 +#
+#
+#
+# head to display the first 5 columns of the dataframe.
+
+# In[23]:
+
+
+df.head()
+
+
+# ### Question 1
+# Display the data types of each column using the attribute dtype, then take a screenshot and submit it, include your code in the image.
+
+# In[24]:
+
+
+df.dtypes
+
+
+# We use the method describe to obtain a statistical summary of the dataframe.
+
+# In[25]:
+
+
+df.describe()
+
+
+# # Module 2: Data Wrangling
+
+# ### Question 2
+# Drop the columns "id" and "Unnamed: 0" from axis 1 using the method drop(), then use the method describe() to obtain a statistical summary of the data. Take a screenshot and submit it, make sure the inplace parameter is set to True
+
+# In[26]:
+
+
+df.drop(["id","Unnamed: 0"],axis=1,inplace=True)
+df.describe()
+
+
+# We can see we have missing values for the columns bedrooms and bathrooms
+
+# In[27]:
+
+
+print("number of NaN values for the column bedrooms :", df['bedrooms'].isnull().sum())
+print("number of NaN values for the column bathrooms :", df['bathrooms'].isnull().sum())
+
+
+#
+# We can replace the missing values of the column 'bedrooms' with the mean of the column 'bedrooms' using the method replace(). Don't forget to set the inplace parameter to True
+
+# In[28]:
+
+
+mean=df['bedrooms'].mean()
+df['bedrooms'].replace(np.nan,mean, inplace=True)
+
+
+#
+# We also replace the missing values of the column 'bathrooms' with the mean of the column 'bathrooms' using the method replace(). Don't forget to set the inplace parameter top True
+
+# In[29]:
+
+
+mean=df['bathrooms'].mean()
+df['bathrooms'].replace(np.nan,mean, inplace=True)
+
+
+# In[30]:
+
+
+print("number of NaN values for the column bedrooms :", df['bedrooms'].isnull().sum())
+print("number of NaN values for the column bathrooms :", df['bathrooms'].isnull().sum())
+
+
+# # Module 3: Exploratory Data Analysis
+
+# ### Question 3
+# Use the method value_counts to count the number of houses with unique floor values, use the method .to_frame() to convert it to a dataframe.
+#
+
+# In[39]:
+
+
+df['floors'].value_counts().to_frame()
+
+
+# ### Question 4
+# Use the function boxplot in the seaborn library to determine whether houses with a waterfront view or without a waterfront view have more price outliers.
+
+# In[40]:
+
+
+sns.boxplot(x=df['waterfront'],y=df['price'],data=df)
+
+
+# ### Question 5
+# Use the function regplot in the seaborn library to determine if the feature sqft_above is negatively or positively correlated with price.
+
+# In[42]:
+
+
+sns.regplot(x=df['sqft_above'],y=df['price'],data=df)
+
+
+#
+# We can use the Pandas method corr() to find the feature other than price that is most correlated with price.
+
+# In[43]:
+
+
+df.corr()['price'].sort_values()
+
+
+# # Module 4: Model Development
+
+#
+# We can Fit a linear regression model using the longitude feature 'long' and caculate the R^2.
+
+# In[44]:
+
+
+X = df[['long']]
+Y = df['price']
+lm = LinearRegression()
+lm.fit(X,Y)
+lm.score(X, Y)
+
+
+# ### Question 6
+# Fit a linear regression model to predict the 'price' using the feature 'sqft_living' then calculate the R^2. Take a screenshot of your code and the value of the R^2.
+
+# In[45]:
+
+
+X2 = df[['sqft_living']]
+Y2 = df['price']
+lm2 = LinearRegression()
+lm2.fit(X2,Y2)
+lm2.score(X2, Y2)
+
+
+# ### Question 7
+# Fit a linear regression model to predict the 'price' using the list of features:
+
+# In[47]:
+
+
+features =["floors", "waterfront","lat" ,"bedrooms" ,"sqft_basement" ,"view" ,"bathrooms","sqft_living15","sqft_above","grade","sqft_living"]
+
+
+# Then calculate the R^2. Take a screenshot of your code.
