diff --git a/solution/0000-0099/0032.Longest Valid Parentheses/README.md b/solution/0000-0099/0032.Longest Valid Parentheses/README.md
index 41b8be83eb9e6..6e23e7719174d 100644
--- a/solution/0000-0099/0032.Longest Valid Parentheses/README.md
+++ b/solution/0000-0099/0032.Longest Valid Parentheses/README.md
@@ -18,7 +18,9 @@ tags:
-给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
+给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号 子串 的长度。
+
+左右括号匹配,即每个左括号都有对应的右括号将其闭合的字符串是格式正确的,比如 "(()())"。
diff --git a/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md b/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md
index d84ddc3e91a90..055329f700460 100644
--- a/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md
+++ b/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md
@@ -19,7 +19,7 @@ tags:
整数数组 nums 按升序排列,数组中的值 互不相同 。
-在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
+在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 向左旋转 3 次后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
diff --git a/solution/0000-0099/0033.Search in Rotated Sorted Array/README_EN.md b/solution/0000-0099/0033.Search in Rotated Sorted Array/README_EN.md
index 871221d1251a8..ff3c0a1ead08a 100644
--- a/solution/0000-0099/0033.Search in Rotated Sorted Array/README_EN.md
+++ b/solution/0000-0099/0033.Search in Rotated Sorted Array/README_EN.md
@@ -19,7 +19,7 @@ tags:
There is an integer array nums sorted in ascending order (with distinct values).
-Prior to being passed to your function, nums is possibly rotated at an unknown pivot index k (1 <= k < nums.length) such that the resulting array is [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]] (0-indexed). For example, [0,1,2,4,5,6,7] might be rotated at pivot index 3 and become [4,5,6,7,0,1,2].
+Prior to being passed to your function, nums is possibly left rotated at an unknown index k (1 <= k < nums.length) such that the resulting array is [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]] (0-indexed). For example, [0,1,2,4,5,6,7] might be left rotated by 3 indices and become [4,5,6,7,0,1,2].
Given the array nums after the possible rotation and an integer target, return the index of target if it is in nums, or -1 if it is not in nums.
diff --git a/solution/0000-0099/0045.Jump Game II/README.md b/solution/0000-0099/0045.Jump Game II/README.md
index df5afce25a020..89be5cab7bfd5 100644
--- a/solution/0000-0099/0045.Jump Game II/README.md
+++ b/solution/0000-0099/0045.Jump Game II/README.md
@@ -20,14 +20,14 @@ tags:
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
-每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
+每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在索引 i 处,你可以跳转到任意 (i + j) 处:
- 0 <= j <= nums[i] 0 <= j <= nums[i] 且i + j < n
-返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。
+返回到达 n - 1 的最小跳跃次数。测试用例保证可以到达 n - 1。
@@ -54,7 +54,7 @@ tags:
1 <= nums.length <= 1040 <= nums[i] <= 1000- 题目保证可以到达
nums[n-1]
+ - 题目保证可以到达
n - 1
diff --git a/solution/0000-0099/0045.Jump Game II/README_EN.md b/solution/0000-0099/0045.Jump Game II/README_EN.md
index 26a6b6242448f..d1f1c273a53a4 100644
--- a/solution/0000-0099/0045.Jump Game II/README_EN.md
+++ b/solution/0000-0099/0045.Jump Game II/README_EN.md
@@ -18,16 +18,16 @@ tags:
-You are given a 0-indexed array of integers nums of length n. You are initially positioned at nums[0].
+You are given a 0-indexed array of integers nums of length n. You are initially positioned at index 0.
-Each element nums[i] represents the maximum length of a forward jump from index i. In other words, if you are at nums[i], you can jump to any nums[i + j] where:
+Each element nums[i] represents the maximum length of a forward jump from index i. In other words, if you are at index i, you can jump to any index (i + j) where:
0 <= j <= nums[i] andi + j < n
-Return the minimum number of jumps to reach nums[n - 1]. The test cases are generated such that you can reach nums[n - 1].
+Return the minimum number of jumps to reach index n - 1. The test cases are generated such that you can reach index n - 1.
Example 1:
diff --git a/solution/0100-0199/0190.Reverse Bits/README.md b/solution/0100-0199/0190.Reverse Bits/README.md
index 4538936385624..9bcaffac01ee3 100644
--- a/solution/0100-0199/0190.Reverse Bits/README.md
+++ b/solution/0100-0199/0190.Reverse Bits/README.md
@@ -23,7 +23,7 @@ tags:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- - 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在 示例 2 中,输入表示有符号整数
-3,输出表示有符号整数 -1073741825。
+ - 在 Java 中,编译器使用二进制补码记法来表示有符号整数。
diff --git a/solution/0100-0199/0190.Reverse Bits/README_EN.md b/solution/0100-0199/0190.Reverse Bits/README_EN.md
index 3e84004956967..9463a8ca49e00 100644
--- a/solution/0100-0199/0190.Reverse Bits/README_EN.md
+++ b/solution/0100-0199/0190.Reverse Bits/README_EN.md
@@ -23,7 +23,7 @@ tags:
- Note that in some languages, such as Java, there is no unsigned integer type. In this case, both input and output will be given as a signed integer type. They should not affect your implementation, as the integer's internal binary representation is the same, whether it is signed or unsigned.
