Error while training Spacy NER with Hindi dataset #11724
Description
Hi, I'm trying to train the Spacy NER transformers model with Hindi language dataset. The issue is there are no F1, Precison and Recall scores changing at all as mentioned in the below training table (please look at the attached image).
Steps to reproduce
!pip install -U spacy-transformers
Successfully converted .conll files to .spacy files using spacy convert command. After conversion to .spacy, total train documents, 30559 and test 3665.
Training - !python -m spacy train /final_config.cfg --output /content/output --paths.train train.spacy --paths.dev test.spacy --gpu-id 0
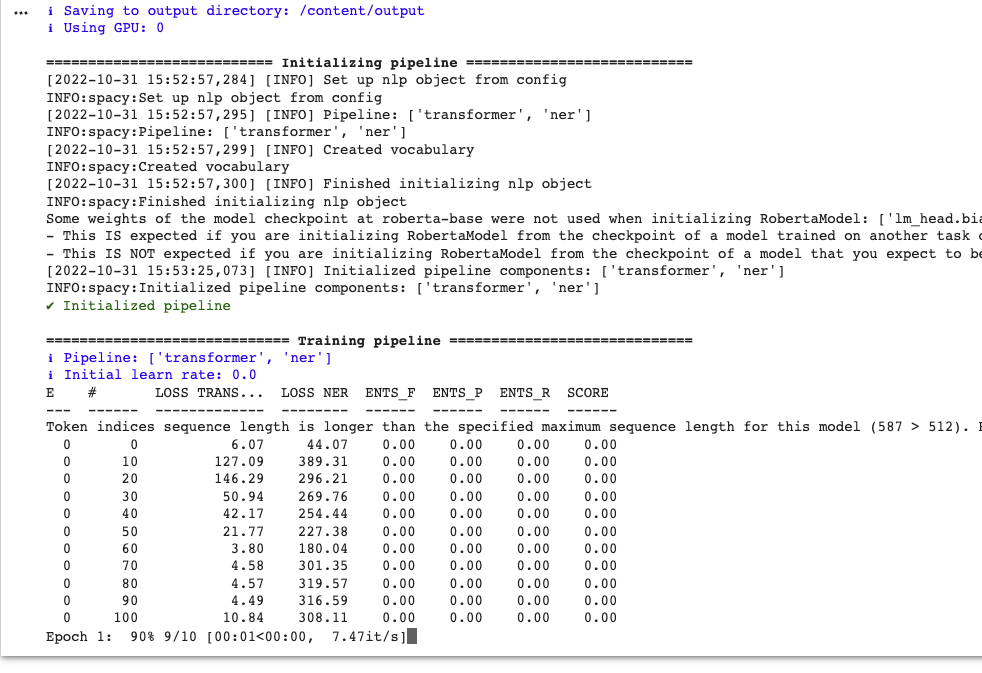
Final configuration file.
`[paths]
train = null
dev = null
vectors = null
init_tok2vec = null
[system]
gpu_allocator = "pytorch"
seed = 0
[nlp]
lang = "hi"
pipeline = ["transformer","ner"]
batch_size = 128
disabled = []
before_creation = null
after_creation = null
after_pipeline_creation = null
tokenizer = {"@Tokenizers":"spacy.Tokenizer.v1"}
[components]
[components.ner]
factory = "ner"
incorrect_spans_key = null
moves = null
scorer = {"@scorers":"spacy.ner_scorer.v1"}
update_with_oracle_cut_size = 100
[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
state_type = "ner"
extra_state_tokens = false
hidden_width = 64
maxout_pieces = 2
use_upper = false
nO = null
[components.ner.model.tok2vec]
@architectures = "spacy-transformers.TransformerListener.v1"
grad_factor = 1.0
pooling = {"@layers":"reduce_mean.v1"}
upstream = "*"
[components.transformer]
factory = "transformer"
max_batch_items = 50
set_extra_annotations = {"@annotation_setters":"spacy-transformers.null_annotation_setter.v1"}
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
name = "roberta-base"
mixed_precision = false
[components.transformer.model.get_spans]
@span_getters = "spacy-transformers.strided_spans.v1"
window = 128
stride = 96
[components.transformer.model.grad_scaler_config]
[components.transformer.model.tokenizer_config]
use_fast = false
[components.transformer.model.transformer_config]
[corpora]
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[training]
accumulate_gradient = 3
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
patience = 1600
max_epochs = 0
max_steps = 20000
eval_frequency = 10
frozen_components = []
annotating_components = []
before_to_disk = null
[training.batcher]
@batchers = "spacy.batch_by_padded.v1"
discard_oversize = false
size = 50
buffer = 256
get_length = null
[training.logger]
@Loggers = "spacy.ConsoleLogger.v1"
progress_bar = true
[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 0.00000001
[training.optimizer.learn_rate]
@schedules = "warmup_linear.v1"
warmup_steps = 250
total_steps = 20000
initial_rate = 0.00005
[training.score_weights]
ents_f = 1.0
ents_p = 0.0
ents_r = 0.0
ents_per_type = null
[pretraining]
[initialize]
vectors = ${paths.vectors}
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
before_init = null
after_init = null
[initialize.components]
[initialize.tokenizer]`
I have modified default values of few parameters in the config file as I was getting CUDA out of memory exception.
- lang - "hi"
- max_batch_items = 50
- eval_frequency = 10
- size = 50
Info about spaCy
`- spaCy version: 3.4.2
- **Notebook - Google Colab
- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.15
- Pipelines: en_core_web_sm (3.4.1)`