48x Difference between TRF model running in Spacy Vs. HF #10740
-
|
Running the benchmark script provided here: Gives the following results with small/big text files: Note: These are CPU only resultsI'll format it properly in next comment/s, but main things I saw is 48x difference between running in spacy vs. hfI've used colab environment (the infamous one I've set up for #9858 ). How to reproduce the behaviourhttps://github.com/explosion/projects/blob/v3/benchmarks/speed |
Beta Was this translation helpful? Give feedback.
Replies: 7 comments 2 replies
-
|
Hi, can you try running the benchmark again after downloading the project assets ( The WPS ratios do not look that different overall though? 20x in your short example vs 15x in our table? A lot of the exact details depend on the CPU and environment in ways that are hard to replicate exactly, in colab especially I bet. (As another data point, locally with 10000 texts I see a 10x difference.) |
Beta Was this translation helpful? Give feedback.
-
Hi, sorry about not updating about the testing environment yesterday - It doesn't look to be quadratic though - only ratio seems really high - 40x and up to 60x pretty constantly, with spikes to 75x. I'll be sharing colab notebook soon, but results are reproducible also on my local machine. Note that I won't forget: Had to change benchmark project a bit as |
Beta Was this translation helpful? Give feedback.
-
|
Testing code is: import en_core_web_lg
import en_core_web_trf
nlp_lg = en_core_web_lg.load()
nlp_lg("warm up")
nlp_trf = en_core_web_trf.load()
nlp_trf("warm up")
nlps_to_run = [
nlp_lg,
nlp_trf
]
import urllib
large_txt_url = "https://www.gutenberg.org/cache/epub/15466/pg15466.txt"
large_txt = urllib.request.urlopen(large_txt_url).read().decode('utf-8')
print(f"Large text length is {len(large_txt)}")
import timeit
piece_size = 200
for p in range(1, 20):
cut_text_to_parse = large_txt[:piece_size*p]
times = []
for nlp in nlps_to_run:
results = timeit.timeit(lambda: nlp(cut_text_to_parse), number=3)
times.append(results)
print(f'For text of length {len(cut_text_to_parse)} it took {nlp.meta["name"]}\t{results:.2f} seconds')
print(f"Ratio between the 2 models running on {len(cut_text_to_parse)} is {int(times[1]/times[0])}") |
Beta Was this translation helpful? Give feedback.
-
|
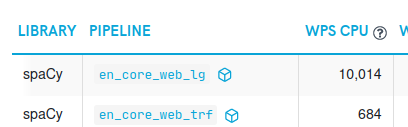
Results from one of the runs: |
Beta Was this translation helpful? Give feedback.
-
|
Colab notebook: |
Beta Was this translation helpful? Give feedback.
-
|
With GPU, ratio seems to be ~2 constantly. |
Beta Was this translation helpful? Give feedback.
-
|
Let me move this to the discussion board... |
Beta Was this translation helpful? Give feedback.
-
|
Why is that a discussion? |
Beta Was this translation helpful? Give feedback.
-
|
The benchmark script was written for shorter texts like the provided assets and for the |
Beta Was this translation helpful? Give feedback.
Hi, can you try running the benchmark again after downloading the project assets (
spacy project assets) so that there are more texts to benchmark? This just really isn't enough texts/time to be a meaningful comparison. To be honest, even the provided default of 1000 texts is a bit a low. Something that runs for at least a few minutes in each instance would provide a more useful comparison.The WPS ratios do not look that different overall though? 20x in your short example vs 15x in our table? A lot of the exact details depend on the CPU and environment in ways that are hard to replicate exactly, in colab especially I bet. (As another data point, locally with 10000 texts I see a 10x differ…