TRF: Inference on larger documents, investigation/tips/tricks #12109
Replies: 2 comments 2 replies
-
|
Thank you very much for the detailed write-up of your investigation and your suggestions! We'll take a closer look at the aforementioned issue(s) and get back to you once we have more information. In the meantime, please feel free to add the timing info (and more context, if any) to this thread. |
Beta Was this translation helpful? Give feedback.
-
|
Hi Thanks for the reply! I was running out of time yesterday, so submitted before I was fully ready, to not loose the waffle. The original post has been updated somewhat, with graphs showing timing info (non-scientific, so the raw numbers don't mean too much), and with another approach that seems to perform better. As mentioned, I'm not really expecting these changes to land in spacy (it would be nice!) but maybe it might help with other investigations and/or ideas for mangaging memory for people parsing larger docs. Thanks! |
Beta Was this translation helpful? Give feedback.
-
|
Our general-purpose advice is to split up long documents for processing, in particular because most NLP tasks don't benefit from huge amounts of context. (You don't need the previous 100 pages of context to predict that a span is an entity, usually only a paragraph or a page/section is sufficient.) If you use batching with Note that Note some related discussions: |
Beta Was this translation helpful? Give feedback.
-
|
Hi, thanks for the comments, totally agree about splitting up, and we can do that, although it does make the implementation code a lot more complex for us, becuase we really care about sentence integrity, so splitting up and maintaining sentence boundaries isn't as trivial as it sounds (also not impossible, I'm being lazy :) ). In this particular case, I actally plan on detecting and stripping out code/stack traces intermingled with the text, which would solve the problems we're having, but that's a whole other piece of work! The thing that drew me into the analysis was the fact that for certain sized-documents, parsing it once works, but parsing it twice in succession does not, which was a bit surprising, and looked a bit like a bad memory leak (rather than a cache issue) Re the |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I've spent a while trying to understand some weirdness with Spacy memory usage, and wanted to share some findings:
Background, we have a service that is processing large(ish) numbers of externally generated texts in a loop. Many of these texts are quite noisy, (and we can/should preprocess the noisier ones more than we are). The job converts text to a doc, extracts the relevant information and then discards the doc/spacy objects entirelty before processing the next one.
A batch job was failing on a 600k text as part of a loop, but parsing that text on its own passed, which was weird.
finding 1
Thinc/cupy seems somewhere to be retaining a reference to the Tensor underpinning the last processed doc even after that doc has gone away and/or been GC'd:
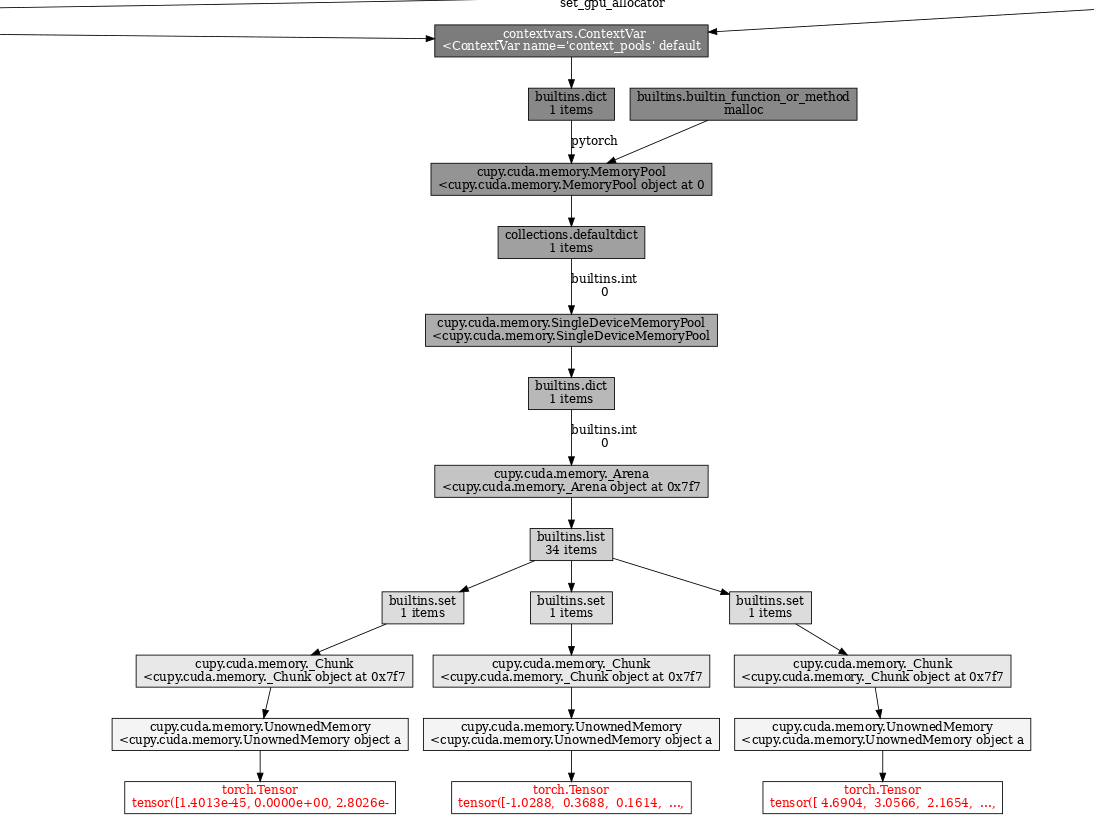
It looks a bit like it's some sort of buffer cache/re-use or similar, but this memory doesn't appear to be freed/re-used early in the processing cycle of the next doc, so this can contribute to memory exhaustion (although it doesn't look like an unbounded leak either, because if you process a short doc, total retained memory goes down).
I had success with two techniques here:
and/or 2. Processing a sacrificial short document after a heavy one, to clean up the residual memory:
finding 2
Spacy splits long documents into spans using
get_spans(https://github.com/explosion/spacy-transformers/blob/master/spacy_transformers/layers/transformer_model.py#L167) which, as far as I can tell, ends up callingget_strided_spans. This seems to be to accommodate transformers models' fixed window size, but can also be used to do inference in batches.Currently, the entire text is passed to the model in one batch, which adds a strict limit on the size of text that can be processed. By processing the flat_spans in batches, and them combining the tensors before passing back to thinc, we can fit in many more tokens, by keeping a limit on the Roberta hidden layer sizes.
Ideally this chunking would be passed up the stack furter, but this may be hard to do!.
By modifying the following in transformer_model:forward()
To read (This could be cleaner, but is proof of concept):
With relevant trivial implementations of make_batches, and merge_outputs, then we can process much more.
(NOTE: chunk size of 384 chosen here to comfortably accomodate 24gb of gpu ram)
Experiment
Another approach is to keep the thinc/spcy side cpu only, but run the transformers model on the GPU (for our use-case running transformers on the CPU is prohibitively slow).
This does significantly increase the RAM consumption of the processing, but this is easier to scale than gpu memory.
Results
I have three scripts:
Test Scripts.zip
v1: Simply process text twice, calculate maximum GPU memory afterwards, calculate time taken to parse second time.
v2: same as v1, but:
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:256, sacrificial document parsed between main document parses, clear memory pool, add chunked transformer code to model forward. (some of this may be redundant!)v3: spacy is set to
require_cpubut modifications made to run the transformers model on the GPU, in 384 span chunks.Each script was run against different sizes of input text, and the max GPU memory and time taken recorded (This ins't particularly scientific, each combination was run once, and in a basic docker environment. the server wasn't doing much else, but it wasn't massively controlled test env, this is indicative measurements). Input sizes were increased until the script stopped running (due to memory exhaustion)
In these graphs, we can see that v2 and v3 have massive vRAM knees around the 400k character mark. This is where the batching kicks in and starts reducing the memory load. v1 stops working (on 3090) at around 400k (The reason it seems to stop at 15gb vram appears to be due to alloc fragmentation), v2 gets to about 5.1million and v3 is flat to 10million.
Zooming in on the more standard range (0-400k):
We can see that memory usage is approx equivalent in this range (I think the alloc split seems to push the v1 higher, but this is really a tuning parameter), and the runtime shows that v1 and v2 are roughly equal, whereas v3 incurs the cost of moving data between the gpu and back much more.
Desired Outcome
I'm not sure really. Internally we will fold some of these changes into our code, but there are reasons why doing this properly within spacy will be harder (these changes only look at inference, applying to training will be hard, and you migth end up with two codepaths otherwise).
It would be nice if the retained cupy references to the tensors could be somehow made to go away.
I've written up the detail here in case it helps other people who may be looking at similar things.
Beta Was this translation helpful? Give feedback.
All reactions