure our ingested data to ensure governance and security on top of PII data
Build a Machine Learning model with Databricks AutoML to identify credit worthy customers
Leverage Databricks DBSQL and the warehouse endpoints to build dashboard to analyze the ingested data and explain the machine learning model outputs
Orchestrate all these steps with Databricks Workflow
",
+ "fullDescription": "The Databricks Lakehouse Platform is an open architecture that combines the best elements of data lakes and data warehouses. In this demo, we'll show you how to build an end-to-end credit decisioning system for underbanked customers, delivering data and insights that would typically take months of effort on legacy platforms.
This demo covers the end to end lakehouse platform:
Ingest both internal and partner data, and then transform them using Delta Live Tables (DLT), a declarative ETL framework for building reliable, maintainable, and testable data processing pipelines.
Secure our ingested data to ensure governance and security on top of PII data
Build and deploy responsibly governed ML models that assess creditworthiness of customers
Leverage Databricks DBSQL and the warehouse endpoints to build dashboard to analyze the ingested data and explain the machine learning model outputs
Orchestrate all these steps with Databricks Workflow
 +
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Security and Table Access Controls
+# MAGIC
+# MAGIC Before proceeding with data exploration, it is crucial to implement security and access controls to ensure data integrity and compliance. Proper security measures help:
+# MAGIC
+# MAGIC - Protect sensitive financial and customer data, preventing unauthorized access and ensuring regulatory adherence.
+# MAGIC - Ensure data consistency, so analysts work with validated and high-quality data without discrepancies.
+# MAGIC - Avoid data leakage risks, preventing the unintentional exposure of confidential information that could lead to compliance violations.
+# MAGIC - Facilitate accountability, ensuring that any modifications or transformations are logged and traceable.
+# MAGIC
+# MAGIC By establishing a secure data foundation, we ensure that subsequent analysis and modeling steps are performed responsibly, with complete confidence in data integrity and compliance.
+# MAGIC
+# MAGIC Table Access Control (TAC) in Databricks lets administrators manage access to specific tables and columns, controlling permissions like read, write, or modify. Integrated with Unity Catalog, it allows fine-grained security to protect sensitive data and ensure only authorized users have access. This feature enhances data governance, compliance, and secure collaboration across the platform.
+# MAGIC
+# MAGIC Now, let's grant only a ```SELECT``` access to ```customer_gold``` table to everyone in the group ```Data Scientist```.
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC
+# MAGIC GRANT SELECT ON TABLE customer_gold TO `Data Scientist`
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Exploratory Data Analysis
+# MAGIC
+# MAGIC The first step as Data Scientist is to explore and understand the data. [Databricks Notebooks](https://docs.databricks.com/en/notebooks/index.html) offer native data quality profiling and dashboarding capabilities that allow users to easily assess and visualize the quality of their data. Built-in tools allows us to:
+# MAGIC - Identify missing values and potential data quality issues.
+# MAGIC - Detect outliers and anomalies that may skew model predictions.
+# MAGIC - Assess statistical distributions of key features to uncover potential biases.
+# MAGIC
+# MAGIC Databricks enables scalable EDA through interactive notebooks, where we can visualize distributions, perform statistical tests, and generate summary reports seamlessly.
+
+# COMMAND ----------
+
+# DBTITLE 1,Use SQL to explore your data
+# MAGIC %sql
+# MAGIC SELECT * FROM customer_gold
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC While Databricks provides built-in data profiling tools, additional Python libraries such as Plotly and Seaborn can be used to enhance analysis. These libraries allow for more interactive and customizable visualizations, helping uncover hidden patterns in the data.
+# MAGIC
+# MAGIC Using these additional libraries in combination with Databricks' built-in capabilities ensures a more comprehensive data exploration process, leading to better insights for responsible model development.
+
+# COMMAND ----------
+
+# DBTITLE 1,Use any of your usual python libraries for analysis
+data = spark.table("customer_gold") \
+ .where("tenure_months BETWEEN 10 AND 150") \
+ .groupBy("tenure_months", "education").sum("income_monthly") \
+ .orderBy('education').toPandas()
+
+px.bar(data, x="tenure_months", y="sum(income_monthly)", color="education", title="Total Monthly Income")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Class representation
+# MAGIC
+# MAGIC Understanding class representation during exploratory data analysis is crucial for identifying potential bias in data. Imbalanced classes can lead to biased models, where underrepresented classes are poorly learned, resulting in inaccurate predictions. If certain groups are over- or underrepresented, the model may inherit societal biases, leading to unfair outcomes. Identifying skewed distributions helps in selecting appropriate resampling techniques or adjusting model evaluation metrics. Moreover, biased training data can reinforce discrimination in applications like credit decisioning. Detecting imbalance early allows for corrective actions, ensuring a more robust, fair, and generalizable model that performs well across all classes.
+
+# COMMAND ----------
+
+data = spark.table("customer_gold") \
+ .groupBy("gender").count() \
+ .orderBy('gender').toPandas()
+
+px.pie(data_frame=data, names="gender", values="count", color="gender", title="Percentage of Males vs. Females")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC After completing exploratory analysis, we proceed to [06.2-Feature-Updates]($./06-Responsible-AI/06.2-Feature-Updates), where we:
+# MAGIC - Continuously ingest new data to keep features relevant and up to date.
+# MAGIC - Apply responsible transformations while maintaining full lineage and compliance.
+# MAGIC - Log feature changes to ensure transparency in model evolution.
+# MAGIC
+# MAGIC By systematically updating features, we reinforce responsible AI practices and enhance our credit scoring model’s fairness, reliability, and effectiveness.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py
deleted file mode 100644
index d267e52e..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py
+++ /dev/null
@@ -1,180 +0,0 @@
-# Databricks notebook source
-# MAGIC %md
-# MAGIC
-# MAGIC # ML: predict credit owners with high default probability
-# MAGIC
-# MAGIC Once all data is loaded and secured (the **data unification** part), we can proceed to exploring, understanding, and using the data to create actionable insights - **data decisioning**.
-# MAGIC
-# MAGIC
-# MAGIC As outlined in the [introductory notebook]($../00-Credit-Decisioning), we will build machine learning (ML) models for driving three business outcomes:
-# MAGIC 1. Identify currently underbanked customers with high credit worthiness so we can offer them credit instruments,
-# MAGIC 2. Predict current credit owners with high probability of defaulting along with the loss-given default, and
-# MAGIC 3. Offer instantaneous micro-loans (Buy Now, Pay Later) when a customer does not have the required credit limit or account balance to complete a transaction.
-# MAGIC
-# MAGIC Here is the flow we'll implement:
-# MAGIC
-# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Security and Table Access Controls
+# MAGIC
+# MAGIC Before proceeding with data exploration, it is crucial to implement security and access controls to ensure data integrity and compliance. Proper security measures help:
+# MAGIC
+# MAGIC - Protect sensitive financial and customer data, preventing unauthorized access and ensuring regulatory adherence.
+# MAGIC - Ensure data consistency, so analysts work with validated and high-quality data without discrepancies.
+# MAGIC - Avoid data leakage risks, preventing the unintentional exposure of confidential information that could lead to compliance violations.
+# MAGIC - Facilitate accountability, ensuring that any modifications or transformations are logged and traceable.
+# MAGIC
+# MAGIC By establishing a secure data foundation, we ensure that subsequent analysis and modeling steps are performed responsibly, with complete confidence in data integrity and compliance.
+# MAGIC
+# MAGIC Table Access Control (TAC) in Databricks lets administrators manage access to specific tables and columns, controlling permissions like read, write, or modify. Integrated with Unity Catalog, it allows fine-grained security to protect sensitive data and ensure only authorized users have access. This feature enhances data governance, compliance, and secure collaboration across the platform.
+# MAGIC
+# MAGIC Now, let's grant only a ```SELECT``` access to ```customer_gold``` table to everyone in the group ```Data Scientist```.
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC
+# MAGIC GRANT SELECT ON TABLE customer_gold TO `Data Scientist`
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Exploratory Data Analysis
+# MAGIC
+# MAGIC The first step as Data Scientist is to explore and understand the data. [Databricks Notebooks](https://docs.databricks.com/en/notebooks/index.html) offer native data quality profiling and dashboarding capabilities that allow users to easily assess and visualize the quality of their data. Built-in tools allows us to:
+# MAGIC - Identify missing values and potential data quality issues.
+# MAGIC - Detect outliers and anomalies that may skew model predictions.
+# MAGIC - Assess statistical distributions of key features to uncover potential biases.
+# MAGIC
+# MAGIC Databricks enables scalable EDA through interactive notebooks, where we can visualize distributions, perform statistical tests, and generate summary reports seamlessly.
+
+# COMMAND ----------
+
+# DBTITLE 1,Use SQL to explore your data
+# MAGIC %sql
+# MAGIC SELECT * FROM customer_gold
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC While Databricks provides built-in data profiling tools, additional Python libraries such as Plotly and Seaborn can be used to enhance analysis. These libraries allow for more interactive and customizable visualizations, helping uncover hidden patterns in the data.
+# MAGIC
+# MAGIC Using these additional libraries in combination with Databricks' built-in capabilities ensures a more comprehensive data exploration process, leading to better insights for responsible model development.
+
+# COMMAND ----------
+
+# DBTITLE 1,Use any of your usual python libraries for analysis
+data = spark.table("customer_gold") \
+ .where("tenure_months BETWEEN 10 AND 150") \
+ .groupBy("tenure_months", "education").sum("income_monthly") \
+ .orderBy('education').toPandas()
+
+px.bar(data, x="tenure_months", y="sum(income_monthly)", color="education", title="Total Monthly Income")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Class representation
+# MAGIC
+# MAGIC Understanding class representation during exploratory data analysis is crucial for identifying potential bias in data. Imbalanced classes can lead to biased models, where underrepresented classes are poorly learned, resulting in inaccurate predictions. If certain groups are over- or underrepresented, the model may inherit societal biases, leading to unfair outcomes. Identifying skewed distributions helps in selecting appropriate resampling techniques or adjusting model evaluation metrics. Moreover, biased training data can reinforce discrimination in applications like credit decisioning. Detecting imbalance early allows for corrective actions, ensuring a more robust, fair, and generalizable model that performs well across all classes.
+
+# COMMAND ----------
+
+data = spark.table("customer_gold") \
+ .groupBy("gender").count() \
+ .orderBy('gender').toPandas()
+
+px.pie(data_frame=data, names="gender", values="count", color="gender", title="Percentage of Males vs. Females")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC After completing exploratory analysis, we proceed to [06.2-Feature-Updates]($./06-Responsible-AI/06.2-Feature-Updates), where we:
+# MAGIC - Continuously ingest new data to keep features relevant and up to date.
+# MAGIC - Apply responsible transformations while maintaining full lineage and compliance.
+# MAGIC - Log feature changes to ensure transparency in model evolution.
+# MAGIC
+# MAGIC By systematically updating features, we reinforce responsible AI practices and enhance our credit scoring model’s fairness, reliability, and effectiveness.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py
deleted file mode 100644
index d267e52e..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.1-Feature-Engineering-credit-decisioning.py
+++ /dev/null
@@ -1,180 +0,0 @@
-# Databricks notebook source
-# MAGIC %md
-# MAGIC
-# MAGIC # ML: predict credit owners with high default probability
-# MAGIC
-# MAGIC Once all data is loaded and secured (the **data unification** part), we can proceed to exploring, understanding, and using the data to create actionable insights - **data decisioning**.
-# MAGIC
-# MAGIC
-# MAGIC As outlined in the [introductory notebook]($../00-Credit-Decisioning), we will build machine learning (ML) models for driving three business outcomes:
-# MAGIC 1. Identify currently underbanked customers with high credit worthiness so we can offer them credit instruments,
-# MAGIC 2. Predict current credit owners with high probability of defaulting along with the loss-given default, and
-# MAGIC 3. Offer instantaneous micro-loans (Buy Now, Pay Later) when a customer does not have the required credit limit or account balance to complete a transaction.
-# MAGIC
-# MAGIC Here is the flow we'll implement:
-# MAGIC
-# MAGIC 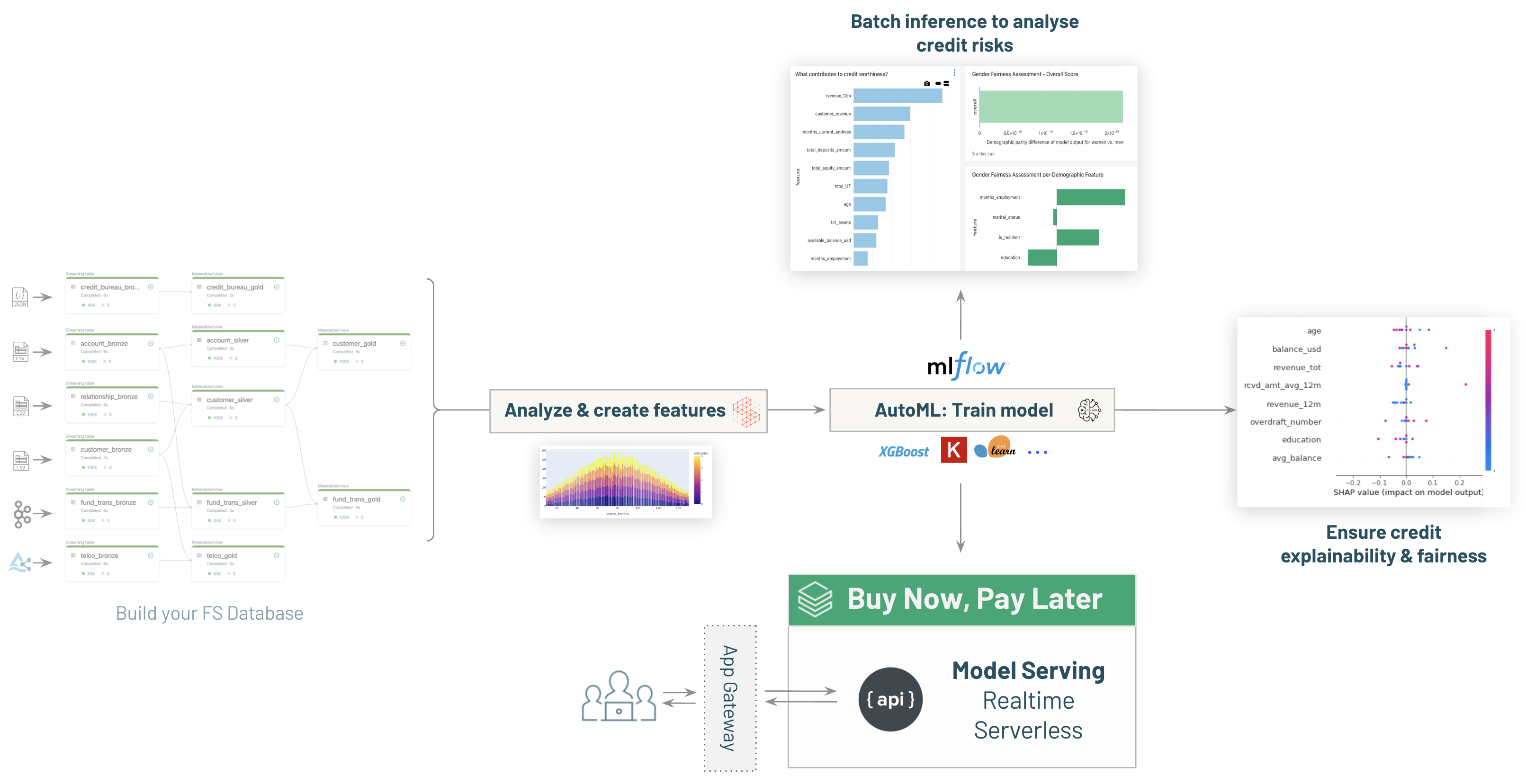 -# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## The need for Enhanced Collaboration
-# MAGIC
-# MAGIC Feature Engineering is an iterative process - we need to quickly generate new features, test the model, and go back to feature selection and more feature engineering - many many times. The Databricks Lakehouse enables data teams to collaborate extremely effectively through the following Databricks Notebook features:
-# MAGIC 1. Sharing and collaborating in the same Notebook by any team member (with different access modes),
-# MAGIC 2. Ability to use python, SQL, and R simultaneously in the same Notebook on the same data,
-# MAGIC 3. Native integration with a Git repository (including AWS Code Commit, Azure DevOps, GitLabs, Github, and others), making the Notebooks tools for CI/CD,
-# MAGIC 4. Variables explorer,
-# MAGIC 5. Automatic Data Profiling (in the cell below), and
-# MAGIC 6. GUI-based dashboards (in the cell below) that can also be added to any Databricks SQL Dashboard.
-# MAGIC
-# MAGIC These features enable teams within FSI organizations to become extremely fast and efficient in building the best ML model at reduced time, thereby making the most out of market opportunities such as the raising interest rates.
-
-# COMMAND ----------
-
-# MAGIC %pip install databricks-sdk==0.36.0 mlflow==2.19.0 databricks-feature-store==0.17.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Data exploration & Features creation
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## The need for Enhanced Collaboration
-# MAGIC
-# MAGIC Feature Engineering is an iterative process - we need to quickly generate new features, test the model, and go back to feature selection and more feature engineering - many many times. The Databricks Lakehouse enables data teams to collaborate extremely effectively through the following Databricks Notebook features:
-# MAGIC 1. Sharing and collaborating in the same Notebook by any team member (with different access modes),
-# MAGIC 2. Ability to use python, SQL, and R simultaneously in the same Notebook on the same data,
-# MAGIC 3. Native integration with a Git repository (including AWS Code Commit, Azure DevOps, GitLabs, Github, and others), making the Notebooks tools for CI/CD,
-# MAGIC 4. Variables explorer,
-# MAGIC 5. Automatic Data Profiling (in the cell below), and
-# MAGIC 6. GUI-based dashboards (in the cell below) that can also be added to any Databricks SQL Dashboard.
-# MAGIC
-# MAGIC These features enable teams within FSI organizations to become extremely fast and efficient in building the best ML model at reduced time, thereby making the most out of market opportunities such as the raising interest rates.
-
-# COMMAND ----------
-
-# MAGIC %pip install databricks-sdk==0.36.0 mlflow==2.19.0 databricks-feature-store==0.17.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Data exploration & Features creation
-# MAGIC
-# MAGIC 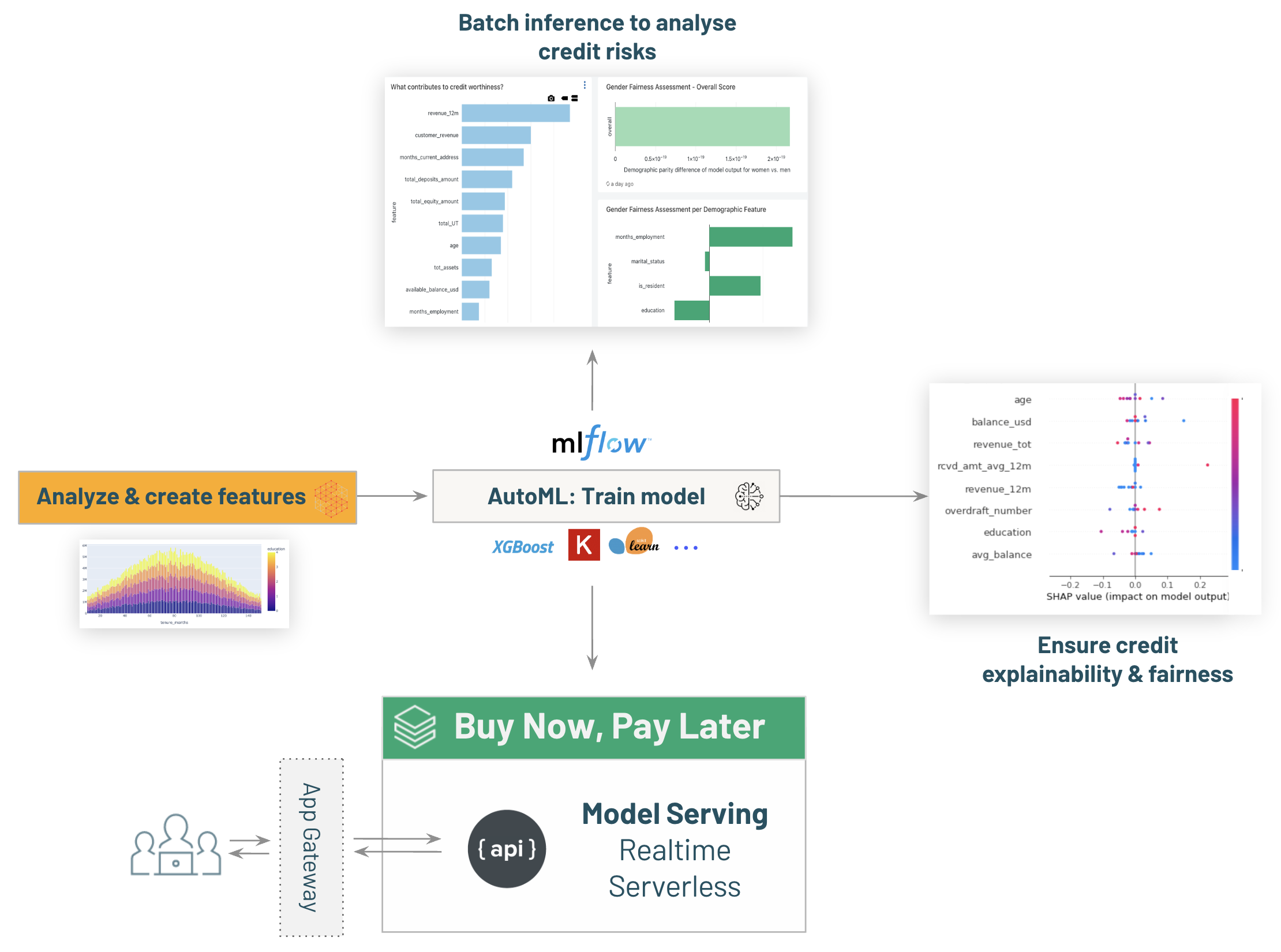 -# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC  -# MAGIC
-# MAGIC Once our features are ready, we'll save them in Databricks Feature Store.
-# MAGIC
-# MAGIC Under the hood, feature store are backed by a Delta Lake table. This will allow discoverability and reusability of our feature across our organization, increasing team efficiency.
-# MAGIC
-# MAGIC
-# MAGIC Databricks Feature Store brings advanced capabilities to accelerate and simplify your ML journey, such as point in time support and online-store, fetching your features within ms for real time Serving.
-# MAGIC
-# MAGIC ### Why use Databricks Feature Store?
-# MAGIC
-# MAGIC Databricks Feature Store is fully integrated with other components of Databricks.
-# MAGIC
-# MAGIC * **Discoverability**. The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
-# MAGIC
-# MAGIC * **Lineage**. When you create a feature table with Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs, and endpoints that use the feature.
-# MAGIC
-# MAGIC * **Batch and Online feature lookup for real time serving**. When you use features from Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
-# MAGIC
-# MAGIC * **Point-in-time lookups**. Feature Store supports time series and event-based use cases that require point-in-time correctness.
-# MAGIC
-# MAGIC
-# MAGIC For more details about Databricks Feature Store, run `dbdemos.install('feature-store')`
-
-# COMMAND ----------
-
-from databricks import feature_store
-fs = feature_store.FeatureStoreClient()
-
-# Drop the fs table if it was already existing to cleanup the demo state
-drop_fs_table(f"{catalog}.{db}.credit_decisioning_features")
-
-fs.create_table(
- name=f"{catalog}.{db}.credit_decisioning_features",
- primary_keys=["cust_id"],
- df=feature_df,
- description="Features for Credit Decisioning.")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Next steps
-# MAGIC
-# MAGIC After creating our features and storing them in the Databricks Feature Store, we can now proceed to the [03.2-AutoML-credit-decisioning]($./03.2-AutoML-credit-decisioning) and build out credit decisioning model.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py
deleted file mode 100644
index 5f8cf299..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py
+++ /dev/null
@@ -1,257 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Data Science on the Databricks Lakehouse
-# MAGIC
-# MAGIC ## ML is key to disruption & personalization
-# MAGIC
-# MAGIC Being able to ingest and query our credit-related database is a first step, but this isn't enough to thrive in a very competitive market.
-# MAGIC
-# MAGIC Customers now expect real time personalization and new form of comunication. Modern data company achieve this with AI.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Once our features are ready, we'll save them in Databricks Feature Store.
-# MAGIC
-# MAGIC Under the hood, feature store are backed by a Delta Lake table. This will allow discoverability and reusability of our feature across our organization, increasing team efficiency.
-# MAGIC
-# MAGIC
-# MAGIC Databricks Feature Store brings advanced capabilities to accelerate and simplify your ML journey, such as point in time support and online-store, fetching your features within ms for real time Serving.
-# MAGIC
-# MAGIC ### Why use Databricks Feature Store?
-# MAGIC
-# MAGIC Databricks Feature Store is fully integrated with other components of Databricks.
