Packaging EntityRuler and adding it to another pipeline #9776
-
|
I suppose this is largely because I'm fairly new to spaCy and NLP in general. But the documentation regarding "Rule-based Matching" is incredibly confusing to me. For example; I'm reading the documentation on how to use the entity ruler, and the first example shows how to add different patterns, by using It's not clear as to why first it's using A second thing I've found confusing, is that there's really no information on how to actually build and package your own models. When searching around, all the examples I've found are fairly similar, but none actually show how to build a real project. For example; I want to build a custom entity ruler, based on a dictionary of words I have. How should I go about that? Do I create a blank spaCy object, and add "entity_ruler" as a pipe? How do I then add this model to another pipeline that loads "en_core_web_lg". Again, this is all probably due to my lack of understanding of NLP. But I've been looking at this for a week or two now, and I just can't get past the basic examples and get a sense of how I actually go about building something with it. Which page or section is this issue related to? |
Beta Was this translation helpful? Give feedback.
Replies: 5 comments 13 replies
-
|
Sorry you're having trouble with this. I'll start with the question from the title here and come back to your other questions.
The entity ruler works using patterns, so you should loop over your dictionary to create patterns. Exactly what patterns depends on the kind of match you want - maybe you want to match all of those if they match regardless of case, in which case you could use them as Phrase Matches and make the entity ruler match on the LOWER attribute. That would look a bit like this. You don't have to use a blank pipeline here, but it will be faster, see here for notes. On the other hand, if you want to match on values set by other components, such as part of speech tags, you would need to use components that set those values. If you're just matching literal strings using a blank pipeline should be best.
You source the component. Suppose you create your component and save it to disk like this: You could then add it to another pipeline like this: The docs on sourcing pipelines also cover how to do it in a config.
There is no easy way to do this. While using named entities as features for document classification is done sometimes, it's not very common. In particular, if you're just matching literal strings it probably doesn't provide much over what the text classifier would learn itself, since it will already learn values for all the words it sees. Some of the ways you could use the entities would be:
Sorry that was confusing. The difference between these two ways of creating the pipeline isn't really important here -
Have you seen the example projects? Not sure if it's what you had in mind, but they cover data preprocessing, model training, and packaging the final model. |
Beta Was this translation helpful? Give feedback.
-
|
Since I saw another question about it recently (maybe on Stack Overflow), I spent a little time searching for papers, blog posts, or other reports of using named entities as features for text classification, and I found less than I expected. This paper from 2017 on the topic was intended to evaluate whether NE features were helpful and concluded they weren't, but the methods they use all seem to be very old - SVM, KNN, Naive Bayes, etc. https://api.semanticscholar.org/CorpusID:54774880 This paper from this year suggested they were helpful, but it seems like a very limited circumstance, and again is using very old classification methods - no word vectors or LSTMs here, it's SVMs, tf-idf, etc. https://api.semanticscholar.org/CorpusID:238744574 It's also hard to find this topic because NER is sometimes considered to have a subtask of "Named Entity Classification", and most of the search results are documents about that. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @polm, I really appreciate your detailed answer, definitely helped me forward a bit. I'll prefix this again with that I have no real knowledge in NLP, and this is the first time I'm actually touching on it. I was previously able to create an entity ruler, based on a Which you helpfully explained here. But it's not something I saw in the docs before, I'm happy to somehow add it in, although I'm not sure if my beginner point of view would be helpful there.
I'll skip the part about text classification, as it seems that's a more comprehensive subject, and definitely seems like something I'm just not ready for yet.
I did look at all the sample project, which were super helpful. I suppose where it confused me, was that they all use the spaCy CLI, and I had a difficult time understanding how I could then integrate those as part of another pipeline. In that sense, I found the docs slightly confusing, because it often switches between showing the code, and how to implement it, but then also switches to just using the CLI. I'm more than happy to contribute to the docs as I go through them, but I'm a bit worried that my contributions would be a bit too "basic". |
Beta Was this translation helpful? Give feedback.
-
Glad I could help. Where in the docs do you think it would be helpful to make an addition, and what was the part that cleared things up for you? Was it the saving part, the loading part, or something else?
