Replies: 1 comment
-
|
Theoretically the same setting (including the random seed) and the same data should lead to the same model. In practice, the truncation error accumulates during training and makes the model different. Although all the models preform well in the regime covered by the training data, their behaviors are different in the "extrapolation regime". I would guess the light blue case in your figures is not covered by the training data. Notice that we cannot expect accuracy in the extrapolation regime, I would recommend adding the light blue case to the training dataset. Best, |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
We are encountering a problem where we are getting different results after applying the trained models to calculate the total energy of certain structures, even though the same settings and data are used for training the models. We think that the statistics change the order of trained structures every time, although we keep the seed fixed. Therefore, we cannot reproduce our model and get different results every time. To clarify, this means that exactly the same training was started multiple times, but the results are not the same, which makes it impossible to evaluate the influence of changes made to the settings and the dataset, because the „statistical“ deviation of the model due to the training cannot be excluded. Have you encountered a similar problem? We are currently using seed = 1 in the input file.
Same settings + Data, Model 1
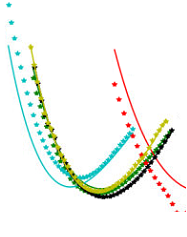
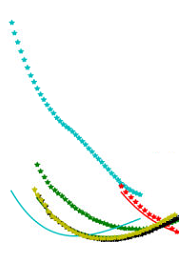
Same settings + Data, Model 2
Beta Was this translation helpful? Give feedback.
All reactions