diff --git a/.github/workflows/run_chatgpt_examples.yml b/.github/workflows/run_chatgpt_examples.yml
index f25a6189fcf2..1194825369ff 100644
--- a/.github/workflows/run_chatgpt_examples.yml
+++ b/.github/workflows/run_chatgpt_examples.yml
@@ -21,7 +21,7 @@ jobs:
container:
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data --shm-size=10.24gb
- timeout-minutes: 60
+ timeout-minutes: 180
defaults:
run:
shell: bash
@@ -34,6 +34,10 @@ jobs:
pip install --no-cache-dir -v -e .
- name: Install ChatGPT
+ env:
+ CFLAGS: "-O1"
+ CXXFLAGS: "-O1"
+ MAX_JOBS: 4
run: |
cd applications/ColossalChat
pip install --no-cache-dir -v .
diff --git a/.github/workflows/run_chatgpt_unit_tests.yml b/.github/workflows/run_chatgpt_unit_tests.yml
index 9180ede37a31..5cbcaa7fbbc0 100644
--- a/.github/workflows/run_chatgpt_unit_tests.yml
+++ b/.github/workflows/run_chatgpt_unit_tests.yml
@@ -21,7 +21,7 @@ jobs:
container:
image: image-cloud.luchentech.com/hpcaitech/pytorch-cuda:2.2.2-12.1.0
options: --gpus all --rm -v /data/scratch/examples-data:/data/scratch/examples-data
- timeout-minutes: 30
+ timeout-minutes: 180
defaults:
run:
shell: bash
@@ -30,6 +30,10 @@ jobs:
uses: actions/checkout@v2
- name: Install ChatGPT
+ env:
+ CFLAGS: "-O1"
+ CXXFLAGS: "-O1"
+ MAX_JOBS: 4
run: |
cd applications/ColossalChat
pip install -v .
diff --git a/.gitignore b/.gitignore
index 8bc74b4c8c2c..94d952295410 100644
--- a/.gitignore
+++ b/.gitignore
@@ -163,3 +163,13 @@ coverage.xml
# log, test files - ColossalChat
applications/ColossalChat/logs
applications/ColossalChat/tests/logs
+applications/ColossalChat/wandb
+applications/ColossalChat/model
+applications/ColossalChat/eval
+applications/ColossalChat/rollouts
+applications/ColossalChat/*.txt
+applications/ColossalChat/*.db
+applications/ColossalChat/stdin
+applications/ColossalChat/*.zip
+applications/ColossalChat/*.prof
+applications/ColossalChat/*.png
diff --git a/applications/ColossalChat/coati/dataset/loader.py b/applications/ColossalChat/coati/dataset/loader.py
index fc3a4930c058..16fd385bad30 100755
--- a/applications/ColossalChat/coati/dataset/loader.py
+++ b/applications/ColossalChat/coati/dataset/loader.py
@@ -352,14 +352,30 @@ def apply_chat_template_and_mask(
tokenizer: PreTrainedTokenizer,
chat: List[Dict[str, str]],
max_length: Optional[int] = None,
+ system_prompt: str = None,
padding: bool = True,
truncation: bool = True,
ignore_idx: int = -100,
) -> Dict[str, torch.Tensor]:
+
+ if system_prompt is None:
+ system_prompt = "You are a helpful assistant. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within and tags, respectively, i.e., reasoning process here answer here . Now the user asks you to solve a math problem that involves reasoning. After thinking, when you finally reach a conclusion, clearly output the final answer without explanation within the tags, i.e., 123 .\n\n"
+
+ system_element = {
+ "role": "system",
+ "content": system_prompt,
+ }
+
+ # Format for RL.
+ if "messages" in chat:
+ gt_answer = chat.get("gt_answer", None)
+ test_cases = chat.get("test_cases", None)
+ chat = [chat["messages"]]
+
tokens = []
assistant_mask = []
for i, msg in enumerate(chat):
- msg_tokens = tokenizer.apply_chat_template([msg], tokenize=True)
+ msg_tokens = tokenizer.apply_chat_template([system_element, msg], tokenize=True, add_generation_prompt=True)
# remove unexpected bos token
if i > 0 and msg_tokens[0] == tokenizer.bos_token_id:
msg_tokens = msg_tokens[1:]
@@ -372,14 +388,10 @@ def apply_chat_template_and_mask(
if max_length is not None:
if padding and len(tokens) < max_length:
to_pad = max_length - len(tokens)
- if tokenizer.padding_side == "right":
- tokens.extend([tokenizer.pad_token_id] * to_pad)
- assistant_mask.extend([False] * to_pad)
- attention_mask.extend([0] * to_pad)
- else:
- tokens = [tokenizer.pad_token_id] * to_pad + tokens
- assistant_mask = [False] * to_pad + assistant_mask
- attention_mask = [0] * to_pad + attention_mask
+ # Left padding for generation.
+ tokens = [tokenizer.pad_token_id] * to_pad + tokens
+ assistant_mask = [False] * to_pad + assistant_mask
+ attention_mask = [0] * to_pad + attention_mask
if truncation and len(tokens) > max_length:
tokens = tokens[:max_length]
assistant_mask = assistant_mask[:max_length]
@@ -389,6 +401,15 @@ def apply_chat_template_and_mask(
labels = input_ids.clone()
labels[~torch.tensor(assistant_mask, dtype=torch.bool)] = ignore_idx
+ if gt_answer is not None:
+ return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels, "gt_answer": gt_answer}
+ elif test_cases is not None:
+ return {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "labels": labels,
+ "test_cases": test_cases,
+ }
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
@@ -402,7 +423,7 @@ class RawConversationDataset(Dataset):
Each instance is a dictionary with fields `system`, `roles`, `messages`, `offset`, `sep_style`, `seps`.
"""
- def __init__(self, tokenizer: PreTrainedTokenizer, input_file: str, max_length: int) -> None:
+ def __init__(self, tokenizer: PreTrainedTokenizer, input_file: str, max_length: int, system_prompt: str) -> None:
self.tokenizer = tokenizer
self.raw_texts = []
with jsonlines.open(input_file) as f:
@@ -410,6 +431,7 @@ def __init__(self, tokenizer: PreTrainedTokenizer, input_file: str, max_length:
self.raw_texts.append(line)
self.tokenized_texts = [None] * len(self.raw_texts)
self.max_length = max_length
+ self.system_prompt = system_prompt
def __len__(self) -> int:
return len(self.raw_texts)
@@ -417,6 +439,23 @@ def __len__(self) -> int:
def __getitem__(self, index: int):
if self.tokenized_texts[index] is None:
message = self.raw_texts[index]
- tokens = apply_chat_template_and_mask(self.tokenizer, message, self.max_length)
+ tokens = apply_chat_template_and_mask(self.tokenizer, message, self.max_length, self.system_prompt)
self.tokenized_texts[index] = dict(tokens)
return self.tokenized_texts[index]
+
+
+def collate_fn_grpo(batch):
+ input_ids = [item["input_ids"] for item in batch]
+ attention_mask = [item["attention_mask"] for item in batch]
+ labels = [item["labels"] for item in batch]
+ # Assume input_ids, attention_mask, labels are already of the same length,
+ # otherwise use pad_sequence(input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
+ input_ids = torch.stack(input_ids)
+ attention_mask = torch.stack(attention_mask)
+ labels = torch.stack(labels)
+ ret = {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
+ if "test_cases" in batch[0]:
+ ret["test_cases"] = [item["test_cases"] for item in batch]
+ if "gt_answer" in batch[0]:
+ ret["gt_answer"] = [item["gt_answer"] for item in batch]
+ return ret
diff --git a/applications/ColossalChat/coati/distributed/README.md b/applications/ColossalChat/coati/distributed/README.md
new file mode 100644
index 000000000000..21647a8cc896
--- /dev/null
+++ b/applications/ColossalChat/coati/distributed/README.md
@@ -0,0 +1,323 @@
+# Distributed RL Framework for Language Model Fine-Tuning
+
+This repository implements a distributed Reinforcement Learning (RL) training framework designed to fine-tune large language models using algorithms such as **GRPO** and **DAPO**. It supports multi-node and multi-GPU setups, scalable rollout generation, and policy optimization using libraries like VLLM. Currently, we support two Reinforcement Learning with Verifiable Reward (RLVR) tasks: solving math problems and code generation.
