Sizing and controlling GPU memory for training #9451
Replies: 6 comments 16 replies
-
|
There are two batch sizes to adjust for GPU RAM:
The training batch size may have some minor effects on performance. The main corpus parameter to consider is text length, which is why the corpus reader also has the option to break texts up into individual sentences if they are beyond a specified token length. We use a lower |
Beta Was this translation helpful? Give feedback.
-
|
Thank you @adrianeboyd . The main help was your explanation of corpus max_length (I see eng_core_web_trf uses 500). Thank you for that. I am converting my data into DocBin using my own code, so it was easy to modify DocBin generating code to: My training data are 'documents' varying between 2 to 8k characters - that translates into 400 to 1600 words each. To make it work, I had to reduce corpus max_length=100 and training batch_size=10. But even that was not enough. and I do not understand the relationship between the training.batcher and corpus max_length, I would assume that with max_length=100 I would not need batcher size limit greater than 100 - but I need it. The main outcome of this exercise is that I now have some 'feel' for what to expect from transformer on GPU, and some assurance that one can 'squeeze' the training into available GPU memory - although at the cost of loosing some accuracy. |
Beta Was this translation helpful? Give feedback.
-
|
Hey, @mbrunecky! |
Beta Was this translation helpful? Give feedback.
-
|
Hi karndeep, can you help me with relation extraction with spacy-transformer, from where we can download this config for 'relation_extraction', training script of "["transformer","ner","relation_extractor"]" is as same as Ner ? |
Beta Was this translation helpful? Give feedback.
-
|
Well, I have gained a bit more experience since I wrote the above. I bought a 12G RTX 3060 ... and my struggle with GPU out of memory did not end there. The fist question to ask is 'in which training phase you run out of memory'. I kept running out of GPU memory in the 'evaluate()' phase, and learned (see #9602) that evaluate() is designed to keep the entire 'dev' corpus in memory (twice + tensor data). Initially I tried using [corpora.dev] max_length = 200, but (after working with language.py) I learned that it is useless - regardless of how you break up your 'dev' corpus, it will be loaded into memory ALL at once, and tensors are kept in GPU till the last document is scored. Note that when using spacy evaluate command, your 'eval' data sample may be bigger than 'dev' - but not that much (same code). IF you are running out of memory during the training (update), the main parameters that do seem to matter are:
That said, perhaps I would try to run only the NER, and only after you succeed there, I would look at what "relation_extractor" addds. |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky Thanks for your wonderful answer. I was also dubgging the error and found that when I train for larger data like 5k samples it get stuck at evaluate() step in training/loop.py file. Thanks again. |
Beta Was this translation helpful? Give feedback.
-
|
Note that higher value for eval_frequency means that your scores are evaluated less frequently, and hence you may have to take a look at your 'patience'. But unlike tok3vec models, my transformer models seem to improve (the score) fairly linearly. In many cases, instead of stopping by 'patience' I stop by max iterations, and the best case is within the last couple iterations. |
Beta Was this translation helpful? Give feedback.
-
|
Regarding max_length, your [corpora.train] has it commented out: As I wrote above, using max_length for [corpora.dev] = evaluate() is pointless, because the code does it's best to load all the data to memory regardless of the batch_size (which is only used by the pipeline components). There were some comments that using max_length other than zero may lead to 'inconsistent results', especially when there are no good sentence markers. I use the sentencier (in my data preparation pipeline), and I have 'good' sentence markers - and I was still getting inconsistent results. Using max_length = 200 for [corpora.train] did not help with the GPU OOM, so I abandoned it. Below is the config.cfg which handles my data set of 9738 'doc' averaging 956 words (Spacy tokens) per document (with 'max' about 1.5 times of avg). The 'dev' uses only 400 such 'doc', above it I get GPU OOM in evaluate() during training. Windows 10, GPU is RTX 3060 12GB, installed NVIDIA CUDA 11.5 and using Spacy 3.2 with: config.cfg -- |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky Thank you again for your valuable insight. So, this issue has not been fixed yet as I can see on the discussion forum you have raised an issue already and explained it very nicely and even did some changes to language.py and scorer.py. This is a generic issue they have to look into this. After changing some part of code in language.py and scorer.py were you able to fit larger dev data in memory and resolve the OOM issue? If so what are the changes I need to do to my codes as well? Please, can you help me understand this I would be good? What are the challenges I could expect during inferencing? Does this OOM issue rise when I will pass the data to the model after getting trained in production? Any suggestion on the production side as well will be good as I don't want to run into memory issues on the production server. You mentioned migration from spacy 3.1 to spacy 3.2 so, does this issue has been resolved in spacy 3.2? And if so what versions you are using for the transformer. Also, I would like to connect with you directly, here is my LinkedIn Id : https://www.linkedin.com/in/karndeepsingh Thanks again. |
Beta Was this translation helpful? Give feedback.
