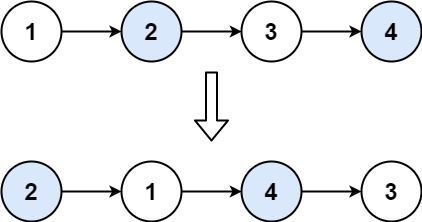
Input: head = [1,2,3,4]
+ +Output: [2,1,4,3]
+ +Explanation:
+ +
Example 1:
-
--Input: head = [1,2,3,4] -Output: [2,1,4,3] -+ +
Input: head = [1,2,3,4]
+ +Output: [2,1,4,3]
+ +Explanation:
+ +
Example 2:
--Input: head = [] -Output: [] -+
Input: head = []
+ +Output: []
+Example 3:
--Input: head = [1] -Output: [1] -+
Input: head = [1]
+ +Output: [1]
+Example 4:
+ +Input: head = [1,2,3]
+ +Output: [2,1,3]
+
Constraints:
diff --git a/solution/0000-0099/0049.Group Anagrams/README_EN.md b/solution/0000-0099/0049.Group Anagrams/README_EN.md index acfbcd0b85a09..5bb59726810d8 100644 --- a/solution/0000-0099/0049.Group Anagrams/README_EN.md +++ b/solution/0000-0099/0049.Group Anagrams/README_EN.md @@ -19,21 +19,41 @@ tags: -Given an array of strings strs, group the anagrams together. You can return the answer in any order.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
+Given an array of strings strs, group the anagrams together. You can return the answer in any order.
Example 1:
-Input: strs = ["eat","tea","tan","ate","nat","bat"] -Output: [["bat"],["nat","tan"],["ate","eat","tea"]] -
Example 2:
-Input: strs = [""] -Output: [[""]] -
Example 3:
-Input: strs = ["a"] -Output: [["a"]] -+ +
Input: strs = ["eat","tea","tan","ate","nat","bat"]
+ +Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
+ +Explanation:
+ +"bat"."nat" and "tan" are anagrams as they can be rearranged to form each other."ate", "eat", and "tea" are anagrams as they can be rearranged to form each other.Example 2:
+ +Input: strs = [""]
+ +Output: [[""]]
+Example 3:
+ +Input: strs = ["a"]
+ +Output: [["a"]]
+
Constraints:
diff --git a/solution/0000-0099/0071.Simplify Path/README.md b/solution/0000-0099/0071.Simplify Path/README.md index 6551d3fe9d4d2..7a812678dee08 100644 --- a/solution/0000-0099/0071.Simplify Path/README.md +++ b/solution/0000-0099/0071.Simplify Path/README.md @@ -17,11 +17,18 @@ tags: -给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为 更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
在 Unix 风格的文件系统中规则如下:
-请注意,返回的 规范路径 必须遵循下述格式:
+'.' 表示当前目录本身。'..' 表示将目录切换到上一级(指向父目录)。'//' 或 '///')都被视为单个斜杠 '/'。'...' 或 '....')均被视为有效的文件/目录名称。返回的 简化路径 必须遵循下述格式:
'/' 开头。示例 1:
输入:path = "/home/"
+输入:path = "/home/"
输出:"/home"
解释:
-应删除尾部斜杠。
+应删除尾随斜杠。
示例 2:
输入:path = "/home//foo/"
+输入:path = "/home//foo/"
-输出:"/home/foo"
+输出:"/home/foo"
解释:
@@ -61,37 +68,37 @@ tags:示例 3:
输入:path = "/home/user/Documents/../Pictures"
+输入:path = "/home/user/Documents/../Pictures"
-输出:"/home/user/Pictures"
+输出:"/home/user/Pictures"
解释:
-两个点 ".." 表示上一级目录。
两个点 ".." 表示上一级目录(父目录)。
示例 4:
输入:path = "/../"
+输入:path = "/../"
-输出:"/"
+输出:"/"
解释:
-不可能从根目录上升级一级。
+不可能从根目录上升一级目录。
示例 5:
输入:path = "/.../a/../b/c/../d/./"
+输入:path = "/.../a/../b/c/../d/./"
-输出:"/.../b/d"
+输出:"/.../b/d"
解释:
-"..." 是此问题中目录的有效名称。
"..." 在这个问题中是一个合法的目录名。
diff --git a/solution/0000-0099/0071.Simplify Path/README_EN.md b/solution/0000-0099/0071.Simplify Path/README_EN.md index eddbbd32ac0b3..fb4562ef05b13 100644 --- a/solution/0000-0099/0071.Simplify Path/README_EN.md +++ b/solution/0000-0099/0071.Simplify Path/README_EN.md @@ -17,20 +17,27 @@ tags: -
Given an absolute path for a Unix-style file system, which begins with a slash '/', transform this path into its simplified canonical path.
