Spacy v2.2.43 TOKENIZE incorrect result #7933
-
|
Hi, So, I'm using spacy to tokenize sentences in my application.
Tim |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments
-
|
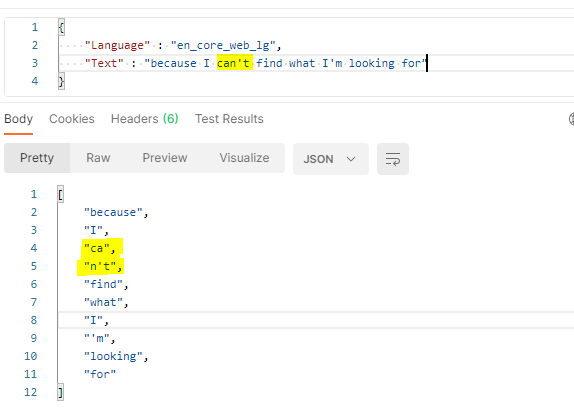
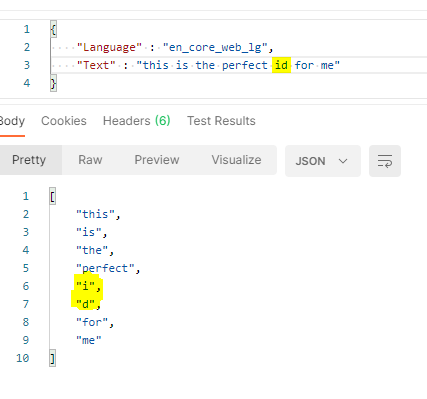
Splitting "can't" into two tokens is normal and intentional and common in NLP tools in general. It makes processing more consistent since it treats it as "can not". You will see this with other contractions like "don't" or "wouldn't". "id" is a bit weird. I guess it's by relation to "I'd" but it seems to be treated as two tokens in any instance, including "Freud talked about the id a lot". That looks like a bug to me. Either way this behavior is the same in the most recent version of spaCy. |
Beta Was this translation helpful? Give feedback.
-
|
@TimVanDorpe Hi, How did you overcome these issues? |
Beta Was this translation helpful? Give feedback.
Splitting "can't" into two tokens is normal and intentional and common in NLP tools in general. It makes processing more consistent since it treats it as "can not". You will see this with other contractions like "don't" or "wouldn't".
"id" is a bit weird. I guess it's by relation to "I'd" but it seems to be treated as two tokens in any instance, including "Freud talked about the id a lot". That looks like a bug to me.
Either way this behavior is the same in the most recent version of spaCy.