-
|
With regards to evaluate() OOM: During inferencing, in (my) "prediction server", I receive one document at a time, run that document thru the entire pipeline, return the result and discard all document related data. Hence, the production GPU memory utilization is much lower - one document at a time, plus whatever parts of the model are cached. In my case, an order of 2GB. Of course, running one document at a time thru the entire pipeline is more costly, but the 'speeds' I am getting are good enough for me. And there is no way I could make my clients 'batch' the documents - not even two. But to give credit to Spacy folks, the pipe() is thread-safe, so I can use a multi-threaded server. In case of evaluate, batching is taken to the ultimate. Instead of using batch_size (as many people incorrectly imply), evaluate() uses ONE batch: all documents. The batch_size is passed to each pipeline components, so it may use it (or have it's own batching rules). But evaluate() will first run ALL document thru transformer (attaching GPU tensors to each document), and then ALL document thru NER, and (if you have another component) all thru that component, while keeping all the necessary data in memory - both main and GPU. I am told that in Spacy 2, the scorer was 'incremental'. But in Spacy 3 it is not - it must score ALL documents at once. My code change makes the scorer 'incremental', but it changes the scorer returns and requires an 'aggregator' to put pieces together - and convert them to what the rest of the code expects. |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky Thanks Again. For now, I am using the following code for inferencing on a single doc (NER + RELATIONAL), if could also share a better way of inferencing on a single doc or batch doc |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky Btw, I am training NER + RELATIONAL model together with 5000 training dataset and 500 dev dataset. And following image shows GPU usage while training, Any suggestions on increasing the dev data also would be helpful as you can see their is still some memory left in GPU which is unused:
|

Beta Was this translation helpful? Give feedback.
-
|
On Windows, the TaskManager GPU performance provides nice graphs showing GPU memory, CUDA and copy, copy2 usage – I use the ‘slow’ refresh.
The GPU memory usage with torch is tricky, because it’s memory allocator keeps the GPU memory even when not in use, and them seems to release it at some (perhaps predictable) points.
I found that the max GPU memory usage can go up anytime (often late) during the first epoch – there may be some bigger document ‘later’ in the data. I relax only after the first epoch completed. And my GPU memory usage eventually grows to 11.5 GB, because IF I see less usage I just add more DocBins to my ‘dev’ sample for the next run.
From: Karndeep Singh ***@***.***
Sent: Sunday, November 28, 2021 5:08 AM
To: explosion/spaCy ***@***.***>
Cc: Martin Brunecky ***@***.***>; Mention ***@***.***>
Subject: [EXT] - Re: [explosion/spaCy] Sizing and controlling GPU memory for training (Discussion #9451)
@mbrunecky<https://github.com/mbrunecky> Btw, I am training NER + RELATIONAL model together with 5000 training dataset and 500 dev dataset. And following image shows GPU usage while training, Any suggestions on increasing the dev data also would be helpful as you can see their is still some memory left in GPU which is unused:
[image]<https://user-images.githubusercontent.com/49562460/143767020-13beee38-0bd1-4a2b-ae8b-477e512bbb21.png>
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<#9451 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AOGQRXJZZMEV3YK2RBJVHSLUOILQ5ANCNFSM5F5V4NDA>.
Triage notifications on the go with GitHub Mobile for iOS<https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675> or Android<https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub>.
|
Beta Was this translation helpful? Give feedback.
