Question about segmentation #10792
Replies: 2 comments
-
|
When sharing text please copy and paste it as text, do not share screenshots of text.
No, the
Since the That said, your Korean tokenization doesn't look like there's any reason it would be a problem in particular.
|
Beta Was this translation helpful? Give feedback.
-
|
I think there are two separate issues/questions here:
|
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Hello! I'm developing a Korean dataset and I was wondering if
#textmetadata part of theconllufile is taken into account during the training & evaluation processes.Would it cause an error if the number of words in the
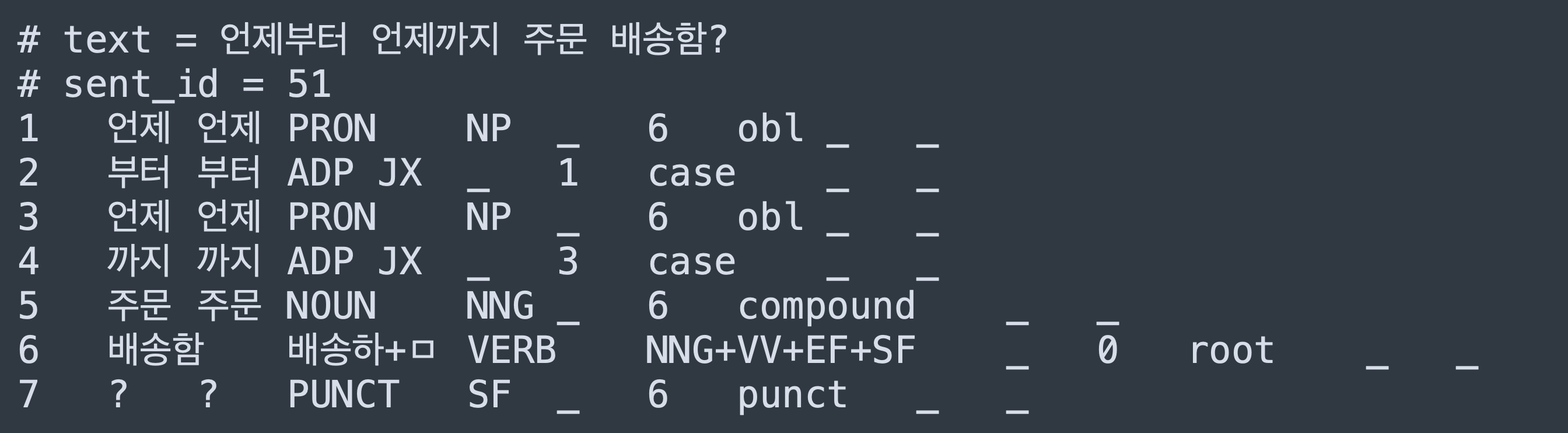
#textdoes not match with the actual number of words in the analysis? For example, if the sentence in the#textwould be언제부터 언제까지 주문 배송함?(From when to when will the order be delivered?) and it would be analyzed into separate tokens such as언제,부터,언제,까지,주문,배송함, as shown below:I saw a similar analysis happening in the Japanese GSB dataset and I was wondering if breaking a sentence without space into separate tokens cause an error during the training & evaluation processes or does it help the
spacy-transformermodel (xml-roberta-base) learn some form of segmentation?Beta Was this translation helpful? Give feedback.
All reactions