Fastest way to split a sentence to tokens #11944
-
|
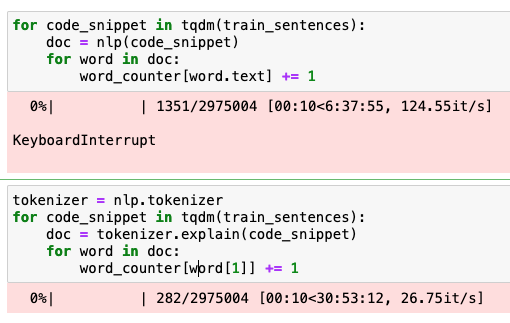
Hello everyone. I want to split a sentence into tokens using the language model/tokenizer. From my understanding there are 2 approaches I can use (1)iterate over the tokens in When I compare the performance of the 2 approaches, I see an interesting behavior, approach (1) is X4.5 times faster!
Adding the snippet of the experiment, note that BTW I know about pipe, want to compare the two methods for single text
|
Beta Was this translation helpful? Give feedback.
Replies: 1 comment
-
|
Please don't post screenshots of code or terminal output, post them as text.
In spaCy, generally the fastest way to tokenize things is basically to use a blank pipeline (like |
Beta Was this translation helpful? Give feedback.
Please don't post screenshots of code or terminal output, post them as text.
nlp.tokenizer.explainis not intended for normal tokenization, it's used to explain or debug the output of the tokenizer. It is not intended to be efficient, and is not the normal way to use the tokenizer.In spaCy, generally the fastest way to tokenize things is basically to use a blank pipeline (like
spacy.blank("en")) which just runs the tokenizer. You can also just call the tokenizer directly (nlp.tokenizer(text)). Note that spaCy tokenizers don't use the language model.