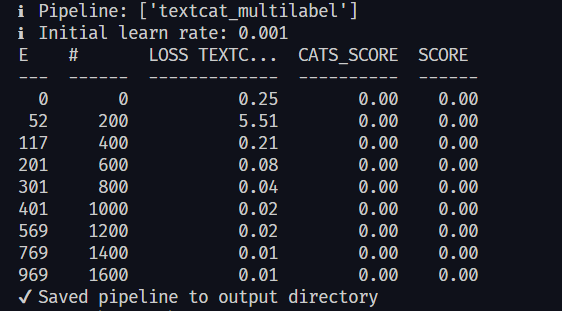
After training process all CATS_SCORE and SCORE has 0.00 #12167
-
|
First step i have already create code to convert csv file to binary spacy, the code look like this and then run cli command for convert csv to binary and cli command for training but the result all CATS_SCORE and SCORE got 0.00
i'm missing something on the code? the code above im updated from spacy project: |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 4 replies
-
|
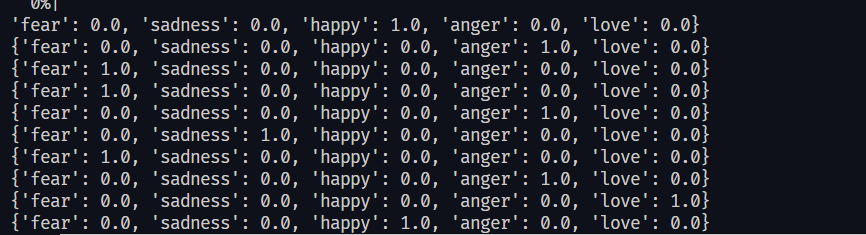
You are reusing the same dictionary for every instance: data_label = {}
# ...
nlp = spacy.blank(lang)
db = DocBin()
for text, label in tqdm(data, total=len(data)):
data_label[label] = 1.0 # <- HERESo, eventually all labels will be set to a probability of 1.0 and all documents will have the same label dict. So, each doc will have a probability of 1.0 for all labels. You could fix this issue by making a copy of the label dict for each doc and setting the label in the copy. |
Beta Was this translation helpful? Give feedback.
-
|
@danieldk thank you for the response i use dictionary to avoid hard coded using if else and the result look like this if i print
|
Beta Was this translation helpful? Give feedback.
-
|
Ah, right, missed that. But the underlying issue is still the same. Every doc gets the same dict, so when you do you are also resetting the label in the doc you just added to the |
Beta Was this translation helpful? Give feedback.
-
|
@danieldk thank you for the explanation, i understand but.. any suggest to improve this code to be better ? |
Beta Was this translation helpful? Give feedback.
-
|
Rather than reinitializing the dict every iteration, you could also do it once and copy it over. E.g. (untested): |
Beta Was this translation helpful? Give feedback.
You are reusing the same dictionary for every instance:
So, eventually all labels will be set to a probability of 1.0 and all documents will have the same label dict. So, each doc will have a probability of 1.0 for all labels. You could fix this issue by making a copy of the label dict for each doc and setting the label in the copy.