- - In Java, the compiler represents the signed integers using 2's complement notation. Therefore, in Example 2 below, the input represents the signed integer
-3 and the output represents the signed integer -1073741825.
+ - In Java, the compiler represents the signed integers using 2's complement notation.
diff --git a/solution/0300-0399/0307.Range Sum Query - Mutable/README.md b/solution/0300-0399/0307.Range Sum Query - Mutable/README.md
index 73f33a3388a62..03d184f9857ae 100644
--- a/solution/0300-0399/0307.Range Sum Query - Mutable/README.md
+++ b/solution/0300-0399/0307.Range Sum Query - Mutable/README.md
@@ -7,6 +7,7 @@ tags:
- 树状数组
- 线段树
- 数组
+ - 分治
---
diff --git a/solution/0300-0399/0307.Range Sum Query - Mutable/README_EN.md b/solution/0300-0399/0307.Range Sum Query - Mutable/README_EN.md
index 380df451ebaaf..b9a6a0b062f3b 100644
--- a/solution/0300-0399/0307.Range Sum Query - Mutable/README_EN.md
+++ b/solution/0300-0399/0307.Range Sum Query - Mutable/README_EN.md
@@ -7,6 +7,7 @@ tags:
- Binary Indexed Tree
- Segment Tree
- Array
+ - Divide and Conquer
---
diff --git a/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md b/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md
index 7beaa49386445..ce09eb5f47c0d 100644
--- a/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md
+++ b/solution/0300-0399/0308.Range Sum Query 2D - Mutable/README.md
@@ -62,13 +62,13 @@ numMatrix.sumRegion(2, 1, 4, 3); // 返回 10 (即,右侧红色矩形的和)
m == matrix.length
n == matrix[i].length
1 <= m, n <= 200
- -105 <= matrix[i][j] <= 105
+ -1000 <= matrix[i][j] <= 1000
0 <= row < m
0 <= col < n
- -105 <= val <= 105
+ -1000 <= val <= 1000
0 <= row1 <= row2 < m
0 <= col1 <= col2 < n
- 最多调用104 次 sumRegion 和 update 方法
+ 最多调用5000 次 sumRegion 和 update 方法
diff --git a/solution/0300-0399/0394.Decode String/README.md b/solution/0300-0399/0394.Decode String/README.md
index 0cbd5f13b03b2..7d1e91b5d87c6 100644
--- a/solution/0300-0399/0394.Decode String/README.md
+++ b/solution/0300-0399/0394.Decode String/README.md
@@ -26,6 +26,8 @@ tags:
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
+测试用例保证输出的长度不会超过 105。
+
示例 1:
diff --git a/solution/0400-0499/0475.Heaters/README_EN.md b/solution/0400-0499/0475.Heaters/README_EN.md
index 518ecb9eb8201..8b63f1ef8dea6 100644
--- a/solution/0400-0499/0475.Heaters/README_EN.md
+++ b/solution/0400-0499/0475.Heaters/README_EN.md
@@ -25,7 +25,7 @@ tags:
Given the positions of houses and heaters on a horizontal line, return the minimum radius standard of heaters so that those heaters could cover all houses.
-Notice that all the heaters follow your radius standard, and the warm radius will the same.
+Notice that all the heaters follow your radius standard, and the warm radius will be the same.
