diff --git a/docs/data-tests/anomaly-detection-tests-oss-vs-cloud.mdx b/docs/data-tests/anomaly-detection-tests-oss-vs-cloud.mdx
new file mode 100644
index 000000000..0c33886e0
--- /dev/null
+++ b/docs/data-tests/anomaly-detection-tests-oss-vs-cloud.mdx
@@ -0,0 +1,37 @@
+---
+title: "Anomaly Detection Tests - OSS vs Cloud"
+---
+
+Elementary OSS and Elementary Cloud Platform both offer data anomaly detection. However, there are significant differences in implementation.
+
+There are two types of anomaly detection tests:
+
+* **Pipeline health monitors** - Monitor the pipeline runs, ensuring timely and complete data ingestion and transformation. These monitors monitor metadata to detect volume and freshness issues.
+
+* **Data quality metrics tests** - Run as part of the pipeline, collect metrics by querying the data itself. These include various data quality metrics such as nullness, cardinality, average, length, etc.
+
+Here is a comparison between the implementation of these tests in Elementary Cloud and OSS:
+
+## Pipeline Health Monitors - Freshness and Volume
+
+| | OSS | Cloud |
+| ----------------------- | --------------------------------------------- | ------------------------------------------------- |
+| **Implementation** | dbt tests | Elementary Cloud monitors |
+| **Tests execution** | Run in dbt | Run in Cloud |
+| **Coverage** | Manually added in code | Automated, out-of-the-box full coverage |
+| **Configuration** | Manual, many parameters required for accuracy | No configuration, automated ML models |
+| **Detection mechanism** | Z-score, statistical | ML anomaly detection, various models |
+| **What is monitored?** | Data | Metadata (query history, information schema) |
+| **Time to detection** | Only when dbt runs | As soon as the problem happens, including sources |
+| **Cost** | DWH compute | No cost, only metadata is leveraged |
+
+## Data Quality Metrics
+
+| | OSS | Cloud |
+| ----------------------- | --------------------------------------------- | ---------------------------------------------------- |
+| **Implementation** | dbt tests | Metrics collection in dbt, Elementary Cloud monitors |
+| **Tests execution** | Run in dbt | Metrics collection in dbt, detection in Cloud |
+| **Coverage** | Manually added in code | Opt-in, can be added in bulk in Cloud |
+| **Configuration** | Manual, many parameters required for accuracy | Automated ML models |
+| **Detection mechanism** | Z-score, statistical | ML anomaly detection, various models |
+| **What is monitored?** | Data | Data |
\ No newline at end of file
diff --git a/docs/data-tests/anomaly-detection-tests/Anomaly-troubleshooting-guide.mdx b/docs/data-tests/anomaly-detection-tests/Anomaly-troubleshooting-guide.mdx
new file mode 100644
index 000000000..c740e8c9b
--- /dev/null
+++ b/docs/data-tests/anomaly-detection-tests/Anomaly-troubleshooting-guide.mdx
@@ -0,0 +1,153 @@
+---
+title: "Anomaly Tests Troubleshooting"
+sidebarTitle: "Anomaly tests troubleshooting"
+---
+
+
+
+First, check if your test uses a timestamp column:
+
+```yaml
+# In your YAML configuration
+tests:
+ - elementary.volume_anomalies:
+ timestamp_column: created_at# If this is configured, you have a timestamp-based test
+```
+
+
+
+ - Metrics are calculated by grouping data into time buckets (default: 'day')
+ - Detection period (default: 2 days) determines how many buckets are being tested
+ - Training period data (default: 14 days) comes from historical buckets, allowing immediate anomaly detection with sufficient history
+
+ Verify data collection:
+
+ ```sql
+ -- Check if metrics are being collected in time buckets
+ SELECT
+ metric_timestamp,
+ metric_value,
+ COUNT(*) as metrics_per_bucket
+ FROM your_schema.data_monitoring_metrics
+ WHERE table_name = 'your_table'
+ GROUP BY metric_timestamp, metric_value
+ ORDER BY metric_timestamp DESC;
+
+ ```
+
+ - Each bucket should represent one time bucket (e.g., daily metrics)
+ - Gaps in `metric_timestamp` might indicate data collection issues
+ - Training uses historical buckets for anomaly detection
+
+ **Common collection issues:**
+
+ - Missing or null values in timestamp column
+ - Timestamp column not in expected format
+ - No data in specified training period
+
+
+
+
+
+ - Training period data builds up over multiple test runs, using the test run time as its timestamp column. This requires time to collect enough points; for a 14 day training period, the test would need 14 different runs on different days to have a full training set.
+ - Metrics are calculated for the entire table in each test run
+ - Detection period (default: 2 days) determines how many buckets are being tested
+
+ Check metric collection across test runs:
+
+ ```sql
+ -- Check metrics from different test runsSELECT
+ updated_at,
+ metric_value
+ FROM your_schema.data_monitoring_metrics
+ WHERE table_name = 'your_table'
+ ORDER BY updated_at DESC;
+
+ ```
+
+ - Should see one metric per test run and per dimension
+ - Training requires multiple test runs over time
+ - Each new test run creates the training point for a time bucket. A second test run within the same bucket will override the first one.
+
+ **Common collection issues:**
+
+ - Test hasn't run enough times
+ - Previous test runs failed
+ - Metrics not being saved between runs
+
+
+
+
+
+
+Anomaly detection is influenced by:
+
+- Detection period (default: 2 days) - the time window being tested
+- Sensitivity (default: 3.0) - how many standard deviations from normal before flagging
+- Training data from previous periods/runs
+- `metrics_anomaly_score` calculates the anomaly based on the data in `data_monitoring metrics`.
+
+Check calculations in `metrics_anomaly_score`:
+
+```sql
+-- Check how anomalies are being calculatedSELECT
+ metric_name,
+ metric_value,
+ training_avg,
+ training_stddev,
+ zscore,
+ severity
+FROM your_schema.metrics_anomaly_score
+WHERE table_name = 'your_table'
+ORDER BY detected_at DESC;
+```
+
+
+
+
+
+This occurs when there are fewer than 7 training data points. To resolve:
+
+### For timestamp-based tests:
+
+- Check if your timestamp column has enough historical data
+- Verify time buckets are being created correctly in `data_monitoring_metrics`
+- Look for gaps in your data that might affect bucket creation
+
+### For non-timestamp tests:
+
+- Run your tests multiple times to build up training data.
+- Check `data_monitoring_metrics` to verify the data collection. The test will need data for at least 7 time buckets (e.g 7 days) to calculate the anomaly.
+
+
+
+
+
+If your test isn't appearing in `data_monitoring_metrics`:
+
+Verify test configuration:
+
+```yaml
+tests:
+ - elementary.volume_anomalies:
+ timestamp_column: created_at# Check if specified correctly
+```
+
+### Common causes:
+
+- Incorrect timestamp column name
+- Timestamp column contains null values or is not of type timestamp or date
+- For non-timestamp tests: Test hasn't run successfully
+- Incorrect test syntax
+
+
+
+
+If you change it after executing elementary tests, you will need to run a full refresh to the metrics collected. This will make the next tests collect data for the new **`training_period`** timeframe. The steps are:
+
+1. Change var **`training_period`** in your **`dbt_project.yml`**.
+2. Full refresh of the model ‘data_monitoring_metrics’ by running **`dbt run --select data_monitoring_metrics --full-refresh`**.
+3. Running the elementary tests again.
+
+If you want the Elementary UI to show data for a longer period of time, use the days-back option of the CLI: **`edr report --days-back 45`**
+
diff --git a/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx
index 613a45d2e..546ea6ebb 100644
--- a/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx
@@ -24,7 +24,7 @@ No mandatory configuration, however it is highly recommended to configure a `tim
-- elementary.all_columns_anomalies:
timestamp_column: column name
column_anomalies: column monitors list
- dimensions: list
+ dimensions: sql expression
exclude_prefix: string
exclude_regexp: regex
where_expression: sql expression
diff --git a/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx
index e48b157fc..fd88dbab9 100644
--- a/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx
@@ -22,7 +22,7 @@ No mandatory configuration, however it is highly recommended to configure a `tim
tests:
-- elementary.column_anomalies:
column_anomalies: column monitors list
- dimensions: list
+ dimensions: sql expression
timestamp_column: column name
where_expression: sql expression
anomaly_sensitivity: int
diff --git a/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
index fffea01c1..b564514fc 100644
--- a/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
@@ -24,7 +24,7 @@ No mandatory configuration, however it is highly recommended to configure a `tim
tests:
- -- elementary.volume_anomalies:
+ - elementary.volume_anomalies:
timestamp_column: column name
where_expression: sql expression
anomaly_sensitivity: int
diff --git a/docs/data-tests/how-anomaly-detection-works.mdx b/docs/data-tests/how-anomaly-detection-works.mdx
index 4a2817968..f2c2663f1 100644
--- a/docs/data-tests/how-anomaly-detection-works.mdx
+++ b/docs/data-tests/how-anomaly-detection-works.mdx
@@ -54,7 +54,7 @@ If a value in the detection set is an outlier to the expected range, it will be
### Expected range
Based of the values in the training test, we calculate an expected range for the monitor.
-Each data point in the detection period will be compared to the expected range calculated based on it’s training set.
+Each data point in the detection period will be compared to the expected range calculated based on its training set.
### Training period
diff --git a/docs/data-tests/introduction.mdx b/docs/data-tests/introduction.mdx
index 1f28c4238..91235c521 100644
--- a/docs/data-tests/introduction.mdx
+++ b/docs/data-tests/introduction.mdx
@@ -3,12 +3,23 @@ title: "Elementary Data Tests"
sidebarTitle: "Introduction"
---
-Elementary provides tests for detection of data quality issues.
+Elementary provides anomaly tests for detection of data quality issues.
Elementary data tests are configured and executed like native tests in your dbt project.
Elementary tests can be used in addition to dbt tests, packages tests (such as dbt-expectations), and custom tests.
All of these test results will be presented in the Elementary UI and alerts.
+The Elementary dbt package offers two test types:
+
+- **Pipeline tests:** Monitor the health of data pipelines, ensuring timely and smooth data ingestion, transformation, and loading.
+- **Data quality tests:** Validate data accuracy, completeness, and correctness, detect anomalies and schema changes, and ensure the data meets predefined business rules.
+
+Together, these tests ensure reliable pipelines and trusted data.
+
+In addition to the previously mentioned tests, the [Elementary Cloud Platform](https://docs.elementary-data.com/cloud/introduction) offers **automated pipeline tests.** While traditional tests query the dbt tables directly, automated pipeline tests analyze **query history metadata**. This method is both **faster and more cost-efficient**, as it eliminates the need to query large datasets, focusing solely on the metadata layer.
+
+Elementary automatically creates monitors for every model and source in your dbt project once you set up your environment, no configuration is required. Learn more about [automated tests](https://docs.elementary-data.com/features/anomaly-detection/automated-monitors).
+
## Anomaly detection tests
@@ -41,7 +52,7 @@ Tests to detect anomalies in data quality metrics such as volume, freshness, nul
title="Event freshness anomalies"
href="/data-tests/anomaly-detection-tests/event-freshness-anomalies"
>
- Monitors the gap between the latest event timestamp and it's loading time, to
+ Monitors the gap between the latest event timestamp and its loading time, to
detect event freshness issues.
 \ No newline at end of file
diff --git a/docs/_snippets/cloud/features/anomaly-detection/volume-configuration.mdx b/docs/_snippets/cloud/features/anomaly-detection/volume-configuration.mdx
new file mode 100644
index 000000000..13729e492
--- /dev/null
+++ b/docs/_snippets/cloud/features/anomaly-detection/volume-configuration.mdx
@@ -0,0 +1,3 @@
+- **Anomaly Direction** - Whether you want the monitor to fail on anomalous drops, spikes, or both. Default is both.
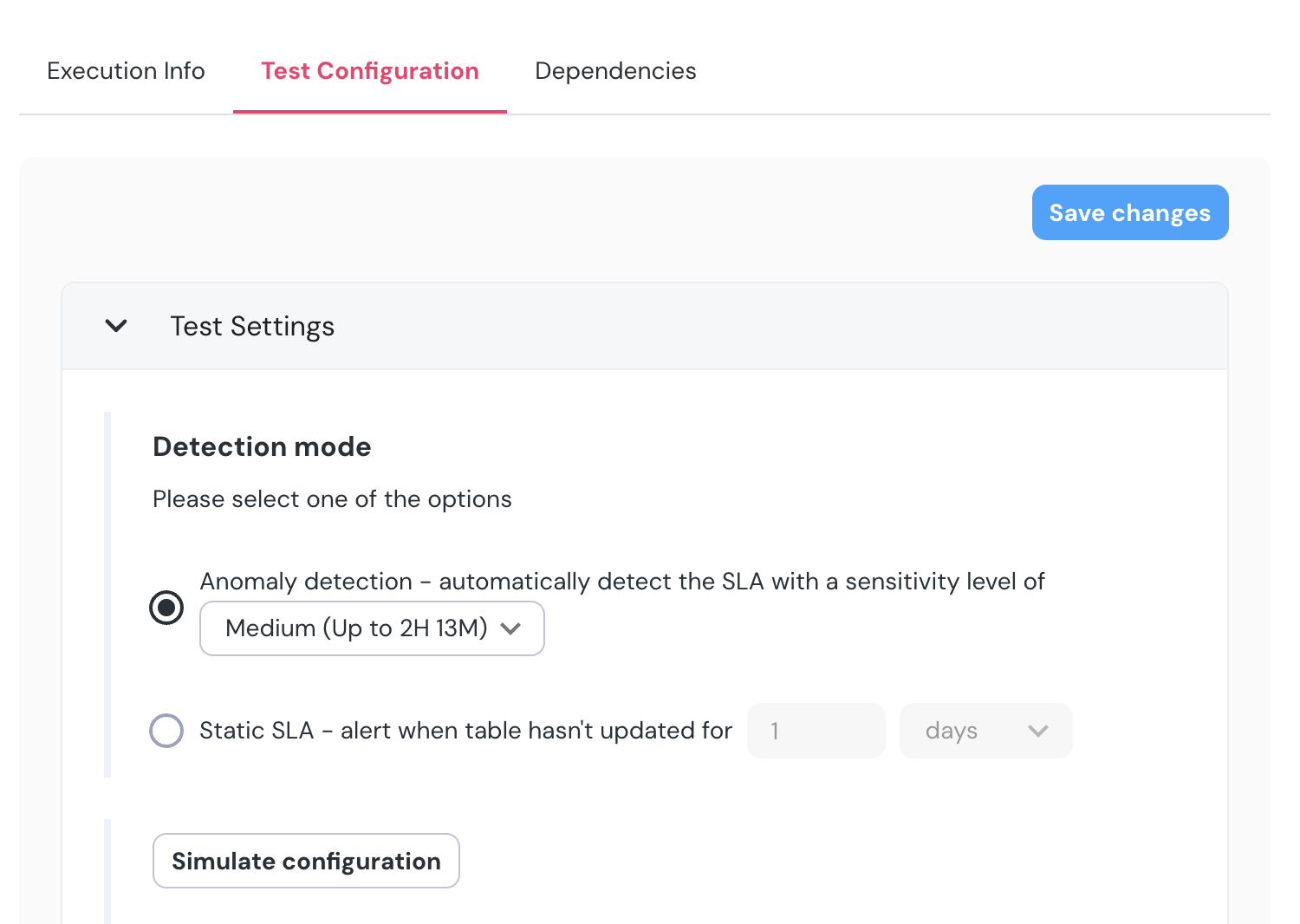
+- **Sensitivity** - You can set the monitor's sensitivity levels to *Low*, *Medium*, or *High*. In the future, we plan to allow for more nuanced adjustments to this parameter. You can use the `Simulate Configuration` button for testing how the change will affect the monitor.
+- **Detection Period** - The period in which the monitor look for anomalies. Default is the last 2 days.
\ No newline at end of file
diff --git a/docs/_snippets/cloud/features/data-health/data-health-intro.mdx b/docs/_snippets/cloud/features/data-health/data-health-intro.mdx
new file mode 100644
index 000000000..c68644d11
--- /dev/null
+++ b/docs/_snippets/cloud/features/data-health/data-health-intro.mdx
@@ -0,0 +1,11 @@
+Once you start sharing data with downstream consumers and stakeholders one of the most important things that you want to create is trust.
+Trust that the data that is being used is “healthy”. Imagine being a data analyst using a specific data asset but you constantly run into data quality issues.
+You will eventually lose trust.
+
+This is why we created **data health scores** in Elementary. It is a way to share an overview of the health of your data assets.
+
+To measure health we use an industry standard framework of [Data Quality Dimensions](/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions).
+These dimensions help assess the reliability of data in various business contexts.
+Ensuring high-quality data across these dimensions is critical for accurate analysis, informed decision-making, and operational efficiency.
+
+
\ No newline at end of file
diff --git a/docs/_snippets/cloud/features/anomaly-detection/volume-configuration.mdx b/docs/_snippets/cloud/features/anomaly-detection/volume-configuration.mdx
new file mode 100644
index 000000000..13729e492
--- /dev/null
+++ b/docs/_snippets/cloud/features/anomaly-detection/volume-configuration.mdx
@@ -0,0 +1,3 @@
+- **Anomaly Direction** - Whether you want the monitor to fail on anomalous drops, spikes, or both. Default is both.
+- **Sensitivity** - You can set the monitor's sensitivity levels to *Low*, *Medium*, or *High*. In the future, we plan to allow for more nuanced adjustments to this parameter. You can use the `Simulate Configuration` button for testing how the change will affect the monitor.
+- **Detection Period** - The period in which the monitor look for anomalies. Default is the last 2 days.
\ No newline at end of file
diff --git a/docs/_snippets/cloud/features/data-health/data-health-intro.mdx b/docs/_snippets/cloud/features/data-health/data-health-intro.mdx
new file mode 100644
index 000000000..c68644d11
--- /dev/null
+++ b/docs/_snippets/cloud/features/data-health/data-health-intro.mdx
@@ -0,0 +1,11 @@
+Once you start sharing data with downstream consumers and stakeholders one of the most important things that you want to create is trust.
+Trust that the data that is being used is “healthy”. Imagine being a data analyst using a specific data asset but you constantly run into data quality issues.
+You will eventually lose trust.
+
+This is why we created **data health scores** in Elementary. It is a way to share an overview of the health of your data assets.
+
+To measure health we use an industry standard framework of [Data Quality Dimensions](/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions).
+These dimensions help assess the reliability of data in various business contexts.
+Ensuring high-quality data across these dimensions is critical for accurate analysis, informed decision-making, and operational efficiency.
+
+ +
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
index bf9a777ac..25f4577ce 100644
--- a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
+++ b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
@@ -51,6 +51,14 @@
}
>
+
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
index bf9a777ac..25f4577ce 100644
--- a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
+++ b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
@@ -51,6 +51,14 @@
}
> +
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/snowflake.mdx b/docs/_snippets/cloud/integrations/snowflake.mdx
index 6eb762ada..6a2ba656b 100644
--- a/docs/_snippets/cloud/integrations/snowflake.mdx
+++ b/docs/_snippets/cloud/integrations/snowflake.mdx
@@ -12,7 +12,7 @@ Provide the following fields:
- **Elementary schema**: The name of your Elementary schema. Usually `[schema name]_elementary`.
- **Role (optional)**: e.g. `ELEMENTARY_ROLE`.
-Elementary cloud supports the user password and key pair authentication connection methods.
+Elementary Cloud supports the user password and key pair authentication connection methods.
- **User password**:
- User: The user created for Elementary.
diff --git a/docs/_snippets/faq/question-disable-elementary-models.mdx b/docs/_snippets/faq/question-disable-elementary-models.mdx
index 407e3ee2d..22bfe4276 100644
--- a/docs/_snippets/faq/question-disable-elementary-models.mdx
+++ b/docs/_snippets/faq/question-disable-elementary-models.mdx
@@ -1,6 +1,6 @@
+
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/snowflake.mdx b/docs/_snippets/cloud/integrations/snowflake.mdx
index 6eb762ada..6a2ba656b 100644
--- a/docs/_snippets/cloud/integrations/snowflake.mdx
+++ b/docs/_snippets/cloud/integrations/snowflake.mdx
@@ -12,7 +12,7 @@ Provide the following fields:
- **Elementary schema**: The name of your Elementary schema. Usually `[schema name]_elementary`.
- **Role (optional)**: e.g. `ELEMENTARY_ROLE`.
-Elementary cloud supports the user password and key pair authentication connection methods.
+Elementary Cloud supports the user password and key pair authentication connection methods.
- **User password**:
- User: The user created for Elementary.
