Ensemble NER approach - queries #8274
-
|
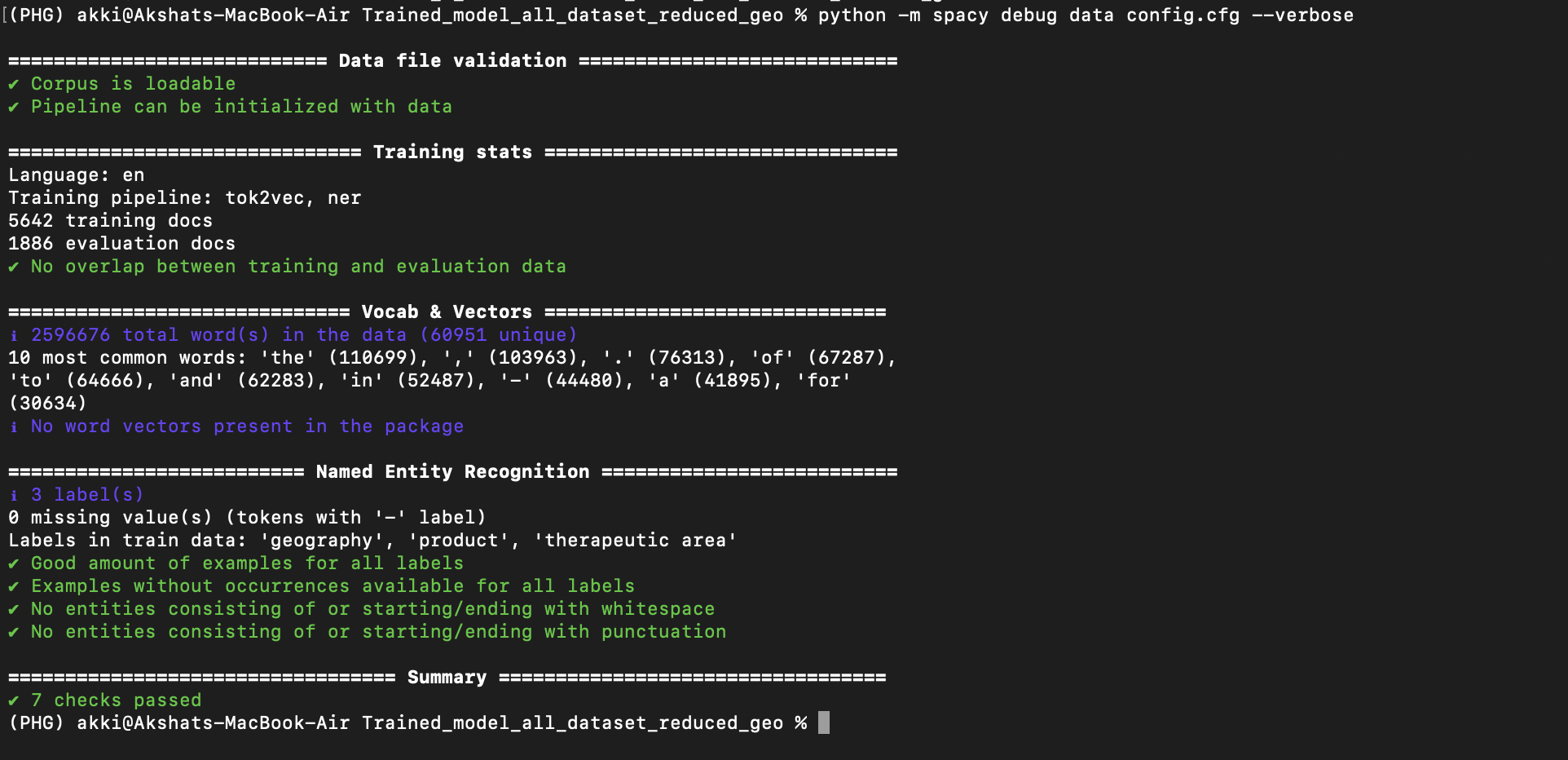
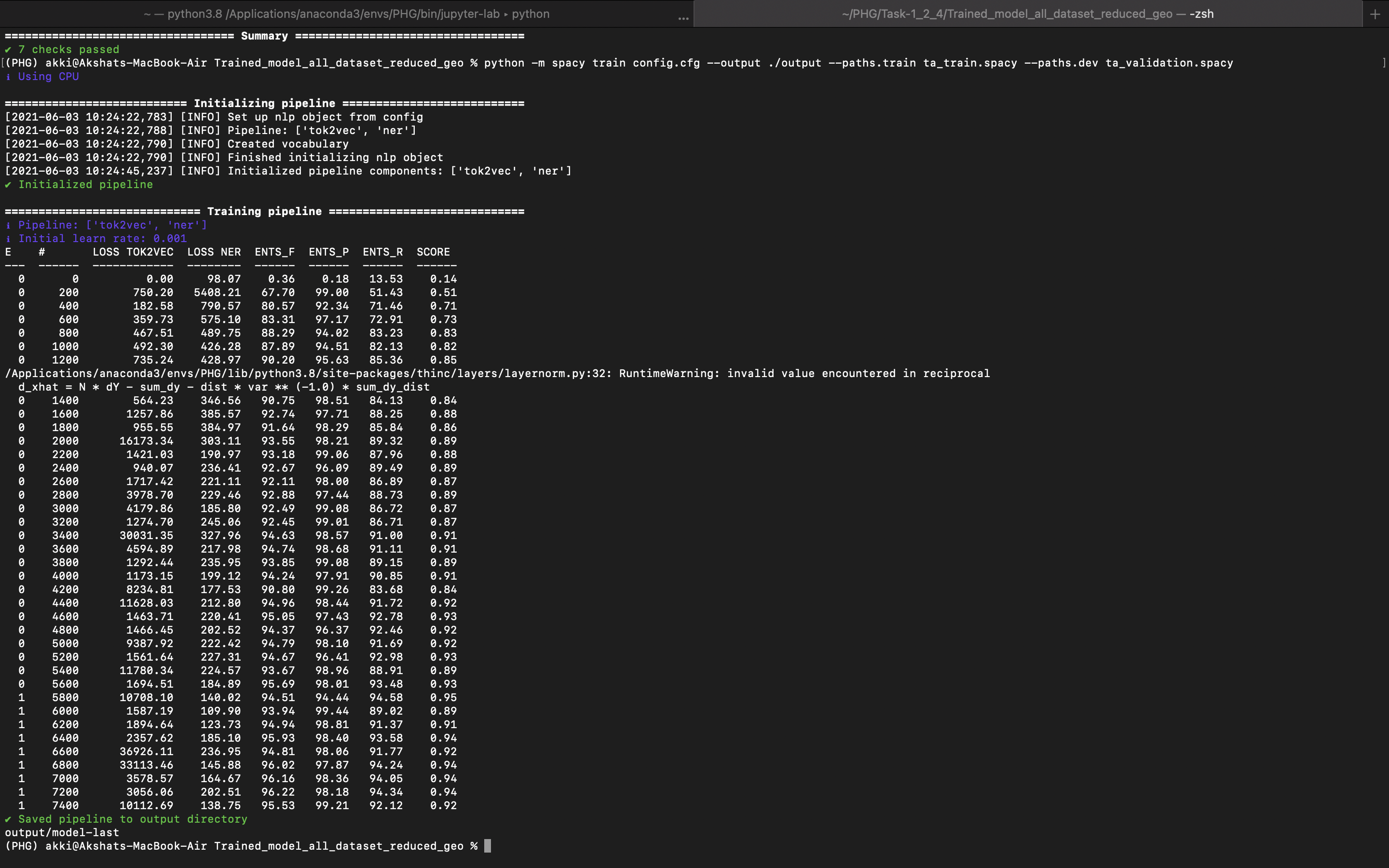
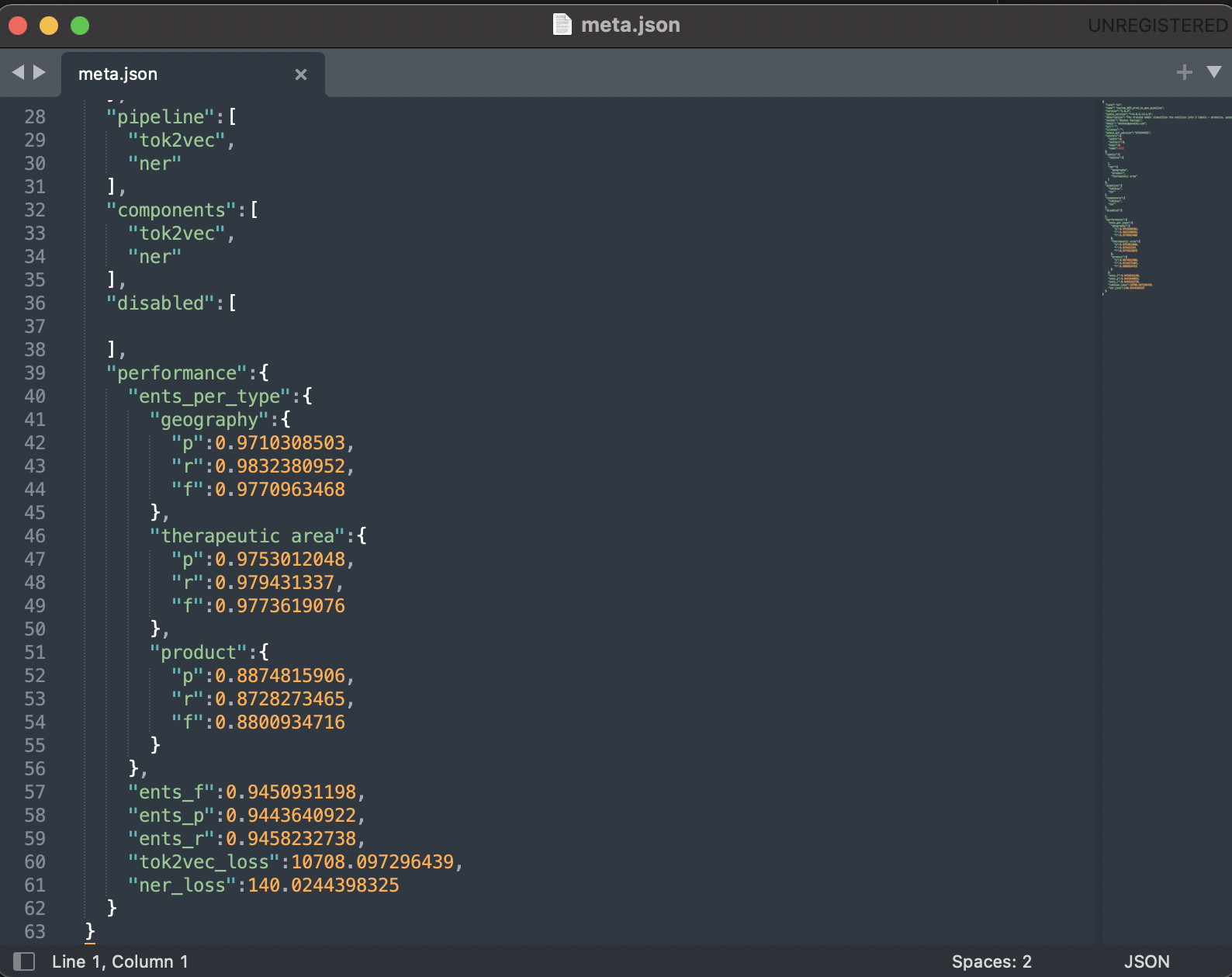
Hi, I'm currently stuck with an approach to extract named entities. Some useful details: The goal is to predict the following labels: therapeutic areas, product / drug names, diseases, chemicals, geography (includes countries, continents and a few abbreviations such as US, USA and EU). My approach is to build something like an ensemble of NER models and is described as follows: Composite NER-1: Identifies the label - therapeutic areas, product / drug names, geography Then, I plan to package all the NER models together in sequence to identify all the labels. For composite NER: First, I generate the training and test set using the EntityRuler approach and train a combined NER models from scratch that identifies all the 3 labels. The performance metrics look too good, so I'm a bit perplexed what is happening here. I'm aware that this approach may somehow incorporate flawed context in the data but I thought this a middle way to get annotated data quickly and train a ML based NER. Total text samples: approximately 10,000 and they have varied length with 200 words to 1500 words (English). I consider all the samples to split into train and test set even when a sample has no entities corresponding to a label in it i.e. 1500 samples have no relevant entities. Data split: 75% (train set), 25%(test set or hold out set) The config.cfg file: [system] [nlp] [components] [components.ner] [components.ner.model] [components.ner.model.tok2vec] [components.tok2vec] [components.tok2vec.model] [components.tok2vec.model.embed] [components.tok2vec.model.encode] [corpora] [corpora.dev] [corpora.train] [training] [training.batcher] [training.batcher.size] [training.logger] [training.optimizer] [training.score_weights] [pretraining] [initialize] [initialize.components] [initialize.tokenizer] The data validation snapshot: The snapshot of the training process: Best model based on recall: Query-1: Currently, it appears that the model is probably overfitting or learning the rules but unable to take context into account and then predict the labels. Now, if want to enhance the generalisation capability of the model. How can I do it (say manually annotating the data is the last preference and having a human in-the-loop is planned but currently not possible)? Query-2: Which evaluation scheme is implemented to compute the performance metrics (precision, recall, etc.) during the training? Is it based on IOB tags or BILOU tags? The ents_f is a weighted F score? Query-3: Is the training process appropriate in your experience? What does the tok2vec loss signify and why does it fluctuate so much? The NER loss does decrease but still fluctuates. Is there a possibility to plot the losses? Query-4: If I plan to move ahead and add the trained (composite NER-1) and pre-trained (en_ner_bc5cdr_md) model in a single pipeline and package it for deployment. How do I do that and is there a blog that