Word "id" represented as two tokens #11154
Answered
by
polm
sillentkill21
asked this question in
Help: Coding & Implementations
-
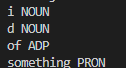
How to reproduce the behaviour`import spacy nlp = spacy.load('en_core_web_sm') doc = nlp("id of something") for token in doc: Your Environment
Additional infoAfter testing the word "id" in multiple situations, the results were the same. Word "id" was represented as two tokens "i" and "d". Is this the expected behavior?
|
Beta Was this translation helpful? Give feedback.
Answered by
polm
Jul 19, 2022
Replies: 1 comment
-
|
This is intended behavior, see #10455. The English tokenizer treats "id" as a typo for "I'd" by default, though you can change it. |
Beta Was this translation helpful? Give feedback.
0 replies
Answer selected by
polm
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
This is intended behavior, see #10455. The English tokenizer treats "id" as a typo for "I'd" by default, though you can change it.