-
|
Just thinking ... perhaps you can load your CONLL annotated data into a (blank) Spacy document, and then 'split' that document as needed ... with the 'split' position somewhere between your annotations. |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky Thanks for replying. I have been training NER Transformer model and while training it is evaluated at every 500 iterations. So, F1 score, Recall, and precision are shown in 93-95% while training. And when I explicitly run command ! spacy project run evaluate on the same dev dataset that I have used for evaluation while training, it shows very little F1 Score, Precision, and Recall. Can please advise here what is the problem and how can get exact metrics to evaluate? Which metric shall I believe, the information that is printed while training or information printed while running ! spacy project run evaluate? Below is the output when I run! a spacy project run evaluate Secondly, How shall I remove False Positive? Because I can see a lot of extra words are being predicted wrong while inferencing. |

Beta Was this translation helpful? Give feedback.
-
|
I am not sure how much I can help here. When I am using command line spacy evaluate against the 'dev' set using in training (same data), I am getting exactly the same results as the ones reported during training - as long as I use max_length=0. But I am doing NER only, I have no experience with relationships. That said, I recall that you were (experimenting?) with limiting the dev corpus data size with max_length=512. is telling me that if I happen to have a document (split) example with no NER annotations, it will be skipped - not counted. Hence any false positive predictions against that document(split) will not be counted., resulting in under counting fp during training. The command line evaluate uses Corpus.max_length=0 (and no augmenter), so it will never happen there. PERHAPS you need take a look at your NER first. The 'aggregate' scores may be misleading. For example Spacy en_core_web_lg comes with nice scores, but when you dive in and look at per-entity scores, you find that it is due to several 'low hanging fruit' entities (i.e. CARDINAL or PERSON) while others (i.e. WORK_OF_ART) have dismal scores. |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky That means, you are also facing the same issue. So, when you evaluate it on the dev set using evaluate.py the metrics reported by the model is misleading right? But while training we can see evaluation done at every 500 iterations, showing good accuracy. So, Which accuracy i need to consider? The evaluation frequency reported while training or information printed while running evaluate.py after the model got trained. My main concern is, how the reporting of accuracy should be done to clients when we see this kind of information printed. |
Beta Was this translation helpful? Give feedback.
-
|
What I am saying is that it depends on what your down stream application does. But I think your problem is at the model level, that you are getting different scores for different evaluation data sets. There may be multiple reasons for that, but for a well-trained model this should not be the case. |
Beta Was this translation helpful? Give feedback.
-
|
