 +
+ +
+LoRA atua adicionando pares de matrizes de decomposição de posto baixo às camadas do Transformer, normalmente focando nas camadas lineares. Durante o treinamento, “congelamos” o restante do modelo e atualizamos apenas os pesos desses adaptadores recém-adicionados.
+
+Ao fazer isso, o número de **parâmetros** que precisamos treinar cai bastante, já que apenas os pesos dos adaptadores são atualizados.
+
+Durante a inferência, a entrada passa tanto pelo adaptador quanto pelo modelo base; também é possível fundir esses pesos com o modelo base, sem gerar latência adicional.
+
+LoRA é especialmente útil para adaptar modelos de linguagem **grandes** a tarefas ou domínios específicos mantendo os requisitos de recursos sob controle. Isso ajuda a reduzir a memória **necessária** para treinar um modelo.
+
+Se quiser aprender mais sobre como LoRA funciona, confira este [tutorial](https://huggingface.co/learn/nlp-course/chapter11/4?fw=pt).
+
+## Fazendo Fine-Tuning de um Modelo para Function Calling
+
+Você pode acessar o notebook do tutorial 👉 [aqui](https://huggingface.co/agents-course/notebooks/blob/main/bonus-unit1/bonus-unit1.ipynb).
+
+Depois, clique em [](https://colab.research.google.com/#fileId=https://huggingface.co/agents-course/notebooks/blob/main/bonus-unit1/bonus-unit1.ipynb) para executá-lo em um Notebook Colab.
+
diff --git a/units/pt_br/bonus-unit1/introduction.mdx b/units/pt_br/bonus-unit1/introduction.mdx
new file mode 100644
index 00000000..91d312fb
--- /dev/null
+++ b/units/pt_br/bonus-unit1/introduction.mdx
@@ -0,0 +1,52 @@
+# Introdução
+
+
+
+Bem-vindo a esta primeira **Unidade Bônus**, na qual você vai aprender a **fazer fine-tuning de um Large Language Model (LLM) para chamadas de função**.
+
+Quando falamos de LLMs, function calling está rapidamente se tornando uma técnica indispensável.
+
+A ideia é que, em vez de depender apenas de abordagens baseadas em prompt como fizemos na Unidade 1, o function calling treina seu modelo para **tomar ações e interpretar observações durante a fase de treinamento**, deixando sua IA mais robusta.
+
+> **Quando devo fazer esta Unidade Bônus?**
+>
+> Esta seção é **opcional** e mais avançada do que a Unidade 1, então sinta-se à vontade para fazê-la agora ou revisitá-la quando seu conhecimento tiver evoluído com este curso.
+>
+> Mas não se preocupe, esta Unidade Bônus foi concebida para trazer todas as informações necessárias. Vamos guiá-lo por cada conceito essencial de fine-tuning para chamadas de função, mesmo que você ainda não domine todos os detalhes desse processo.
+
+A melhor forma de aproveitar esta Unidade Bônus é:
+
+1. Saber como fazer fine-tuning de um LLM com Transformers; se ainda não souber, [confira isto](https://huggingface.co/learn/nlp-course/chapter3/1?fw=pt).
+2. Conhecer o `SFTTrainer` para ajustar o modelo; para saber mais, [acesse esta documentação](https://huggingface.co/learn/nlp-course/en/chapter11/1).
+
+---
+
+## O que você vai aprender
+
+1. **Function Calling**
+ Como LLMs modernos estruturam suas conversas, permitindo acionar **Ferramentas**.
+
+2. **LoRA (Low-Rank Adaptation)**
+ Um método de fine-tuning **leve e eficiente** que reduz o custo computacional e de armazenamento. LoRA torna o treinamento de grandes modelos *mais rápido, barato e fácil* de colocar em produção.
+
+3. **O ciclo Pensar → Agir → Observar** em modelos com function calling
+ Uma abordagem simples e poderosa para estruturar como o seu modelo decide quando (e como) chamar funções, acompanhar etapas intermediárias e interpretar resultados vindos de ferramentas externas ou APIs.
+
+4. **Novos tokens especiais**
+ Vamos apresentar **marcadores especiais** que ajudam o modelo a diferenciar entre:
+ - raciocínio interno (“chain-of-thought”);
+ - chamadas de função enviadas;
+ - respostas que retornam de ferramentas externas.
+
+---
+
+Ao final desta unidade bônus, você será capaz de:
+
+- **Entender** o funcionamento interno de APIs no contexto de Ferramentas;
+- **Fazer fine-tuning** de um modelo usando a técnica LoRA;
+- **Implementar** e **ajustar** o ciclo Pensar → Agir → Observar para criar fluxos de trabalho robustos e fáceis de manter para function calling;
+- **Criar e utilizar** tokens especiais para separar de forma fluida o raciocínio interno das ações externas do modelo.
+
+E você **terá ajustado seu próprio modelo para realizar chamadas de função.** 🔥
+
+Vamos mergulhar em **function calling**!
diff --git a/units/pt_br/bonus-unit1/what-is-function-calling.mdx b/units/pt_br/bonus-unit1/what-is-function-calling.mdx
new file mode 100644
index 00000000..656b68ea
--- /dev/null
+++ b/units/pt_br/bonus-unit1/what-is-function-calling.mdx
@@ -0,0 +1,78 @@
+# O que é Function Calling?
+
+Function calling é uma **maneira de um LLM executar ações em seu ambiente**. Ele foi [introduzido pela primeira vez no GPT-4](https://openai.com/index/function-calling-and-other-api-updates/) e depois reproduzido em outros modelos.
+
+Assim como as ferramentas de um Agente, function calling dá ao modelo a capacidade de **agir sobre o ambiente**. Entretanto, essa capacidade **é aprendida pelo modelo** e depende **menos de prompting do que outras técnicas baseadas em agentes**.
+
+Na Unidade 1, o agente **não aprendeu a usar as ferramentas**; apenas fornecemos a lista e confiamos que o modelo **conseguiria generalizar para definir um plano usando essas Ferramentas**.
+
+Aqui, **com function calling, o agente passa por fine-tuning (treinamento) para usar Ferramentas**.
+
+## Como o modelo "aprende" a tomar uma ação?
+
+Na Unidade 1, exploramos o fluxo de trabalho geral de um agente. Depois que o usuário fornece ferramentas ao agente e o instrui com uma solicitação, o modelo passa pelo ciclo:
+
+1. *Pensar*: Quais ações preciso executar para atingir o objetivo?
+2. *Agir*: Formatar a ação com os parâmetros corretos e interromper a geração.
+3. *Observar*: Receber o resultado da execução.
+
+Em uma conversa "típica" com um modelo via API, as mensagens alternam entre usuário e assistente, como neste exemplo:
+
+```python
+conversation = [
+ {"role": "user", "content": "I need help with my order"},
+ {"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
+ {"role": "user", "content": "It's ORDER-123"},
+]
+```
+
+Function calling adiciona **novos papéis à conversa**!
+
+1. Um novo papel para uma **Ação**
+2. Um novo papel para uma **Observação**
+
+Se usarmos a [API da Mistral](https://docs.mistral.ai/capabilities/function_calling/) como exemplo, ela ficaria assim:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": "What's the status of my transaction T1001?"
+ },
+ {
+ "role": "assistant",
+ "content": "",
+ "function_call": {
+ "name": "retrieve_payment_status",
+ "arguments": "{\"transaction_id\": \"T1001\"}"
+ }
+ },
+ {
+ "role": "tool",
+ "name": "retrieve_payment_status",
+ "content": "{\"status\": \"Paid\"}"
+ },
+ {
+ "role": "assistant",
+ "content": "Your transaction T1001 has been successfully paid."
+ }
+]
+```
+
+> ... Mas você disse que existe um novo papel para chamadas de função?
+
+**Sim e não**. Neste caso, e em muitas outras APIs, o modelo formata a ação que deve executar como uma mensagem de "assistant". O template de chat então representa isso com **tokens especiais** para function calling.
+
+- `[AVAILABLE_TOOLS]` – Início da lista de ferramentas disponíveis
+- `[/AVAILABLE_TOOLS]` – Fim da lista de ferramentas disponíveis
+- `[TOOL_CALLS]` – Chamada a uma ferramenta (ou seja, uma "Ação")
+- `[TOOL_RESULTS]` – "Observa" o resultado da ação
+- `[/TOOL_RESULTS]` – Fim da observação (ou seja, o modelo pode voltar a decodificar)
+
+Falaremos novamente sobre function calling ao longo do curso, mas, se quiser se aprofundar, confira [esta excelente seção da documentação](https://docs.mistral.ai/capabilities/function_calling/).
+
+---
+
+Agora que entendemos o que é function calling e como ele funciona, vamos **adicionar essas capacidades a um modelo que ainda não as possui**: o [google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it), incluindo novos tokens especiais no modelo.
+
+Para conseguir fazer isso, **precisamos primeiro compreender fine-tuning e LoRA**.
diff --git a/units/pt_br/bonus-unit2/introduction.mdx b/units/pt_br/bonus-unit2/introduction.mdx
new file mode 100644
index 00000000..f1638c5a
--- /dev/null
+++ b/units/pt_br/bonus-unit2/introduction.mdx
@@ -0,0 +1,33 @@
+# Observabilidade e Avaliação de Agentes de IA
+
+
+
+Bem-vindo à **Unidade Bônus 2**! Neste capítulo, você vai explorar estratégias avançadas para observar, avaliar e, por fim, aprimorar o desempenho dos seus agentes.
+
+---
+
+## 📚 Quando devo fazer esta Unidade Bônus?
+
+Esta unidade é ideal se você:
+- **Desenvolve e coloca Agentes de IA em produção:** quer garantir que eles atuem de forma confiável.
+- **Precisa de insights detalhados:** busca diagnosticar problemas, otimizar desempenho ou entender o funcionamento interno do seu agente.
+- **Deseja reduzir o custo operacional:** ao monitorar custos de execução, latência e detalhes das execuções, você gerencia recursos com eficiência.
+- **Busca melhoria contínua:** deseja integrar feedback de usuários em tempo real e avaliação automatizada nas suas aplicações de IA.
+
+Em resumo, é para todo mundo que quer colocar seus agentes nas mãos dos usuários!
+
+---
+
+## 🤓 O que você vai aprender
+
+Ao longo desta unidade, você aprenderá a:
+- **Instrumentar seu agente:** integrar ferramentas de observabilidade via OpenTelemetry com o framework *smolagents*.
+- **Monitorar métricas:** acompanhar indicadores como uso de tokens (custos), latência e rastros de erros.
+- **Avaliar em tempo real:** aplicar técnicas de avaliação contínua, coletando feedback de usuários e usando um LLM como avaliador.
+- **Analisar offline:** utilizar conjuntos de benchmark (como o GSM8K) para testar e comparar o desempenho do agente.
+
+---
+
+## 🚀 Pronto para começar?
+
+Na próxima seção, você verá os fundamentos de Observabilidade e Avaliação de Agentes. Depois disso, é hora de ver tudo em ação!
diff --git a/units/pt_br/bonus-unit2/monitoring-and-evaluating-agents-notebook.mdx b/units/pt_br/bonus-unit2/monitoring-and-evaluating-agents-notebook.mdx
new file mode 100644
index 00000000..49bb2d7f
--- /dev/null
+++ b/units/pt_br/bonus-unit2/monitoring-and-evaluating-agents-notebook.mdx
@@ -0,0 +1,442 @@
+
+
+LoRA atua adicionando pares de matrizes de decomposição de posto baixo às camadas do Transformer, normalmente focando nas camadas lineares. Durante o treinamento, “congelamos” o restante do modelo e atualizamos apenas os pesos desses adaptadores recém-adicionados.
+
+Ao fazer isso, o número de **parâmetros** que precisamos treinar cai bastante, já que apenas os pesos dos adaptadores são atualizados.