-# MAGIC
-# MAGIC * **Discoverability**. The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
-# MAGIC
-# MAGIC * **Lineage**. When you create a feature table with Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs, and endpoints that use the feature.
-# MAGIC
-# MAGIC * **Batch and Online feature lookup for real time serving**. When you use features from Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
-# MAGIC
-# MAGIC * **Point-in-time lookups**. Feature Store supports time series and event-based use cases that require point-in-time correctness.
-# MAGIC
-# MAGIC
-# MAGIC For more details about Databricks Feature Store, run `dbdemos.install('feature-store')`
-
-# COMMAND ----------
-
-from databricks import feature_store
-fs = feature_store.FeatureStoreClient()
-
-# Drop the fs table if it was already existing to cleanup the demo state
-drop_fs_table(f"{catalog}.{db}.credit_decisioning_features")
-
-fs.create_table(
- name=f"{catalog}.{db}.credit_decisioning_features",
- primary_keys=["cust_id"],
- df=feature_df,
- description="Features for Credit Decisioning.")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Next steps
-# MAGIC
-# MAGIC After creating our features and storing them in the Databricks Feature Store, we can now proceed to the [03.2-AutoML-credit-decisioning]($./03.2-AutoML-credit-decisioning) and build out credit decisioning model.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py
deleted file mode 100644
index 5f8cf299..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-AutoML-credit-decisioning.py
+++ /dev/null
@@ -1,257 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Data Science on the Databricks Lakehouse
-# MAGIC
-# MAGIC ## ML is key to disruption & personalization
-# MAGIC
-# MAGIC Being able to ingest and query our credit-related database is a first step, but this isn't enough to thrive in a very competitive market.
-# MAGIC
-# MAGIC Customers now expect real time personalization and new form of comunication. Modern data company achieve this with AI.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## So what makes machine learning and data science difficult?
-# MAGIC
-# MAGIC These are the top challenges we have observed companies struggle with:
-# MAGIC 1. Inability to ingest the required data in a timely manner,
-# MAGIC 2. Inability to properly control the access of the data,
-# MAGIC 3. Inability to trace problems in the feature store to the raw data,
-# MAGIC
-# MAGIC ... and many other data-related problems.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC # Data-centric Machine Learning
-# MAGIC
-# MAGIC In Databricks, machine learning is not a separate product or service that needs to be "connected" to the data. The Lakehouse being a single, unified product, machine learning in Databricks "sits" on top of the data, so challenges like inability to discover and access data no longer exist.
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## So what makes machine learning and data science difficult?
-# MAGIC
-# MAGIC These are the top challenges we have observed companies struggle with:
-# MAGIC 1. Inability to ingest the required data in a timely manner,
-# MAGIC 2. Inability to properly control the access of the data,
-# MAGIC 3. Inability to trace problems in the feature store to the raw data,
-# MAGIC
-# MAGIC ... and many other data-related problems.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC # Data-centric Machine Learning
-# MAGIC
-# MAGIC In Databricks, machine learning is not a separate product or service that needs to be "connected" to the data. The Lakehouse being a single, unified product, machine learning in Databricks "sits" on top of the data, so challenges like inability to discover and access data no longer exist.
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %pip install databricks-sdk==0.36.0 mlflow==2.19.0 databricks-feature-store==0.17.0 scikit-learn==1.3.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Credit Scoring default prediction
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %pip install databricks-sdk==0.36.0 mlflow==2.19.0 databricks-feature-store==0.17.0 scikit-learn==1.3.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC # Credit Scoring default prediction
-# MAGIC
-# MAGIC
-# MAGIC 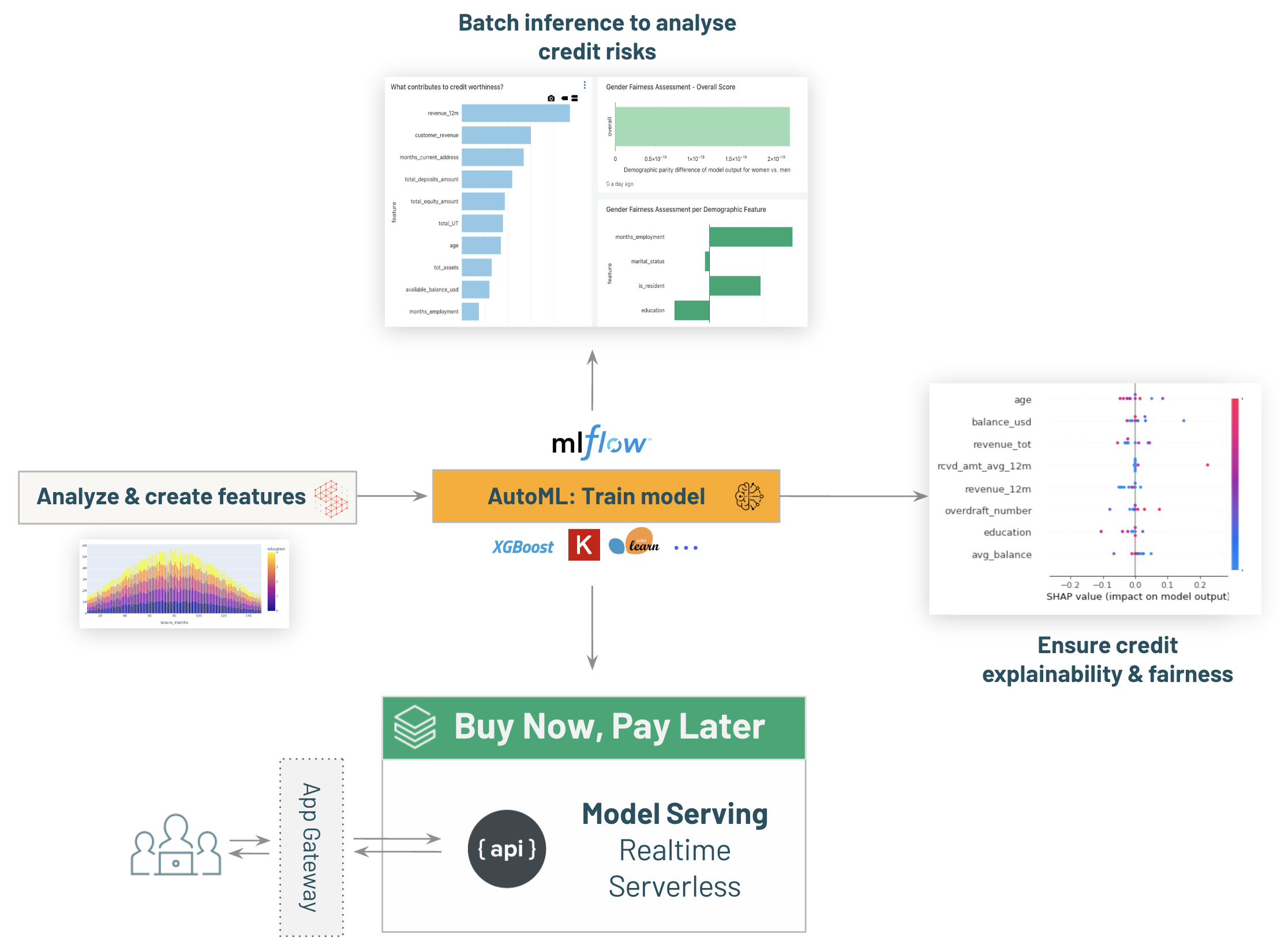 -# MAGIC
-# MAGIC ## Single click deployment with AutoML
-# MAGIC
-# MAGIC
-# MAGIC Let's see how we can now leverage the credit decisioning data to build a model predicting and explaining customer creditworthiness.
-# MAGIC
-# MAGIC We'll start by retrieving our data from the feature store and creating our training dataset.
-# MAGIC
-# MAGIC We'll then use Databricks AutoML to automatically build our model.
-
-# COMMAND ----------
-
-# DBTITLE 1,Loading the training dataset from the Databricks Feature Store
-from databricks import feature_store
-fs = feature_store.FeatureStoreClient()
-features_set = fs.read_table(name=f"{catalog}.{db}.credit_decisioning_features")
-display(features_set)
-
-# COMMAND ----------
-
-# DBTITLE 1,Creating the label: "defaulted"
-credit_bureau_label = (spark.table("credit_bureau_gold")
- .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE") > 60, 1)
- .otherwise(0))
- .select("cust_id", "defaulted"))
-#As you can see, we have a fairly imbalanced dataset
-df = credit_bureau_label.groupBy('defaulted').count().toPandas()
-px.pie(df, values='count', names='defaulted', title='Credit default ratio')
-
-# COMMAND ----------
-
-# DBTITLE 1,Build our training dataset (join features and label)
-training_dataset = credit_bureau_label.join(features_set, "cust_id", "inner")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Balancing our dataset
-# MAGIC
-# MAGIC Let's downsample and upsample our dataset to improve our model performance
-
-# COMMAND ----------
-
-major_df = training_dataset.filter(col("defaulted") == 0)
-minor_df = training_dataset.filter(col("defaulted") == 1)
-
-# duplicate the minority rows
-oversampled_df = minor_df.union(minor_df)
-
-# downsample majority rows
-undersampled_df = major_df.sample(oversampled_df.count()/major_df.count()*3, 42)
-
-# combine both oversampled minority rows and undersampled majority rows, this will improve our balance while preseving enough information.
-train_df = undersampled_df.unionAll(oversampled_df).drop('cust_id').na.fill(0)
-# Save it as a table to be able to select it with the AutoML UI.
-train_df.write.mode('overwrite').saveAsTable('credit_risk_train_df')
-px.pie(train_df.groupBy('defaulted').count().toPandas(), values='count', names='defaulted', title='Credit default ratio')
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Accelerating credit scoring model creation using MLFlow and Databricks AutoML
-# MAGIC
-# MAGIC MLFlow is an open source project allowing model tracking, packaging and deployment. Every time your Data Science team works on a model, Databricks will track all parameters and data used and will auto-log them. This ensures ML traceability and reproductibility, making it easy to know what parameters/data were used to build each model and model version.
-# MAGIC
-# MAGIC ### A glass-box solution that empowers data teams without taking control away
-# MAGIC
-# MAGIC While Databricks simplifies model deployment and governance (MLOps) with MLFlow, bootstraping new ML projects can still be a long and inefficient process.
-# MAGIC
-# MAGIC Instead of creating the same boilerplate for each new project, Databricks AutoML can automatically generate state of the art models for Classifications, Regression, and Forecasting.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC ## Single click deployment with AutoML
-# MAGIC
-# MAGIC
-# MAGIC Let's see how we can now leverage the credit decisioning data to build a model predicting and explaining customer creditworthiness.
-# MAGIC
-# MAGIC We'll start by retrieving our data from the feature store and creating our training dataset.
-# MAGIC
-# MAGIC We'll then use Databricks AutoML to automatically build our model.
-
-# COMMAND ----------
-
-# DBTITLE 1,Loading the training dataset from the Databricks Feature Store
-from databricks import feature_store
-fs = feature_store.FeatureStoreClient()
-features_set = fs.read_table(name=f"{catalog}.{db}.credit_decisioning_features")
-display(features_set)
-
-# COMMAND ----------
-
-# DBTITLE 1,Creating the label: "defaulted"
-credit_bureau_label = (spark.table("credit_bureau_gold")
- .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE") > 60, 1)
- .otherwise(0))
- .select("cust_id", "defaulted"))
-#As you can see, we have a fairly imbalanced dataset
-df = credit_bureau_label.groupBy('defaulted').count().toPandas()
-px.pie(df, values='count', names='defaulted', title='Credit default ratio')
-
-# COMMAND ----------
-
-# DBTITLE 1,Build our training dataset (join features and label)
-training_dataset = credit_bureau_label.join(features_set, "cust_id", "inner")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Balancing our dataset
-# MAGIC
-# MAGIC Let's downsample and upsample our dataset to improve our model performance
-
-# COMMAND ----------
-
-major_df = training_dataset.filter(col("defaulted") == 0)
-minor_df = training_dataset.filter(col("defaulted") == 1)
-
-# duplicate the minority rows
-oversampled_df = minor_df.union(minor_df)
-
-# downsample majority rows
-undersampled_df = major_df.sample(oversampled_df.count()/major_df.count()*3, 42)
-
-# combine both oversampled minority rows and undersampled majority rows, this will improve our balance while preseving enough information.
-train_df = undersampled_df.unionAll(oversampled_df).drop('cust_id').na.fill(0)
-# Save it as a table to be able to select it with the AutoML UI.
-train_df.write.mode('overwrite').saveAsTable('credit_risk_train_df')
-px.pie(train_df.groupBy('defaulted').count().toPandas(), values='count', names='defaulted', title='Credit default ratio')
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Accelerating credit scoring model creation using MLFlow and Databricks AutoML
-# MAGIC
-# MAGIC MLFlow is an open source project allowing model tracking, packaging and deployment. Every time your Data Science team works on a model, Databricks will track all parameters and data used and will auto-log them. This ensures ML traceability and reproductibility, making it easy to know what parameters/data were used to build each model and model version.
-# MAGIC
-# MAGIC ### A glass-box solution that empowers data teams without taking control away
-# MAGIC
-# MAGIC While Databricks simplifies model deployment and governance (MLOps) with MLFlow, bootstraping new ML projects can still be a long and inefficient process.
-# MAGIC
-# MAGIC Instead of creating the same boilerplate for each new project, Databricks AutoML can automatically generate state of the art models for Classifications, Regression, and Forecasting.
-# MAGIC
-# MAGIC
-# MAGIC  -# MAGIC
-# MAGIC
-# MAGIC Models can be directly deployed, or instead leverage generated notebooks to boostrap projects with best-practices, saving you weeks worth of effort.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Models can be directly deployed, or instead leverage generated notebooks to boostrap projects with best-practices, saving you weeks worth of effort.
-# MAGIC
-# MAGIC 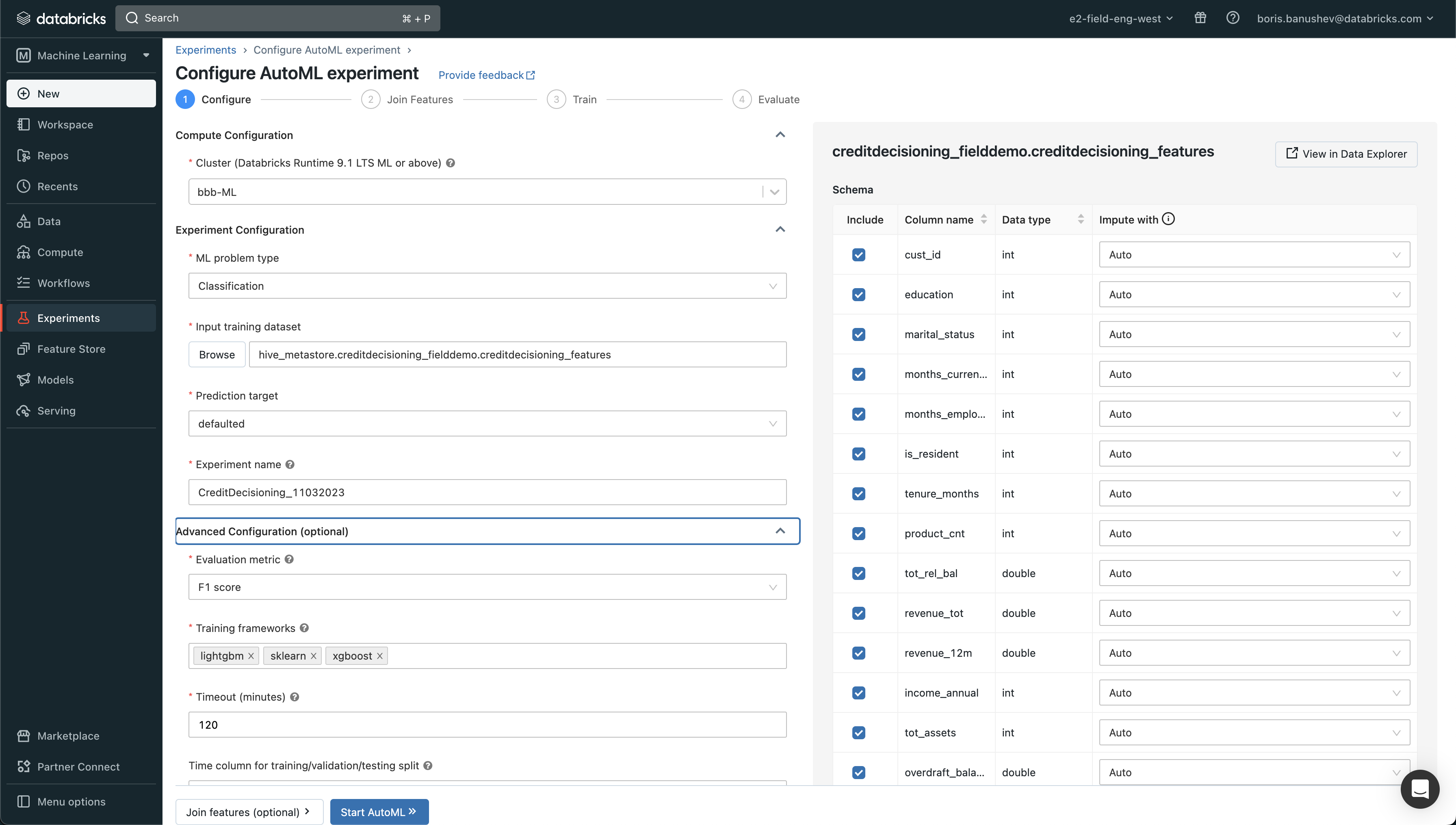 -# MAGIC
-# MAGIC ### Using Databricks Auto ML with our Credit Scoring dataset
-# MAGIC
-# MAGIC AutoML is available in the "Machine Learning" space. All we have to do is start a new AutoML Experiments and select the feature table we just created (`creditdecisioning_features`)
-# MAGIC
-# MAGIC Our prediction target is the `defaulted` column.
-# MAGIC
-# MAGIC Click on Start, and Databricks will do the rest.
-# MAGIC
-# MAGIC While this is done using the UI, you can also leverage the [python API](https://docs.databricks.com/applications/machine-learning/automl.html#automl-python-api-1)
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-xp_path = "/Shared/dbdemos/experiments/lakehouse-fsi-credit-decisioning"
-xp_name = f"automl_credit_{datetime.now().strftime('%Y-%m-%d_%H:%M:%S')}"
-try:
- from databricks import automl
- automl_run = automl.classify(
- experiment_name = xp_name,
- experiment_dir = xp_path,
- dataset = train_df.sample(0.1),
- target_col = "defaulted",
- timeout_minutes = 10
- )
- #Make sure all users can access dbdemos shared experiment
- DBDemos.set_experiment_permission(f"{xp_path}/{xp_name}")
-except Exception as e:
- if "cannot import name 'automl'" in str(e):
- # Note: cannot import name 'automl' from 'databricks' likely means you're using serverless. Dbdemos doesn't support autoML serverless API - this will be improved soon.
- # Adding a temporary workaround to make sure it works well for now - ignore this for classic run
- automl_run = DBDemos.create_mockup_automl_run(f"{xp_path}/{xp_name}", train_df.sample(0.1).toPandas(), model_name=model_name, target_col="defaulted")
- else:
- raise e
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Deploying our model in production
-# MAGIC
-# MAGIC Our model is now ready. We can review the notebook generated by the auto-ml run and customize if if required.
-# MAGIC
-# MAGIC For this demo, we'll consider that our model is ready and deploy it in production in our Model Registry:
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-from mlflow import MlflowClient
-import mlflow
-
-#Use Databricks Unity Catalog to save our model
-mlflow.set_registry_uri('databricks-uc')
-client = MlflowClient()
-
-#Add model within our catalog
-latest_model = mlflow.register_model(f'runs:/{automl_run.best_trial.mlflow_run_id}/model', f"{catalog}.{db}.{model_name}")
-# Flag it as Production ready using UC Aliases
-client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="prod", version=latest_model.version)
-#DBDemos.set_model_permission(f"{catalog}.{db}.{model_name}", "ALL_PRIVILEGES", "account users")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC We just moved our automl model as production ready!
-# MAGIC
-# MAGIC Open [the dbdemos_fsi_credit_decisioning model](#mlflow/models/dbdemos_fsi_credit_decisioning) to explore its artifact and analyze the parameters used, including traceability to the notebook used for its creation.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Our model predicting default risks is now deployed in production
-# MAGIC
-# MAGIC
-# MAGIC So far we have:
-# MAGIC * ingested all required data in a single source of truth,
-# MAGIC * properly secured all data (including granting granular access controls, masked PII data, applied column level filtering),
-# MAGIC * enhanced that data through feature engineering,
-# MAGIC * used MLFlow AutoML to track experiments and build a machine learning model,
-# MAGIC * registered the model.
-# MAGIC
-# MAGIC ### Next steps
-# MAGIC We're now ready to use our model use it for:
-# MAGIC
-# MAGIC - Batch inferences in notebook [03.3-Batch-Scoring-credit-decisioning]($./03.3-Batch-Scoring-credit-decisioning) to start using it for identifying currently underbanked customers with good credit-worthiness (**increase the revenue**) and predict current credit-owners who might default so we can prevent such defaults from happening (**manage risk**),
-# MAGIC - Real time inference with [03.4-model-serving-BNPL-credit-decisioning]($./03.4-model-serving-BNPL-credit-decisioning) to enable ```Buy Now, Pay Later``` capabilities within the bank.
-# MAGIC
-# MAGIC Extra: review model explainability & fairness with [03.5-Explainability-and-Fairness-credit-decisioning]($./03.5-Explainability-and-Fairness-credit-decisioning)
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py
new file mode 100644
index 00000000..0e8da74c
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py
@@ -0,0 +1,171 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Feature Updates
+# MAGIC
+# MAGIC In responsible credit scoring, ensuring that machine learning models operate on high-quality and up-to-date data is essential. Continuous feature updates play a crucial role in maintaining model accuracy, fairness, and regulatory compliance. By centralizing feature management, we can improve governance, enforce lineage tracking, and ensure consistency across multiple ML projects.
+# MAGIC
+# MAGIC This notebook focuses on the ingestion, transformation, and tracking of features within the Databricks Feature Store. We ensure that every update is logged for traceability and that feature engineering practices align with Responsible AI principles. With transparent feature updates, we enhance the model’s effectiveness while meeting compliance standards.
+# MAGIC
+# MAGIC
-# MAGIC
-# MAGIC ### Using Databricks Auto ML with our Credit Scoring dataset
-# MAGIC
-# MAGIC AutoML is available in the "Machine Learning" space. All we have to do is start a new AutoML Experiments and select the feature table we just created (`creditdecisioning_features`)
-# MAGIC
-# MAGIC Our prediction target is the `defaulted` column.
-# MAGIC
-# MAGIC Click on Start, and Databricks will do the rest.
-# MAGIC
-# MAGIC While this is done using the UI, you can also leverage the [python API](https://docs.databricks.com/applications/machine-learning/automl.html#automl-python-api-1)
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-xp_path = "/Shared/dbdemos/experiments/lakehouse-fsi-credit-decisioning"
-xp_name = f"automl_credit_{datetime.now().strftime('%Y-%m-%d_%H:%M:%S')}"
-try:
- from databricks import automl
- automl_run = automl.classify(
- experiment_name = xp_name,
- experiment_dir = xp_path,
- dataset = train_df.sample(0.1),
- target_col = "defaulted",
- timeout_minutes = 10
- )
- #Make sure all users can access dbdemos shared experiment
- DBDemos.set_experiment_permission(f"{xp_path}/{xp_name}")
-except Exception as e:
- if "cannot import name 'automl'" in str(e):
- # Note: cannot import name 'automl' from 'databricks' likely means you're using serverless. Dbdemos doesn't support autoML serverless API - this will be improved soon.
- # Adding a temporary workaround to make sure it works well for now - ignore this for classic run
- automl_run = DBDemos.create_mockup_automl_run(f"{xp_path}/{xp_name}", train_df.sample(0.1).toPandas(), model_name=model_name, target_col="defaulted")
- else:
- raise e
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Deploying our model in production
-# MAGIC
-# MAGIC Our model is now ready. We can review the notebook generated by the auto-ml run and customize if if required.
-# MAGIC
-# MAGIC For this demo, we'll consider that our model is ready and deploy it in production in our Model Registry:
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-from mlflow import MlflowClient
-import mlflow
-
-#Use Databricks Unity Catalog to save our model
-mlflow.set_registry_uri('databricks-uc')
-client = MlflowClient()
-
-#Add model within our catalog
-latest_model = mlflow.register_model(f'runs:/{automl_run.best_trial.mlflow_run_id}/model', f"{catalog}.{db}.{model_name}")
-# Flag it as Production ready using UC Aliases
-client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="prod", version=latest_model.version)
-#DBDemos.set_model_permission(f"{catalog}.{db}.{model_name}", "ALL_PRIVILEGES", "account users")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC We just moved our automl model as production ready!