diff --git a/docs/_snippets/faq/question-disable-elementary-models.mdx b/docs/_snippets/faq/question-disable-elementary-models.mdx
index 407e3ee2d..22bfe4276 100644
--- a/docs/_snippets/faq/question-disable-elementary-models.mdx
+++ b/docs/_snippets/faq/question-disable-elementary-models.mdx
@@ -1,6 +1,6 @@
 -
-
-### Supported adapters
-
-
-
-
-### Supported adapters
-
- @@ -26,7 +25,6 @@
@@ -26,7 +25,6 @@
 diff --git a/docs/_snippets/setup-teams-integration.mdx b/docs/_snippets/setup-teams-integration.mdx
index 9780e3c97..dd9aa0a70 100644
--- a/docs/_snippets/setup-teams-integration.mdx
+++ b/docs/_snippets/setup-teams-integration.mdx
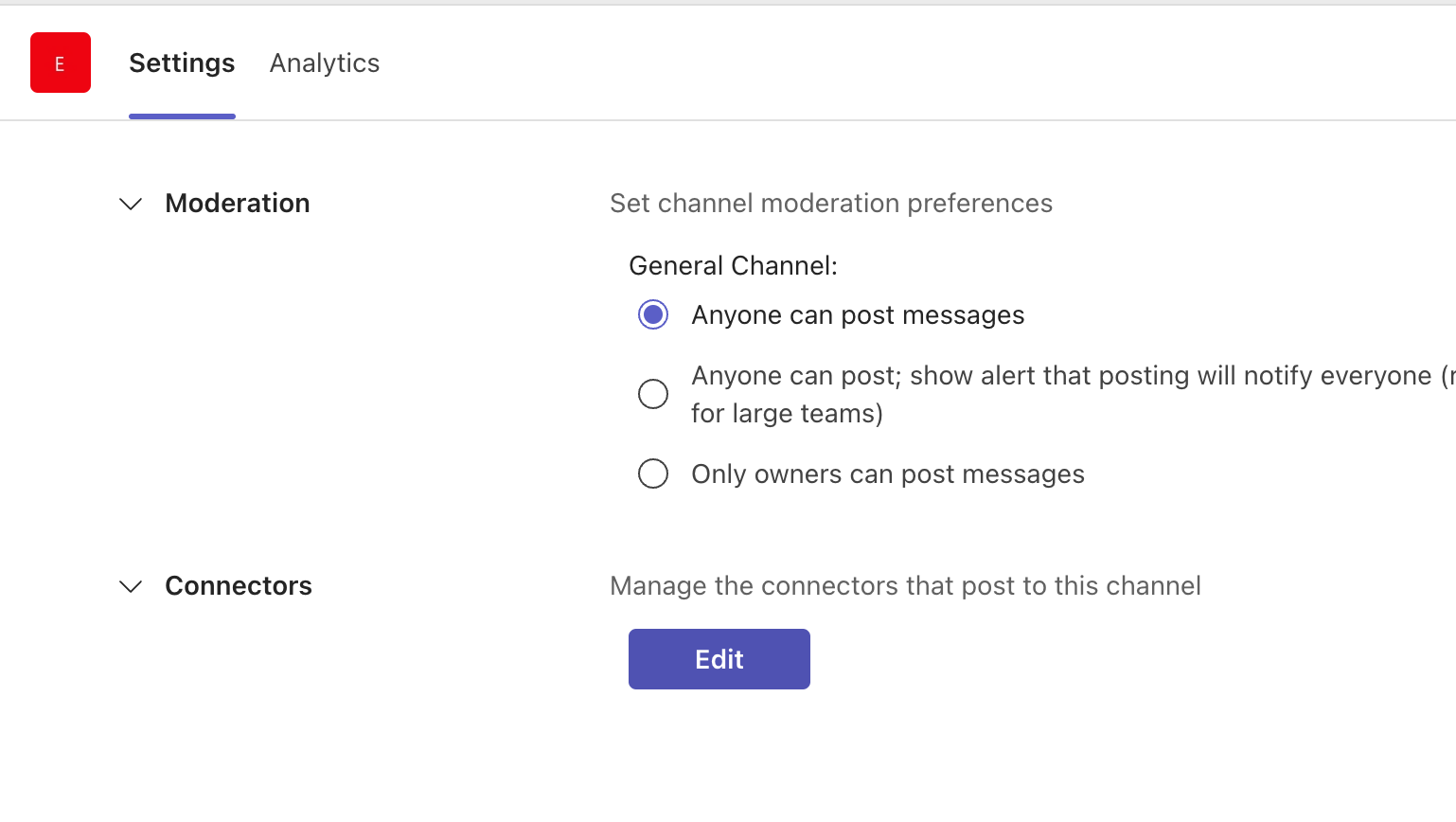
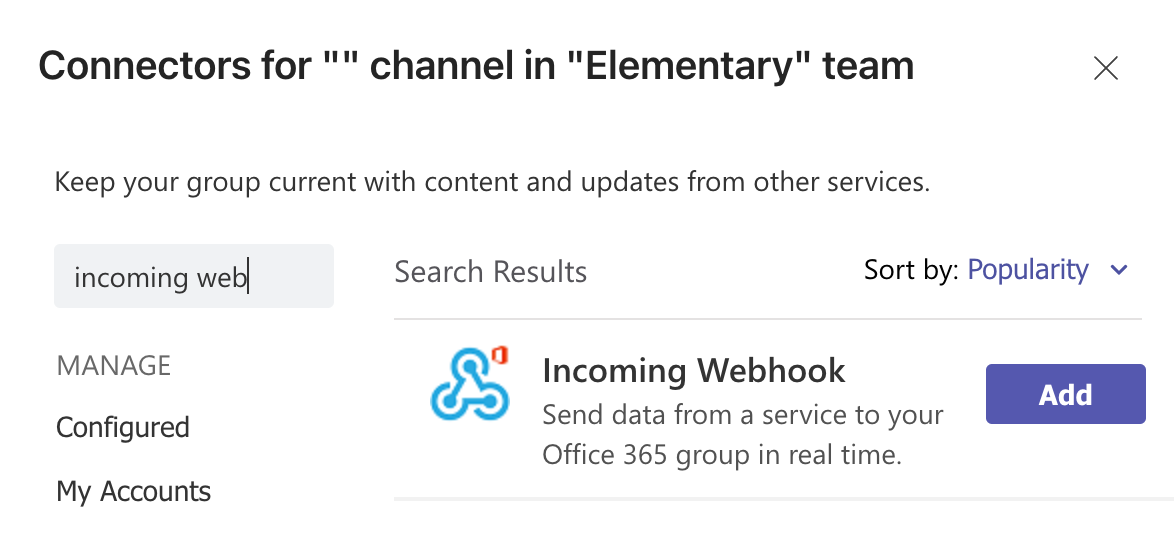
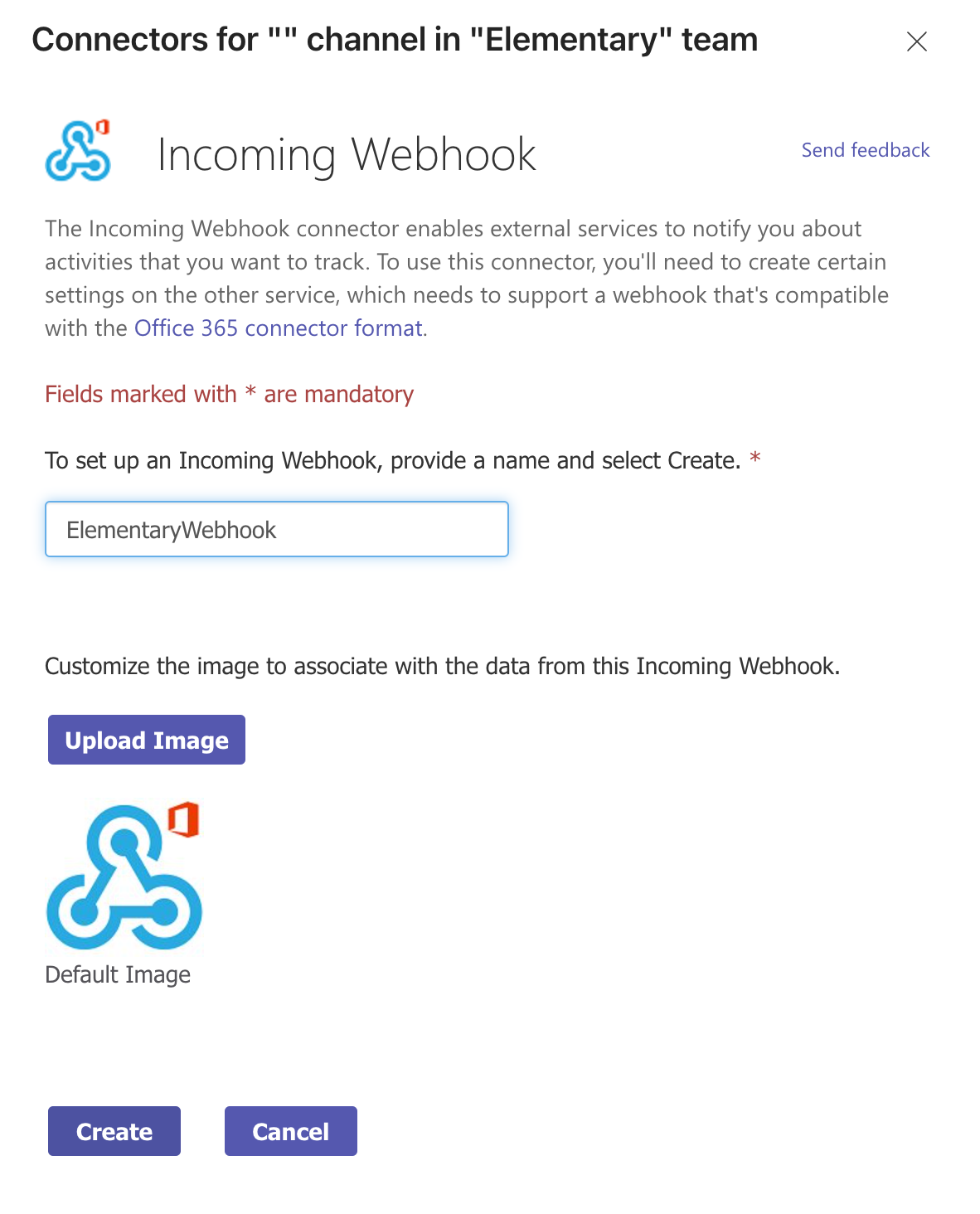
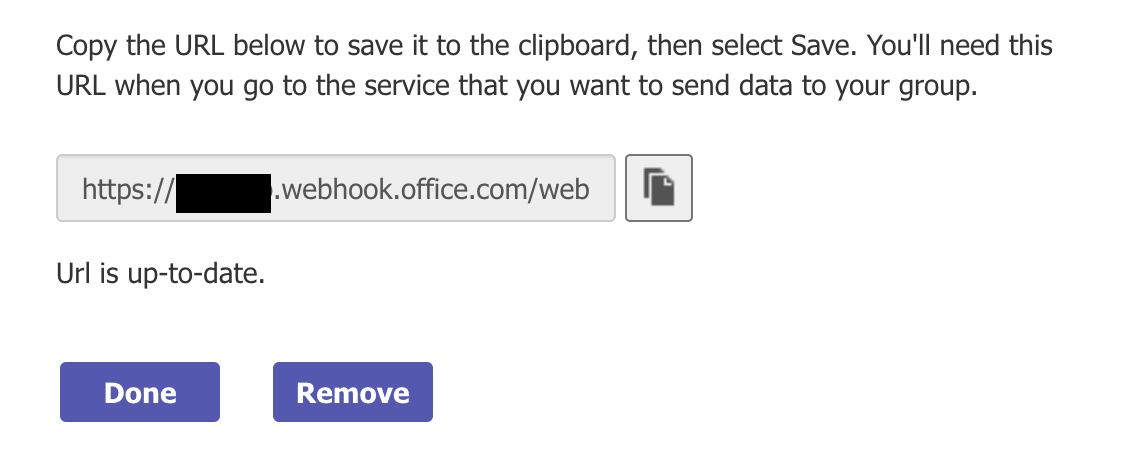
@@ -34,11 +34,13 @@ Call it `Elementary` (or whatever you prefer) and connect it to the workspace of
-Now it is time to setup the webhook for this channel.
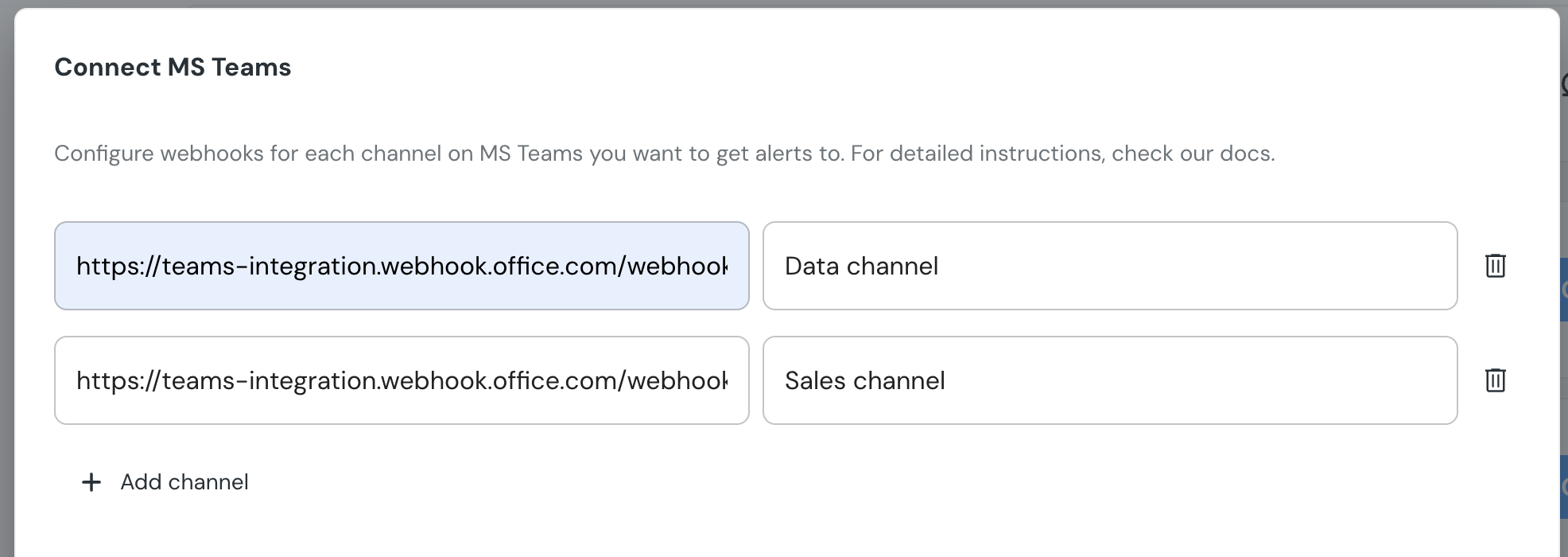
+Now it's time to set up a webhook. You have two options for creating a webhook:
-
diff --git a/docs/_snippets/setup-teams-integration.mdx b/docs/_snippets/setup-teams-integration.mdx
index 9780e3c97..dd9aa0a70 100644
--- a/docs/_snippets/setup-teams-integration.mdx
+++ b/docs/_snippets/setup-teams-integration.mdx
@@ -34,11 +34,13 @@ Call it `Elementary` (or whatever you prefer) and connect it to the workspace of
-Now it is time to setup the webhook for this channel.
+Now it's time to set up a webhook. You have two options for creating a webhook:
- +
+
+## Custom SQL tests in UI
+
+
+
+
+## Custom SQL tests in UI
+
+ +
+
+## Model runs in dashboard
+
+
+
+
+## Model runs in dashboard
+
+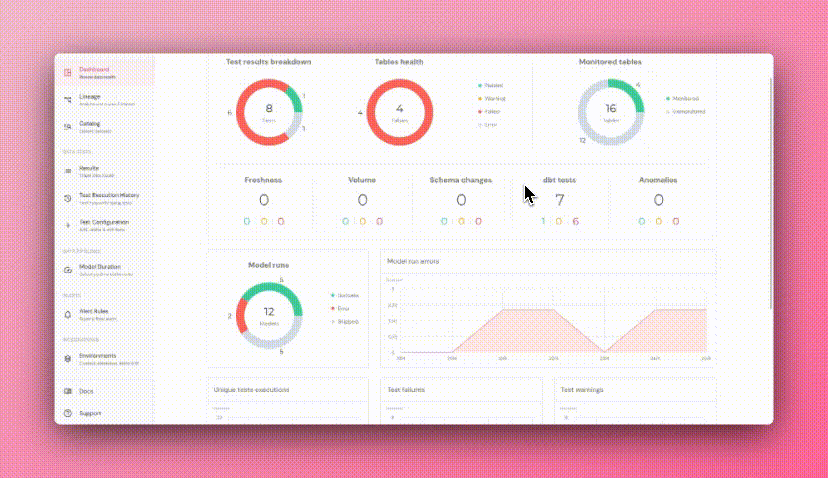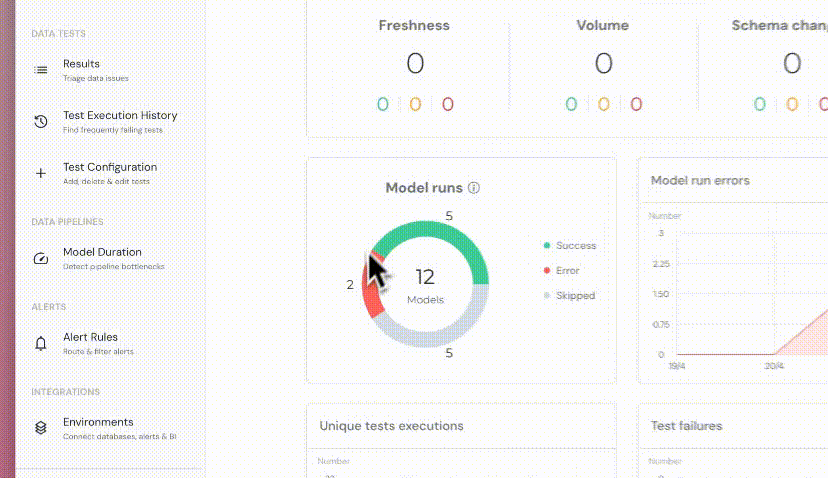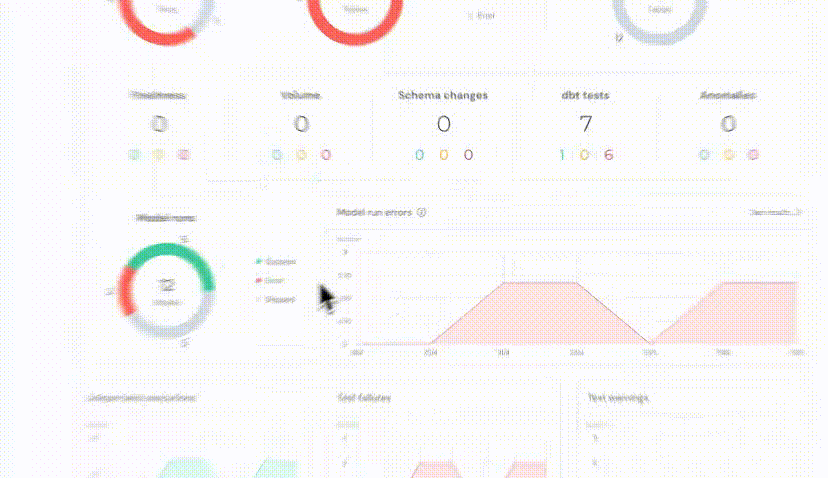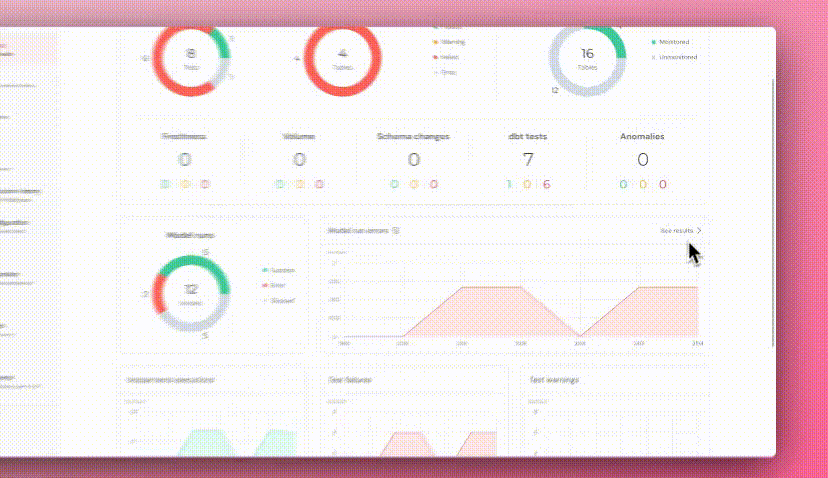 +
+
+## DAG subset in Lineage
+
+
+
+
+## DAG subset in Lineage
+
+ +
+
+## Role-based access control
+
+
+
+
+## Role-based access control
+
+ +
diff --git a/docs/cloud/features.mdx b/docs/cloud/features.mdx
new file mode 100644
index 000000000..4a27276bb
--- /dev/null
+++ b/docs/cloud/features.mdx
@@ -0,0 +1,6 @@
+---
+title: "Platform features"
+icon: "browsers"
+---
+
+
+
diff --git a/docs/cloud/features.mdx b/docs/cloud/features.mdx
new file mode 100644
index 000000000..4a27276bb
--- /dev/null
+++ b/docs/cloud/features.mdx
@@ -0,0 +1,6 @@
+---
+title: "Platform features"
+icon: "browsers"
+---
+
+ -
+
-
+ -
-  -
-  -Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that would trigger a sync after your jobs are done.
+Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that will trigger a sync after your jobs are done.
-- Make sure the webhook is triggered on `Run completed` events
+- Make sure the webhook is triggered on `Run completed` events.
- Select **only** the main jobs of the relevant environment.
-Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that would trigger a sync after your jobs are done.
+Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that will trigger a sync after your jobs are done.
-- Make sure the webhook is triggered on `Run completed` events
+- Make sure the webhook is triggered on `Run completed` events.
- Select **only** the main jobs of the relevant environment.
 +
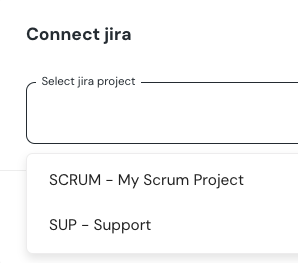
+## How to connect Jira
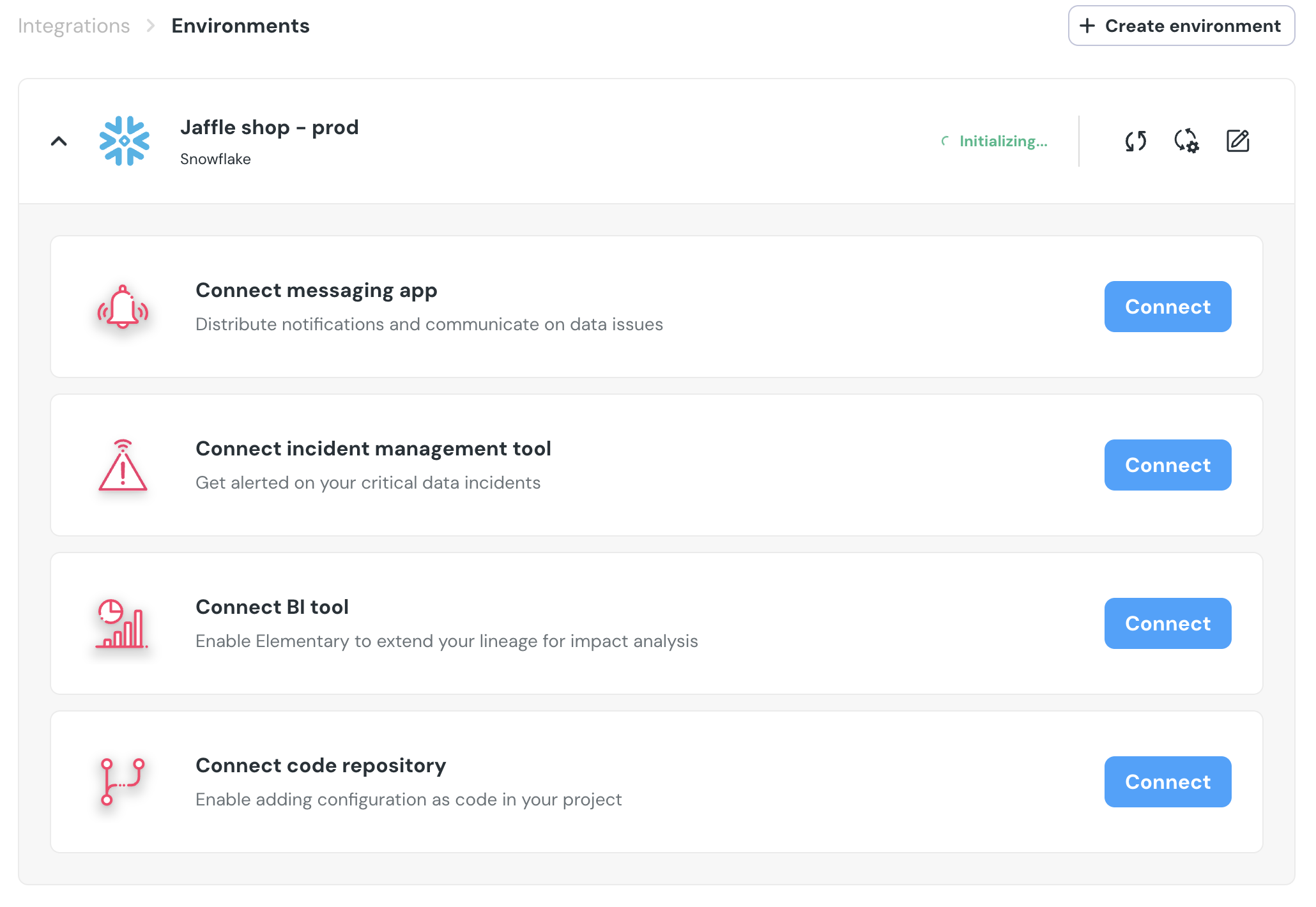
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Jira`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default project for tickets
+5. Click `Save` to finish the setup
+
+
+
+## How to connect Jira
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Jira`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default project for tickets
+5. Click `Save` to finish the setup
+
+ +
+ +
+ +
+ +
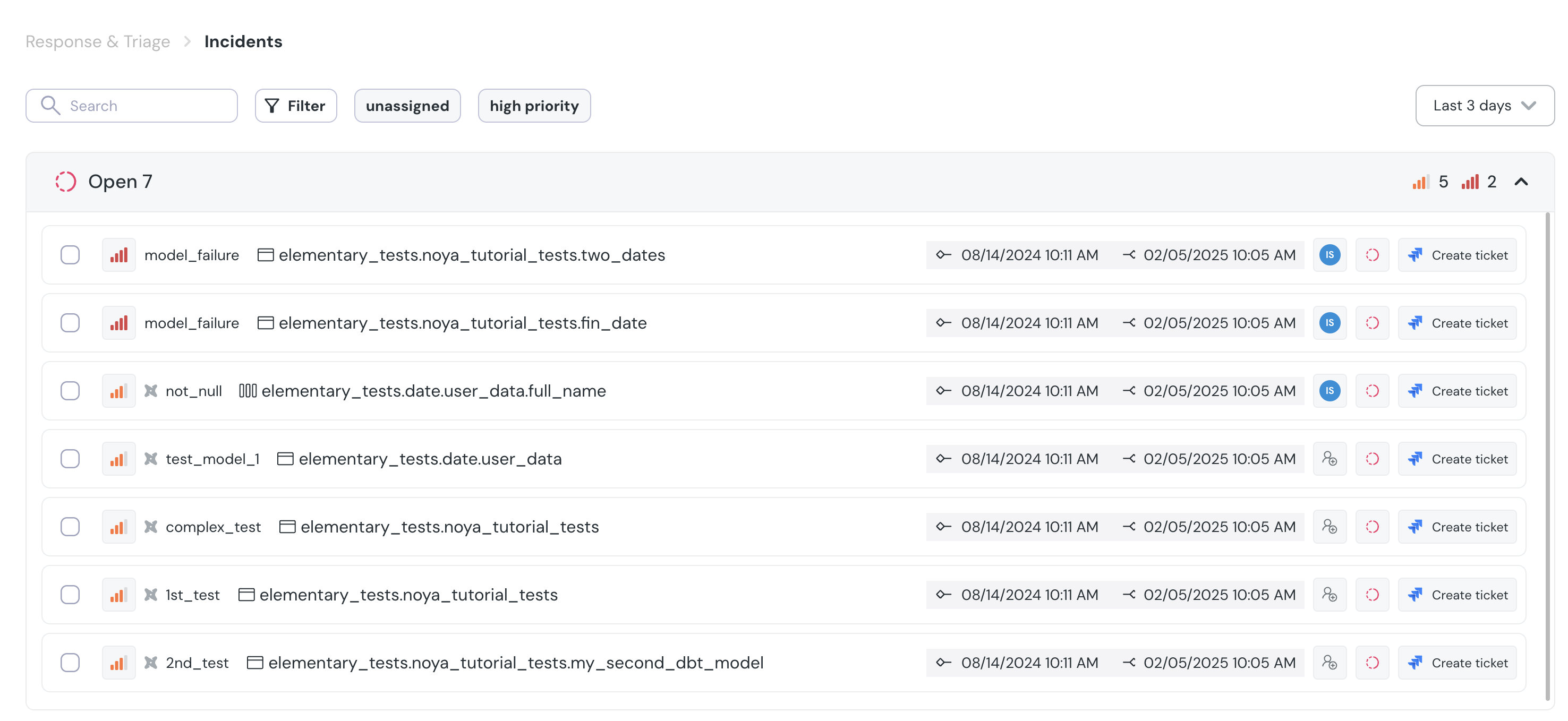
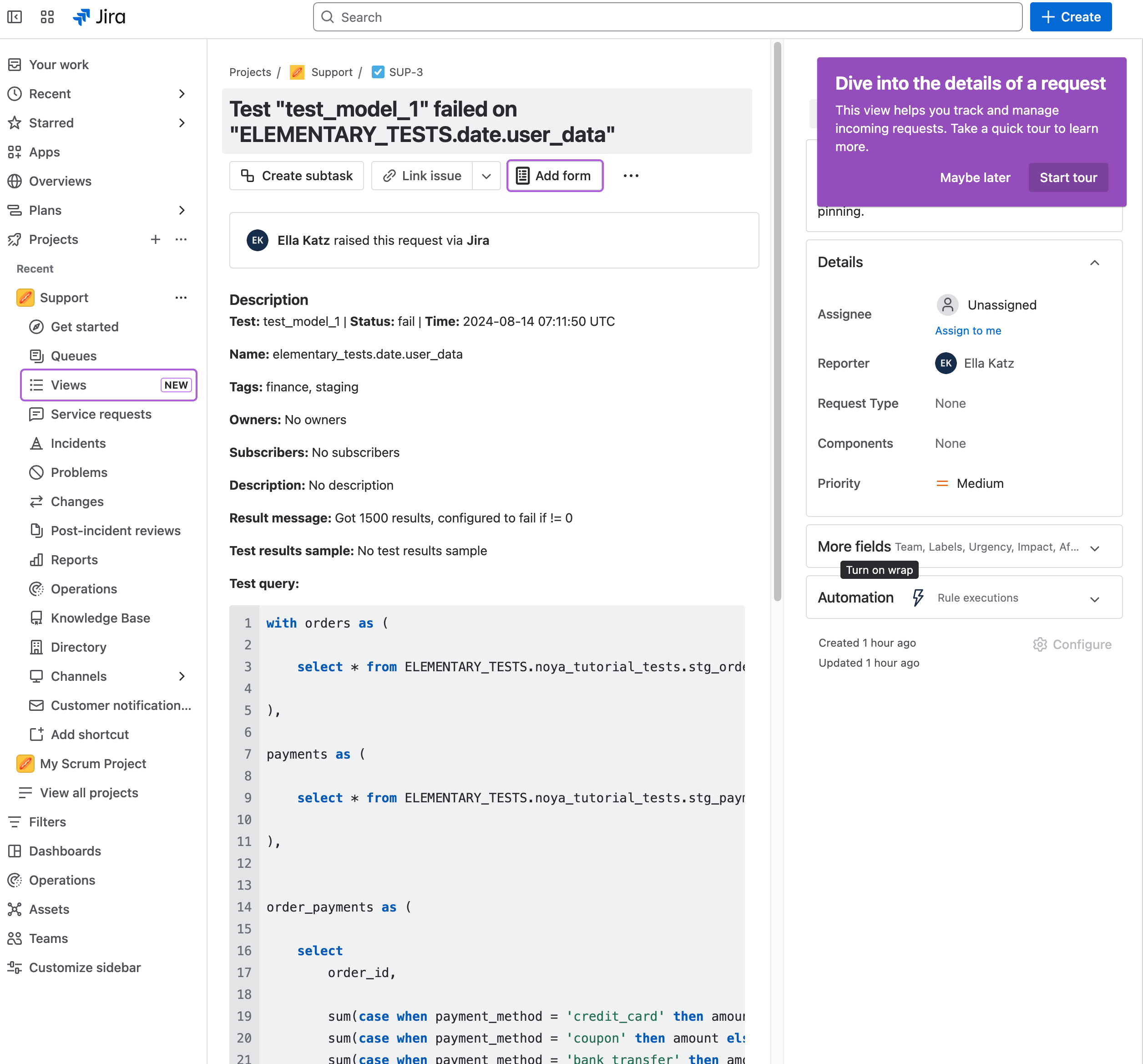
+## Creating Jira issues from incidents
+When an incident is created, you can create a Jira issue from the incident page by simply clicking on "Create Jira Ticket".