+
+Durante a inferência, a entrada passa tanto pelo adaptador quanto pelo modelo base; também é possível fundir esses pesos com o modelo base, sem gerar latência adicional.
+
+LoRA é especialmente útil para adaptar modelos de linguagem **grandes** a tarefas ou domínios específicos mantendo os requisitos de recursos sob controle. Isso ajuda a reduzir a memória **necessária** para treinar um modelo.
+
+Se quiser aprender mais sobre como LoRA funciona, confira este [tutorial](https://huggingface.co/learn/nlp-course/chapter11/4?fw=pt).
+
+## Fazendo Fine-Tuning de um Modelo para Function Calling
+
+Você pode acessar o notebook do tutorial 👉 [aqui](https://huggingface.co/agents-course/notebooks/blob/main/bonus-unit1/bonus-unit1.ipynb).
+
+Depois, clique em [](https://colab.research.google.com/#fileId=https://huggingface.co/agents-course/notebooks/blob/main/bonus-unit1/bonus-unit1.ipynb) para executá-lo em um Notebook Colab.
+
diff --git a/units/pt_br/bonus-unit1/introduction.mdx b/units/pt_br/bonus-unit1/introduction.mdx
new file mode 100644
index 00000000..91d312fb
--- /dev/null
+++ b/units/pt_br/bonus-unit1/introduction.mdx
@@ -0,0 +1,52 @@
+# Introdução
+
+
+
+Bem-vindo a esta primeira **Unidade Bônus**, na qual você vai aprender a **fazer fine-tuning de um Large Language Model (LLM) para chamadas de função**.
+
+Quando falamos de LLMs, function calling está rapidamente se tornando uma técnica indispensável.
+
+A ideia é que, em vez de depender apenas de abordagens baseadas em prompt como fizemos na Unidade 1, o function calling treina seu modelo para **tomar ações e interpretar observações durante a fase de treinamento**, deixando sua IA mais robusta.
+
+> **Quando devo fazer esta Unidade Bônus?**
+>
+> Esta seção é **opcional** e mais avançada do que a Unidade 1, então sinta-se à vontade para fazê-la agora ou revisitá-la quando seu conhecimento tiver evoluído com este curso.
+>
+> Mas não se preocupe, esta Unidade Bônus foi concebida para trazer todas as informações necessárias. Vamos guiá-lo por cada conceito essencial de fine-tuning para chamadas de função, mesmo que você ainda não domine todos os detalhes desse processo.
+
+A melhor forma de aproveitar esta Unidade Bônus é:
+
+1. Saber como fazer fine-tuning de um LLM com Transformers; se ainda não souber, [confira isto](https://huggingface.co/learn/nlp-course/chapter3/1?fw=pt).
+2. Conhecer o `SFTTrainer` para ajustar o modelo; para saber mais, [acesse esta documentação](https://huggingface.co/learn/nlp-course/en/chapter11/1).
+
+---
+
+## O que você vai aprender
+
+1. **Function Calling**
+ Como LLMs modernos estruturam suas conversas, permitindo acionar **Ferramentas**.
+
+2. **LoRA (Low-Rank Adaptation)**
+ Um método de fine-tuning **leve e eficiente** que reduz o custo computacional e de armazenamento. LoRA torna o treinamento de grandes modelos *mais rápido, barato e fácil* de colocar em produção.
+
+3. **O ciclo Pensar → Agir → Observar** em modelos com function calling
+ Uma abordagem simples e poderosa para estruturar como o seu modelo decide quando (e como) chamar funções, acompanhar etapas intermediárias e interpretar resultados vindos de ferramentas externas ou APIs.
+
+4. **Novos tokens especiais**
+ Vamos apresentar **marcadores especiais** que ajudam o modelo a diferenciar entre:
+ - raciocínio interno (“chain-of-thought”);
+ - chamadas de função enviadas;
+ - respostas que retornam de ferramentas externas.
+
+---
+
+Ao final desta unidade bônus, você será capaz de:
+
+- **Entender** o funcionamento interno de APIs no contexto de Ferramentas;
+- **Fazer fine-tuning** de um modelo usando a técnica LoRA;
+- **Implementar** e **ajustar** o ciclo Pensar → Agir → Observar para criar fluxos de trabalho robustos e fáceis de manter para function calling;
+- **Criar e utilizar** tokens especiais para separar de forma fluida o raciocínio interno das ações externas do modelo.
+
+E você **terá ajustado seu próprio modelo para realizar chamadas de função.** 🔥
+
+Vamos mergulhar em **function calling**!
diff --git a/units/pt_br/bonus-unit1/what-is-function-calling.mdx b/units/pt_br/bonus-unit1/what-is-function-calling.mdx
new file mode 100644
index 00000000..656b68ea
--- /dev/null
+++ b/units/pt_br/bonus-unit1/what-is-function-calling.mdx
@@ -0,0 +1,78 @@
+# O que é Function Calling?
+
+Function calling é uma **maneira de um LLM executar ações em seu ambiente**. Ele foi [introduzido pela primeira vez no GPT-4](https://openai.com/index/function-calling-and-other-api-updates/) e depois reproduzido em outros modelos.
+
+Assim como as ferramentas de um Agente, function calling dá ao modelo a capacidade de **agir sobre o ambiente**. Entretanto, essa capacidade **é aprendida pelo modelo** e depende **menos de prompting do que outras técnicas baseadas em agentes**.
+
+Na Unidade 1, o agente **não aprendeu a usar as ferramentas**; apenas fornecemos a lista e confiamos que o modelo **conseguiria generalizar para definir um plano usando essas Ferramentas**.
+
+Aqui, **com function calling, o agente passa por fine-tuning (treinamento) para usar Ferramentas**.
+
+## Como o modelo "aprende" a tomar uma ação?
+
+Na Unidade 1, exploramos o fluxo de trabalho geral de um agente. Depois que o usuário fornece ferramentas ao agente e o instrui com uma solicitação, o modelo passa pelo ciclo:
+
+1. *Pensar*: Quais ações preciso executar para atingir o objetivo?
+2. *Agir*: Formatar a ação com os parâmetros corretos e interromper a geração.
+3. *Observar*: Receber o resultado da execução.
+
+Em uma conversa "típica" com um modelo via API, as mensagens alternam entre usuário e assistente, como neste exemplo:
+
+```python
+conversation = [
+ {"role": "user", "content": "I need help with my order"},
+ {"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
+ {"role": "user", "content": "It's ORDER-123"},
+]
+```
+
+Function calling adiciona **novos papéis à conversa**!
+
+1. Um novo papel para uma **Ação**
+2. Um novo papel para uma **Observação**
+
+Se usarmos a [API da Mistral](https://docs.mistral.ai/capabilities/function_calling/) como exemplo, ela ficaria assim:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": "What's the status of my transaction T1001?"
+ },
+ {
+ "role": "assistant",
+ "content": "",
+ "function_call": {
+ "name": "retrieve_payment_status",
+ "arguments": "{\"transaction_id\": \"T1001\"}"
+ }
+ },
+ {
+ "role": "tool",
+ "name": "retrieve_payment_status",
+ "content": "{\"status\": \"Paid\"}"
+ },
+ {
+ "role": "assistant",
+ "content": "Your transaction T1001 has been successfully paid."
+ }
+]
+```
+
+> ... Mas você disse que existe um novo papel para chamadas de função?
+
+**Sim e não**. Neste caso, e em muitas outras APIs, o modelo formata a ação que deve executar como uma mensagem de "assistant". O template de chat então representa isso com **tokens especiais** para function calling.
+
+- `[AVAILABLE_TOOLS]` – Início da lista de ferramentas disponíveis
+- `[/AVAILABLE_TOOLS]` – Fim da lista de ferramentas disponíveis
+- `[TOOL_CALLS]` – Chamada a uma ferramenta (ou seja, uma "Ação")
+- `[TOOL_RESULTS]` – "Observa" o resultado da ação
+- `[/TOOL_RESULTS]` – Fim da observação (ou seja, o modelo pode voltar a decodificar)
+
+Falaremos novamente sobre function calling ao longo do curso, mas, se quiser se aprofundar, confira [esta excelente seção da documentação](https://docs.mistral.ai/capabilities/function_calling/).
+
+---
+
+Agora que entendemos o que é function calling e como ele funciona, vamos **adicionar essas capacidades a um modelo que ainda não as possui**: o [google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it), incluindo novos tokens especiais no modelo.
+
+Para conseguir fazer isso, **precisamos primeiro compreender fine-tuning e LoRA**.
diff --git a/units/pt_br/bonus-unit2/introduction.mdx b/units/pt_br/bonus-unit2/introduction.mdx
new file mode 100644
index 00000000..f1638c5a
--- /dev/null
+++ b/units/pt_br/bonus-unit2/introduction.mdx
@@ -0,0 +1,33 @@
+# Observabilidade e Avaliação de Agentes de IA
+
+
+
+Bem-vindo à **Unidade Bônus 2**! Neste capítulo, você vai explorar estratégias avançadas para observar, avaliar e, por fim, aprimorar o desempenho dos seus agentes.
+
+---
+
+## 📚 Quando devo fazer esta Unidade Bônus?
+
+Esta unidade é ideal se você:
+- **Desenvolve e coloca Agentes de IA em produção:** quer garantir que eles atuem de forma confiável.
+- **Precisa de insights detalhados:** busca diagnosticar problemas, otimizar desempenho ou entender o funcionamento interno do seu agente.
+- **Deseja reduzir o custo operacional:** ao monitorar custos de execução, latência e detalhes das execuções, você gerencia recursos com eficiência.
+- **Busca melhoria contínua:** deseja integrar feedback de usuários em tempo real e avaliação automatizada nas suas aplicações de IA.
+
+Em resumo, é para todo mundo que quer colocar seus agentes nas mãos dos usuários!
+
+---
+
+## 🤓 O que você vai aprender
+
+Ao longo desta unidade, você aprenderá a:
+- **Instrumentar seu agente:** integrar ferramentas de observabilidade via OpenTelemetry com o framework *smolagents*.
+- **Monitorar métricas:** acompanhar indicadores como uso de tokens (custos), latência e rastros de erros.
+- **Avaliar em tempo real:** aplicar técnicas de avaliação contínua, coletando feedback de usuários e usando um LLM como avaliador.
+- **Analisar offline:** utilizar conjuntos de benchmark (como o GSM8K) para testar e comparar o desempenho do agente.
+
+---
+
+## 🚀 Pronto para começar?
+
+Na próxima seção, você verá os fundamentos de Observabilidade e Avaliação de Agentes. Depois disso, é hora de ver tudo em ação!
diff --git a/units/pt_br/bonus-unit2/monitoring-and-evaluating-agents-notebook.mdx b/units/pt_br/bonus-unit2/monitoring-and-evaluating-agents-notebook.mdx
new file mode 100644
index 00000000..49bb2d7f
--- /dev/null
+++ b/units/pt_br/bonus-unit2/monitoring-and-evaluating-agents-notebook.mdx
@@ -0,0 +1,442 @@
+ +
+A maioria dos jogos precisa rodar em torno de 30 FPS, o que significa que um agente de IA em tempo real teria que agir 30 vezes por segundo — algo inviável com os LLMs agentivos atuais.
+
+Por outro lado, jogos em turnos como *Pokémon* são candidatos ideais, pois permitem que a IA tenha tempo para deliberar e tomar decisões estratégicas.
+
+É por isso que, na próxima seção, você vai construir seu próprio Agente de IA para batalhas em turnos no estilo Pokémon — e ainda poderá enfrentá-lo. Vamos lá!
diff --git a/units/pt_br/bonus-unit3/introduction.mdx b/units/pt_br/bonus-unit3/introduction.mdx
new file mode 100644
index 00000000..74aeec05
--- /dev/null
+++ b/units/pt_br/bonus-unit3/introduction.mdx
@@ -0,0 +1,26 @@
+# Introdução
+
+
+
+A maioria dos jogos precisa rodar em torno de 30 FPS, o que significa que um agente de IA em tempo real teria que agir 30 vezes por segundo — algo inviável com os LLMs agentivos atuais.