Example 1:
diff --git a/solution/0400-0499/0499.The Maze III/README.md b/solution/0400-0499/0499.The Maze III/README.md
index 65546e7027af0..8b82449612cf2 100644
--- a/solution/0400-0499/0499.The Maze III/README.md
+++ b/solution/0400-0499/0499.The Maze III/README.md
@@ -23,9 +23,9 @@ tags:
-由空地和墙组成的迷宫中有一个球。球可以向上(u)下(d)左(l)右(r)四个方向滚动,但在遇到墙壁前不会停止滚动。当球停下时,可以选择下一个方向。迷宫中还有一个洞,当球运动经过洞时,就会掉进洞里。
+由空地和墙组成的迷宫中有一个球。球可以向上(u)下(d)左(l)右(r)四个方向滚动,但在遇到墙壁前不会停止滚动。当球停下时,可以选择下一个方向(必须与上一个选择的方向不同)。迷宫中还有一个洞,当球运动经过洞时,就会掉进洞里。
-给定球的起始位置,目的地和迷宫,找出让球以最短距离掉进洞里的路径。 距离的定义是球从起始位置(不包括)到目的地(包括)经过的空地个数。通过'u', 'd', 'l' 和 'r'输出球的移动方向。 由于可能有多条最短路径, 请输出字典序最小的路径。如果球无法进入洞,输出"impossible"。
+给定球的起始位置,目的地和迷宫,找出让球以最短距离掉进洞里的路径。 距离的定义是球从起始位置(不包括)到目的地(包括)经过的空地个数。通过'u', 'd', 'l' 和 'r'输出球的移动方向。 由于可能有多条最短路径, 请输出字典序最小的路径。如果球无法进入洞,输出"impossible"。
迷宫由一个0和1的二维数组表示。 1表示墙壁,0表示空地。你可以假定迷宫的边缘都是墙壁。起始位置和目的地的坐标通过行号和列号给出。
@@ -33,7 +33,8 @@ tags:
示例1:
-输入 1: 迷宫由以下二维数组表示
+
+输入 1: 迷宫由以下二维数组表示
0 0 0 0 0
1 1 0 0 1
@@ -44,18 +45,19 @@ tags:
输入 2: 球的初始位置 (rowBall, colBall) = (4, 3)
输入 3: 洞的位置 (rowHole, colHole) = (0, 1)
-输出: "lul"
+输出: "lul"
解析: 有两条让球进洞的最短路径。
-第一条路径是 左 -> 上 -> 左, 记为 "lul".
-第二条路径是 上 -> 左, 记为 'ul'.
-两条路径都具有最短距离6, 但'l' < 'u',故第一条路径字典序更小。因此输出"lul"。
- +第一条路径是 左 -> 上 -> 左, 记为 "lul".
+第二条路径是 上 -> 左, 记为 'ul'.
+两条路径都具有最短距离6, 但'l' < 'u',故第一条路径字典序更小。因此输出"lul"。
+
+第一条路径是 左 -> 上 -> 左, 记为 "lul".
+第二条路径是 上 -> 左, 记为 'ul'.
+两条路径都具有最短距离6, 但'l' < 'u',故第一条路径字典序更小。因此输出"lul"。
+
示例 2:
-输入 1: 迷宫由以下二维数组表示
+
+输入 1: 迷宫由以下二维数组表示
0 0 0 0 0
1 1 0 0 1
@@ -66,10 +68,10 @@ tags:
输入 2: 球的初始位置 (rowBall, colBall) = (4, 3)
输入 3: 洞的位置 (rowHole, colHole) = (3, 0)
-输出: "impossible"
+输出: "impossible"
示例: 球无法到达洞。
- +
+
diff --git a/solution/0500-0599/0544.Output Contest Matches/README.md b/solution/0500-0599/0544.Output Contest Matches/README.md
index 6a0ea9563e040..a834513118b31 100644
--- a/solution/0500-0599/0544.Output Contest Matches/README.md
+++ b/solution/0500-0599/0544.Output Contest Matches/README.md
@@ -58,7 +58,7 @@ tags:
提示:
- n == 2x,并且 x 在范围 [1,12] 内。n == 2x,并且 x 在范围 [1, 12] 内。
diff --git a/solution/0800-0899/0808.Soup Servings/README.md b/solution/0800-0899/0808.Soup Servings/README.md
index f294befb103e1..598b2d354b358 100644
--- a/solution/0800-0899/0808.Soup Servings/README.md
+++ b/solution/0800-0899/0808.Soup Servings/README.md
@@ -18,29 +18,36 @@ tags:
-有 A 和 B 两种类型 的汤。一开始每种类型的汤有 n 毫升。有四种分配操作:
+你有两种汤,A 和 B,每种初始为 n 毫升。在每一轮中,会随机选择以下四种操作中的一种,每种操作的概率为 0.25,且与之前的所有轮次 无关:
- - 提供
100ml 的 汤A 和 0ml 的 汤B 。
- - 提供
75ml 的 汤A 和 25ml 的 汤B 。
- - 提供
50ml 的 汤A 和 50ml 的 汤B 。
- - 提供
25ml 的 汤A 和 75ml 的 汤B 。
+ - 从汤 A 取 100 毫升,从汤 B 取 0 毫升
+ - 从汤 A 取 75 毫升,从汤 B 取 25 毫升
+ - 从汤 A 取 50 毫升,从汤 B 取 50 毫升
+ - 从汤 A 取 25 毫升,从汤 B 取 75 毫升
-当我们把汤分配给某人之后,汤就没有了。每个回合,我们将从四种概率同为 0.25 的操作中进行分配选择。如果汤的剩余量不足以完成某次操作,我们将尽可能分配。当两种类型的汤都分配完时,停止操作。
+注意:
-注意 不存在先分配 100 ml 汤B 的操作。
+
+ - 不存在从汤 A 取
0 ml 和从汤 B 取 100 ml 的操作。
+ - 汤 A 和 B 在每次操作中同时被取出。
+ - 如果一次操作要求你取出比剩余的汤更多的量,请取出该汤剩余的所有部分。
+
+
+操作过程在任何回合中任一汤被取完后立即停止。
-需要返回的值: 汤A 先分配完的概率 + 汤A和汤B 同时分配完的概率 / 2。返回值在正确答案 10-5 的范围内将被认为是正确的。
+返回汤 A 在 B 前取完的概率,加上两种汤在 同一回合 取完概率的一半。返回值在正确答案 10-5 的范围内将被认为是正确的。