+The ticket will automatically be created in Jira, in the team you chose upon connecting Jira.
+
+After the ticket is created you can see the Jira issue link in the incident page.
+The ticket will also contain a link to the incident in Elementary.
+
+
+
+
+## Creating Jira issues from incidents
+When an incident is created, you can create a Jira issue from the incident page by simply clicking on "Create Jira Ticket".
+The ticket will automatically be created in Jira, in the team you chose upon connecting Jira.
+
+After the ticket is created you can see the Jira issue link in the incident page.
+The ticket will also contain a link to the incident in Elementary.
+
+
+ \ No newline at end of file
diff --git a/docs/cloud/integrations/alerts/linear.mdx b/docs/cloud/integrations/alerts/linear.mdx
index 5837a8c8a..ddd19c653 100644
--- a/docs/cloud/integrations/alerts/linear.mdx
+++ b/docs/cloud/integrations/alerts/linear.mdx
@@ -2,14 +2,30 @@
title: "Linear"
---
-
\ No newline at end of file
diff --git a/docs/cloud/integrations/alerts/linear.mdx b/docs/cloud/integrations/alerts/linear.mdx
index 5837a8c8a..ddd19c653 100644
--- a/docs/cloud/integrations/alerts/linear.mdx
+++ b/docs/cloud/integrations/alerts/linear.mdx
@@ -2,14 +2,30 @@
title: "Linear"
---
- +
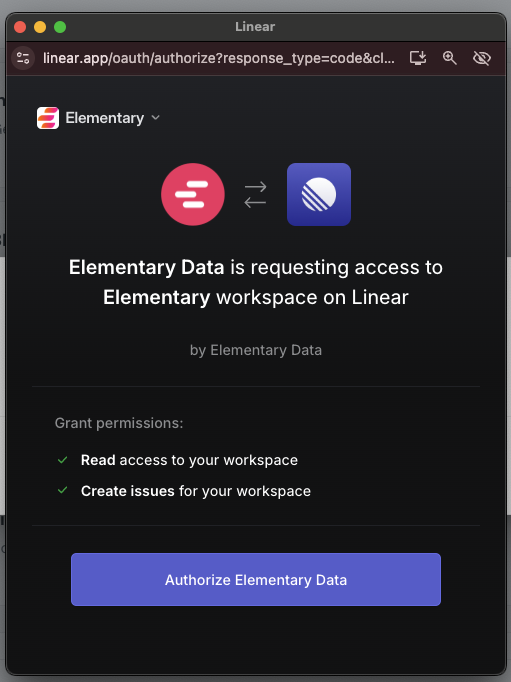
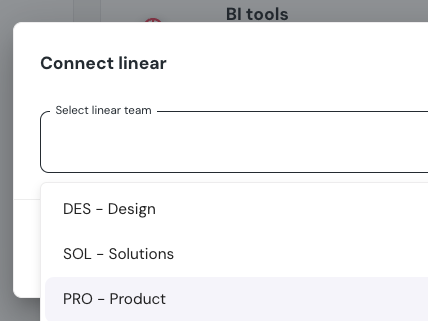
+## How to connect Linear
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Linear`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default team for new tickets
+5. Click `Save` to finish the setup
+
+
+
+## How to connect Linear
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Linear`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default team for new tickets
+5. Click `Save` to finish the setup
+
+ +
+ +
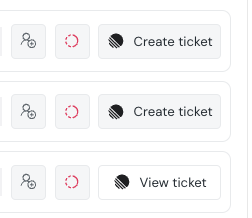
+## Creating Linear ticket from incidents
+When an incident is created, you can create a Linear ticket from the incident page by simply clicking on "Create Linear Ticket".
+The ticket will automatically be created in Linear, in the team you chose upon connecting Linear.
+
+After the ticket is created you can see the Linear ticket link in the incident page.
+The ticket will also contain a link to the incident in Elementary.
+
+
+## Creating Linear ticket from incidents
+When an incident is created, you can create a Linear ticket from the incident page by simply clicking on "Create Linear Ticket".
+The ticket will automatically be created in Linear, in the team you chose upon connecting Linear.
+
+After the ticket is created you can see the Linear ticket link in the incident page.
+The ticket will also contain a link to the incident in Elementary.
+ +
+
+
+ \ No newline at end of file
diff --git a/docs/cloud/integrations/alerts/ms-teams.mdx b/docs/cloud/integrations/alerts/ms-teams.mdx
index 542a1dfaa..08746bded 100644
--- a/docs/cloud/integrations/alerts/ms-teams.mdx
+++ b/docs/cloud/integrations/alerts/ms-teams.mdx
@@ -1,6 +1,124 @@
---
-title: "MS Teams (Beta)"
+title: "Microsoft Teams"
---
-Routing alerts to MS Teams is supported as a beta integration.
-Reach out to us to enable it for your instance!
\ No newline at end of file
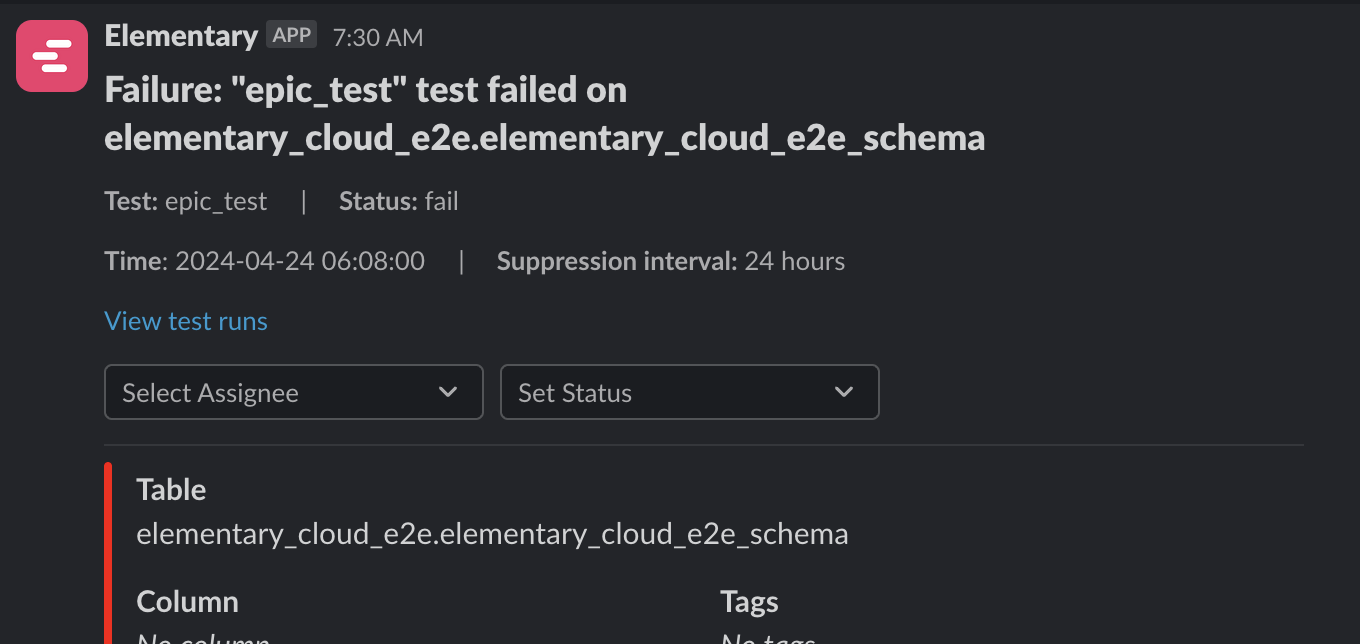
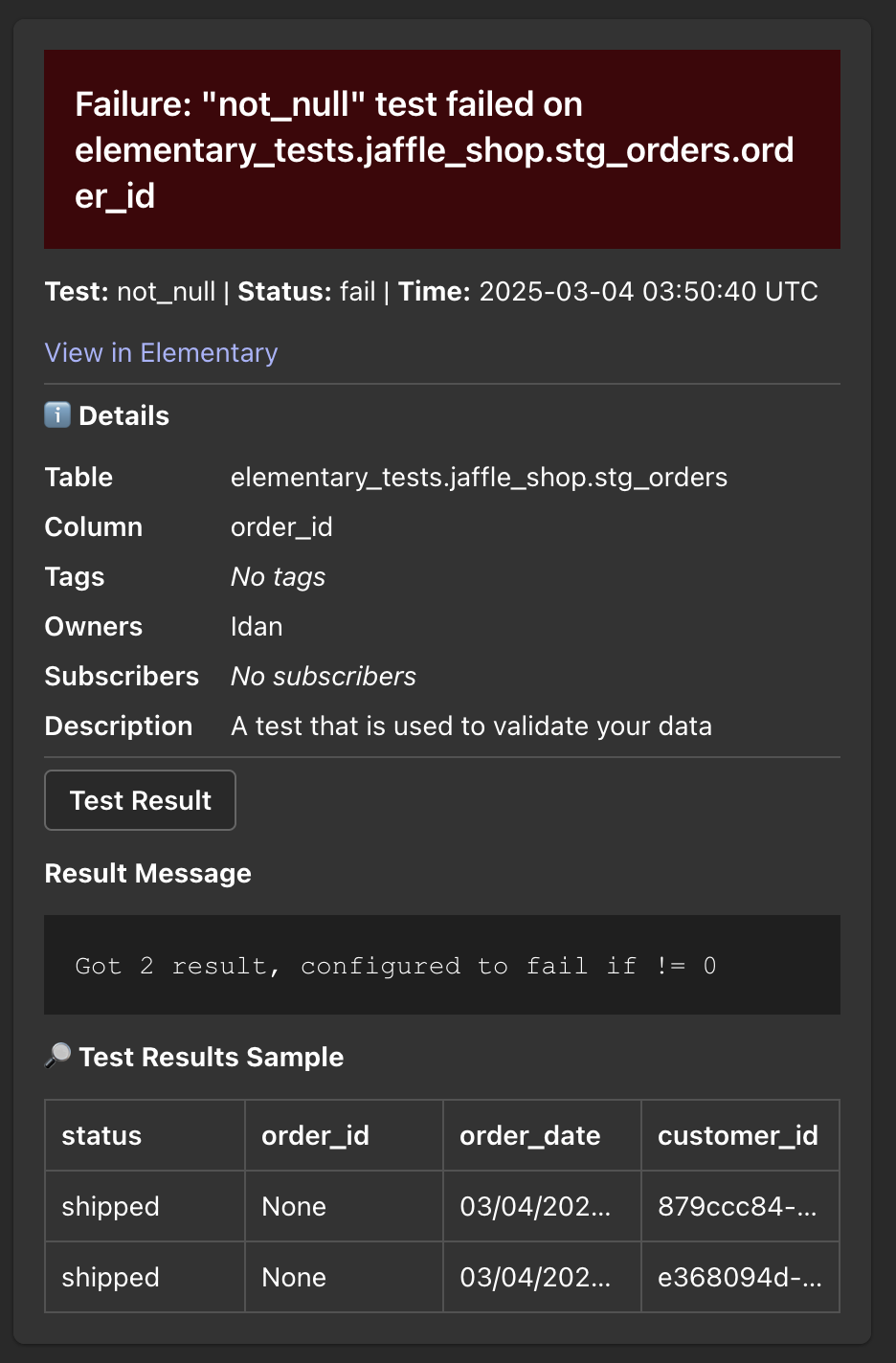
+Elementary's Microsoft Teams integration enables sending alerts when data issues happen.
+The alerts are sent using Adaptive Cards format, which provides rich formatting and interactive capabilities.
+
+The alerts include rich context, and you can create [alert rules](/features/alerts-and-incidents/alert-rules) to distribute alerts to different channels and destinations.
+
+
+
\ No newline at end of file
diff --git a/docs/cloud/integrations/alerts/ms-teams.mdx b/docs/cloud/integrations/alerts/ms-teams.mdx
index 542a1dfaa..08746bded 100644
--- a/docs/cloud/integrations/alerts/ms-teams.mdx
+++ b/docs/cloud/integrations/alerts/ms-teams.mdx
@@ -1,6 +1,124 @@
---
-title: "MS Teams (Beta)"
+title: "Microsoft Teams"
---
-Routing alerts to MS Teams is supported as a beta integration.
-Reach out to us to enable it for your instance!
\ No newline at end of file
+Elementary's Microsoft Teams integration enables sending alerts when data issues happen.
+The alerts are sent using Adaptive Cards format, which provides rich formatting and interactive capabilities.
+
+The alerts include rich context, and you can create [alert rules](/features/alerts-and-incidents/alert-rules) to distribute alerts to different channels and destinations.
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  -
+
-
+ -
+## Repository connection settings
+
+
-
+## Repository connection settings
+
+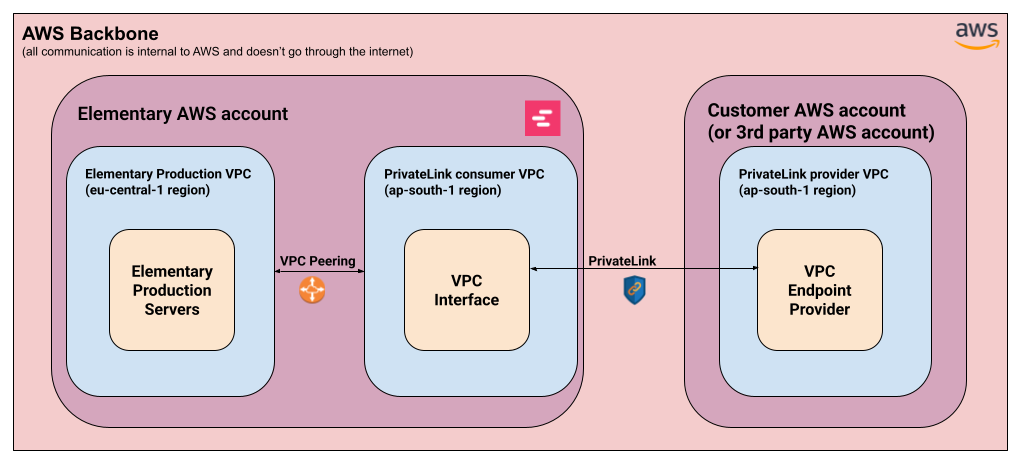 +
+Elementary’s PrivateLink setup consists generally from two parts:
+
+1. **AWS PrivateLink connection** -
+ 1. Provider side (Customer / 3rd party) - **A VPC endpoint service** is set up at the customer’s AWS account (or a 3rd party AWS account in the case of Snowflake). This provides access to a particular service in that account.
+ 2. Consumer side (Elementary) - Elementary sets up a dedicated VPC interface that will connect to the integrated service, in the same AWS region as the service.
+ This is done through a dedicated regional VPC created for this purpose.
+2. **AWS VPC Peering:**
+ 1. Elementary’s production servers are located in the **eu-central-1** (Frankfurt) region. For us to be able to access the service exposed through PrivateLink, we connect our main production VPC with the regional VPC mentioned above.
+
+## Supported integrations
+
+### Snowflake
+
+Snowflake has support for connecting to AWS-hosted Snowflake accounts via PrivateLink. This setup is entirely managed by Snowflake, so Elementary connects with an endpoint service hosted on Snowflake’s AWS account for this purpose.
+
+In order to set up a PrivateLink connection with Snowflake, please follow the steps below:
+
+1. **Open a support case to Snowflake Support**
+ 1. Ask to authorize Elementary’s AWS account for PrivateLink access.
+ 2. Provide Elementary’s account ID in the request - `743289191656`
+2. **Obtain the PrivateLink configuration**
+ 1. Once Snowflake’s support team approves the request, obtain the PrivateLink configuration by invoking the following commands (admin access is required):
+
+ ```sql
+ USE ROLE ACCOUNTADMIN;
+ SELECT SYSTEM$GET_PRIVATELINK_CONFIG();
+ ```
+
+3. **Provide Elementary with the configuration obtained in the previous step.**
+ 1. Elementary will then setup the required infrastructure to connect to Snowflake via PrivateLink.
+4. **Add a Snowflake environment in Elementary**
+ 1. Follow the instructions [here](https://docs.elementary-data.com/cloud/onboarding/connect-data-warehouse) to set up a Snowflake environment in Elementary.
+ 1. When supplying the account, use `
+
+Elementary’s PrivateLink setup consists generally from two parts:
+
+1. **AWS PrivateLink connection** -
+ 1. Provider side (Customer / 3rd party) - **A VPC endpoint service** is set up at the customer’s AWS account (or a 3rd party AWS account in the case of Snowflake). This provides access to a particular service in that account.
+ 2. Consumer side (Elementary) - Elementary sets up a dedicated VPC interface that will connect to the integrated service, in the same AWS region as the service.
+ This is done through a dedicated regional VPC created for this purpose.
+2. **AWS VPC Peering:**
+ 1. Elementary’s production servers are located in the **eu-central-1** (Frankfurt) region. For us to be able to access the service exposed through PrivateLink, we connect our main production VPC with the regional VPC mentioned above.
+
+## Supported integrations
+
+### Snowflake
+
+Snowflake has support for connecting to AWS-hosted Snowflake accounts via PrivateLink. This setup is entirely managed by Snowflake, so Elementary connects with an endpoint service hosted on Snowflake’s AWS account for this purpose.
+
+In order to set up a PrivateLink connection with Snowflake, please follow the steps below:
+
+1. **Open a support case to Snowflake Support**
+ 1. Ask to authorize Elementary’s AWS account for PrivateLink access.
+ 2. Provide Elementary’s account ID in the request - `743289191656`
+2. **Obtain the PrivateLink configuration**
+ 1. Once Snowflake’s support team approves the request, obtain the PrivateLink configuration by invoking the following commands (admin access is required):
+
+ ```sql
+ USE ROLE ACCOUNTADMIN;
+ SELECT SYSTEM$GET_PRIVATELINK_CONFIG();
+ ```
+
+3. **Provide Elementary with the configuration obtained in the previous step.**
+ 1. Elementary will then setup the required infrastructure to connect to Snowflake via PrivateLink.
+4. **Add a Snowflake environment in Elementary**
+ 1. Follow the instructions [here](https://docs.elementary-data.com/cloud/onboarding/connect-data-warehouse) to set up a Snowflake environment in Elementary.