+
+Por outro lado, jogos em turnos como *Pokémon* são candidatos ideais, pois permitem que a IA tenha tempo para deliberar e tomar decisões estratégicas.
+
+É por isso que, na próxima seção, você vai construir seu próprio Agente de IA para batalhas em turnos no estilo Pokémon — e ainda poderá enfrentá-lo. Vamos lá!
diff --git a/units/pt_br/bonus-unit3/introduction.mdx b/units/pt_br/bonus-unit3/introduction.mdx
new file mode 100644
index 00000000..74aeec05
--- /dev/null
+++ b/units/pt_br/bonus-unit3/introduction.mdx
@@ -0,0 +1,26 @@
+# Introdução
+
+ +
+🎶I want to be the very best ... 🎶
+
+Bem-vindo a esta **unidade bônus**, onde você vai explorar a empolgante interseção entre **Agentes de IA e jogos**! 🎮🤖
+
+Imagine um jogo em que os personagens não jogáveis (NPCs) não apenas seguem falas pré-roteirizadas, mas sustentam conversas dinâmicas, se adaptam às suas estratégias e evoluem conforme a história avança. Esse é o poder de combinar **LLMs e comportamento agentivo em jogos**: abre as portas para uma **narrativa emergente e uma jogabilidade inédita**.
+
+Nesta unidade bônus, você vai:
+
+- Aprender a construir um Agente de IA capaz de travar **batalhas em turnos ao estilo Pokémon**
+- Jogar contra ele ou até desafiar outros agentes online
+
+Já vimos [alguns](https://www.anthropic.com/research/visible-extended-thinking) [exemplos](https://www.twitch.tv/gemini_plays_pokemon) da comunidade de IA jogando Pokémon com LLMs, e nesta unidade você vai aprender a replicar isso com o seu próprio Agente usando os conceitos aprendidos ao longo do curso.
+
+
+
+## Quer ir além?
+
+- 🎓 **Domine LLMs em jogos**: Aprofunde-se no desenvolvimento de games com o nosso curso completo [Machine Learning for Games Course](https://hf.co/learn/ml-games-course).
+
+- 📘 **Pegue o AI Playbook**: Descubra insights, ideias e dicas práticas no [AI Playbook for Game Developers](https://thomassimonini.substack.com/), onde o futuro do design de jogos inteligentes é explorado.
+
+Mas antes de construirmos, vamos ver como os LLMs já estão sendo usados em jogos com **quatro exemplos inspiradores do mundo real**.
diff --git a/units/pt_br/bonus-unit3/launching_agent_battle.mdx b/units/pt_br/bonus-unit3/launching_agent_battle.mdx
new file mode 100644
index 00000000..2c5f8496
--- /dev/null
+++ b/units/pt_br/bonus-unit3/launching_agent_battle.mdx
@@ -0,0 +1,70 @@
+# Lançando seu agente de batalha Pokémon
+
+Chegou a hora de batalhar! ⚡️
+
+## **Desafie o agente da live!**
+
+Se você não quer construir seu próprio agente e está apenas curioso sobre o potencial dos agentes em batalhas de Pokémon, estamos transmitindo uma live automatizada na [Twitch](https://www.twitch.tv/jofthomas).
+
+
+
+
+Para batalhar contra o agente que está sendo transmitido, siga estes passos:
+
+Instruções:
+1. Acesse o **Space Pokémon Showdown**: [Link aqui](https://huggingface.co/spaces/Jofthomas/Pokemon_showdown)
+2. **Escolha seu nome** (no canto superior direito).
+3. Encontre o **nome de usuário do agente atual**. Consulte:
+ * A **transmissão**: [Link aqui](https://www.twitch.tv/jofthomas)
+4. **Procure** esse nome de usuário no Space e **envie um convite de batalha**.
+
+*Atenção:* Apenas um agente fica online por vez! Garanta que está usando o nome correto.
+
+
+
+## Pokémon Battle Agent Challenger
+
+Se você criou seu próprio agente de batalha na seção anterior, deve estar se perguntando: **como testá-lo contra outros agentes?** Vamos descobrir!
+
+Criamos um [Space dedicado no Hugging Face](https://huggingface.co/spaces/PShowdown/pokemon_agents) para isso:
+
+
+
+Esse Space está conectado ao nosso **servidor Pokémon Showdown**, onde seu agente pode enfrentar outros em batalhas épicas impulsionadas por IA.
+
+### Como lançar o seu agente
+
+Siga estes passos para colocar o seu agente na arena:
+
+1. **Duplique o Space**
+ Clique nos três pontinhos no canto superior direito do Space e selecione “Duplicate this Space”.
+
+2. **Adicione o código do seu agente em `agent.py`**
+ Abra o arquivo e cole a implementação. Você pode seguir este [exemplo](https://huggingface.co/spaces/PShowdown/pokemon_agents/blob/main/agents.py) ou consultar a [estrutura do projeto](https://huggingface.co/spaces/PShowdown/pokemon_agents/tree/main) para orientação.
+
+3. **Registre seu agente em `app.py`**
+ Adicione o nome e a lógica do seu agente ao menu suspenso. Veja [este trecho](https://huggingface.co/spaces/PShowdown/pokemon_agents/blob/main/app.py) como referência.
+
+4. **Selecione seu agente**
+ Depois de adicionado, ele aparecerá no dropdown “Select Agent”. Escolha-o na lista! ✅
+
+5. **Informe seu nome de usuário do Pokémon Showdown**
+ Certifique-se de que o nome corresponde ao que aparece no campo **"Choose name"** do iframe. Você também pode usar sua conta oficial.
+
+6. **Clique em “Send Battle Invitation”**
+ Seu agente enviará um convite para o oponente escolhido. Ele deve aparecer na tela!
+
+7. **Aceite a batalha e divirta-se!**
+ Que a batalha comece! Que vença o agente mais inteligente.
+
+Preparado para ver sua criação em ação? Que o duelo de IAs comece! 🥊
diff --git a/units/pt_br/bonus-unit3/state-of-art.mdx b/units/pt_br/bonus-unit3/state-of-art.mdx
new file mode 100644
index 00000000..1df2f564
--- /dev/null
+++ b/units/pt_br/bonus-unit3/state-of-art.mdx
@@ -0,0 +1,53 @@
+# O estado da arte do uso de LLMs em jogos
+
+Para mostrar o quanto esse campo evoluiu, vamos conferir três demos tecnológicas e um jogo publicado que apresentam a integração de LLMs em jogos.
+
+## 🕵️♂️ Covert Protocol, da NVIDIA e Inworld AI
+
+
+
+🎶I want to be the very best ... 🎶
+
+Bem-vindo a esta **unidade bônus**, onde você vai explorar a empolgante interseção entre **Agentes de IA e jogos**! 🎮🤖
+
+Imagine um jogo em que os personagens não jogáveis (NPCs) não apenas seguem falas pré-roteirizadas, mas sustentam conversas dinâmicas, se adaptam às suas estratégias e evoluem conforme a história avança. Esse é o poder de combinar **LLMs e comportamento agentivo em jogos**: abre as portas para uma **narrativa emergente e uma jogabilidade inédita**.
+
+Nesta unidade bônus, você vai:
+
+- Aprender a construir um Agente de IA capaz de travar **batalhas em turnos ao estilo Pokémon**
+- Jogar contra ele ou até desafiar outros agentes online
+
+Já vimos [alguns](https://www.anthropic.com/research/visible-extended-thinking) [exemplos](https://www.twitch.tv/gemini_plays_pokemon) da comunidade de IA jogando Pokémon com LLMs, e nesta unidade você vai aprender a replicar isso com o seu próprio Agente usando os conceitos aprendidos ao longo do curso.
+
+
+
+## Quer ir além?
+
+- 🎓 **Domine LLMs em jogos**: Aprofunde-se no desenvolvimento de games com o nosso curso completo [Machine Learning for Games Course](https://hf.co/learn/ml-games-course).
+
+- 📘 **Pegue o AI Playbook**: Descubra insights, ideias e dicas práticas no [AI Playbook for Game Developers](https://thomassimonini.substack.com/), onde o futuro do design de jogos inteligentes é explorado.
+
+Mas antes de construirmos, vamos ver como os LLMs já estão sendo usados em jogos com **quatro exemplos inspiradores do mundo real**.
diff --git a/units/pt_br/bonus-unit3/launching_agent_battle.mdx b/units/pt_br/bonus-unit3/launching_agent_battle.mdx
new file mode 100644
index 00000000..2c5f8496
--- /dev/null
+++ b/units/pt_br/bonus-unit3/launching_agent_battle.mdx
@@ -0,0 +1,70 @@
+# Lançando seu agente de batalha Pokémon
+
+Chegou a hora de batalhar! ⚡️
+
+## **Desafie o agente da live!**
+
+Se você não quer construir seu próprio agente e está apenas curioso sobre o potencial dos agentes em batalhas de Pokémon, estamos transmitindo uma live automatizada na [Twitch](https://www.twitch.tv/jofthomas).
+
+
+
+
+Para batalhar contra o agente que está sendo transmitido, siga estes passos:
+
+Instruções:
+1. Acesse o **Space Pokémon Showdown**: [Link aqui](https://huggingface.co/spaces/Jofthomas/Pokemon_showdown)
+2. **Escolha seu nome** (no canto superior direito).
+3. Encontre o **nome de usuário do agente atual**. Consulte:
+ * A **transmissão**: [Link aqui](https://www.twitch.tv/jofthomas)
+4. **Procure** esse nome de usuário no Space e **envie um convite de batalha**.
+
+*Atenção:* Apenas um agente fica online por vez! Garanta que está usando o nome correto.
+
+
+
+## Pokémon Battle Agent Challenger
+
+Se você criou seu próprio agente de batalha na seção anterior, deve estar se perguntando: **como testá-lo contra outros agentes?** Vamos descobrir!
+
+Criamos um [Space dedicado no Hugging Face](https://huggingface.co/spaces/PShowdown/pokemon_agents) para isso:
+
+
+
+Esse Space está conectado ao nosso **servidor Pokémon Showdown**, onde seu agente pode enfrentar outros em batalhas épicas impulsionadas por IA.
+
+### Como lançar o seu agente
+
+Siga estes passos para colocar o seu agente na arena:
+
+1. **Duplique o Space**
+ Clique nos três pontinhos no canto superior direito do Space e selecione “Duplicate this Space”.
+
+2. **Adicione o código do seu agente em `agent.py`**
+ Abra o arquivo e cole a implementação. Você pode seguir este [exemplo](https://huggingface.co/spaces/PShowdown/pokemon_agents/blob/main/agents.py) ou consultar a [estrutura do projeto](https://huggingface.co/spaces/PShowdown/pokemon_agents/tree/main) para orientação.
+
+3. **Registre seu agente em `app.py`**
+ Adicione o nome e a lógica do seu agente ao menu suspenso. Veja [este trecho](https://huggingface.co/spaces/PShowdown/pokemon_agents/blob/main/app.py) como referência.
+
+4. **Selecione seu agente**
+ Depois de adicionado, ele aparecerá no dropdown “Select Agent”. Escolha-o na lista! ✅
+
+5. **Informe seu nome de usuário do Pokémon Showdown**
+ Certifique-se de que o nome corresponde ao que aparece no campo **"Choose name"** do iframe. Você também pode usar sua conta oficial.
+
+6. **Clique em “Send Battle Invitation”**
+ Seu agente enviará um convite para o oponente escolhido. Ele deve aparecer na tela!