The Entity Ruler will work fine in a blank pipeline, as long as you don't need attributes set by other components. Lemmas are set by a lemmatizer so that wouldn't work in a blank pipeline, for example. The EntityRuler should come after any components that it relies on annotations from. Besides that, the order only matters if the entity labels interact with other components.
It sounds like you haven't trained a text classifier at all yet? Using the EntityRuler output as features for textcat is complicated, but doing text classification by itself shouldn't be tricky. One general tip for machine learning projects is to start with something that works, even if it's not quite what you want, and change it one piece at a time. In particular, using a simple method to get a "baseline" score and only then comparing it to an advanced model is how you prove that your extra work was worth it. (This is useful for any engineering project, but it's especially important for ML.) So for example you can copy one of the spaCy example projects with textcat, and then replace the example data with your data. Change the preprocessing script so it works and try training a model. Etc.
The double NER project has an example of combining multiple pipelines that might be helpful. Also note it is fine to have multiple pipelines without combining them.
Can you point out a section where that happened? |
Beta Was this translation helpful? Give feedback.
-
I think it would fit fairly well somewhere under https://spacy.io/usage/saving-loading#_title. It does talk about how to save and load your model, but the
I guess this is where my lack of understanding of NLP comes in, I assumed that having more data (as in, more labeled entities), would somehow help the classifier. But I understand now that it just comes back to providing more training data, and that my entity ruler will just help with labeling the data. I had tried to train a classifier before, which is fairly easy with the CLI. But in that sense, in my mind, it was almost too easy, so I assumed there was more to it.
This is actually a really great tip. From my point of view, I had in mind what I wanted to achieve, and wanted to work against that. But I now understand that perhaps I need to split it up into smaller pieces, and accept that it won't be perfect from the start. |
Beta Was this translation helpful? Give feedback.
-
|
