You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+3-3Lines changed: 3 additions & 3 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -10,18 +10,18 @@ There are two broad categories of ANN index:
10
10
11
11
Graph-based indexes tend to be simpler to implement and faster, but more importantly they can be constructed and updated incrementally. This makes them a much better fit for a general-purpose index than partitioning approaches that only work on static datasets that are completely specified up front. That is why all the major commercial vector indexes use graph approaches.
12
12
13
-
JVector is a graph index that takes a hybrid merging the the DiskANN and HNSW family trees.
13
+
JVector is a graph index that merges the DiskANN and HNSW family trees.
14
14
JVector borrows the hierarchical structure from HNSW, and uses Vamana (the algorithm behind DiskANN) within each layer.
15
15
16
16
17
17
## JVector Architecture
18
18
19
-
JVector is a graph-based index that builds on the HNSW anD DiskANN designs with composable extensions.
19
+
JVector is a graph-based index that builds on the HNSW and DiskANN designs with composable extensions.
20
20
21
21
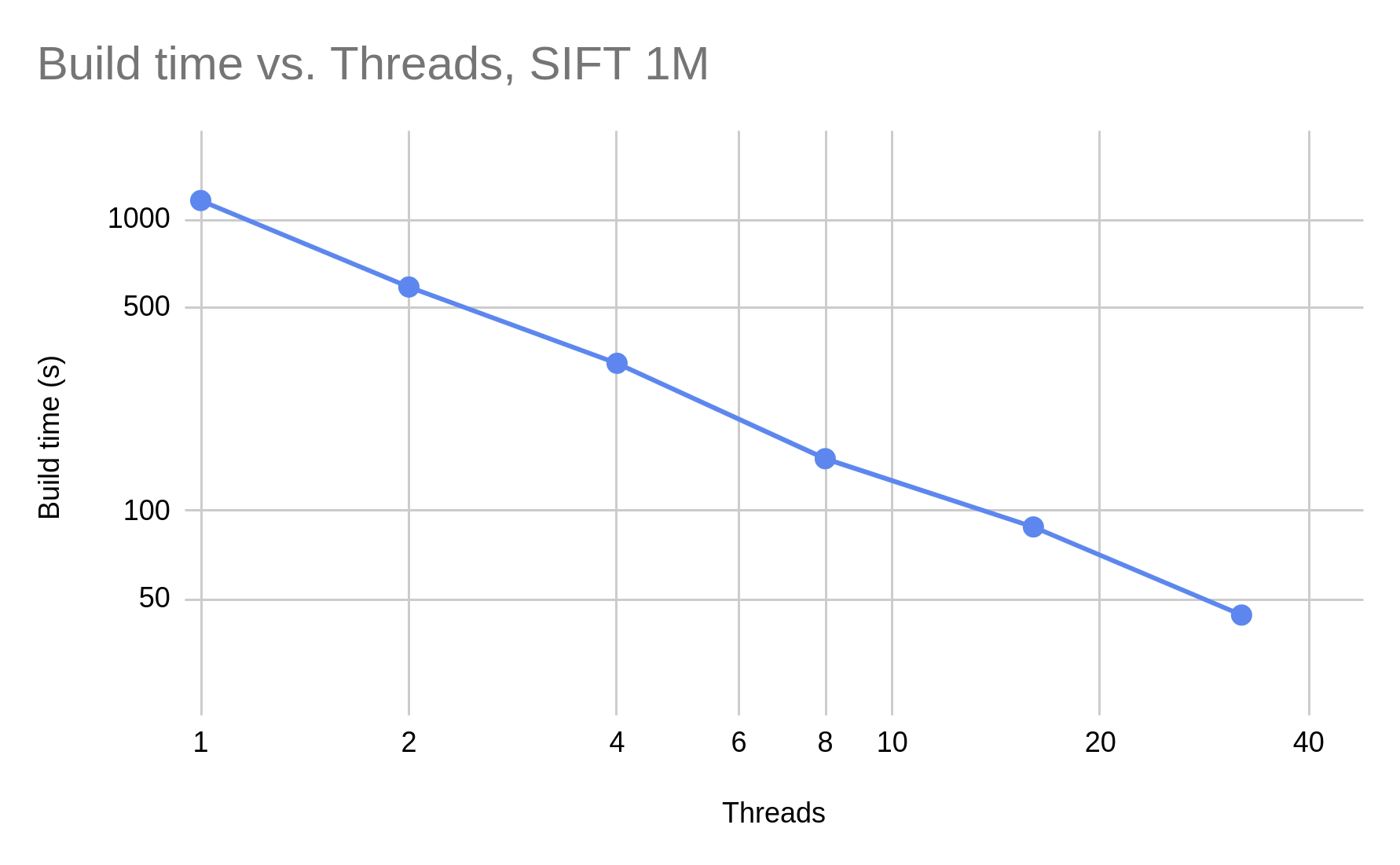
JVector implements a multi-layer graph with nonblocking concurrency control, allowing construction to scale linearly with the number of cores:
22
22
23
23
24
-
The upper layers of the hierarchy are represnted by an in-memory adjacency list per node. This allows for quick navigation with no IOs.
24
+
The upper layers of the hierarchy are represented by an in-memory adjacency list per node. This allows for quick navigation with no IOs.
25
25
The bottom layer of the graph is represented by an on-disk adjacency list per node. JVector uses additional data stored inline to support two-pass searches, with the first pass powered by lossily compressed representations of the vectors kept in memory, and the second by a more accurate representation read from disk. The first pass can be performed with
26
26
* Product quantization (PQ), optionally with [anisotropic weighting](https://arxiv.org/abs/1908.10396)
0 commit comments