+
+7. **Aceite a batalha e divirta-se!**
+ Que a batalha comece! Que vença o agente mais inteligente.
+
+Preparado para ver sua criação em ação? Que o duelo de IAs comece! 🥊
diff --git a/units/pt_br/bonus-unit3/state-of-art.mdx b/units/pt_br/bonus-unit3/state-of-art.mdx
new file mode 100644
index 00000000..1df2f564
--- /dev/null
+++ b/units/pt_br/bonus-unit3/state-of-art.mdx
@@ -0,0 +1,53 @@
+# O estado da arte do uso de LLMs em jogos
+
+Para mostrar o quanto esse campo evoluiu, vamos conferir três demos tecnológicas e um jogo publicado que apresentam a integração de LLMs em jogos.
+
+## 🕵️♂️ Covert Protocol, da NVIDIA e Inworld AI
+
+ +
+Apresentada na GDC 2024, *Covert Protocol* é uma demo tecnológica que coloca você no papel de um detetive particular.
+
+O destaque da demo é o uso de NPCs com IA que respondem às suas perguntas em tempo real, moldando a narrativa conforme suas interações.
+
+Construída na Unreal Engine 5, a experiência usa o Avatar Cloud Engine (ACE) da NVIDIA e a IA da Inworld para criar interações extremamente realistas.
+
+Saiba mais 👉 [Blog da Inworld AI](https://inworld.ai/blog/nvidia-inworld-ai-demo-on-device-capabilities)
+
+## 🤖 NEO NPCs, da Ubisoft
+
+
+
+Apresentada na GDC 2024, *Covert Protocol* é uma demo tecnológica que coloca você no papel de um detetive particular.
+
+O destaque da demo é o uso de NPCs com IA que respondem às suas perguntas em tempo real, moldando a narrativa conforme suas interações.
+
+Construída na Unreal Engine 5, a experiência usa o Avatar Cloud Engine (ACE) da NVIDIA e a IA da Inworld para criar interações extremamente realistas.
+
+Saiba mais 👉 [Blog da Inworld AI](https://inworld.ai/blog/nvidia-inworld-ai-demo-on-device-capabilities)
+
+## 🤖 NEO NPCs, da Ubisoft
+
+ +
+Também na GDC 2024, a Ubisoft apresentou *NEO NPCs*, um protótipo com NPCs impulsionados por IA generativa.
+
+Esses personagens percebem o ambiente, lembram interações anteriores e mantêm conversas significativas com os jogadores.
+
+A ideia é criar mundos mais imersivos e responsivos, onde o jogador possa realmente interagir com os NPCs.
+
+Saiba mais 👉 [Blog da Inworld AI](https://inworld.ai/blog/gdc-2024)
+
+## ⚔️ Mecha BREAK com a tecnologia ACE da NVIDIA
+
+
+
+Também na GDC 2024, a Ubisoft apresentou *NEO NPCs*, um protótipo com NPCs impulsionados por IA generativa.
+
+Esses personagens percebem o ambiente, lembram interações anteriores e mantêm conversas significativas com os jogadores.
+
+A ideia é criar mundos mais imersivos e responsivos, onde o jogador possa realmente interagir com os NPCs.
+
+Saiba mais 👉 [Blog da Inworld AI](https://inworld.ai/blog/gdc-2024)
+
+## ⚔️ Mecha BREAK com a tecnologia ACE da NVIDIA
+
+ +
+*Mecha BREAK*, um jogo multiplayer de batalhas entre mechas que ainda será lançado, integra a tecnologia ACE da NVIDIA para dar vida a NPCs com IA.
+
+Os jogadores podem interagir com esses personagens usando linguagem natural, e os NPCs reconhecem jogadores e objetos via webcam graças à integração com o GPT-4o. A promessa é uma experiência muito mais imersiva e interativa.
+
+Saiba mais 👉 [Blog da NVIDIA](https://blogs.nvidia.com/blog/digital-human-technology-mecha-break/)
+
+## 🧛♂️ *Suck Up!*, da Proxima Enterprises
+
+
+
+*Mecha BREAK*, um jogo multiplayer de batalhas entre mechas que ainda será lançado, integra a tecnologia ACE da NVIDIA para dar vida a NPCs com IA.
+
+Os jogadores podem interagir com esses personagens usando linguagem natural, e os NPCs reconhecem jogadores e objetos via webcam graças à integração com o GPT-4o. A promessa é uma experiência muito mais imersiva e interativa.
+
+Saiba mais 👉 [Blog da NVIDIA](https://blogs.nvidia.com/blog/digital-human-technology-mecha-break/)
+
+## 🧛♂️ *Suck Up!*, da Proxima Enterprises
+
+ +
+Por fim, *Suck Up!* é um jogo publicado em que você controla um vampiro tentando entrar nas casas **convencendo NPCs controlados por IA a convidá-lo**.
+
+Cada personagem é movido por IA generativa, o que garante interações dinâmicas e imprevisíveis.
+
+Saiba mais 👉 [Site oficial de Suck Up!](https://www.playsuckup.com/)
+
+## Mas... onde estão os agentes?
+
+Depois de explorar essas demos, você pode se perguntar: “Esses exemplos mostram o uso de LLMs em jogos, mas não parecem envolver agentes. Qual é a diferença e o que os agentes acrescentam?”
+
+Não se preocupe, é exatamente o que vamos estudar na próxima seção.
diff --git a/units/pt_br/communication/live1.mdx b/units/pt_br/communication/live1.mdx
new file mode 100644
index 00000000..8e321ecf
--- /dev/null
+++ b/units/pt_br/communication/live1.mdx
@@ -0,0 +1,7 @@
+# Live 1: Como o Curso Funciona e Primeira Sessão de Perguntas e Respostas
+
+Nesta primeira transmissão ao vivo do Curso de Agentes, explicamos como o curso **funciona** (escopo, unidades, desafios e mais) e respondemos suas perguntas.
+
+
+
+Para saber quando a próxima sessão ao vivo está agendada, verifique nosso **servidor Discord**. Também enviaremos um e-mail para você. Se não puder participar, não se preocupe, nós **gravamos todas as sessões ao vivo**.
diff --git a/units/pt_br/unit0/discord101.mdx b/units/pt_br/unit0/discord101.mdx
new file mode 100644
index 00000000..7cf0073c
--- /dev/null
+++ b/units/pt_br/unit0/discord101.mdx
@@ -0,0 +1,52 @@
+# (Opcional) Discord 101 [[discord-101]]
+
+
+
+Por fim, *Suck Up!* é um jogo publicado em que você controla um vampiro tentando entrar nas casas **convencendo NPCs controlados por IA a convidá-lo**.
+
+Cada personagem é movido por IA generativa, o que garante interações dinâmicas e imprevisíveis.
+
+Saiba mais 👉 [Site oficial de Suck Up!](https://www.playsuckup.com/)
+
+## Mas... onde estão os agentes?
+
+Depois de explorar essas demos, você pode se perguntar: “Esses exemplos mostram o uso de LLMs em jogos, mas não parecem envolver agentes. Qual é a diferença e o que os agentes acrescentam?”
+
+Não se preocupe, é exatamente o que vamos estudar na próxima seção.
diff --git a/units/pt_br/communication/live1.mdx b/units/pt_br/communication/live1.mdx
new file mode 100644
index 00000000..8e321ecf
--- /dev/null
+++ b/units/pt_br/communication/live1.mdx
@@ -0,0 +1,7 @@
+# Live 1: Como o Curso Funciona e Primeira Sessão de Perguntas e Respostas
+
+Nesta primeira transmissão ao vivo do Curso de Agentes, explicamos como o curso **funciona** (escopo, unidades, desafios e mais) e respondemos suas perguntas.
+
+
+
+Para saber quando a próxima sessão ao vivo está agendada, verifique nosso **servidor Discord**. Também enviaremos um e-mail para você. Se não puder participar, não se preocupe, nós **gravamos todas as sessões ao vivo**.
diff --git a/units/pt_br/unit0/discord101.mdx b/units/pt_br/unit0/discord101.mdx
new file mode 100644
index 00000000..7cf0073c
--- /dev/null
+++ b/units/pt_br/unit0/discord101.mdx
@@ -0,0 +1,52 @@
+# (Opcional) Discord 101 [[discord-101]]
+
+ +
+Este guia foi projetado para ajudá-lo a começar com Discord, uma plataforma de chat gratuita popular nas comunidades de jogos e ML.
+
+Junte-se ao servidor Discord da Comunidade Hugging Face, que **tem mais de 100.000 membros**, clicando aqui. É um ótimo lugar para se conectar com outras pessoas!
+
+## O curso de Agentes na Comunidade Discord do Hugging Face
+
+Começar no Discord pode ser um pouco avassalador, então aqui está um guia rápido para ajudá-lo a navegar.
+
+
+
+O Servidor da Comunidade HF hospeda uma comunidade vibrante com interesses em várias áreas, oferecendo oportunidades de aprendizado através de discussões de papers, eventos e muito mais.
+
+Após [se inscrever](http://hf.co/join/discord), apresente-se no canal `#introduce-yourself`.
+
+Criamos 4 canais para o Curso de Agentes:
+
+- `agents-course-announcements`: para as **últimas informações do curso**.
+- `🎓-agents-course-general`: para **discussões gerais e conversas**.
+- `agents-course-questions`: para **fazer perguntas e ajudar seus colegas de classe**.
+- `agents-course-showcase`: para **mostrar seus melhores agentes**.
+
+Além disso, você pode verificar:
+
+- `smolagents`: para **discussão e suporte com a biblioteca**.
+
+## Dicas para usar Discord efetivamente
+
+### Como se juntar a um servidor
+
+Se você não está muito familiarizado com Discord, pode querer verificar este guia sobre como se juntar a um servidor.
+
+Aqui está um resumo rápido dos passos:
+
+1. Clique no Link de Convite.
+2. Faça login com sua conta Discord, ou crie uma conta se não tiver uma.
+3. Valide que você não é um agente de IA!
+4. Configure seu apelido e avatar.
+5. Clique em "Entrar no Servidor".
+
+### Como usar Discord efetivamente
+
+Aqui estão algumas dicas para usar Discord efetivamente:
+
+- **Canais de voz** estão disponíveis, embora o chat de texto seja mais comumente usado.
+- Você pode formatar texto usando **estilo markdown**, que é especialmente útil para escrever código. Note que markdown não funciona tão bem para links.
+- Considere abrir threads para **conversas longas** para manter as discussões organizadas.
+
+Esperamos que você ache este guia útil! Se tiver alguma dúvida, sinta-se livre para nos perguntar no Discord 🤗.
diff --git a/units/pt_br/unit0/introduction.mdx b/units/pt_br/unit0/introduction.mdx
new file mode 100644
index 00000000..023109f4
--- /dev/null
+++ b/units/pt_br/unit0/introduction.mdx
@@ -0,0 +1,161 @@
+# Bem-vindos ao Curso de Agentes de IA 🤗 [[introduction]]
+
+
+
+
+Este guia foi projetado para ajudá-lo a começar com Discord, uma plataforma de chat gratuita popular nas comunidades de jogos e ML.
+
+Junte-se ao servidor Discord da Comunidade Hugging Face, que **tem mais de 100.000 membros**, clicando aqui. É um ótimo lugar para se conectar com outras pessoas!
+
+## O curso de Agentes na Comunidade Discord do Hugging Face
+
+Começar no Discord pode ser um pouco avassalador, então aqui está um guia rápido para ajudá-lo a navegar.
+
+
+
+O Servidor da Comunidade HF hospeda uma comunidade vibrante com interesses em várias áreas, oferecendo oportunidades de aprendizado através de discussões de papers, eventos e muito mais.
+
+Após [se inscrever](http://hf.co/join/discord), apresente-se no canal `#introduce-yourself`.
+
+Criamos 4 canais para o Curso de Agentes:
+
+- `agents-course-announcements`: para as **últimas informações do curso**.