+
+# In[48]:
+
+
+X3 = df[features]
+Y3 = df['price']
+lm3 = LinearRegression()
+lm3.fit(X3,Y3)
+lm3.score(X3, Y3)
+
+
+# ### This will help with Question 8
+#
+# Create a list of tuples, the first element in the tuple contains the name of the estimator:
+#
+# 'scale'
+#
+# 'polynomial'
+#
+# 'model'
+#
+# The second element in the tuple contains the model constructor
+#
+# StandardScaler()
+#
+# PolynomialFeatures(include_bias=False)
+#
+# LinearRegression()
+#
+
+# In[49]:
+
+
+Input=[('scale',StandardScaler()),('polynomial', PolynomialFeatures(include_bias=False)),('model',LinearRegression())]
+
+
+# ### Question 8
+# Use the list to create a pipeline object to predict the 'price', fit the object using the features in the list features, and calculate the R^2.
+
+# In[54]:
+
+
+pipe=Pipeline(Input)
+pipe.fit(X3,Y3)
+pipe.score(X3,Y3)
+
+
+# # Module 5: Model Evaluation and Refinement
+
+# Import the necessary modules:
+
+# In[55]:
+
+
+from sklearn.model_selection import cross_val_score
+from sklearn.model_selection import train_test_split
+print("done")
+
+
+# We will split the data into training and testing sets:
+
+# In[56]:
+
+
+features =["floors", "waterfront","lat" ,"bedrooms" ,"sqft_basement" ,"view" ,"bathrooms","sqft_living15","sqft_above","grade","sqft_living"]
+X = df[features]
+Y = df['price']
+
+x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.15, random_state=1)