示例 1:
-输入: n = 50
-输出: 0.62500
-解释:如果我们选择前两个操作,A 首先将变为空。
+输入:n = 50
+输出:0.62500
+解释:
+如果我们选择前两个操作,A 首先将变为空。
对于第三个操作,A 和 B 会同时变为空。
对于第四个操作,B 首先将变为空。
所以 A 变为空的总概率加上 A 和 B 同时变为空的概率的一半是 0.25 *(1 + 1 + 0.5 + 0)= 0.625。
@@ -49,8 +56,14 @@ tags:
示例 2:
-输入: n = 100
-输出: 0.71875
+输入:n = 100
+输出:0.71875
+解释:
+如果我们选择第一个操作,A 首先将变为空。
+如果我们选择第二个操作,A 将在执行操作 [1, 2, 3] 时变为空,然后 A 和 B 在执行操作 4 时同时变空。
+如果我们选择第三个操作,A 将在执行操作 [1, 2] 时变为空,然后 A 和 B 在执行操作 3 时同时变空。
+如果我们选择第四个操作,A 将在执行操作 1 时变为空,然后 A 和 B 在执行操作 2 时同时变空。
+所以 A 变为空的总概率加上 A 和 B 同时变为空的概率的一半是 0.71875。
@@ -58,7 +71,7 @@ tags:
提示:
- 0 <= n <= 1090 <= n <= 109
diff --git a/solution/0800-0899/0808.Soup Servings/README_EN.md b/solution/0800-0899/0808.Soup Servings/README_EN.md
index 07bca39d5b0c1..e65944861f883 100644
--- a/solution/0800-0899/0808.Soup Servings/README_EN.md
+++ b/solution/0800-0899/0808.Soup Servings/README_EN.md
@@ -18,20 +18,26 @@ tags:
-There are two types of soup: type A and type B. Initially, we have n ml of each type of soup. There are four kinds of operations:
+You have two soups, A and B, each starting with n mL. On every turn, one of the following four serving operations is chosen at random, each with probability 0.25 independent of all previous turns:
-
- - Serve
100 ml of soup A and 0 ml of soup B,
- - Serve
75 ml of soup A and 25 ml of soup B,
- - Serve
50 ml of soup A and 50 ml of soup B, and
- - Serve
25 ml of soup A and 75 ml of soup B.
-
+
+ - pour 100 mL from type A and 0 mL from type B
+ - pour 75 mL from type A and 25 mL from type B
+ - pour 50 mL from type A and 50 mL from type B
+ - pour 25 mL from type A and 75 mL from type B
+
+
+Note:
-When we serve some soup, we give it to someone, and we no longer have it. Each turn, we will choose from the four operations with an equal probability 0.25. If the remaining volume of soup is not enough to complete the operation, we will serve as much as possible. We stop once we no longer have some quantity of both types of soup.
+
+ - There is no operation that pours 0 mL from A and 100 mL from B.
+ - The amounts from A and B are poured simultaneously during the turn.
+ - If an operation asks you to pour more than you have left of a soup, pour all that remains of that soup.
+
-Note that we do not have an operation where all 100 ml's of soup B are used first.
+The process stops immediately after any turn in which one of the soups is used up.
-Return the probability that soup A will be empty first, plus half the probability that A and B become empty at the same time. Answers within 10-5 of the actual answer will be accepted.
+Return the probability that A is used up before B, plus half the probability that both soups are used up in the same turn. Answers within 10-5 of the actual answer will be accepted.
Example 1:
@@ -39,9 +45,10 @@ tags:
Input: n = 50
Output: 0.62500
-Explanation: If we choose the first two operations, A will become empty first.
-For the third operation, A and B will become empty at the same time.
-For the fourth operation, B will become empty first.
