How are models structured? #9179
-
|
Is it preferable to train models for NER, POS tagging and dependency parsing tasks on the same dataset? Or can they be trained on different datasets but with the same tagset? Also, could someone please explain how these trained models are then combined inside the package? Discussed in #3056 |
Beta Was this translation helpful? Give feedback.
Replies: 5 comments 4 replies
-
|
Hello, just a heads up that I edited your question to make it more in line with other discussions.
Also note that 3056 is old and we do things a little differently now. |
Beta Was this translation helpful? Give feedback.
-
|
Oh, thank you so much. I’m but could you please refer me to some resources
where I can get an idea how things are being done these days?
…On Thu, Sep 9, 2021 at 17:31 polm ***@***.***> wrote:
Hello, just a heads up that I edited your question to make it more in line
with other discussions.
1. Your title is too long and makes it hard to figure out what's going
on, so I moved it to the body.
2. Including the whole of 3056 is not helpful.
Also note that 3056 is old and we do things a little differently now.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#9179 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AFNZAFE4C5FV4EHZKECP3Q3UBBWGXANCNFSM5DWSQ47A>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
|
Beta Was this translation helpful? Give feedback.
-
|
We don't have a more up to date guide to adding support for a language from scratch. What language do you want to support? The advice in 3056 is still kind of a good starting point in that you have to get the tokenizer working and get training data for each component. If you have that or another idea feel free to open a thread with a title like "Building a model for [my language]". |
Beta Was this translation helpful? Give feedback.
-
|
To answer your questions...
It depends. Usually it helps to train things together, because the tasks have some things in common. However, as an end user it is unusual to have to train a POS or dependency parsing model.
Leaving aside the issues from the previous question, I am not sure what you mean. Each task uses a separate tagset. If you used two different tagsets for the same task that would not work.
Please see the pipeline docs, or let me know if you have a more specific question. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much for such a detailed answer. I really appreciate it!
My company wants me to develop Korean language package for spaCy. From I
know there is a basic tokenizer in the official spacy repo. Did I
understand correctly that to develop the pipeline for Korean language, I
need to train pos tagger, parser, ner tagger either by using models
provided by spacy or by using my own model through thinc?
Let me rephrase my question about the datasets for different tasks. When I
looked at the sources used for Japanese language, they used the same data
(UD_GSD) for both pos tagging and ner. The tagsets are of course different,
but the data is the same. UD website doesn’t have NER dataset, so I was
wondering if it is okay to use some other data, but with UD tagset for NER
task.
…On Thu, Sep 9, 2021 at 19:14 polm ***@***.***> wrote:
We don't have a more up to date guide to adding support for a language
from scratch. What language do you want to support? The advice in 3056 is
still kind of a good starting point in that you have to get the tokenizer
working and get training data for each component. If you have that or
another idea feel free to open a thread with a title like "Building a model
for [my language]".
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#9179 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AFNZAFFFMIE3SD4E36YU2ODUBCCHNANCNFSM5DWSQ47A>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
|
Beta Was this translation helpful? Give feedback.
-
|
A few notes about Korean: The default For Japanese, Megagon Labs has added NER annotation to the UD Japanese GSD corpus in their own separate release. There are a few languages where separate work has added NER to the UD data, but this hasn't been done in general for most UD corpora. For CNN pipelines, it's not too slow/large to have two separate For a simple transformer pipeline, you need the tag/parse/ner annotations to be all on the same data to train the components well with only one What spacy doesn't support is multiple tokenizations for the same I'll add that spacy pipelines are very flexible and it's not 100% impossible, but it would be a task for advanced spacy users who are willing to put in a fair amount of effort. For most users I'd recommend having two separate pipelines because it is probably not worth it. I've been doing some experiments with Korean recently and if you're knowledgeable about Korean NER datasets, I'd be interested in asking for your input. If we want to add a pretrained pipeline for a new language, usually the trickiest part is finding an NER dataset with a commercial-friendly license. I've searched a bit without any luck in English publications about Korean NER, but I can't read/search in Korean so I could easily be missing potential resources. We're happy to consider corpora with fees for commercial use, too. |
Beta Was this translation helpful? Give feedback.
-
|
I will add that I maintain several MeCab-related packages for Japanese, but I don't speak Korean and don't entirely understand how mecab-ko differs from standard MeCab. If you think there's anything that can be done to make it easier to use, like maybe packaging wheels so people don't have to install MeCab themselves, let me know and I'd be glad to work on it. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you so much for such a detailed answer. Our company is working on the
NER dataset and I will definitely keep you updated on the progress.
Does config file needs to be created for training the tokenizer?
I mean, does the tokenizer need to be trained? And if yes, does one need a ready vocab file?
<img width="665" alt="Screen Shot 2021-09-14 at 11 53 38 AM" src="https://user-images.githubusercontent.com/22777876/133199256-6d618b0d-4a95-42db-b8d7-dab8ccf654dd.png">
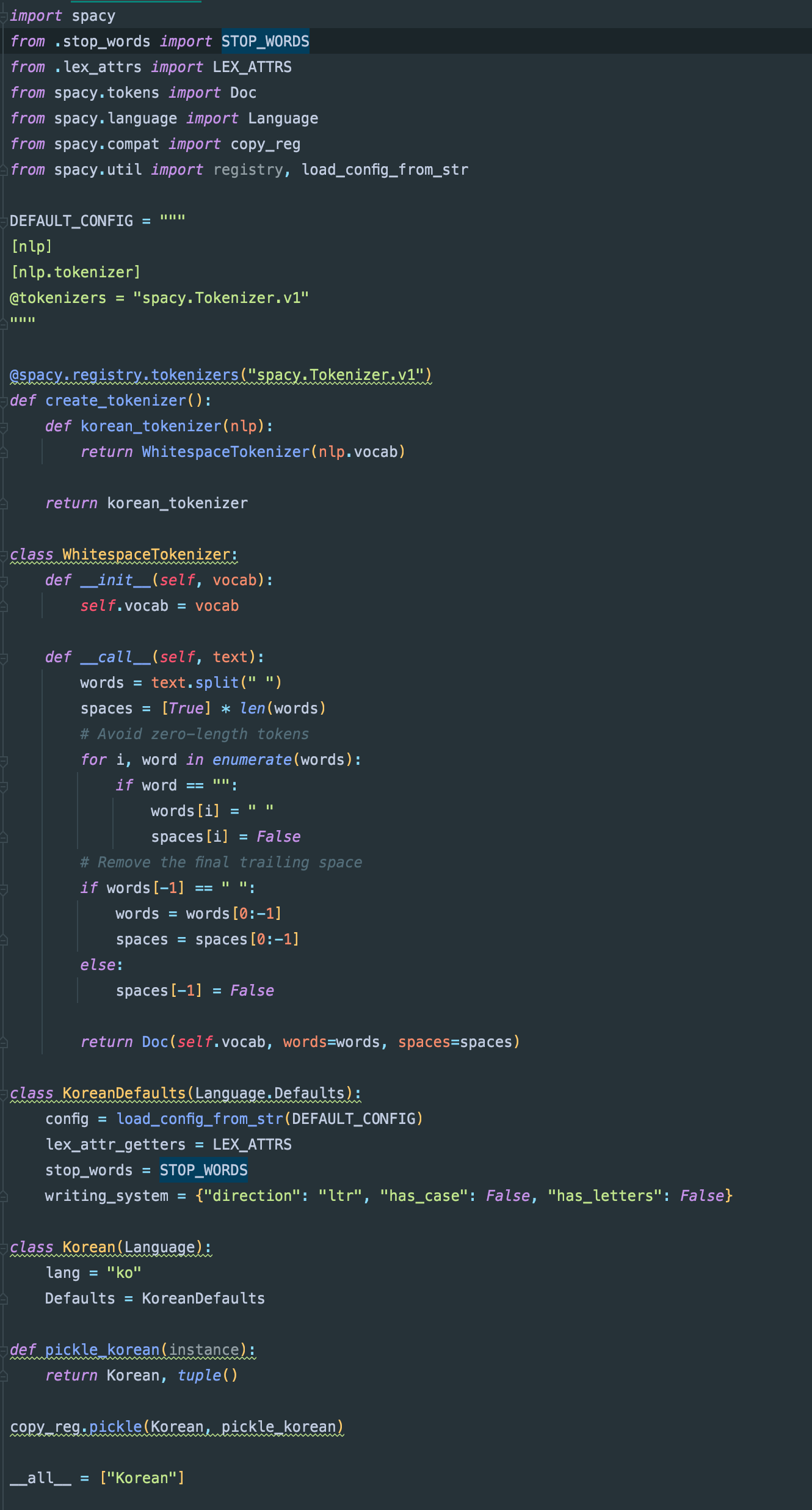
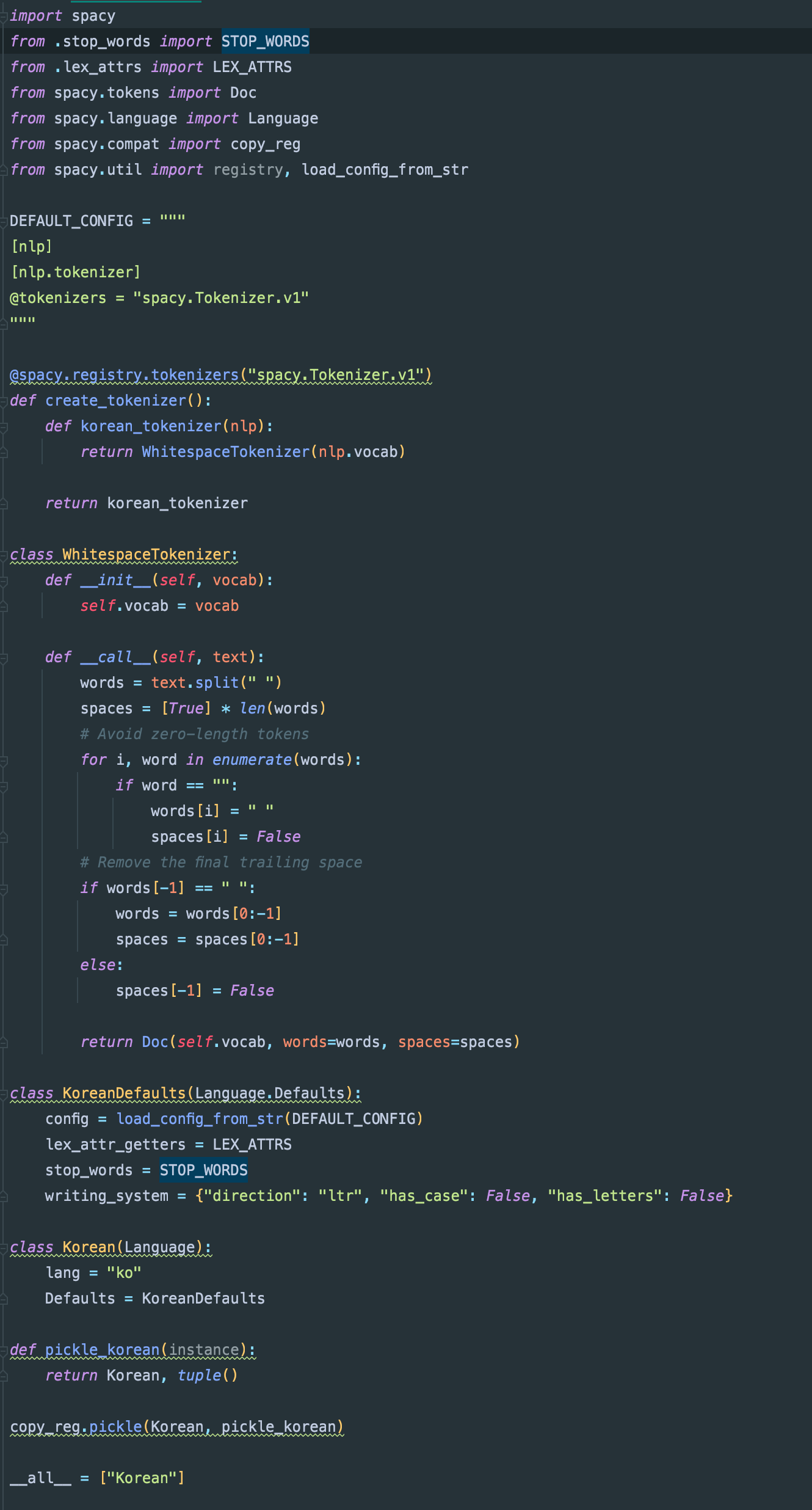
If you don't mind having a quick look, does the code below make sense?
<img width="665" alt="Screen Shot 2021-09-14 at 11 53 38 AM" src="https://user-images.githubusercontent.com/22777876/133199457-bf58bcb0-8765-405c-8ff9-09b0817ada56.png">
…On Fri, Sep 10, 2021 at 6:14 PM Adriane Boyd ***@***.***> wrote:
A few notes about Korean:
The default Korean tokenizer spacy.ko.KoreanTokenizer uses mecab-ko and
natto-py to do morpheme segmentation. However, the UD Korean corpora
(GSD, Kaist, PUD) have word segmentation instead of morpheme segmentation,
so the ko defaults are a not a good match for training a tagger/parser on
UD. If you want to train on the UD corpora, create your config with spacy
init config and then edit it by hand to switch to spacy.Tokenizer.v1. The
Tokenizer defaults work well here for word segmentation.
------------------------------
For Japanese, Megagon Labs has added NER annotation to the UD Japanese GSD
corpus in their own separate release. There are a few languages where
separate work has added NER to the UD data, but this hasn't been done in
general for most UD corpora.
For CNN pipelines, it's not too slow/large to have two separate tok2vec
components, one for tagger/parser and one for ner. This is what the
pretrained pipelines do, see: https://spacy.io/models#design
For a simple transformer pipeline, you need the tag/parse/ner annotations
to be all on the same data to train the components well with only one
transformer component, since having more than one would really bloat the
pipeline.
------------------------------
What spacy *doesn't* support is multiple tokenizations for the same Doc
object, so if you have NER data with morpheme segmentation (which is used
by most Korean NER corpora I've seen, since it's more suitable) and
tags/parses with word segmentation, it's going to be very difficult to
train and run these components in the same pipeline.
I'll add that spacy pipelines are very flexible and it's not 100%
impossible, but it would be a task for advanced spacy users who are willing
to put in a fair amount of effort. For most users I'd recommend having two
separate pipelines because it is probably not worth it.
------------------------------
I've been doing some experiments with Korean recently and if you're
knowledgeable about Korean NER datasets, I'd be interested in asking for
your input.
If we want to add a pretrained pipeline for a new language, usually the
trickiest part is finding an NER dataset with a commercial-friendly
license. I've searched a bit without any luck in English publications about
Korean NER, but I can't read/search in Korean so I could easily be missing
potential resources. We're happy to consider corpora with fees for
commercial use, too.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#9179 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AFNZAFERHBYRJA4LAQ7BXSLUBHEALANCNFSM5DWSQ47A>
.
Triage notifications on the go with GitHub Mobile for iOS
<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>
or Android
<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
|
{kind=link}
{kind=link}
Beta Was this translation helpful? Give feedback.
-
|
I think you replied to this via email, but note that email attachments do not show up on Github, they are just discarded. If you use the web UI you can upload them. |
Beta Was this translation helpful? Give feedback.
To answer your questions...
It depends. Usually it helps to train things together, because the tasks have some things in common. However, as an end user it is unusual to have to train a POS or dependency parsing model.
Leaving aside the issues from the previous question, I am not sure what you mean. Each task uses a separate tagset. If you used two different tagsets for the same task that would not work.
Please see t…