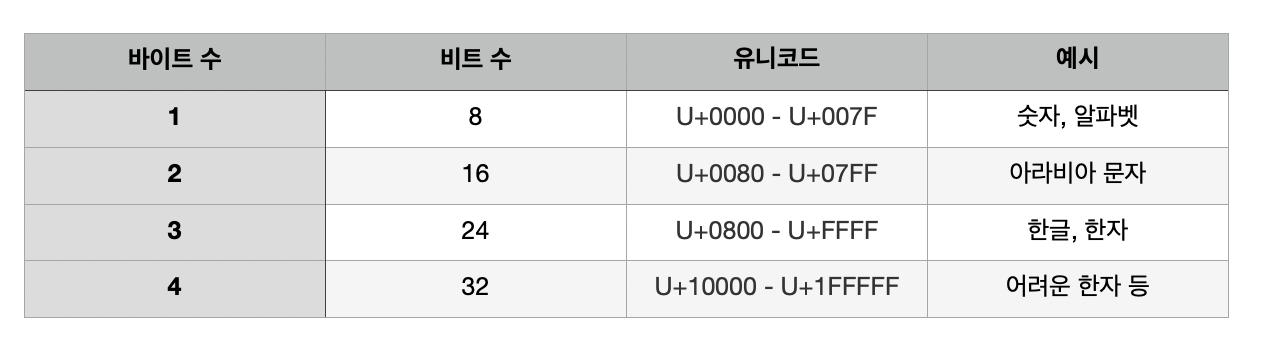
우리는 어떻게 decimal number 를 binary code 로 바꾸는지 알고 있습니다. 182 -> 10110110.
그렇다면 문자는 어떻게 binary code로 바꿀 수 있는 것일까요?
키보드를 한번 살펴봅시다. 각각의 키는 어떤 숫자와 연결되어 있습니다. 우리가 어떤 키를 치던간에 그 키에 해당하는 문자는 decimal number(십진수)와 mapping됩니다.
예로 대문자 A는 십진수로 65이고, 이것을 이진수로 변환하면 1000001이 되어 컴퓨터가 인식할 수 있습니다.
바로 위와 같이 쓰기로 약속하고 이 체계를 표로 정리한 것이 바로 ASCII Code입니다.
ASCII는 The American Standard Code for Information Interchange의 줄임말로, 이름에서 알 수 있듯이 미국에서 제정되었기 때문에
알파벳 대문자, 소문자 그리고 0~9까지의 숫자, 그리고 몇가지 symbol로 구성되어 있습니다.
ASCII Code는 7bits로 표현됩니다. 즉 127개의 서로 다른 문자 및 숫자 등을 표현할 수 있습니다.
몇가지 command(명령어)를 살펴보면...
backspace -> 0001000(8)
escape -> 0011011(27)
Tab -> 0001001(9)
Enter -> 001101(13)
Delete 111111(127)
이렇게 mapping되어 있습니다. Delete는 127로 ASCII Code로 표현할 수 있는 마지막 문자입니다.
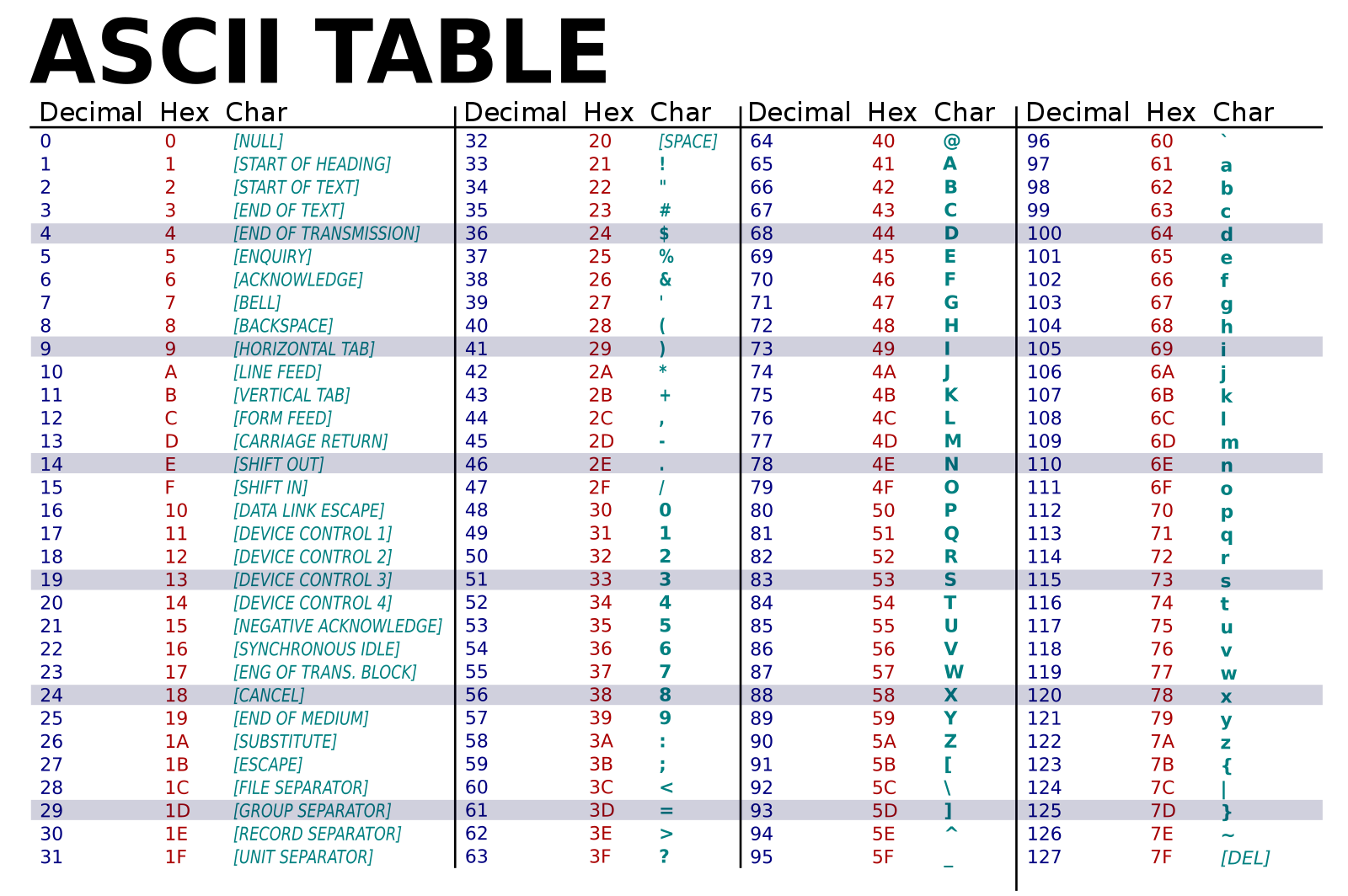 (출처: https://en.wikipedia.org/wiki/File:ASCII-Table-wide.svg).
(출처: https://en.wikipedia.org/wiki/File:ASCII-Table-wide.svg).
{kind=link}
위의 ASCII code 테이블에는 기본적인 127개의 문자를 보여주고 있습니다.
이후 IBM에서 8-bit ASCII code, 기존 ASCII Code의 확장형을 만들어 새로운 심볼, 사인, 문장 부호, 스페인어 등을 추가했다고 합니다.
IBM에서 만든 IBM-PC, MS-DOS 같은 모델에서 실제로 이 확장된 ASCII code를 사용한다고 합니다.
그런데 여기에는 문제점이 있습니다. 아무리 ASCII Code를 확장했다고 하더라도 ASCII 표준에 포함되지 않는 다른 문자가 너무나도 많다는 것입니다.
Greek, Hebric, Arabic, Korean, Japanese, Chinese, Emoji 등 이 모든 것을 표현하기에 부족합니다.
이 문제점을 해결하기 위해서 Unicode를 사용하게 됩니다. Unicode는 ASCII와 비슷하게 문자들이 숫자들과 연결되어있다는 점에서는 같지만,
ASCII보다 더 많은 bits를 사용할 수 있다는 점에서 차이가 있습니다.
Unicode는 더 확장되어서 8, 16, 32bits 로도 사용할 수 있는데요, 32bits를 사용할 수 있다는 것은 총 2,147,483,647개의 문자를 나타낼 수 있다는 것을 의미합니다.
확실히 ASCII에 비해 어마어마한 양이죠?
Encoding은 간단하게 이야기하면 인간의 언어를 컴퓨터의 언어로 바꿔주는 것입니다.
ASCII Code에서는 문자에 mapping 되어 있는 숫자를 2진수로 바꾸면, 그 값이 메모리에 저장된다고 해도 무방합니다.
아까 봤던 예시에서 A와 매칭되어 있는 65를 이진수로 변환한다면 하나의 byte 안에서는 다음과 같이 표현할 수 있습니다.