I think my question is similar to the parts of the question above, especially I have a project that has a training step for an ner model and then another training for a text classification step, which is not the basic textcat but the textcat_multilabel that gets applied to a each sentence via a segmentation step prior to the textcat_multilabel step. It does not seem possible to use the entityRuler in between these steps and I dont think it would matter even if they were not trained components I still cant see how I would add it. I understand and am able to add an entityRuler to a pipeline that I create via python code but not if its a step in a spacy project. In most attempts I get a I can sorta get it to work in two different ways, one that creates an nlp object from English() and will have predictable bugs because basically what it does is take the current doc and apply the pipeline and then identify any ents from the entityRuler and add those to the doc.ents but earlier retokenize steps make the index from the English() nlp object no longer align. The other way of getting working tells me that the component is in the pipeline but it does not have any impact which I think is because it does not modify the doc in any way and just adds the component to the pipeline but never makes the logic change the doc object. This is odd though because it is how you use the entityRuler in other contexts so it seems like having the logic in the pipeline is not the same as having the logic modify the doc in the pipeline. This is also where I was thinking it is likely easier to just use the Matcher because it creates a thing that can be used without creating a recursion error. Another item that seems like an error or bug that pops up here that the two different methods of creating the entity ruler produce different results.
In these two images you can see how the ents only created by one of the documented methods and the other does not do anything. You can also see in that code how I was attempting to add the new ents from the commented out code, but that creates errors because the offsets from the English nlp object will not align with the current doc offset. So ideally you could use the nlp pipeline that is created up through that component. But if you change uncomment out the nlp = self.nlp and comment nlp = English() it claims the entityRuler already exists in the current pipeline. Moving that step of adding the entityRuler to the init method though is what recreates the recursion issue. |
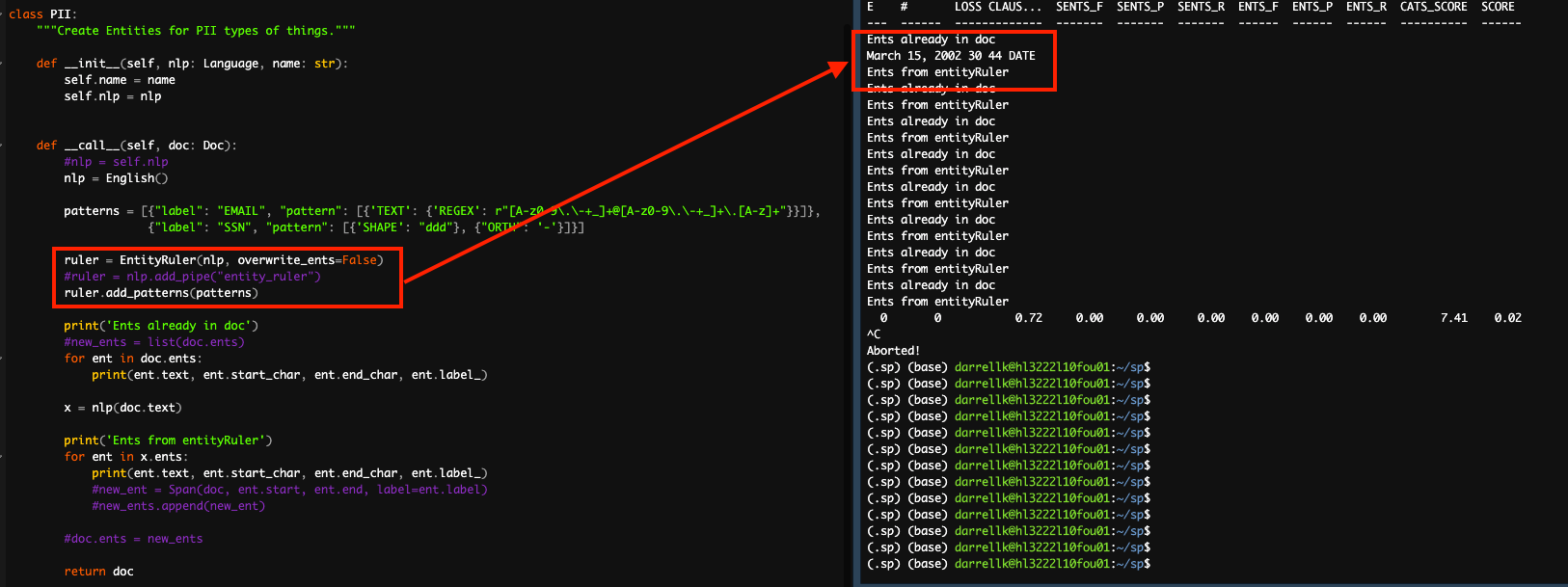
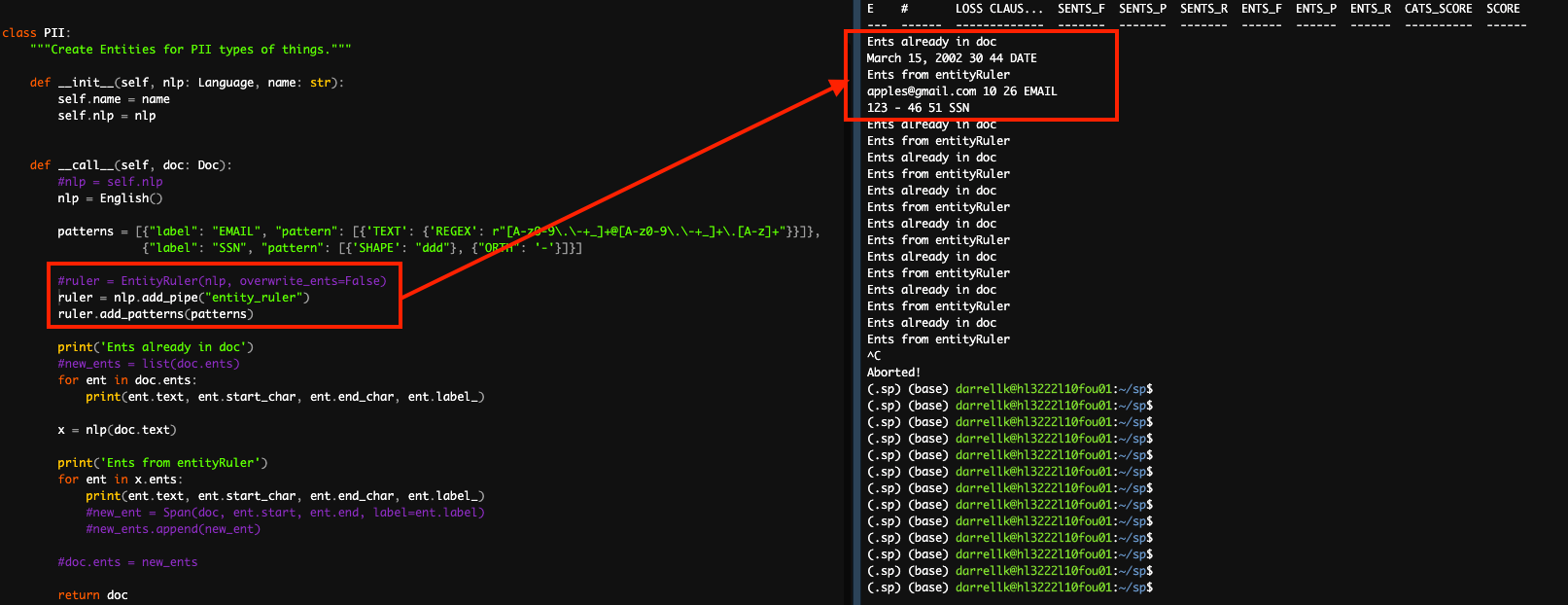
Beta Was this translation helpful? Give feedback.
