Custom model took more time to load than model standard pipeline #12111
-
How to reproduce the behaviourmy custom model took more than 10 second to load, but en_core_web_trf and en_core_web_lg jus few second.
and then i tried on my laptop, the result is the same took more 10 second for custom model how to reduce the load time? Your EnvironmentGoogle Colab:
Laptop:
|
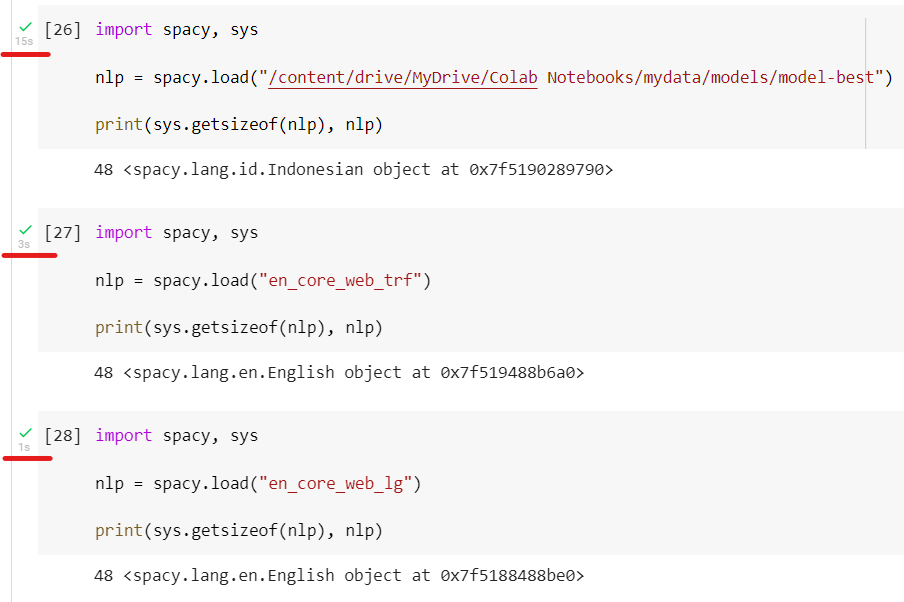
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 7 replies
-
|
This is due to differences in the default If this is a major concern on your end, you can consider customizing the tokenizer settings (https://spacy.io/usage/training#custom-tokenizer), but changing the tokenization can cause misalignments with your training data that can have a big effect on the model performance, especially for token-level annotation like tags and parses. So keep an eye on the (As a side note, |
Beta Was this translation helpful? Give feedback.
-
|
when im training model using but im not only using texcat, in the future i will combine |
Beta Was this translation helpful? Give feedback.
-
|
what if i load the every model first
and then store so the api endpoint not load the model in every request, but get data from the storage something like redis? is it possible to save the loaded models in something like redis ? |
Beta Was this translation helpful? Give feedback.
-
|
You would use Usually you would want to have the models preloaded for your API if possible, to improve the speed. |
Beta Was this translation helpful? Give feedback.
-
|
is it possible to save models preloaded in something like redis or mysql, mongo ? look like: |
Beta Was this translation helpful? Give feedback.
-
|
You can save the config + model bytes, here's what that looks like: https://spacy.io/usage/saving-loading#pipeline |
Beta Was this translation helpful? Give feedback.
This is due to differences in the default
EnglishandIndonesiantokenizer settings. The Indonesian defaults include a large number of exceptions to handle cases like"aba-aba", which take longer to load.If this is a major concern on your end, you can consider customizing the tokenizer settings (https://spacy.io/usage/training#custom-tokenizer), but changing the tokenization can cause misalignments with your training data that can have a big effect on the model performance, especially for token-level annotation like tags and parses. So keep an eye on the
token_*scores for your training data while modifying this.(As a side note,
sys.getsizeof()isn't going to give you any useful info in…