Vectors corresponding to other language #10013
-
|
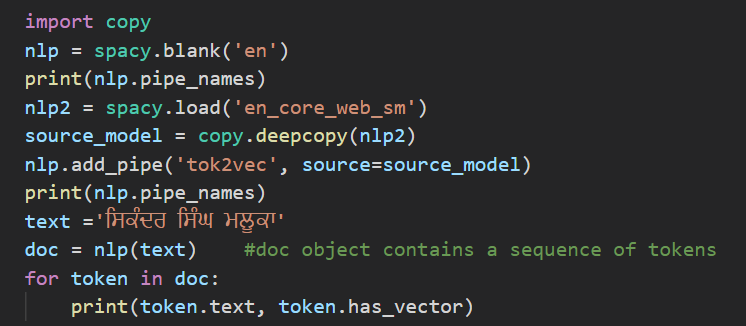
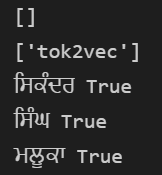
Hi. I have a very basic question. I am creating a blank spacy model with
Although we are using english language then how does it contain vectors corresponding to punjabi language? Please explain. |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 2 replies
-
|
This is a confusing legacy backoff behavior from What you're seeing here aren't static word vectors like from word2vec or glove, but the context-sensitive tensors from the If you download |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the nice explanation. Can you please explain
Actually I am a beginner, so I am sorry if I am asking really basic questions. Thanks. |
Beta Was this translation helpful? Give feedback.
-
|
Please read the docs on pipelines and embeddings, which should answer your questions. |
Beta Was this translation helpful? Give feedback.
This is a confusing legacy backoff behavior from
doc.tensortodoc.vector.What you're seeing here aren't static word vectors like from word2vec or glove, but the context-sensitive tensors from the
tok2veccomponent. Thetok2veccomponent is able to generate a vector for any token, but they're not really useful for anything other than the following pipeline components (tagger,parser). They're not particularly good for word similarity. See the first yellow warning box here: https://spacy.io/usage/linguistic-features#vectors-similarityIf you download
en_core_web_mdoren_core_web_lg, you'll see static word vectors undertoken.vectorwith OOV (all zero) vectors for unknown words like Punja…