-
|
Please don't paste screenshots of code, copy and paste the code as text. Your code works differently because it's doing different things. This creates an EntityRuler, but it's just an object in memory - it's not attached to any pipeline. Thus it doesn't do anything. This actually adds a ruler to your pipeline. If you don't create your ruler this way there's no way for it to be connected to the It seems like there are a lot of things going on in your code. Maybe you can open a new Discussion and include a code sample or a link a to a repo with your code so that it's easier to troubleshoot? |
Beta Was this translation helpful? Give feedback.
-
|
I will try to create a new discussion. I'm not sure how to digest that second to last sentence though, about if the ruler is not created that way there is no way for it to be connected to the nlp object. Is that nlp object the one that ends up being loading after building and installing the package then loading with spacy.load()? I also dont actually want the EntityRuler in the pipeline the goal was for the pii component to be added to the pipeline. |
Beta Was this translation helpful? Give feedback.
-
|
The pipeline - which is the same as the If that doesn't clear things up feel free to open a new discussion with code as text and a description of your problem. |
Beta Was this translation helpful? Give feedback.
-
|
That was how my mental model of pipelines and components worked prior to Spacy version 3 but that doesn't seem like it can be the full story for Spacy version 3. That still is how I think about building a pipeline in interactive code but the process that builds a pipeline of components when using Spacy projects complicates that issue. As an example, for the logic I was originally trying to implement with the EntityRuler, I was able to implement using a Matcher. Here is the code for this component. import spacy
from spacy.language import Language
from spacy.tokens import Doc
from spacy.tokens import Span
from spacy.matcher import Matcher
from spacy.tokens import Token
from spacy.util import filter_spans
from itertools import *
@Language.factory("con.PII.v1")
def create_PII(nlp: Language, name: str):
return PII(nlp.vocab)
class PII:
"""Create Entities for PII types of things."""
def __init__(self, vocab):
self.matcher = Matcher(vocab)
self.vocab = vocab
patterns = [[{'SHAPE': "ddd"}, {"ORTH": '-'}]]
self.matcher.add("SSN", patterns)
def __call__(self, doc: Doc):
matches = self.matcher(doc, as_spans=True)
matches = filter_spans(matches)
new_ents = list(doc.ents)
for span in matches:
new_ent = Span(doc, span.start, span.end, label=self.vocab.strings[span.label])
new_ents.append(new_ent)
doc.ents = new_ents
return docIn this example though the Matcher is not actually meant to be a component in the pipeline, the pii component is what will end up in the pipeline. All the permutations I was mentioning for the EntityRuler were an attempt to use that construct to build the custom pii component which is desired to be in the resultant pipeline. There are multiple trained components that are build in this project/package. I do not however fully grasp the process that adds them to the pipeline as a component though. What seems to be sufficient is for the next trained component that requires a config file to declare this component in the pipeline portion of the nlp portion. If I run all the training steps up through the first item after the PII component and then package that content with
