Reading results from pipe without blocking the processing of the next batch #10475
-
|
Hello all! I've been trying to implement an efficient way of processing a large number of text batches on GPU using the pipe() functionality of the model. Using the nvidia-smi as the analysis tool, it shows full GPU utilization when the processing of the batch starts, but as soon as it is time to read the results from the pipe generator, it will stop almost all processing while the results are being read. Since the batch size is quite significant, this leads to a long period where the GPU utilization is 0%. It seems like the reading of the results blocks the processing completely. Is there a way to prevent this behavior so that the pipe would start processing the next batch immediately after it has finished processing the previous batch? A short code example to replicate this behavior: import spacy
def data_feeder():
while True:
yield f"This is a test sentence for the spacy transformer GPU utilization test case."
spacy.require_gpu()
model = spacy.load("en_core_web_trf")
if __name__ == "__main__":
for i, result in enumerate(model.pipe(data_feeder(), batch_size=20000)):
result
if i % 10000 == 0:
print(result)Using Nvidia Tesla T4 GPU, this code runs processing for approximately 30-40 seconds and then stops processing for approximately 10 seconds between each batch of 20000 items. |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 1 reply
-
|
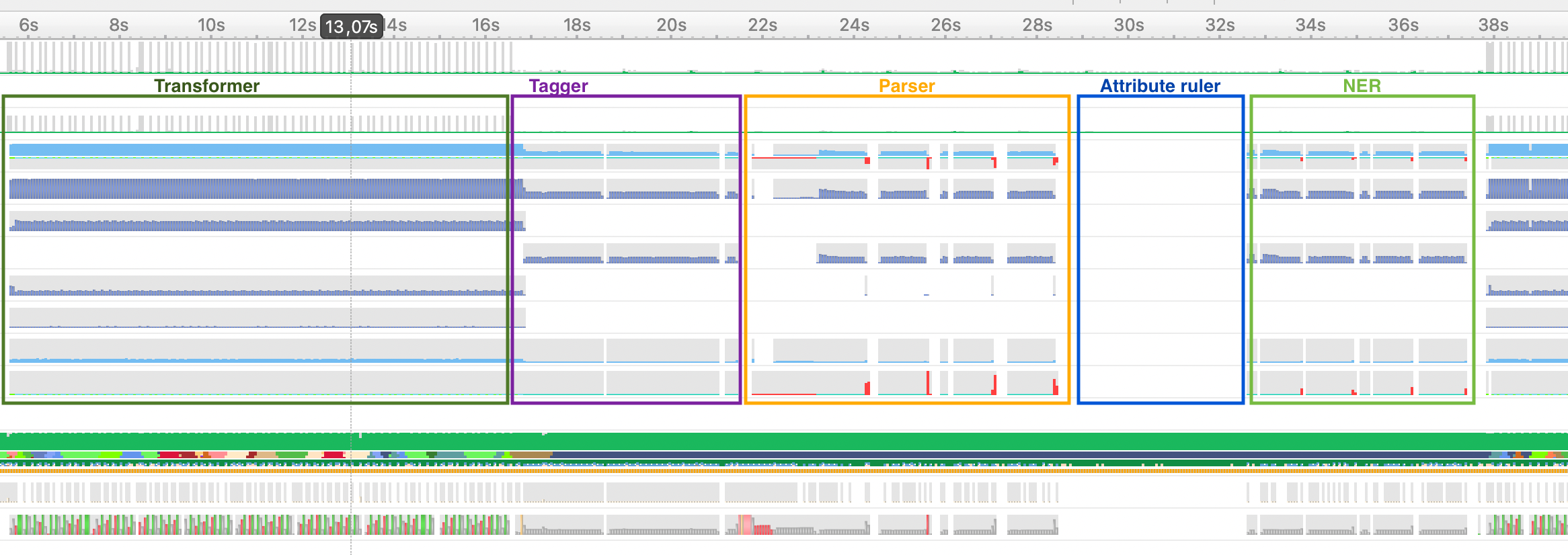
Thanks for providing an example, this makes it much easier to reproduce the issue that you encountered! I have profiled your example for two minutes using Nsight Systems, which gives this GPU utilization profile (I have cut off the initialization/loading of the model):
As you can see, the GPU is mostly utilized, except for three time frames where it's not. I think this is where you are seeing 0% GPU utilization. I zoomed in the profile to one batch, where you can see one time frame with 0% GPU utilization. I have also annotated what spaCy does throughout processing a batch based on the kernels/backtraces:
During the time frame where there is no GPU utilization, the attribute ruler pipe is run. This makes sense, since the attribute ruler is a rule-based pipe that does not use the GPU. Interestingly, the period of no GPU utilization is shorter on my machine (around 4 seconds), but that may be caused by hardware differences (I was profiling on an otherwise unused 5900X). |

Beta Was this translation helpful? Give feedback.
-
|
Many thanks! The answer and the graphs were actually extremely helpful, as it made me realize that I should do only the transformer part on the GPU, then just serialize the intermediate docs to storage and run the latter parts of the pipeline separately on a CPU machine, achieving basically 100% GPU utilization. |
Beta Was this translation helpful? Give feedback.
Thanks for providing an example, this makes it much easier to reproduce the issue that you encountered! I have profiled your example for two minutes using Nsight Systems, which gives this GPU utilization profile (I have cut off the initialization/loading of the model):
As you can see, the GPU is mostly utilized, except for three time frames where it's not. I think this is where you are seeing 0% GPU utilization. I zoomed in the profile to one batch, where you can see one time frame with 0% GPU utilization. I have also annotated what spaCy does throughout processing a batch based on the kernels/backtraces:
During the time frame where there is no GPU utilization, the attribute ruler pipe …