+- `🎓-agents-course-general`: para **discussões gerais e conversas**.
+- `agents-course-questions`: para **fazer perguntas e ajudar seus colegas de classe**.
+- `agents-course-showcase`: para **mostrar seus melhores agentes**.
+
+Além disso, você pode verificar:
+
+- `smolagents`: para **discussão e suporte com a biblioteca**.
+
+## Dicas para usar Discord efetivamente
+
+### Como se juntar a um servidor
+
+Se você não está muito familiarizado com Discord, pode querer verificar este guia sobre como se juntar a um servidor.
+
+Aqui está um resumo rápido dos passos:
+
+1. Clique no Link de Convite.
+2. Faça login com sua conta Discord, ou crie uma conta se não tiver uma.
+3. Valide que você não é um agente de IA!
+4. Configure seu apelido e avatar.
+5. Clique em "Entrar no Servidor".
+
+### Como usar Discord efetivamente
+
+Aqui estão algumas dicas para usar Discord efetivamente:
+
+- **Canais de voz** estão disponíveis, embora o chat de texto seja mais comumente usado.
+- Você pode formatar texto usando **estilo markdown**, que é especialmente útil para escrever código. Note que markdown não funciona tão bem para links.
+- Considere abrir threads para **conversas longas** para manter as discussões organizadas.
+
+Esperamos que você ache este guia útil! Se tiver alguma dúvida, sinta-se livre para nos perguntar no Discord 🤗.
diff --git a/units/pt_br/unit0/introduction.mdx b/units/pt_br/unit0/introduction.mdx
new file mode 100644
index 00000000..023109f4
--- /dev/null
+++ b/units/pt_br/unit0/introduction.mdx
@@ -0,0 +1,161 @@
+# Bem-vindos ao Curso de Agentes de IA 🤗 [[introduction]]
+
+
+ +
+## O Processo de Certificação [[certification-process]]
+
+
+
+## O Processo de Certificação [[certification-process]]
+
+ +
+Você pode escolher seguir este curso *em modo de auditoria* ou fazer as atividades e *obter um dos dois certificados que emitiremos*.
+
+Se você auditar o curso, pode participar de todos os desafios e fazer tarefas se quiser, e **não precisa nos notificar**.
+
+O processo de certificação é **completamente gratuito**:
+
+- *Para obter uma certificação de fundamentos*: você precisa completar a Unidade 1 do curso. Isto é destinado a estudantes que querem se atualizar com as últimas tendências em Agentes.
+- *Para obter um certificado de conclusão*: você precisa completar a Unidade 1, uma das tarefas de caso de uso que proporemos durante o curso e o desafio final.
+
+**Não há prazo** para o processo de certificação.
+
+## Qual é o ritmo recomendado? [[recommended-pace]]
+
+Cada capítulo neste curso foi projetado **para ser completado em 1 semana, com aproximadamente 3-4 horas de trabalho por semana**.
+
+Fornecemos um ritmo recomendado:
+
+
+
+Você pode escolher seguir este curso *em modo de auditoria* ou fazer as atividades e *obter um dos dois certificados que emitiremos*.
+
+Se você auditar o curso, pode participar de todos os desafios e fazer tarefas se quiser, e **não precisa nos notificar**.
+
+O processo de certificação é **completamente gratuito**:
+
+- *Para obter uma certificação de fundamentos*: você precisa completar a Unidade 1 do curso. Isto é destinado a estudantes que querem se atualizar com as últimas tendências em Agentes.
+- *Para obter um certificado de conclusão*: você precisa completar a Unidade 1, uma das tarefas de caso de uso que proporemos durante o curso e o desafio final.
+
+**Não há prazo** para o processo de certificação.
+
+## Qual é o ritmo recomendado? [[recommended-pace]]
+
+Cada capítulo neste curso foi projetado **para ser completado em 1 semana, com aproximadamente 3-4 horas de trabalho por semana**.
+
+Fornecemos um ritmo recomendado:
+
+ +
+## Como aproveitar ao máximo o curso? [[advice]]
+
+Para aproveitar ao máximo o curso, temos algumas dicas:
+
+1. Participe de grupos de estudo no Discord: estudar em grupos é sempre mais fácil. Para isso, você precisa se juntar ao nosso servidor discord e verificar sua conta do Hugging Face.
+2. **Faça os quizzes e tarefas**: a melhor maneira de aprender é através da prática hands-on e autoavaliação.
+3. **Defina um cronograma para ficar em sincronia**: você pode usar nosso cronograma de ritmo recomendado abaixo ou criar o seu.
+
+
+
+## Como aproveitar ao máximo o curso? [[advice]]
+
+Para aproveitar ao máximo o curso, temos algumas dicas:
+
+1. Participe de grupos de estudo no Discord: estudar em grupos é sempre mais fácil. Para isso, você precisa se juntar ao nosso servidor discord e verificar sua conta do Hugging Face.
+2. **Faça os quizzes e tarefas**: a melhor maneira de aprender é através da prática hands-on e autoavaliação.
+3. **Defina um cronograma para ficar em sincronia**: você pode usar nosso cronograma de ritmo recomendado abaixo ou criar o seu.
+
+ +
+## Quem somos [[who-are-we]]
+
+Este curso é mantido por [Ben Burtenshaw](https://huggingface.co/burtenshaw) e [Sergio Paniego](https://huggingface.co/sergiopaniego). Se você tiver alguma dúvida, entre em contato conosco no Hub!
+
+## Agradecimentos
+
+Gostaríamos de estender nossa gratidão aos seguintes indivíduos por suas contribuições inestimáveis para este curso:
+
+- **[Joffrey Thomas](https://huggingface.co/Jofthomas)** – Por escrever e desenvolver o curso.
+- **[Thomas Simonini](https://huggingface.co/ThomasSimonini)** – Por escrever e desenvolver o curso.
+- **[Pedro Cuenca](https://huggingface.co/pcuenq)** – Por orientar o curso e fornecer feedback.
+- **[Aymeric Roucher](https://huggingface.co/m-ric)** – Por seus incríveis demo spaces (decodificação e agente final) bem como sua ajuda nas partes do smolagents.
+- **[Joshua Lochner](https://huggingface.co/Xenova)** – Por seu incrível demo space sobre tokenização.
+- **[Quentin Gallouédec](https://huggingface.co/qgallouedec)** – Por sua ajuda no conteúdo do curso.
+- **[David Berenstein](https://huggingface.co/davidberenstein1957)** – Por sua ajuda no conteúdo do curso e moderação.
+- **[XiaXiao (ShawnSiao)](https://huggingface.co/SSSSSSSiao)** – Tradutor chinês do curso.
+- **[Jiaming Huang](https://huggingface.co/nordicsushi)** – Tradutor chinês do curso.
+- **[Kim Noel](https://github.com/knoel99)** – Tradutor francês do curso.
+- **[Loïck Bourdois](https://huggingface.co/lbourdois)** – Tradutor francês do curso da [CATIE](https://www.catie.fr/).
+- **[Mauro Risonho de Paula Assumpção](https://huggingface.co/maurorisonho)** – Tradutor português brasileiro do curso.
+
+
+## Encontrei um bug ou quero melhorar o curso [[contribute]]
+
+Contribuições são **bem-vindas** 🤗
+
+- Se você *encontrou um bug 🐛 em um notebook*, por favor abra uma issue e **descreva o problema**.
+- Se você *quer melhorar o curso*, pode abrir um Pull Request.
+- Se você *quer adicionar uma seção completa ou uma nova unidade*, o melhor é abrir uma issue e **descrever que conteúdo você quer adicionar antes de começar a escrever para que possamos te orientar**.
+
+## Ainda tenho dúvidas [[questions]]
+
+Por favor, faça sua pergunta em nosso servidor discord #agents-course-questions.
+
+Agora que você tem todas as informações, vamos embarcar ⛵
+
+
+
+## Quem somos [[who-are-we]]
+
+Este curso é mantido por [Ben Burtenshaw](https://huggingface.co/burtenshaw) e [Sergio Paniego](https://huggingface.co/sergiopaniego). Se você tiver alguma dúvida, entre em contato conosco no Hub!
+
+## Agradecimentos
+
+Gostaríamos de estender nossa gratidão aos seguintes indivíduos por suas contribuições inestimáveis para este curso:
+
+- **[Joffrey Thomas](https://huggingface.co/Jofthomas)** – Por escrever e desenvolver o curso.
+- **[Thomas Simonini](https://huggingface.co/ThomasSimonini)** – Por escrever e desenvolver o curso.
+- **[Pedro Cuenca](https://huggingface.co/pcuenq)** – Por orientar o curso e fornecer feedback.
+- **[Aymeric Roucher](https://huggingface.co/m-ric)** – Por seus incríveis demo spaces (decodificação e agente final) bem como sua ajuda nas partes do smolagents.
+- **[Joshua Lochner](https://huggingface.co/Xenova)** – Por seu incrível demo space sobre tokenização.
+- **[Quentin Gallouédec](https://huggingface.co/qgallouedec)** – Por sua ajuda no conteúdo do curso.
+- **[David Berenstein](https://huggingface.co/davidberenstein1957)** – Por sua ajuda no conteúdo do curso e moderação.
+- **[XiaXiao (ShawnSiao)](https://huggingface.co/SSSSSSSiao)** – Tradutor chinês do curso.
+- **[Jiaming Huang](https://huggingface.co/nordicsushi)** – Tradutor chinês do curso.
+- **[Kim Noel](https://github.com/knoel99)** – Tradutor francês do curso.
+- **[Loïck Bourdois](https://huggingface.co/lbourdois)** – Tradutor francês do curso da [CATIE](https://www.catie.fr/).
+- **[Mauro Risonho de Paula Assumpção](https://huggingface.co/maurorisonho)** – Tradutor português brasileiro do curso.
+
+
+## Encontrei um bug ou quero melhorar o curso [[contribute]]
+
+Contribuições são **bem-vindas** 🤗
+
+- Se você *encontrou um bug 🐛 em um notebook*, por favor abra uma issue e **descreva o problema**.
+- Se você *quer melhorar o curso*, pode abrir um Pull Request.
+- Se você *quer adicionar uma seção completa ou uma nova unidade*, o melhor é abrir uma issue e **descrever que conteúdo você quer adicionar antes de começar a escrever para que possamos te orientar**.
+
+## Ainda tenho dúvidas [[questions]]
+
+Por favor, faça sua pergunta em nosso servidor discord #agents-course-questions.
+
+Agora que você tem todas as informações, vamos embarcar ⛵
+
+ +
diff --git a/units/pt_br/unit0/onboarding.mdx b/units/pt_br/unit0/onboarding.mdx
new file mode 100644
index 00000000..29f61957
--- /dev/null
+++ b/units/pt_br/unit0/onboarding.mdx
@@ -0,0 +1,104 @@
+# Integração: Seus Primeiros Passos ⛵
+
+
+
+Agora que você tem todos os detalhes, vamos começar! Vamos fazer quatro coisas:
+
+1. **Criar sua Conta do Hugging Face** se ainda não foi feito
+2. **Inscrever-se no Discord e se apresentar** (não seja tímido 🤗)
+3. **Seguir o Curso de Agentes do Hugging Face** no Hub
+4. **Espalhar a palavra** sobre o curso
+
+### Passo 1: Criar sua Conta do Hugging Face
+
+(Se você ainda não fez) crie uma conta do Hugging Face aqui.
+
+### Passo 2: Juntar-se à Nossa Comunidade Discord
+
+👉🏻 Junte-se ao nosso servidor discord aqui.
+
+Quando você se juntar, lembre-se de se apresentar em `#introduce-yourself`.
+
+Temos múltiplos canais relacionados a Agentes de IA:
+- `agents-course-announcements`: para as **últimas informações do curso**.
