Training data for spancat #11351
-
|
Wanted to try out spancategorizer for a text dataset with overlapping entities but can't seem to find anywhere as to how the training data format looks like. Can someone possibly share a training.jsonl file so as to ease this process? |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 3 replies
-
|
Hi @RandomArnab , In spaCy v3, we use the serialized .spacy files instead of JSONL. To prepare the training data for span categorization, you need to assign entities in the import spacy
from spacy import displacy
from spacy.tokens import Span
text = "Welcome to the Bank of China."
nlp = spacy.blank("en")
doc = nlp(text)
doc.spans["sc"] = [
Span(doc, 3, 6, "ORG"),
Span(doc, 5, 6, "GPE"),
]To serialize them into a You can check some of our spaCy projects to better understand this process. We have one for overlapping spans. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks a lot! |
Beta Was this translation helpful? Give feedback.
-
|
Hello, I am working on a NLP project using spacy where i am trying to use the SpanCat component. I already used ner but i am unable to get the desired performance. I prepared my training data for SpanCat using the method mentioned in this post and the several other posts including using SpanGroup, however when i train my model using these train.spacy and dev.spacy files, my model does not seem to provide any scores. PFB output while training my model: Below is my code: I tried different combinations by playing around with the default config file generated for spancat but none of them work. I tried using the spacy files from the projects provided by spacy(experimental/ner_spancat) and spancat seems to train properly for those spacy files. Can someone please provide me pointers where i might be going wrong in preparing the training data? TIA |
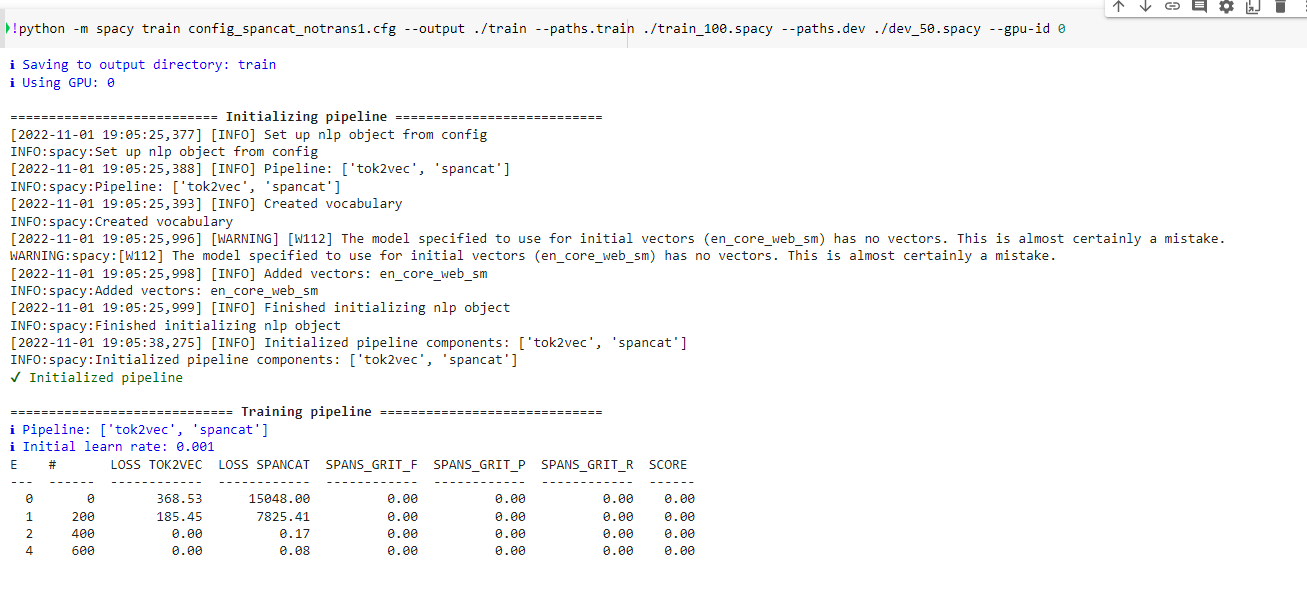
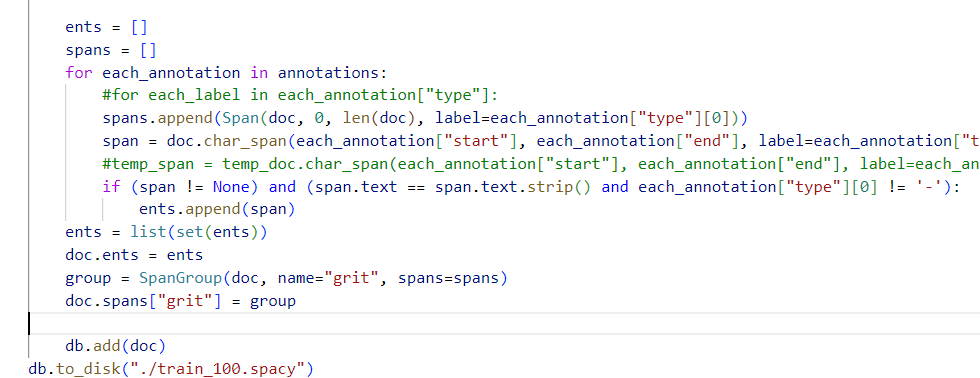
Beta Was this translation helpful? Give feedback.
-
|
Hey, please do not post the same question in multiple threads. We will follow up in #11731. |
Beta Was this translation helpful? Give feedback.
Hi @RandomArnab ,
In spaCy v3, we use the serialized .spacy files instead of JSONL. To prepare the training data for span categorization, you need to assign entities in the
doc.spanattribute. Here's an example below for an example sentence "Welcome to the Bank of China":To serialize them into a
.spacyfile, you need to collect them inside aDocBinobject and call theto_disk()method. Something like this: