diff --git a/Cloud Web App/DynamoDB.md b/Cloud Web App/DynamoDB.md
new file mode 100644
index 0000000..e10ec49
--- /dev/null
+++ b/Cloud Web App/DynamoDB.md
@@ -0,0 +1,57 @@
+# DynamoDB
+
+Amazon DynamoDB is a nonrelational database that delivers reliable performance at any scale. It's a fully managed, multi-region, multi-master database that provides consistent single-digit millisecond latency, and offers built-in security, backup and restore, and in-memory caching.
+
+
+
+## Task1: Create a New Table
+
+1. In the console, click Service, then click DynamoDB.
+2. Click Create table.
+3. For Table name, type: Music
+4. For primary key, type Artist and leave String selected.
+5. Select **Add sorted key**, then in the new field type song and leave **String** selected. Your table will use default setting for indexes and provisioned capacity.
+6. Click Create.
+
+
+
+## Task2: Add Data
+
+1. Click the Items tab, then click Create item.
+
+2. For Artist String, type: Pink Floyd.
+
+3. For song String, type: Money.
+
+4. To create additional attribute, click the plus sign to the left of Song, then click append.
+
+5. In the drop-down list, select String.
+
+6. For the new attribute, enter:
+
+ In FIELD, type: Album
+
+ In VALUE, type: The Dark side of the Moon
+
+7. ...
+
+
+
+## Task3: Modify an Existing Item
+
+1. Click Psy.
+2. Change the Year from 2011 to 2012.
+3. Click save.
+
+
+
+## Task4: Query the table
+
+1. Click the drop-down list showing Scan (located below the Create item button) and change it to Query.
+2. Enter these details: Partition Key, Sort Key.
+3. Click Start Search.
+4. Click Add Filter.
+
+## Task5: Delete the Table
+
+Click the Delete table. On the confirmation panel, click Delete.
\ No newline at end of file
diff --git a/Cloud Web App/Install an LAMP server on Amazon Linux.md b/Cloud Web App/Install an LAMP server on Amazon Linux.md
new file mode 100644
index 0000000..bdaae92
--- /dev/null
+++ b/Cloud Web App/Install an LAMP server on Amazon Linux.md
@@ -0,0 +1,49 @@
+# Install LAMP server on Linux
+
+## Prepare
+
+1. Connect to instance.
+
+2. Ensure that all of software packages are up to date, perform a quick software update on your instance. It is important to make sure that you have the latest security updates and bug fixes
+
+ `sudo yum update -y` is used to update source.
+
+3. Install the lamp-mariadb10.2-php7.2 and php7.2 Amazon Linux Extras repositories to get the latest versions of the LAMP MariaDB and PHP packages for Amazon Linux 2.
+
+ `sudo amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2`
+
+4. Install the Apache web server, MariaDB, and PHP software packages.
+
+ Use the **yum install** command to install multiple software packages and all related dependencies at the same time.
+
+ `sudo yum install -y httpd mariadb-server`
+
+ `yum info package_name` is used to view the current versions of packages.
+
+5. Start the Apache web server.
+
+ `sudo systemctl start httpd`
+
+6. Use the **systemctl** command to configure the Apache web server to start at each system boot.
+
+ `sudo systemctl enable httpd`
+
+7. Add a security rule to allow inbound HTTP (port 80) connections to instance. By default, a **launch-wizard-N** security group was set up for your instance during initialization. This group contains a single rule to allow SSH connections.
+ 1. Open the Amazon EC2 console at .
+ 2. Choose **Instances** and select your instance.
+ 3. Under **Security groups**, choose **view inbound rules**.
+ 4. You should see the following list of rules in your default security group
+8. Test your web server.
+
+## Test
+
+1. Create a PHP file in the Apache document root.
+2. In a web browser, type the URL of the file that you just created. This URL is the public DNS address of your instance followed by a forward slash and the file name.
+
+## Secure the Database Server
+
+1. Start the MariaDB server.
+2. Run **mysql_secure_installation**.
+
+## Install phpMyAdmin
+
diff --git a/Cloud Web App/Launch VM.md b/Cloud Web App/Launch VM.md
new file mode 100644
index 0000000..cd81557
--- /dev/null
+++ b/Cloud Web App/Launch VM.md
@@ -0,0 +1,18 @@
+# Launch VM
+
+1. Launch an Amazon EC2 Instance
+
+2. Configure your Instance
+
+ * Find a suitable system and click select
+ * Configure storage, tagging, and security settings
+ * choose an existing key pair or create a new key pair
+
+3. Connect to instance
+
+ * Open terminal.