+ 1. When supplying the account, use ` +
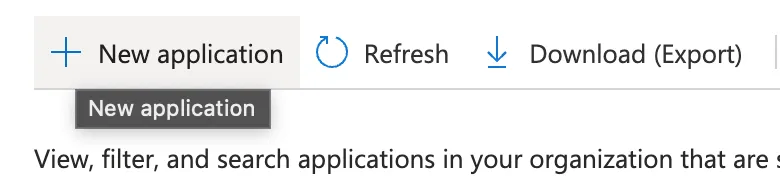
+- Click on “New Application”
+
+
+
+- Click on “New Application”
+
+ +
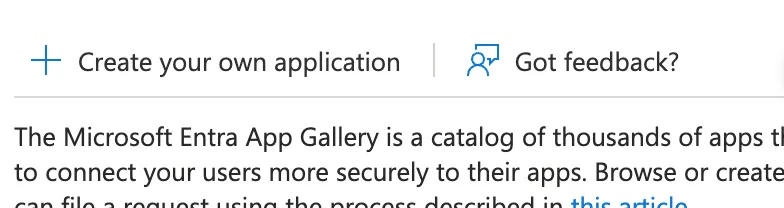
+- Click on “Create your own application”
+
+
+
+- Click on “Create your own application”
+
+ +
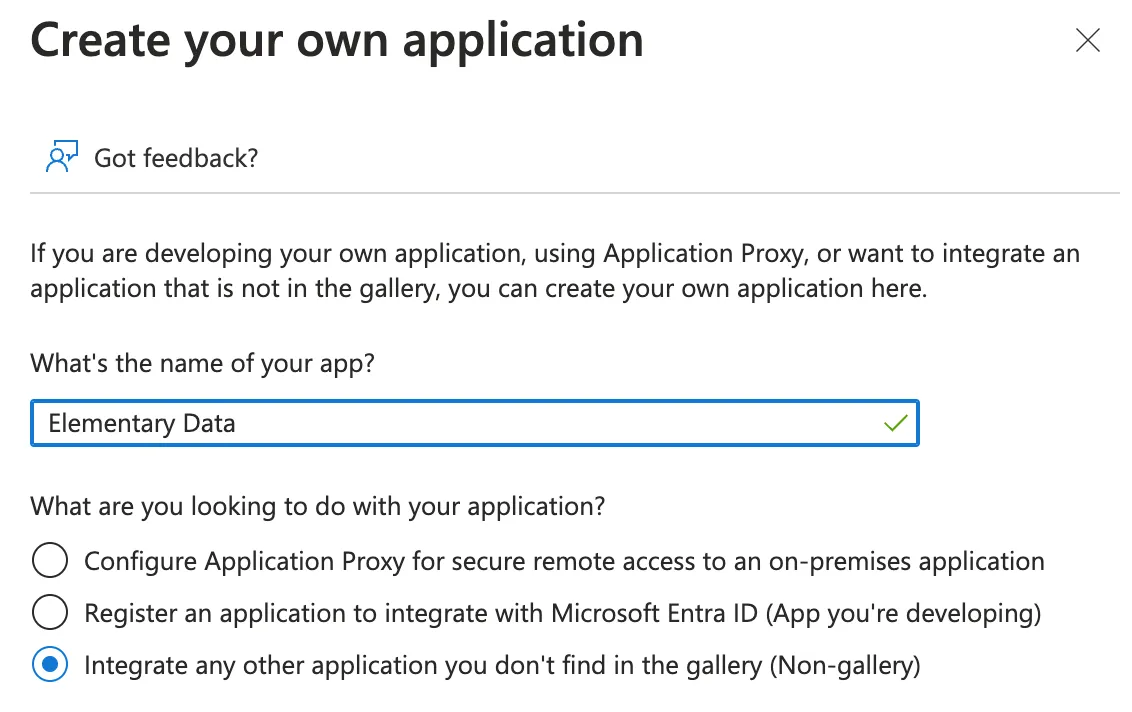
+- Choose the last option in the side-window that opens and click “Create”
+
+
+
+- Choose the last option in the side-window that opens and click “Create”
+
+ +
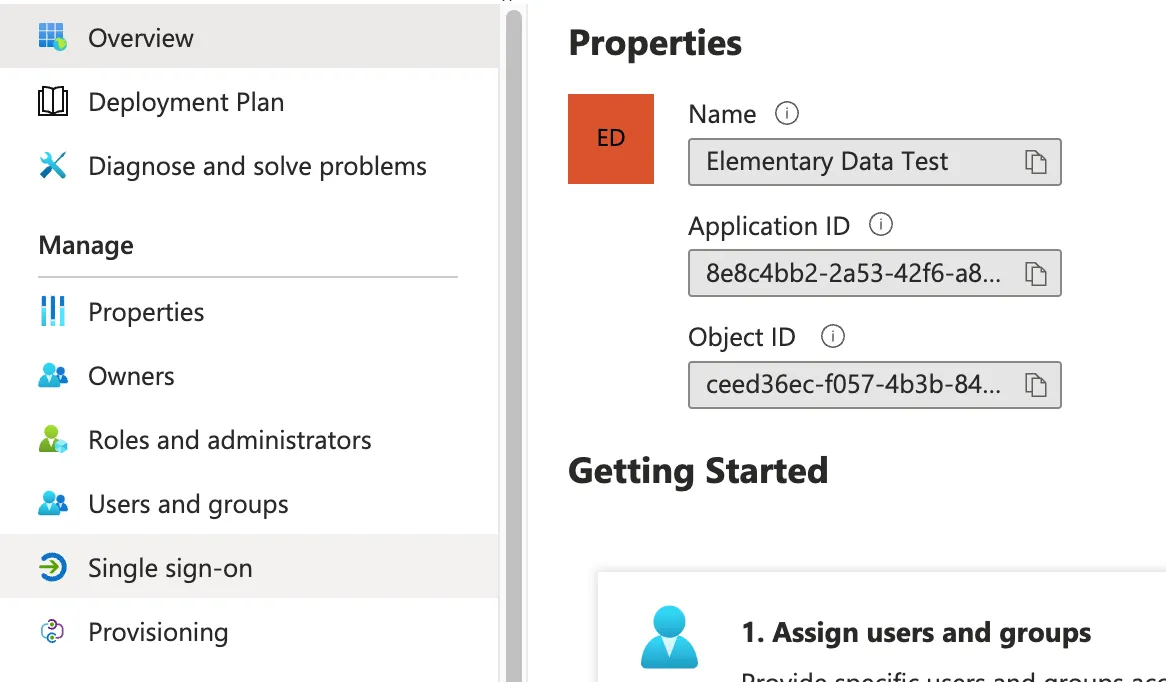
+- In the App window that opens, click on “Single Sign-On”
+
+
+
+- In the App window that opens, click on “Single Sign-On”
+
+ +
+- Choose SAML
+
+
+
+- Choose SAML
+
+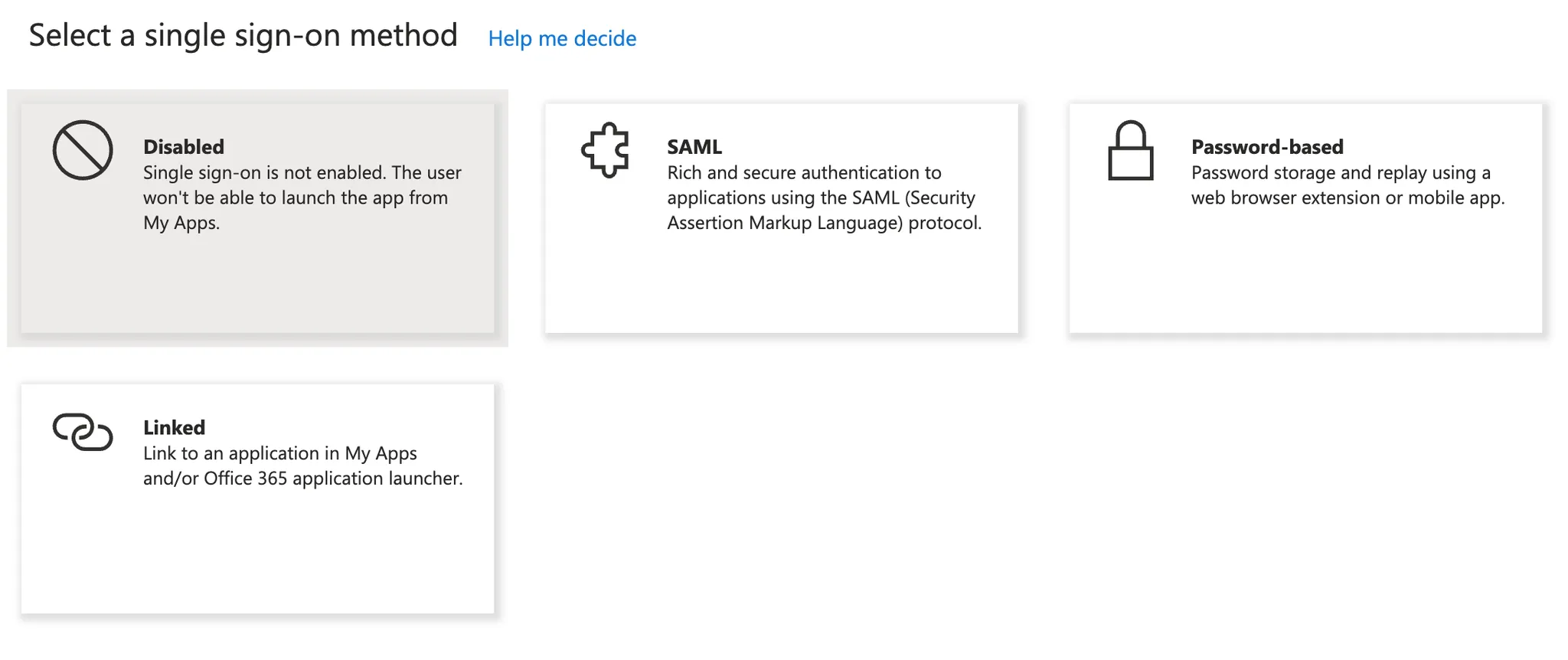 +
+- Click on Edit on the “Basic SAML Configuration” section
+
+
+
+- Click on Edit on the “Basic SAML Configuration” section
+
+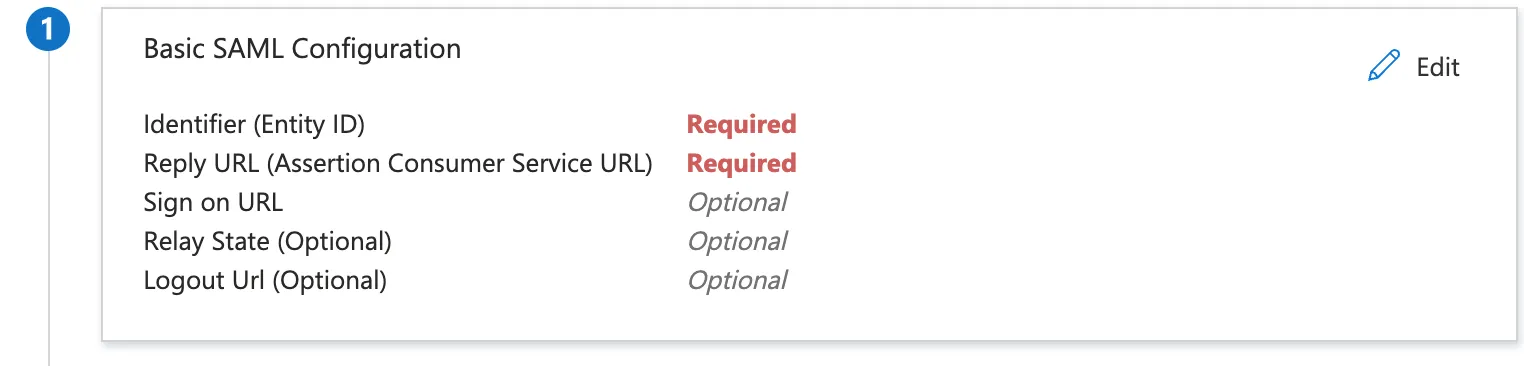 +
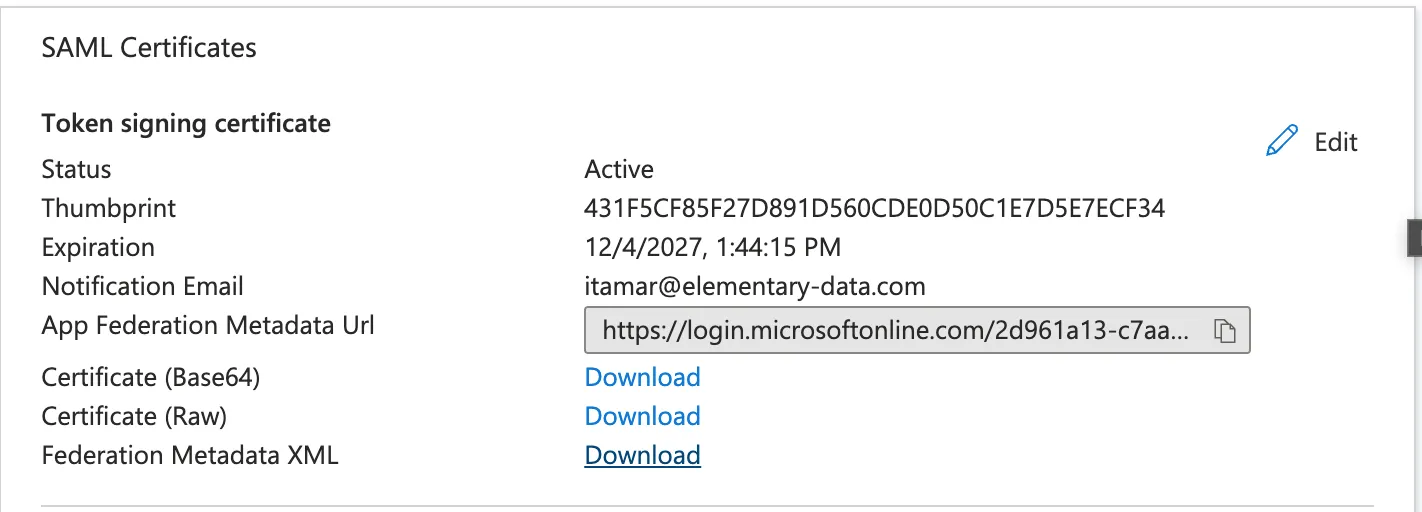
+- Fill the following entries:
+ - Identifier (Entity ID) - `elementary`
+ - Reply URL - [`https://elementary-data.frontegg.com/auth/saml/callback`](https://elementary-data.frontegg.com/auth/saml/callback)
+- Download the Federation Metadata XML and send it to the Elementary team.
+
+
+
+- Fill the following entries:
+ - Identifier (Entity ID) - `elementary`
+ - Reply URL - [`https://elementary-data.frontegg.com/auth/saml/callback`](https://elementary-data.frontegg.com/auth/saml/callback)
+- Download the Federation Metadata XML and send it to the Elementary team.
+
+ +
+- We recommend setting up a short call where we’ll validate together that the new configuration works.
+- After that, if you wish, we can disable until you update your team internally about the new configuration and update when you give us the OK!
+
+
+## Provisioning
+
+Elementary supports user provisioning via SCIM to automate user management. If you want to enable automatic provisioning, follow these steps:
+- In the **Microsoft Entra portal**, go to **Enterprise Applications** and select the newly created SAML application.
+- Navigate to **Provisioning** and click **Get Started**.
+- Set the **Provisioning Mode** to **Automatic**.
+- Configure the **Tenant URL** and **Secret Token** (email the Elementary team for a 1password vault with the configuration).
+- Click **Test Connection** to validate the setup.
+- Enable provisioning and save changes.
+
+This setup ensures that users are automatically created, updated, and deactivated in Elementary based on their status in Microsoft Entra ID. You can always reach out if you need any help.
diff --git a/docs/cloud/integrations/security-and-connectivity/okta.mdx b/docs/cloud/integrations/security-and-connectivity/okta.mdx
new file mode 100644
index 000000000..c10b5a9f2
--- /dev/null
+++ b/docs/cloud/integrations/security-and-connectivity/okta.mdx
@@ -0,0 +1,80 @@
+---
+title: "Okta"
+sidebarTitle: "Okta"
+---
+
+## Authentication & SSO Integration
+
+### Supported Authentication Protocols
+
+Elementary Cloud supports **Okta Single Sign-On (SSO)** via multiple authentication protocols:
+
+- **SAML 2.0** (Security Assertion Markup Language)
+- **OIDC (OpenID Connect)**
+
+These protocols enable seamless authentication, reducing the need for manual credential management.
+
+### SCIM for Automated Provisioning
+
+Elementary Cloud supports **SCIM (System for Cross-domain Identity Management)** for automated user provisioning and deprovisioning:
+
+- **Automated User Creation**: Users added in Okta can be provisioned automatically in Elementary Cloud.
+- **Deprovisioning Support**: When a user is removed from Okta, their access to Elementary Cloud is revoked automatically.
+- **Group-Based Provisioning**: Okta groups can be mapped to roles in Elementary Cloud by the Elementary team.
+
+For more details on SCIM setup, refer to Okta’s SCIM integration guide: [Okta SCIM Guide](https://help.okta.com/en-us/content/topics/apps/apps_app_integration_wizard_scim.htm).
+
+## Security & Access Control
+
+### Multi-Factor Authentication (MFA)
+
+Elementary Cloud does not enforce MFA directly, but any MFA policies configured through Okta will automatically apply once Okta SSO is enabled.
+
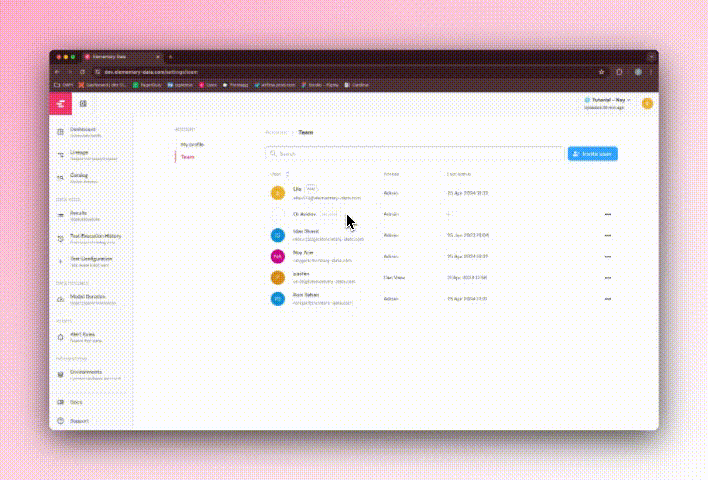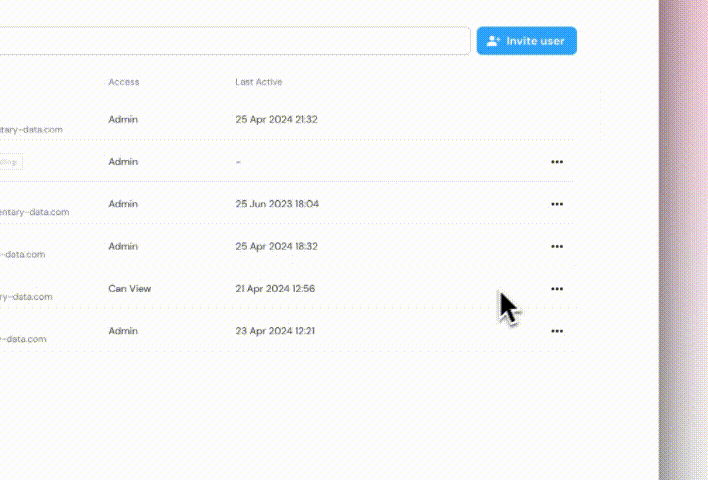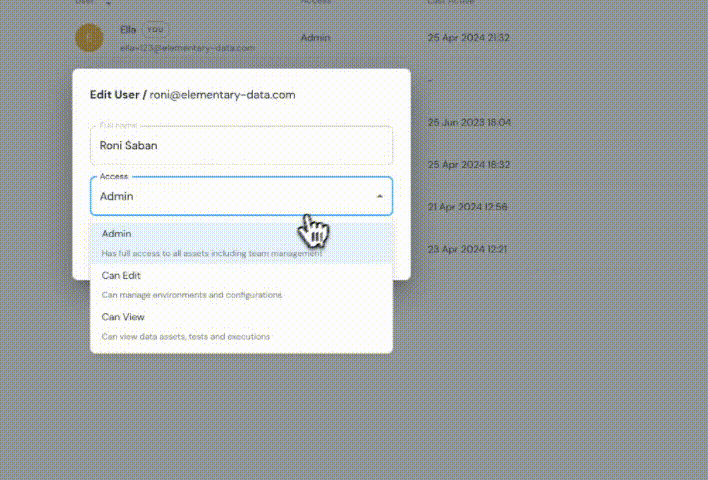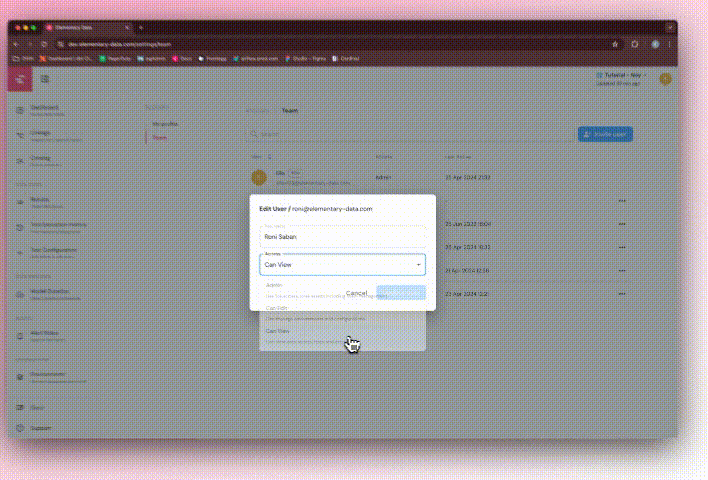
+### Role-Based Access Control (RBAC) and Group Sync
+
+- Supports **RBAC with predefined roles** (**Admin, Can Write, Can Read**).
+- **Role mappings for group names** can be pre-defined if sent in advance.
+- **Role Assignment**:
+ - The account creator will have a default **Admin** role.
+ - For provisioned users, If no configuration is made, the **default role will be Can Read**.
+ - Manually invited users will have the role defined during the invite process.
+ - **Custom roles** are currently not supported.
+
+
+
+## How to Set Up Okta SSO for Elementary Cloud
+
+### Step 1: Create a Custom App in Okta
+
+1. Navigate to **Okta Admin Dashboard** > **Applications**.
+2. Click **Create App Integration** and select **SAML 2.0**.
+3. Configure the following settings:
+ - **Single Sign-On URL**: `https://elementary-data.frontegg.com/auth/saml/callback`
+ - **Audience URI (SP Entity ID)**: `elementary`
+4. Obtain the **Okta IdP Metadata and SAML Signing Certificates** as an **XML file**.
+5. Share the **XML file** with Elementary Cloud Support to complete the integration.
+
+### Step 2: Verify Integration with Elementary Cloud
+
+- Once the XML file is shared, Elementary Cloud will complete the integration setup.
+- We recommend scheduling a **real-time verification call** to ensure everything is working before making the setting permanent.
+
+
+
+## How to Set Up SCIM for Automated Provisioning
+
+### Step 1: Configure SCIM in Okta
+
+1. Go to **Okta Admin Dashboard** > **Applications**.
+2. Locate the **Elementary Cloud app** and open it.
+3. Navigate to the **Provisioning tab** and enable **SCIM provisioning**.
+4. Enter the following details:
+ - **SCIM Provisioning URL**: *(See internal 1Password for details)*
+ - **Authorization Token**: *(See internal 1Password for details)*
+5. Save the settings and test provisioning by adding a test user.
+
+### Step 2: Define Role Mapping
+
+- By default, users are assigned the **Can Read** role.
+- The default role can be changed to **Can Write** or **Admin**.
+- Okta group names can be mapped to specific roles upon request.
\ No newline at end of file
diff --git a/docs/cloud/introduction.mdx b/docs/cloud/introduction.mdx
index 0ced5c12c..3e4a14691 100644
--- a/docs/cloud/introduction.mdx
+++ b/docs/cloud/introduction.mdx
@@ -1,20 +1,32 @@
---
-title: "Elementary Cloud"
+title: "Elementary Cloud Platform"
sidebarTitle: "Introduction"
icon: "cloud"
---
-
+
+- We recommend setting up a short call where we’ll validate together that the new configuration works.
+- After that, if you wish, we can disable until you update your team internally about the new configuration and update when you give us the OK!
+
+
+## Provisioning
+
+Elementary supports user provisioning via SCIM to automate user management. If you want to enable automatic provisioning, follow these steps:
+- In the **Microsoft Entra portal**, go to **Enterprise Applications** and select the newly created SAML application.
+- Navigate to **Provisioning** and click **Get Started**.
+- Set the **Provisioning Mode** to **Automatic**.
+- Configure the **Tenant URL** and **Secret Token** (email the Elementary team for a 1password vault with the configuration).
+- Click **Test Connection** to validate the setup.
+- Enable provisioning and save changes.
+
+This setup ensures that users are automatically created, updated, and deactivated in Elementary based on their status in Microsoft Entra ID. You can always reach out if you need any help.
diff --git a/docs/cloud/integrations/security-and-connectivity/okta.mdx b/docs/cloud/integrations/security-and-connectivity/okta.mdx
new file mode 100644
index 000000000..c10b5a9f2
--- /dev/null
+++ b/docs/cloud/integrations/security-and-connectivity/okta.mdx
@@ -0,0 +1,80 @@
+---
+title: "Okta"
+sidebarTitle: "Okta"
+---
+
+## Authentication & SSO Integration
+
+### Supported Authentication Protocols
+
+Elementary Cloud supports **Okta Single Sign-On (SSO)** via multiple authentication protocols:
+
+- **SAML 2.0** (Security Assertion Markup Language)
+- **OIDC (OpenID Connect)**
+
+These protocols enable seamless authentication, reducing the need for manual credential management.
+
+### SCIM for Automated Provisioning
+
+Elementary Cloud supports **SCIM (System for Cross-domain Identity Management)** for automated user provisioning and deprovisioning:
+
+- **Automated User Creation**: Users added in Okta can be provisioned automatically in Elementary Cloud.
+- **Deprovisioning Support**: When a user is removed from Okta, their access to Elementary Cloud is revoked automatically.
+- **Group-Based Provisioning**: Okta groups can be mapped to roles in Elementary Cloud by the Elementary team.