-# MAGIC
-# MAGIC Open [the dbdemos_fsi_credit_decisioning model](#mlflow/models/dbdemos_fsi_credit_decisioning) to explore its artifact and analyze the parameters used, including traceability to the notebook used for its creation.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Our model predicting default risks is now deployed in production
-# MAGIC
-# MAGIC
-# MAGIC So far we have:
-# MAGIC * ingested all required data in a single source of truth,
-# MAGIC * properly secured all data (including granting granular access controls, masked PII data, applied column level filtering),
-# MAGIC * enhanced that data through feature engineering,
-# MAGIC * used MLFlow AutoML to track experiments and build a machine learning model,
-# MAGIC * registered the model.
-# MAGIC
-# MAGIC ### Next steps
-# MAGIC We're now ready to use our model use it for:
-# MAGIC
-# MAGIC - Batch inferences in notebook [03.3-Batch-Scoring-credit-decisioning]($./03.3-Batch-Scoring-credit-decisioning) to start using it for identifying currently underbanked customers with good credit-worthiness (**increase the revenue**) and predict current credit-owners who might default so we can prevent such defaults from happening (**manage risk**),
-# MAGIC - Real time inference with [03.4-model-serving-BNPL-credit-decisioning]($./03.4-model-serving-BNPL-credit-decisioning) to enable ```Buy Now, Pay Later``` capabilities within the bank.
-# MAGIC
-# MAGIC Extra: review model explainability & fairness with [03.5-Explainability-and-Fairness-credit-decisioning]($./03.5-Explainability-and-Fairness-credit-decisioning)
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py
new file mode 100644
index 00000000..0e8da74c
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.2-Feature-Updates-credit-decisioning.py
@@ -0,0 +1,171 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Feature Updates
+# MAGIC
+# MAGIC In responsible credit scoring, ensuring that machine learning models operate on high-quality and up-to-date data is essential. Continuous feature updates play a crucial role in maintaining model accuracy, fairness, and regulatory compliance. By centralizing feature management, we can improve governance, enforce lineage tracking, and ensure consistency across multiple ML projects.
+# MAGIC
+# MAGIC This notebook focuses on the ingestion, transformation, and tracking of features within the Databricks Feature Store. We ensure that every update is logged for traceability and that feature engineering practices align with Responsible AI principles. With transparent feature updates, we enhance the model’s effectiveness while meeting compliance standards.
+# MAGIC
+# MAGIC  +
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC # Building our Features for Credit Default risks
+# MAGIC
+# MAGIC To build our model predicting credit default risks, we need a comprehensive set of features that capture various aspects of customer behavior, financial activity, and risk indicators. Our primary data sources include:
+# MAGIC
+# MAGIC - `customer_gold`: Contains aggregated customer demographic, behavioral, and credit history attributes.
+# MAGIC - `telco_gold`: Includes telecommunications data, such as call patterns and payment behaviors.
+# MAGIC - `fund_trans_gold`: Provides insights into customer fund movements, transaction behaviors, and cash flow trends.
+# MAGIC
+# MAGIC To improve governance and centralize feature management for multiple machine learning projects, we leverage the Databricks Feature Store.
+
+# COMMAND ----------
+
+# DBTITLE 1,Read the customer table
+customer_gold_features = (spark.table("customer_gold")
+ .withColumn('age', int(date.today().year) - col('birth_year'))
+ .select('cust_id', 'education', 'marital_status', 'months_current_address', 'months_employment', 'is_resident',
+ 'tenure_months', 'product_cnt', 'tot_rel_bal', 'revenue_tot', 'revenue_12m', 'income_annual', 'tot_assets',
+ 'overdraft_balance_amount', 'overdraft_number', 'total_deposits_number', 'total_deposits_amount', 'total_equity_amount',
+ 'total_UT', 'customer_revenue', 'age', 'gender', 'avg_balance', 'num_accs', 'balance_usd', 'available_balance_usd')).dropDuplicates(['cust_id'])
+display(customer_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Read the telco table
+telco_gold_features = (spark.table("telco_gold")
+ .select('cust_id', 'is_pre_paid', 'number_payment_delays_last12mo', 'pct_increase_annual_number_of_delays_last_3_year', 'phone_bill_amt', \
+ 'avg_phone_bill_amt_lst12mo')).dropDuplicates(['cust_id'])
+display(telco_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Adding some additional features on transactional trends
+fund_trans_gold_features = spark.table("fund_trans_gold").dropDuplicates(['cust_id'])
+
+for c in ['12m', '6m', '3m']:
+ fund_trans_gold_features = fund_trans_gold_features.withColumn('tot_txn_cnt_'+c, col('sent_txn_cnt_'+c)+col('rcvd_txn_cnt_'+c))\
+ .withColumn('tot_txn_amt_'+c, col('sent_txn_amt_'+c)+col('rcvd_txn_amt_'+c))
+
+fund_trans_gold_features = fund_trans_gold_features.withColumn('ratio_txn_amt_3m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_3m')/col('tot_txn_amt_12m')))\
+ .withColumn('ratio_txn_amt_6m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_6m')/col('tot_txn_amt_12m')))\
+ .na.fill(0)
+display(fund_trans_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Consolidating all the features
+feature_df = customer_gold_features.join(telco_gold_features.alias('telco'), "cust_id", how="left")
+feature_df = feature_df.join(fund_trans_gold_features, "cust_id", how="left")
+display(feature_df)
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Databricks Feature Store
+# MAGIC
+# MAGIC Once our features are ready, we'll save them in Databricks Feature Store.
+# MAGIC
+# MAGIC Under the hood, feature store are backed by a Delta Lake table. This will allow discoverability and reusability of our feature across our organization, increasing team efficiency.
+# MAGIC
+# MAGIC
+# MAGIC Databricks Feature Store brings advanced capabilities to accelerate and simplify your ML journey, such as point in time support and online-store, fetching your features within ms for real time Serving.
+# MAGIC
+# MAGIC ### Why use Databricks Feature Store?
+# MAGIC
+# MAGIC Databricks Feature Store is fully integrated with other components of Databricks.
+# MAGIC
+# MAGIC * **Discoverability**. The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
+# MAGIC
+# MAGIC * **Lineage**. When you create a feature table with Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs, and endpoints that use the feature.
+# MAGIC
+# MAGIC * **Batch and Online feature lookup for real time serving**. When you use features from Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
+# MAGIC
+# MAGIC * **Point-in-time lookups**. Feature Store supports time series and event-based use cases that require point-in-time correctness.
+# MAGIC
+# MAGIC
+# MAGIC For more details about Databricks Feature Store, run `dbdemos.install('feature-store')`
+
+# COMMAND ----------
+
+from databricks.feature_engineering import FeatureEngineeringClient
+
+fe = FeatureEngineeringClient()
+
+# Drop the fs table if it was already existing to cleanup the demo state
+try:
+ fe.drop_table(name=f"{catalog}.{db}.credit_decisioning_features")
+ print("Dropped existing feature table.")
+except:
+ print("Feature table does not exist. Creating a new feature table.")
+
+# Create feature table with `cust_id` as the primary key.
+fe.create_table(
+ name=f"{catalog}.{db}.credit_decisioning_features",
+ primary_keys="cust_id",
+ schema=feature_df.schema,
+ description="Features for Credit Decisioning.")
+
+fe.write_table(
+ name=f"{catalog}.{db}.credit_decisioning_features",
+ df = feature_df,
+ mode = 'merge'
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Transparency
+# MAGIC
+# MAGIC Databricks Unity Catalog's **automated data lineage** feature tracks and visualizes data flow from ingestion to consumption. It ensures transparency in feature engineering for machine learning by capturing transformations, dependencies, and usage across notebooks, workflows, and dashboards. This enhances reproducibility, debugging, compliance, and model accuracy.
+# MAGIC
+# MAGIC Accessing lineage via [system tables](https://docs.databricks.com/en/admin/system-tables/lineage.html) allows users to query lineage metadata, track data dependencies, and analyze usage patterns. This structured approach aids auditing, debugging, and optimizing workflows, ensuring data quality across analytics and ML pipelines.
+# MAGIC
+# MAGIC Next, we'll import lineage data for the feature tables created in this Notebook.
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC
+# MAGIC select * from system.access.table_lineage
+# MAGIC where target_table_catalog=current_catalog()
+# MAGIC and target_table_schema=current_schema()
+# MAGIC and target_table_name = 'credit_decisioning_features';
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Documentation of the data
+# MAGIC
+# MAGIC In Databricks, the AI-generated column and table description feature leverages machine learning models to automatically analyze and generate meaningful metadata descriptions for tables and columns within a dataset. This functionality improves data discovery and understanding by providing natural language descriptions, helping users quickly interpret data without needing to manually write documentation. The AI can identify patterns, data types, and relationships between columns, offering suggestions that can enhance data governance, streamline collaboration, and make datasets more accessible, especially for those unfamiliar with the underlying schema. This feature is part of Databricks' broader effort to simplify data exploration and enhance productivity within its unified data analytics platform.
+
+# COMMAND ----------
+
+table_name = "credit_decisioning_features"
+
+table_description = spark.sql(f"DESCRIBE TABLE EXTENDED {table_name}").filter("col_name = 'Comment'").select("data_type").collect()[0][0]
+
+column_descriptions = spark.sql(f"DESCRIBE TABLE EXTENDED {table_name}").filter("col_name != ''").select("col_name", "comment").collect()
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With our feature set prepared and stored, the next step is model training. In the [06.3-Model-Training]($./06-Responsible-AI/06.3-Model-Training) notebook, we will:
+# MAGIC - Train multiple candidate models using the engineered features.
+# MAGIC - Evaluate models based on fairness, accuracy, and stability metrics.
+# MAGIC - Log model artifacts, ensuring full reproducibility.
+# MAGIC
+# MAGIC By maintaining transparency and governance throughout feature updates and model training, we lay the foundation for responsible credit decisioning and robust AI deployment.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py
deleted file mode 100644
index af64954b..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py
+++ /dev/null
@@ -1,85 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC # Use the best AutoML generated model to batch score credit worthiness
-# MAGIC
-# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC # Building our Features for Credit Default risks
+# MAGIC
+# MAGIC To build our model predicting credit default risks, we need a comprehensive set of features that capture various aspects of customer behavior, financial activity, and risk indicators. Our primary data sources include:
+# MAGIC
+# MAGIC - `customer_gold`: Contains aggregated customer demographic, behavioral, and credit history attributes.
+# MAGIC - `telco_gold`: Includes telecommunications data, such as call patterns and payment behaviors.
+# MAGIC - `fund_trans_gold`: Provides insights into customer fund movements, transaction behaviors, and cash flow trends.
+# MAGIC
+# MAGIC To improve governance and centralize feature management for multiple machine learning projects, we leverage the Databricks Feature Store.
+
+# COMMAND ----------
+
+# DBTITLE 1,Read the customer table
+customer_gold_features = (spark.table("customer_gold")
+ .withColumn('age', int(date.today().year) - col('birth_year'))
+ .select('cust_id', 'education', 'marital_status', 'months_current_address', 'months_employment', 'is_resident',
+ 'tenure_months', 'product_cnt', 'tot_rel_bal', 'revenue_tot', 'revenue_12m', 'income_annual', 'tot_assets',
+ 'overdraft_balance_amount', 'overdraft_number', 'total_deposits_number', 'total_deposits_amount', 'total_equity_amount',
+ 'total_UT', 'customer_revenue', 'age', 'gender', 'avg_balance', 'num_accs', 'balance_usd', 'available_balance_usd')).dropDuplicates(['cust_id'])
+display(customer_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Read the telco table
+telco_gold_features = (spark.table("telco_gold")
+ .select('cust_id', 'is_pre_paid', 'number_payment_delays_last12mo', 'pct_increase_annual_number_of_delays_last_3_year', 'phone_bill_amt', \
+ 'avg_phone_bill_amt_lst12mo')).dropDuplicates(['cust_id'])
+display(telco_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Adding some additional features on transactional trends
+fund_trans_gold_features = spark.table("fund_trans_gold").dropDuplicates(['cust_id'])
+
+for c in ['12m', '6m', '3m']:
+ fund_trans_gold_features = fund_trans_gold_features.withColumn('tot_txn_cnt_'+c, col('sent_txn_cnt_'+c)+col('rcvd_txn_cnt_'+c))\
+ .withColumn('tot_txn_amt_'+c, col('sent_txn_amt_'+c)+col('rcvd_txn_amt_'+c))
+
+fund_trans_gold_features = fund_trans_gold_features.withColumn('ratio_txn_amt_3m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_3m')/col('tot_txn_amt_12m')))\
+ .withColumn('ratio_txn_amt_6m_12m', F.when(col('tot_txn_amt_12m')==0, 0).otherwise(col('tot_txn_amt_6m')/col('tot_txn_amt_12m')))\
+ .na.fill(0)
+display(fund_trans_gold_features)
+
+# COMMAND ----------
+
+# DBTITLE 1,Consolidating all the features
+feature_df = customer_gold_features.join(telco_gold_features.alias('telco'), "cust_id", how="left")
+feature_df = feature_df.join(fund_trans_gold_features, "cust_id", how="left")
+display(feature_df)
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Databricks Feature Store
+# MAGIC
+# MAGIC Once our features are ready, we'll save them in Databricks Feature Store.
+# MAGIC
+# MAGIC Under the hood, feature store are backed by a Delta Lake table. This will allow discoverability and reusability of our feature across our organization, increasing team efficiency.
+# MAGIC
+# MAGIC
+# MAGIC Databricks Feature Store brings advanced capabilities to accelerate and simplify your ML journey, such as point in time support and online-store, fetching your features within ms for real time Serving.
+# MAGIC
+# MAGIC ### Why use Databricks Feature Store?
+# MAGIC
+# MAGIC Databricks Feature Store is fully integrated with other components of Databricks.
+# MAGIC
+# MAGIC * **Discoverability**. The Feature Store UI, accessible from the Databricks workspace, lets you browse and search for existing features.
+# MAGIC
+# MAGIC * **Lineage**. When you create a feature table with Feature Store, the data sources used to create the feature table are saved and accessible. For each feature in a feature table, you can also access the models, notebooks, jobs, and endpoints that use the feature.
+# MAGIC
+# MAGIC * **Batch and Online feature lookup for real time serving**. When you use features from Feature Store to train a model, the model is packaged with feature metadata. When you use the model for batch scoring or online inference, it automatically retrieves features from Feature Store. The caller does not need to know about them or include logic to look up or join features to score new data. This makes model deployment and updates much easier.
+# MAGIC
+# MAGIC * **Point-in-time lookups**. Feature Store supports time series and event-based use cases that require point-in-time correctness.
+# MAGIC
+# MAGIC
+# MAGIC For more details about Databricks Feature Store, run `dbdemos.install('feature-store')`
+
+# COMMAND ----------
+
+from databricks.feature_engineering import FeatureEngineeringClient
+
+fe = FeatureEngineeringClient()
+
+# Drop the fs table if it was already existing to cleanup the demo state
+try:
+ fe.drop_table(name=f"{catalog}.{db}.credit_decisioning_features")
+ print("Dropped existing feature table.")
+except:
+ print("Feature table does not exist. Creating a new feature table.")
+
+# Create feature table with `cust_id` as the primary key.
+fe.create_table(
+ name=f"{catalog}.{db}.credit_decisioning_features",
+ primary_keys="cust_id",
+ schema=feature_df.schema,
+ description="Features for Credit Decisioning.")
+
+fe.write_table(
+ name=f"{catalog}.{db}.credit_decisioning_features",
+ df = feature_df,
+ mode = 'merge'
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Transparency
+# MAGIC
+# MAGIC Databricks Unity Catalog's **automated data lineage** feature tracks and visualizes data flow from ingestion to consumption. It ensures transparency in feature engineering for machine learning by capturing transformations, dependencies, and usage across notebooks, workflows, and dashboards. This enhances reproducibility, debugging, compliance, and model accuracy.
+# MAGIC
+# MAGIC Accessing lineage via [system tables](https://docs.databricks.com/en/admin/system-tables/lineage.html) allows users to query lineage metadata, track data dependencies, and analyze usage patterns. This structured approach aids auditing, debugging, and optimizing workflows, ensuring data quality across analytics and ML pipelines.
+# MAGIC
+# MAGIC Next, we'll import lineage data for the feature tables created in this Notebook.
+
+# COMMAND ----------
+
+# MAGIC %sql
+# MAGIC
+# MAGIC select * from system.access.table_lineage
+# MAGIC where target_table_catalog=current_catalog()
+# MAGIC and target_table_schema=current_schema()
+# MAGIC and target_table_name = 'credit_decisioning_features';
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Documentation of the data
+# MAGIC
+# MAGIC In Databricks, the AI-generated column and table description feature leverages machine learning models to automatically analyze and generate meaningful metadata descriptions for tables and columns within a dataset. This functionality improves data discovery and understanding by providing natural language descriptions, helping users quickly interpret data without needing to manually write documentation. The AI can identify patterns, data types, and relationships between columns, offering suggestions that can enhance data governance, streamline collaboration, and make datasets more accessible, especially for those unfamiliar with the underlying schema. This feature is part of Databricks' broader effort to simplify data exploration and enhance productivity within its unified data analytics platform.
+
+# COMMAND ----------
+
+table_name = "credit_decisioning_features"
+
+table_description = spark.sql(f"DESCRIBE TABLE EXTENDED {table_name}").filter("col_name = 'Comment'").select("data_type").collect()[0][0]
+
+column_descriptions = spark.sql(f"DESCRIBE TABLE EXTENDED {table_name}").filter("col_name != ''").select("col_name", "comment").collect()
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With our feature set prepared and stored, the next step is model training. In the [06.3-Model-Training]($./06-Responsible-AI/06.3-Model-Training) notebook, we will:
+# MAGIC - Train multiple candidate models using the engineered features.
+# MAGIC - Evaluate models based on fairness, accuracy, and stability metrics.
+# MAGIC - Log model artifacts, ensuring full reproducibility.
+# MAGIC
+# MAGIC By maintaining transparency and governance throughout feature updates and model training, we lay the foundation for responsible credit decisioning and robust AI deployment.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py
deleted file mode 100644
index af64954b..00000000
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.3-Batch-Scoring-credit-decisioning.py
+++ /dev/null
@@ -1,85 +0,0 @@
-# Databricks notebook source
-# MAGIC %md-sandbox
-# MAGIC # Use the best AutoML generated model to batch score credit worthiness
-# MAGIC
-# MAGIC 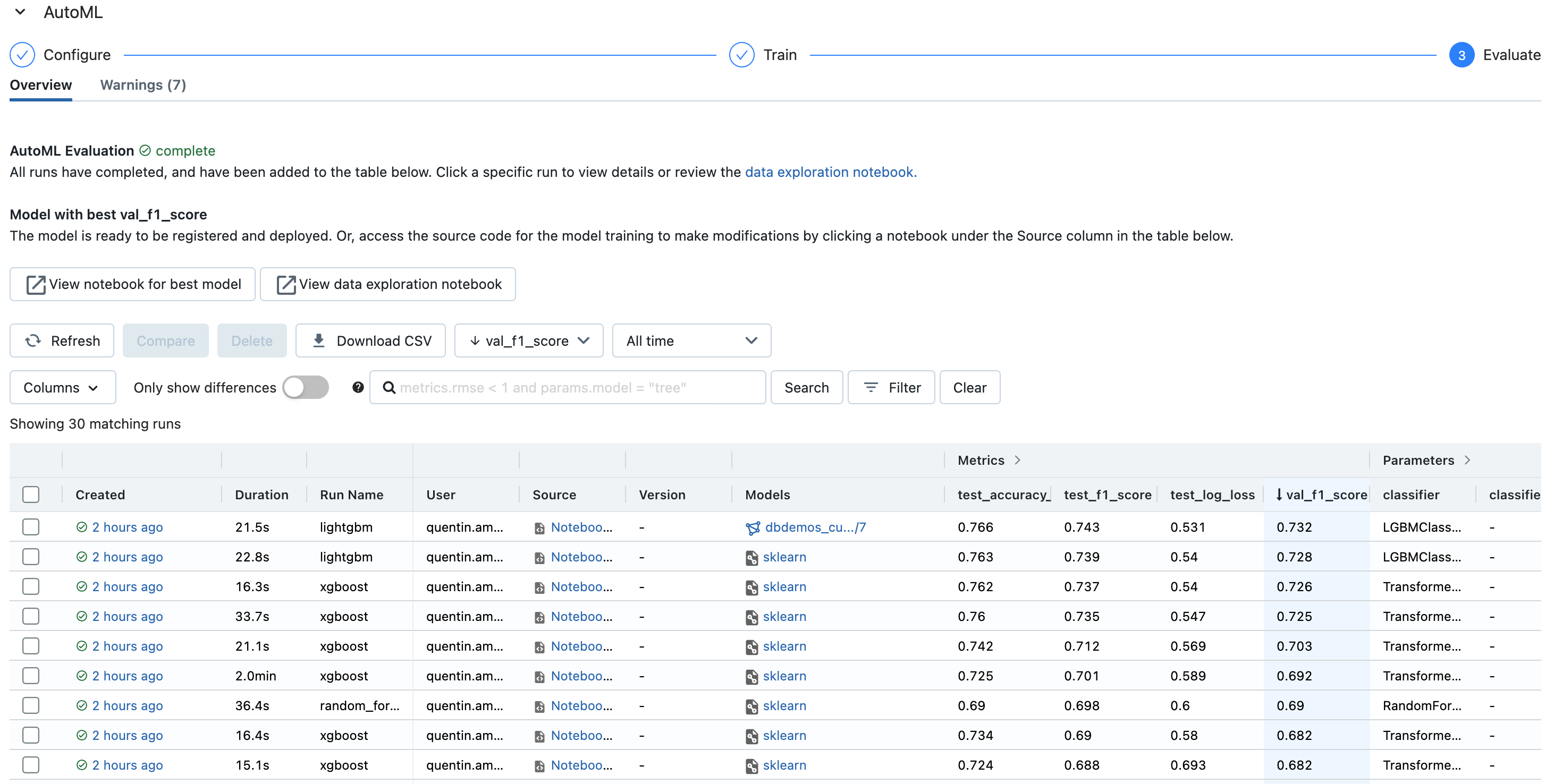 -# MAGIC
-# MAGIC
-# MAGIC Databricks AutoML runs experiments across a grid and creates many models and metrics to determine the best models among all trials. This is a glass-box approach to create a baseline model, meaning we have all the code artifacts and experiments available afterwards.
-# MAGIC
-# MAGIC Here, we selected the Notebook from the best run from the AutoML experiment.
-# MAGIC
-# MAGIC All the code below has been automatically generated. As data scientists, we can tune it based on our business knowledge, or use the generated model as-is.
-# MAGIC
-# MAGIC This saves data scientists hours of developement and allows team to quickly bootstrap and validate new projects, especally when we may not know the predictors for alternative data such as the telco payment data.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Databricks AutoML runs experiments across a grid and creates many models and metrics to determine the best models among all trials. This is a glass-box approach to create a baseline model, meaning we have all the code artifacts and experiments available afterwards.
-# MAGIC
-# MAGIC Here, we selected the Notebook from the best run from the AutoML experiment.
-# MAGIC
-# MAGIC All the code below has been automatically generated. As data scientists, we can tune it based on our business knowledge, or use the generated model as-is.
-# MAGIC
-# MAGIC This saves data scientists hours of developement and allows team to quickly bootstrap and validate new projects, especally when we may not know the predictors for alternative data such as the telco payment data.