You are given an absolute path for a Unix-style file system, which always begins with a slash '/'. Your task is to transform this absolute path into its simplified canonical path.
In Unix-style file system context, a single period '.' signifies the current directory, a double period ".." denotes moving up one directory level, and multiple slashes such as "//" are interpreted as a single slash. In this problem, treat sequences of periods not covered by the previous rules (like "...") as valid names for files or directories.
The rules of a Unix-style file system are as follows:
-The simplified canonical path should adhere to the following rules:
+'.' represents the current directory.'..' represents the previous/parent directory.'//' and '///' are treated as a single slash '/'.'...' and '....' are valid directory or file names.The simplified canonical path should follow these rules:
'/'.'/'.'/', unless it's the root directory.'/'.'/'.'/', unless it is the root directory.'.' and '..') used to denote current or parent directories.Return the new path.
+Return the simplified canonical path.
Example 1:
@@ -66,7 +73,7 @@ tags:Explanation:
-A double period ".." refers to the directory up a level.
A double period ".." refers to the directory up a level (the parent directory).
Example 4:
diff --git a/solution/0200-0299/0217.Contains Duplicate/README.md b/solution/0200-0299/0217.Contains Duplicate/README.md index 34c6038c0e33f..c5e921dfdbc03 100644 --- a/solution/0200-0299/0217.Contains Duplicate/README.md +++ b/solution/0200-0299/0217.Contains Duplicate/README.md @@ -22,23 +22,37 @@ tags:-
示例 1:
+示例 1:
--输入:nums = [1,2,3,1] -输出:true+
输入:nums = [1,2,3,1]
-示例 2:
+输出:true
--输入:nums = [1,2,3,4] -输出:false+
解释:
-示例 3:
+元素 1 在下标 0 和 3 出现。
+-输入:nums = [1,1,1,3,3,4,3,2,4,2] -输出:true+
示例 2:
+ +输入:nums = [1,2,3,4]
+ +输出:false
+ +解释:
+ +所有元素都不同。
+示例 3:
+ +输入:nums = [1,1,1,3,3,4,3,2,4,2]
+ +输出:true
+diff --git a/solution/0200-0299/0217.Contains Duplicate/README_EN.md b/solution/0200-0299/0217.Contains Duplicate/README_EN.md index 96e6ab2776a6e..dc8c7fe14f89c 100644 --- a/solution/0200-0299/0217.Contains Duplicate/README_EN.md +++ b/solution/0200-0299/0217.Contains Duplicate/README_EN.md @@ -22,15 +22,37 @@ tags:
Example 1:
-Input: nums = [1,2,3,1] -Output: true -
Example 2:
-Input: nums = [1,2,3,4] -Output: false -
Example 3:
-Input: nums = [1,1,1,3,3,4,3,2,4,2] -Output: true -+ +
Input: nums = [1,2,3,1]
+ +Output: true
+ +Explanation:
+ +The element 1 occurs at the indices 0 and 3.
+Example 2:
+ +Input: nums = [1,2,3,4]
+ +Output: false
+ +Explanation:
+ +All elements are distinct.