+
+For more details on SCIM setup, refer to Okta’s SCIM integration guide: [Okta SCIM Guide](https://help.okta.com/en-us/content/topics/apps/apps_app_integration_wizard_scim.htm).
+
+## Security & Access Control
+
+### Multi-Factor Authentication (MFA)
+
+Elementary Cloud does not enforce MFA directly, but any MFA policies configured through Okta will automatically apply once Okta SSO is enabled.
+
+### Role-Based Access Control (RBAC) and Group Sync
+
+- Supports **RBAC with predefined roles** (**Admin, Can Write, Can Read**).
+- **Role mappings for group names** can be pre-defined if sent in advance.
+- **Role Assignment**:
+ - The account creator will have a default **Admin** role.
+ - For provisioned users, If no configuration is made, the **default role will be Can Read**.
+ - Manually invited users will have the role defined during the invite process.
+ - **Custom roles** are currently not supported.
+
+
+
+## How to Set Up Okta SSO for Elementary Cloud
+
+### Step 1: Create a Custom App in Okta
+
+1. Navigate to **Okta Admin Dashboard** > **Applications**.
+2. Click **Create App Integration** and select **SAML 2.0**.
+3. Configure the following settings:
+ - **Single Sign-On URL**: `https://elementary-data.frontegg.com/auth/saml/callback`
+ - **Audience URI (SP Entity ID)**: `elementary`
+4. Obtain the **Okta IdP Metadata and SAML Signing Certificates** as an **XML file**.
+5. Share the **XML file** with Elementary Cloud Support to complete the integration.
+
+### Step 2: Verify Integration with Elementary Cloud
+
+- Once the XML file is shared, Elementary Cloud will complete the integration setup.
+- We recommend scheduling a **real-time verification call** to ensure everything is working before making the setting permanent.
+
+
+
+## How to Set Up SCIM for Automated Provisioning
+
+### Step 1: Configure SCIM in Okta
+
+1. Go to **Okta Admin Dashboard** > **Applications**.
+2. Locate the **Elementary Cloud app** and open it.
+3. Navigate to the **Provisioning tab** and enable **SCIM provisioning**.
+4. Enter the following details:
+ - **SCIM Provisioning URL**: *(See internal 1Password for details)*
+ - **Authorization Token**: *(See internal 1Password for details)*
+5. Save the settings and test provisioning by adding a test user.
+
+### Step 2: Define Role Mapping
+
+- By default, users are assigned the **Can Read** role.
+- The default role can be changed to **Can Write** or **Admin**.
+- Okta group names can be mapped to specific roles upon request.
\ No newline at end of file
diff --git a/docs/cloud/introduction.mdx b/docs/cloud/introduction.mdx
index 0ced5c12c..3e4a14691 100644
--- a/docs/cloud/introduction.mdx
+++ b/docs/cloud/introduction.mdx
@@ -1,20 +1,32 @@
---
-title: "Elementary Cloud"
+title: "Elementary Cloud Platform"
sidebarTitle: "Introduction"
icon: "cloud"
---
- +
+ +
+ +
+  +
+  +
+ 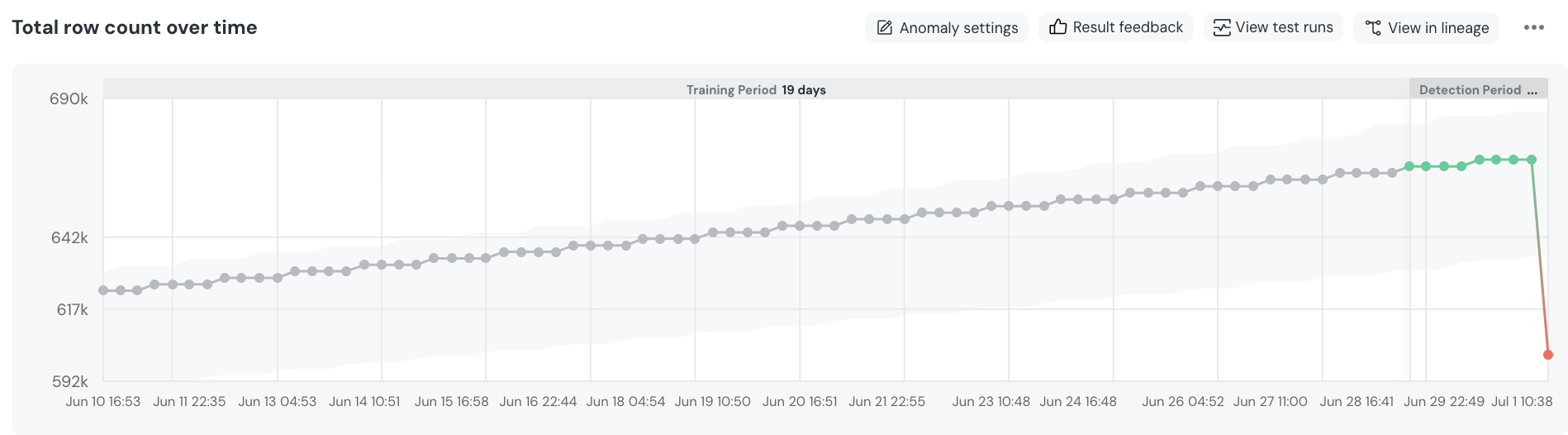 +
+ 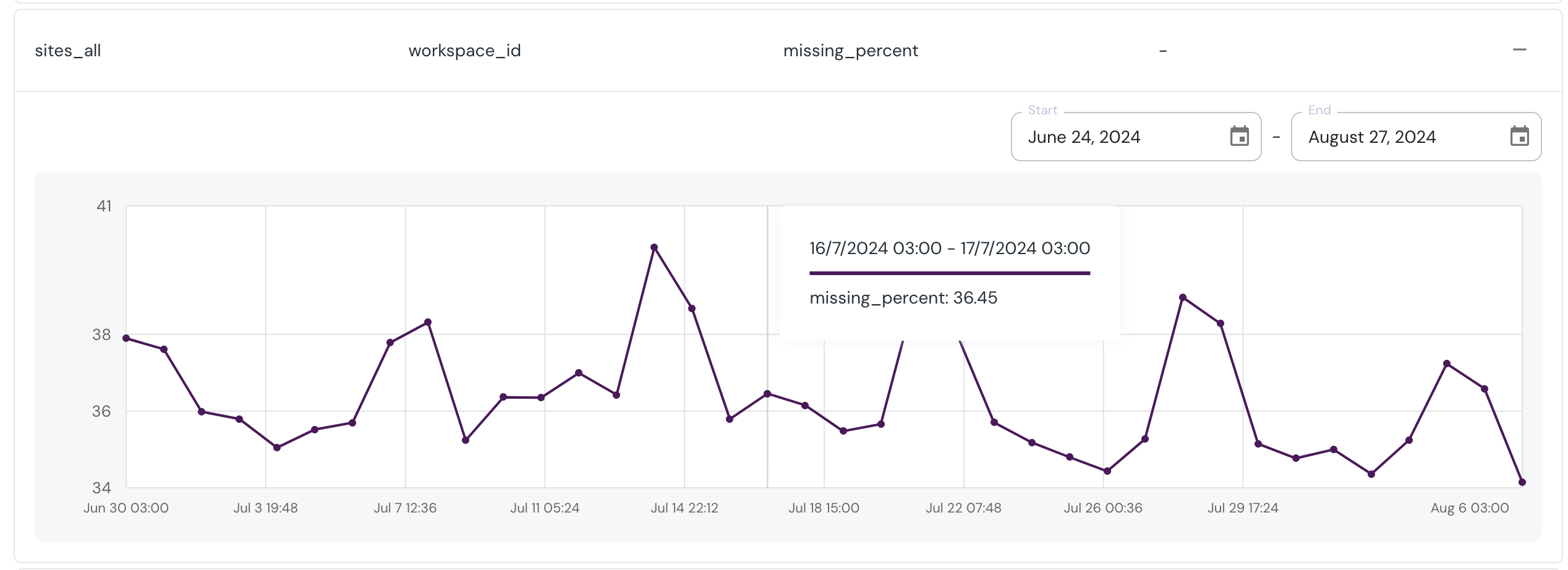 +
+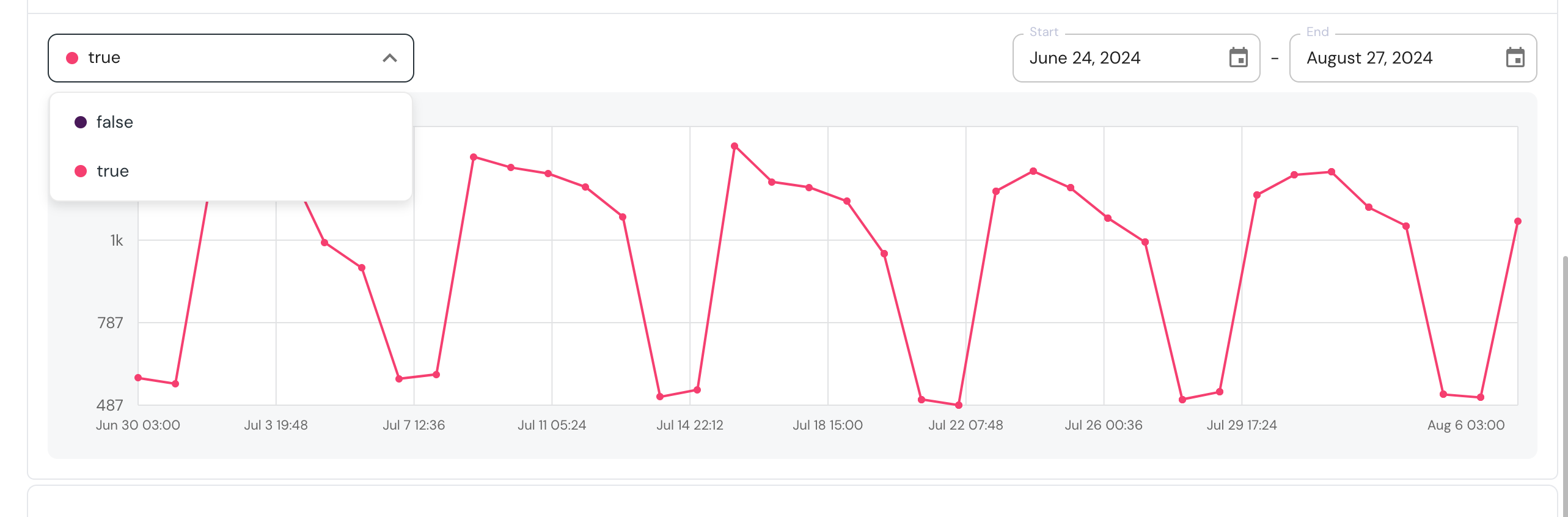 +
+
+## How to set up a data content metric?
+
+The monitored metrics are set up in the code, in a way similar to dbt tests.
+
+
+
+
+No mandatory configuration, however it is highly recommended to configure a `timestamp_column`.
+
+{/* prettier-ignore */}
+
+
+
+## How to set up a data content metric?
+
+The monitored metrics are set up in the code, in a way similar to dbt tests.
+
+
+
+
+No mandatory configuration, however it is highly recommended to configure a `timestamp_column`.
+
+{/* prettier-ignore */}
+ +
+  +
+  -
-
-## Supported automated monitors
-
-### Volume
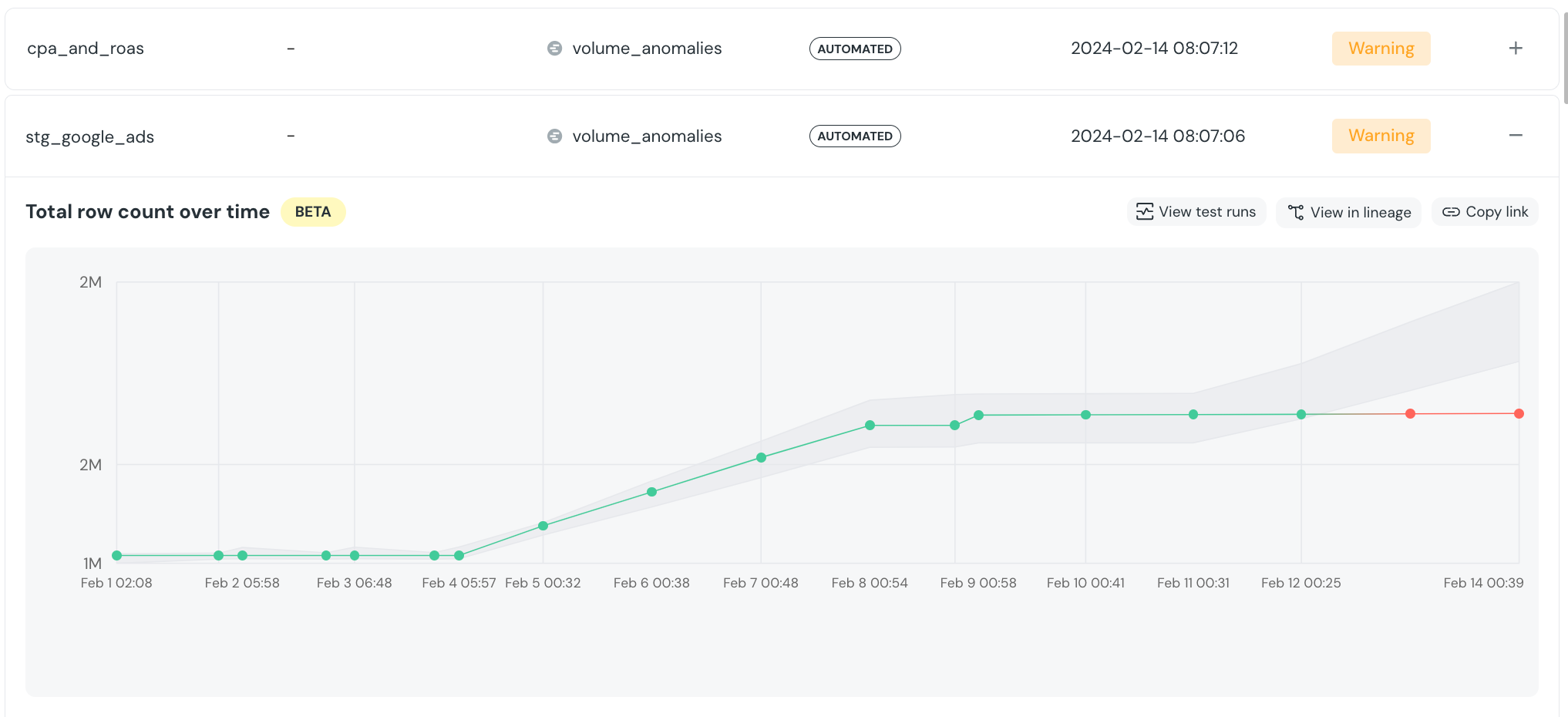
-
-Monitors how much data was added / removed / updated to the table with each update.
-The monitor alerts you if there is an unexpected drop or spike in rows.
-
-### Freshness
-
-Monitors how frequently a table is updated, and alerts you if there is an unexpected delay.
-
-### Schema changes
-
-_Coming soon_
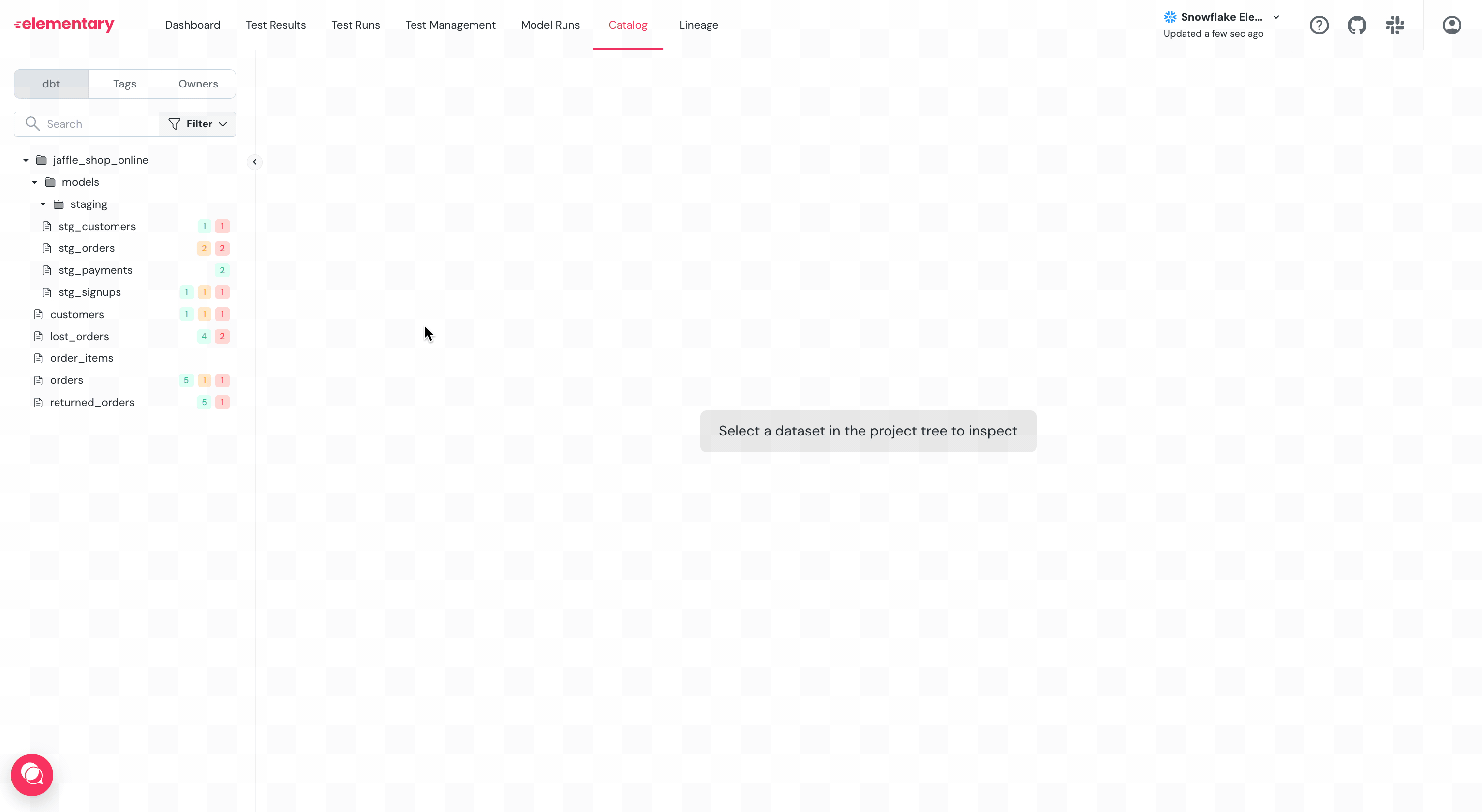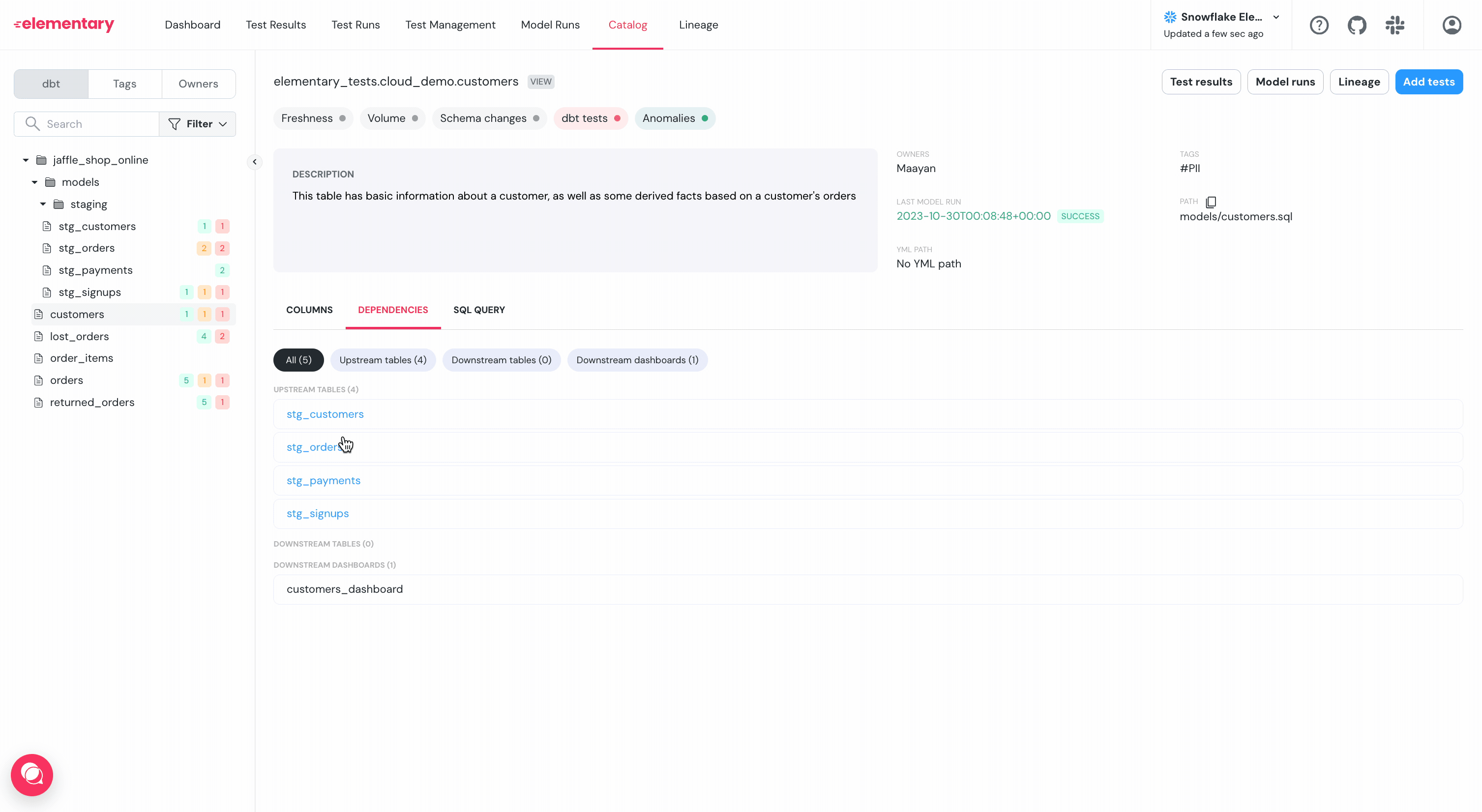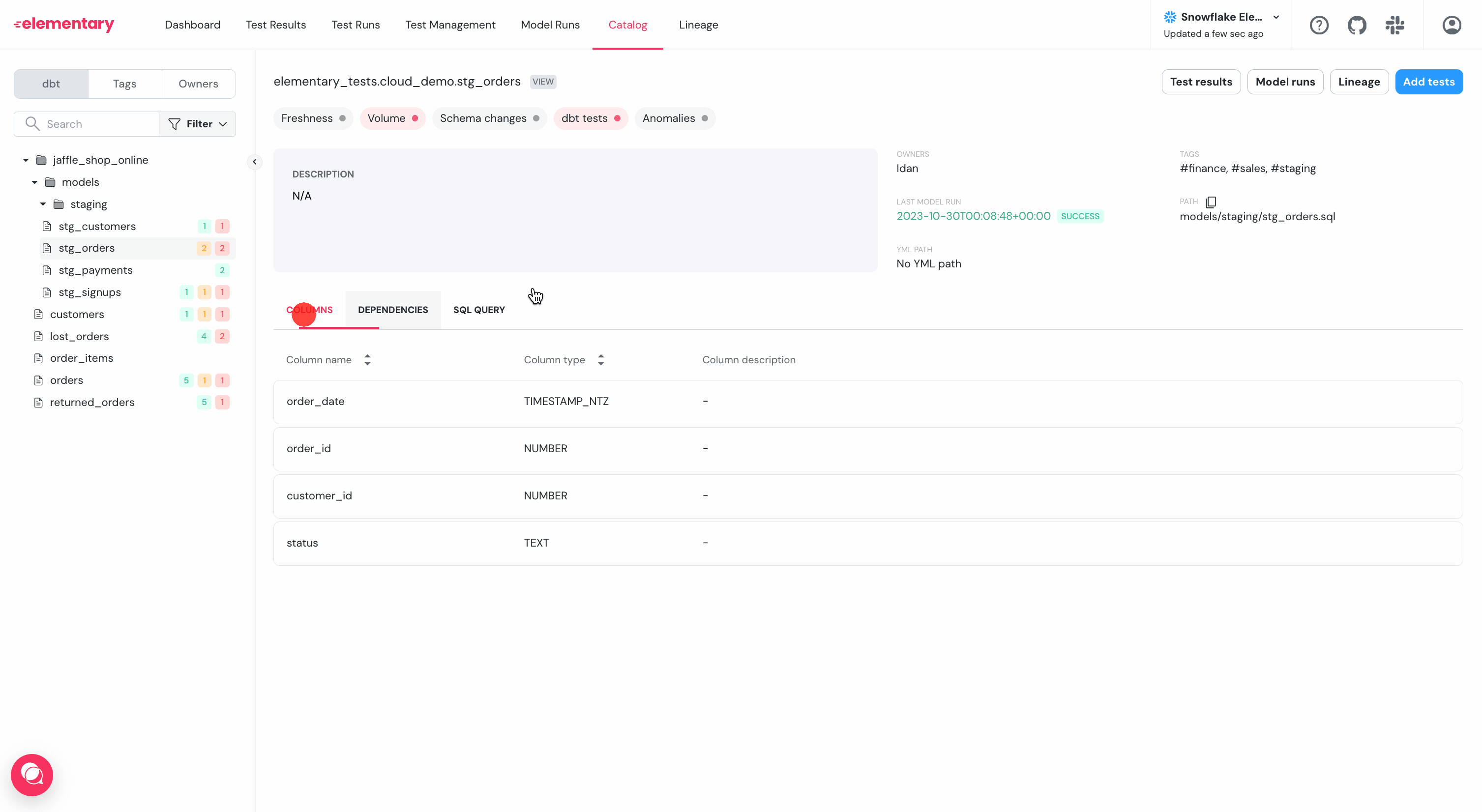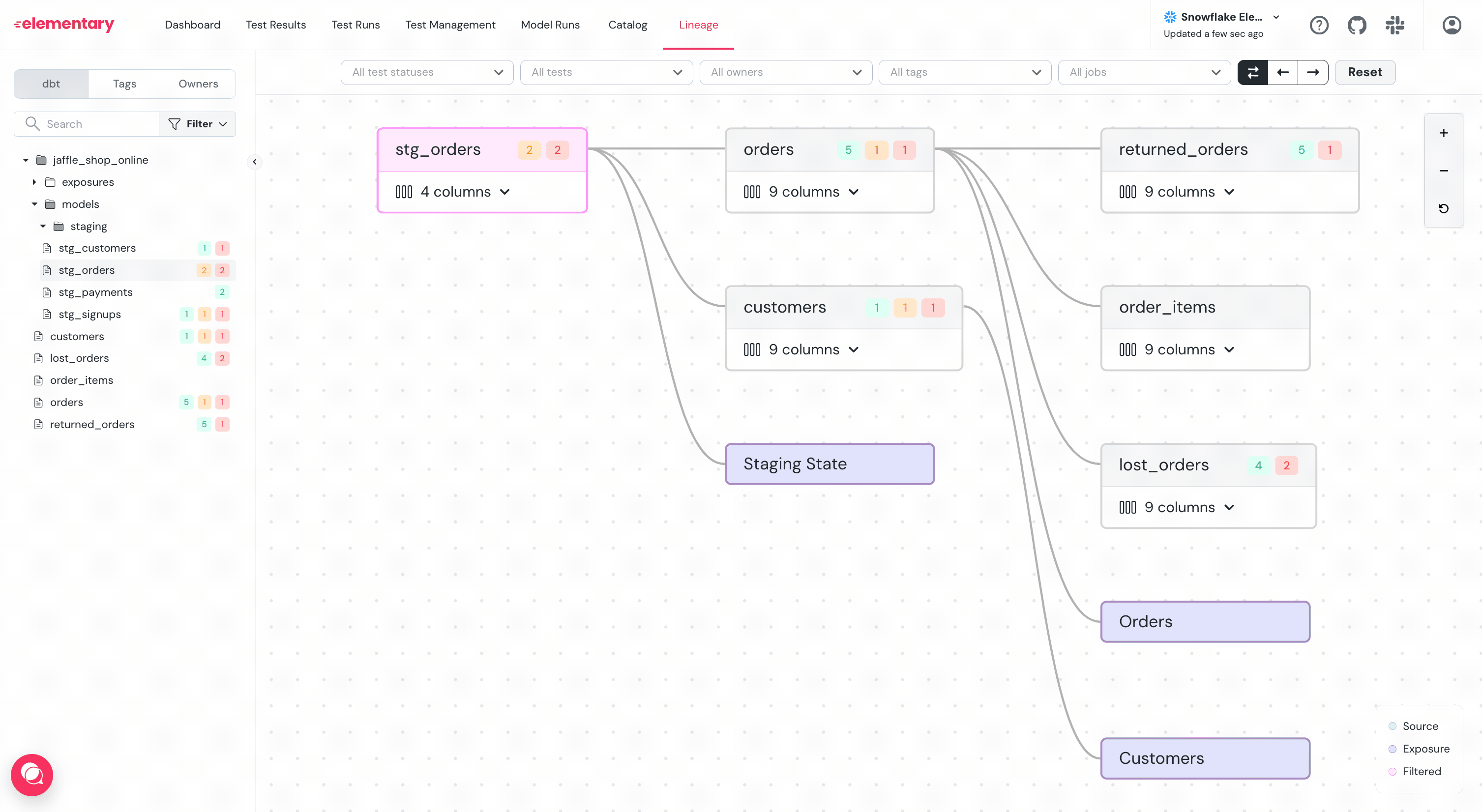
diff --git a/docs/features/catalog.mdx b/docs/features/catalog.mdx
deleted file mode 100644
index 5f61a58b4..000000000
--- a/docs/features/catalog.mdx
+++ /dev/null
@@ -1,21 +0,0 @@
----
-title: "Data Catalog"
-icon: "folder-tree"
-iconType: "solid"
----
-
-
-
-
-## Supported automated monitors
-
-### Volume
-
-Monitors how much data was added / removed / updated to the table with each update.