하지만 Unicode는 문자를 Encoding하고 메모리에 저장하는 과정에서 ASCII Code와 차이가 있습니다.
ASCII Code는 단 하나의 byte를 사용했지만, Unicode는 문자와 매핑된 정수를 몇 bytes를 사용해서 변환해서 메모리에 할당해야할지 정해지지 않은 상태입니다.
A와 정수 65와 매핑되면 이때 65를 decimal code point, 100001 binary code point라고 부릅니다.
Unicode에서 이 code point는 아직 메모리에 어떻게 표현될지 정해지지 않은 상태인 것입니다.
따라서 어떤 Encoding방식을 사용하는지에 따라서 메모리에 저장되는 형태가 달라질 것입니다.
3가지의 대표적인 Encoding(or Decoding) 방식이 바로 Utf-32, Utf-16, Utf-8 입니다.
이 방식들이 가장 널리 사용되는 Encoding 시스탬이고, 많은 사람들이 이 방법을 쓰자고 약속한 것입니다.
특히 Utf-8은 웹 어플리케이션 환경에서 대표적으로 쓰이고 있습니다.
Mapping된 정수 4 bytes(32 bits)로 저장하기로 약속한 것입니다.
만약 Code point가 100001이면
0000000 ….. 01000001 (4 bytes) 로 표현이 되어 메모리에 저장될 것입니다.
하지만 Utf-32방식은 메모리 낭비가 심해서 잘 사용하지 않습니다.
특히 서구권에서는 single byte로 표현할 수 있는 알파벳을 굳이 4bytes로 변환해야 하기 때문에 더더욱 사용하지 않는다고 합니다.
1KB 파일을 Utf-32방식으로 인코딩을 하면 4KB가 되어버립니다.
많은 사람들이 Utf-32는 32비트로 나타냈으니 Utf-16 역시 16비트로 나타낸거고 Utf-8은 8비트로 나타낸 것이라고 생각하는데 아닙니다.
Utf-16는 16bits 또는 32bits로 표현됩니다.
16bits 하나 또는, 16bits 2개로 나타냅니다.
OR

