Huge losses while Training Spacy Custom Model #12280
-
|
I tried to create a new spacy model and train it with a custom dataset but received huge losses while training. How can I fix the issue and get it trained correctly? Length of the training data seems more than 1000 samples ex training data: Here is my Code: |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 6 replies
-
|
Hey, Thanks for the question! Let me focus on the example data first: data = [
("AGS", {"entities": [(0, 3, "CUST")]}),
("YML SERVICOS LTD", {"entities": [(0, 16, "CUST")]}),
("BORG GROUP", {"entities": [(0, 10, "CUST")]}),
("GRABCRANEX", {"entities": [(0, 10, "CUST")]}),
("GREEN SHIP", {"entities": [(0, 10, "CUST")]}),
]If I understand correctly the texts here are the names of entities and not documents. When training a named entity recognizer the goal most often is to find the names of entities within texts. As such the methodology is to annotate the texts with entities and not to only expose the model to the entities themselves. What you have here is a list of entities and you can look at the In terms of the value for the loss. Do I understand correctly that this is the same question: https://stackoverflow.com/questions/75459001/spacy-train-the-existing-model-with-custom-data? The loss seems to be around assert 1.6 * 10**-8 == 1.6e-08You can ask Python to show the actual number with: print(f"{1.6e-08:.10f}")The output should be If I'm getting it right then the loss is really low. |
Beta Was this translation helpful? Give feedback.
-
|
Happy to hear the model works better now! What you are doing now in my understanding is to generate a synthetic training corpus for your model. To get better performance on realistic data that your model will encounter it would be good if you could annotate real data. Our colleague has published a really nice post on how he bootstrapped NER annotation for the Tagalog language https://ljvmiranda921.github.io/notebook/2023/02/04/tagalog-pipeline/. It can be time consuming for sure to annotate real data, but working exclusively with synthetically generated data leads to this situation that you've noticed is that its hard to include the different kinds of real-world situations your model will encounter in your data generation algorithm. Something that you could look into as well is weak-labeling for NER: https://spacy.io/universe/project/skweak. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @kadarakos , Thank you for the reply, I had reviewed the above links and it was very useful. Will try that. And also, I have a quick question, I have trained my model without any punctuations. so while testing it, it didn't detect any customers that comes with comma or dot in the middle. So, how can I overcome this issue?? FYI, I also tried training the model by not removing the punctuation in training data. But receiived huge loss like more than 70.44** and also model didn't detect any words correctly. |
Beta Was this translation helpful? Give feedback.
-
|
I'm sorry, but I can only kind of reiterate. The main idea is to train your models on data that you think will naturally occur. You might have pre-processing steps you apply to the data and potential post-processing steps you apply to the model. In that case again its important that the model sees the pre-processed data and that you evaluate on the post-processed output. The bottom line is: you have to make sure the model is trained on the kind of data you will feed to it in practice and that you evaluate in a way that is again matching the circumstances of your application. Concretely, its a good idea in general to train with punctuation. If you have some sort of pre-processing step that removes punctuation then you have to make it part of your pipeline so that your model receives the kind of input at test time as during training time. |
Beta Was this translation helpful? Give feedback.
-
|
@kadarakos Thank you for the reply. I trained the model with the punctuations but while training I received very high losses. I have attached the snapshot below. Even after training more than 100 epochs, I'm getting huge losses. Is there anyway, Can I check whether my data is correct?? The format of the data is correct but not sure why the model is not learning. I have kept the batch size as |
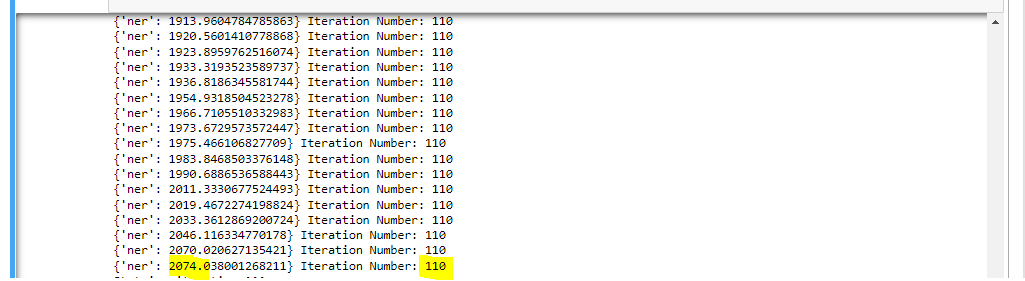
Beta Was this translation helpful? Give feedback.
-
|
Hey @Pravin770, the loss by itself is not very meaningful - I feel like you're unnecessarily focused on it. Ideally you'd also be evaluating your trained model on an independent dev set at each iteration, and the F-score or accuracy for that should be going up as you train - that is the best way to evaluate whether your model is in fact learning properly. |
Beta Was this translation helpful? Give feedback.
Hey,
Thanks for the question! Let me focus on the example data first:
If I understand correctly the texts here are the names of entities and not documents. When training a named entity recognizer the goal most often is to find the names of entities within texts. As such the methodology is to annotate the texts with entities and not to only expose the model to the entities themselves.
What you have here is a list of enti…