-The monitor alerts you if there is an unexpected drop or spike in rows.
-
-### Freshness
-
-Monitors how frequently a table is updated, and alerts you if there is an unexpected delay.
-
-### Schema changes
-
-_Coming soon_
diff --git a/docs/features/catalog.mdx b/docs/features/catalog.mdx
deleted file mode 100644
index 5f61a58b4..000000000
--- a/docs/features/catalog.mdx
+++ /dev/null
@@ -1,21 +0,0 @@
----
-title: "Data Catalog"
-icon: "folder-tree"
-iconType: "solid"
----
-
- -
diff --git a/docs/features/ci.mdx b/docs/features/ci.mdx
index c17753e90..236a35c5c 100644
--- a/docs/features/ci.mdx
+++ b/docs/features/ci.mdx
@@ -1,7 +1,6 @@
---
title: "Elementary CI"
sidebarTitle: "Elementary CI"
-icon: "code-pull-request"
---
-
diff --git a/docs/features/ci.mdx b/docs/features/ci.mdx
index c17753e90..236a35c5c 100644
--- a/docs/features/ci.mdx
+++ b/docs/features/ci.mdx
@@ -1,7 +1,6 @@
---
title: "Elementary CI"
sidebarTitle: "Elementary CI"
-icon: "code-pull-request"
---
 +
-Elementary CI automations will help you make changes with confidence and seeing the full picture before merging your pull request.
+Elementary CI automations help you make changes with confidence by providing a comprehensive view before merging your pull request.
## Want to join the beta?
-
+
-Elementary CI automations will help you make changes with confidence and seeing the full picture before merging your pull request.
+Elementary CI automations help you make changes with confidence by providing a comprehensive view before merging your pull request.
## Want to join the beta?
- +
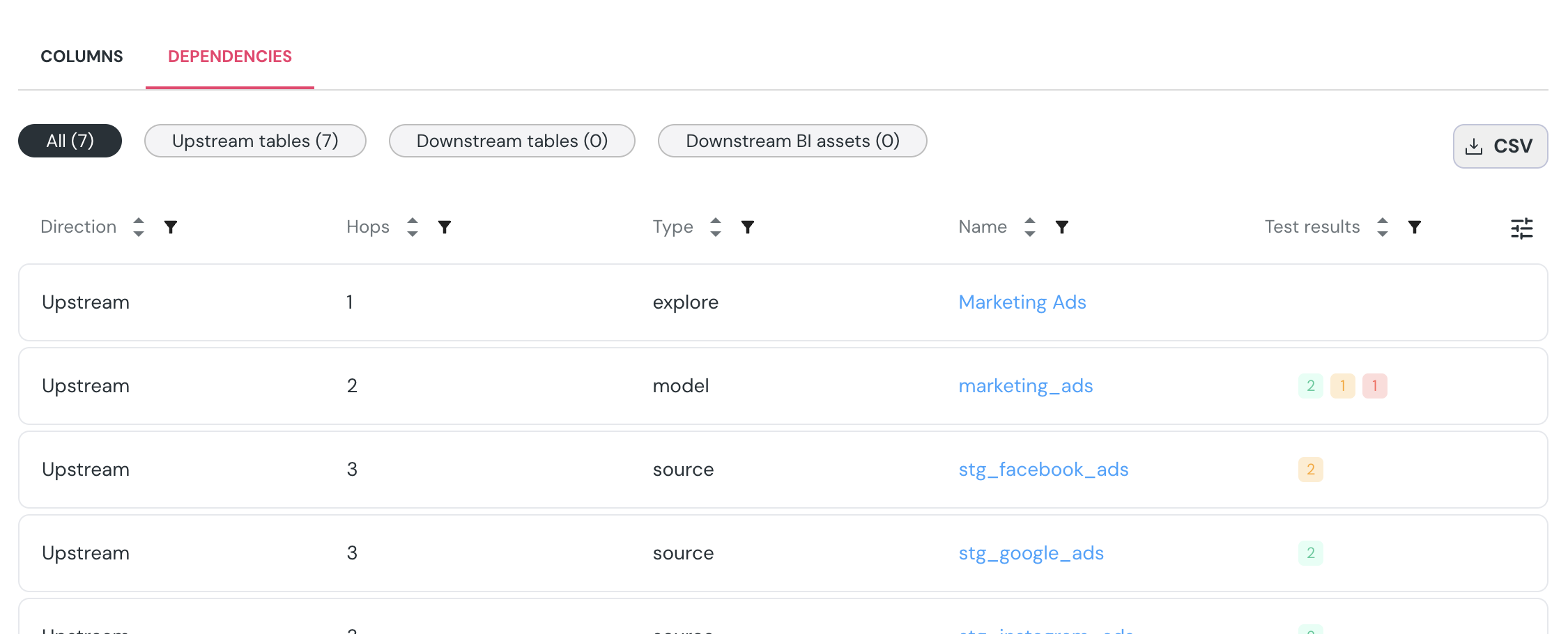
+### Custom Metadata Support
+Need to display additional metadata fields from your dbt `meta` config? Reach out to our team to customize the catalog with fields that best fit your data workflows.
+
+### Critical Asset Tagging
+Mark key datasets as critical to highlight their importance and prioritize monitoring efforts. Read more [here](/features/data-governance/critical_assets).
+
+### Lineage & Dependency Export
+View upstream and downstream dependencies for each dataset, and export the full dependency list as a CSV for further analysis or documentation.
+
+
+### Custom Metadata Support
+Need to display additional metadata fields from your dbt `meta` config? Reach out to our team to customize the catalog with fields that best fit your data workflows.
+
+### Critical Asset Tagging
+Mark key datasets as critical to highlight their importance and prioritize monitoring efforts. Read more [here](/features/data-governance/critical_assets).
+
+### Lineage & Dependency Export
+View upstream and downstream dependencies for each dataset, and export the full dependency list as a CSV for further analysis or documentation.
+ +
+## Data Source
+The catalog content is automatically generated from the descriptions maintained in your dbt project YML files, ensuring consistency with your existing documentation.
+In addition, Elementary enriches the catalog with health scores, test coverage status and results, as well as metadata from your DWH information schema, providing a comprehensive view of your datasets.
+
+## Coming soon
+Click on the links below to be notified when these features are released!
+
+
+
+## Data Source
+The catalog content is automatically generated from the descriptions maintained in your dbt project YML files, ensuring consistency with your existing documentation.
+In addition, Elementary enriches the catalog with health scores, test coverage status and results, as well as metadata from your DWH information schema, providing a comprehensive view of your datasets.
+
+## Coming soon
+Click on the links below to be notified when these features are released!
+
+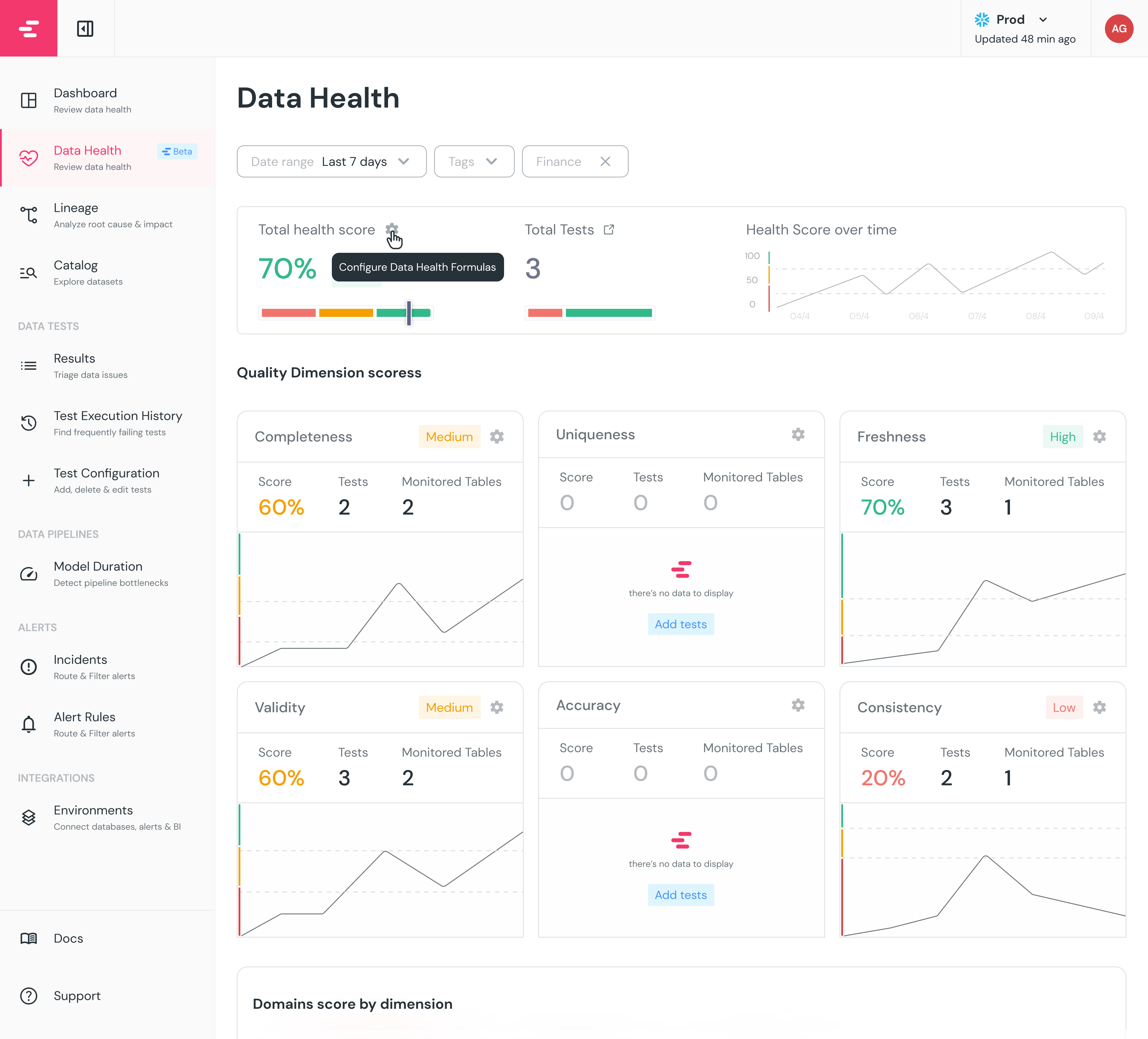 +
+The dashboard is based on the 6 [Data Quality Dimensions](/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions):
+
+
+
+The dashboard is based on the 6 [Data Quality Dimensions](/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions):
+
+ +
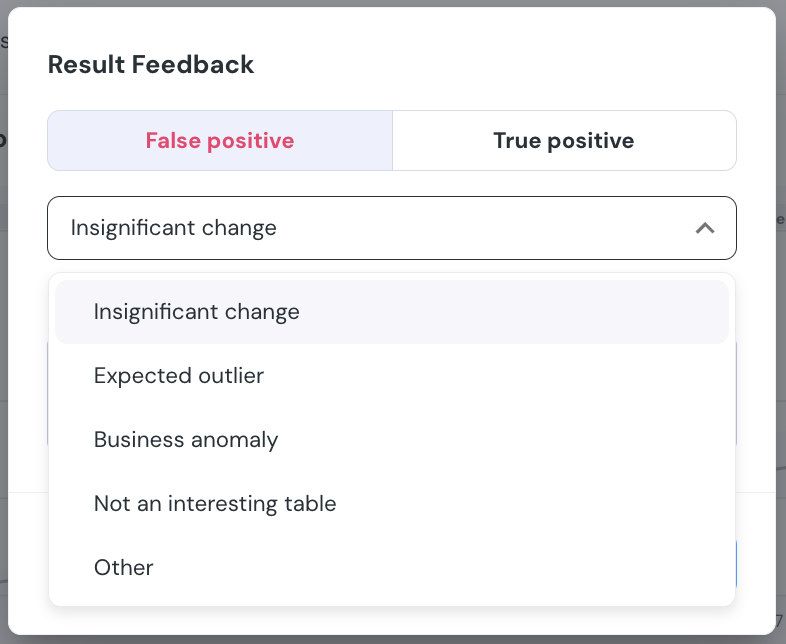
+### Can I customize the quality dimension mapping of my tests?
+
+Of course!
+Each test you run, whether it's a generic or a custom test, can be mapped to one of the 6 quality dimensions.
+The way to do so is to add `quality_dimension` to the test definition in your dbt project:
+
+
+
+### Can I customize the quality dimension mapping of my tests?
+
+Of course!
+Each test you run, whether it's a generic or a custom test, can be mapped to one of the 6 quality dimensions.
+The way to do so is to add `quality_dimension` to the test definition in your dbt project:
+
+ -
+
-
+  +
+  +
+
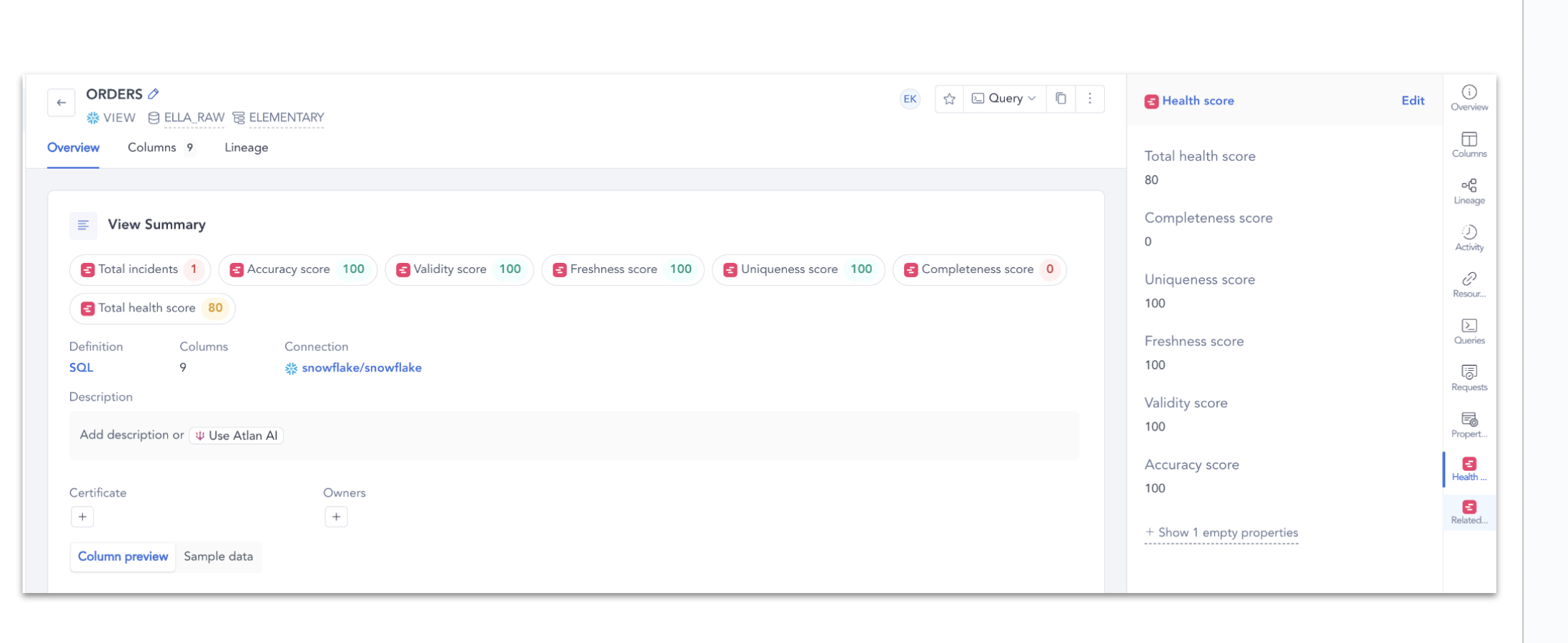
+## **What Should Be Set as a Critical Asset?**
+
+You should mark an asset as **critical** if:
+
+- It directly impacts key **business reports, dashboards, or decision-making tools**.
+- It serves as an essential **upstream dependency** for other important data models.
+- It is frequently used by **multiple teams or stakeholders**.
+- Its failure or inaccuracy could cause **significant business or operational risks**
+
+## **Why Should I Define My Critical Assets?**
+
+Defining your **critical assets** helps you:
+
+- **Quickly identify and respond to issues**– Get notified when upstream problems may impact your critical assets, ensuring faster resolution and minimal disruption.
+- **Prioritize issue resolution**– Focus on addressing incidents that have the greatest impact on business operations, dashboards, and decision-making.
+- **Improve data reliability**– Ensure key stakeholders have access to accurate and up-to-date data by monitoring critical assets more effectively.
+- **Enhance observability**– Gain better visibility into the health of your most important assets through prioritized monitoring and alerting.
+
+## **How to Set a Critical Asset?**
+
+You can mark an asset as **critical** directly in the UI:
+
+- **From the Catalog Page** – Navigate to the asset in the catalog and click the **diamond icon** to **"Set as Critical Asset."**
+- **From the Lineage View** – Right-click on the node representing the asset and select **"Set as Critical Asset"** from the list.
+
+Once an asset is marked as critical, **alerts will now highlight any issues that may impact this asset or its upstream dependencies, ensuring prioritization.**
+
+
+
+## **Where Can You See Critical Assets?**
+
+Once an asset is marked as **critical**, you will be able to:
+
+- **Identify it in the UI**, where it will be visually highlighted.
+- **Receive alerts** when upstream issues may impact the critical asset.
+- **Filter incidents** by their impact on critical assets.
+- **Track the health of critical data assets** over time through dashboard monitoring (Coming soon).
+
+## **Test Coverage Analysis (Coming Soon)**
+
+In upcoming releases, we will introduce **test coverage analysis** based on the monitoring state of your assets across key data quality dimensions. This feature will help you:
+
+- **Identify gaps** in monitoring and testing coverage for your most important assets and their upstream dependencies.
+- **Ensure that key data components** are properly monitored and continuously observed to maintain data reliability.
+
+By carefully selecting **which assets to mark as critical**, you can quickly detect and prioritize issues that impact your most important data, reducing disruptions, improving reliability, and keeping key stakeholders informed.
\ No newline at end of file
diff --git a/docs/features/column-level-lineage.mdx b/docs/features/data-lineage/column-level-lineage.mdx
similarity index 51%
rename from docs/features/column-level-lineage.mdx
rename to docs/features/data-lineage/column-level-lineage.mdx
index d94b067ed..7b8a7239e 100644
--- a/docs/features/column-level-lineage.mdx
+++ b/docs/features/data-lineage/column-level-lineage.mdx
@@ -1,38 +1,37 @@
---
-title: Column Level Lineage
-sidebarTitle: Column Level Lineage
+title: Column-Level Lineage
+sidebarTitle: Column level lineage
---
+
+
+## **What Should Be Set as a Critical Asset?**
+
+You should mark an asset as **critical** if:
+
+- It directly impacts key **business reports, dashboards, or decision-making tools**.
+- It serves as an essential **upstream dependency** for other important data models.
+- It is frequently used by **multiple teams or stakeholders**.
+- Its failure or inaccuracy could cause **significant business or operational risks**
+
+## **Why Should I Define My Critical Assets?**
+
+Defining your **critical assets** helps you:
+
+- **Quickly identify and respond to issues**– Get notified when upstream problems may impact your critical assets, ensuring faster resolution and minimal disruption.
