How do I retrieve spacy's compound words? #11969
-
|
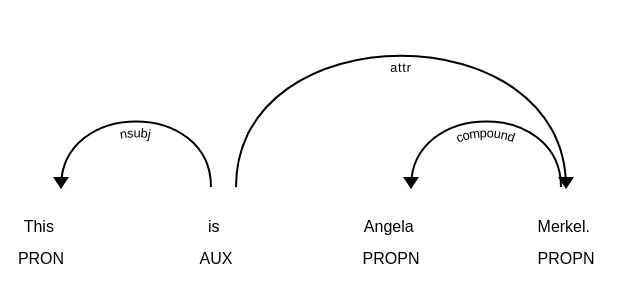
Hi! I am currently trying to retrieve any compound words from my sentence. For example, I will have a sentence such as "This is Angela Merkel" and would get pos tags (simply printing the texts) such as: This this PRON DT nsubj Xxxx True True
is be AUX VBZ ROOT xx True True
Angela Angela PROPN NNP compound Xxxxx True False
Merkel Merkel PROPN NNP attr Xxxxx True False
. . PUNCT . punct . False FalseNow I know and can see using the visualizer that Angela is compound to Merkel, but I don't quite understand yet how I find this information using just Python. Could someone point me there? My test script: import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is Angela Merkel.")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)answered in subthread / subcomment #11969 (reply in thread) |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 3 replies
-
|
The There's not a special function for getting words marked with the |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your answer! However, it is not quite what I need. Yes, accessing if STRING is compound:
return all STRING2 that STRING is compound toObviously I might have more complex sentences in the actual situation, possibly containing multiple compound words which are not following right behind each other. Merging the words wouldn't really be working for me as I don't want or need them merged and still prefer them all separate. |
Beta Was this translation helpful? Give feedback.
-
|
Ah, OK, thanks for explaining - that shouldn't be very hard then. You can do something like this: You could also use the DependencyMatcher. |
Beta Was this translation helpful? Give feedback.
-
|
Your snipped already did it! Thank you! |
Beta Was this translation helpful? Give feedback.
The
compoundrelation is a dependency relation and is set by the (dependency) parser, you can access it withtoken.dep_.There's not a special function for getting words marked with the
compoundrelation, butmerge_noun_chunksshould merge compound words (in addition to other chunks).