+
+ * Use `chmod 400 ~/.ssh/mykeypair.pem` to restrict permissions to your private SSH key.
+ * Use `ssh -i ~/.ssh/MyKeyPair.pem ec2-user@{IP_Address}` to connect instace.
+
+4. Terminate Instace
\ No newline at end of file
diff --git a/Cloud Web App/S3.md b/Cloud Web App/S3.md
new file mode 100644
index 0000000..fe13e78
--- /dev/null
+++ b/Cloud Web App/S3.md
@@ -0,0 +1,22 @@
+# S3
+
+## Overview
+
+Amazon Simple Storage Service(S3) is storage for the Internet. We can use S3 to store and retrive any amount of data at any time, from anywhere on the web.
+
+## Create a bucket in Amazon S3
+
+* In the **AWS Management Console**, on the Services menu, click S3, then configure it.
+* Upload an object to the Bucket and make the object public.
+
+## Create a Bucket Policy
+
+* Click the name of your bucket at the top of the window.
+* Click the Permissions tab.
+* In the permission tab, click Bucket Policy.
+* Copy the ARN of your Bucket to the clipboard.
+* Click the **Policy Generator** to generate policy.
+
+## Explore Versioning
+
+Versioning is a mean of keeping multiple variants of an object in the same bucket.
\ No newline at end of file
diff --git a/Cloud Web App/Virtualization.md b/Cloud Web App/Virtualization.md
new file mode 100644
index 0000000..ccfd754
--- /dev/null
+++ b/Cloud Web App/Virtualization.md
@@ -0,0 +1,7 @@
+## Virtualization
+
+Virtualization is technology that separates functions from hardware, while clouds rely on that split. It's easy to confuse the 2, particularly because they both revolve around creating useful environments from abstract resources.
+
+The easiest way to describe the difference is from a purely Infrastructure-as-a-Service (IaaS) perspective. At the base of cloud computing is a stable operating system (like Linux). This is the layer that gives users independence across public, private, and hybrid environments. Assuming intranet access, internet access, or both is already established, virtualization is what creates clouds. Software called a hypervisor sits on top of physical hardware and abstracts the machine's resources. These resources can be raw processing power, storage, or cloud-based applications containing all the runtime code and resources required to deploy it.
+
+*If the process stops here, it's not cloud computing—it's just virtualization*. Virtual resources need to be allocated into centralized pools before they're called clouds, and those clouds need to be orchestrated by management and automation software before it's considered cloud computing. Clouds deliver the added benefits of self-service access, automated infrastructure scaling, and dynamic resource pools, which most clearly distinguish it from traditional virtualization.
\ No newline at end of file
diff --git a/Docker/Basic.md b/Docker/Basic.md
new file mode 100644
index 0000000..d6ac843
--- /dev/null
+++ b/Docker/Basic.md
@@ -0,0 +1,57 @@
+# Why Docker?
+
+## Major Infrastructure Shifts
+
+* Mainframe to PC in 90's
+* Baremental to Virtual in 00's
+* Datacenter to Cloud in 10's
+
+
+
+## What is Container
+
+A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings.
+
+Containers also reduce management overhead. Because they share a common operating system, only a single operating system needs care and feeding for bug fixes, patches, and so on. This concept is similar to what we experience with hypervisor hosts: fewer management points but slightly higher fault domain. In short, containers are lighter weight and more portable than VMs.
+
+
+
+## What are VMs
+
+Virtual machines (VMs) are an abstraction of physical hardware, that would slice your one giant physical server into multiple ones. The *hypervisor* or *VMM (Virtual Machine Monitor)* provides the capability to run multiple Virtual Machines on one set of hardwar and each one of these VMs with have an OS (you need to have licenses, update and patch them and everything IT related you do with all of your regular computers).
+
+Before containers showed up, we used to use VMs to host our application. With VMs, we were able to get a big server and slice it up to several VMs and have multiple computers and simulate a network.
+
+## Vitual Machines VS Containers
+
+Virtual machines and containers differ in several ways, but the primary difference is that containers provide a way to virtualize an OS so that multiple workloads can run on a single OS instance. With VMs, the hardware is being virtualized to run multiple OS instances. Containers’ speed, agility, and portability make them yet another tool to help streamline software development.
+
+1. Size
+
+2. Isolation
+
+ In VMs, each vm has a bundle of EFI, Kernel + INIT, user space, and it is a sandbox.
+
+ In containers, it is not secure enough
+
+3. Boot time
+
+
+
+
+
+## Image VS Container
+
+Simply, the container is a runtime instance of a image, but it has a extra read-write layer. It includes one or a group of applications and the environment the applications relied.
+
+## Terms
+
+**Registry** A place to find and download Docker images.
+
+**Layers** A Docker image is built up from a series of layers. Each layer represents an instruction in the image’s Dockerfile. Each layer except the last one is read-only.
+
+**Container Image** It is simply a binary representation. It is just a bunch of bits on a filesystem. VMDK is a disk image and an OVA is an image for VM.
+
+**Dockerfile** A text file that contains all the commands, in order, needed to build a given image. The [Dockerfile reference](https://docs.docker.com/engine/reference/builder) page lists the various commands and format details for Dockerfiles.
+
+**Volume** A special Docker container layer that allows data to persist and be shared separately from the container itself. Think of volumes as a way to abstract and manage your persistent data separately from the application itself.
\ No newline at end of file
diff --git a/Docker/Container.md b/Docker/Container.md
new file mode 100644
index 0000000..4de7e71
--- /dev/null
+++ b/Docker/Container.md
@@ -0,0 +1,61 @@
+#Container
+
+### check info
+
+1. `docker container ls` shows us all containers that are currently **running**.
+2. `docker container ls -a` shows us all containers that we **ran**.
+3. `docker container diff ` shows a list of all the files that were added or changed to in the container.
+4. `docker container commit ` commits the container and create an image out of it.
+
+### run
+
+1. `docker container run ` is used to run a image from local. If it is not exist in local, **docker engine** goes to its default **Docker Registry**, which is Docker Store, to look for an image named "hello-world". It finds the image there, pulls it down, and then runs it in a contianer.
+
+ this is pretty much just like running a virtual machine, except with a central repository of VM images.
+
+ 
+
+2. `docker container [options] run `
+
+ This command is used to run the specified image, execute the command, shutdown the image and sent back to host OS.
+
+ Options:
+
+ * `—detach` will run the container in the background
+ * `—name` will give the continer a name
+
+ Example:
+
+ * `docker container run alpine ls -l` return the output of the `ls` command. When you call `run`, the Docker client finds the image(alpine in this case), creates the container and then runs a command in that container. When you run `docker container run alpine`, you provided a command(ls -l), so Docker executed this command inside the container for which you saw the directory listing. after the `ls` command finished, the container shut down.
+
+ 
+
+ * `docker container run alpine echo "hello from alpine"`
+
+ It will output "hello from alpine". In this case, all of that happened pretty quickly and again our container exited.
+
+ Difference with VM:
+
+ Imagine booting up a virtual machine (VM), running a command and then killing it; it would take a minute or two just to boot the VM before running the command. A VM has to emulate a full hardware stack, boot an operating system, and then launch your app - it’s a virtualized *hardware* environment. Docker containers function at the application layer so they skip most of the steps VMs require and just run what is required for the app.
+
+ * `docker container run -it alpine /bin/sh` let us could use the interactive shell where we could type some commands. Docker has a facility for that by adding a flag to run the container in an interactive terminal.
+
+ * `docker container run —interactive —tty —rm ubuntu bash` is used to create a ubuntu container, enter into bash and remove it when exited.
+
+ 
+
+ To find out more about `run`, use `docker container run —help` to see a list of all flags it supports.
+
+ * `docker container start `
+
+ * `docker container exec ls`
+
+3. `docker container exec` allows us to run a command line inside a container.
+
+## stop
+
+1. `docker container stop ` is used to stop a container.
+
+## remove
+
+1. `docker container rm ` could remove a container.
\ No newline at end of file
diff --git a/Docker/Features.md b/Docker/Features.md
new file mode 100644
index 0000000..091f994
--- /dev/null
+++ b/Docker/Features.md
@@ -0,0 +1,9 @@
+# Features
+
+## Isolation
+
+It is basically a sandbox for a process. The process runs in the container has its own proces, name space and cgroups.
+
+This is a critical security concept in the world of Docker containers! Even though each `docker container run` command used the same alpine image, each execution was a separate, isolated container. Each container has a separate filesystem and runs in a different namespace; By default a container has no way of interactint with other containers, even those from the same image. Let's try another exercise to learn more about isolation.
+
+
\ No newline at end of file
diff --git a/Docker/Image.md b/Docker/Image.md
new file mode 100644
index 0000000..260c70e
--- /dev/null
+++ b/Docker/Image.md
@@ -0,0 +1,106 @@
+## Image
+
+## Command
+
+1. `docker image pull `, the pull command fetches the image from the **Docker Registry** and saves it in our system.
+2. `docker image ls` is used to see a list of all images on our system.
+3. `docker image insepect ` could check the detailed info about specified image.
+4. `docker image tag ` get a image and rename it.
+5. `docker image remove ` could remove one image.
+6. `docker image save -o ` export a image to local environment.
+7. `docker image load —input ` import a image to system.
+8. `docker image push ` push an image to docker hub.
+9. `docker image history ` checks out the image we created before.
+
+## Image Layers
+
+**If we modify a context and rebuild an image**, the docker recognized that we had already built some of these layers in our earlier image builds and since nothing had changed in those layers it could simply use a cached version of the layer, rather than pulling down code a second time and running those steps. Docker’s layer management is very useful to IT teams when patching systems, updating or upgrading to the latest version of code, or making configuration changes to applications. Docker is intelligent enough to build the container in the most efficient way possible, as opposed to repeatedly building an image from the ground up each and every time.
+
+
+
+## Image Inspection
+
+How could we check what is inside the container? Docker has an `inspect` command for images and it returns details on the container image.
+
+There is a lot of information in there:
+
+- the layers the image is composed of
+- the driver used to store the layers
+- the architecture / OS it has been created for
+- metadata of the image
+- …
+
+You may have noticed that the image information is in JSON format. We can take advantage of that to use the inspect command with some filtering info to just get specific data from the image.
+
+`docker image inspect --format "{{ json .RootFS.Layers }}" ` shows layer information.
+
+Another important note about layers: each layer is immutable. As an image is created and successive layers are added, the new layers keep track of the changes from the layer below. When you start the container running there is an additional layer used to keep track of any changes that occur as the application runs (like the “hello.txt” file we created in the earlier exercises). This design principle is important for both security and data management. If someone mistakenly or maliciously changes something in a running container, you can very easily revert back to its original state because the base layers cannot be changed. Or you can simply start a new container instance which will start fresh from your pristine image. And applications that create and store data (databases, for example) can store their data in a special kind of Docker object called a **volume**, so that data can persist and be shared with other containers. We will explore volumes in a later lab.
+
+## Build
+
+###Build from container
+
+1. In order to make the following commands more copy/paste friendly, export an environment variable containing your DockerID.
+
+ `export DOCKERID=`
+
+2. Use the `docker image build` command to create a new Docker image using the Dockerfile
+
+ - `—tage` allows us to give the image a custom name. In this case it’s comprised of our DockerID, the application name, and a version. Having the Docker ID attached to the name will allow us to store it on Docker Hub.
+ - `.` tells Docker to use the current directory as the build context
+
+ example: `docker image build --tag $DOCKERID/linux_tweet_app:1.0 .`
+
+**Modify**
+
+When you’re actively working on an application it is inconvenient to have to stop the container, rebuild the image, and run a new version every time you make a change to your source code.
+
+One way to streamline this process is to mount the source code directory on the local machine into the running container. This will allow any changes made to the files on the host to be immediately reflected in the container.
+
+We do this using something called a [bind mount](https://docs.docker.com/engine/admin/volumes/bind-mounts/).
+
+When you use a bind mount, a file or directory on the host machine is mounted into a container running on the same host.
+
+For example, we'll use the `—mount` flag to mount the current directory on the host.
+
+```docker container run \ --detach \ --publish 80:80 \ --name linux_tweet_app \ --mount type=bind,source="$(pwd)",target=/usr/share/nginx/html \ $dockerid/linux_tweet_app:1.0
+docker container run \
+--detach \
+--publish 80:80 \
+--name linux_tweet_app \
+--mount type=bind,source="$(pwd)",target=/usr/share/nginx/html \
+$DOCKERID/linux_tweet_app:1.0
+```
+
+After we update the container, the website will change.
+
+**However**, if we delete the container and create a new one, we find the change is not saved. So, we need to save the modification to the image, (meaning rebuild the image).
+
+` docker image build --tag $DOCKERID/linux_tweet_app:2.0 .`
+
+###Build from commit
+
+`docker container commit ` commits the container and create an image out of it.
+
+###Build from Dockerfile
+
+The final result is essentially the same, but with a Dockerfile we are supplying the instructions for building the image, rather than just the raw binary files. This is useful because it becomes much easier to manage changes, especially as your images get bigger and more complex.
+
+- [FROM](https://docs.docker.com/engine/reference/builder/#from) specifies the base image to use as the starting point for this new image you’re creating.
+- [COPY](https://docs.docker.com/engine/reference/builder/#copy) copies files from the Docker host into the image, at a known location. In this example, `COPY` is used to copy two files into the image: `index.html`. and a graphic that will be used on our webpage.
+- [EXPOSE](https://docs.docker.com/engine/reference/builder/#expose) documents which ports the application uses.
+- [CMD](https://docs.docker.com/engine/reference/builder/#cmd) specifies what command to run when a container is started from the image. Notice that we can specify the command, as well as run-time arguments.
+
+example:
+
+
+
+**What just happened?** We created two files: our application code (index.js) is a simple bit of javascript code that prints out a message. And the Dockerfile is the instructions for Docker engine to create our custom container. This Dockerfile does the following:
+
+1. Specifies a base image to pull **FROM** - the *alpine* image we used in earlier labs.
+2. Then it **RUN**s two commands (*apk update* and *apk add*) inside that container which installs the Node.js server.
+3. Then we told it to **COPY** files from our working directory in to the container. The only file we have right now is our *index.js*.
+4. Next we specify the **WORKDIR** - the directory the container should use when it starts up
+5. And finally, we gave our container a command (**CMD**) to run when the container starts.
+
+Recall that in previous labs we put commands like `echo "hello world"` on the command line. With a Dockerfile we can specify precise commands to run for everyone who uses this container. Other users do not have to build the container themselves once you push your container up to a repository (which we will cover later) or even know what commands are used. The *Dockerfile* allows us to specify *how* to build a container so that we can repeat those steps precisely everytime and we can specify *what* the container should do when it runs. There are actually multiple methods for specifying the commands and accepting parameters a container will use, but for now it is enough to know that you have the tools to create some pretty powerful containers.
\ No newline at end of file
diff --git a/Docker/Kubernetes.md b/Docker/Kubernetes.md
new file mode 100644
index 0000000..0ce5db8
--- /dev/null
+++ b/Docker/Kubernetes.md
@@ -0,0 +1,27 @@
+## Kubernetes
+
+## What is Kubernetes
+
+Kubernetes is a portable, extensible open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
+
+#### Pros of using Kubernetes
+
+- **Its fast:** When it comes to continuously deploy new features without downtime; Kubernetes is a perfect choice. The goal of the Kubernetes is to update an application with a constant uptime. Its speed is measured through a number of features you can ship per hour while maintaining an available service.
+- **Adheres to the principals of immutable infrastructure:** In a traditional way, if anything goes wrong with multiple updates, you don’t have any record of how many updates you deployed and at which point error occurred. In immutable infrastructure, if you wish to update any application, you need to build container image with a new tag and deploy it, killing the old container with old image version. In this way, you will have a record and get an insight of what you did and in-case if there is any error; you can easily rollback to the previous image.
+- **Provides declarative configuration:** User can know in what state the system should be to avoid errors. Source control, unit tests etc. which are traditional tools can’t be used with imperative configurations but can be used with declarative configurations.
+- **Deploy and update software at scale:** Scaling is easy due to its immutable, declarative nature of Kubernetes. Kubernetes offers several useful features for scaling purpose**:- Horizontal Infrastructure Scaling:** Operations are done at the individual server level to apply horizontal scaling. Latest servers can be added or detached effortlessly.
+ **-** **Auto-scaling:** Based on the usage of CPU resources or other application-metrics, you can change the number of containers that are running
+ **- Manual scaling:** You can manually scale the number of running containers through a command or the interface
+ **-** **Replication controller:** The Replication controller makes sure that cluster has a specified number of equivalent pods in a running condition. If in-case, there are too many pods; replication controller can remove extra pods or vice-versa.
+- **Handles the availability of the application:** Kubernetes checks the health of nodes and containers as well as provides self-healing and auto-replacement if in-case pod crashes due to an error. Moreover, it distributes the load across multiple pods to balance the resources quickly during accidental traffic.
+- **Storage Volume:** In Kubernetes, data is shared across the containers, but if pods get killed volume is automatically removed. Moreover, data is stored remotely, if the pod is moved to another node, the data will remain until it is deleted by the user.
+
+#### Cons of using Kubernetes
+
+- **Initial process takes time:** When a new process is created, you have to wait for the app to commence before it is available to the users. If you are migrating to Kubernetes, modifications in the code base need to be done to make a start process more efficient so that users don’t have a bad experience.
+- **Migrating to stateless requires many efforts:** If your application is clustered or stateless, extra pods will not get configured and will have to rework on the configurations within your applications.
+- **The installation process is tedious:** It is difficult to set up Kubernetes on your cluster if you are not using any cloud provider like Azure, Google or Amazon.
+
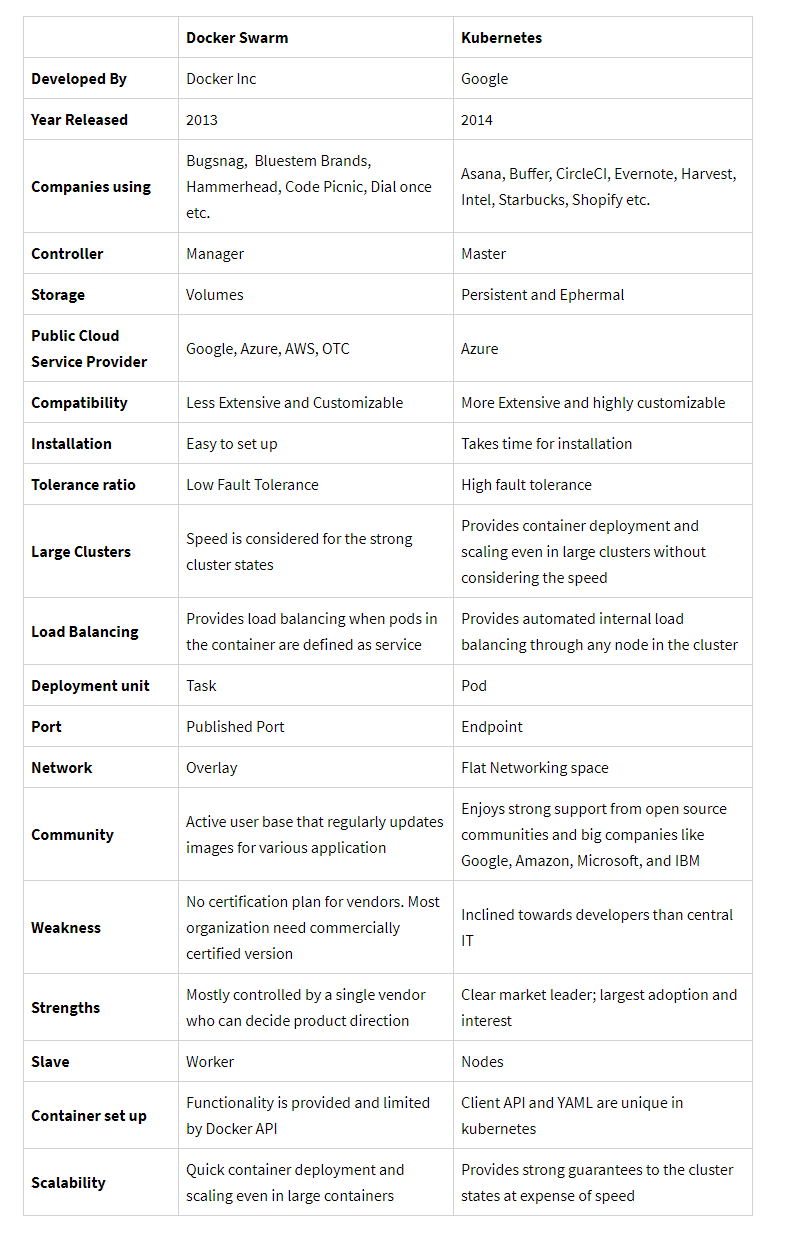
+## Kubernetes VS Docker Swarm
+
+
\ No newline at end of file
diff --git a/Docker/Network.md b/Docker/Network.md
new file mode 100644
index 0000000..30397ed
--- /dev/null
+++ b/Docker/Network.md
@@ -0,0 +1,3 @@
+# Network
+
+Docker
\ No newline at end of file
diff --git a/Docker/Swarm.md b/Docker/Swarm.md
new file mode 100644
index 0000000..9f488ce
--- /dev/null
+++ b/Docker/Swarm.md
@@ -0,0 +1,68 @@
+# Swarm
+
+For real applications IT users and app teams need more sophisticated tools. Docker supplies two such tools: **Docker Compose** and **Docker Swarm Mode**. The two tools have some similarities but some important differences:
+
+- **Compose** is used to control multiple containers on a single system. Much like the *Dockerfile* we looked at to build an image, there is a text file that describes the application: which images to use, how many instances, the network connections, etc. But *Compose* only runs on a single system so while it is useful, we are going to skip Compose and go straight to *Docker Swarm Mode*.
+- **Swarm Mode** tells Docker that you will be running many Docker engines and you want to coordinate operations across all of them. Swarm mode combines the ability to not only define the application architecture, like Compose, but to define and maintain high availability levels, scaling, load balancing, and more. With all this functionality, *Swarm mode* is used more often in production environments than it’s more simplistic cousin, Compose.
+
+## What is swarm
+
+a swarm consists of multiple Docker hosts which run in swarm mode and act as managers and workers.
+
+## How swarm works: Nodes and Services
+
+###How Nodes Work
+
+There are two types of nodes: managers and workers.
+
+**Manager nodes** handle cluster management tasks: maintaining cluster state, scheduling services, and serving swarm mode HTTP API endpoints. The managers maintain a consistent state of the swarm and services running on it, using an implementation of the Raft algorithm.
+
+Running multiple manager nodes allows you to take advantage of swarm mode’s fault-tolerance features. However, adding more managers does not mean increased scalability or higher performance. In general, the opposite is true. Docker recommends implementing an odd number of manager nodes.
+
+A three-manager swarm tolerates a maximum loss of one manager without downtime. A five-manager swarm tolerates a maximum simultaneous loss of two manager nodes. In general, an N manager cluster will tolerate the loss of at most (N-1)/2 managers. When managers fail beyond this threshold, services continue to run, but you need to create a new cluster to recover.
+
+**Worker nodes** are also instances of Docker Engine whose sole purpose is to run containers. Worker nodes require at least one manager node to function.
+
+By default, all managers are also workers. In a single manager node cluster, you can run commands like `docker service create` and the scheduler places all tasks on the local Engine. To prevent a manager node from executing tasks, set the availability for a manager node to `Drain`.
+
+You can promote a worker node to be a manager by running docker node promote. For example, you may want to promote a worker node when you take a manager node offline for maintenance. You can also demote a manager node to a worker node using node demote.
+
+###How Services Work
+
+Services allow you to deploy an application image to a Docker swarm. Examples of services include an HTTP server, a database, or other software that needs to run in a distributed environment. The basic definition of the service includes a container image to run, and commands to execute inside the running containers.
+
+- **Service options** – when you create a service, you can specify the port to publish for external access, an overlay network for the service to connect to other services in the swarm, CPU and memory restrictions, a rolling update policy, and number of replicas of the image to run in the swarm.
+- **Services, scheduling and desired state** – when you deploy the service to the swarm, the service definition is the desired state for the service. For example, the desired state might be running three instances of an HTTP listener, with load balancing between them. The swarm manager schedules a replica task on three Docker Engines in the swarm, each of which runs a container with an HTTP listener. If one of these instances fails, the manager recognizes the desired state is not fulfilled, schedules another replica task, and spawns a new container to bring the number of listeners back to three.
+- **When tasks fail** – if a task in a Docker swarm fails, it is not recovered or restarted. The orchestrator simply removes the container related to the failed tasks, and creates a new task to replace it according to the desired state specified by the service.
+- **Pending services** – a service is pending if there aren’t currently nodes available in the cluster to run its tasks. For example, this might happen if all the nodes in the cluster are paused or Drained (defined as manager nodes which may not act as worker nodes). You can also specify constraints on a service, such as minimal memory of 100 GB on a node. If no nodes have this amount of memory, the service will be pending until a node joins the swarm that satisfies the requirement.
+- **Replicated vs. global services** – a replicated service specifies a number of identical tasks you want to run. For example, you decide to deploy an HTTP service with three replicas, each serving the same content. A global service is a service that runs one task on all the nodes in the swarm, with no pre-specified number of tasks/nodes. Each time you add a node to the swarm, the same task is run on it. For example, a typical global service is a monitoring agent or an anti-virus scanner.
+
+
+
+
+
+## The application
+
+`docker swarm init --advertise-addr $(hostname -i)` can initialize a **Swarm Manager**.
+
+Run a docker node ls to verify that both nodes are part of the Swarm. The ID and HOSTNAME values may be different in your lab. The important thing to check is that both nodes have joined the Swarm and are ready and active.
+
+To add a worker to this swarm, run the following command: `docker swarm join —token`
+
+`docker node ls` could show swarm members.
+
+##Pros & Cons
+
+###Pros
+
+- **Runs at a faster pace:** When you were using a virtual environment, you may have realized that it takes a long time and includes the tedious procedure of booting up and starting the application that you want to run. With Docker Swarm, this is no more a problem. Docker Swarm removes the need to boot up a full virtual machine and enables the app to run in a virtual and software-defined environment quickly and helps in DevOps implementation.
+- **Documentation provides every bit of information:** The Docker team stands out when it comes to documentation! Docker is rapidly evolving and has received great applause for the entire platform. When version gets released at a short interval of time, some platform doesn’t maintain/take care to maintain documentation. But docker swarm never compromises with it. If in case the information only applies to the certain versions of a docker swarm, the documentation makes sure that all information is updated.
+- **Provides simple and fast configuration:** One of the key benefits of Docker Swarm is that, it simplifies the matter. Docker Swarm enables the user to take their own configuration, put it into a code and deploy it without any hassle. As Docker Swarm can be used in various environments, requirements are just not bound by the environment of the application.
+- **Ensures that application is isolated:** Docker Swarm takes care that each container is isolated from the other containers and has its own resources. Various containers can be deployed for running the separate application in different stacks. Apart from this, Docker Swarm cleans app removal as each application runs on its own container. If the application is no longer required, you can delete its container. It won’t leave any temporary or configuration files on your host OS.
+- **Version control and component reuse —** With Docker Swarm, you can track consecutive versions of a container, examine differences or roll-back to the preceding versions. Containers reuse the components from the preceding layers which makes them noticeably lightweight.
+
+#### ###Cons
+
+- **Docker is platform dependent:** Docker Swarm is a Linux agonistic platform. Although Docker supports Windows and Mac OS X, it utilizes virtual machines to run on a non-Linux platform. An application which is designed to run in docker container on Windows can’t run on Linux and vice versa.
+- **Doesn’t provide storage option:** Docker Swarm doesn’t provide a hassle-free way to connect containers to storage and this is one of the major disadvantages. Its data volumes require a lot of improvising on the host and manual configurations. If you’re expecting Docker Swarm to solve the storage issues, it may get done but not in an efficient and user-friendly way.
+- **Poor monitoring:** Docker Swarm provides the basic information about the container and if you are looking for the basic monitoring solution than *Stats command* is suffice. If you are looking for the advanced monitoring than Docker Swarm is never an option. Although there are third-party tools available like CAdvisor which offers more monitoring. It is not feasible to collect more data about containers in real-time with Docker itself
\ No newline at end of file
diff --git a/README.md b/README.md
index 37d2d46..9a223df 100644
--- a/README.md
+++ b/README.md
@@ -1,8 +1,18 @@
# Distributed Systems Practice
Notes from learning about distributed systems in [GW CS 6421](https://gwdistsys18.github.io/) with [Prof. Wood](https://faculty.cs.gwu.edu/timwood/)
-## Area 1
-> Include notes here about each of the links
+## Docker and Containers
+1. [Basic](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Basic.md)
+2. [Image](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Image.md)
+3. [Container](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Container.md)
+4. [Features](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Features.md)
+5. [Network](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Network.md)
+6. [Swarm](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Swarm.md)
+7. [Kubernetes](https://github.com/GXwar/dist-sys-practice/blob/master/Docker/Kubernetes.md)
-## Area 2
-> Include notes here about each of the links
+## Cloud Web Apps
+1. [Launch VM](https://github.com/GXwar/dist-sys-practice/blob/master/Cloud%20Web%20App/Launch%20VM.md)
+2. [S3](https://github.com/GXwar/dist-sys-practice/blob/master/Cloud%20Web%20App/S3.md)
+3. [Virtualization](https://github.com/GXwar/dist-sys-practice/blob/master/Cloud%20Web%20App/Virtualization.md)
+4. [Install an LAMP server on Amazon Linux](https://github.com/GXwar/dist-sys-practice/blob/master/Cloud%20Web%20App/Install%20an%20LAMP%20server%20on%20Amazon%20Linux.md)
+5. [DynamoDB](https://github.com/GXwar/dist-sys-practice/blob/master/Cloud%20Web%20App/DynamoDB.md)
\ No newline at end of file