helps to do it? I wanted to write the thought process regarding the approach so that the queries have a background. Please let me know if you need further information from my side and any suggestions are welcome. Thanks. |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 2 replies
-
While background on a problem is helpful, this post is a lot of information. It would be easier for us to help you if you broke things down into more specific questions honestly. One question about your system: What do you mean by "composite NER"? I'm not clear what you mean by "composite" when referring to a single component.
Since you generated the training data using rules it sounds like your model is just memorizing some keywords. If that's working well on your test data then maybe an explicit list of keywords and rule based tagging is enough for your project? If not you should look into data augmentation - by replacing keywords or changing their spelling slightly you can make the model rely more on context. Take a look at the augmentation section in the docs and libraries like nlpaug as a starting point. Note that the process of creating artificial training data you have used is called "weak supervision", so looking for information about that may help you deal with common issues users of it have encountered.
Check the Weights & Biases integration.
On a quick look it looks fine. If you use the quickstart as a base you should be OK.
The tok2vec layer, since it's a layer in the model which is being trained, has its own loss values. Since you're just training NER, that's the only objective, so it's the loss that's backpropagated from that. I wouldn't worry about it fluctuating.
We don't have a specific guide for multiple NER models because it should basically just work. The things to watch out for are that the components need to have separate names in the config (they can't both be just "ner") and order matters - NER components won't overwrite existing entities, so models earlier in your pipeline have precedence. This thread covers a pipeline kind of similar to what you're planning.
The issue here is that an NER layer really needs to be combined with the tok2vec layer it was trained with. If you're using a pretrained NER model without updating it you need to use the |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the reply and the suggestions. :) Sorry, I will make sure to break the questions next time. Could you please also answer to the query-2 ? |
Beta Was this translation helpful? Give feedback.
-
|
NER scoring implementation is here. spaCy docs only store IOB tags, not BILOU, though once applied to a doc they're equivalent anyway. Yes, |
Beta Was this translation helpful? Give feedback.
While background on a problem is helpful, this post is a lot of information. It would be easier for us to help you if you broke things down into more specific questions honestly.
One question about your system: What do you mean by "composite NER"? I'm not clear what you mean by "composite" when referring to a single component.
Since …