-# MAGIC
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %pip install mlflow==2.19.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Running batch inference to score our existing database
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %pip install mlflow==2.19.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC ## Running batch inference to score our existing database
-# MAGIC
-# MAGIC 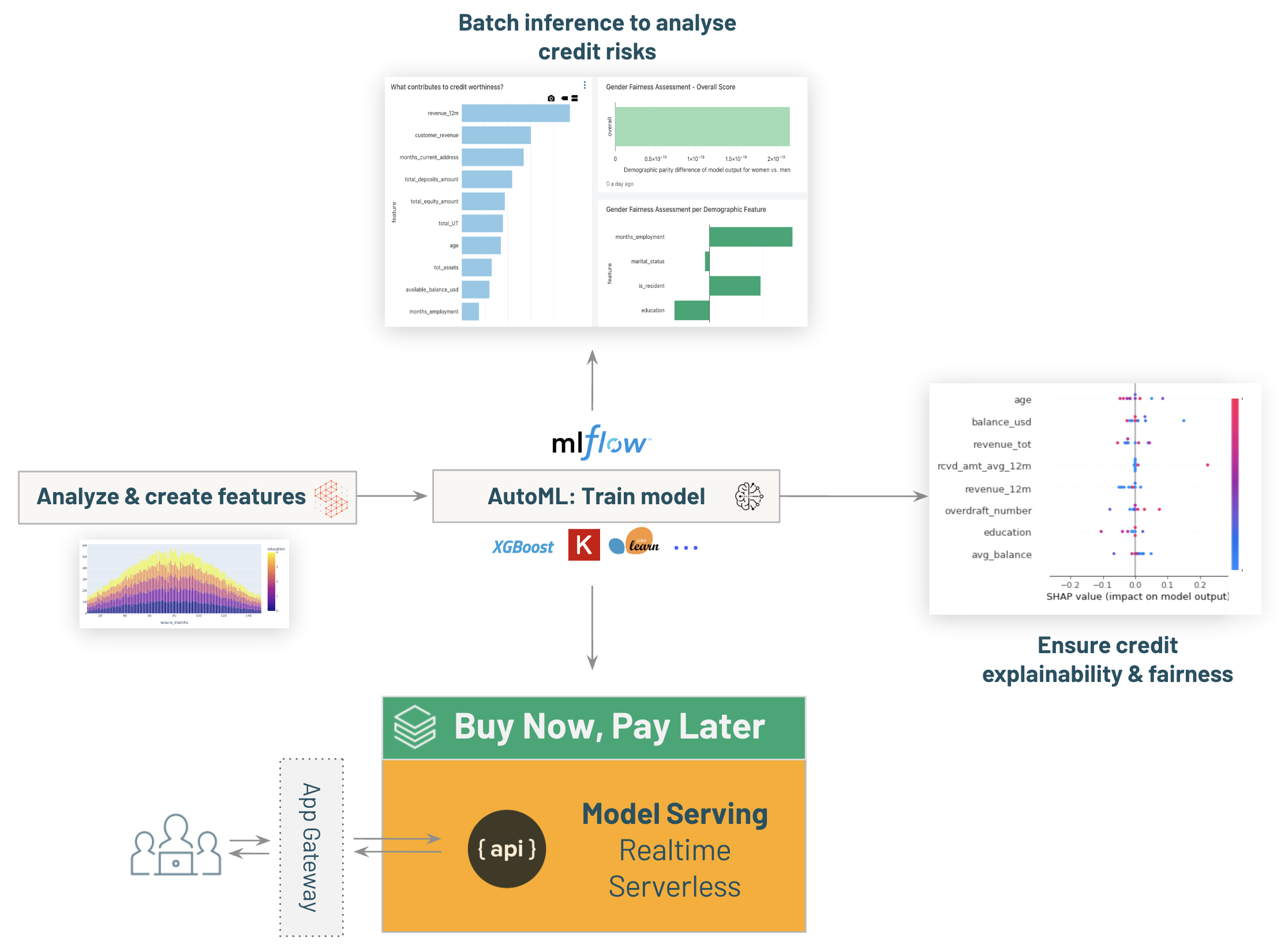 -# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC  +
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Building a Responsible Credit Scoring Model
+# MAGIC
+# MAGIC With our credit decisioning data prepared, we can now leverage it to build a predictive model assessing customer creditworthiness. Our approach will emphasize transparency, fairness, and governance at every step.
+# MAGIC
+# MAGIC Steps in Model Training:
+# MAGIC - **Retrieve Data from the Feature Store:** We begin by accessing the curated and validated features stored in the Databricks Feature Store. This ensures consistency, traceability, and compliance with feature engineering best practices.
+# MAGIC - **Create the Training Dataset:** We assemble a well-balanced training dataset by selecting relevant features and handling missing or biased data points.
+# MAGIC - **Leverage Databricks AutoML:** To streamline model development, we use Databricks AutoML to automatically build and evaluate multiple models. This step ensures we select the most effective model while adhering to Responsible AI principles.
+
+# COMMAND ----------
+
+# DBTITLE 1,Loading the training dataset from the Databricks Feature Store
+from databricks.feature_engineering import FeatureEngineeringClient
+fe = FeatureEngineeringClient()
+
+features_set = fe.read_table(name=f"{catalog}.{db}.credit_decisioning_features")
+display(features_set)
+
+# COMMAND ----------
+
+# DBTITLE 1,Creating the label: "defaulted"
+credit_bureau_label = (spark.table("credit_bureau_gold")
+ .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE") > 60, 1)
+ .otherwise(0))
+ .select("cust_id", "defaulted"))
+#As you can see, we have a fairly imbalanced dataset
+df = credit_bureau_label.groupBy('defaulted').count().toPandas()
+px.pie(df, values='count', names='defaulted', title='Credit default ratio')
+
+# COMMAND ----------
+
+# DBTITLE 1,Build our training dataset (join features and label)
+training_dataset = credit_bureau_label.join(features_set, "cust_id", "inner")
+training_dataset.write.mode('overwrite').saveAsTable('credit_decisioning_features_labels')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Adressing the class imbalance of our dataset
+# MAGIC
+# MAGIC Let's downsample and upsample our dataset to improve our model performance
+
+# COMMAND ----------
+
+major_df = training_dataset.filter(col("defaulted") == 0)
+minor_df = training_dataset.filter(col("defaulted") == 1)
+
+# duplicate the minority rows
+oversampled_df = minor_df.union(minor_df)
+
+# downsample majority rows
+undersampled_df = major_df.sample(oversampled_df.count()/major_df.count()*3, 42)
+
+
+# COMMAND ----------
+
+# combine both oversampled minority rows and undersampled majority rows, this will improve our balance while preseving enough information.
+train_df = undersampled_df.unionAll(oversampled_df).drop('cust_id').na.fill(0)
+
+# COMMAND ----------
+
+# Save it as a table to be able to select it with the AutoML UI.
+train_df.write.mode('overwrite').saveAsTable('credit_risk_train_df')
+px.pie(train_df.groupBy('defaulted').count().toPandas(), values='count', names='defaulted', title='Credit default ratio')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Addressing Demographic or Ethical Bias
+# MAGIC
+# MAGIC When dealing with demographic or ethical bias—where disparities exist across sensitive attributes like gender, race, or age—standard class balancing techniques may be insufficient. Instead, more targeted strategies are used to promote fairness. Pre-processing methods like reweighing assign different instance weights to ensure equitable representation across groups. Techniques such as the disparate impact remover modify feature values to reduce bias while preserving predictive utility. In-processing approaches like adversarial debiasing involve training the main model alongside an adversary that attempts to predict the sensitive attribute, thereby encouraging the model to learn representations that are less biased. Additionally, fair sampling methods, such as Kamiran’s preferential sampling, selectively sample training data to correct for group imbalances. These approaches aim to improve fairness metrics like demographic parity or equal opportunity while maintaining model performance.
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Accelerating credit scoring model creation using MLFlow and Databricks AutoML
+# MAGIC
+# MAGIC MLFlow is an open source project allowing model tracking, packaging and deployment. Every time your Data Science team works on a model, Databricks will track all parameters and data used and will auto-log them. This ensures ML transparency, traceability, and reproducibility, making it easy to know what parameters/data were used to build each model and model version.
+# MAGIC
+# MAGIC ### A glass-box solution that empowers data teams without taking control away
+# MAGIC
+# MAGIC While Databricks simplifies model deployment and governance (MLOps) with MLFlow, bootstraping new ML projects can still be a long and inefficient process.
+# MAGIC
+# MAGIC Instead of creating the same boilerplate for each new project, Databricks AutoML can automatically generate state of the art models for Classifications, Regression, and Forecasting.
+# MAGIC
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Building a Responsible Credit Scoring Model
+# MAGIC
+# MAGIC With our credit decisioning data prepared, we can now leverage it to build a predictive model assessing customer creditworthiness. Our approach will emphasize transparency, fairness, and governance at every step.
+# MAGIC
+# MAGIC Steps in Model Training:
+# MAGIC - **Retrieve Data from the Feature Store:** We begin by accessing the curated and validated features stored in the Databricks Feature Store. This ensures consistency, traceability, and compliance with feature engineering best practices.
+# MAGIC - **Create the Training Dataset:** We assemble a well-balanced training dataset by selecting relevant features and handling missing or biased data points.
+# MAGIC - **Leverage Databricks AutoML:** To streamline model development, we use Databricks AutoML to automatically build and evaluate multiple models. This step ensures we select the most effective model while adhering to Responsible AI principles.
+
+# COMMAND ----------
+
+# DBTITLE 1,Loading the training dataset from the Databricks Feature Store
+from databricks.feature_engineering import FeatureEngineeringClient
+fe = FeatureEngineeringClient()
+
+features_set = fe.read_table(name=f"{catalog}.{db}.credit_decisioning_features")
+display(features_set)
+
+# COMMAND ----------
+
+# DBTITLE 1,Creating the label: "defaulted"
+credit_bureau_label = (spark.table("credit_bureau_gold")
+ .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE") > 60, 1)
+ .otherwise(0))
+ .select("cust_id", "defaulted"))
+#As you can see, we have a fairly imbalanced dataset
+df = credit_bureau_label.groupBy('defaulted').count().toPandas()
+px.pie(df, values='count', names='defaulted', title='Credit default ratio')
+
+# COMMAND ----------
+
+# DBTITLE 1,Build our training dataset (join features and label)
+training_dataset = credit_bureau_label.join(features_set, "cust_id", "inner")
+training_dataset.write.mode('overwrite').saveAsTable('credit_decisioning_features_labels')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Adressing the class imbalance of our dataset
+# MAGIC
+# MAGIC Let's downsample and upsample our dataset to improve our model performance
+
+# COMMAND ----------
+
+major_df = training_dataset.filter(col("defaulted") == 0)
+minor_df = training_dataset.filter(col("defaulted") == 1)
+
+# duplicate the minority rows
+oversampled_df = minor_df.union(minor_df)
+
+# downsample majority rows
+undersampled_df = major_df.sample(oversampled_df.count()/major_df.count()*3, 42)
+
+
+# COMMAND ----------
+
+# combine both oversampled minority rows and undersampled majority rows, this will improve our balance while preseving enough information.
+train_df = undersampled_df.unionAll(oversampled_df).drop('cust_id').na.fill(0)
+
+# COMMAND ----------
+
+# Save it as a table to be able to select it with the AutoML UI.
+train_df.write.mode('overwrite').saveAsTable('credit_risk_train_df')
+px.pie(train_df.groupBy('defaulted').count().toPandas(), values='count', names='defaulted', title='Credit default ratio')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Addressing Demographic or Ethical Bias
+# MAGIC
+# MAGIC When dealing with demographic or ethical bias—where disparities exist across sensitive attributes like gender, race, or age—standard class balancing techniques may be insufficient. Instead, more targeted strategies are used to promote fairness. Pre-processing methods like reweighing assign different instance weights to ensure equitable representation across groups. Techniques such as the disparate impact remover modify feature values to reduce bias while preserving predictive utility. In-processing approaches like adversarial debiasing involve training the main model alongside an adversary that attempts to predict the sensitive attribute, thereby encouraging the model to learn representations that are less biased. Additionally, fair sampling methods, such as Kamiran’s preferential sampling, selectively sample training data to correct for group imbalances. These approaches aim to improve fairness metrics like demographic parity or equal opportunity while maintaining model performance.
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Accelerating credit scoring model creation using MLFlow and Databricks AutoML
+# MAGIC
+# MAGIC MLFlow is an open source project allowing model tracking, packaging and deployment. Every time your Data Science team works on a model, Databricks will track all parameters and data used and will auto-log them. This ensures ML transparency, traceability, and reproducibility, making it easy to know what parameters/data were used to build each model and model version.
+# MAGIC
+# MAGIC ### A glass-box solution that empowers data teams without taking control away
+# MAGIC
+# MAGIC While Databricks simplifies model deployment and governance (MLOps) with MLFlow, bootstraping new ML projects can still be a long and inefficient process.
+# MAGIC
+# MAGIC Instead of creating the same boilerplate for each new project, Databricks AutoML can automatically generate state of the art models for Classifications, Regression, and Forecasting.
+# MAGIC
+# MAGIC
+# MAGIC 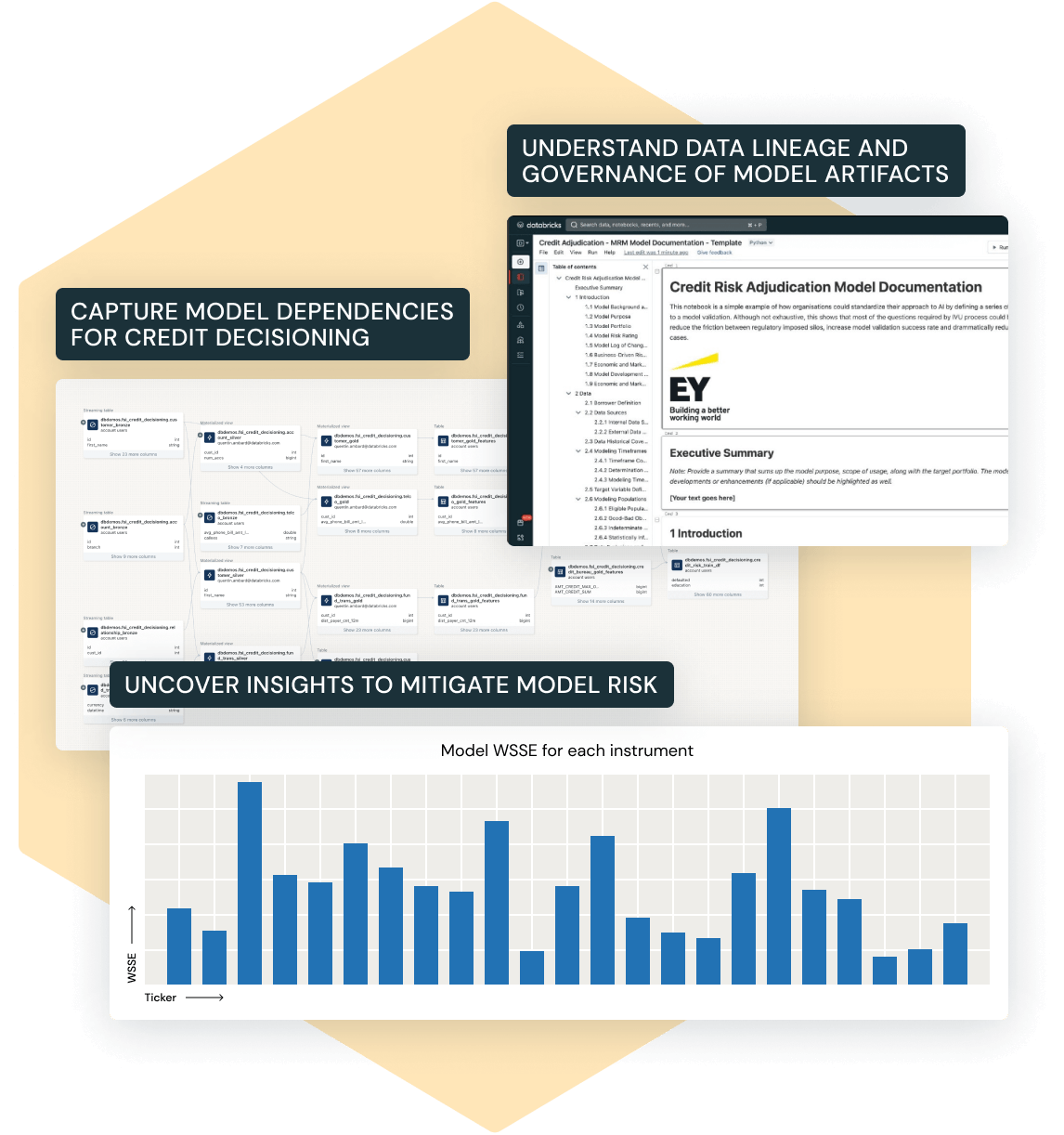 +# MAGIC
+# MAGIC Once we have trained the model, we generate comprehensive model documentation using [Databricks' solutions accelerator](https://www.databricks.com/solutions/accelerators/model-risk-management-with-ey). This step is critical for maintaining compliance, governance, and transparency in financial services.
+# MAGIC
+# MAGIC #### Benefits of Automated Model Documentation:
+# MAGIC
+# MAGIC - Streamlined Model Governance: Automatically generate structured documentation for both machine learning and non-machine learning models, ensuring regulatory alignment.
+# MAGIC - Integrated Data Visualization & Reporting: Provide insights into model performance with built-in dashboards and visual analytics.
+# MAGIC - Risk Identification for Banking Models: Help model validation teams detect and mitigate risks associated with incorrect or misused models in financial decisioning.
+# MAGIC - Foundations for Explainable AI: Enhance trust by making every stage of the model lifecycle transparent, accelerating model validation and deployment processes.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With our model trained and documented, the next step is validation. In the [06.4-Model-Validation]($./06-Responsible-AI/06.4-Model-Validation) notebook, we will conduct compliance checks, pre-deployment tests, and fairness evaluations. This ensures that our model meets regulatory requirements and maintains transparency before it is deployed into production.
+
+# COMMAND ----------
+
+
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py
new file mode 100644
index 00000000..033b784a
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py
@@ -0,0 +1,367 @@
+# Databricks notebook source
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Model Validation
+# MAGIC
+# MAGIC Model validation is a critical step in ensuring the compliance, fairness, and reliability of our credit scoring model before deployment. This notebook performs key compliance checks to align with Responsible AI principles. Specifically, we:
+# MAGIC
+# MAGIC - Validate model fairness for existing credit customers.
+# MAGIC - Analyze feature importance and model behavior using Shapley values.
+# MAGIC - Log custom metrics for auditing and transparency.
+# MAGIC - Ensure compliance with regulatory fairness constraints.
+# MAGIC
+# MAGIC In addition, we also implement the champion-challenger framework to ensure that only the most effective and responsible model is promoted to a higher enviroment. This approach allows us to:
+# MAGIC - Compare the current production model (champion model) with a newly trained model (challenger model).
+# MAGIC - Incorporate human oversight to validate the challenger model before deployment.
+# MAGIC - Maintain full traceability and accountability at each stage of model deployment.
+# MAGIC
+# MAGIC Model validation includes both the model compliance checks and champion-challenger testing. It is only after a model passes these two checks that it is allowed to progress to a high environment. To do so, we:
+# MAGIC - Register the validated model in Unity Catalog and transition it to the next stage.
+# MAGIC
+# MAGIC By following this structured validation approach, we ensure that model transitions are transparent, fair, and aligned with Responsible AI principles.
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC Once we have trained the model, we generate comprehensive model documentation using [Databricks' solutions accelerator](https://www.databricks.com/solutions/accelerators/model-risk-management-with-ey). This step is critical for maintaining compliance, governance, and transparency in financial services.
+# MAGIC
+# MAGIC #### Benefits of Automated Model Documentation:
+# MAGIC
+# MAGIC - Streamlined Model Governance: Automatically generate structured documentation for both machine learning and non-machine learning models, ensuring regulatory alignment.
+# MAGIC - Integrated Data Visualization & Reporting: Provide insights into model performance with built-in dashboards and visual analytics.
+# MAGIC - Risk Identification for Banking Models: Help model validation teams detect and mitigate risks associated with incorrect or misused models in financial decisioning.
+# MAGIC - Foundations for Explainable AI: Enhance trust by making every stage of the model lifecycle transparent, accelerating model validation and deployment processes.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With our model trained and documented, the next step is validation. In the [06.4-Model-Validation]($./06-Responsible-AI/06.4-Model-Validation) notebook, we will conduct compliance checks, pre-deployment tests, and fairness evaluations. This ensures that our model meets regulatory requirements and maintains transparency before it is deployed into production.
+
+# COMMAND ----------
+
+
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py
new file mode 100644
index 00000000..033b784a
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.4-Model-Validation-credit-decisioning.py
@@ -0,0 +1,367 @@
+# Databricks notebook source
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC # Model Validation
+# MAGIC
+# MAGIC Model validation is a critical step in ensuring the compliance, fairness, and reliability of our credit scoring model before deployment. This notebook performs key compliance checks to align with Responsible AI principles. Specifically, we:
+# MAGIC
+# MAGIC - Validate model fairness for existing credit customers.
+# MAGIC - Analyze feature importance and model behavior using Shapley values.
+# MAGIC - Log custom metrics for auditing and transparency.
+# MAGIC - Ensure compliance with regulatory fairness constraints.
+# MAGIC
+# MAGIC In addition, we also implement the champion-challenger framework to ensure that only the most effective and responsible model is promoted to a higher enviroment. This approach allows us to:
+# MAGIC - Compare the current production model (champion model) with a newly trained model (challenger model).
+# MAGIC - Incorporate human oversight to validate the challenger model before deployment.
+# MAGIC - Maintain full traceability and accountability at each stage of model deployment.
+# MAGIC
+# MAGIC Model validation includes both the model compliance checks and champion-challenger testing. It is only after a model passes these two checks that it is allowed to progress to a high environment. To do so, we:
+# MAGIC - Register the validated model in Unity Catalog and transition it to the next stage.
+# MAGIC
+# MAGIC By following this structured validation approach, we ensure that model transitions are transparent, fair, and aligned with Responsible AI principles.
+# MAGIC
+# MAGIC  +
+# COMMAND ----------
+
+# MAGIC %pip install --quiet shap==0.46.0
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Load Data
+# MAGIC
+# MAGIC To validate our model, we first load the necessary data from `credit_decisioning_features` and `credit_bureau_gold` tables. These datasets provide customer financial and credit bureau insights necessary for validation.
+
+# COMMAND ----------
+
+feature_df = spark.table("credit_decisioning_features")
+credit_bureau_label = spark.table("credit_bureau_gold")
+
+df = (feature_df.join(credit_bureau_label, "cust_id", how="left")
+ .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE").isNull(), 2)
+ .when(col("CREDIT_DAY_OVERDUE") > 60, 1)
+ .otherwise(0))
+ .drop('CREDIT_DAY_OVERDUE')
+ .fillna(0))
+display(df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Load model
+# MAGIC
+# MAGIC We retrieve our trained model from the Unity Catalog model registry
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+model = mlflow.pyfunc.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@none")
+features = model.metadata.get_input_schema().input_names()
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Ensuring model fairness for existing credit customers
+# MAGIC
+# MAGIC In this example, we'll make sure that our model behaves as expected and is fair for our existing customers.
+# MAGIC
+# MAGIC We'll select our existing customers not having credit and make sure that our model is fair and behave the same among different group of the population.
+
+# COMMAND ----------
+
+underbanked_df = df[df.defaulted==2].toPandas() # Features for underbanked customers
+banked_df = df[df.defaulted!=2].toPandas() # Features for our existing credit customers
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Feature importance using Shapley values
+# MAGIC
+# MAGIC SHAP is a game-theoretic approach to explain machine learning models, providing a summary plot
+# MAGIC of the relationship between features and model output. Features are ranked in descending order of
+# MAGIC importance, and impact/color describe the correlation between the feature and the target variable.
+# MAGIC - Generating SHAP feature importance is a very memory intensive operation.
+
+# COMMAND ----------
+
+# MAGIC %pip install --quiet shap==0.46.0
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Load Data
+# MAGIC
+# MAGIC To validate our model, we first load the necessary data from `credit_decisioning_features` and `credit_bureau_gold` tables. These datasets provide customer financial and credit bureau insights necessary for validation.
+
+# COMMAND ----------
+
+feature_df = spark.table("credit_decisioning_features")
+credit_bureau_label = spark.table("credit_bureau_gold")
+
+df = (feature_df.join(credit_bureau_label, "cust_id", how="left")
+ .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE").isNull(), 2)
+ .when(col("CREDIT_DAY_OVERDUE") > 60, 1)
+ .otherwise(0))
+ .drop('CREDIT_DAY_OVERDUE')
+ .fillna(0))
+display(df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Load model
+# MAGIC
+# MAGIC We retrieve our trained model from the Unity Catalog model registry
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+model = mlflow.pyfunc.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@none")
+features = model.metadata.get_input_schema().input_names()
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Ensuring model fairness for existing credit customers
+# MAGIC
+# MAGIC In this example, we'll make sure that our model behaves as expected and is fair for our existing customers.
+# MAGIC
+# MAGIC We'll select our existing customers not having credit and make sure that our model is fair and behave the same among different group of the population.
+
+# COMMAND ----------
+
+underbanked_df = df[df.defaulted==2].toPandas() # Features for underbanked customers
+banked_df = df[df.defaulted!=2].toPandas() # Features for our existing credit customers
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Feature importance using Shapley values
+# MAGIC
+# MAGIC SHAP is a game-theoretic approach to explain machine learning models, providing a summary plot
+# MAGIC of the relationship between features and model output. Features are ranked in descending order of
+# MAGIC importance, and impact/color describe the correlation between the feature and the target variable.