@mbrunecky Hi Any Idea Why I am getting the "UNMARRIED" word's each character is being Predicted as PARTY IDCODE rather than whole "UNMARRIED" word predicted as "PARTY_IDCODE". Please help me to understand. |
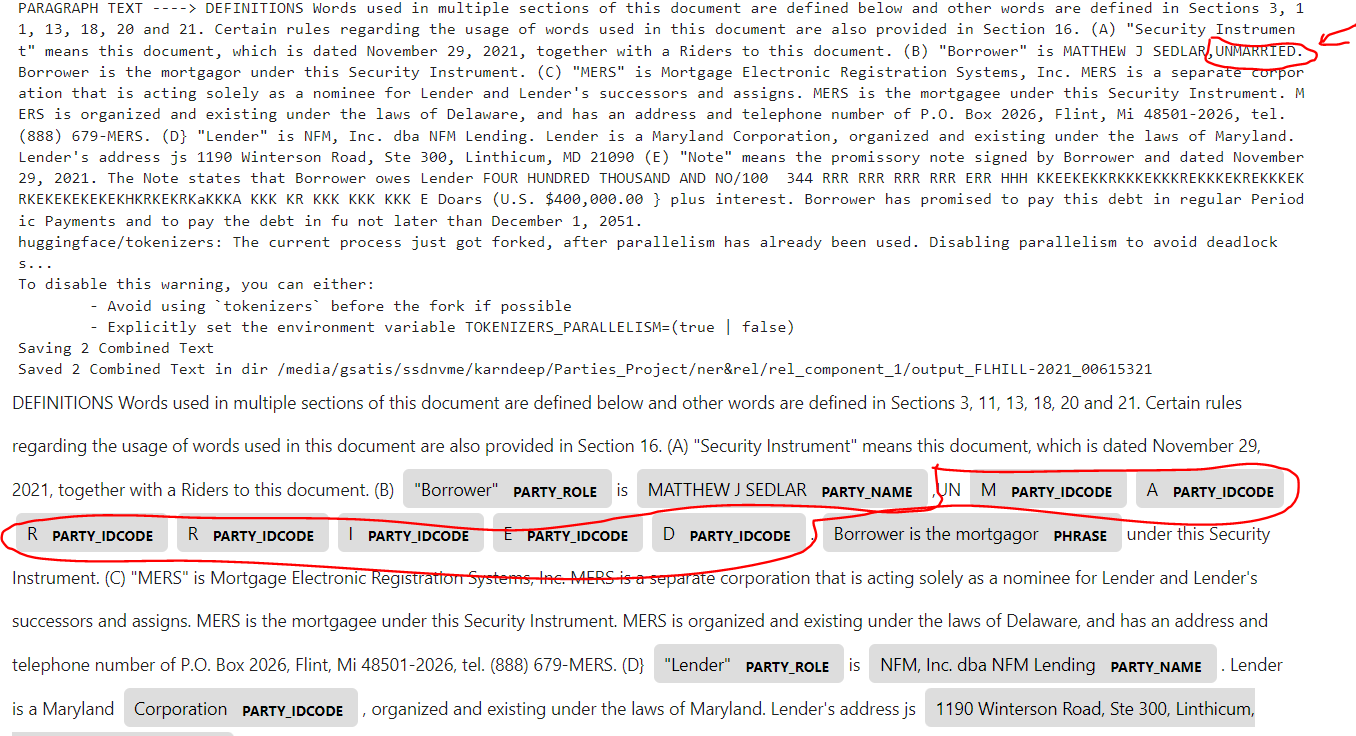
Beta Was this translation helpful? Give feedback.
-
|
Sorry I can't help too much. This 'looks' like a tokenization problems. It seems you are using OCR data, and it is possible that your capitalized text is actually reported as individual letters (by the OCR engine). Or that whatever tokenizer you use turns that text into multiple 'words'. Old Spacy2 used JSON document data format, and I used it to load document and look at what Spacy tokenization (and BILO markup) did to me. Because your training is probably teaching your model that PARTY_NAME is (often) followed by PARTY_IDCODE, this becomes what the model learns to predict. The other issue is 'false positives'. I keep struggling with those, because I can get recall 0.97 on 'dev' or a huge validation set, but then on the 'real data' I get more false positives (and I do not think I am over-training). The only thing I am trying is being very careful about training data. I am often throwing away up to 20% of data having some 'deficiency'. The problem is that whenever I come with yet another great 'throw it away' rule, chances are 50/50 that applying this rule makes things worse... I do not know how are you creating your training markup, but human operators tend to be error prone... and machine rules-generated markup has it's own sets of pitfalls. In my years of pretending to work in AI, I learned AI has the same tendency as little kids: given opportunity, they both take the worst lesson possible :-). |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Background:
In Spacy 2.3 I was able to use an 8GB GPU for all my NER training, getting about 3x better performance. With Spacy 3, the documentation suggests 'at least 10GB' and sure enough, the same models run out of 8GB GPU memory (unless I tweak down the parameters - but than my prediction accuracy suffers).
With the addition of transformers (and they are great), the GPU memory needs go even higher (at least I am unable to 'tweak down' my configuration to fit into 8GB).
That said, the GPU memory usage is significantly lower in production (using trained models to get predictions) . I can easily use my 8GB GPU for my (CPU-only trained) transformer models or en_core_web_trf - and get the speed.
This raises two questions:
I do not want to buy another GPU card (especially at today's prices) and later find out that (for example) 12GB is not enough, and I need another upgrade. On the other hand, training transformer on CPU only (even with 20 cores) takes too many days...
On the subject of 'controlling GPU memory usage':
It seems that
batch_sizehas only a limited impact (used mainly during validation), so reducing it only adds some overhead and saves memory.For tok2vec training, significant parameters seem (and there is probably more)
Reducing width/depth saves memory - but (in my case) goes against accuracy.
And (despite lots of trying) I have not found anything that would reduce the transformer memory greed :-).
Beta Was this translation helpful? Give feedback.
All reactions