Need Help on Custom Tokenization using Spacy! #9721
-
|
Hi, |
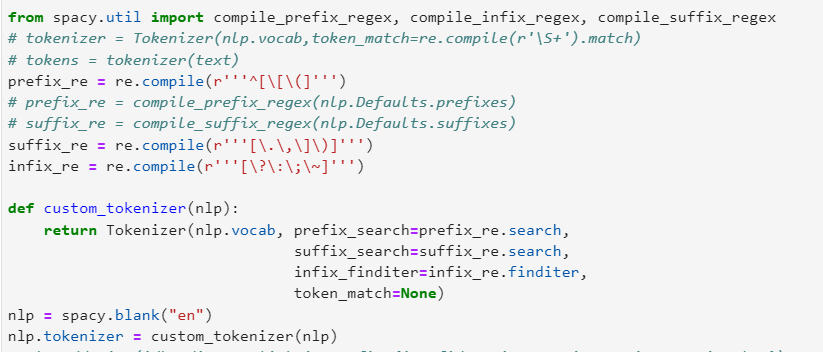
Beta Was this translation helpful? Give feedback.
Replies: 1 comment
-
|
Sorry, I can't tell what the input text looks like from the formatting in the question. If you have run-on words like |
Beta Was this translation helpful? Give feedback.
Sorry, I can't tell what the input text looks like from the formatting in the question. If you have run-on words like
borroweristhen you might want look into libraries related to spell-checking that identify run-ons and either run this as a preprocessing step before spacy (inserting whitespace), or potentially as a postprocessing step after the tokenizer that retokenizes those tokens (which you could do while preserving the original whitespace). The rule-based tokenizer can handle predictable cases likeca n't, but not any potential run-on words.