Word spacing/word segmentation model #10973
Replies: 2 comments 6 replies
-
|
For the spaCy Korean pipelines, we use If you want to train a model to do this from scratch in spaCy, the easiest way to do it would be to put a space between every character and use NER labels on them, essentially labelling each space-delimited chunk as an entity. You could then train the model to reproduce those labels, which would let you figure out where spaces should go in inputs. It would be easy to set that up, but the NER model wasn't really designed to be used that way, so I'm not sure it would work well. You could maybe also use the SentenceRecognizer, which handles a similar problem where you have a single class. In the past I think there was an experimental tokenization component, but it hasn't been worked on in a while. I believe the |
Beta Was this translation helpful? Give feedback.
-
|
To add a few notes: There is an experimental trainable tokenizer using NER like Paul described: https://github.com/explosion/spacy-experimental/tree/v0.5.0#character-based-ner-tokenizer. It works well for languages with whitespace where it's mainly learning how to split off punctuation, but when I tried it for Chinese it didn't work very well. It's possible it might work a little better for Korean where grammatical suffixes might be easier to identify as word boundaries, but I'm not sure, and my guess would be that tools like The |
Beta Was this translation helpful? Give feedback.
-
|
The NER example is just for explanation (the actual tag/NER part is entirely internals). You just have to create normal |
Beta Was this translation helpful? Give feedback.