+- **Prioritize issue resolution**– Focus on addressing incidents that have the greatest impact on business operations, dashboards, and decision-making.
+- **Improve data reliability**– Ensure key stakeholders have access to accurate and up-to-date data by monitoring critical assets more effectively.
+- **Enhance observability**– Gain better visibility into the health of your most important assets through prioritized monitoring and alerting.
+
+## **How to Set a Critical Asset?**
+
+You can mark an asset as **critical** directly in the UI:
+
+- **From the Catalog Page** – Navigate to the asset in the catalog and click the **diamond icon** to **"Set as Critical Asset."**
+- **From the Lineage View** – Right-click on the node representing the asset and select **"Set as Critical Asset"** from the list.
+
+Once an asset is marked as critical, **alerts will now highlight any issues that may impact this asset or its upstream dependencies, ensuring prioritization.**
+
+
+
+## **Where Can You See Critical Assets?**
+
+Once an asset is marked as **critical**, you will be able to:
+
+- **Identify it in the UI**, where it will be visually highlighted.
+- **Receive alerts** when upstream issues may impact the critical asset.
+- **Filter incidents** by their impact on critical assets.
+- **Track the health of critical data assets** over time through dashboard monitoring (Coming soon).
+
+## **Test Coverage Analysis (Coming Soon)**
+
+In upcoming releases, we will introduce **test coverage analysis** based on the monitoring state of your assets across key data quality dimensions. This feature will help you:
+
+- **Identify gaps** in monitoring and testing coverage for your most important assets and their upstream dependencies.
+- **Ensure that key data components** are properly monitored and continuously observed to maintain data reliability.
+
+By carefully selecting **which assets to mark as critical**, you can quickly detect and prioritize issues that impact your most important data, reducing disruptions, improving reliability, and keeping key stakeholders informed.
\ No newline at end of file
diff --git a/docs/features/column-level-lineage.mdx b/docs/features/data-lineage/column-level-lineage.mdx
similarity index 51%
rename from docs/features/column-level-lineage.mdx
rename to docs/features/data-lineage/column-level-lineage.mdx
index d94b067ed..7b8a7239e 100644
--- a/docs/features/column-level-lineage.mdx
+++ b/docs/features/data-lineage/column-level-lineage.mdx
@@ -1,38 +1,37 @@
---
-title: Column Level Lineage
-sidebarTitle: Column Level Lineage
+title: Column-Level Lineage
+sidebarTitle: Column level lineage
---
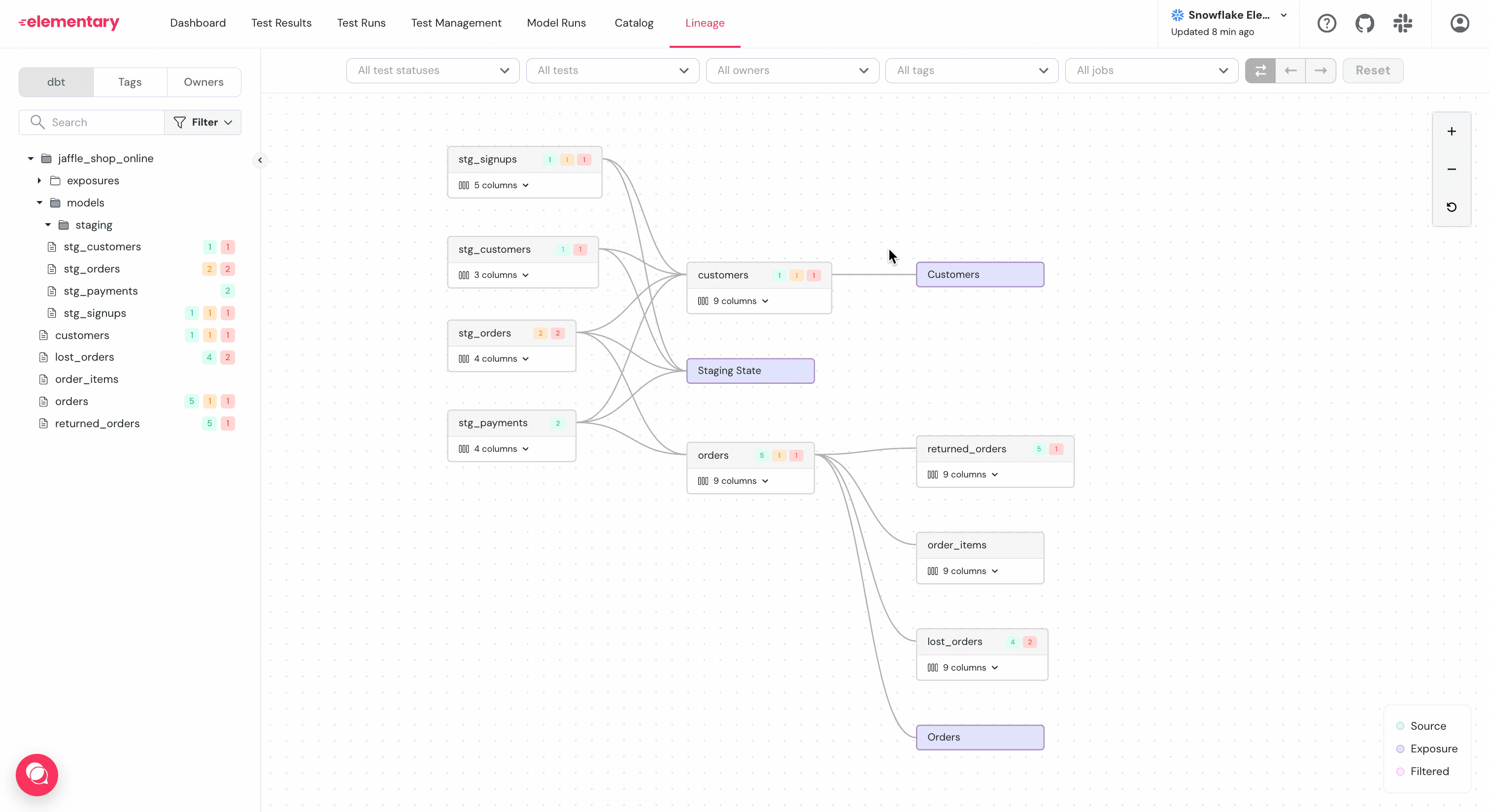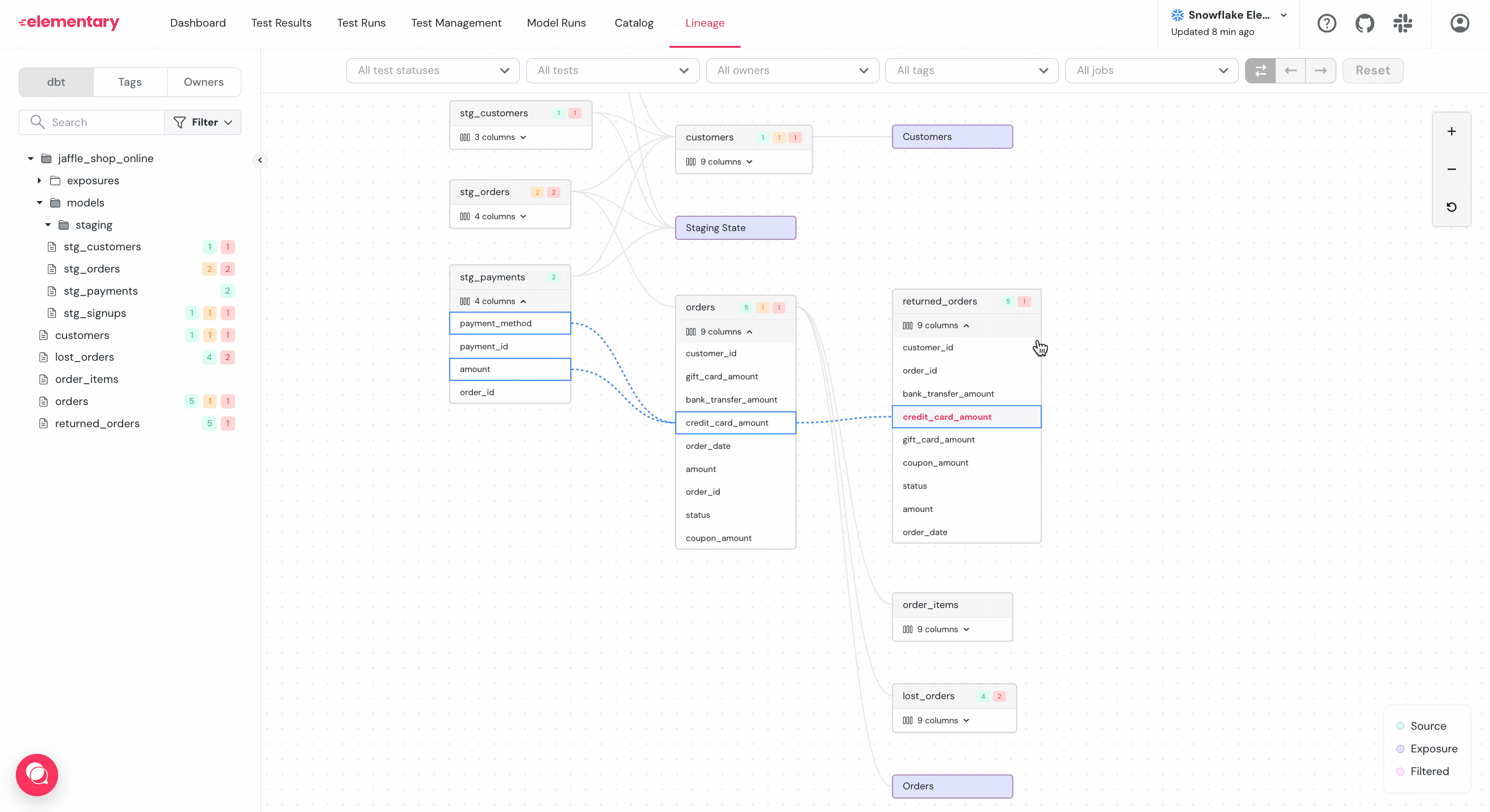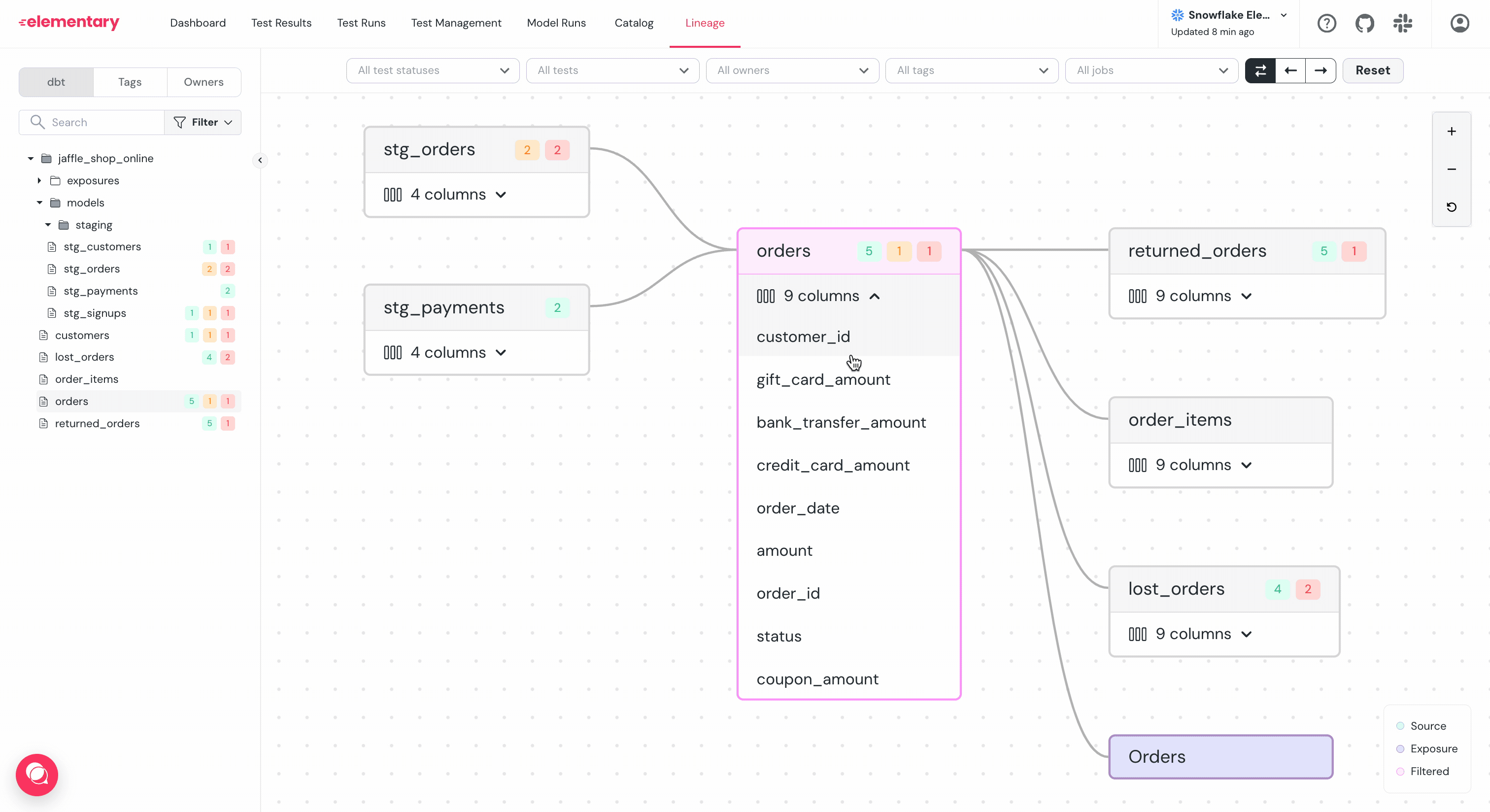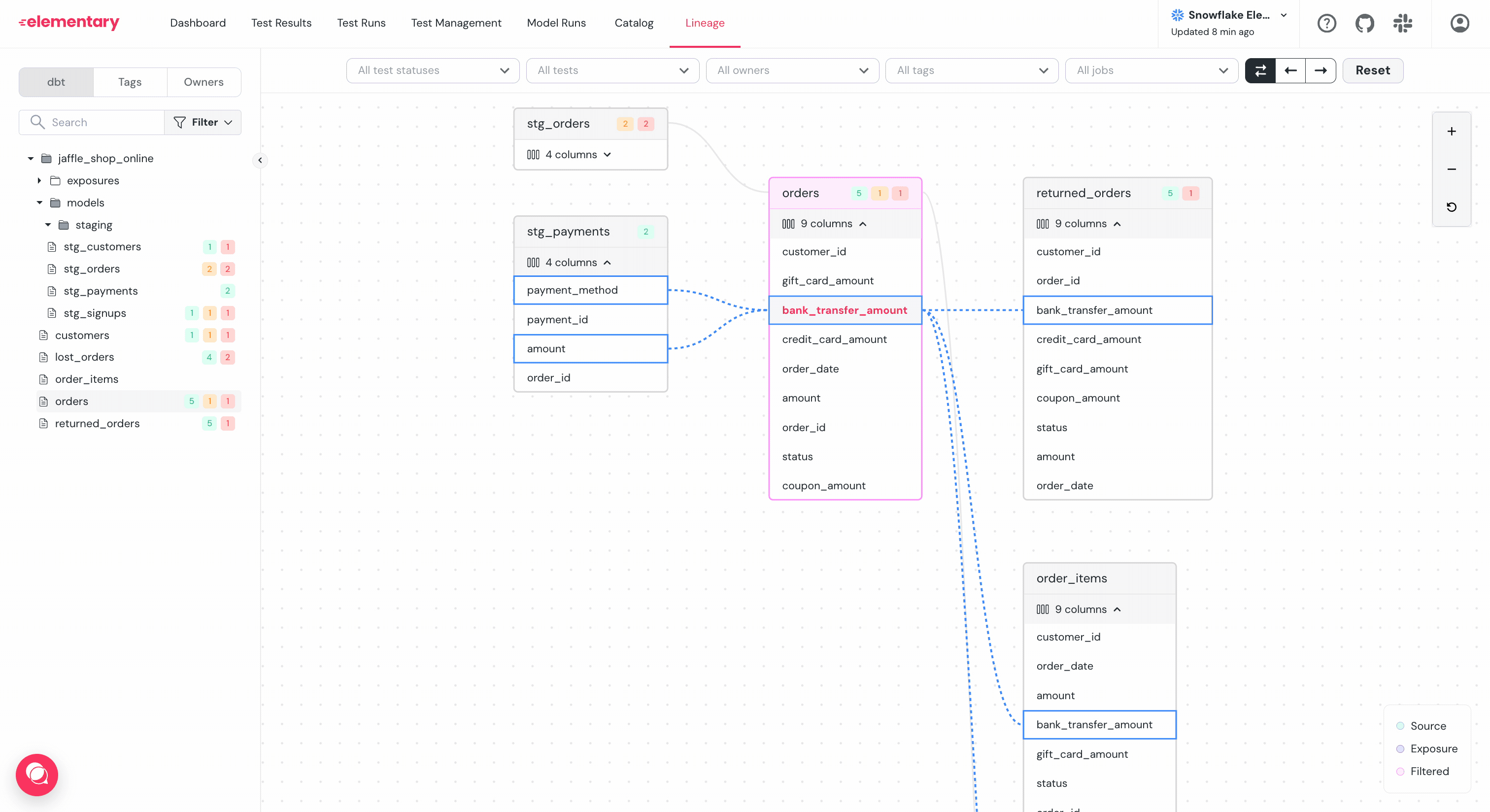 -
+* Will changing this column impact a dashboard?
### Filter and highlight columns path
-To help navigate graphs with large amount of columns per table, use the `...` menu right to the column:
+To help navigate graphs with large amount of columns per table, use the `...` menu to the right of the column:
+
+* **Filter**: Will show a graph of only the selected column and its dependencies.
+
+* **Highlight**: Will highlight only the selected column and its dependencies.
-- **Filter**: Will show a graph of only the selected column and it's dependencies.
-- **Highlight**: Will highlight only the selected column and it's dependencies.
+
-### Column level lineage generation
+### Column-level lineage generation
Elementary parses SQL queries to determine the dependencies between columns.
Note that the lineage is only of the columns that directly contribute data to the column.
-For example for the query:
+For example, for the query:
```sql
create or replace table db.schema.users as
@@ -46,4 +45,4 @@ where user_type != 'test_user'
The direct dependency of `total_logins` is `login_events.login_time`.
The column `login_events.user_type` filter the data of `total_logins`, but it is an indirect dependency and will not show in lineage.
-If you want a different approach in your Elementary Cloud instance - Contact us.
+If you want a different approach in your Elementary Cloud instance - contact us.
\ No newline at end of file
diff --git a/docs/features/exposures-lineage.mdx b/docs/features/data-lineage/exposures-lineage.mdx
similarity index 53%
rename from docs/features/exposures-lineage.mdx
rename to docs/features/data-lineage/exposures-lineage.mdx
index c99f90666..634427c2d 100644
--- a/docs/features/exposures-lineage.mdx
+++ b/docs/features/data-lineage/exposures-lineage.mdx
@@ -1,17 +1,17 @@
---
-title: Lineage to Downstream Dashboards
-sidebarTitle: BI Integrations
+title: Lineage to Downstream Dashboards and Tools
+sidebarTitle: Lineage to BI
---
Some of your data is used downstream in dashboards, applications, data science pipelines, reverse ETLs, etc.
These downstream data consumers are called _exposures_.
-Elementary lineage graph presents downstream exposures of two origins:
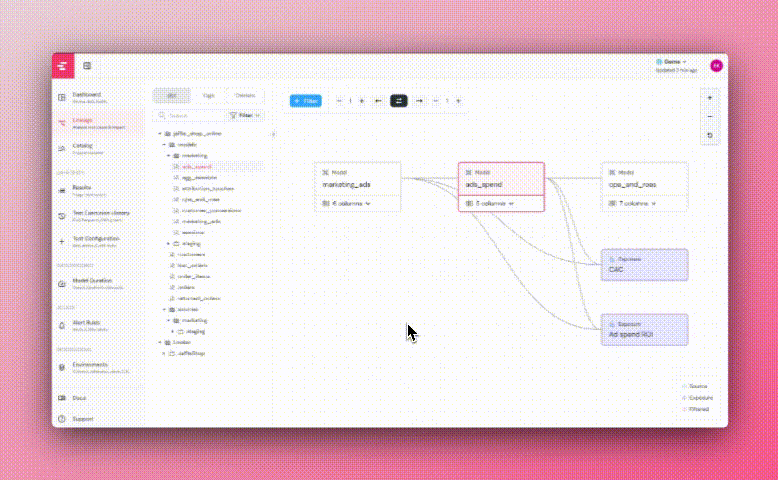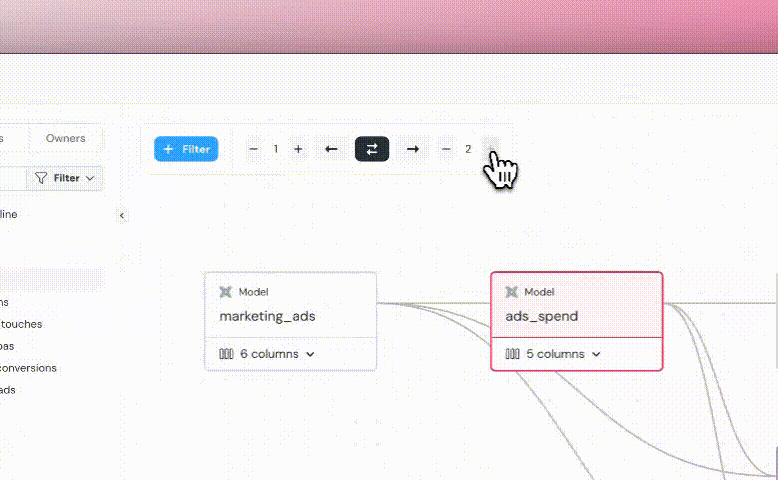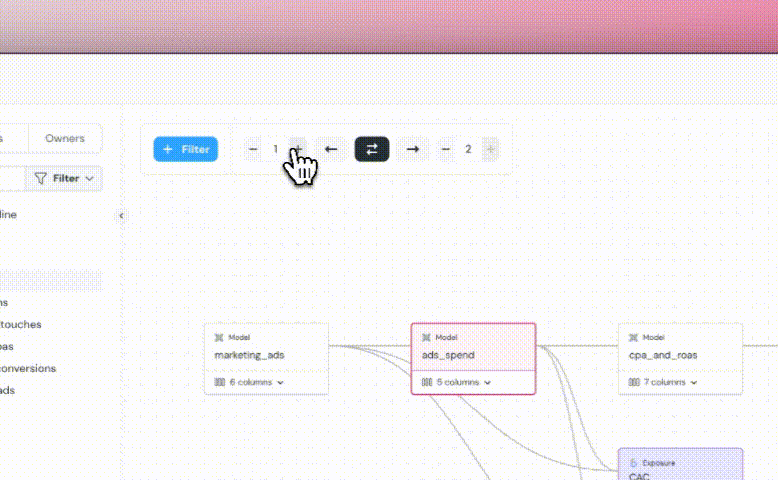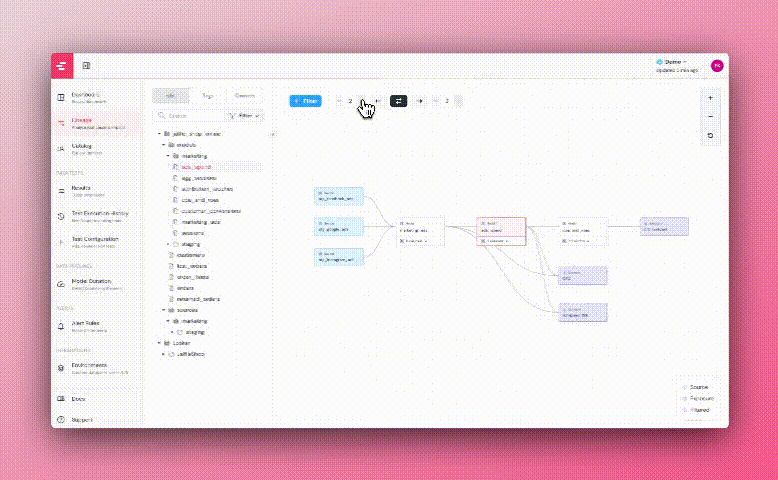
+The Elementary lineage graph presents downstream exposures of two origins:
-1. Elementary Cloud Automated BI integrations
+1. Elementary automated BI integrations
2. Exposures configured in your dbt project. Read about [how to configure exposures](https://docs.getdbt.com/docs/build/exposures) in code.
-
-
+* Will changing this column impact a dashboard?
### Filter and highlight columns path
-To help navigate graphs with large amount of columns per table, use the `...` menu right to the column:
+To help navigate graphs with large amount of columns per table, use the `...` menu to the right of the column:
+
+* **Filter**: Will show a graph of only the selected column and its dependencies.