+Explanation:
+If we perform either of the first two serving operations, soup A will become empty first.
+If we perform the third operation, A and B will become empty at the same time.
+If we perform the fourth operation, B will become empty first.
So the total probability of A becoming empty first plus half the probability that A and B become empty at the same time, is 0.25 * (1 + 1 + 0.5 + 0) = 0.625.
@@ -50,6 +57,12 @@ So the total probability of A becoming empty first plus half the probability tha
Input: n = 100
Output: 0.71875
+Explanation:
+If we perform the first serving operation, soup A will become empty first.
+If we perform the second serving operations, A will become empty on performing operation [1, 2, 3], and both A and B become empty on performing operation 4.
+If we perform the third operation, A will become empty on performing operation [1, 2], and both A and B become empty on performing operation 3.
+If we perform the fourth operation, A will become empty on performing operation 1, and both A and B become empty on performing operation 2.
+So the total probability of A becoming empty first plus half the probability that A and B become empty at the same time, is 0.71875.
diff --git a/solution/0800-0899/0873.Length of Longest Fibonacci Subsequence/README.md b/solution/0800-0899/0873.Length of Longest Fibonacci Subsequence/README.md
index 4a4ddd95f3f1f..6944d36dfbcfc 100644
--- a/solution/0800-0899/0873.Length of Longest Fibonacci Subsequence/README.md
+++ b/solution/0800-0899/0873.Length of Longest Fibonacci Subsequence/README.md
@@ -18,7 +18,7 @@ tags:
-如果序列 x1, x2, ..., x2 满足下列条件,就说它是 斐波那契式 的:
+如果序列 x1, x2, ..., xn 满足下列条件,就说它是 斐波那契式 的:
n >= 3示例 4:
+ +
+
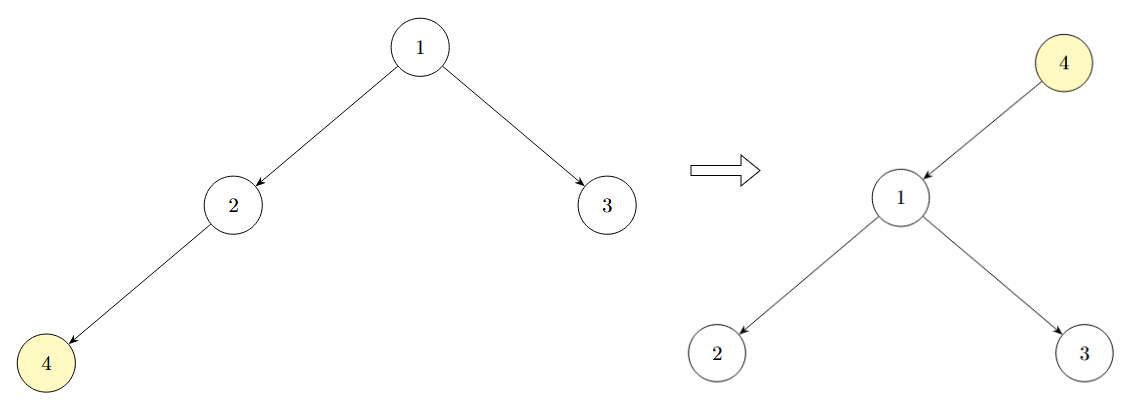
+输入:root = [1,null,2,3,null,4], p = 1, q = 4
+输出:[4,null,1,null,2,3]
+解释:该示例属于第一种情况,因为节点 q 在节点 p 的子树中。断开节点 4 与其父节点,并将节点 1 及其子树移动,使其成为节点 4 的子节点。
+
+
提示:
diff --git a/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md b/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md
index c45eecbc8686b..35de4c68d1b42 100644
--- a/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md
+++ b/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README.md
@@ -34,7 +34,7 @@ tags:
输入:nums = [3,4,5,1,2]
输出:true
解释:[1,2,3,4,5] 为有序的源数组。
-可以轮转 x = 3 个位置,使新数组从值为 3 的元素开始:[3,4,5,1,2] 。
+可以轮转 x = 2 个位置,使新数组从值为 3 的元素开始:[3,4,5,1,2] 。
示例 2:
diff --git a/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README_EN.md b/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README_EN.md
index a9302e2480207..c4aaccde44fc3 100644
--- a/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README_EN.md
+++ b/solution/1700-1799/1752.Check if Array Is Sorted and Rotated/README_EN.md
@@ -31,7 +31,7 @@ tags:
Input: nums = [3,4,5,1,2]
Output: true
Explanation: [1,2,3,4,5] is the original sorted array.
-You can rotate the array by x = 3 positions to begin on the element of value 3: [3,4,5,1,2].
+You can rotate the array by x = 2 positions to begin on the element of value 3: [3,4,5,1,2].