+- `🎓-agents-course-general`: para **discussões gerais e conversas**.
+- `agents-course-questions`: para **fazer perguntas e ajudar seus colegas de classe**.
+- `agents-course-showcase`: para **mostrar seus melhores agentes**.
+
+Além disso, você pode verificar:
+
+- `smolagents`: para **discussão e suporte com a biblioteca**.
+
+Se esta é sua primeira vez usando Discord, escrevemos um Discord 101 para obter as melhores práticas. Verifique [a próxima seção](discord101).
+
+### Passo 3: Seguir a Organização do Curso de Agentes do Hugging Face
+
+Mantenha-se atualizado com os materiais mais recentes do curso, atualizações e anúncios **seguindo a Organização do Curso de Agentes do Hugging Face**.
+
+👉 Vá aqui e clique em **seguir**.
+
+
+
diff --git a/units/pt_br/unit0/onboarding.mdx b/units/pt_br/unit0/onboarding.mdx
new file mode 100644
index 00000000..29f61957
--- /dev/null
+++ b/units/pt_br/unit0/onboarding.mdx
@@ -0,0 +1,104 @@
+# Integração: Seus Primeiros Passos ⛵
+
+
+
+Agora que você tem todos os detalhes, vamos começar! Vamos fazer quatro coisas:
+
+1. **Criar sua Conta do Hugging Face** se ainda não foi feito
+2. **Inscrever-se no Discord e se apresentar** (não seja tímido 🤗)
+3. **Seguir o Curso de Agentes do Hugging Face** no Hub
+4. **Espalhar a palavra** sobre o curso
+
+### Passo 1: Criar sua Conta do Hugging Face
+
+(Se você ainda não fez) crie uma conta do Hugging Face aqui.
+
+### Passo 2: Juntar-se à Nossa Comunidade Discord
+
+👉🏻 Junte-se ao nosso servidor discord aqui.
+
+Quando você se juntar, lembre-se de se apresentar em `#introduce-yourself`.
+
+Temos múltiplos canais relacionados a Agentes de IA:
+- `agents-course-announcements`: para as **últimas informações do curso**.
+- `🎓-agents-course-general`: para **discussões gerais e conversas**.
+- `agents-course-questions`: para **fazer perguntas e ajudar seus colegas de classe**.
+- `agents-course-showcase`: para **mostrar seus melhores agentes**.
+
+Além disso, você pode verificar:
+
+- `smolagents`: para **discussão e suporte com a biblioteca**.
+
+Se esta é sua primeira vez usando Discord, escrevemos um Discord 101 para obter as melhores práticas. Verifique [a próxima seção](discord101).
+
+### Passo 3: Seguir a Organização do Curso de Agentes do Hugging Face
+
+Mantenha-se atualizado com os materiais mais recentes do curso, atualizações e anúncios **seguindo a Organização do Curso de Agentes do Hugging Face**.
+
+👉 Vá aqui e clique em **seguir**.
+
+ +
+### Passo 4: Espalhar a palavra sobre o curso
+
+Ajude-nos a tornar este curso mais visível! Há duas maneiras de você nos ajudar:
+
+1. Mostre seu apoio dando ⭐ ao repositório do curso.
+
+
+
+### Passo 4: Espalhar a palavra sobre o curso
+
+Ajude-nos a tornar este curso mais visível! Há duas maneiras de você nos ajudar:
+
+1. Mostre seu apoio dando ⭐ ao repositório do curso.
+
+ +
+2. Compartilhe sua Jornada de Aprendizado: Deixe outros **saberem que você está fazendo este curso**! Preparamos uma ilustração que você pode usar em suas postagens de mídia social
+
+
+
+2. Compartilhe sua Jornada de Aprendizado: Deixe outros **saberem que você está fazendo este curso**! Preparamos uma ilustração que você pode usar em suas postagens de mídia social
+
+ +
+Você pode baixar a imagem clicando 👉 [aqui](https://huggingface.co/datasets/agents-course/course-images/resolve/main/en/communication/share.png?download=true)
+
+### Passo 5: Executando Modelos Localmente com Ollama (Caso você encontre limites de crédito)
+
+1. **Instalar Ollama**
+
+ Siga as instruções oficiais aqui.
+
+2. **Baixar um modelo localmente**
+
+ ```bash
+ ollama pull qwen2:7b
+ ```
+
+ Aqui, baixamos o modelo qwen2:7b. Confira o site do ollama para mais modelos.
+
+3. **Iniciar Ollama em segundo plano (Em um terminal)**
+ ``` bash
+ ollama serve
+ ```
+
+ Se você encontrar o erro "listen tcp 127.0.0.1:11434: bind: address already in use", pode usar o comando `sudo lsof -i :11434` para identificar o ID do processo
+ (PID) que está atualmente usando esta porta. Se o processo for `ollama`, é provável que o script de instalação acima tenha iniciado o serviço ollama,
+ então você pode pular este comando para iniciar o Ollama.
+
+4. **Usar `LiteLLMModel` em vez de `InferenceClientModel`**
+
+ Para usar o módulo `LiteLLMModel` no `smolagents`, você pode executar o comando `pip` para instalar o módulo.
+
+``` bash
+ pip install 'smolagents[litellm]'
+```
+
+``` python
+ from smolagents import LiteLLMModel
+
+ model = LiteLLMModel(
+ model_id="ollama_chat/qwen2:7b", # Ou tente outros modelos suportados pelo Ollama
+ api_base="http://127.0.0.1:11434", # Servidor local padrão do Ollama
+ num_ctx=8192,
+ )
+```
+
+5. **Por que isso funciona?**
+- O Ollama serve modelos localmente usando uma API compatível com OpenAI em `http://localhost:11434`.
+- `LiteLLMModel` foi construído para se comunicar com qualquer modelo que suporte o formato de API chat/completion do OpenAI.
+- Isso significa que você pode simplesmente trocar `InferenceClientModel` por `LiteLLMModel` sem outras mudanças de código necessárias. É uma solução perfeita e plug-and-play.
+
+Parabéns! 🎉 **Você completou o processo de integração**! Agora você está pronto para começar a aprender sobre Agentes de IA. Divirta-se!
+
+Continue Aprendendo, permaneça incrível 🤗
diff --git a/units/pt_br/unit1/README.md b/units/pt_br/unit1/README.md
new file mode 100644
index 00000000..a40be38d
--- /dev/null
+++ b/units/pt_br/unit1/README.md
@@ -0,0 +1,19 @@
+# Sumário
+
+Você pode acessar a Unidade 1 em hf.co/learn 👉 neste link
+
+
diff --git a/units/pt_br/unit1/actions.mdx b/units/pt_br/unit1/actions.mdx
new file mode 100644
index 00000000..21f64d3e
--- /dev/null
+++ b/units/pt_br/unit1/actions.mdx
@@ -0,0 +1,124 @@
+# Ações: habilitando o agente a interagir com o ambiente
+
+> [!TIP]
+> Nesta seção, exploramos as etapas concretas que um agente de IA segue para interagir com seu ambiente.
+>
+> Vamos ver como as ações são representadas (usando JSON ou código), por que a abordagem stop and parse é importante e quais tipos de agentes existem.
+
+Ações são as etapas concretas que um **agente de IA executa para interagir com o ambiente**.
+
+Seja buscando informações na web ou controlando um dispositivo físico, cada ação é uma operação deliberada feita pelo agente.
+
+Por exemplo, um agente de suporte ao cliente pode recuperar dados do usuário, sugerir artigos de ajuda ou encaminhar o caso para um atendente humano.
+
+## Tipos de ações de um agente
+
+Há vários tipos de agentes que executam ações de maneiras diferentes:
+
+| Tipo de agente | Descrição |
+|-------------------------|-------------------------------------------------------------------------------------------------|
+| Agente JSON | A ação é especificada em formato JSON. |
+| Agente de código | O agente escreve um bloco de código que será interpretado externamente. |
+| Agente com function calling | Subcategoria do agente JSON, ajustada para gerar uma nova mensagem a cada ação. |
+
+As ações em si podem servir a muitos propósitos:
+
+| Tipo de ação | Descrição |
+|--------------------------|---------------------------------------------------------------------------------------------|
+| Coleta de informações | Fazer buscas na web, consultar bancos de dados ou recuperar documentos. |
+| Uso de ferramentas | Realizar chamadas de API, executar cálculos e rodar código. |
+| Interação com o ambiente | Manipular interfaces digitais ou controlar dispositivos físicos. |
+| Comunicação | Conversar com usuários via chat ou colaborar com outros agentes. |
+
+O LLM lida apenas com texto. Ele descreve a ação que deseja executar e os parâmetros que serão enviados à ferramenta. Para que o agente funcione corretamente, o LLM precisa parar de gerar tokens assim que terminar de definir completamente a ação. Isso devolve o controle para o agente e garante que o resultado seja analisável, seja em JSON, código ou formato de function calling.
+
+## A abordagem stop and parse
+
+Uma estratégia fundamental para implementar ações é a **stop and parse**. Ela garante que a saída do agente seja estruturada e previsível:
+
+1. **Geração em formato estruturado**:
+
+O agente escreve a ação desejada em um formato claro e pré-definido (JSON ou código).
+
+2. **Interromper a geração**:
+
+Assim que o texto que define a ação é emitido, **o LLM interrompe a geração de novos tokens**. Isso evita saídas extra ou equivocadas.
+
+3. **Analisar a saída**:
+
+Um parser externo lê a ação formatada, identifica qual ferramenta chamar e extrai os parâmetros necessários.
+
+Por exemplo, um agente que precisa consultar o clima pode produzir:
+
+
+```json
+Thought: I need to check the current weather for New York.
+Action :
+{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}
+```
+O framework consegue analisar facilmente o nome da função a ser chamada e os argumentos necessários.
+
+Esse formato claro e legível por máquina reduz erros e permite que ferramentas externas processem o comando com precisão.
+
+Observação: agentes com function calling funcionam de forma semelhante, estruturando cada ação para invocar a função certa com os argumentos corretos. Vamos aprofundar nesses agentes em uma unidade futura.
+
+## Agentes de código
+
+Uma abordagem alternativa é usar *agentes de código*.
+A ideia é: **em vez de produzir um objeto JSON simples**, o agente gera um **bloco de código executável — normalmente em uma linguagem de alto nível como Python**.
+
+
+
+Você pode baixar a imagem clicando 👉 [aqui](https://huggingface.co/datasets/agents-course/course-images/resolve/main/en/communication/share.png?download=true)
+
+### Passo 5: Executando Modelos Localmente com Ollama (Caso você encontre limites de crédito)
+
+1. **Instalar Ollama**
+
+ Siga as instruções oficiais aqui.
+
+2. **Baixar um modelo localmente**
+
+ ```bash
+ ollama pull qwen2:7b
+ ```
+
+ Aqui, baixamos o modelo qwen2:7b. Confira o site do ollama para mais modelos.
+
+3. **Iniciar Ollama em segundo plano (Em um terminal)**
+ ``` bash
+ ollama serve
+ ```
+
+ Se você encontrar o erro "listen tcp 127.0.0.1:11434: bind: address already in use", pode usar o comando `sudo lsof -i :11434` para identificar o ID do processo
+ (PID) que está atualmente usando esta porta. Se o processo for `ollama`, é provável que o script de instalação acima tenha iniciado o serviço ollama,
+ então você pode pular este comando para iniciar o Ollama.
+
+4. **Usar `LiteLLMModel` em vez de `InferenceClientModel`**
+
+ Para usar o módulo `LiteLLMModel` no `smolagents`, você pode executar o comando `pip` para instalar o módulo.