+
+* **Highlight**: Will highlight only the selected column and its dependencies.
-- **Filter**: Will show a graph of only the selected column and it's dependencies.
-- **Highlight**: Will highlight only the selected column and it's dependencies.
+
-### Column level lineage generation
+### Column-level lineage generation
Elementary parses SQL queries to determine the dependencies between columns.
Note that the lineage is only of the columns that directly contribute data to the column.
-For example for the query:
+For example, for the query:
```sql
create or replace table db.schema.users as
@@ -46,4 +45,4 @@ where user_type != 'test_user'
The direct dependency of `total_logins` is `login_events.login_time`.
The column `login_events.user_type` filter the data of `total_logins`, but it is an indirect dependency and will not show in lineage.
-If you want a different approach in your Elementary Cloud instance - Contact us.
+If you want a different approach in your Elementary Cloud instance - contact us.
\ No newline at end of file
diff --git a/docs/features/exposures-lineage.mdx b/docs/features/data-lineage/exposures-lineage.mdx
similarity index 53%
rename from docs/features/exposures-lineage.mdx
rename to docs/features/data-lineage/exposures-lineage.mdx
index c99f90666..634427c2d 100644
--- a/docs/features/exposures-lineage.mdx
+++ b/docs/features/data-lineage/exposures-lineage.mdx
@@ -1,17 +1,17 @@
---
-title: Lineage to Downstream Dashboards
-sidebarTitle: BI Integrations
+title: Lineage to Downstream Dashboards and Tools
+sidebarTitle: Lineage to BI
---
Some of your data is used downstream in dashboards, applications, data science pipelines, reverse ETLs, etc.
These downstream data consumers are called _exposures_.
-Elementary lineage graph presents downstream exposures of two origins:
+The Elementary lineage graph presents downstream exposures of two origins:
-1. Elementary Cloud Automated BI integrations
+1. Elementary automated BI integrations
2. Exposures configured in your dbt project. Read about [how to configure exposures](https://docs.getdbt.com/docs/build/exposures) in code.
- +
+  +
+  +
+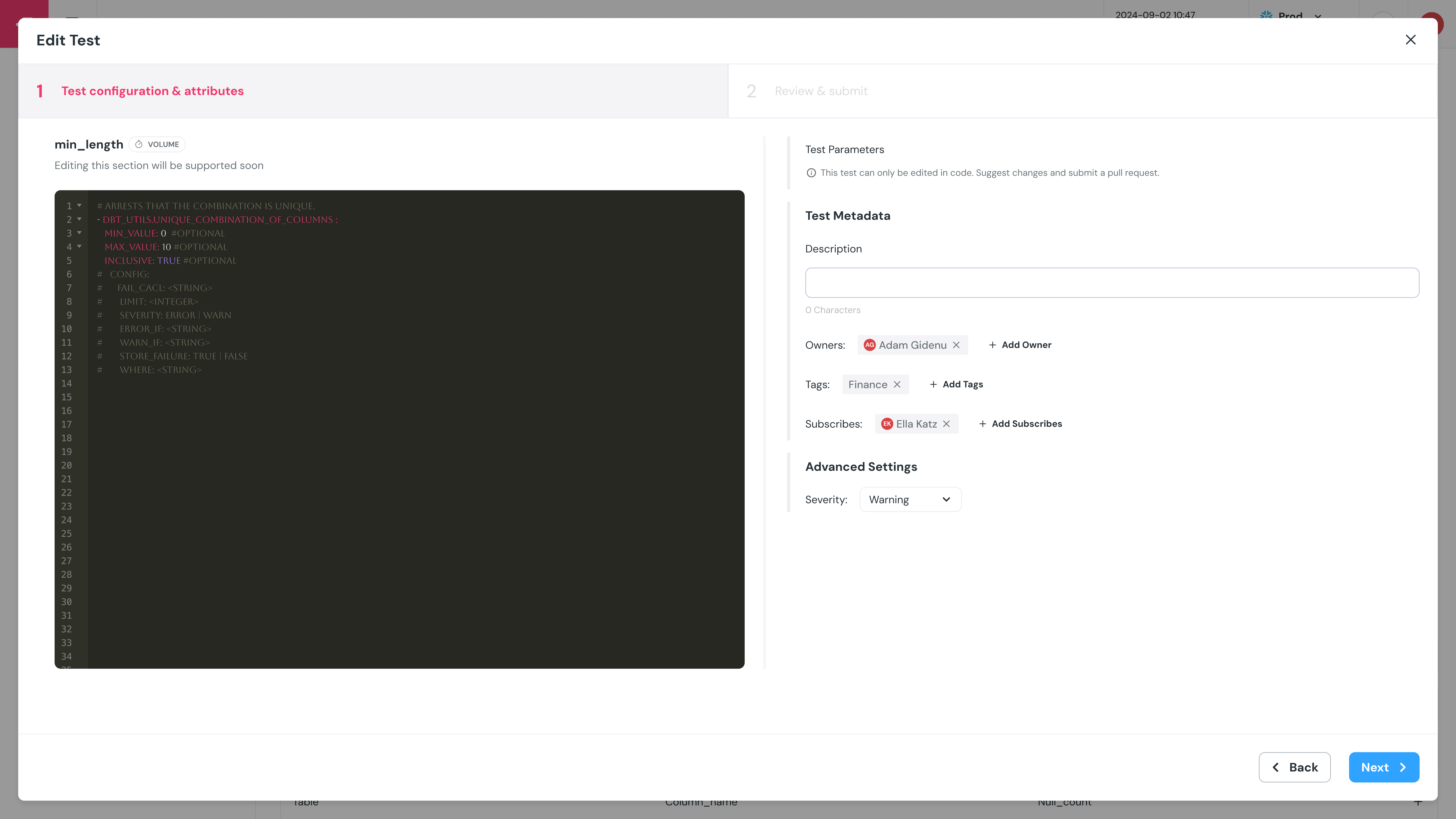 +
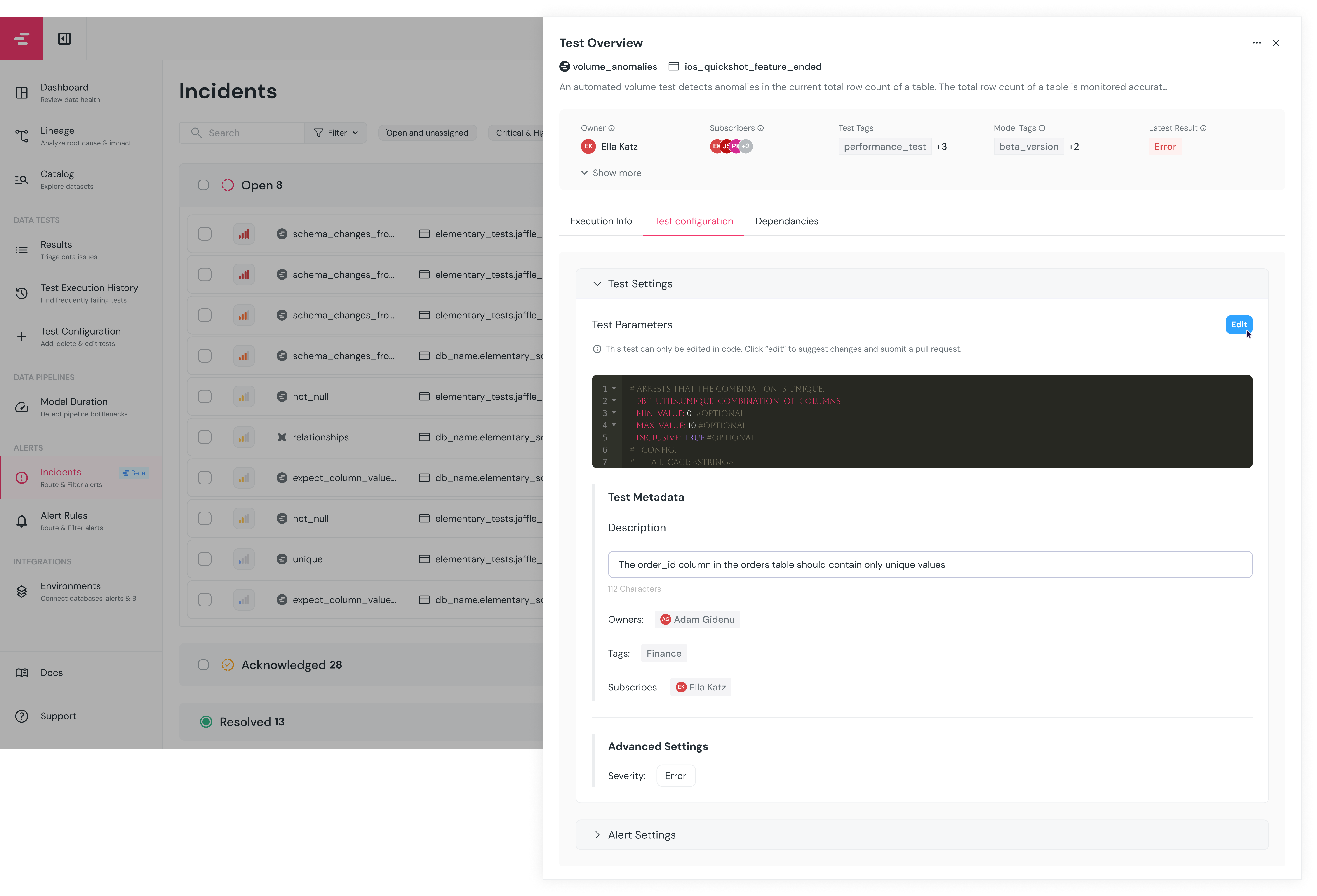
+A pull request will be opened in the code repository, and a link to the PR will be provided in the UI.
+
+
+A pull request will be opened in the code repository, and a link to the PR will be provided in the UI.
+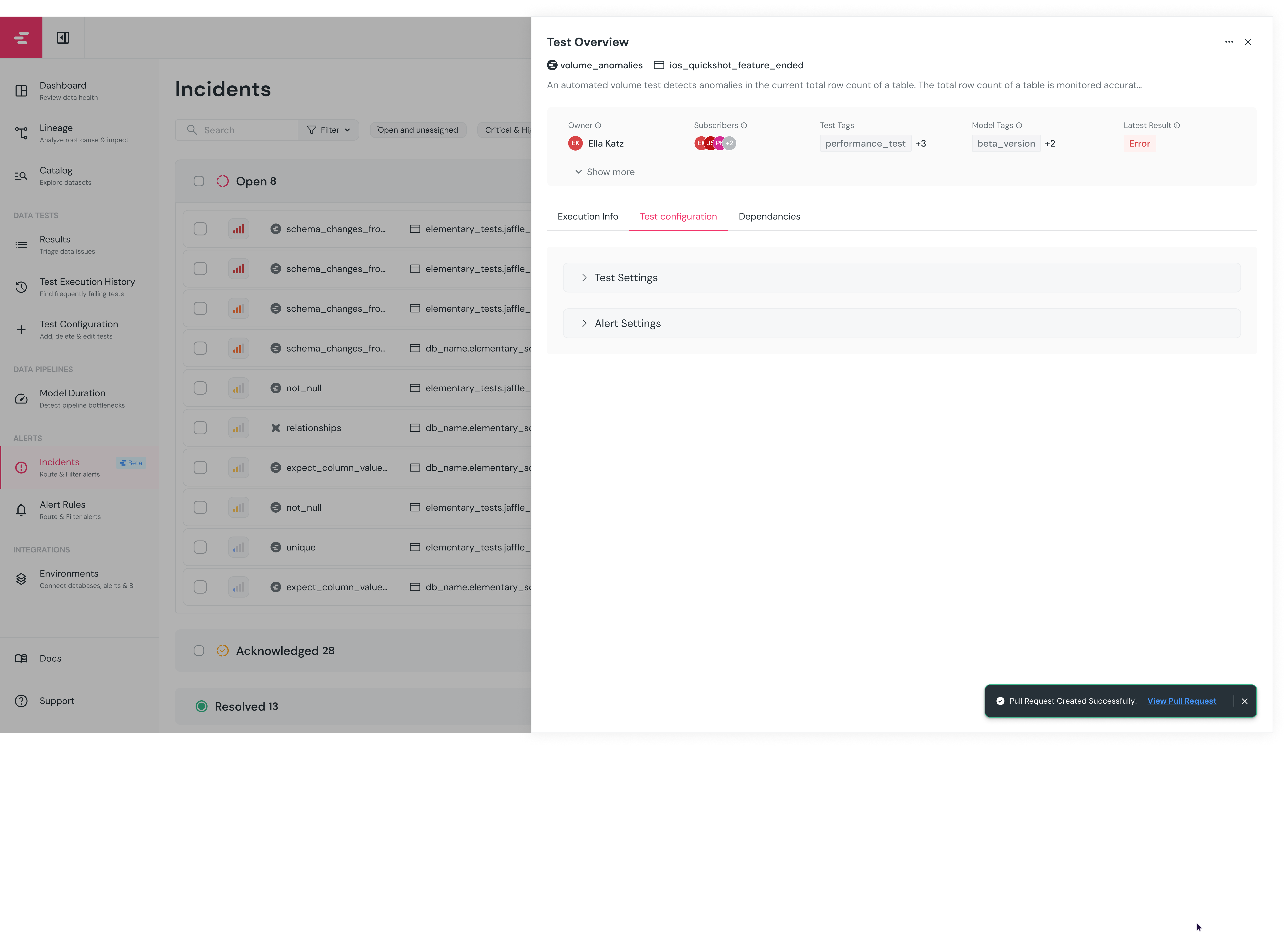 +### Benefits of leveraging dbt tests
+
+
+### Benefits of leveraging dbt tests
+
+ +
+  +
+
+
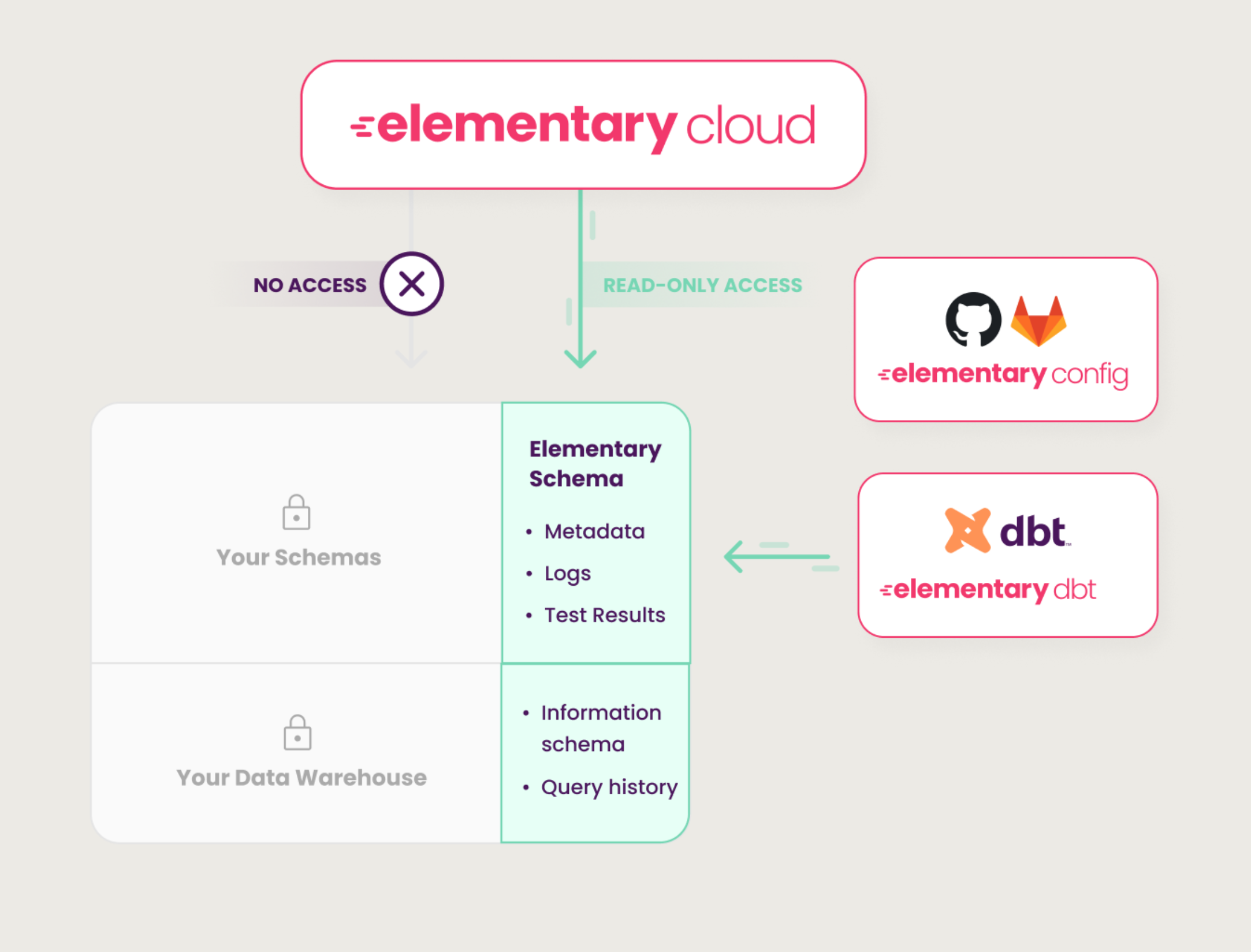
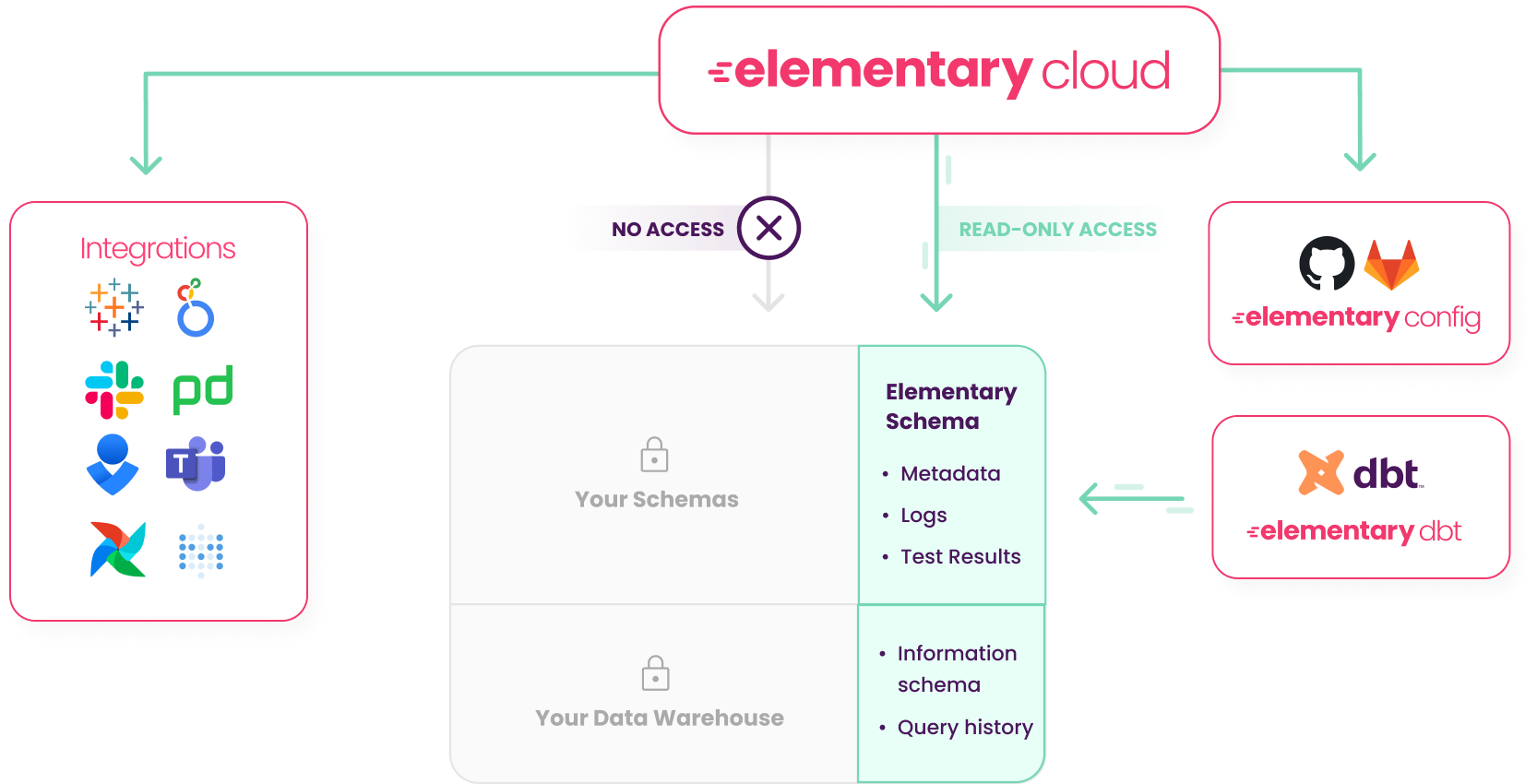
+## How it works?
+1. You install the Elementary dbt package in your dbt project and configure it to write to it's own schema, the Elementary schema.
+2. The package writes test results, run results, logs and metadata to the Elementary schema.
+3. The cloud service only requires `read access` to the Elementary schema, not to schemas where your sensitive data is stored.
+4. The cloud service connects to sync the Elementary schema using an **encrypted connection** and a **static IP address** that you will need to add to your allowlist.
+
+
+##
+
+
+[Read about Security and Privacy](/cloud/general/security-and-privacy)
\ No newline at end of file
diff --git a/docs/x_old/understand-elementary/elementary-report-ui.mdx b/docs/x_old/understand-elementary/elementary-report-ui.mdx
index 2498bb3a9..ae49f10fa 100644
--- a/docs/x_old/understand-elementary/elementary-report-ui.mdx
+++ b/docs/x_old/understand-elementary/elementary-report-ui.mdx
@@ -7,8 +7,8 @@ the [dbt-package](/guides/modules-overview/dbt-package) tables, which includes d
test results, Elementary anomaly detection results, dbt artifacts, etc.
In order to visualize the data from
-the [dbt-package](/general/contributions#contributing-to-the-dbt-package) tables, use
-the [CLI](/understand-elementary/cli-install) you can generate the Elementary UI.
+the [dbt-package](/oss/general/contributions#contributing-to-the-dbt-package) tables, use
+the [CLI](/oss/cli-install) you can generate the Elementary UI.
After installing and configuring the CLI, execute the command:
```shell
@@ -111,4 +111,4 @@ test failure, for example on an exposure or a dashboard in the data stack.
The data tests report UI can be sent via Slack, Google Cloud Storage, or Amazon S3 when you
run `edr send-report`.
-Refer to [this guide](/quickstart/share-report-ui) for detailed instructions.
+Refer to [this guide](/oss/guides/share-report-ui) for detailed instructions.
+
+
+
+## How it works?
+1. You install the Elementary dbt package in your dbt project and configure it to write to it's own schema, the Elementary schema.
+2. The package writes test results, run results, logs and metadata to the Elementary schema.
+3. The cloud service only requires `read access` to the Elementary schema, not to schemas where your sensitive data is stored.
+4. The cloud service connects to sync the Elementary schema using an **encrypted connection** and a **static IP address** that you will need to add to your allowlist.
+
+
+##
+
+
+[Read about Security and Privacy](/cloud/general/security-and-privacy)
\ No newline at end of file
diff --git a/docs/x_old/understand-elementary/elementary-report-ui.mdx b/docs/x_old/understand-elementary/elementary-report-ui.mdx
index 2498bb3a9..ae49f10fa 100644
--- a/docs/x_old/understand-elementary/elementary-report-ui.mdx
+++ b/docs/x_old/understand-elementary/elementary-report-ui.mdx
@@ -7,8 +7,8 @@ the [dbt-package](/guides/modules-overview/dbt-package) tables, which includes d
test results, Elementary anomaly detection results, dbt artifacts, etc.
In order to visualize the data from
-the [dbt-package](/general/contributions#contributing-to-the-dbt-package) tables, use
-the [CLI](/understand-elementary/cli-install) you can generate the Elementary UI.
+the [dbt-package](/oss/general/contributions#contributing-to-the-dbt-package) tables, use
+the [CLI](/oss/cli-install) you can generate the Elementary UI.
After installing and configuring the CLI, execute the command:
```shell
@@ -111,4 +111,4 @@ test failure, for example on an exposure or a dashboard in the data stack.
The data tests report UI can be sent via Slack, Google Cloud Storage, or Amazon S3 when you
run `edr send-report`.
-Refer to [this guide](/quickstart/share-report-ui) for detailed instructions.
+Refer to [this guide](/oss/guides/share-report-ui) for detailed instructions.