+
+
+print("number of test samples:", x_test.shape[0])
+print("number of training samples:",x_train.shape[0])
+
+
+# ### Question 9
+# Create and fit a Ridge regression object using the training data, set the regularization parameter to 0.1, and calculate the R^2 using the test data.
+#
+
+# In[61]:
+
+
+from sklearn.linear_model import Ridge
+
+
+# In[63]:
+
+
+model_1=Ridge(alpha=0.1)
+model_1.fit(x_train,y_train)
+model_1.score(x_test,y_test)
+
+
+# ### Question 10
+# Perform a second order polynomial transform on both the training data and testing data. Create and fit a Ridge regression object using the training data, set the regularisation parameter to 0.1, and calculate the R^2 utilising the test data provided. Take a screenshot of your code and the R^2.
+
+# In[64]:
+
+
+pr=PolynomialFeatures(degree=2)
+x_train_pr=pr.fit_transform(x_train)
+x_test_pr=pr.fit_transform(x_test)
+model_2=Ridge(alpha=0.1)
+model_2.fit(x_train_pr,y_train)
+model_2.score(x_test_pr,y_test)
+
+
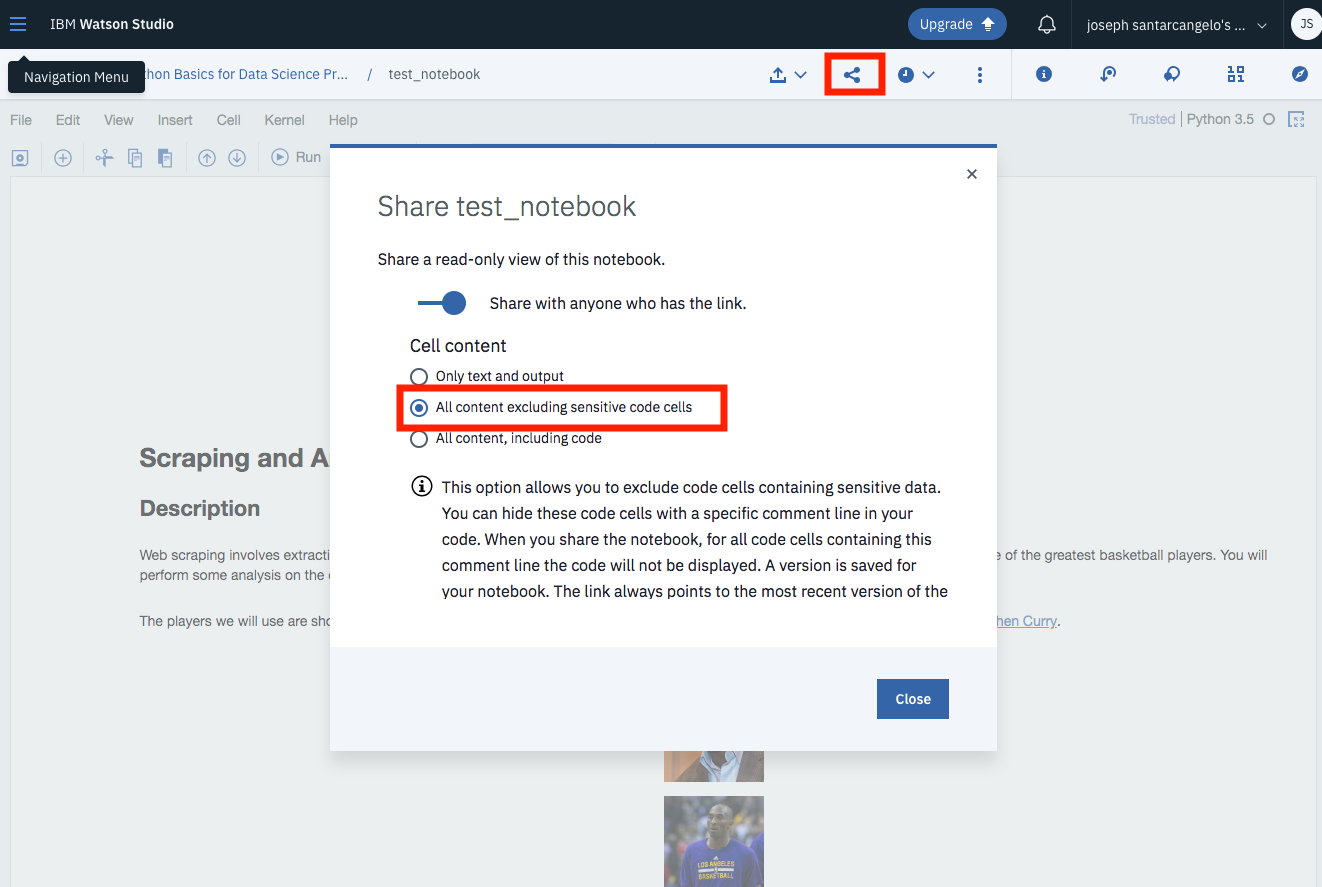
+# Once you complete your notebook you will have to share it. Select the icon on the top right a marked in red in the image below, a dialogue box should open, and select the option all content excluding sensitive code cells.
+#
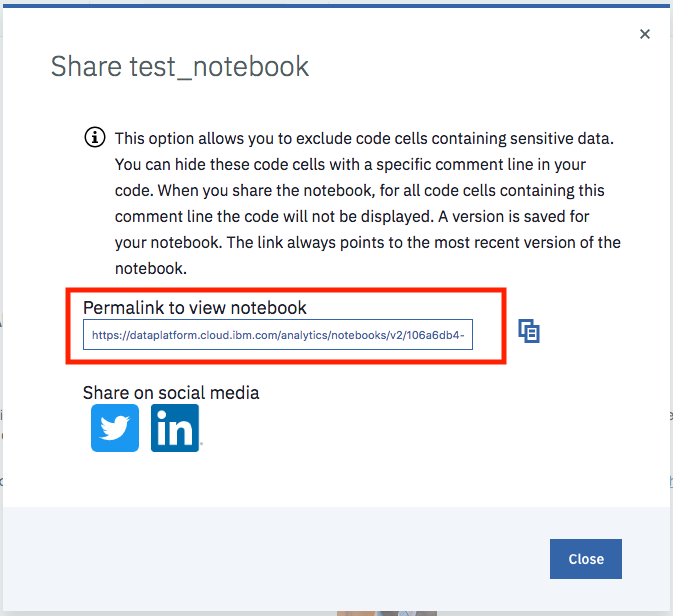
You can then share the notebook via a URL by scrolling down as shown in the following image:
+#
+ +#