Problem in retraining spacy for sentence splitting #12573
Answered
by
adrianeboyd
nikhilajoshy
asked this question in
Help: Other Questions
-
|
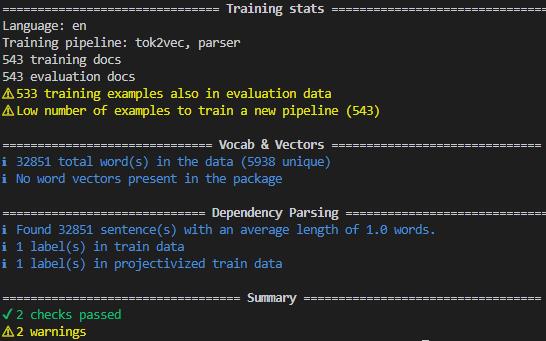
I created training data using But when I debug config file, I am getting this why is training data split as one word per sentence?? |
Beta Was this translation helpful? Give feedback.
Answered by
adrianeboyd
Apr 25, 2023
Replies: 1 comment
-
|
For data where you have set sentence boundaries with (The |
Beta Was this translation helpful? Give feedback.
0 replies
Answer selected by
adrianeboyd
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
For data where you have set sentence boundaries with
token.is_sent_start, you want to train asentercomponent instead of aparsercomponent.(The
parseruses dependency trees to identify sentence boundaries, so in data without dependency annotation, each word looks like its own separate tree and own separate sentence.)