+
+**Please note that we are still under intensive development, stay tuned.**
+
+---
+
+## 🚀 Features
+
+* **Distributed Training with Ray**: Scalable to multiple machines and GPUs.
+* **Support for GRPO and DAPO**: Choose your preferred policy optimization algorithm.
+* **Model Backends**: Support `vllm` as inference backends.
+* **Rollout and Policy Decoupling**: Efficient generation and consumption of data through parallel inferencer-trainer architecture.
+* **Evaluation Integration**: Easily plug in task-specific eval datasets.
+* **Checkpoints and Logging**: Configurable intervals and directories.
+
+---
+
+## 🛠 Installation
+
+### Prepare Develop Environment
+
+Install Colossalai & ColossalChat
+```bash
+git clone https://github.com/hpcaitech/ColossalAI.git
+git checkout grpo-latest
+BUILD_EXT=1 pip install -e .
+
+cd ./applications/ColossalChat
+pip install -e .
+```
+
+Install vllm
+```bash
+pip install vllm==0.7.3
+```
+
+Install Ray.
+```bash
+pip install ray
+```
+
+Install Other Dependencies
+```bash
+pip install cupy-cuda12x
+python -m cupyx.tools.install_library --cuda 12.x --library nccl
+```
+
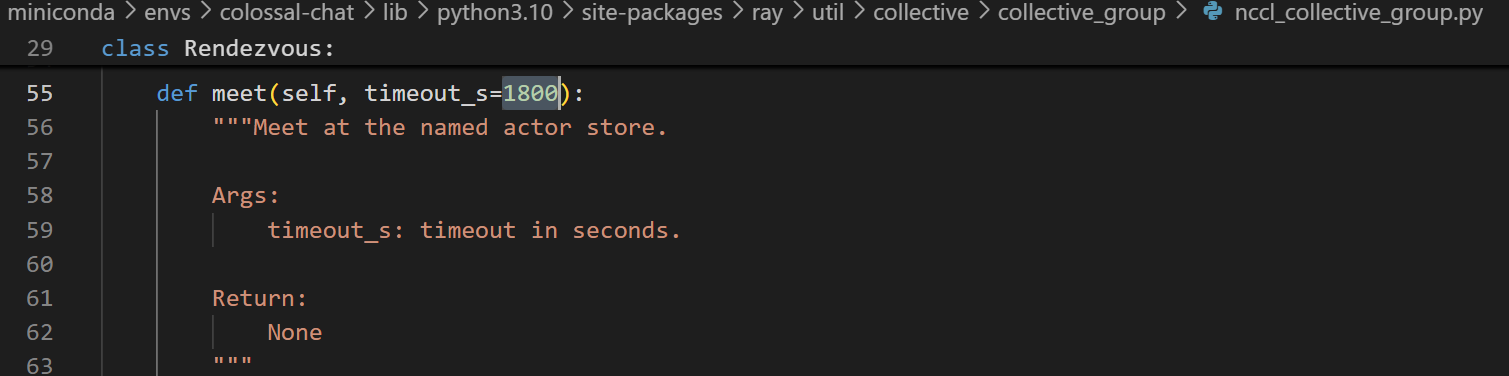
+To support long input/output sequence length (e.g., 32K), you may need to manually change the default setting (180 seconds) for the `timeout_s` variable in your ray installation to a larger value as shown in the screenshot below.
+
+
+
+  +
+
+
+
+  +
+
+