+# MAGIC - Generating SHAP feature importance is a very memory intensive operation.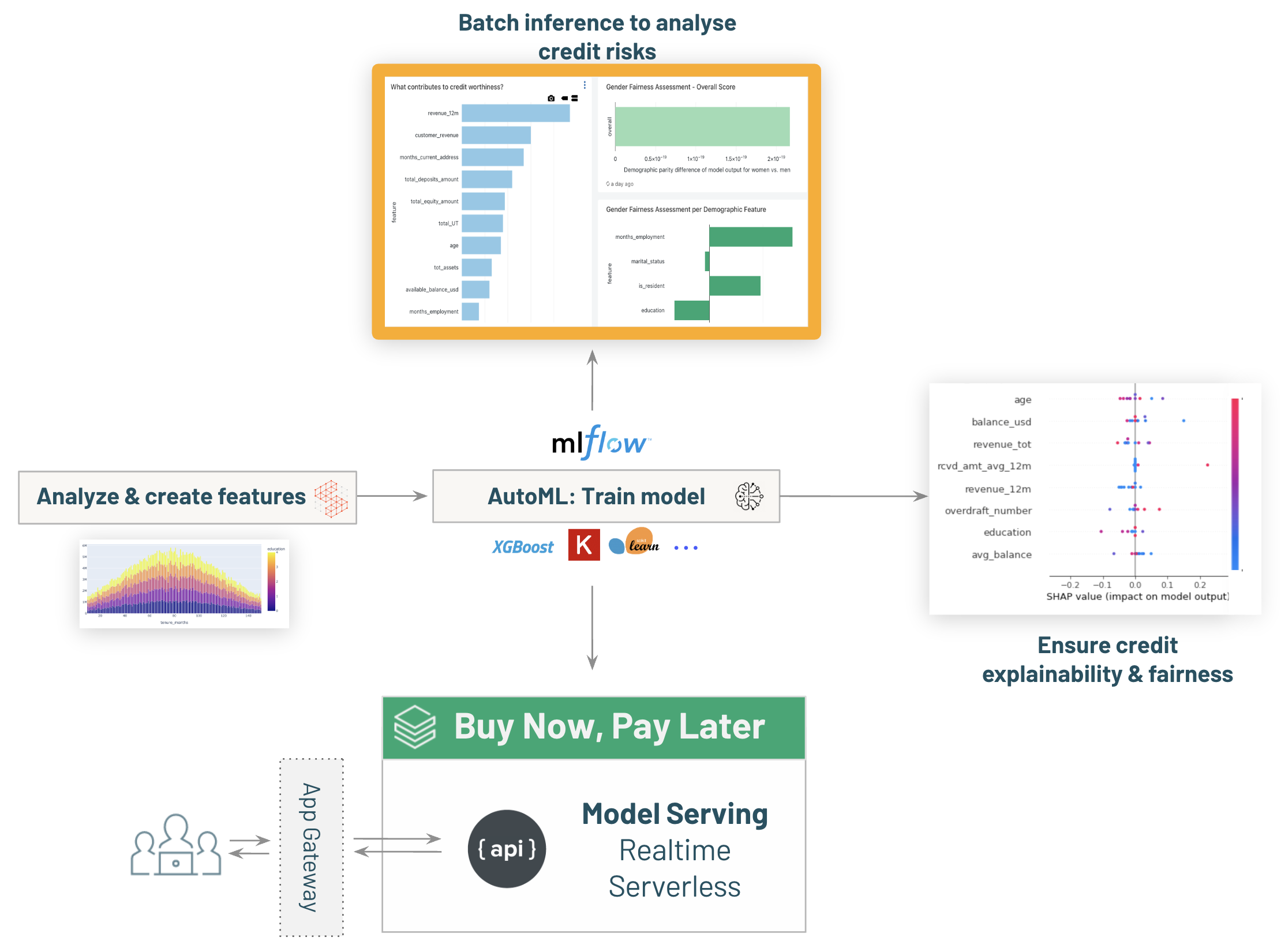 -# MAGIC
-# MAGIC
-# MAGIC ### *"Can we allow a user without sufficient balance in their account to complete the current (debit or credit) transaction?"*
-# MAGIC
-# MAGIC
-# MAGIC We will utilize our credit risk model (built in the previous steps) in real-time to answer this question.
-# MAGIC
-# MAGIC The payment system will be able to call our API in realtime and get a score within a few ms.
-# MAGIC
-# MAGIC With this information, we'll be able to offer our customer the choice to pay with a credit automatically, or refuse if the model believes the risk is too high and will likely result in a payment default.
-# MAGIC
-# MAGIC
-# MAGIC These types of decisions are typically embedded in live Point Of Sales (stores, online shop). That is why we need real-time serving capabilities.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC ### *"Can we allow a user without sufficient balance in their account to complete the current (debit or credit) transaction?"*
-# MAGIC
-# MAGIC
-# MAGIC We will utilize our credit risk model (built in the previous steps) in real-time to answer this question.
-# MAGIC
-# MAGIC The payment system will be able to call our API in realtime and get a score within a few ms.
-# MAGIC
-# MAGIC With this information, we'll be able to offer our customer the choice to pay with a credit automatically, or refuse if the model believes the risk is too high and will likely result in a payment default.
-# MAGIC
-# MAGIC
-# MAGIC These types of decisions are typically embedded in live Point Of Sales (stores, online shop). That is why we need real-time serving capabilities.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC # Deploying the Credit Scoring model for real-time serving
-# MAGIC
-# MAGIC
-# MAGIC Let's deploy our model behind a scalable API to evaluate credit-worthiness in real-time.
-# MAGIC
-# MAGIC ## Databricks Model Serving
-# MAGIC
-# MAGIC Now that our model has been created with Databricks AutoML, we can easily flag it as Production Ready and turn on Databricks Model Serving.
-# MAGIC
-# MAGIC We'll be able to send HTTP Requests and get inference in real-time.
-# MAGIC
-# MAGIC Databricks Model Serving is fully serverless:
-# MAGIC
-# MAGIC * One-click deployment. Databricks will handle scalability, providing blazing fast inferences and startup time.
-# MAGIC * Scale down to zero as an option for best TCO (will shut down if the endpoint isn't used).
-# MAGIC * Built-in support for multiple models & version deployed.
-# MAGIC * A/B Testing and easy upgrade, routing traffic between each versions while measuring impact.
-# MAGIC * Built-in metrics & monitoring.
-
-# COMMAND ----------
-
-# MAGIC %pip install mlflow==2.19.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# DBTITLE 1,Make sure our last model version is deployed in production in our registry
-import mlflow
-model_name = "dbdemos_fsi_credit_decisioning"
-mlflow.set_registry_uri('databricks-uc')
-
-# COMMAND ----------
-
-
-from databricks.sdk import WorkspaceClient
-from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, AutoCaptureConfigInput
-
-model_name = f"{catalog}.{db}.dbdemos_fsi_credit_decisioning"
-serving_endpoint_name = "dbdemos_fsi_credit_decisioning_endpoint"
-w = WorkspaceClient()
-endpoint_config = EndpointCoreConfigInput(
- name=serving_endpoint_name,
- served_entities=[
- ServedEntityInput(
- entity_name=model_name,
- entity_version=get_latest_model_version(model_name),
- scale_to_zero_enabled=True,
- workload_size="Small"
- )
- ],
- auto_capture_config = AutoCaptureConfigInput(catalog_name=catalog, schema_name=db, enabled=True, table_name_prefix="inference_table" )
-)
-
-force_update = False #Set this to True to release a newer version (the demo won't update the endpoint to a newer model version by default)
-existing_endpoint = next((e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None)
-if existing_endpoint == None:
- print(f"Creating the endpoint {serving_endpoint_name}, this will take a few minutes to package and deploy the endpoint...")
- w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
-else:
- print(f"endpoint {serving_endpoint_name} already exist...")
- if force_update:
- w.serving_endpoints.update_config_and_wait(served_entities=endpoint_config.served_entities, name=serving_endpoint_name)
-
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC Our model endpoint was automatically created.
-# MAGIC
-# MAGIC Open the [endpoint UI](#mlflow/endpoints/dbdemos_fsi_credit_decisioning_endpoint) to explore your endpoint and use the UI to send queries.
-# MAGIC
-# MAGIC *Note that the first deployment will build your model image and take a few minutes. It'll then stop & start instantly.*
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ### Testing the model
-# MAGIC
-# MAGIC Now that the model is deployed, let's test it with information for a customer trying to temporarily increase their credit limits or obtain a micro-loan at the point-of-sale.
-
-# COMMAND ----------
-
-from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
-from mlflow.models.model import Model
-
-p = ModelsArtifactRepository(f"models:/{model_name}@prod").download_artifacts("")
-dataset = {"dataframe_split": Model.load(p).load_input_example(p).to_dict(orient='split')}
-
-# COMMAND ----------
-
-import mlflow
-from mlflow import deployments
-client = mlflow.deployments.get_deploy_client("databricks")
-predictions = client.predict(endpoint=serving_endpoint_name, inputs=dataset)
-
-prediction_score = list(predictions["predictions"])[0]
-print(
- f"The transaction will be approved. Score: {prediction_score}."
- if prediction_score == 0
- else f"The transaction will not be approved. Score: {prediction_score}."
-)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC # Updating your model and monitoring its performance with A/B testing
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC # Deploying the Credit Scoring model for real-time serving
-# MAGIC
-# MAGIC
-# MAGIC Let's deploy our model behind a scalable API to evaluate credit-worthiness in real-time.
-# MAGIC
-# MAGIC ## Databricks Model Serving
-# MAGIC
-# MAGIC Now that our model has been created with Databricks AutoML, we can easily flag it as Production Ready and turn on Databricks Model Serving.
-# MAGIC
-# MAGIC We'll be able to send HTTP Requests and get inference in real-time.
-# MAGIC
-# MAGIC Databricks Model Serving is fully serverless:
-# MAGIC
-# MAGIC * One-click deployment. Databricks will handle scalability, providing blazing fast inferences and startup time.
-# MAGIC * Scale down to zero as an option for best TCO (will shut down if the endpoint isn't used).
-# MAGIC * Built-in support for multiple models & version deployed.
-# MAGIC * A/B Testing and easy upgrade, routing traffic between each versions while measuring impact.
-# MAGIC * Built-in metrics & monitoring.
-
-# COMMAND ----------
-
-# MAGIC %pip install mlflow==2.19.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# DBTITLE 1,Make sure our last model version is deployed in production in our registry
-import mlflow
-model_name = "dbdemos_fsi_credit_decisioning"
-mlflow.set_registry_uri('databricks-uc')
-
-# COMMAND ----------
-
-
-from databricks.sdk import WorkspaceClient
-from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, AutoCaptureConfigInput
-
-model_name = f"{catalog}.{db}.dbdemos_fsi_credit_decisioning"
-serving_endpoint_name = "dbdemos_fsi_credit_decisioning_endpoint"
-w = WorkspaceClient()
-endpoint_config = EndpointCoreConfigInput(
- name=serving_endpoint_name,
- served_entities=[
- ServedEntityInput(
- entity_name=model_name,
- entity_version=get_latest_model_version(model_name),
- scale_to_zero_enabled=True,
- workload_size="Small"
- )
- ],
- auto_capture_config = AutoCaptureConfigInput(catalog_name=catalog, schema_name=db, enabled=True, table_name_prefix="inference_table" )
-)
-
-force_update = False #Set this to True to release a newer version (the demo won't update the endpoint to a newer model version by default)
-existing_endpoint = next((e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None)
-if existing_endpoint == None:
- print(f"Creating the endpoint {serving_endpoint_name}, this will take a few minutes to package and deploy the endpoint...")
- w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
-else:
- print(f"endpoint {serving_endpoint_name} already exist...")
- if force_update:
- w.serving_endpoints.update_config_and_wait(served_entities=endpoint_config.served_entities, name=serving_endpoint_name)
-
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC Our model endpoint was automatically created.
-# MAGIC
-# MAGIC Open the [endpoint UI](#mlflow/endpoints/dbdemos_fsi_credit_decisioning_endpoint) to explore your endpoint and use the UI to send queries.
-# MAGIC
-# MAGIC *Note that the first deployment will build your model image and take a few minutes. It'll then stop & start instantly.*
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ### Testing the model
-# MAGIC
-# MAGIC Now that the model is deployed, let's test it with information for a customer trying to temporarily increase their credit limits or obtain a micro-loan at the point-of-sale.
-
-# COMMAND ----------
-
-from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
-from mlflow.models.model import Model
-
-p = ModelsArtifactRepository(f"models:/{model_name}@prod").download_artifacts("")
-dataset = {"dataframe_split": Model.load(p).load_input_example(p).to_dict(orient='split')}
-
-# COMMAND ----------
-
-import mlflow
-from mlflow import deployments
-client = mlflow.deployments.get_deploy_client("databricks")
-predictions = client.predict(endpoint=serving_endpoint_name, inputs=dataset)
-
-prediction_score = list(predictions["predictions"])[0]
-print(
- f"The transaction will be approved. Score: {prediction_score}."
- if prediction_score == 0
- else f"The transaction will not be approved. Score: {prediction_score}."
-)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC # Updating your model and monitoring its performance with A/B testing
-# MAGIC
-# MAGIC
-# MAGIC 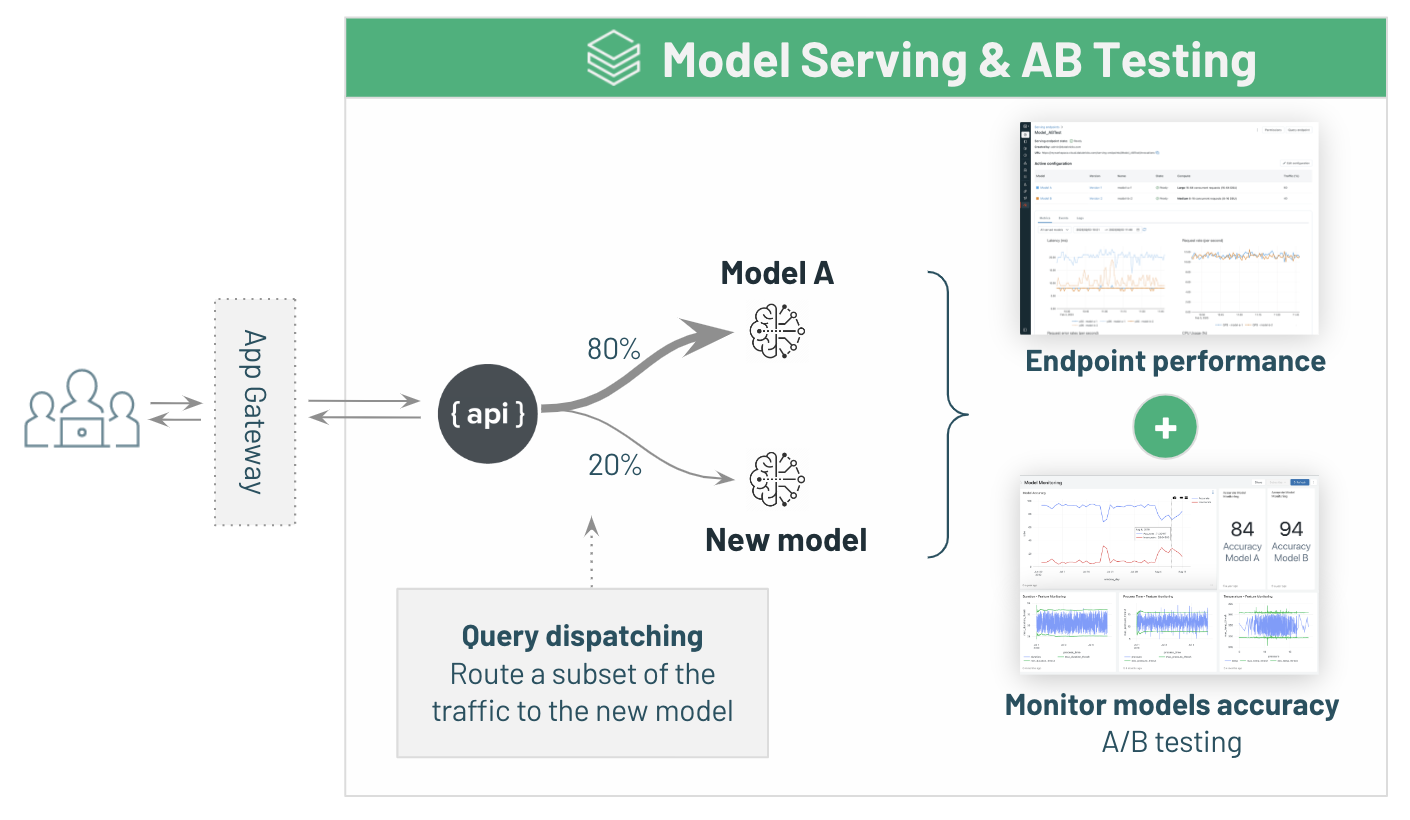 -# MAGIC
-# MAGIC Databricks Model Serving let you easily deploy & test new versions of your model.
-# MAGIC
-# MAGIC You can dynamically reconfigure your endpoint to route a subset of your traffic to a newer version. In addition, you can leverage endpoint monitoring to understand your model behavior and track your A/B deployment.
-# MAGIC
-# MAGIC * Without making any production outage
-# MAGIC * Slowly routing requests to the new model
-# MAGIC * Supporting auto-scaling & potential bursts
-# MAGIC * Performing some A/B testing ensuring the new model is providing better outcomes
-# MAGIC * Monitorig our model outcome and technical metrics (CPU/load etc)
-# MAGIC
-# MAGIC Databricks makes this process super simple with Serverless Model Serving endpoint.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Databricks Model Serving let you easily deploy & test new versions of your model.
-# MAGIC
-# MAGIC You can dynamically reconfigure your endpoint to route a subset of your traffic to a newer version. In addition, you can leverage endpoint monitoring to understand your model behavior and track your A/B deployment.
-# MAGIC
-# MAGIC * Without making any production outage
-# MAGIC * Slowly routing requests to the new model
-# MAGIC * Supporting auto-scaling & potential bursts
-# MAGIC * Performing some A/B testing ensuring the new model is providing better outcomes
-# MAGIC * Monitorig our model outcome and technical metrics (CPU/load etc)
-# MAGIC
-# MAGIC Databricks makes this process super simple with Serverless Model Serving endpoint.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC 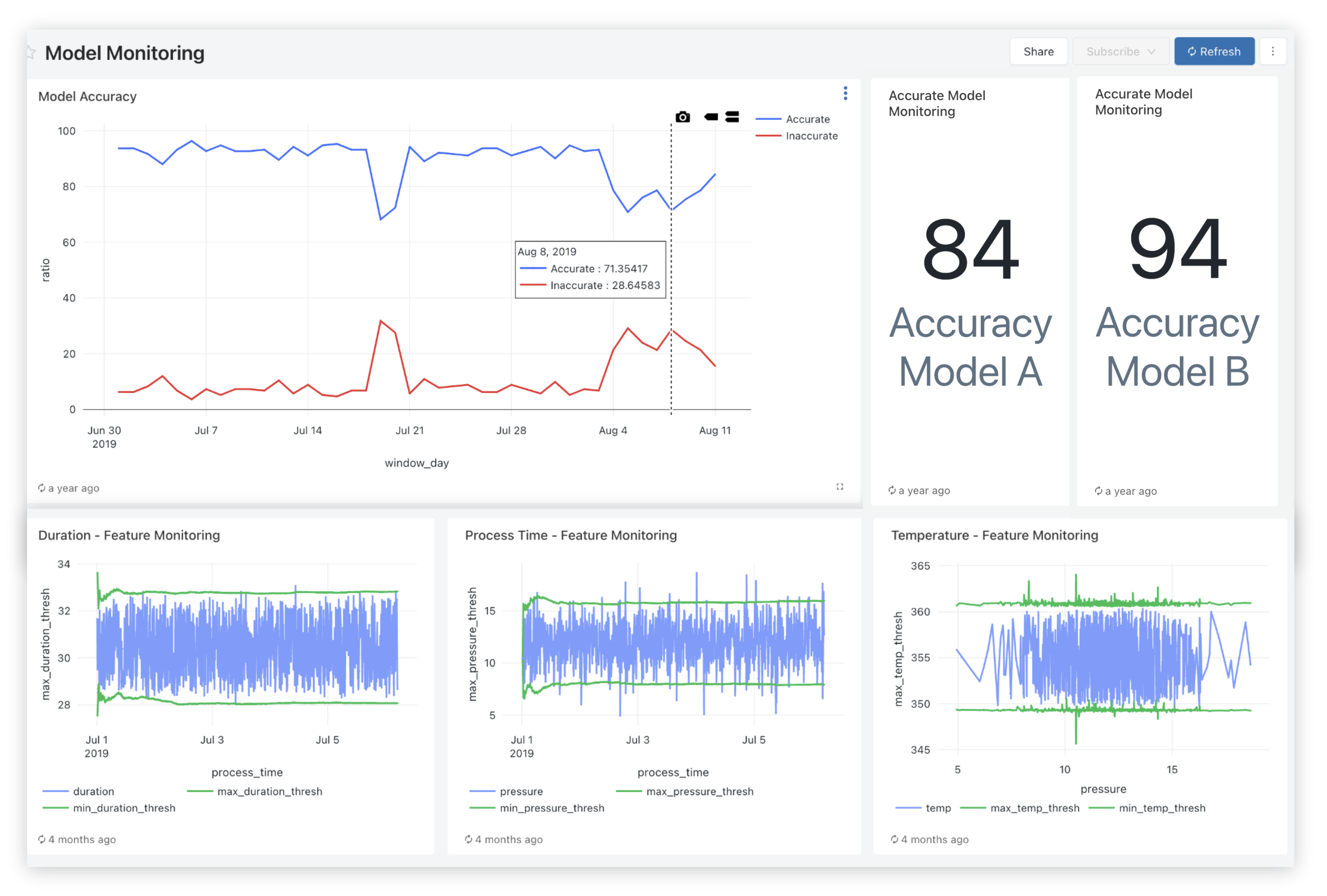 -
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Next
-# MAGIC
-# MAGIC Making sure your model is fair towards customers of any demographics are extremely important parts of building production-ready ML models for FSI use cases.
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC ## Next
-# MAGIC
-# MAGIC Making sure your model is fair towards customers of any demographics are extremely important parts of building production-ready ML models for FSI use cases. 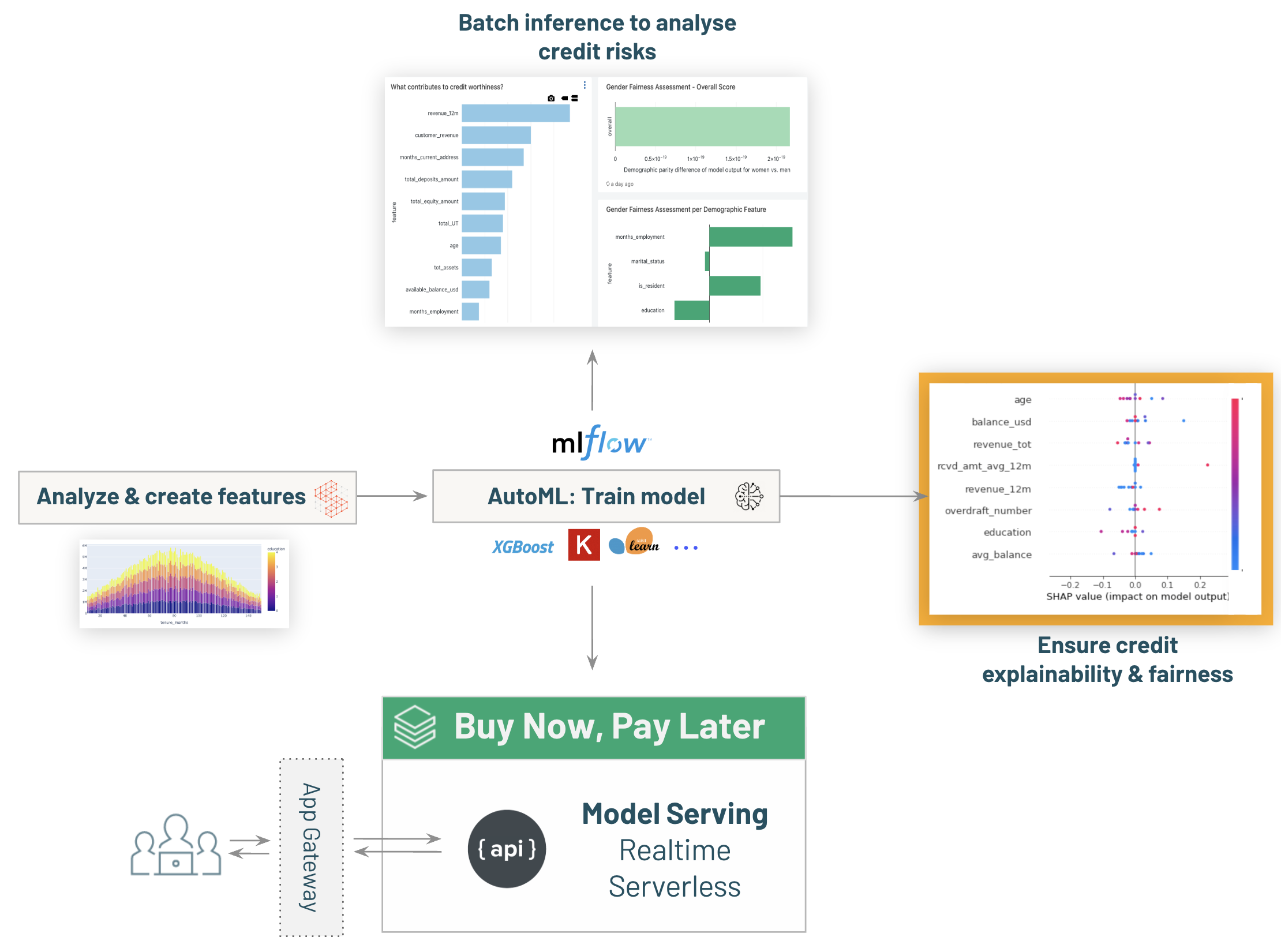 -# MAGIC
-# MAGIC
-# MAGIC Machine learning (ML) models are increasingly being used in credit decisioning to automate lending processes, reduce costs, and improve accuracy.
