There is nothing or a little change after training on an existing model for dependency parser using 71 examples. #8295
Replies: 1 comment 7 replies
-
There aren't really any magic numbers but 71 examples is nowhere near enough. In general the larger the model the more data you need; for Transformers this is definitely not enough. Who is "the administrator"? I think we sometimes suggest a few hundred examples as a minimum for NER, but retraining the parser is generally more complicated. |
Beta Was this translation helpful? Give feedback.
-
|
Would someone like to help me? |
Beta Was this translation helpful? Give feedback.
-
|
Hi @qingyun1988 : please don't artificially bump your thread as this is really unhelpful to us. We try to get to everyone's questions in due time, but with no garantuees. |
Beta Was this translation helpful? Give feedback.
-
So can you help me to answer the above questions? Thank you. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, the main problem is probably that this is just not enough data to update the parser for this kind of parse that's very different from all the parses it's been trained on so far.
You also want to update the model with a mixture of inverted and non-inverted sentences or you'll run into problems where it "forgets" how to parse other sentences. See a related comment about catastrophic forgetting: #7666 (comment) |
Beta Was this translation helpful? Give feedback.
-
|
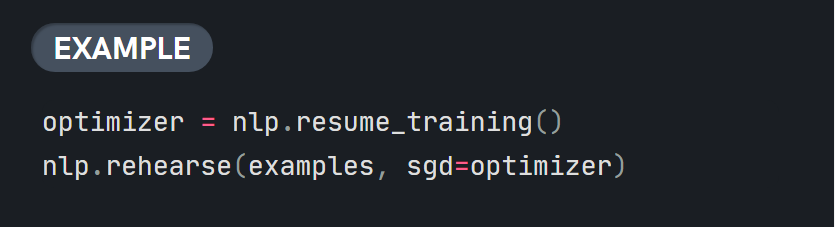
@adrianeboyd It seems to have two ways to resolve the 'catastrophic forgetting' problem. Another is
Doesn't the I'm a bit confused about these. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
I've trained on an existing model 'en_core_web_trf' for dependency parser using 71 examples, but there is nothing change on it.
And then I replaced 'en_core_web_trf' to 'en_core_web_lg', there is literally a little change, but it is not as that I expected. for example, use this sentence to check the change:
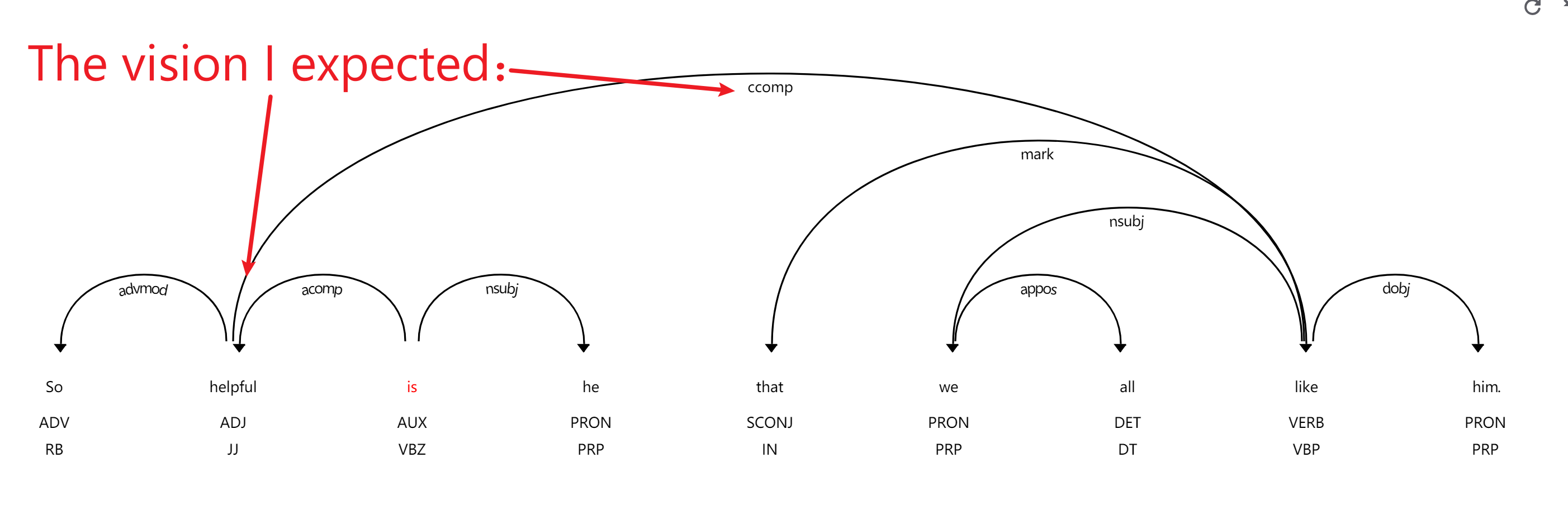
"So helpful is he that we all like him."
The vision I expected:
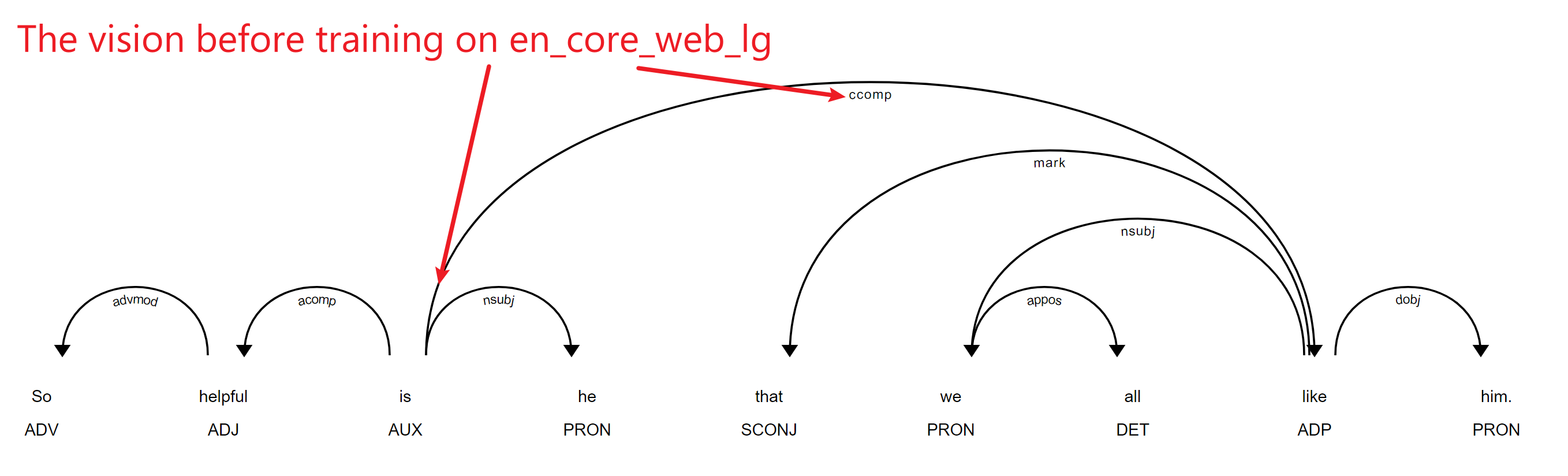
The vision before training:
The vision after training:
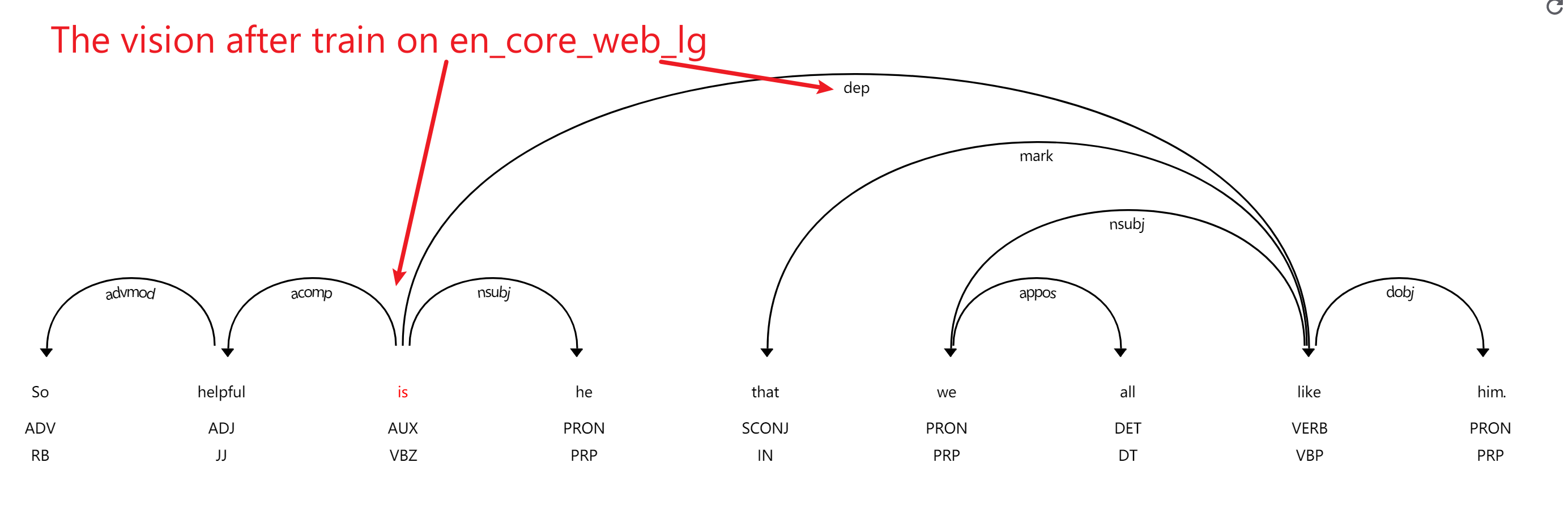
Observing the there pictures, I extracted 2 pieces of information:
My questions are why there is nothing change after training on model 'en_core_web_trf' for dependency parser and why the change on model 'en_core_web_lg' is not as expected.
Is the amount of examples not enough for training on a model to get any change? However, I provided 71 examples for training. I remembered the administrator told me that 20 or 30 examples are enough to do.
Did I miss some step or method? Did I do something wrong? Please help me, any help will be appreciated!
By the way, The training way I adopted was 'training api' not 'train command'. This is my code:
`def train(trainData):
global _nlp,_model_dir
if _nlp == None:
_nlp = spacy.load(_model_dir)
Beta Was this translation helpful? Give feedback.
All reactions