Example 2:
@@ -51,24 +51,6 @@ You can rotate the array by x = 3 positions to begin on the element of value 3:
You can rotate the array by x = 0 positions (i.e. no rotation) to make nums.
-
-
Constraints:
diff --git a/solution/1900-1999/1962.Remove Stones to Minimize the Total/README.md b/solution/1900-1999/1962.Remove Stones to Minimize the Total/README.md
index 347d8989c2680..3ad285fcae654 100644
--- a/solution/1900-1999/1962.Remove Stones to Minimize the Total/README.md
+++ b/solution/1900-1999/1962.Remove Stones to Minimize the Total/README.md
@@ -23,14 +23,14 @@ tags:
给你一个整数数组 piles ,数组 下标从 0 开始 ,其中 piles[i] 表示第 i 堆石子中的石子数量。另给你一个整数 k ,请你执行下述操作 恰好 k 次:
- - 选出任一石子堆
piles[i] ,并从中 移除 ceil(piles[i] / 2) 颗石子。
+ - 选出任一石子堆
piles[i] ,并从中 移除 floor(piles[i] / 2) 颗石子。
注意:你可以对 同一堆 石子多次执行此操作。
返回执行 k 次操作后,剩下石子的 最小 总数。
-ceil(x) 为 大于 或 等于 x 的 最小 整数。(即,对 x 向上取整)。
+floor(x) 为 小于 或 等于 x 的 最大 整数。(即,对 x 向下取整)。
diff --git a/solution/2000-2099/2019.The Score of Students Solving Math Expression/README.md b/solution/2000-2099/2019.The Score of Students Solving Math Expression/README.md
index 3f98e3762a616..3bc0c67f8f974 100644
--- a/solution/2000-2099/2019.The Score of Students Solving Math Expression/README.md
+++ b/solution/2000-2099/2019.The Score of Students Solving Math Expression/README.md
@@ -8,6 +8,7 @@ tags:
- 栈
- 记忆化搜索
- 数组
+ - 哈希表
- 数学
- 字符串
- 动态规划
@@ -44,9 +45,10 @@ tags:
示例 1:
-
+
-输入:s = "7+3*1*2", answers = [20,13,42]
+
+输入:s = "7+3*1*2", answers = [20,13,42]
输出:7
解释:如上图所示,正确答案为 13 ,因此有一位学生得分为 5 分:[20,13,42] 。
一位学生可能通过错误的运算顺序得到结果 20 :7+3=10,10*1=10,10*2=20 。所以这位学生得分为 2 分:[20,13,42] 。
@@ -55,7 +57,8 @@ tags:
示例 2:
-输入:s = "3+5*2", answers = [13,0,10,13,13,16,16]
+
+输入:s = "3+5*2", answers = [13,0,10,13,13,16,16]
输出:19
解释:表达式的正确结果为 13 ,所以有 3 位学生得到 5 分:[13,0,10,13,13,16,16] 。
学生可能通过错误的运算顺序得到结果 16 :3+5=8,8*2=16 。所以两位学生得到 2 分:[13,0,10,13,13,16,16] 。
@@ -64,7 +67,8 @@ tags:
示例 3:
-输入:s = "6+0*1", answers = [12,9,6,4,8,6]
+
+输入:s = "6+0*1", answers = [12,9,6,4,8,6]
输出:10
解释:表达式的正确结果为 6 。
如果一位学生通过错误的运算顺序计算该表达式,结果仍为 6 。
@@ -82,6 +86,7 @@ tags:
表达式中所有整数运算数字都在闭区间 [0, 9] 以内。
1 <= 数学表达式中所有运算符数目('+' 和 '*') <= 15
测试数据保证正确表达式结果在范围 [0, 1000] 以内。
+ 测试用例保证乘法中间步骤中的值永远不会超过 109。
n == answers.length
1 <= n <= 104
0 <= answers[i] <= 1000
diff --git a/solution/2000-2099/2019.The Score of Students Solving Math Expression/README_EN.md b/solution/2000-2099/2019.The Score of Students Solving Math Expression/README_EN.md
index 57471129cdde4..4f97ba51de745 100644
--- a/solution/2000-2099/2019.The Score of Students Solving Math Expression/README_EN.md
+++ b/solution/2000-2099/2019.The Score of Students Solving Math Expression/README_EN.md
@@ -8,6 +8,7 @@ tags:
- Stack
- Memoization
- Array
+ - Hash Table
- Math
- String
- Dynamic Programming
@@ -81,6 +82,7 @@ The points for the students are: [0,0,5,0,0,5]. The sum of the points is 10.
All the integer operands in the expression are in the inclusive range [0, 9].