+Example 3:
+ +Input: nums = [1,1,1,3,3,4,3,2,4,2]
+ +Output: true
+
Constraints:
diff --git a/solution/0200-0299/0242.Valid Anagram/README.md b/solution/0200-0299/0242.Valid Anagram/README.md index ffd047fc8c537..7c6263ac96aa8 100644 --- a/solution/0200-0299/0242.Valid Anagram/README.md +++ b/solution/0200-0299/0242.Valid Anagram/README.md @@ -18,23 +18,21 @@ tags: -给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
字母异位词 是通过重新排列不同单词或短语的字母而形成的单词或短语,通常只使用所有原始字母一次。
+给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的 字母异位词。
示例 1:
-输入: s = "anagram", t = "nagaram" +输入: s = "anagram", t = "nagaram" 输出: true
示例 2:
-输入: s = "rat", t = "car" +输入: s = "rat", t = "car" 输出: false
diff --git a/solution/0200-0299/0242.Valid Anagram/README_EN.md b/solution/0200-0299/0242.Valid Anagram/README_EN.md index 69e35ae8d1379..645c3738e357f 100644 --- a/solution/0200-0299/0242.Valid Anagram/README_EN.md +++ b/solution/0200-0299/0242.Valid Anagram/README_EN.md @@ -18,18 +18,25 @@ tags: -
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
+Given two strings s and t, return true if t is an anagram of s, and false otherwise.
Example 1:
-Input: s = "anagram", t = "nagaram" -Output: true -
Example 2:
-Input: s = "rat", t = "car" -Output: false -+ +
Input: s = "anagram", t = "nagaram"
+ +Output: true
+Example 2:
+ +Input: s = "rat", t = "car"
+ +Output: false
+
Constraints:
diff --git a/solution/0300-0399/0387.First Unique Character in a String/README_EN.md b/solution/0300-0399/0387.First Unique Character in a String/README_EN.md index 741838efba85c..a86551f835c7c 100644 --- a/solution/0300-0399/0387.First Unique Character in a String/README_EN.md +++ b/solution/0300-0399/0387.First Unique Character in a String/README_EN.md @@ -19,19 +19,37 @@ tags: -Given a string s, find the first non-repeating character in it and return its index. If it does not exist, return -1.
Given a string s, find the first non-repeating character in it and return its index. If it does not exist, return -1.
Example 1:
-Input: s = "leetcode" -Output: 0 -
Example 2:
-Input: s = "loveleetcode" -Output: 2 -
Example 3:
-Input: s = "aabb" -Output: -1 -+ +
Input: s = "leetcode"
+ +Output: 0
+ +Explanation:
+ +The character 'l' at index 0 is the first character that does not occur at any other index.
Example 2:
+ +Input: s = "loveleetcode"
+ +Output: 2
+Example 3:
+ +Input: s = "aabb"
+ +Output: -1
+
Constraints:
diff --git a/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md b/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md index 2b12c0afd2c64..a49c977a497eb 100644 --- a/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md +++ b/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md @@ -4,6 +4,7 @@ difficulty: 困难 edit_url: https://github.com/doocs/leetcode/edit/main/solution/0400-0499/0411.Minimum%20Unique%20Word%20Abbreviation/README.md tags: - 位运算 + - 数组 - 字符串 - 回溯 --- @@ -70,6 +71,7 @@ tags:1 <= dictionary[i].length <= 100n > 0 ,那么 log2(n) + m <= 21target 和 dictionary[i] 仅包含小写字符dictionary 不包含 target。diff --git a/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README_EN.md b/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README_EN.md index b212be8d5b140..039935058905c 100644 --- a/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README_EN.md +++ b/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README_EN.md @@ -4,6 +4,7 @@ difficulty: Hard edit_url: https://github.com/doocs/leetcode/edit/main/solution/0400-0499/0411.Minimum%20Unique%20Word%20Abbreviation/README_EN.md tags: - Bit Manipulation + - Array - String - Backtracking --- diff --git a/solution/0700-0799/0733.Flood Fill/README.md b/solution/0700-0799/0733.Flood Fill/README.md index 8f767ef589da4..e428216c351e4 100644 --- a/solution/0700-0799/0733.Flood Fill/README.md +++ b/solution/0700-0799/0733.Flood Fill/README.md @@ -23,7 +23,7 @@ tags:
