Predict text using REST API with ability to change model #12279
Replies: 5 comments 3 replies
-
|
update:
but when i think when i do (method 2 above) so this proses just like method 1, slow. any suggest? but i don't to do this https://stackoverflow.com/questions/61643370/spacy-english-language-model-take-too-long-to-load because i assume my total model will increase, not just one or two model. |
Beta Was this translation helpful? Give feedback.
-
|
Hey, Let me try to understand your problem better. Seems like you have a selection of models and each API call takes a model name and a piece of text. My first question here is whether it would be possible to cache the models in memory? The simplest and most memory intensive approach would be to keep all models in memory at all times. A potentially more viable approach is to use an LRU cache policy perhaps? This would mean that you keep at most a fixed number of models in memory and when the cache is full you release the model that was used the least recently. If the caching approach is viable maybe its worth reviewing the various cache replacement policies for inspiration: https://en.wikipedia.org/wiki/Cache_replacement_policies. |
Beta Was this translation helpful? Give feedback.
-
|
hey @kadarakos thank you for the response. how do best practice this is what i know: and then if i have another model 2, i should update the code and then restart server again and then if i have another model 3 , i should update the code and then restart server again... the problem is
|
Beta Was this translation helpful? Give feedback.
-
|
This is not really an issue with The prediction speed can be improved by disabling components that are not required by your application for example: The loading can be made faster and reduce memory usage by relying on smaller models especially with smaller vector tables. |
Beta Was this translation helpful? Give feedback.
-
|
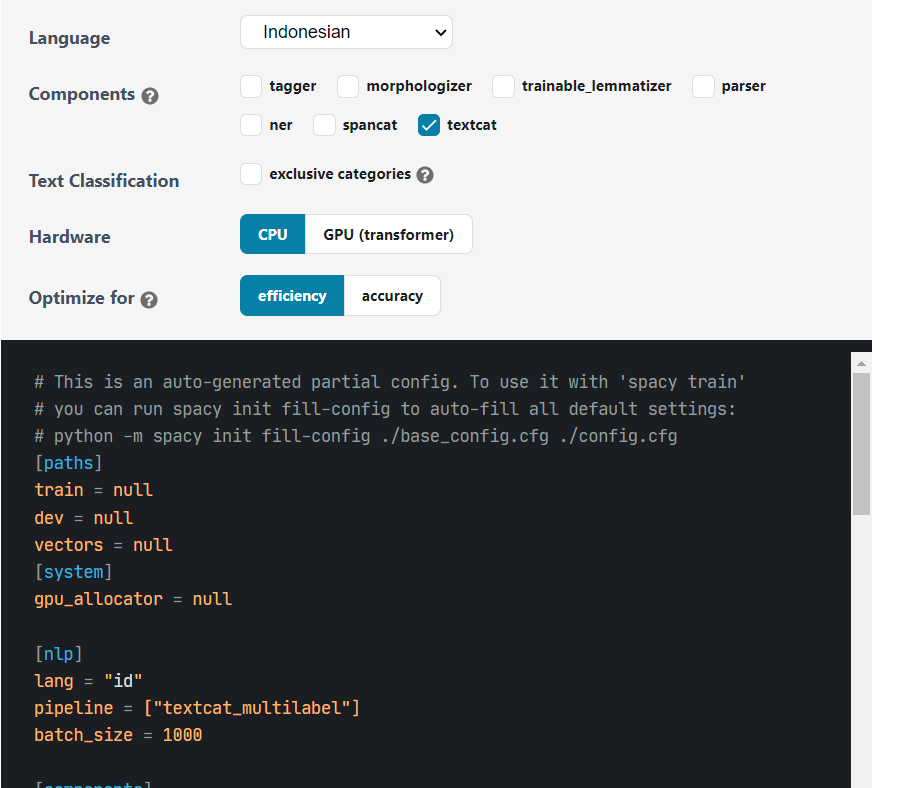
hi @kadarakos for prediction speed not my issue but my concern is when i do this is my config for training, i use
|
Beta Was this translation helpful? Give feedback.
-
|
First thing I can think about is that the import spacy
import time
class time_context:
def __enter__(self):
self.start = time.perf_counter()
return self
def __exit__(self, type, value, traceback):
self.elapsed = time.perf_counter() - self.start
def speed_test_load_blank(lang, it):
with time_context() as elapsed:
for i in range(it):
spacy.blank(lang)
print("blank time", elapsed.elapsed/it)
def speed_test_load_model(model, it):
with time_context() as elapsed:
for i in range(it):
spacy.load(model)
print(f"{model} time", elapsed.elapsed/it)
speed_test_load_blank("id", 10)
speed_test_load_model("en_core_web_trf", 10)On my machine this gives the output: |
Beta Was this translation helpful? Give feedback.
-
|
i'm sorry what i mean is when i say my machine
google colab
btw how look like tokenizer settings for lang |


Beta Was this translation helpful? Give feedback.
-
|
Unfortunately I cannot really debug the slow loading time without knowing more about the model. I agree that its quite slow. If you would like to focus on debugging the loading time of the You can try excluding various pipeline components to identify which one seems to be the bottleneck: https://spacy.io/usage/processing-pipelines#disabling. You can try adding more to the coarse speed benchmarking script: import spacy
import time
class time_context:
def __enter__(self):
self.start = time.perf_counter()
return self
def __exit__(self, type, value, traceback):
self.elapsed = time.perf_counter() - self.start
def speed_test_load_blank(lang, it):
with time_context() as elapsed:
for i in range(it):
spacy.blank(lang)
print("blank time: ", elapsed.elapsed/it)
def speed_test_load_model(model, it=10):
with time_context() as elapsed:
for i in range(it):
spacy.load(model)
print(f"{model} time: ", elapsed.elapsed/it)
def speed_test_load_exclude(model, it=10):
speed_test_load_model(model, it)
components = spacy.load(model).components
for name, _ in components:
with time_context() as elapsed:
for i in range(it):
spacy.load(model, exclude=[name])
print(f"without {name}: ", elapsed.elapsed / it)
speed_test_load_exclude("en_core_web_trf", 3)On my machine this gave: About the question of your web app, I'm afraid its hard to help further since its a design and infrastructure decision whether you can add more resources to be able to keep all models in memory or you prefer to use a cache or some other option. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
let say curently i have 10 model and the model i have will increase 11, 12, 13, 50 ... model and the languange is ID
Method 1
so i will consume the model using REST API the parameter look like this:
the code for API will look like this
but the problem with that code, the request to predict is slow because
everytime i send the text and chose model name, it will load the model and the respone time will slow to.
Method 2
because problem with method 1, i try to change the method:
load model and consume model in diferent API
i will choose the model first with this API, to load model once
i will predict text with this API but still send model_name for model i have load before
i try split two proses for beter response time when i predict the text
but i canont save load model to database, i have try to save using mongodb but i got error
how to save
spacy.load()result to database?any sugest to handle case like this?
Note:
Beta Was this translation helpful? Give feedback.
All reactions