-# MAGIC
-# MAGIC As ML models become more complex and data-driven, their decision-making processes can become opaque, making it challenging to understand how decisions are made, and to ensure that they are fair and non-discriminatory.
-# MAGIC
-# MAGIC Therefore, it is essential to develop techniques that enable model explainability and fairness in credit decisioning to ensure that the use of ML does not perpetuate existing biases or discrimination.
-# MAGIC
-# MAGIC In this context, explainability refers to the ability to understand how an ML model is making its decisions, while fairness refers to ensuring that the model is not discriminating against certain groups of people.
-# MAGIC
-# MAGIC ## Ensuring model fairness for new credit customers
-# MAGIC
-# MAGIC In this example, we'll make sure that our model behaves as expected and is fair for our new customers.
-# MAGIC
-# MAGIC We'll select our existing customers not having credit (We'll flag them as `defaulted = 2`) and make sure that our model is fair and behave the same among different group of the population.
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC Machine learning (ML) models are increasingly being used in credit decisioning to automate lending processes, reduce costs, and improve accuracy.
-# MAGIC
-# MAGIC As ML models become more complex and data-driven, their decision-making processes can become opaque, making it challenging to understand how decisions are made, and to ensure that they are fair and non-discriminatory.
-# MAGIC
-# MAGIC Therefore, it is essential to develop techniques that enable model explainability and fairness in credit decisioning to ensure that the use of ML does not perpetuate existing biases or discrimination.
-# MAGIC
-# MAGIC In this context, explainability refers to the ability to understand how an ML model is making its decisions, while fairness refers to ensuring that the model is not discriminating against certain groups of people.
-# MAGIC
-# MAGIC ## Ensuring model fairness for new credit customers
-# MAGIC
-# MAGIC In this example, we'll make sure that our model behaves as expected and is fair for our new customers.
-# MAGIC
-# MAGIC We'll select our existing customers not having credit (We'll flag them as `defaulted = 2`) and make sure that our model is fair and behave the same among different group of the population.
-# MAGIC
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %pip install --quiet shap==0.46.0 mlflow==2.19.0 scikit-learn==1.3.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC Here we are merging several PII columns (hence we read from the ```customer_silver``` table) with the model prediction output table for visualizing them on the dashboard for end user consumption
-
-# COMMAND ----------
-
-feature_df = spark.table("credit_decisioning_features")
-credit_bureau_label = spark.table("credit_bureau_gold")
-customer_df = spark.table(f"customer_silver").select("cust_id", "gender", "first_name", "last_name", "email", "mobile_phone")
-
-df = (feature_df.join(customer_df, "cust_id", how="left")
- .join(credit_bureau_label, "cust_id", how="left")
- .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE").isNull(), 2)
- .when(col("CREDIT_DAY_OVERDUE") > 60, 1)
- .otherwise(0))
- .drop('CREDIT_DAY_OVERDUE')
- .fillna(0))
-display(df)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Load Model from the registry
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-import mlflow
-mlflow.set_registry_uri('databricks-uc')
-
-model = mlflow.pyfunc.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@prod")
-features = model.metadata.get_input_schema().input_names()
-
-# COMMAND ----------
-
-underbanked_df = df[df.defaulted==2].toPandas() # Features for underbanked customers
-banked_df = df[df.defaulted!=2].toPandas() # Features for rest of the customers
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Feature importance using Shapley values
-# MAGIC
-# MAGIC SHAP is a game-theoretic approach to explain machine learning models, providing a summary plot
-# MAGIC of the relationship between features and model output. Features are ranked in descending order of
-# MAGIC importance, and impact/color describe the correlation between the feature and the target variable.
-# MAGIC - Generating SHAP feature importance is a very memory intensive operation.
-
-# COMMAND ----------
-
-# MAGIC %pip install --quiet shap==0.46.0 mlflow==2.19.0 scikit-learn==1.3.0
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-# MAGIC %run ../_resources/00-setup $reset_all_data=false
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC Here we are merging several PII columns (hence we read from the ```customer_silver``` table) with the model prediction output table for visualizing them on the dashboard for end user consumption
-
-# COMMAND ----------
-
-feature_df = spark.table("credit_decisioning_features")
-credit_bureau_label = spark.table("credit_bureau_gold")
-customer_df = spark.table(f"customer_silver").select("cust_id", "gender", "first_name", "last_name", "email", "mobile_phone")
-
-df = (feature_df.join(customer_df, "cust_id", how="left")
- .join(credit_bureau_label, "cust_id", how="left")
- .withColumn("defaulted", F.when(col("CREDIT_DAY_OVERDUE").isNull(), 2)
- .when(col("CREDIT_DAY_OVERDUE") > 60, 1)
- .otherwise(0))
- .drop('CREDIT_DAY_OVERDUE')
- .fillna(0))
-display(df)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Load Model from the registry
-
-# COMMAND ----------
-
-model_name = "dbdemos_fsi_credit_decisioning"
-import mlflow
-mlflow.set_registry_uri('databricks-uc')
-
-model = mlflow.pyfunc.load_model(model_uri=f"models:/{catalog}.{db}.{model_name}@prod")
-features = model.metadata.get_input_schema().input_names()
-
-# COMMAND ----------
-
-underbanked_df = df[df.defaulted==2].toPandas() # Features for underbanked customers
-banked_df = df[df.defaulted!=2].toPandas() # Features for rest of the customers
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Feature importance using Shapley values
-# MAGIC
-# MAGIC SHAP is a game-theoretic approach to explain machine learning models, providing a summary plot
-# MAGIC of the relationship between features and model output. Features are ranked in descending order of
-# MAGIC importance, and impact/color describe the correlation between the feature and the target variable.
-# MAGIC - Generating SHAP feature importance is a very memory intensive operation. +
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Retrieve the `Staging` model
+# MAGIC
+# MAGIC We will first retrieve the `Staging` model registered in Unity Catalog. As we run integration tests against it, we will update the model with status information from the tests.
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve model info run by alias
+client = mlflow.tracking.MlflowClient()
+
+# Fetch the Staging model
+try:
+ model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+except:
+ model_info = None
+
+assert model_info is not None, 'No Staging model. Deploy one to Staging first.'
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Testing batch inference
+# MAGIC
+# MAGIC Since the model will be integrated into a batch inference pipeline, we will illustrate integration testing by running a batch inference test in this demo.
+# MAGIC
+# MAGIC We can easily load the model as a Spark UDF scoring function by indicating its `Staging` alias. This is the same way as how we load models for batch scoring in Production. The only difference is the the alias we use, as we will see in the next notebook.
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark,
+ model_uri=f"models:/{catalog}.{db}.{model_name}@staging", result_type='double',
+ env_manager="virtualenv")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC For now, we will test the batch inference pipeline by loading the features in the Staging environment, and apply the model to perform inference. Performing integration tests can help us detect issues arising from missing features in upstream tables, empty prediction values due to feature values not used in training, just to name a couple of examples.
+
+# COMMAND ----------
+
+from pyspark.sql import functions as F
+
+features = loaded_model.metadata.get_input_schema().input_names()
+
+feature_df = spark.table("credit_decisioning_features_labels").fillna(0)
+
+try:
+ prediction_df = feature_df.withColumn("prediction", loaded_model(F.struct(*features)).cast("integer")) \
+ .withColumn("model_id", F.lit(1)).cache()
+except:
+ prediction_df = None
+
+display(prediction_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Perform tests
+# MAGIC
+# MAGIC Next, we perform a number of tests on the inference results to ensure that the systems will behave properly after integrating the model. We use a few simple examples:
+# MAGIC
+# MAGIC - Check that a object is returned for the resulting DataFrame
+# MAGIC - The inference code may not return a result if there are missing features in the upstream table.
+# MAGIC - Furthermore, a `None` return object can cause issues to downstream code.
+# MAGIC - Check that the resulting DataFrame has rows in it
+# MAGIC - An empty DataFrame may cause issues to downstream code.
+# MAGIC - Check that there are no null values in the prediction column
+# MAGIC - The team needs to determine if null values are expected, and how the system should handle them.
+
+# COMMAND ----------
+
+# These tests should all return True to pass
+result_df_not_null = (
+ prediction_df != None
+)
+result_df_not_empty = (
+ prediction_df.count() > 0
+)
+no_null_pred_values = (
+ prediction_df.filter(prediction_df.prediction.isNull()).count() == 0
+)
+
+print(f"An object is returned for the result DataFrame: {result_df_not_null}")
+print(f"Result DataFrame contains rows: {result_df_not_empty}")
+print(f"No null prediction values: {no_null_pred_values}")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Update integration testing status
+# MAGIC
+# MAGIC Having performed the tests, we will now update the model's integration testing status. Only models that have passed all tests are allowed to be promoted to production.
+# MAGIC
+# MAGIC For auditability, we also apply tags on the version of the model in Unity Catalog to record the status of the integration tests.
+
+# COMMAND ----------
+
+# Indicate if result_df_not_null test has passed
+pass_fail = "failed"
+if result_df_not_null:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_result_df_not_null", pass_fail)
+
+# Indicate if result_df_not_empty test has passed
+pass_fail = "failed"
+if result_df_not_empty:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_result_df_not_empty", pass_fail)
+
+# Indicate if no_null_pred_values test has passed
+pass_fail = "failed"
+if no_null_pred_values:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_no_null_pred_values", pass_fail)
+
+# Model Validation Status is 'approved' only if both compliance checks and champion-challenger test have passed
+# Otherwise Model Validation Status is 'rejected'
+integration_test_status = "Not tested"
+if result_df_not_null & result_df_not_empty & no_null_pred_values:
+ integration_test_status = "passed"
+else:
+ integration_test_status = "failed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, "integration_test_status", integration_test_status)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Promote model to Production
+# MAGIC
+# MAGIC Our model is now ready to be promoted to `Production`. As we do so, we also archive the existing production model by setting its alias to `Archived`.
+# MAGIC
+# MAGIC If our model did not pass the integration tests, we simply transition it to `Archived`, while leaving the existing model in `Production` untouched.
+
+# COMMAND ----------
+
+# Fetch the Production model (if any)
+try:
+ prod_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="production")
+except:
+ prod_model_info = None
+
+if integration_test_status == "passed":
+ # This model has passed integration testing. Check if there's an existing model in Production
+ if prod_model_info is not None:
+ # Existing model in production. Archive the existing prod model.
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=prod_model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", prod_model_info.version, f"archived", "true")
+ print(f'Version {prod_model_info.version} of {catalog}.{db}.{model_name} is now archived.')
+ else:
+ # No model in production.
+ print(f'{catalog}.{db}.{model_name} does not have a Production model.')
+ # Promote this model to Production
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="production", version=model_info.version)
+ print(f'Version {model_info.version} of {catalog}.{db}.{model_name} is now promoted to Production.')
+else:
+ # This model has failed integration testing. Set it to Archived
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"archived", "true")
+ print(f'Version {model_info.version} of {catalog}.{db}.{model_name} is transitioned to Archived. No model promoted to Production.')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC We just moved our automl model as production ready!
+# MAGIC
+# MAGIC Open the model in Unity Catalog to explore its artifact and analyze the parameters used, including traceability to the notebook used for its creation.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC
+# MAGIC Now that the model is in Production, we proceed to [06.6-Model-Inference]($./06-Responsible-AI/06.6-Model-Inference), where the deployed model is used for batch or real-time inference and predictions are logged for explainability and transparency. This ensures that model outputs are reliable, ethical, and aligned with regulatory standards, closing the loop on Responsible AI implementation.
+
+# COMMAND ----------
+
+
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py
new file mode 100644
index 00000000..ed952bb1
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py
@@ -0,0 +1,183 @@
+# Databricks notebook source
+# MAGIC %md-sandbox
+# MAGIC # Model Inference
+# MAGIC
+# MAGIC In this notebook, we demonstrate how to operationalize machine learning models on Databricks by enabling both batch and real-time inference. For real-time serving, we leverage Databricks Model Serving, which allows us to expose the model through a low-latency REST API endpoint, enabling scalable and responsive predictions for downstream applications. We also implement batch inference using pyspark for large-scale processing. This dual approach illustrates how Databricks supports a unified platform for production-grade ML inference across diverse use cases.
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Retrieve the `Staging` model
+# MAGIC
+# MAGIC We will first retrieve the `Staging` model registered in Unity Catalog. As we run integration tests against it, we will update the model with status information from the tests.
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve model info run by alias
+client = mlflow.tracking.MlflowClient()
+
+# Fetch the Staging model
+try:
+ model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+except:
+ model_info = None
+
+assert model_info is not None, 'No Staging model. Deploy one to Staging first.'
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Testing batch inference
+# MAGIC
+# MAGIC Since the model will be integrated into a batch inference pipeline, we will illustrate integration testing by running a batch inference test in this demo.
+# MAGIC
+# MAGIC We can easily load the model as a Spark UDF scoring function by indicating its `Staging` alias. This is the same way as how we load models for batch scoring in Production. The only difference is the the alias we use, as we will see in the next notebook.
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark,
+ model_uri=f"models:/{catalog}.{db}.{model_name}@staging", result_type='double',
+ env_manager="virtualenv")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC For now, we will test the batch inference pipeline by loading the features in the Staging environment, and apply the model to perform inference. Performing integration tests can help us detect issues arising from missing features in upstream tables, empty prediction values due to feature values not used in training, just to name a couple of examples.
+
+# COMMAND ----------
+
+from pyspark.sql import functions as F
+
+features = loaded_model.metadata.get_input_schema().input_names()
+
+feature_df = spark.table("credit_decisioning_features_labels").fillna(0)
+
+try:
+ prediction_df = feature_df.withColumn("prediction", loaded_model(F.struct(*features)).cast("integer")) \
+ .withColumn("model_id", F.lit(1)).cache()
+except:
+ prediction_df = None
+
+display(prediction_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Perform tests
+# MAGIC
+# MAGIC Next, we perform a number of tests on the inference results to ensure that the systems will behave properly after integrating the model. We use a few simple examples:
+# MAGIC
+# MAGIC - Check that a object is returned for the resulting DataFrame
+# MAGIC - The inference code may not return a result if there are missing features in the upstream table.
+# MAGIC - Furthermore, a `None` return object can cause issues to downstream code.
+# MAGIC - Check that the resulting DataFrame has rows in it
+# MAGIC - An empty DataFrame may cause issues to downstream code.
+# MAGIC - Check that there are no null values in the prediction column
+# MAGIC - The team needs to determine if null values are expected, and how the system should handle them.
+
+# COMMAND ----------
+
+# These tests should all return True to pass
+result_df_not_null = (
+ prediction_df != None
+)
+result_df_not_empty = (
+ prediction_df.count() > 0
+)
+no_null_pred_values = (
+ prediction_df.filter(prediction_df.prediction.isNull()).count() == 0
+)
+
+print(f"An object is returned for the result DataFrame: {result_df_not_null}")
+print(f"Result DataFrame contains rows: {result_df_not_empty}")
+print(f"No null prediction values: {no_null_pred_values}")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Update integration testing status
+# MAGIC
+# MAGIC Having performed the tests, we will now update the model's integration testing status. Only models that have passed all tests are allowed to be promoted to production.
+# MAGIC
+# MAGIC For auditability, we also apply tags on the version of the model in Unity Catalog to record the status of the integration tests.
+
+# COMMAND ----------
+
+# Indicate if result_df_not_null test has passed
+pass_fail = "failed"
+if result_df_not_null:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_result_df_not_null", pass_fail)
+
+# Indicate if result_df_not_empty test has passed
+pass_fail = "failed"
+if result_df_not_empty:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_result_df_not_empty", pass_fail)
+
+# Indicate if no_null_pred_values test has passed
+pass_fail = "failed"
+if no_null_pred_values:
+ pass_fail = "passed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"inttest_no_null_pred_values", pass_fail)
+
+# Model Validation Status is 'approved' only if both compliance checks and champion-challenger test have passed
+# Otherwise Model Validation Status is 'rejected'
+integration_test_status = "Not tested"
+if result_df_not_null & result_df_not_empty & no_null_pred_values:
+ integration_test_status = "passed"
+else:
+ integration_test_status = "failed"
+client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, "integration_test_status", integration_test_status)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Promote model to Production
+# MAGIC
+# MAGIC Our model is now ready to be promoted to `Production`. As we do so, we also archive the existing production model by setting its alias to `Archived`.
+# MAGIC
+# MAGIC If our model did not pass the integration tests, we simply transition it to `Archived`, while leaving the existing model in `Production` untouched.
+
+# COMMAND ----------
+
+# Fetch the Production model (if any)
+try:
+ prod_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="production")
+except:
+ prod_model_info = None
+
+if integration_test_status == "passed":
+ # This model has passed integration testing. Check if there's an existing model in Production
+ if prod_model_info is not None:
+ # Existing model in production. Archive the existing prod model.
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=prod_model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", prod_model_info.version, f"archived", "true")
+ print(f'Version {prod_model_info.version} of {catalog}.{db}.{model_name} is now archived.')
+ else:
+ # No model in production.
+ print(f'{catalog}.{db}.{model_name} does not have a Production model.')
+ # Promote this model to Production
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="production", version=model_info.version)
+ print(f'Version {model_info.version} of {catalog}.{db}.{model_name} is now promoted to Production.')
+else:
+ # This model has failed integration testing. Set it to Archived
+ client.delete_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="staging")
+ client.set_registered_model_alias(name=f"{catalog}.{db}.{model_name}", alias="archived", version=model_info.version)
+ client.set_model_version_tag(f"{catalog}.{db}.{model_name}", model_info.version, f"archived", "true")
+ print(f'Version {model_info.version} of {catalog}.{db}.{model_name} is transitioned to Archived. No model promoted to Production.')
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC We just moved our automl model as production ready!
+# MAGIC
+# MAGIC Open the model in Unity Catalog to explore its artifact and analyze the parameters used, including traceability to the notebook used for its creation.
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC
+# MAGIC Now that the model is in Production, we proceed to [06.6-Model-Inference]($./06-Responsible-AI/06.6-Model-Inference), where the deployed model is used for batch or real-time inference and predictions are logged for explainability and transparency. This ensures that model outputs are reliable, ethical, and aligned with regulatory standards, closing the loop on Responsible AI implementation.
+
+# COMMAND ----------
+
+
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py
new file mode 100644
index 00000000..ed952bb1
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.6-Model-Inference-credit-decisioning.py
@@ -0,0 +1,183 @@
+# Databricks notebook source
+# MAGIC %md-sandbox
+# MAGIC # Model Inference
+# MAGIC
+# MAGIC In this notebook, we demonstrate how to operationalize machine learning models on Databricks by enabling both batch and real-time inference. For real-time serving, we leverage Databricks Model Serving, which allows us to expose the model through a low-latency REST API endpoint, enabling scalable and responsive predictions for downstream applications. We also implement batch inference using pyspark for large-scale processing. This dual approach illustrates how Databricks supports a unified platform for production-grade ML inference across diverse use cases.
+# MAGIC  +
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Running batch inference
+# MAGIC
+# MAGIC Now that our model has been successfully trained and deployed to production within the MLFlow registry, we can seamlessly integrate it into various Data Engineering workflows.
+# MAGIC
+# MAGIC We can now easily load it calling the `Production` stage, and use it in any Data Engineering pipeline (a job running every night, in streaming or even within a Delta Live Table pipeline).
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark,
+ model_uri=f"models:/{catalog}.{db}.{model_name}@production", result_type='double',
+ env_manager="virtualenv")
+
+# COMMAND ----------
+
+from pyspark.sql import functions as F
+
+features = loaded_model.metadata.get_input_schema().input_names()
+
+feature_df = spark.table("credit_decisioning_features_labels").fillna(0)
+
+prediction_df = feature_df.withColumn("prediction", loaded_model(F.struct(*features)).cast("integer")) \
+ .withColumn("model_id", F.lit(1)).cache()
+
+display(prediction_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC In the scored data frame above, we have essentially created an end-to-end process to predict credit worthiness for any customer, regardless of whether the customer has an existing bank account. We have a binary prediction which captures this and incorporates all the intellience from Databricks AutoML and curated features from our feature store.
+
+# COMMAND ----------
+
+(prediction_df
+ .write
+ .format("delta")
+ .mode("overwrite")
+ .option("overwriteSchema",True)
+ .option("delta.enableChangeDataFeed", "true")
+ .saveAsTable("credit_decisioning_baseline_predictions")
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Deploying the Credit Scoring model for real-time serving
+# MAGIC
+# MAGIC
+# MAGIC Let's deploy our model behind a scalable API to evaluate credit-worthiness in real-time.
+# MAGIC
+# MAGIC Now that our model has been created with Databricks AutoML, we can easily flag it as Production Ready and turn on Databricks Model Serving.
+# MAGIC
+# MAGIC We'll be able to send HTTP Requests and get inference in real-time.
+# MAGIC
+# MAGIC Databricks Model Serving is fully serverless:
+# MAGIC
+# MAGIC * One-click deployment. Databricks will handle scalability, providing blazing fast inferences and startup time.
+# MAGIC * Scale down to zero as an option for best TCO (will shut down if the endpoint isn't used).
+# MAGIC * Built-in support for multiple models & version deployed.
+# MAGIC * A/B Testing and easy upgrade, routing traffic between each versions while measuring impact.
+# MAGIC * Built-in metrics & monitoring.
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve model info run by alias
+client = mlflow.tracking.MlflowClient()
+
+production_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="Production")
+
+# COMMAND ----------
+
+from mlflow.deployments import get_deploy_client
+
+mlflow.set_registry_uri("databricks-uc")
+deploy_client = get_deploy_client("databricks")
+
+endpoint = deploy_client.create_endpoint(
+ name=f"{endpoint_name}",
+ config={
+ "served_entities": [
+ {
+ "name": f"{model_name}-{production_model_info.version}",
+ "entity_name": f"{catalog}.{db}.{model_name}",
+ "entity_version": f"{production_model_info.version}",
+ "workload_size": "Small",
+ "scale_to_zero_enabled": True
+ }
+ ],
+ "traffic_config": {
+ "routes": [
+ {
+ "served_model_name": f"{model_name}-{production_model_info.version}",
+ "traffic_percentage": "100"
+ }
+ ]
+ },
+ "auto_capture_config":{
+ "catalog_name": f"{catalog}",
+ "schema_name": f"{db}",
+ "table_name_prefix": f"{endpoint_name}"
+ },
+ "environment_variables": {
+ "ENABLE_MLFLOW_TRACING": "True"
+ }
+ }
+)
+
+# COMMAND ----------
+
+from time import sleep
+
+# Wait for endpoint to be ready before running inference
+# This can take 10 minutes or so
+
+endpoint_udpate = endpoint
+is_not_ready = True
+is_not_updated = True
+
+print("Waiting for endpoint to be ready...")
+while(is_not_ready | is_not_updated):
+ sleep(10)
+ endpoint_udpate = deploy_client.get_endpoint(endpoint_name)
+ is_not_ready = endpoint_udpate["state"]["ready"] != "READY"
+ is_not_updated = endpoint_udpate["state"]["config_update"] != "NOT_UPDATING"
+
+print(f"Endpoint status: {endpoint_udpate['state']['ready']}; {endpoint_udpate['state']['config_update']}")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Our model endpoint was automatically created.
+# MAGIC
+# MAGIC Open the [endpoint UI](#mlflow/endpoints) to explore your endpoint and use the UI to send queries.
+# MAGIC
+# MAGIC *Note that the first deployment will build your model image and take a few minutes. It'll then stop & start instantly.*
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ### Testing the model serving endpoint
+# MAGIC
+# MAGIC Now that the model is deployed, let's test it with some queries and investigate the inferance table.
+
+# COMMAND ----------
+
+from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
+from mlflow.models.model import Model
+
+p = ModelsArtifactRepository(f"models:/{model_name}@production").download_artifacts("")
+dataset = {"dataframe_split": Model.load(p).load_input_example(p).to_dict(orient='split')}
+predictions = deploy_client.predict(endpoint=endpoint_name, inputs=dataset)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With model inference in place, the next critical step is [06.7-Model-Monitoring]($./06-Responsible-AI/06.7-Model-Monitoring). In this final stage, we will continuously track data drift and model performance degradation using Lakehouse Monitoring. By integrating real-time monitoring with inference, we can proactively manage model health and maintain responsible AI principles throughout the credit scoring lifecycle.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py
new file mode 100644
index 00000000..599bb8f4
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py
@@ -0,0 +1,383 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Model Monitoring
+# MAGIC
+# MAGIC In this notebook, we focus on **Lakehouse monitoring** to ensure the ongoing reliability, fairness, and performance of our credit scoring model. A critical aspect of **Responsible AI** is maintaining trust and effectiveness over time, which requires systematic tracking of model behavior, detecting data drift, and recalibrating models as necessary.