-
|
Oh, I see thanks! One more question: how does one use the trained tokenizer? I've tried to pip install and used via
|
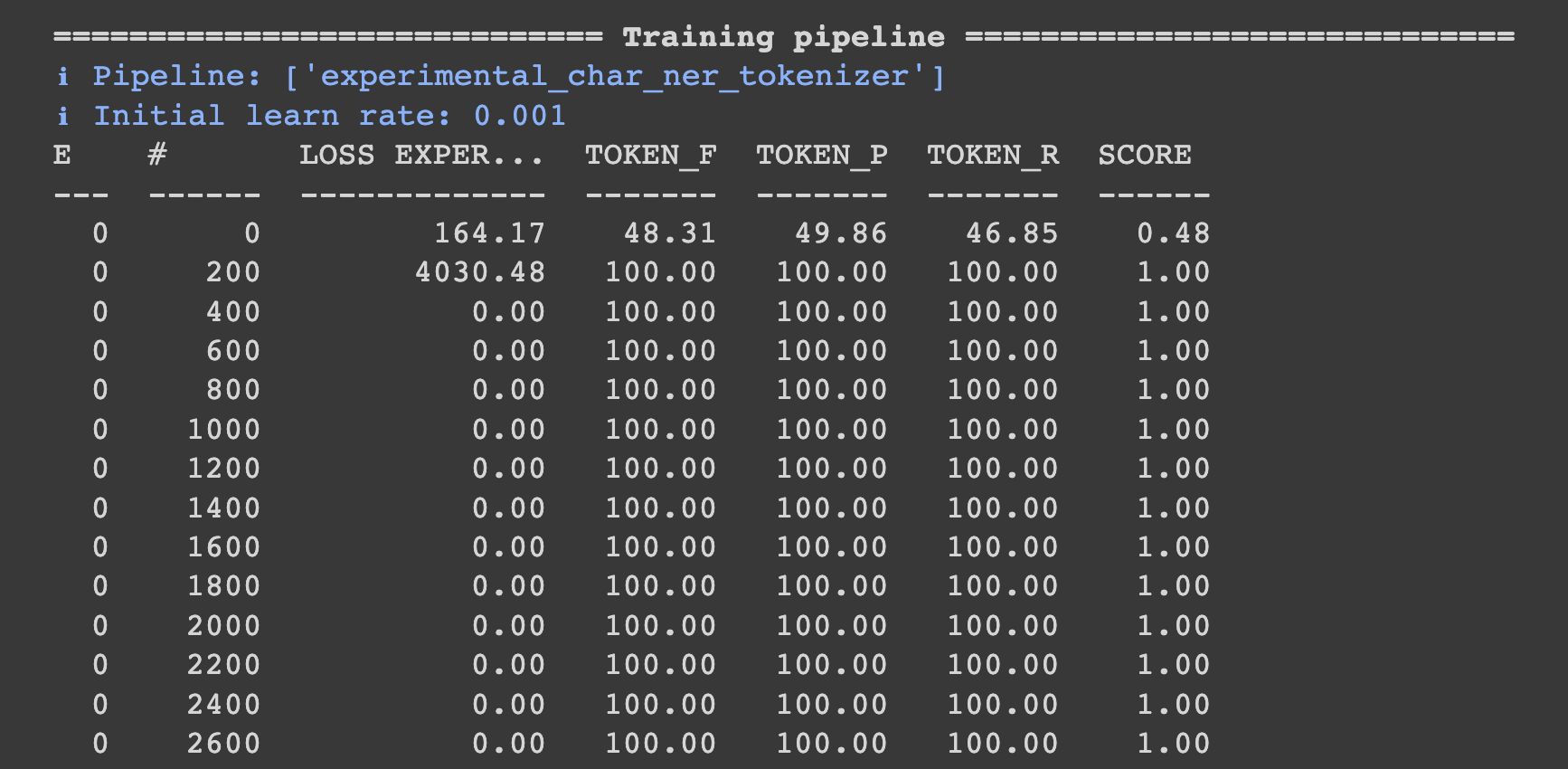
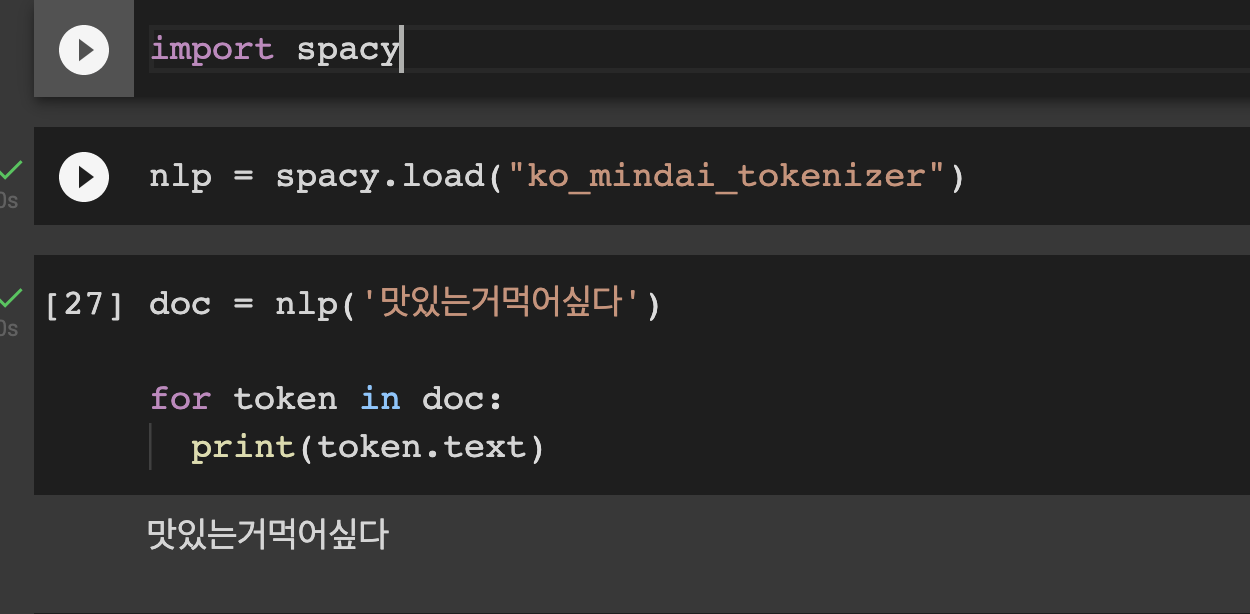
Beta Was this translation helpful? Give feedback.
-
|
It's really hard to know what's going on from screenshots, especially without more context. (In general, please copy and paste text as code blocks instead of using screenshots!) My first guesses would be either that your training docs don't have the right tokenization or that you're not loading the right model in your test? I'm sure that this component works in the UD benchmarks example project and in the |
Beta Was this translation helpful? Give feedback.
-
|
Sorry, I'll paste the code from now on. I have used the Below is the short piece from conllu file that gets converted to Also, in the example you've provided the English text is |
Beta Was this translation helpful? Give feedback.
-
|
Without So it's only learning to split on whitespace. As I said at the top of this thread, I don't think these particular tokenizers will work well for cases without whitespace. I'd be curious to hear about the results for Korean, but I haven't tried it myself. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
I was wondering if there is a way to train Tokenizer to split the text without any space? For example, in Korean people often type without any white space and an input text can look like "맛있는음식먹어싶다" which translates to "I wanna eat tasty food." Is there a way to train the model to split "맛있는음식먹어싶다" into "맛있는 음식 먹어 싶다"?
Beta Was this translation helpful? Give feedback.
All reactions