This is why I thought this issue was related to the original question, I was trying to use the EntityRuler in a step that is part of a larger project and that step occurs prior to a text classification step. The clausecat component here is a textcat_multilabel that gets applied to each sentence of the input doc which the segmentation component sets up. The conclusion I had come to was that it is not possible to use the EntityRuler in a spacy project that gets built into a larger pipeline of components. Instead if that functionality is desired the Matcher should instead be used like in the PII code above. The question about |
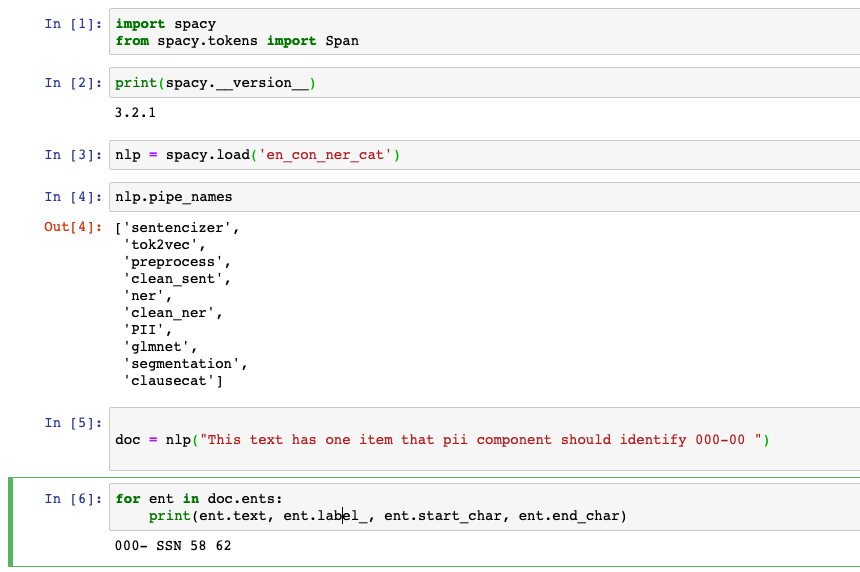
Beta Was this translation helpful? Give feedback.
-
|
OK, thanks for the code, that clarifies what you're trying to do. It looks to me like your PII component is basically the same thing as an EntityRuler. An EntityRuler wraps a Matcher (which is not a component by itself) so it can go in a pipeline. Is your PII component supposed to do something different from an EntityRuler with the same patterns? About the more general idea, a pipeline really is just a list of components, and you can think of it as being assembled by multiple calls to When a pipeline is loaded from a config, spaCy just walks through the list in In your case, assuming you have all your other components in a trained pipeline and want to add PII, I think the following will do what you want: |
Beta Was this translation helpful? Give feedback.
-
|
Adding an entityRuler component in this way seems problematic for a few reasons. The first is that this would mean that a component that was trained on input that is all processed in a very specific way will now be going forward when it is actually used and evaluated only see data that was processed in a different way because it has this new step added. I have always treated that process as an ML anti-pattern as it is a common culprit for training-serving skew. The following trained component does not specifically use those features but if you were to use Those issues are more generic but there are also project specific issues related to specifics of the overall pipeline. The config and pipeline in the code are specific to the next trained component after the intended use of the entityRuler and not the end of the full pipeline. There is another trained component after the clausecat textcat_multilabel component that is a trained relation extraction component and some of the entity relations depend on the entity created from that step. The other issue is that there are patterns that catch specific instances of existing entities. Since the patterns and code were simplified to make it easier to add an example is needed. The pii component that uses the Matcher and the attempted version that use the entityRuler loop through the result matches. In that code it shows the loop creating a new span and then adding that span to a growing list that eventually get added to the doc's It also seems like maybe even attempting to use the entityRuler in a spacy project is probably not optimal and should use the Matcher instead, especially as the former is a wrapped version of the latter. The initial goal was to use the entityRuler inside the larger spacy project to assist with the logic in one of the components. Using the Matcher sufficiently resolves any of the issues that arise from trying to use the entityRuler so I was less trying to get something to work but more trying to figure out how or if the entityRuler could be used inside a spacy project and by project not just a project that uses spacy but more specifically a Spacy Projects project. I created a project here that uses the textcat_docs_issues repo as a base and only adds the entityRuler step. There are a few versions of the pii.py file in there that all fail in different ways. Another item to note here is version that will be called now fails with the error below. The config file declares the pipeline as |

Beta Was this translation helpful? Give feedback.