你也被给予三个整数 sr , sc 和 color 。你应该从像素 image[sr][sc] 开始对图像进行 上色填充 。
为了完成 上色工作 ,从初始像素开始,记录初始坐标的 上下左右四个方向上 像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应 四个方向上 像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为 color 。
为了完成 上色工作,从初始像素开始,记录初始坐标的 上下左右四个方向上 相邻且同色的像素点,接着再记录与这些像素点相邻且同色的新像素点,……,重复该过程。将所有有记录的像素点的颜色值改为 color。
最后返回 经过上色渲染后的图像 。
diff --git a/solution/0800-0899/0884.Uncommon Words from Two Sentences/README.md b/solution/0800-0899/0884.Uncommon Words from Two Sentences/README.md index 5e9167837601e..d2a7051f4907c 100644 --- a/solution/0800-0899/0884.Uncommon Words from Two Sentences/README.md +++ b/solution/0800-0899/0884.Uncommon Words from Two Sentences/README.md @@ -5,6 +5,7 @@ edit_url: https://github.com/doocs/leetcode/edit/main/solution/0800-0899/0884.Un tags: - 哈希表 - 字符串 + - 计数 --- diff --git a/solution/0800-0899/0884.Uncommon Words from Two Sentences/README_EN.md b/solution/0800-0899/0884.Uncommon Words from Two Sentences/README_EN.md index 8c5c9a9410380..178d6d746c811 100644 --- a/solution/0800-0899/0884.Uncommon Words from Two Sentences/README_EN.md +++ b/solution/0800-0899/0884.Uncommon Words from Two Sentences/README_EN.md @@ -5,6 +5,7 @@ edit_url: https://github.com/doocs/leetcode/edit/main/solution/0800-0899/0884.Un tags: - Hash Table - String + - Counting --- @@ -25,12 +26,25 @@ tags:
Example 1:
-Input: s1 = "this apple is sweet", s2 = "this apple is sour" -Output: ["sweet","sour"] -
Example 2:
-Input: s1 = "apple apple", s2 = "banana" -Output: ["banana"] -+ +
Input: s1 = "this apple is sweet", s2 = "this apple is sour"
+ +Output: ["sweet","sour"]
+ +Explanation:
+ +The word "sweet" appears only in s1, while the word "sour" appears only in s2.
Example 2:
+ +Input: s1 = "apple apple", s2 = "banana"
+ +Output: ["banana"]
+
Constraints:
diff --git a/solution/1000-1099/1055.Shortest Way to Form String/README.md b/solution/1000-1099/1055.Shortest Way to Form String/README.md index 5758f5ec5725f..8134b32effe24 100644 --- a/solution/1000-1099/1055.Shortest Way to Form String/README.md +++ b/solution/1000-1099/1055.Shortest Way to Form String/README.md @@ -6,6 +6,7 @@ tags: - 贪心 - 双指针 - 字符串 + - 二分查找 --- diff --git a/solution/1000-1099/1055.Shortest Way to Form String/README_EN.md b/solution/1000-1099/1055.Shortest Way to Form String/README_EN.md index c15d06aae9335..38ec03f24a9a1 100644 --- a/solution/1000-1099/1055.Shortest Way to Form String/README_EN.md +++ b/solution/1000-1099/1055.Shortest Way to Form String/README_EN.md @@ -6,6 +6,7 @@ tags: - Greedy - Two Pointers - String + - Binary Search --- diff --git a/solution/1000-1099/1078.Occurrences After Bigram/README.md b/solution/1000-1099/1078.Occurrences After Bigram/README.md index 08b432a41fb2a..a89a520d96bee 100644 --- a/solution/1000-1099/1078.Occurrences After Bigram/README.md +++ b/solution/1000-1099/1078.Occurrences After Bigram/README.md @@ -48,6 +48,7 @@ tags:text 中的所有单词之间都由 单个空格字符 分隔1 <= first.length, second.length <= 10first 和 second 由小写英文字母组成text 不包含任何前缀或尾随空格。1 <= text.length <= 1000text consists of lowercase English letters and spaces.text a separated by a single space.text are separated by a single space.1 <= first.length, second.length <= 10first and second consist of lowercase English letters.text will not have any leading or trailing spaces.Given n, return the value of Tn.
