Memory sharing in Python 3.8 for SpaCy models #5051
Replies: 11 comments 4 replies
-
|
I'd also like to see if this is possible |
Beta Was this translation helpful? Give feedback.
-
|
This would save so much memory. |
Beta Was this translation helpful? Give feedback.
-
|
I think something of this sort may already be happening. When I load sense2vec at a global level and then access the object from within multiprocess python instances, each instance is apparently using 6.2GB of memory. But the overall system resource sits at 9.6GB, swap use is negligible. |
Beta Was this translation helpful? Give feedback.
-
|
Most of the memory in spaCy models lives in numpy (or cupy) arrays, so it's possible this is happening for us automagically? The main data that isn't shared is the If not, the main chunk of memory that you'll want to share is the vectors. The non-vectors memory in the models is really small. So all you need to do is reallocate |
Beta Was this translation helpful? Give feedback.
-
|
If someone's looking for project ideas, I think this could be a good blog post project? You could:
|
Beta Was this translation helpful? Give feedback.
-
|
Turns out I was wrong about the memory being shared across multiprocesses... I am using sense2vec pretty extensively. If I max out my RAM (very likely) then I may tackle this. |

Beta Was this translation helpful? Give feedback.
-
|
Looking at the data in the reddit model, the vectors file is 4.2Gb and is presumably causing the majority of RAM usage. Wouldn't I've run the above on my machine after building spacy and it seems to work. You can see from the below that the processes each use 5.7Gb of RAM but the overall system usage is 12.4Gb. I am not modifying the vectors at all but I believe this can be achieved by adding locks to the functions that change the vectors object.
|
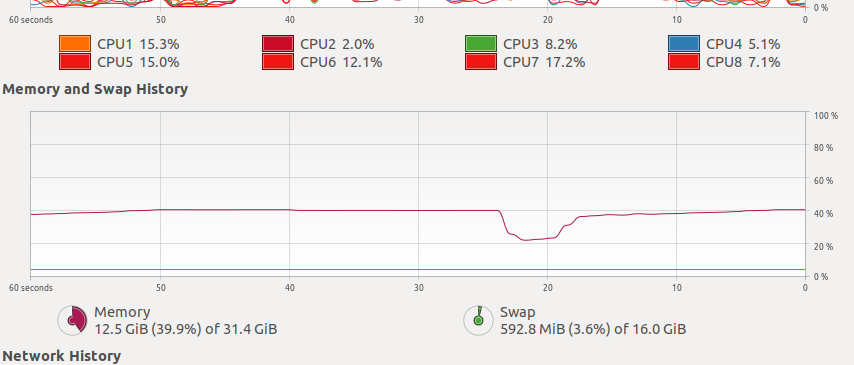
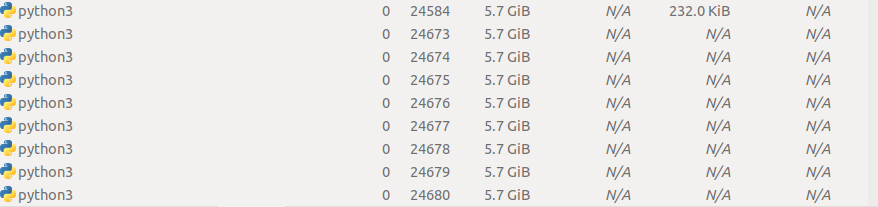
Beta Was this translation helpful? Give feedback.
-
|
I've forked the library and committed the changes to the vectors.pyx file in a branch called shared-memory. The branch is based on master. I can't get the tests to run because of the following error: I've tried modification of the vectors.data object in 4 processes simultaneously and it seemed to mostly work with the following arbitrary code. Someone who is interested in performance of writing could check if it's better or worse than multiple objects in memory. There were a few exceptions like this:
They occurred for the following keys.
I am not able to replicate the error when modifying the vectors in a single process so it could be related to the same object being shared. Or perhaps it is related to this issue. |
Beta Was this translation helpful? Give feedback.
-
|
Eventually I gave up on the idea of getting this working with v2.3. It is now merged with nightly.spacy.io in a branch. There are examples for how to get the branch working here. Most tests are working with the exceptions of those that fail because of a pydantic class wrapping issue. The process for using shared memory in child processes is as follows:
This saves me approx 5GB of RAM when running 4 processes and the common crawl fasttext model (crawl-300d-2M.vec.zip). The amount of RAM saved increases as you add processses. I'd be happy to help make this production ready if its something spacy want in the codebase. |
Beta Was this translation helpful? Give feedback.
-
|
I've been working on my shared memory fork for some time and I recently realised that I could save more RAM by using vector binarization. To give an idea, Common Crawl embeddings are 500Mb in memory when binarized (256 length) and 2.4Gb when represented by floats. I added the binarization stuff into a pull for spaCy v2.3 and I've just finished porting it to the shared memory branch of nightly. It turns out that the shared memory cdef is not compatible with fused ctypedefs. Sharing the array in the Vectors class in cython looks like this:
But if the data can be either However, these fused types (Templates) cannot be used in classes. So I've duplicated the vectors.pyx file to create a second class called VectorsBin in vectorsbin.pyx. The class is then selected dynamically in various places based on the config file or the dtype of the data. The updated nightly branch is here. |
Beta Was this translation helpful? Give feedback.
-
|
Does the Cython class need to specify it as a buffer? We could just type it as cdef struct VectorHandleC:
# Don't take the specifics here too literally. Maybe we just want to use the Python buffer
# struct or something, instead of exploiting that our vectors data should be 2d.
void* data
int n_row
int n_col
int stride
char dtype
char device
cdef class VectorHandle:
# I usually like to have a plain old struct when I'm working with C representations, so that
# I can stack allocate and get a pointer if necessary.
# The cdef class then owns the struct and provides the Python API.
cdef VectorHandleC c
def __init__(self, array):
...
def __array_interface__(self):
... |
Beta Was this translation helpful? Give feedback.
-
|
This was something I struggled with. I couldn't get Cython to compile using |
Beta Was this translation helpful? Give feedback.
-
|
Setting data to be an |
Beta Was this translation helpful? Give feedback.
-
|
Hi @forgetso , Sorry for missing this before, and thanks for keeping at this idea. I'm thinking about how to best isolate this change and make it production-ready without the changes spreading out over the codebase. Do you think the following would be a good approach?
In general the multiprocessing stuff hasn't been worked on very much in spaCy. One reason is that before v3, we also had to support Python2. Combined with the multiple OSes we have to support (Linux, OSX and Windows) and supporting both CPU and GPU, there's a large matrix of places where things can be different. |
Beta Was this translation helpful? Give feedback.
-
|
Is My process was even more basic:
Finally, this works fine when you're dealing with CPU processing only but could conflict with GPU processing. If you're copying the model to the GPU in, say, 8 different child processes then you're going to have a problem unless you have many GPUs. You could additionally implement shared memory using cuda in the Let me know your thoughts. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
This is more of a question than a feature request. But could SpaCy use the new shared memory interface in Python 3.8 to share a single copy of its language model across multiple processes? Is it possible? If so, are there plans to support it?
Beta Was this translation helpful? Give feedback.
All reactions