-
|
To address one point - my suggestion was to use the EntityRuler instead of your PII component. Your PII component seems to be doing the same thing as an EntityRuler, but with specific patterns. In your initial screenshot code sample, it wasn't clear that PII was supposed to be a component - you didn't include that part of the code, so it looked like that was your whole program. You shouldn't call |
Beta Was this translation helpful? Give feedback.
-
|
Hi @darrkj, it definitely takes some time getting used to the v3 config and projects systems. Have you had a chance to look into the video's we distributed to explain these concepts in more detail? cf https://www.youtube.com/watch?v=9k_EfV7Cns0 & https://www.youtube.com/watch?v=BWhh3r6W-qE&t=2s It can really help to understand the design in general when implementing a specific pipeline for a specific use-case.
You should definitely be able to use the I have to admit to you that I find it very hard to follow all your other questions and comments. An example code snippet or config file typically paints a thousand words. If you have further questions - please create a new discussion thread and share actual code (not screenshots) to help us better understand the specific issues you run into. Thanks! |
Beta Was this translation helpful? Give feedback.
-
|
I added a zip file above that has code for a simplified project that tries to add the EntityRuler. It is very minimal and just added that to a project from the tutorials repo. I was able to implement the desired logic using the Matcher component though so this was more to flesh out my understanding of how that component is able to be used in a larger pipeline. I was trying to add the entity ruler as a component to a pipeline with other components being trained in the pipeline. This component was named PII as it detected personally identifiable information and thus it was implemented in a python script called pii.py. The component after pii is a trained textcat_multilabel. Inside the config file I add the PII component to the nlp pipeline and also specify the factory for it. I went back through the implementations I had tried and it looked as though there are a few aspects that can be done in one of two ways. I essentially tried each permutation of the prior mentioned items. I was able to get it to work, the code for that is below. @Language.factory("con.PII.v1")
def create_PII(nlp: Language, name: str):
return PII(nlp, name)
class PII:
"""Create Entities for PII types of things."""
def __init__(self, nlp: Language, name: str):
self.nlp = nlp
self.name = name
patterns = [{"label": "SSN", "pattern": [{'LOWER': "virtual"}, {"LOWER": 'appliance'}]}]
ruler = EntityRuler(self.nlp, overwrite_ents=False)
ruler.add_patterns(patterns)
self.ruler = ruler
def __call__(self, doc: Doc):
new_ents = list(doc.ents)
x = self.ruler(doc)
for ent in x.ents:
new_ent = Span(doc, ent.start, ent.end, label=ent.label)
new_ents.append(new_ent)
doc.ents = new_ents
return docIn retrospect some parts of it make sense as to why certain things are this way but other aspects dont seem intuitive as to why it is like this. Also when I said this version works more specifically I meant that the Some permutations were able to get through some of those steps but not all and thus considered to not work. As an example one of the permutations that seemed like a natural progression of debugging was to use It also leads me to think there is a problem with this statement from earlier in the thread:
I think I see the intent but it seems to conflict the script above. Is this a better way to capture the distinction between these two:
Sorry for the confusion, and thanks to both you and @polm for taking the time to respond and discuss this. |
Beta Was this translation helpful? Give feedback.
-
|
Could someone please provide a short example of how this EntityRuler init method can be used (from spaCy docs): Specifically, how can an entityruler entity created in this way be added to a pipeline, or is it to be used in an entirely different way, or for a different purpose? |
Beta Was this translation helpful? Give feedback.
-
|
Typically you'd create the Entity Ruler that way if you want to call it on Docs directly, without a pipeline. You may never need to do this, but it can make since if you want to conditionally use a couple of different rulers or something. Since a component is callable, you can just do To add a ruler to a pipeline you'd usually do this: |
Beta Was this translation helpful? Give feedback.
-
|
Many thanks, polm. Makes perfect sense. I'll try calling such a ruler on a doc today just for fun. I've only used the add_pipe() method before. |
Beta Was this translation helpful? Give feedback.
Sorry you're having trouble with this. I'll start with the question from the title here and come back to your other questions.
The entity ruler works using patterns, so you should loop over your dictionary to create patterns. Exactly what patterns depends on the kind of match you want - maybe you want to match all of those if they match regardless of case, in which case you could use them as Phrase Matches and make the entity ruler match on the LOWER attribute. That would look a bit like this.