-
Example 1:
- Input: n = 4 - Output: 4 - Explanation: - T_3 = 0 + 1 + 1 = 2 - T_4 = 1 + 1 + 2 = 4 -
Example 2:
- Input: n = 25 - Output: 1389537 -
-
Constraints:
0 <= n <= 37answer <= 2^31 - 1.0 <= n <= 37answer <= 2^31 - 1.如果一个整数上的每一位数字与其相邻位上的数字的绝对差都是 1,那么这个数就是一个「步进数」。
如果一个整数上的每一位数字与其相邻位上的数字的绝对差都是 1,那么这个数就是一个「步进数」。
例如,321 是一个步进数,而 421 不是。
例如,321 是一个 步进数,而 421 不是。
给你两个整数,low 和 high,请你找出在 [low, high] 范围内的所有步进数,并返回 排序后 的结果。
给你两个整数,low 和 high,请你找出在 [low, high] 范围内的所有 步进数,并返回 排序后 的结果。
-
示例:
+示例 1:
-输入:low = 0, high = 21 ++输入:low = 0, high = 21 输出:[0,1,2,3,4,5,6,7,8,9,10,12,21]+示例 2:
+ ++输入:low = 10, high = 15 +输出:[10,12] ++
提示:
0 <= low <= high <= 2 * 10^90 <= low <= high <= 2 * 109s 中选出 最小 的字符,将它 接在 结果字符串的后面。s 剩余字符中选出 最小 的字符,且该字符比上一个添加的字符大,将它 接在 结果字符串后面。s 剩余字符中选出比上一个添加字符更大的 最小 字符,将它 接在 结果字符串后面。s 中选择字符。s 中选出 最大 的字符,将它 接在 结果字符串的后面。s 剩余字符中选出 最大 的字符,且该字符比上一个添加的字符小,将它 接在 结果字符串后面。s 剩余字符中选出比上一个添加字符更小的 最大 字符,将它 接在 结果字符串后面。s 中选择字符。s 中所有字符都已经被选过。示例 2:
diff --git a/solution/1600-1699/1684.Count the Number of Consistent Strings/README.md b/solution/1600-1699/1684.Count the Number of Consistent Strings/README.md index 866df5d11f411..c0a6aebff87a2 100644 --- a/solution/1600-1699/1684.Count the Number of Consistent Strings/README.md +++ b/solution/1600-1699/1684.Count the Number of Consistent Strings/README.md @@ -9,6 +9,7 @@ tags: - 数组 - 哈希表 - 字符串 + - 计数 --- diff --git a/solution/1600-1699/1684.Count the Number of Consistent Strings/README_EN.md b/solution/1600-1699/1684.Count the Number of Consistent Strings/README_EN.md index bfd62009bf747..68ead74ee66be 100644 --- a/solution/1600-1699/1684.Count the Number of Consistent Strings/README_EN.md +++ b/solution/1600-1699/1684.Count the Number of Consistent Strings/README_EN.md @@ -9,6 +9,7 @@ tags: - Array - Hash Table - String + - Counting --- diff --git a/solution/1800-1899/1822.Sign of the Product of an Array/README_EN.md b/solution/1800-1899/1822.Sign of the Product of an Array/README_EN.md index 37522697c5fc4..35a3fcf6183e9 100644 --- a/solution/1800-1899/1822.Sign of the Product of an Array/README_EN.md +++ b/solution/1800-1899/1822.Sign of the Product of an Array/README_EN.md @@ -19,7 +19,7 @@ tags: -There is a function signFunc(x) that returns:
Implement a function signFunc(x) that returns:
1 if x is positive.1 <= arr[i] <= 105+
Note: This question is the same as 2615: Sum of Distances.