+
+``` bash
+ pip install 'smolagents[litellm]'
+```
+
+``` python
+ from smolagents import LiteLLMModel
+
+ model = LiteLLMModel(
+ model_id="ollama_chat/qwen2:7b", # Ou tente outros modelos suportados pelo Ollama
+ api_base="http://127.0.0.1:11434", # Servidor local padrão do Ollama
+ num_ctx=8192,
+ )
+```
+
+5. **Por que isso funciona?**
+- O Ollama serve modelos localmente usando uma API compatível com OpenAI em `http://localhost:11434`.
+- `LiteLLMModel` foi construído para se comunicar com qualquer modelo que suporte o formato de API chat/completion do OpenAI.
+- Isso significa que você pode simplesmente trocar `InferenceClientModel` por `LiteLLMModel` sem outras mudanças de código necessárias. É uma solução perfeita e plug-and-play.
+
+Parabéns! 🎉 **Você completou o processo de integração**! Agora você está pronto para começar a aprender sobre Agentes de IA. Divirta-se!
+
+Continue Aprendendo, permaneça incrível 🤗
diff --git a/units/pt_br/unit1/README.md b/units/pt_br/unit1/README.md
new file mode 100644
index 00000000..a40be38d
--- /dev/null
+++ b/units/pt_br/unit1/README.md
@@ -0,0 +1,19 @@
+# Sumário
+
+Você pode acessar a Unidade 1 em hf.co/learn 👉 neste link
+
+
diff --git a/units/pt_br/unit1/actions.mdx b/units/pt_br/unit1/actions.mdx
new file mode 100644
index 00000000..21f64d3e
--- /dev/null
+++ b/units/pt_br/unit1/actions.mdx
@@ -0,0 +1,124 @@
+# Ações: habilitando o agente a interagir com o ambiente
+
+> [!TIP]
+> Nesta seção, exploramos as etapas concretas que um agente de IA segue para interagir com seu ambiente.
+>
+> Vamos ver como as ações são representadas (usando JSON ou código), por que a abordagem stop and parse é importante e quais tipos de agentes existem.
+
+Ações são as etapas concretas que um **agente de IA executa para interagir com o ambiente**.
+
+Seja buscando informações na web ou controlando um dispositivo físico, cada ação é uma operação deliberada feita pelo agente.
+
+Por exemplo, um agente de suporte ao cliente pode recuperar dados do usuário, sugerir artigos de ajuda ou encaminhar o caso para um atendente humano.
+
+## Tipos de ações de um agente
+
+Há vários tipos de agentes que executam ações de maneiras diferentes:
+
+| Tipo de agente | Descrição |
+|-------------------------|-------------------------------------------------------------------------------------------------|
+| Agente JSON | A ação é especificada em formato JSON. |
+| Agente de código | O agente escreve um bloco de código que será interpretado externamente. |
+| Agente com function calling | Subcategoria do agente JSON, ajustada para gerar uma nova mensagem a cada ação. |
+
+As ações em si podem servir a muitos propósitos:
+
+| Tipo de ação | Descrição |
+|--------------------------|---------------------------------------------------------------------------------------------|
+| Coleta de informações | Fazer buscas na web, consultar bancos de dados ou recuperar documentos. |
+| Uso de ferramentas | Realizar chamadas de API, executar cálculos e rodar código. |
+| Interação com o ambiente | Manipular interfaces digitais ou controlar dispositivos físicos. |
+| Comunicação | Conversar com usuários via chat ou colaborar com outros agentes. |
+
+O LLM lida apenas com texto. Ele descreve a ação que deseja executar e os parâmetros que serão enviados à ferramenta. Para que o agente funcione corretamente, o LLM precisa parar de gerar tokens assim que terminar de definir completamente a ação. Isso devolve o controle para o agente e garante que o resultado seja analisável, seja em JSON, código ou formato de function calling.
+
+## A abordagem stop and parse
+
+Uma estratégia fundamental para implementar ações é a **stop and parse**. Ela garante que a saída do agente seja estruturada e previsível:
+
+1. **Geração em formato estruturado**:
+
+O agente escreve a ação desejada em um formato claro e pré-definido (JSON ou código).
+
+2. **Interromper a geração**:
+
+Assim que o texto que define a ação é emitido, **o LLM interrompe a geração de novos tokens**. Isso evita saídas extra ou equivocadas.
+
+3. **Analisar a saída**:
+
+Um parser externo lê a ação formatada, identifica qual ferramenta chamar e extrai os parâmetros necessários.
+
+Por exemplo, um agente que precisa consultar o clima pode produzir:
+
+
+```json
+Thought: I need to check the current weather for New York.
+Action :
+{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}
+```
+O framework consegue analisar facilmente o nome da função a ser chamada e os argumentos necessários.
+
+Esse formato claro e legível por máquina reduz erros e permite que ferramentas externas processem o comando com precisão.
+
+Observação: agentes com function calling funcionam de forma semelhante, estruturando cada ação para invocar a função certa com os argumentos corretos. Vamos aprofundar nesses agentes em uma unidade futura.
+
+## Agentes de código
+
+Uma abordagem alternativa é usar *agentes de código*.
+A ideia é: **em vez de produzir um objeto JSON simples**, o agente gera um **bloco de código executável — normalmente em uma linguagem de alto nível como Python**.
+
+ +
+Essa abordagem traz várias vantagens:
+
+- **Expressividade:** Código representa naturalmente lógica complexa, com loops, condicionais e funções aninhadas, oferecendo mais flexibilidade que JSON.
+- **Modularidade e reuso:** O código gerado pode incluir funções e módulos reutilizáveis em diferentes ações ou tarefas.
+- **Facilidade de depuração:** Com sintaxe bem definida, erros de código costumam ser mais simples de identificar e corrigir.
+- **Integração direta:** Agentes de código se conectam a bibliotecas e APIs externas, permitindo operações avançadas como processamento de dados ou decisões em tempo real.
+
+Lembre-se de que executar código gerado por LLM pode representar riscos de segurança, desde prompt injection até execução de código malicioso. Por isso, recomenda-se usar frameworks como o `smolagents`, que já incluem proteções padrão. Para saber mais sobre riscos e mitigação, [consulte esta seção dedicada](https://huggingface.co/docs/smolagents/tutorials/secure_code_execution).
+
+Por exemplo, um agente encarregado de buscar informações climáticas poderia gerar este trecho em Python:
+
+```python
+# Code Agent Example: Retrieve Weather Information
+def get_weather(city):
+ import requests
+ api_url = f"https://api.weather.com/v1/location/{city}?apiKey=YOUR_API_KEY"
+ response = requests.get(api_url)
+ if response.status_code == 200:
+ data = response.json()
+ return data.get("weather", "No weather information available")
+ else:
+ return "Error: Unable to fetch weather data."
+
+# Execute the function and prepare the final answer
+result = get_weather("New York")
+final_answer = f"The current weather in New York is: {result}"
+print(final_answer)
+```
+
+Nesse exemplo, o agente:
+
+- Obtém dados climáticos **via chamada de API**,
+- Processa a resposta,
+- E usa `print()` para exibir o resultado final.
+
+Essa abordagem **também segue o stop and parse**, delimitando o bloco de código e sinalizando quando a execução termina (neste caso, imprimindo `final_answer`).
+
+---
+
+Vimos que as ações fazem a ponte entre o raciocínio interno do agente e sua interação com o mundo, executando tarefas claras e estruturadas — seja via JSON, código ou chamadas de função.
+
+Essa execução cuidadosa garante que cada ação seja precisa e pronta para processamento externo por meio do stop and parse. Na próxima seção, vamos explorar Observações para entender como os agentes capturam e integram feedback do ambiente.
+
+Depois disso, estaremos **finalmente prontos para construir nosso primeiro agente!**
+
+After this, we will **finally be ready to build our first Agent!**
+
+
+
+
diff --git a/units/pt_br/unit1/agent-steps-and-structure.mdx b/units/pt_br/unit1/agent-steps-and-structure.mdx
new file mode 100644
index 00000000..381c044f
--- /dev/null
+++ b/units/pt_br/unit1/agent-steps-and-structure.mdx
@@ -0,0 +1,150 @@
+# Entendendo agentes de IA pelo ciclo Pensamento-Ação-Observação
+
+
+
+Essa abordagem traz várias vantagens:
+
+- **Expressividade:** Código representa naturalmente lógica complexa, com loops, condicionais e funções aninhadas, oferecendo mais flexibilidade que JSON.
+- **Modularidade e reuso:** O código gerado pode incluir funções e módulos reutilizáveis em diferentes ações ou tarefas.
+- **Facilidade de depuração:** Com sintaxe bem definida, erros de código costumam ser mais simples de identificar e corrigir.
+- **Integração direta:** Agentes de código se conectam a bibliotecas e APIs externas, permitindo operações avançadas como processamento de dados ou decisões em tempo real.
+
+Lembre-se de que executar código gerado por LLM pode representar riscos de segurança, desde prompt injection até execução de código malicioso. Por isso, recomenda-se usar frameworks como o `smolagents`, que já incluem proteções padrão. Para saber mais sobre riscos e mitigação, [consulte esta seção dedicada](https://huggingface.co/docs/smolagents/tutorials/secure_code_execution).
+
+Por exemplo, um agente encarregado de buscar informações climáticas poderia gerar este trecho em Python:
+
+```python
+# Code Agent Example: Retrieve Weather Information
+def get_weather(city):
+ import requests
+ api_url = f"https://api.weather.com/v1/location/{city}?apiKey=YOUR_API_KEY"
+ response = requests.get(api_url)
+ if response.status_code == 200:
+ data = response.json()
+ return data.get("weather", "No weather information available")
+ else:
+ return "Error: Unable to fetch weather data."
+
+# Execute the function and prepare the final answer
+result = get_weather("New York")
+final_answer = f"The current weather in New York is: {result}"
+print(final_answer)
+```
+
+Nesse exemplo, o agente:
+
+- Obtém dados climáticos **via chamada de API**,
+- Processa a resposta,
+- E usa `print()` para exibir o resultado final.
+
+Essa abordagem **também segue o stop and parse**, delimitando o bloco de código e sinalizando quando a execução termina (neste caso, imprimindo `final_answer`).
+
+---
+
+Vimos que as ações fazem a ponte entre o raciocínio interno do agente e sua interação com o mundo, executando tarefas claras e estruturadas — seja via JSON, código ou chamadas de função.
+
+Essa execução cuidadosa garante que cada ação seja precisa e pronta para processamento externo por meio do stop and parse. Na próxima seção, vamos explorar Observações para entender como os agentes capturam e integram feedback do ambiente.
+
+Depois disso, estaremos **finalmente prontos para construir nosso primeiro agente!**
+
+After this, we will **finally be ready to build our first Agent!**
+
+
+
+
diff --git a/units/pt_br/unit1/agent-steps-and-structure.mdx b/units/pt_br/unit1/agent-steps-and-structure.mdx
new file mode 100644
index 00000000..381c044f
--- /dev/null
+++ b/units/pt_br/unit1/agent-steps-and-structure.mdx
@@ -0,0 +1,150 @@
+# Entendendo agentes de IA pelo ciclo Pensamento-Ação-Observação
+
+ +
+Nas seções anteriores, vimos:
+
+- **Como as ferramentas ficam disponíveis para o agente no system prompt**.
+- **Como agentes de IA são sistemas capazes de “raciocinar”, planejar e interagir com o ambiente**.
+
+Nesta seção, **vamos explorar todo o fluxo de trabalho do agente**, um ciclo que chamamos de Pensamento-Ação-Observação.
+
+Em seguida, vamos detalhar cada uma dessas etapas.
+
+
+## Componentes centrais
+
+O trabalho dos agentes segue um ciclo contínuo: **pensar (Thought) → agir (Act) → observar (Observe)**.
+
+Vamos analisar cada etapa:
+
+1. **Pensamento (Thought):** A parte LLM do agente decide qual deve ser o próximo passo.
+2. **Ação (Action):** O agente executa a ação chamando as ferramentas com os argumentos necessários.
