Training Data Sample for NER #9495
-
|
I am trying to build a custom NER model. The data is scraped from internet and cleaned. I have several thousands of these type of data for training purpose. I have annotated this data using annotation tools and one sample of data in spacy training format is given. I would like to know if i take this much bigger unstructured data, will NER is going to work. Also any insight for improvement from the above annotated data is requested. |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 17 replies
-
|
You can use documents of that length, but in general it's easier to work with documents if you cut them down to paragraph length. In your case there don't seem to be real paragraphs but it looks like you could split the data into lines without losing information. There are other issues with your data. A lot of lines are irrelevant and could be pre-filtered, which would make the rest of your task much easier. You can filter lines by removing set phrases or overly short lines. The show title is the first line, but there's not any useful context for the model to learn, or any useful keywords really. So if most of your data looks like that it won't help. You're labelling the show start time and date, but those are the only dates in the text except for years (season and copyright), which can be filtered out easily. So you should be able to just use the date label in the pretrained model. |
Beta Was this translation helpful? Give feedback.
-
|
@polm I have a sample data annotated. I will share the image for easy understanding
here you can see the tagged data. The tagged data is the required ones in that page. (This data is obtained from a single url page as discussed in the thread above)
|
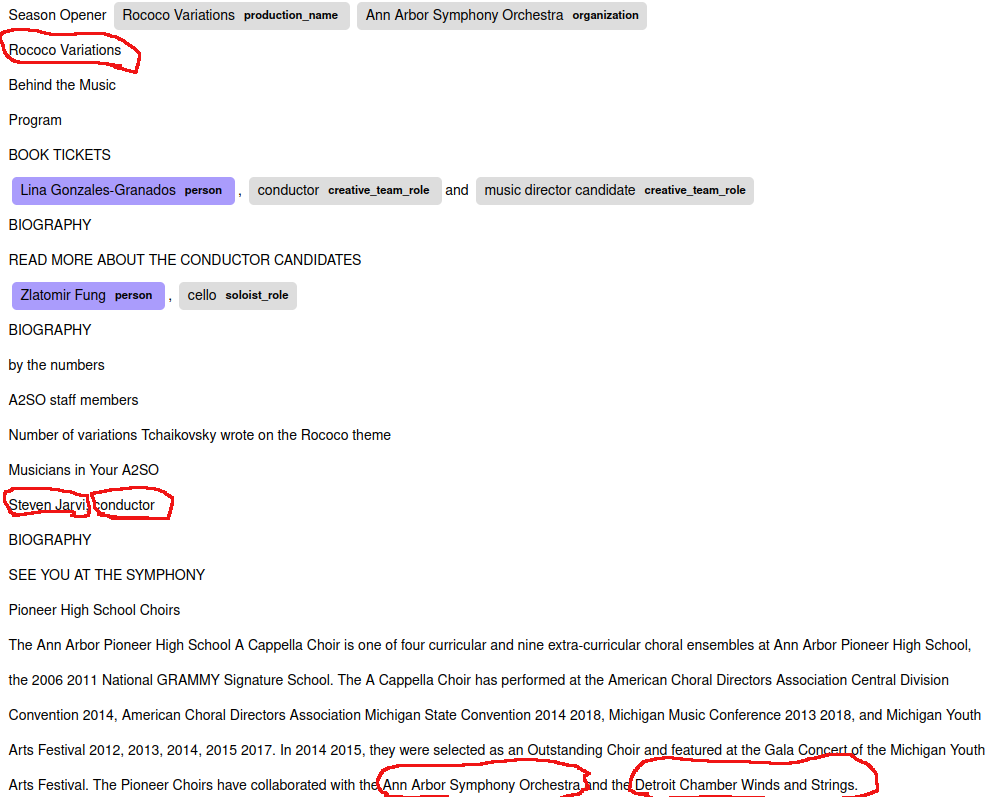
Beta Was this translation helpful? Give feedback.
-
|
The model will learn to reproduce the data it sees in training. That almost always means you should annotate every instance of something, so you should mark "Rococo Variations" in all locations. If you don't do that then your model will have conflicting information - sometimes "Rococo Variations" should be labelled, sometimes it shouldn't. How will the model tell the difference? Is there a reason only the first one is tagged in your data? If you're lucky, the model will learn something like "production names occur on a line by themselves". If you're unlucky it will just behave strangely and unreliably. Regarding the name/role, it is not clear to me why it is not relevant in this document. If it's not clear to a person, how will it be clear to the model? It's not impossible for the model to make those kinds of distinctions but it sounds hard. |
Beta Was this translation helpful? Give feedback.
-
|
There is no reason that i tagged this "Rococo Variations" only once. I thought it will be fine by tagging once. |
Beta Was this translation helpful? Give feedback.
-
|
@polm According to the suggestion given, i have retagged the data. So can you have a quick glance at the tagged data and give a comment on the new tagging.
One more doubt is if we tagged Steven Jarvi as a person, then some other parts the same name can be mentioned by just steven or jarvi. So if tagging steven jarvi, steven and jarvi as persons, will that cause any issue ? |

Beta Was this translation helpful? Give feedback.
-
|
Those annotations look good.
It's fine to tag all those as PERSON. The most important thing is that your input should be tagged the way you want the model to tag your output. Since "Steven Jarvi", "Steven", and "Jarvi" all refer to a person, they should all be tagged PERSON. This is not always true of substrings - for example, "Twelve Days of Christmas" could be a PRODUCTION, but "Christmas", "Days", and even "of" are of course not PRODUCTION on their own. |
Beta Was this translation helpful? Give feedback.
-
|
Hi. The Dev data given while training the ner model for computing the accuracy of the model should also be tagged data right? |
Beta Was this translation helpful? Give feedback.
-
|
Yes, the dev data needs labels. I'm not sure why you commented on this issue instead of opening a new one. If in doubt about whether your question is related to an existing discussion, it's often better to open a new thread than commenting on another one, especially if the older thread isn't currently active. (Keep in mind that when you comment on a thread, other participants in the thread usually get notifications.) |
Beta Was this translation helpful? Give feedback.
-
|
Sure. I'll remember that. Thanks! |
Beta Was this translation helpful? Give feedback.
You can use documents of that length, but in general it's easier to work with documents if you cut them down to paragraph length. In your case there don't seem to be real paragraphs but it looks like you could split the data into lines without losing information.
There are other issues with your data. A lot of lines are irrelevant and could be pre-filtered, which would make the rest of your task much easier. You can filter lines by removing set phrases or overly short lines.
The show title is the first line, but there's not any useful context for the model to learn, or any useful keywords really. So if most of your data looks like that it won't help.
You're labelling the show start time a…