이러한 character set을 variable length character set 이라고도 하는데, 메모리의 비트 길이가 정해지지 않았기 때문입니다.
code point가 1000001(A)이라면, 이것은 16bits로 나타낼 수 있으므로 16bits를 사용합니다.
그리고 위의 경우에는 첫번 째 byte를 모두 0으로 채웁니다. 두번 째 바이트는 16진법으로 표현했을 때 41(이진법으로 1000001)이 들어오게 됩니다.
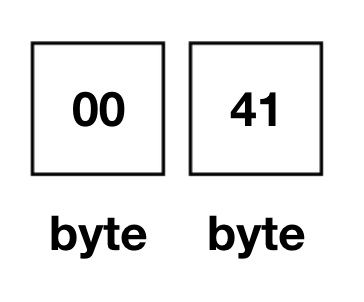
(Binary -> 00000000 01000001)
00 41 (little endian) vs 41 00(big endian)
사실 Unicode에서 ASCII와 중복되는 문자들은 똑같이 mapping되어 있기 때문에 같은 code points를 가지고 있습니다. 하지만 ASCII에 있는 문자들을 담은 파일이 하나의 byte가 아닌 Utf-16 방식으로 변환되어야 하기 떄문에 Utf-16는 ASCII와 하위 호환이 되지 않습니다.
Utf-16와 마찬가지로 Utf-8의 8은 고정된 값이 아닙니다. Utf-8은 multi byte character set입니다. 8bits(1byte), 16bits(2byte), 24bits(3byte), 32bits(4byte)로 표현할 수 있습니다.
그렇다면 utf-8체계에서 메모리에 저장된 어떤 값을 decoding 한다고 가정해봅시다. 그런데 위의 4개 중에서 대체 어떤 byte로 encoding이 된걸까요? Decoding을 제대로 하기 위해서는 어떤 byte로 encoding이 되었는지 반드시 알아야 합니다.
이를 위해 marker가 존재하는데요, 만약 byte의 첫번째 bit가 0이라면 이것은 1byte로 인코딩되었다고 봅니다.

이러한 경우는 ASCII 코드가 0 ~ 127까지 표현 가능하고 1bytef로 표현하기 때문에 ASCII와 하위 호환이 된다고 합니다.
Code point가 127보다 크면 multi-byte sequence를 사용해야할 것입니다.
만약 인코딩 된 것의 바이트가 110으로 시작하면,(110xxxxx) 이것은 문자가 2bytes로 인코딩 되었다는 것을 의미합니다.

Leading byte -> 어떤 byte로 인코딩 되었는지 알려준다. 110으로 시작하면 2bytes로 인코딩 되었다는 것을 의미한다. continuation byte -> Leading byte 뒤에 따라온다. continuation byte의 맨 앞 부분은 10으로 표기된다.
만약에 3bytes로 인코딩 되었다면 어떨까요?
1110으로 시작하는 Leading byte와 뒤에 2개의 continuous bytes가 있을 것입니다.

만약에 4bytes가 인코딩될 때 사용되었다면?
11110으로 시작하는 Leading byte와 뒤에 3개의 continuous bytes가 있을 것입니다.
11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
Quiz! Utf-8를 표기한 것으로 알맞지 않은 것은?
- 01001010
- 11001010
- 11101010 10110010 10010011
- 11010010 11001110
11000110 10011101
이렇게 인코딩 된 것이 있다고 가정해봅시다.
여기서 marker가 아닌 부분을 가져와서 붙입니다.
00110 + 011101 -> 00110011101 00110011101라는 binary code point를 가리키는 것입니다. 이것을 10진수로 변환하면 413입니다.