+# MAGIC
+# MAGIC ### Why Model Monitoring Matters
+# MAGIC Machine learning models are exposed to evolving real-world conditions, such as economic shifts and changes in customer behavior. If left unmonitored, models can degrade in accuracy, introduce unintended biases, or fail regulatory compliance. **Databricks’ Lakehouse architecture** provides a unified approach to monitoring both data and models, ensuring end-to-end traceability and governance.
+# MAGIC
+# MAGIC ### Key Components of Model Monitoring
+# MAGIC We will leverage Databricks’ built-in monitoring capabilities to:
+# MAGIC
+# MAGIC 1. **Detect Data Drift:** Continuously track statistical distributions of input features and predictions, identifying shifts that could impact model reliability.
+# MAGIC 2. **Monitor Model Performance Decay:** Compare real-world outcomes against model predictions to detect degrading performance.
+# MAGIC 3. **Ensure Fairness and Bias Control:** Check if fairness metrics remain within acceptable thresholds to prevent unintended discrimination.
+# MAGIC 4. **Trigger Recalibration Workflows:** Automate retraining and redeployment when model effectiveness declines, ensuring continuous improvement.
+# MAGIC 5. **Generate Alerts and Reports:** Notify stakeholders when significant changes occur, maintaining transparency and accountability.
+# MAGIC
+# MAGIC By embedding monitoring within the **Databricks Data Intelligence Platform**, we create a scalable and responsible approach to lifecycle management, aligning with regulatory requirements while ensuring that credit decisions remain fair, accurate, and explainable.
+# MAGIC
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Running batch inference
+# MAGIC
+# MAGIC Now that our model has been successfully trained and deployed to production within the MLFlow registry, we can seamlessly integrate it into various Data Engineering workflows.
+# MAGIC
+# MAGIC We can now easily load it calling the `Production` stage, and use it in any Data Engineering pipeline (a job running every night, in streaming or even within a Delta Live Table pipeline).
+
+# COMMAND ----------
+
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark,
+ model_uri=f"models:/{catalog}.{db}.{model_name}@production", result_type='double',
+ env_manager="virtualenv")
+
+# COMMAND ----------
+
+from pyspark.sql import functions as F
+
+features = loaded_model.metadata.get_input_schema().input_names()
+
+feature_df = spark.table("credit_decisioning_features_labels").fillna(0)
+
+prediction_df = feature_df.withColumn("prediction", loaded_model(F.struct(*features)).cast("integer")) \
+ .withColumn("model_id", F.lit(1)).cache()
+
+display(prediction_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC In the scored data frame above, we have essentially created an end-to-end process to predict credit worthiness for any customer, regardless of whether the customer has an existing bank account. We have a binary prediction which captures this and incorporates all the intellience from Databricks AutoML and curated features from our feature store.
+
+# COMMAND ----------
+
+(prediction_df
+ .write
+ .format("delta")
+ .mode("overwrite")
+ .option("overwriteSchema",True)
+ .option("delta.enableChangeDataFeed", "true")
+ .saveAsTable("credit_decisioning_baseline_predictions")
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Deploying the Credit Scoring model for real-time serving
+# MAGIC
+# MAGIC
+# MAGIC Let's deploy our model behind a scalable API to evaluate credit-worthiness in real-time.
+# MAGIC
+# MAGIC Now that our model has been created with Databricks AutoML, we can easily flag it as Production Ready and turn on Databricks Model Serving.
+# MAGIC
+# MAGIC We'll be able to send HTTP Requests and get inference in real-time.
+# MAGIC
+# MAGIC Databricks Model Serving is fully serverless:
+# MAGIC
+# MAGIC * One-click deployment. Databricks will handle scalability, providing blazing fast inferences and startup time.
+# MAGIC * Scale down to zero as an option for best TCO (will shut down if the endpoint isn't used).
+# MAGIC * Built-in support for multiple models & version deployed.
+# MAGIC * A/B Testing and easy upgrade, routing traffic between each versions while measuring impact.
+# MAGIC * Built-in metrics & monitoring.
+
+# COMMAND ----------
+
+import mlflow
+
+# Retrieve model info run by alias
+client = mlflow.tracking.MlflowClient()
+
+production_model_info = client.get_model_version_by_alias(name=f"{catalog}.{db}.{model_name}", alias="Production")
+
+# COMMAND ----------
+
+from mlflow.deployments import get_deploy_client
+
+mlflow.set_registry_uri("databricks-uc")
+deploy_client = get_deploy_client("databricks")
+
+endpoint = deploy_client.create_endpoint(
+ name=f"{endpoint_name}",
+ config={
+ "served_entities": [
+ {
+ "name": f"{model_name}-{production_model_info.version}",
+ "entity_name": f"{catalog}.{db}.{model_name}",
+ "entity_version": f"{production_model_info.version}",
+ "workload_size": "Small",
+ "scale_to_zero_enabled": True
+ }
+ ],
+ "traffic_config": {
+ "routes": [
+ {
+ "served_model_name": f"{model_name}-{production_model_info.version}",
+ "traffic_percentage": "100"
+ }
+ ]
+ },
+ "auto_capture_config":{
+ "catalog_name": f"{catalog}",
+ "schema_name": f"{db}",
+ "table_name_prefix": f"{endpoint_name}"
+ },
+ "environment_variables": {
+ "ENABLE_MLFLOW_TRACING": "True"
+ }
+ }
+)
+
+# COMMAND ----------
+
+from time import sleep
+
+# Wait for endpoint to be ready before running inference
+# This can take 10 minutes or so
+
+endpoint_udpate = endpoint
+is_not_ready = True
+is_not_updated = True
+
+print("Waiting for endpoint to be ready...")
+while(is_not_ready | is_not_updated):
+ sleep(10)
+ endpoint_udpate = deploy_client.get_endpoint(endpoint_name)
+ is_not_ready = endpoint_udpate["state"]["ready"] != "READY"
+ is_not_updated = endpoint_udpate["state"]["config_update"] != "NOT_UPDATING"
+
+print(f"Endpoint status: {endpoint_udpate['state']['ready']}; {endpoint_udpate['state']['config_update']}")
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Our model endpoint was automatically created.
+# MAGIC
+# MAGIC Open the [endpoint UI](#mlflow/endpoints) to explore your endpoint and use the UI to send queries.
+# MAGIC
+# MAGIC *Note that the first deployment will build your model image and take a few minutes. It'll then stop & start instantly.*
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ### Testing the model serving endpoint
+# MAGIC
+# MAGIC Now that the model is deployed, let's test it with some queries and investigate the inferance table.
+
+# COMMAND ----------
+
+from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
+from mlflow.models.model import Model
+
+p = ModelsArtifactRepository(f"models:/{model_name}@production").download_artifacts("")
+dataset = {"dataframe_split": Model.load(p).load_input_example(p).to_dict(orient='split')}
+predictions = deploy_client.predict(endpoint=endpoint_name, inputs=dataset)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Next Steps
+# MAGIC
+# MAGIC With model inference in place, the next critical step is [06.7-Model-Monitoring]($./06-Responsible-AI/06.7-Model-Monitoring). In this final stage, we will continuously track data drift and model performance degradation using Lakehouse Monitoring. By integrating real-time monitoring with inference, we can proactively manage model health and maintain responsible AI principles throughout the credit scoring lifecycle.
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py
new file mode 100644
index 00000000..599bb8f4
--- /dev/null
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/03-Data-Science-ML/03.7-Model-Monitoring-credit-decisioning.py
@@ -0,0 +1,383 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC
+# MAGIC # Model Monitoring
+# MAGIC
+# MAGIC In this notebook, we focus on **Lakehouse monitoring** to ensure the ongoing reliability, fairness, and performance of our credit scoring model. A critical aspect of **Responsible AI** is maintaining trust and effectiveness over time, which requires systematic tracking of model behavior, detecting data drift, and recalibrating models as necessary.
+# MAGIC
+# MAGIC ### Why Model Monitoring Matters
+# MAGIC Machine learning models are exposed to evolving real-world conditions, such as economic shifts and changes in customer behavior. If left unmonitored, models can degrade in accuracy, introduce unintended biases, or fail regulatory compliance. **Databricks’ Lakehouse architecture** provides a unified approach to monitoring both data and models, ensuring end-to-end traceability and governance.
+# MAGIC
+# MAGIC ### Key Components of Model Monitoring
+# MAGIC We will leverage Databricks’ built-in monitoring capabilities to:
+# MAGIC
+# MAGIC 1. **Detect Data Drift:** Continuously track statistical distributions of input features and predictions, identifying shifts that could impact model reliability.
+# MAGIC 2. **Monitor Model Performance Decay:** Compare real-world outcomes against model predictions to detect degrading performance.
+# MAGIC 3. **Ensure Fairness and Bias Control:** Check if fairness metrics remain within acceptable thresholds to prevent unintended discrimination.
+# MAGIC 4. **Trigger Recalibration Workflows:** Automate retraining and redeployment when model effectiveness declines, ensuring continuous improvement.
+# MAGIC 5. **Generate Alerts and Reports:** Notify stakeholders when significant changes occur, maintaining transparency and accountability.
+# MAGIC
+# MAGIC By embedding monitoring within the **Databricks Data Intelligence Platform**, we create a scalable and responsible approach to lifecycle management, aligning with regulatory requirements while ensuring that credit decisions remain fair, accurate, and explainable.
+# MAGIC
+# MAGIC
+# MAGIC  +
+# COMMAND ----------
+
+# DBTITLE 1,Install Lakehouse Monitoring client wheel
+# MAGIC %pip install "databricks-sdk>=0.28.0"
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Background
+# MAGIC The following are required to create an inference log monitor with [Lakehouse Monitoring](https://www.databricks.com/product/machine-learning/lakehouse-monitoring):
+# MAGIC - A Delta table in Unity Catalog that you own.
+# MAGIC - The data can be batch scored data or inference logs. The following columns are required:
+# MAGIC - `timestamp` (TimeStamp): Used for windowing and aggregation when calculating metrics
+# MAGIC - `model_id` (String): Model version/id used for each prediction.
+# MAGIC - `prediction` (String): Value predicted by the model.
+# MAGIC
+# MAGIC - The following column is optional:
+# MAGIC - `label` (String): Ground truth label.
+# MAGIC
+# MAGIC You can also provide an optional baseline table to track performance changes in the model and drifts in the statistical characteristics of features.
+# MAGIC - To track performance changes in the model, consider using the test or validation set.
+# MAGIC - To track drifts in feature distributions, consider using the training set or the associated feature tables.
+# MAGIC - The baseline table must use the same column names as the monitored table, and must also have a `model_version` column.
+# MAGIC
+# MAGIC Databricks recommends enabling Delta's Change-Data-Feed ([AWS](https://docs.databricks.com/delta/delta-change-data-feed.html#enable-change-data-feed)|[Azure](https://learn.microsoft.com/azure/databricks/delta/delta-change-data-feed#enable-change-data-feed)) table property for better metric computation performance for all monitored tables, including the baseline table. This notebook shows how to enable Change Data Feed when you create the Delta table.
+
+# COMMAND ----------
+
+TABLE_NAME = f"{catalog}.{db}.credit_decisioning_inferencelogs"
+BASELINE_TABLE = f"{catalog}.{db}.credit_decisioning_baseline_predictions"
+MODEL_NAME = f"{model_name}" # Name of (registered) model in mlflow registry
+TIMESTAMP_COL = "timestamp"
+MODEL_ID_COL = "model_id" # Name of column to use as model identifier (here we'll use the model_name+version)
+PREDICTION_COL = "prediction" # What to name predictions in the generated tables
+LABEL_COL = "defaulted" # Name of ground-truth labels column
+ID_COL = "cust_id"
+new_model_version = 1
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create a sample inference table
+# MAGIC
+# MAGIC Example pre-processing step
+# MAGIC * Extract ground-truth labels (in practice, labels might arrive later)
+# MAGIC * Split into two batches
+# MAGIC * Add `model_version` column and write to the table that we will attach a monitor to
+# MAGIC * Add ground-truth `label_col` column with empty/NaN values
+# MAGIC
+# MAGIC Set `mergeSchema` to `True` to enable appending dataframes without label column available
+
+# COMMAND ----------
+
+from datetime import timedelta, datetime
+import random
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=f"models:/{catalog}.{db}.{model_name}@production", result_type='double', env_manager="virtualenv")
+features = loaded_model.metadata.get_input_schema().input_names()
+
+# Simulate inferences for n days
+n_days = 10
+
+feature_df = spark.table("credit_decisioning_features").orderBy(F.rand()).limit(10)
+feature_df = feature_df.withColumn(TIMESTAMP_COL, F.lit(datetime.now().timestamp()).cast("timestamp"))
+
+for n in range(1, n_days):
+ temp_df = spark.table("credit_decisioning_features").orderBy(F.rand()).limit(random.randint(5, 20))
+ timestamp = (datetime.now() - timedelta(days = n)).timestamp()
+ temp_df = temp_df.withColumn(TIMESTAMP_COL, F.lit(timestamp).cast("timestamp"))
+ feature_df = feature_df.union(temp_df)
+
+feature_df = feature_df.fillna(0)
+
+# Introducing synthetic drift into few columns
+feature_df = feature_df.withColumn('total_deposits_amount', F.col('total_deposits_amount') + F.rand() * 100000) \
+ .withColumn('total_equity_amount', F.col('total_equity_amount') + F.rand() * 100000) \
+ .withColumn('total_UT', F.col('total_UT') + F.rand() * 100000) \
+ .withColumn('customer_revenue', F.col('customer_revenue') + F.rand() * 100000)
+
+pred_df = feature_df.withColumn(PREDICTION_COL, loaded_model(*features).cast("integer")) \
+ .withColumn(MODEL_ID_COL, F.lit(new_model_version))
+
+(pred_df
+ .withColumn(MODEL_ID_COL, F.lit(new_model_version))
+ .withColumn(LABEL_COL, F.lit(None).cast("integer"))
+ .withColumn("cust_id", col("cust_id").cast("bigint"))
+ .write.format("delta").mode("overwrite")
+ .option("mergeSchema",True)
+ .option("delta.enableChangeDataFeed", "true")
+ .saveAsTable(TABLE_NAME)
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Join ground-truth labels to inference table
+# MAGIC **Note: If ground-truth value can change for a given id through time, then consider also joining/merging on timestamp column**
+
+# COMMAND ----------
+
+# DBTITLE 1,Using MERGE INTO (Recommended)
+# Step 1: Create temporary view using synthetic labels
+df = spark.table(TABLE_NAME).select(ID_COL, PREDICTION_COL)
+df = df.withColumn("temp", F.rand())
+df = df.withColumn(LABEL_COL,
+ F.when(df["temp"] < 0.14, 1 - df[PREDICTION_COL]).otherwise(df[PREDICTION_COL]))
+df = df.drop("temp", PREDICTION_COL)
+ground_truth_df = df.withColumnRenamed(PREDICTION_COL, LABEL_COL)
+late_labels_view_name = f"credit_decisioning_late_labels"
+ground_truth_df.createOrReplaceTempView(late_labels_view_name)
+
+# Step 2: Merge into inference table
+merge_info = spark.sql(
+ f"""
+ MERGE INTO {TABLE_NAME} AS i
+ USING {late_labels_view_name} AS l
+ ON i.{ID_COL} == l.{ID_COL}
+ WHEN MATCHED THEN UPDATE SET i.{LABEL_COL} == l.{LABEL_COL}
+ """
+)
+display(merge_info)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Create a custom metric
+# MAGIC
+# MAGIC Customer metrics can be defined and will automatically be calculated by lakehouse monitoring. They often serve as a mean to capture some aspect of business logic or use a custom model quality score. See the documentation for more details about how to create custom metrics ([AWS](https://docs.databricks.com/lakehouse-monitoring/custom-metrics.html)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/custom-metrics)).
+# MAGIC
+# MAGIC In this example, we will calculate the business impact (the overdraft balance amount) of a bad model performance.
+
+# COMMAND ----------
+
+from pyspark.sql.types import DoubleType, StructField
+from databricks.sdk.service.catalog import MonitorMetric, MonitorMetricType
+
+CUSTOM_METRICS = [
+ MonitorMetric(
+ type=MonitorMetricType.CUSTOM_METRIC_TYPE_AGGREGATE,
+ name="avg_overdraft_balance_amt",
+ input_columns=[":table"],
+ definition="""avg(CASE
+ WHEN {{prediction_col}} != {{label_col}} AND {{label_col}} = 1 THEN overdraft_balance_amount
+ ELSE 0 END
+ )""",
+ output_data_type= StructField("output", DoubleType()).json()
+ )
+]
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create the monitor
+# MAGIC Use `InferenceLog` type analysis.
+# MAGIC
+# MAGIC **Make sure to drop any column that you don't want to track or which doesn't make sense from a business or use-case perspective**, otherwise create a VIEW with only columns of interest and monitor it.
+
+# COMMAND ----------
+
+from databricks.sdk import WorkspaceClient
+from databricks.sdk.service.catalog import MonitorInferenceLog, MonitorInferenceLogProblemType, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric
+
+w = WorkspaceClient()
+
+# COMMAND ----------
+
+# Delete any axisting monitor
+
+try:
+ w.quality_monitors.delete(table_name=TABLE_NAME)
+except:
+ print("Monitor doesn't exist.")
+
+# COMMAND ----------
+
+import os
+
+# ML problem type, either "classification" or "regression"
+PROBLEM_TYPE = MonitorInferenceLogProblemType.PROBLEM_TYPE_CLASSIFICATION
+
+# Window sizes to analyze data over
+GRANULARITIES = ["1 day"]
+
+# Directory to store generated dashboard
+ASSETS_DIR = f"{os.getcwd()}/monitoring"
+
+# Optional parameters
+SLICING_EXPRS = ["age<25", "age>60"] # Expressions to slice data with
+
+# COMMAND ----------
+
+# DBTITLE 1,Create Monitor
+print(f"Creating monitor for {TABLE_NAME}")
+
+info = w.quality_monitors.create(
+ table_name=TABLE_NAME,
+ inference_log=MonitorInferenceLog(
+ timestamp_col=TIMESTAMP_COL,
+ granularities=GRANULARITIES,
+ model_id_col=MODEL_ID_COL, # Model version number
+ prediction_col=PREDICTION_COL,
+ problem_type=PROBLEM_TYPE,
+ label_col=LABEL_COL # Optional
+ ),
+ baseline_table_name=BASELINE_TABLE,
+ slicing_exprs=SLICING_EXPRS,
+ output_schema_name=f"{catalog}.{db}",
+ custom_metrics=CUSTOM_METRICS,
+ assets_dir=ASSETS_DIR
+)
+
+# COMMAND ----------
+
+import time
+
+# Wait for monitor to be created
+while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
+ info = w.quality_monitors.get(table_name=TABLE_NAME)
+ time.sleep(10)
+
+assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
+
+# COMMAND ----------
+
+# A metric refresh will automatically be triggered on creation
+refreshes = w.quality_monitors.list_refreshes(table_name=TABLE_NAME).refreshes
+assert(len(refreshes) > 0)
+
+run_info = refreshes[0]
+while run_info.state in (MonitorRefreshInfoState.PENDING, MonitorRefreshInfoState.RUNNING):
+ run_info = w.quality_monitors.get_refresh(table_name=TABLE_NAME, refresh_id=run_info.refresh_id)
+ time.sleep(30)
+
+assert run_info.state == MonitorRefreshInfoState.SUCCESS, "Monitor refresh failed"
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC To view the dashboard, click **Dashboards** in the left nav bar.
+# MAGIC
+# MAGIC You can also navigate to the dashboard from the primary table in the Catalog Explorer UI. On the **Quality** tab, click the **View dashboard** button.
+# MAGIC
+# MAGIC For details, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-dashboard.html) | [Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-dashboard)).
+# MAGIC
+
+# COMMAND ----------
+
+w.quality_monitors.get(table_name=TABLE_NAME)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Inspect the metrics tables
+# MAGIC
+# MAGIC By default, the metrics tables are saved in the default database.
+# MAGIC
+# MAGIC The `create_monitor` call created two new tables: the profile metrics table and the drift metrics table.
+# MAGIC
+# MAGIC These two tables record the outputs of analysis jobs. The tables use the same name as the primary table to be monitored, with the suffixes `_profile_metrics` and `_drift_metrics`.
+
+# COMMAND ----------
+
+# MAGIC %md ### Orientation to the profile metrics table
+# MAGIC
+# MAGIC The profile metrics table has the suffix `_profile_metrics`. For a list of statistics that are shown in the table, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-output.html#profile-metrics-table)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-output#profile-metrics-table)).
+# MAGIC
+# MAGIC - For every column in the primary table, the profile table shows summary statistics for the baseline table and for the primary table. The column `log_type` shows `INPUT` to indicate statistics for the primary table, and `BASELINE` to indicate statistics for the baseline table. The column from the primary table is identified in the column `column_name`.
+# MAGIC - For `TimeSeries` type analysis, the `granularity` column shows the granularity corresponding to the row. For baseline table statistics, the `granularity` column shows `null`.
+# MAGIC - The table shows statistics for each value of each slice key in each time window, and for the table as whole. Statistics for the table as a whole are indicated by `slice_key` = `slice_value` = `null`.
+# MAGIC - In the primary table, the `window` column shows the time window corresponding to that row. For baseline table statistics, the `window` column shows `null`.
+# MAGIC - Some statistics are calculated based on the table as a whole, not on a single column. In the column `column_name`, these statistics are identified by `:table`.
+
+# COMMAND ----------
+
+# Display profile metrics table
+profile_table = f"{TABLE_NAME}_profile_metrics"
+profile_df = spark.sql(f"SELECT * FROM {profile_table}")
+display(profile_df)
+
+# COMMAND ----------
+
+# MAGIC %md ### Orientation to the drift metrics table
+# MAGIC
+# MAGIC The drift metrics table has the suffix `_drift_metrics`. For a list of statistics that are shown in the table, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-output.html#drift-metrics-table)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-output#drift-metrics-table)).
+# MAGIC
+# MAGIC - For every column in the primary table, the drift table shows a set of metrics that compare the current values in the table to the values at the time of the previous analysis run and to the baseline table. The column `drift_type` shows `BASELINE` to indicate drift relative to the baseline table, and `CONSECUTIVE` to indicate drift relative to a previous time window. As in the profile table, the column from the primary table is identified in the column `column_name`.
+# MAGIC - At this point, because this is the first run of this monitor, there is no previous window to compare to. So there are no rows where `drift_type` is `CONSECUTIVE`.
+# MAGIC - For `TimeSeries` type analysis, the `granularity` column shows the granularity corresponding to that row.
+# MAGIC - The table shows statistics for each value of each slice key in each time window, and for the table as whole. Statistics for the table as a whole are indicated by `slice_key` = `slice_value` = `null`.
+# MAGIC - The `window` column shows the the time window corresponding to that row. The `window_cmp` column shows the comparison window. If the comparison is to the baseline table, `window_cmp` is `null`.
+# MAGIC - Some statistics are calculated based on the table as a whole, not on a single column. In the column `column_name`, these statistics are identified by `:table`.
+
+# COMMAND ----------
+
+# Display the drift metrics table
+drift_table = f"{TABLE_NAME}_drift_metrics"
+display(spark.sql(f"SELECT * FROM {drift_table}"))
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Look at fairness and bias metrics
+# MAGIC Fairness and bias metrics are calculated for boolean type slices that were defined. The group defined by `slice_value=true` is considered the protected group ([AWS](https://docs.databricks.com/en/lakehouse-monitoring/fairness-bias.html)|[Azure](https://learn.microsoft.com/en-us/azure/databricks/lakehouse-monitoring/fairness-bias)).
+
+# COMMAND ----------
+
+fb_cols = ["window", "model_id", "slice_key", "slice_value", "predictive_parity", "predictive_equality", "equal_opportunity", "statistical_parity"]
+fb_metrics_df = profile_df.select(fb_cols).filter(f"column_name = ':table' AND slice_value = 'true'")
+display(fb_metrics_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create Alert for changes in model behavior
+# MAGIC
+# MAGIC Now that we have set up the components to constantly monitor the model's behavior, we can set up alerts to notify us of significant changes.
+# MAGIC
+# MAGIC Run the following cell and you will find a SQL Query and an Alert created for you in the `monitoring` folder.
+# MAGIC
+# MAGIC The query retrieves key model KPIs from the monitor's metric table, and the Alert will be triggered when the rules defined over the query's results are violated. Our exmample shows an Alert that is triggered when the model's F1 score falls below a threshold:
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+# DBTITLE 1,Install Lakehouse Monitoring client wheel
+# MAGIC %pip install "databricks-sdk>=0.28.0"
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/00-setup $reset_all_data=false
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Background
+# MAGIC The following are required to create an inference log monitor with [Lakehouse Monitoring](https://www.databricks.com/product/machine-learning/lakehouse-monitoring):
+# MAGIC - A Delta table in Unity Catalog that you own.