+ ## Solutions diff --git a/solution/2400-2499/2456.Most Popular Video Creator/README_EN.md b/solution/2400-2499/2456.Most Popular Video Creator/README_EN.md index 9c04d49793fdd..555644f9d94a1 100644 --- a/solution/2400-2499/2456.Most Popular Video Creator/README_EN.md +++ b/solution/2400-2499/2456.Most Popular Video Creator/README_EN.md @@ -22,7 +22,7 @@ tags: -You are given two string arrays creators and ids, and an integer array views, all of length n. The ith video on a platform was created by creator[i], has an id of ids[i], and has views[i] views.
You are given two string arrays creators and ids, and an integer array views, all of length n. The ith video on a platform was created by creators[i], has an id of ids[i], and has views[i] views.
The popularity of a creator is the sum of the number of views on all of the creator's videos. Find the creator with the highest popularity and the id of their most viewed video.
@@ -31,32 +31,40 @@ tags:Return a 2D array of strings answer where answer[i] = [creatori, idi] means that creatori has the highest popularity and idi is the id of their most popular video. The answer can be returned in any order.
Note: It is possible for different videos to have the same id, meaning that ids do not uniquely identify a video. For example, two videos with the same ID are considered as distinct videos with their own viewcount.
Return a 2D array of strings answer where answer[i] = [creatorsi, idi] means that creatorsi has the highest popularity and idi is the id of their most popular video. The answer can be returned in any order.
Example 1:
--Input: creators = ["alice","bob","alice","chris"], ids = ["one","two","three","four"], views = [5,10,5,4] -Output: [["alice","one"],["bob","two"]] -Explanation: -The popularity of alice is 5 + 5 = 10. -The popularity of bob is 10. -The popularity of chris is 4. -alice and bob are the most popular creators. -For bob, the video with the highest view count is "two". -For alice, the videos with the highest view count are "one" and "three". Since "one" is lexicographically smaller than "three", it is included in the answer. -+
Input: creators = ["alice","bob","alice","chris"], ids = ["one","two","three","four"], views = [5,10,5,4]
+ +Output: [["alice","one"],["bob","two"]]
+ +Explanation:
+ +The popularity of alice is 5 + 5 = 10.
+The popularity of bob is 10.
+The popularity of chris is 4.
+alice and bob are the most popular creators.
+For bob, the video with the highest view count is "two".
+For alice, the videos with the highest view count are "one" and "three". Since "one" is lexicographically smaller than "three", it is included in the answer.
Example 2:
--Input: creators = ["alice","alice","alice"], ids = ["a","b","c"], views = [1,2,2] -Output: [["alice","b"]] -Explanation: -The videos with id "b" and "c" have the highest view count. -Since "b" is lexicographically smaller than "c", it is included in the answer. -+
Input: creators = ["alice","alice","alice"], ids = ["a","b","c"], views = [1,2,2]
+ +Output: [["alice","b"]]
+ +Explanation:
+ +The videos with id "b" and "c" have the highest view count.
+Since "b" is lexicographically smaller than "c", it is included in the answer.
Constraints:
diff --git a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md index cd17af9badb85..aa9e74b194079 100644 --- a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md +++ b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README.md @@ -9,6 +9,7 @@ tags: - 数组 - 哈希表 - 字符串 + - 计数 --- diff --git a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md index 4fd22e5926292..3b483b5ff297d 100644 --- a/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md +++ b/solution/2500-2599/2506.Count Pairs Of Similar Strings/README_EN.md @@ -9,6 +9,7 @@ tags: - Array - Hash Table - String + - Counting --- diff --git a/solution/2500-2599/2576.Find the Maximum Number of Marked Indices/README_EN.md b/solution/2500-2599/2576.Find the Maximum Number of Marked Indices/README_EN.md index ff328aff8910e..d18fe806c6420 100644 --- a/solution/2500-2599/2576.Find the Maximum Number of Marked Indices/README_EN.md +++ b/solution/2500-2599/2576.Find the Maximum Number of Marked Indices/README_EN.md @@ -70,7 +70,7 @@ Since there is no other operation, the answer is 4.-