1 <= The count of all operators ('+' and '*') in the math expression <= 15
Test data are generated such that the correct answer of the expression is in the range of [0, 1000].
+ Test data are generated such that value never exceeds 109 in intermediate steps of multiplication.
n == answers.length
1 <= n <= 104
0 <= answers[i] <= 1000
diff --git a/solution/2500-2599/2561.Rearranging Fruits/README.md b/solution/2500-2599/2561.Rearranging Fruits/README.md
index ec80d1c864dc2..9f4b96da07532 100644
--- a/solution/2500-2599/2561.Rearranging Fruits/README.md
+++ b/solution/2500-2599/2561.Rearranging Fruits/README.md
@@ -55,7 +55,7 @@ tags:
提示:
- basket1.length == bakste2.lengthbasket1.length == basket2.length1 <= basket1.length <= 1051 <= basket1i,basket2i <= 109
diff --git a/solution/2800-2899/2861.Maximum Number of Alloys/README.md b/solution/2800-2899/2861.Maximum Number of Alloys/README.md
index 3cbf2067df150..2f31702307582 100644
--- a/solution/2800-2899/2861.Maximum Number of Alloys/README.md
+++ b/solution/2800-2899/2861.Maximum Number of Alloys/README.md
@@ -21,7 +21,7 @@ tags:
假设你是一家合金制造公司的老板,你的公司使用多种金属来制造合金。现在共有 n 种不同类型的金属可以使用,并且你可以使用 k 台机器来制造合金。每台机器都需要特定数量的每种金属来创建合金。
-对于第 i 台机器而言,创建合金需要 composition[i][j] 份 j 类型金属。最初,你拥有 stock[i] 份 i 类型金属,而每购入一份 i 类型金属需要花费 cost[i] 的金钱。
+对于第 i 台机器而言,创建合金需要 composition[i][j] 份 j 类型金属。最初,你拥有 stock[x] 份 x 类型金属,而每购入一份 x 类型金属需要花费 cost[x] 的金钱。
给你整数 n、k、budget,下标从 1 开始的二维数组 composition,两个下标从 1 开始的数组 stock 和 cost,请你在预算不超过 budget 金钱的前提下,最大化 公司制造合金的数量。
diff --git a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README.md b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README.md
index 7af11d3ddb0a0..a1a291150c627 100644
--- a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README.md
+++ b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README.md
@@ -48,7 +48,7 @@ tags:
解释:
-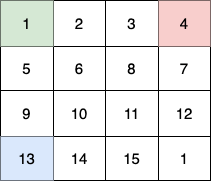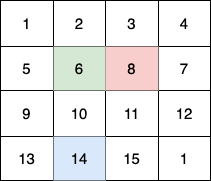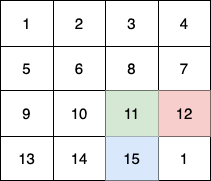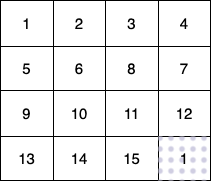
+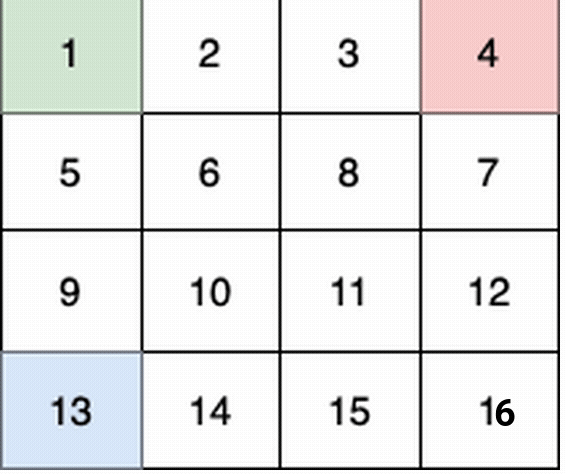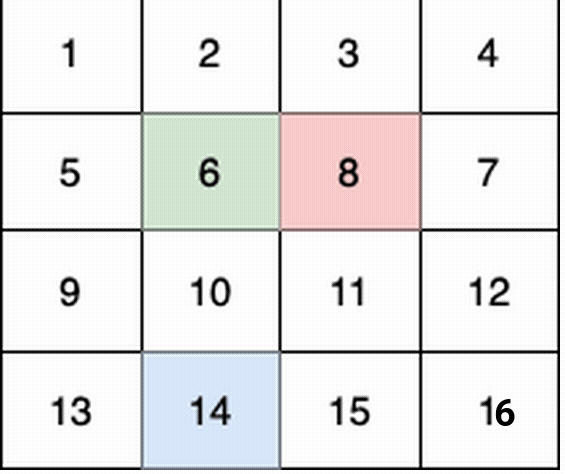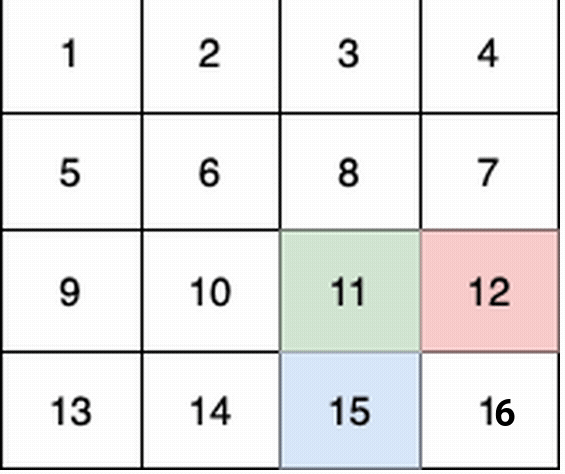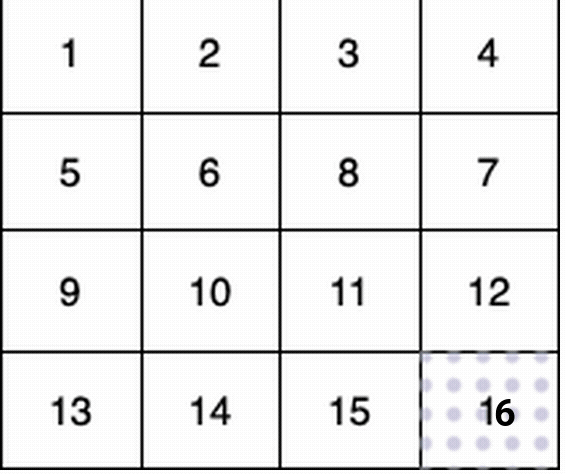
这个例子中:
@@ -58,7 +58,7 @@ tags:
第 3 个小朋友(蓝色)的移动路径为 (3,0) -> (3,1) -> (3,2) -> (3, 3) 。
-他们总共能收集 1 + 6 + 11 + 1 + 4 + 8 + 12 + 13 + 14 + 15 = 100 个水果。
