doc.set_ents uses tokens but Span uses char #7128
Description
I'm trying to remove trailing special character at the end of entities. However, doc.set_ents uses token but Span uses character count. What's a good way to resolve this conflict?
from spacy.language import Language
from spacy.tokens import Span
import re
nlp = spacy.load("en_core_web_lg")
@Language.component("remove_special")
def remove_spcials(doc):
for ent in doc.ents:
text = ent.text
print(ent.text, ent.start_char, ent.end_char)
tmp = re.search("[#|.|,|%|@|\s]$", text)
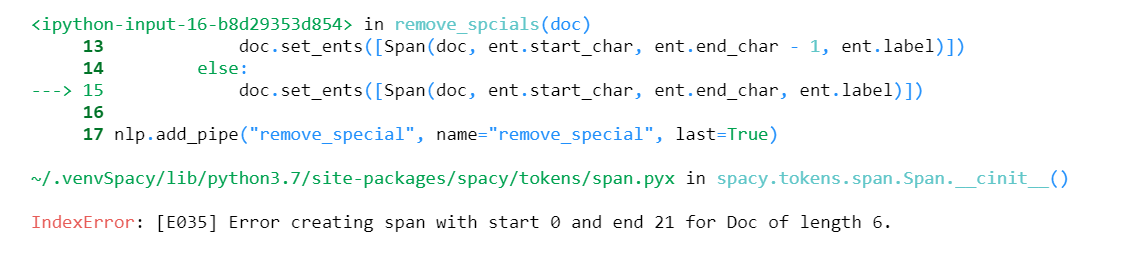
if tmp != None:
doc.set_ents([Span(doc, ent.start_char, ent.end_char - 1, ent.label)])
else:
doc.set_ents([Span(doc, ent.start_char, ent.end_char, ent.label)])
nlp.add_pipe("remove_special", name="remove_special", last=True)
print(nlp.pipe_names)
doc = nlp("Today is Feb 8th 2021.")