+# MAGIC - The data can be batch scored data or inference logs. The following columns are required:
+# MAGIC - `timestamp` (TimeStamp): Used for windowing and aggregation when calculating metrics
+# MAGIC - `model_id` (String): Model version/id used for each prediction.
+# MAGIC - `prediction` (String): Value predicted by the model.
+# MAGIC
+# MAGIC - The following column is optional:
+# MAGIC - `label` (String): Ground truth label.
+# MAGIC
+# MAGIC You can also provide an optional baseline table to track performance changes in the model and drifts in the statistical characteristics of features.
+# MAGIC - To track performance changes in the model, consider using the test or validation set.
+# MAGIC - To track drifts in feature distributions, consider using the training set or the associated feature tables.
+# MAGIC - The baseline table must use the same column names as the monitored table, and must also have a `model_version` column.
+# MAGIC
+# MAGIC Databricks recommends enabling Delta's Change-Data-Feed ([AWS](https://docs.databricks.com/delta/delta-change-data-feed.html#enable-change-data-feed)|[Azure](https://learn.microsoft.com/azure/databricks/delta/delta-change-data-feed#enable-change-data-feed)) table property for better metric computation performance for all monitored tables, including the baseline table. This notebook shows how to enable Change Data Feed when you create the Delta table.
+
+# COMMAND ----------
+
+TABLE_NAME = f"{catalog}.{db}.credit_decisioning_inferencelogs"
+BASELINE_TABLE = f"{catalog}.{db}.credit_decisioning_baseline_predictions"
+MODEL_NAME = f"{model_name}" # Name of (registered) model in mlflow registry
+TIMESTAMP_COL = "timestamp"
+MODEL_ID_COL = "model_id" # Name of column to use as model identifier (here we'll use the model_name+version)
+PREDICTION_COL = "prediction" # What to name predictions in the generated tables
+LABEL_COL = "defaulted" # Name of ground-truth labels column
+ID_COL = "cust_id"
+new_model_version = 1
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create a sample inference table
+# MAGIC
+# MAGIC Example pre-processing step
+# MAGIC * Extract ground-truth labels (in practice, labels might arrive later)
+# MAGIC * Split into two batches
+# MAGIC * Add `model_version` column and write to the table that we will attach a monitor to
+# MAGIC * Add ground-truth `label_col` column with empty/NaN values
+# MAGIC
+# MAGIC Set `mergeSchema` to `True` to enable appending dataframes without label column available
+
+# COMMAND ----------
+
+from datetime import timedelta, datetime
+import random
+import mlflow
+
+mlflow.set_registry_uri('databricks-uc')
+
+# Load model as a Spark UDF.
+loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=f"models:/{catalog}.{db}.{model_name}@production", result_type='double', env_manager="virtualenv")
+features = loaded_model.metadata.get_input_schema().input_names()
+
+# Simulate inferences for n days
+n_days = 10
+
+feature_df = spark.table("credit_decisioning_features").orderBy(F.rand()).limit(10)
+feature_df = feature_df.withColumn(TIMESTAMP_COL, F.lit(datetime.now().timestamp()).cast("timestamp"))
+
+for n in range(1, n_days):
+ temp_df = spark.table("credit_decisioning_features").orderBy(F.rand()).limit(random.randint(5, 20))
+ timestamp = (datetime.now() - timedelta(days = n)).timestamp()
+ temp_df = temp_df.withColumn(TIMESTAMP_COL, F.lit(timestamp).cast("timestamp"))
+ feature_df = feature_df.union(temp_df)
+
+feature_df = feature_df.fillna(0)
+
+# Introducing synthetic drift into few columns
+feature_df = feature_df.withColumn('total_deposits_amount', F.col('total_deposits_amount') + F.rand() * 100000) \
+ .withColumn('total_equity_amount', F.col('total_equity_amount') + F.rand() * 100000) \
+ .withColumn('total_UT', F.col('total_UT') + F.rand() * 100000) \
+ .withColumn('customer_revenue', F.col('customer_revenue') + F.rand() * 100000)
+
+pred_df = feature_df.withColumn(PREDICTION_COL, loaded_model(*features).cast("integer")) \
+ .withColumn(MODEL_ID_COL, F.lit(new_model_version))
+
+(pred_df
+ .withColumn(MODEL_ID_COL, F.lit(new_model_version))
+ .withColumn(LABEL_COL, F.lit(None).cast("integer"))
+ .withColumn("cust_id", col("cust_id").cast("bigint"))
+ .write.format("delta").mode("overwrite")
+ .option("mergeSchema",True)
+ .option("delta.enableChangeDataFeed", "true")
+ .saveAsTable(TABLE_NAME)
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Join ground-truth labels to inference table
+# MAGIC **Note: If ground-truth value can change for a given id through time, then consider also joining/merging on timestamp column**
+
+# COMMAND ----------
+
+# DBTITLE 1,Using MERGE INTO (Recommended)
+# Step 1: Create temporary view using synthetic labels
+df = spark.table(TABLE_NAME).select(ID_COL, PREDICTION_COL)
+df = df.withColumn("temp", F.rand())
+df = df.withColumn(LABEL_COL,
+ F.when(df["temp"] < 0.14, 1 - df[PREDICTION_COL]).otherwise(df[PREDICTION_COL]))
+df = df.drop("temp", PREDICTION_COL)
+ground_truth_df = df.withColumnRenamed(PREDICTION_COL, LABEL_COL)
+late_labels_view_name = f"credit_decisioning_late_labels"
+ground_truth_df.createOrReplaceTempView(late_labels_view_name)
+
+# Step 2: Merge into inference table
+merge_info = spark.sql(
+ f"""
+ MERGE INTO {TABLE_NAME} AS i
+ USING {late_labels_view_name} AS l
+ ON i.{ID_COL} == l.{ID_COL}
+ WHEN MATCHED THEN UPDATE SET i.{LABEL_COL} == l.{LABEL_COL}
+ """
+)
+display(merge_info)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Create a custom metric
+# MAGIC
+# MAGIC Customer metrics can be defined and will automatically be calculated by lakehouse monitoring. They often serve as a mean to capture some aspect of business logic or use a custom model quality score. See the documentation for more details about how to create custom metrics ([AWS](https://docs.databricks.com/lakehouse-monitoring/custom-metrics.html)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/custom-metrics)).
+# MAGIC
+# MAGIC In this example, we will calculate the business impact (the overdraft balance amount) of a bad model performance.
+
+# COMMAND ----------
+
+from pyspark.sql.types import DoubleType, StructField
+from databricks.sdk.service.catalog import MonitorMetric, MonitorMetricType
+
+CUSTOM_METRICS = [
+ MonitorMetric(
+ type=MonitorMetricType.CUSTOM_METRIC_TYPE_AGGREGATE,
+ name="avg_overdraft_balance_amt",
+ input_columns=[":table"],
+ definition="""avg(CASE
+ WHEN {{prediction_col}} != {{label_col}} AND {{label_col}} = 1 THEN overdraft_balance_amount
+ ELSE 0 END
+ )""",
+ output_data_type= StructField("output", DoubleType()).json()
+ )
+]
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create the monitor
+# MAGIC Use `InferenceLog` type analysis.
+# MAGIC
+# MAGIC **Make sure to drop any column that you don't want to track or which doesn't make sense from a business or use-case perspective**, otherwise create a VIEW with only columns of interest and monitor it.
+
+# COMMAND ----------
+
+from databricks.sdk import WorkspaceClient
+from databricks.sdk.service.catalog import MonitorInferenceLog, MonitorInferenceLogProblemType, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric
+
+w = WorkspaceClient()
+
+# COMMAND ----------
+
+# Delete any axisting monitor
+
+try:
+ w.quality_monitors.delete(table_name=TABLE_NAME)
+except:
+ print("Monitor doesn't exist.")
+
+# COMMAND ----------
+
+import os
+
+# ML problem type, either "classification" or "regression"
+PROBLEM_TYPE = MonitorInferenceLogProblemType.PROBLEM_TYPE_CLASSIFICATION
+
+# Window sizes to analyze data over
+GRANULARITIES = ["1 day"]
+
+# Directory to store generated dashboard
+ASSETS_DIR = f"{os.getcwd()}/monitoring"
+
+# Optional parameters
+SLICING_EXPRS = ["age<25", "age>60"] # Expressions to slice data with
+
+# COMMAND ----------
+
+# DBTITLE 1,Create Monitor
+print(f"Creating monitor for {TABLE_NAME}")
+
+info = w.quality_monitors.create(
+ table_name=TABLE_NAME,
+ inference_log=MonitorInferenceLog(
+ timestamp_col=TIMESTAMP_COL,
+ granularities=GRANULARITIES,
+ model_id_col=MODEL_ID_COL, # Model version number
+ prediction_col=PREDICTION_COL,
+ problem_type=PROBLEM_TYPE,
+ label_col=LABEL_COL # Optional
+ ),
+ baseline_table_name=BASELINE_TABLE,
+ slicing_exprs=SLICING_EXPRS,
+ output_schema_name=f"{catalog}.{db}",
+ custom_metrics=CUSTOM_METRICS,
+ assets_dir=ASSETS_DIR
+)
+
+# COMMAND ----------
+
+import time
+
+# Wait for monitor to be created
+while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
+ info = w.quality_monitors.get(table_name=TABLE_NAME)
+ time.sleep(10)
+
+assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
+
+# COMMAND ----------
+
+# A metric refresh will automatically be triggered on creation
+refreshes = w.quality_monitors.list_refreshes(table_name=TABLE_NAME).refreshes
+assert(len(refreshes) > 0)
+
+run_info = refreshes[0]
+while run_info.state in (MonitorRefreshInfoState.PENDING, MonitorRefreshInfoState.RUNNING):
+ run_info = w.quality_monitors.get_refresh(table_name=TABLE_NAME, refresh_id=run_info.refresh_id)
+ time.sleep(30)
+
+assert run_info.state == MonitorRefreshInfoState.SUCCESS, "Monitor refresh failed"
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC To view the dashboard, click **Dashboards** in the left nav bar.
+# MAGIC
+# MAGIC You can also navigate to the dashboard from the primary table in the Catalog Explorer UI. On the **Quality** tab, click the **View dashboard** button.
+# MAGIC
+# MAGIC For details, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-dashboard.html) | [Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-dashboard)).
+# MAGIC
+
+# COMMAND ----------
+
+w.quality_monitors.get(table_name=TABLE_NAME)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Inspect the metrics tables
+# MAGIC
+# MAGIC By default, the metrics tables are saved in the default database.
+# MAGIC
+# MAGIC The `create_monitor` call created two new tables: the profile metrics table and the drift metrics table.
+# MAGIC
+# MAGIC These two tables record the outputs of analysis jobs. The tables use the same name as the primary table to be monitored, with the suffixes `_profile_metrics` and `_drift_metrics`.
+
+# COMMAND ----------
+
+# MAGIC %md ### Orientation to the profile metrics table
+# MAGIC
+# MAGIC The profile metrics table has the suffix `_profile_metrics`. For a list of statistics that are shown in the table, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-output.html#profile-metrics-table)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-output#profile-metrics-table)).
+# MAGIC
+# MAGIC - For every column in the primary table, the profile table shows summary statistics for the baseline table and for the primary table. The column `log_type` shows `INPUT` to indicate statistics for the primary table, and `BASELINE` to indicate statistics for the baseline table. The column from the primary table is identified in the column `column_name`.
+# MAGIC - For `TimeSeries` type analysis, the `granularity` column shows the granularity corresponding to the row. For baseline table statistics, the `granularity` column shows `null`.
+# MAGIC - The table shows statistics for each value of each slice key in each time window, and for the table as whole. Statistics for the table as a whole are indicated by `slice_key` = `slice_value` = `null`.
+# MAGIC - In the primary table, the `window` column shows the time window corresponding to that row. For baseline table statistics, the `window` column shows `null`.
+# MAGIC - Some statistics are calculated based on the table as a whole, not on a single column. In the column `column_name`, these statistics are identified by `:table`.
+
+# COMMAND ----------
+
+# Display profile metrics table
+profile_table = f"{TABLE_NAME}_profile_metrics"
+profile_df = spark.sql(f"SELECT * FROM {profile_table}")
+display(profile_df)
+
+# COMMAND ----------
+
+# MAGIC %md ### Orientation to the drift metrics table
+# MAGIC
+# MAGIC The drift metrics table has the suffix `_drift_metrics`. For a list of statistics that are shown in the table, see the documentation ([AWS](https://docs.databricks.com/lakehouse-monitoring/monitor-output.html#drift-metrics-table)|[Azure](https://learn.microsoft.com/azure/databricks/lakehouse-monitoring/monitor-output#drift-metrics-table)).
+# MAGIC
+# MAGIC - For every column in the primary table, the drift table shows a set of metrics that compare the current values in the table to the values at the time of the previous analysis run and to the baseline table. The column `drift_type` shows `BASELINE` to indicate drift relative to the baseline table, and `CONSECUTIVE` to indicate drift relative to a previous time window. As in the profile table, the column from the primary table is identified in the column `column_name`.
+# MAGIC - At this point, because this is the first run of this monitor, there is no previous window to compare to. So there are no rows where `drift_type` is `CONSECUTIVE`.
+# MAGIC - For `TimeSeries` type analysis, the `granularity` column shows the granularity corresponding to that row.
+# MAGIC - The table shows statistics for each value of each slice key in each time window, and for the table as whole. Statistics for the table as a whole are indicated by `slice_key` = `slice_value` = `null`.
+# MAGIC - The `window` column shows the the time window corresponding to that row. The `window_cmp` column shows the comparison window. If the comparison is to the baseline table, `window_cmp` is `null`.
+# MAGIC - Some statistics are calculated based on the table as a whole, not on a single column. In the column `column_name`, these statistics are identified by `:table`.
+
+# COMMAND ----------
+
+# Display the drift metrics table
+drift_table = f"{TABLE_NAME}_drift_metrics"
+display(spark.sql(f"SELECT * FROM {drift_table}"))
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Look at fairness and bias metrics
+# MAGIC Fairness and bias metrics are calculated for boolean type slices that were defined. The group defined by `slice_value=true` is considered the protected group ([AWS](https://docs.databricks.com/en/lakehouse-monitoring/fairness-bias.html)|[Azure](https://learn.microsoft.com/en-us/azure/databricks/lakehouse-monitoring/fairness-bias)).
+
+# COMMAND ----------
+
+fb_cols = ["window", "model_id", "slice_key", "slice_value", "predictive_parity", "predictive_equality", "equal_opportunity", "statistical_parity"]
+fb_metrics_df = profile_df.select(fb_cols).filter(f"column_name = ':table' AND slice_value = 'true'")
+display(fb_metrics_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Create Alert for changes in model behavior
+# MAGIC
+# MAGIC Now that we have set up the components to constantly monitor the model's behavior, we can set up alerts to notify us of significant changes.
+# MAGIC
+# MAGIC Run the following cell and you will find a SQL Query and an Alert created for you in the `monitoring` folder.
+# MAGIC
+# MAGIC The query retrieves key model KPIs from the monitor's metric table, and the Alert will be triggered when the rules defined over the query's results are violated. Our exmample shows an Alert that is triggered when the model's F1 score falls below a threshold:
+# MAGIC
+# MAGIC  +# MAGIC
+# MAGIC Check them out in the `monitoring` folder.
+# MAGIC - Open the Alert `rai_credit_decisioning_accuracy_alert` to inspect its definition
+# MAGIC - Open the query `rai_credit_decisioning_performance_last_window` and run it to inspect its results
+# MAGIC
+# MAGIC You can create your own queries and alerts using the UI.
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/02-create-monitoring-query-and-alert
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Conclusion
+# MAGIC
+# MAGIC With this **Model Monitoring** notebook, we complete our end-to-end journey of building a **Responsible Credit Scoring Model** on the Databricks Data Intelligence Platform. Our approach ensures that the credit decisioning process is:
+# MAGIC
+# MAGIC - **Transparent:** Through explainability and bias monitoring at every stage.
+# MAGIC - **Effective:** By continuously evaluating model performance and recalibrating as needed.
+# MAGIC - **Reliable:** Through proactive drift detection, compliance validation, and automated retraining.
+# MAGIC
+# MAGIC By leveraging **Databricks Data Intelligence Platform**, we demonstrate how Responsible AI is more than just a compliance requirement—it is a fundamental pillar for building **trustworthy and value-driven machine learning solutions**. This monitoring framework ensures that our model remains **fair, accountable, and high-performing**, delivering long-term value to both the bank and its customers.
+# MAGIC
+# MAGIC With this, we conclude our **Responsible AI demo**. Thank you for exploring this journey with us!
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
similarity index 69%
rename from demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py
rename to demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
index a2af3b44..1f24f440 100644
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
@@ -1,6 +1,11 @@
# Databricks notebook source
+# MAGIC %md
+# MAGIC
+
+# COMMAND ----------
+
# MAGIC %md-sandbox
-# MAGIC # Data Intelligence Platform for Financial Services - Serving the Underbanked population with the Databricks Lakehouse
+# MAGIC # Data Intelligence Platform for Financial Services - Serving the Underbanked population
# MAGIC
+# MAGIC
+# MAGIC Check them out in the `monitoring` folder.
+# MAGIC - Open the Alert `rai_credit_decisioning_accuracy_alert` to inspect its definition
+# MAGIC - Open the query `rai_credit_decisioning_performance_last_window` and run it to inspect its results
+# MAGIC
+# MAGIC You can create your own queries and alerts using the UI.
+
+# COMMAND ----------
+
+# MAGIC %run ../_resources/02-create-monitoring-query-and-alert
+
+# COMMAND ----------
+
+# MAGIC %md-sandbox
+# MAGIC
+# MAGIC ## Conclusion
+# MAGIC
+# MAGIC With this **Model Monitoring** notebook, we complete our end-to-end journey of building a **Responsible Credit Scoring Model** on the Databricks Data Intelligence Platform. Our approach ensures that the credit decisioning process is:
+# MAGIC
+# MAGIC - **Transparent:** Through explainability and bias monitoring at every stage.
+# MAGIC - **Effective:** By continuously evaluating model performance and recalibrating as needed.
+# MAGIC - **Reliable:** Through proactive drift detection, compliance validation, and automated retraining.
+# MAGIC
+# MAGIC By leveraging **Databricks Data Intelligence Platform**, we demonstrate how Responsible AI is more than just a compliance requirement—it is a fundamental pillar for building **trustworthy and value-driven machine learning solutions**. This monitoring framework ensures that our model remains **fair, accountable, and high-performing**, delivering long-term value to both the bank and its customers.
+# MAGIC
+# MAGIC With this, we conclude our **Responsible AI demo**. Thank you for exploring this journey with us!
diff --git a/demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py b/demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
similarity index 69%
rename from demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py
rename to demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
index a2af3b44..1f24f440 100644
--- a/demo-FSI/lakehouse-fsi-credit-decisioning/00-Credit-Decisioning.py
+++ b/demo-FSI/lakehouse-fsi-credit-decisioning/Data-Intelligence-Platform-Demo.py
@@ -1,6 +1,11 @@
# Databricks notebook source
+# MAGIC %md
+# MAGIC
+
+# COMMAND ----------
+
# MAGIC %md-sandbox
-# MAGIC # Data Intelligence Platform for Financial Services - Serving the Underbanked population with the Databricks Lakehouse
+# MAGIC # Data Intelligence Platform for Financial Services - Serving the Underbanked population
# MAGIC  # MAGIC
@@ -22,15 +27,6 @@
# COMMAND ----------
-# MAGIC %md
-# MAGIC
-# MAGIC # Raising Interest Rates - an opportunity or a threat?
-# MAGIC
-# MAGIC The current raising interest rates can be both a great opportunity for retail banks and other FS organizations to increase their revenues from their credit instruments (such as loans, mortgages, and credit cards) but also a risk for larger losses as customers might end up unable to repay credits with higher rates. In the current market conditions, FS companies need better credit scoring and decisioning models and approaches. Such models, however, are very difficult to achieve as financial information might be insufficient or siloed.
# MAGIC
@@ -22,15 +27,6 @@
# COMMAND ----------
-# MAGIC %md
-# MAGIC
-# MAGIC # Raising Interest Rates - an opportunity or a threat?
-# MAGIC
-# MAGIC The current raising interest rates can be both a great opportunity for retail banks and other FS organizations to increase their revenues from their credit instruments (such as loans, mortgages, and credit cards) but also a risk for larger losses as customers might end up unable to repay credits with higher rates. In the current market conditions, FS companies need better credit scoring and decisioning models and approaches. Such models, however, are very difficult to achieve as financial information might be insufficient or siloed. 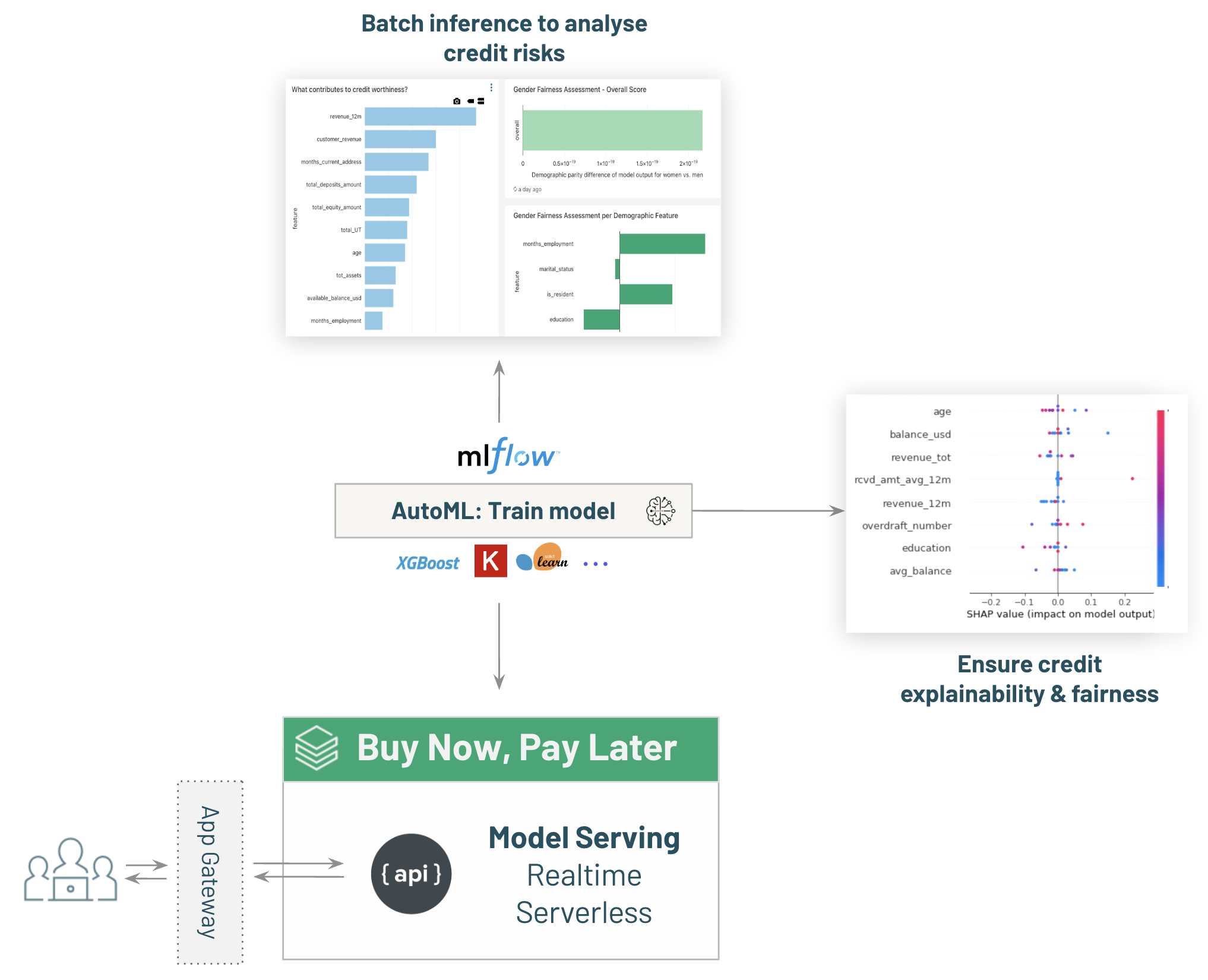 -# MAGIC
-# MAGIC To do that, we'll leverage the data previously ingested, analyze, and save the features set within Databricks feature store.
-# MAGIC
-# MAGIC Databricks AutoML will then accelerate our ML journey by creating state of the art Notebooks that we'll use to deploy our model in production within MLFlow Model registry.
-# MAGIC
-# MAGIC
-# MAGIC Once our is model ready, we'll leverage it to:
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC To do that, we'll leverage the data previously ingested, analyze, and save the features set within Databricks feature store.
-# MAGIC
-# MAGIC Databricks AutoML will then accelerate our ML journey by creating state of the art Notebooks that we'll use to deploy our model in production within MLFlow Model registry.
-# MAGIC
-# MAGIC
-# MAGIC Once our is model ready, we'll leverage it to:
-# MAGIC
-# MAGIC 