+他们总共能收集 1 + 6 + 11 + 16 + 4 + 8 + 12 + 13 + 14 + 15 = 100 个水果。
示例 2:
diff --git a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README_EN.md b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README_EN.md
index 9527625928b9b..6df3874d8b778 100644
--- a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README_EN.md
+++ b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/README_EN.md
@@ -46,7 +46,7 @@ tags:
Explanation:
-
+
In this example:
diff --git a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/images/clideo_editor_d0b446db9ba448e1a3fcdd0eecdb58d0-ezgifcom-crop.gif b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/images/clideo_editor_d0b446db9ba448e1a3fcdd0eecdb58d0-ezgifcom-crop.gif
new file mode 100644
index 0000000000000..a9f5c8312a62a
Binary files /dev/null and b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/images/clideo_editor_d0b446db9ba448e1a3fcdd0eecdb58d0-ezgifcom-crop.gif differ
diff --git a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/images/example_1.gif b/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/images/example_1.gif
deleted file mode 100644
index 238b35efb076c..0000000000000
Binary files a/solution/3300-3399/3363.Find the Maximum Number of Fruits Collected/images/example_1.gif and /dev/null differ
diff --git a/solution/3300-3399/3374.First Letter Capitalization II/README_EN.md b/solution/3300-3399/3374.First Letter Capitalization II/README_EN.md
index 33398814f88f9..c7b8ec71ce7d2 100644
--- a/solution/3300-3399/3374.First Letter Capitalization II/README_EN.md
+++ b/solution/3300-3399/3374.First Letter Capitalization II/README_EN.md
@@ -106,6 +106,13 @@ Each row contains a unique ID and the corresponding text content.
+
+Constraints:
+
+
+ context_text contains only English letters, and the characters in the list ['\', ' ', '@', '-', '/', '^', ',']
+
## Solutions
diff --git a/solution/3300-3399/3384.Team Dominance by Pass Success/README.md b/solution/3300-3399/3384.Team Dominance by Pass Success/README.md
index 65fd4b74ea843..3a9b7d49dd8d0 100644
--- a/solution/3300-3399/3384.Team Dominance by Pass Success/README.md
+++ b/solution/3300-3399/3384.Team Dominance by Pass Success/README.md
@@ -47,7 +47,7 @@ pass_to 表示 player_id 对应队员接球。
-编写一个解决方案来计算每支球队 在上半场的优势得分。规则如下:
+编写一个解决方案来计算每支球队 在上下两个半场的优势得分。规则如下:
 +
+ +
+