+3. **Observação (Observation):** O modelo reflete sobre a resposta recebida da ferramenta.
+
+## O ciclo Pensamento-Ação-Observação
+
+Esses três componentes funcionam juntos em um laço contínuo. Fazendo uma analogia com programação, o agente roda um **while loop**: o ciclo continua até que o objetivo seja alcançado.
+
+Visualmente, fica assim:
+
+
+
+Nas seções anteriores, vimos:
+
+- **Como as ferramentas ficam disponíveis para o agente no system prompt**.
+- **Como agentes de IA são sistemas capazes de “raciocinar”, planejar e interagir com o ambiente**.
+
+Nesta seção, **vamos explorar todo o fluxo de trabalho do agente**, um ciclo que chamamos de Pensamento-Ação-Observação.
+
+Em seguida, vamos detalhar cada uma dessas etapas.
+
+
+## Componentes centrais
+
+O trabalho dos agentes segue um ciclo contínuo: **pensar (Thought) → agir (Act) → observar (Observe)**.
+
+Vamos analisar cada etapa:
+
+1. **Pensamento (Thought):** A parte LLM do agente decide qual deve ser o próximo passo.
+2. **Ação (Action):** O agente executa a ação chamando as ferramentas com os argumentos necessários.
+3. **Observação (Observation):** O modelo reflete sobre a resposta recebida da ferramenta.
+
+## O ciclo Pensamento-Ação-Observação
+
+Esses três componentes funcionam juntos em um laço contínuo. Fazendo uma analogia com programação, o agente roda um **while loop**: o ciclo continua até que o objetivo seja alcançado.
+
+Visualmente, fica assim:
+
+ +
+Em muitos frameworks de agentes, **as regras e orientações ficam embutidas diretamente no system prompt**, garantindo que cada ciclo siga a lógica estabelecida.
+
+Numa versão simplificada, o system prompt pode ser assim:
+
+
+
+Em muitos frameworks de agentes, **as regras e orientações ficam embutidas diretamente no system prompt**, garantindo que cada ciclo siga a lógica estabelecida.
+
+Numa versão simplificada, o system prompt pode ser assim:
+
+ +
+Na mensagem de sistema definimos:
+
+- O *comportamento do agente*;
+- As *ferramentas às quais o agente tem acesso* (como vimos na seção anterior);
+- O *ciclo Pensamento-Ação-Observação*, incorporado nas instruções para o LLM.
+
+Vamos ver um exemplo para entender o processo antes de detalhar cada etapa.
+
+## Alfred, o agente do clima
+
+Apresentamos Alfred, o agente de clima.
+
+Um usuário pergunta: “Como está o tempo agora em Nova York?”
+
+
+
+Na mensagem de sistema definimos:
+
+- O *comportamento do agente*;
+- As *ferramentas às quais o agente tem acesso* (como vimos na seção anterior);
+- O *ciclo Pensamento-Ação-Observação*, incorporado nas instruções para o LLM.
+
+Vamos ver um exemplo para entender o processo antes de detalhar cada etapa.
+
+## Alfred, o agente do clima
+
+Apresentamos Alfred, o agente de clima.
+
+Um usuário pergunta: “Como está o tempo agora em Nova York?”
+
+ +
+O trabalho de Alfred é responder usando uma ferramenta de API de clima.
+
+Veja como o ciclo acontece:
+
+### Pensamento
+
+**Raciocínio interno:**
+
+Ao receber a pergunta, Alfred pode pensar:
+
+*"O usuário precisa das condições climáticas atuais de Nova York. Tenho uma ferramenta que busca dados de clima. Primeiro preciso chamar a API para obter as informações atualizadas."*
+
+Aqui, o agente divide o problema em etapas: primeiro coleta os dados necessários.
+
+
+
+O trabalho de Alfred é responder usando uma ferramenta de API de clima.
+
+Veja como o ciclo acontece:
+
+### Pensamento
+
+**Raciocínio interno:**
+
+Ao receber a pergunta, Alfred pode pensar:
+
+*"O usuário precisa das condições climáticas atuais de Nova York. Tenho uma ferramenta que busca dados de clima. Primeiro preciso chamar a API para obter as informações atualizadas."*
+
+Aqui, o agente divide o problema em etapas: primeiro coleta os dados necessários.
+
+ +
+### Ação
+
+**Uso de ferramenta:**
+
+Com base nesse raciocínio e sabendo que existe uma ferramenta `get_weather`, Alfred prepara um comando em JSON chamando a API de clima. Por exemplo:
+
+Thought: I need to check the current weather for New York.
+
+ ```
+ {
+ "action": "get_weather",
+ "action_input": {
+ "location": "New York"
+ }
+ }
+ ```
+
+Aqui, a ação informa qual ferramenta usar (`get_weather`) e o parâmetro a ser enviado (`"location": "New York"`).
+
+
+
+### Ação
+
+**Uso de ferramenta:**
+
+Com base nesse raciocínio e sabendo que existe uma ferramenta `get_weather`, Alfred prepara um comando em JSON chamando a API de clima. Por exemplo:
+
+Thought: I need to check the current weather for New York.
+
+ ```
+ {
+ "action": "get_weather",
+ "action_input": {
+ "location": "New York"
+ }
+ }
+ ```
+
+Aqui, a ação informa qual ferramenta usar (`get_weather`) e o parâmetro a ser enviado (`"location": "New York"`).
+
+ +
+### Observação
+
+**Retorno do ambiente:**
+
+Depois da chamada, Alfred recebe uma observação. Pode ser a resposta direta da API, por exemplo:
+
+*"Clima atual em Nova York: parcialmente nublado, 15 °C, umidade de 60%."*
+
+
+
+### Observação
+
+**Retorno do ambiente:**
+
+Depois da chamada, Alfred recebe uma observação. Pode ser a resposta direta da API, por exemplo:
+
+*"Clima atual em Nova York: parcialmente nublado, 15 °C, umidade de 60%."*
+
+ +
+Essa observação é adicionada ao prompt como contexto extra. Ela funciona como um feedback real, confirmando se a ação deu certo e trazendo os detalhes necessários.
+
+
+### Pensamento atualizado
+
+**Reflexão:**
+
+Com a observação em mãos, Alfred atualiza seu raciocínio interno:
+
+*"Agora que já tenho os dados, posso preparar uma resposta para o usuário."*
+
+
+
+Essa observação é adicionada ao prompt como contexto extra. Ela funciona como um feedback real, confirmando se a ação deu certo e trazendo os detalhes necessários.
+
+
+### Pensamento atualizado
+
+**Reflexão:**
+
+Com a observação em mãos, Alfred atualiza seu raciocínio interno:
+
+*"Agora que já tenho os dados, posso preparar uma resposta para o usuário."*
+
+ +
+
+### Ação final
+
+Alfred então gera a resposta final no formato definido:
+
+Thought: I have the weather data now. The current weather in New York is partly cloudy with a temperature of 15°C and 60% humidity."
+
+Final answer : The current weather in New York is partly cloudy with a temperature of 15°C and 60% humidity.
+
+A ação final devolve a resposta ao usuário, encerrando o ciclo.
+
+
+
+
+
+### Ação final
+
+Alfred então gera a resposta final no formato definido:
+
+Thought: I have the weather data now. The current weather in New York is partly cloudy with a temperature of 15°C and 60% humidity."
+
+Final answer : The current weather in New York is partly cloudy with a temperature of 15°C and 60% humidity.
+
+A ação final devolve a resposta ao usuário, encerrando o ciclo.
+
+
+ +
+
+O que observamos nesse exemplo:
+
+- **Agentes iteram até cumprir o objetivo:**
+
+**O processo de Alfred é cíclico**. Ele começa com um pensamento, age chamando uma ferramenta e observa o resultado. Se a observação mostrasse erro ou dados incompletos, Alfred repetiria o ciclo para corrigir o caminho.
+
+- **Integração com ferramentas:**
+
+A capacidade de chamar ferramentas (como uma API de clima) permite que Alfred vá **além do conhecimento estático e busque dados em tempo real**, algo essencial para muitos agentes.
+
+- **Adaptação dinâmica:**
+
+Cada ciclo permite incorporar novas informações (observações) ao raciocínio (pensamento), garantindo uma resposta bem embasada e precisa.
+
+Esse exemplo ilustra o conceito central do *ciclo ReAct* (que veremos na próxima seção): **a interação entre Pensamento, Ação e Observação capacita agentes de IA a resolver tarefas complexas de forma iterativa**.
+
+Ao entender e aplicar esses princípios, você pode projetar agentes que não apenas raciocinam sobre suas tarefas, mas também **utilizam ferramentas externas com eficácia**, refinando a saída com base no feedback do ambiente.
+
+---
+
+Agora vamos nos aprofundar em Pensamento, Ação e Observação como etapas individuais do processo.
diff --git a/units/pt_br/unit1/conclusion.mdx b/units/pt_br/unit1/conclusion.mdx
new file mode 100644
index 00000000..72578ef9
--- /dev/null
+++ b/units/pt_br/unit1/conclusion.mdx
@@ -0,0 +1,19 @@
+# Conclusão [[conclusion]]
+
+Parabéns por terminar esta primeira unidade 🥳
+
+Você acabou de **dominar os fundamentos de Agentes** e criou o seu primeiro Agente de IA!
+
+É **normal ainda se sentir confuso com alguns conceitos**. Agentes são um assunto complexo; leva tempo para absorver tudo.
+
+**Reserve um tempo para consolidar o conteúdo** antes de seguir em frente. É essencial dominar essas bases antes de entrar nas partes mais divertidas.
+
+E, se você passar no quiz, não esqueça de pegar seu certificado 🎓 👉 [neste link](https://huggingface.co/spaces/agents-course/unit1-certification-app)
+
+
+
+
+O que observamos nesse exemplo:
+
+- **Agentes iteram até cumprir o objetivo:**
+
+**O processo de Alfred é cíclico**. Ele começa com um pensamento, age chamando uma ferramenta e observa o resultado. Se a observação mostrasse erro ou dados incompletos, Alfred repetiria o ciclo para corrigir o caminho.
+
+- **Integração com ferramentas:**
+
+A capacidade de chamar ferramentas (como uma API de clima) permite que Alfred vá **além do conhecimento estático e busque dados em tempo real**, algo essencial para muitos agentes.
+
+- **Adaptação dinâmica:**
+
+Cada ciclo permite incorporar novas informações (observações) ao raciocínio (pensamento), garantindo uma resposta bem embasada e precisa.
+
+Esse exemplo ilustra o conceito central do *ciclo ReAct* (que veremos na próxima seção): **a interação entre Pensamento, Ação e Observação capacita agentes de IA a resolver tarefas complexas de forma iterativa**.
+
+Ao entender e aplicar esses princípios, você pode projetar agentes que não apenas raciocinam sobre suas tarefas, mas também **utilizam ferramentas externas com eficácia**, refinando a saída com base no feedback do ambiente.
+
+---
+
+Agora vamos nos aprofundar em Pensamento, Ação e Observação como etapas individuais do processo.
diff --git a/units/pt_br/unit1/conclusion.mdx b/units/pt_br/unit1/conclusion.mdx
new file mode 100644
index 00000000..72578ef9
--- /dev/null
+++ b/units/pt_br/unit1/conclusion.mdx
@@ -0,0 +1,19 @@
+# Conclusão [[conclusion]]
+
+Parabéns por terminar esta primeira unidade 🥳
+
+Você acabou de **dominar os fundamentos de Agentes** e criou o seu primeiro Agente de IA!
+
+É **normal ainda se sentir confuso com alguns conceitos**. Agentes são um assunto complexo; leva tempo para absorver tudo.
+
+**Reserve um tempo para consolidar o conteúdo** antes de seguir em frente. É essencial dominar essas bases antes de entrar nas partes mais divertidas.
+
+E, se você passar no quiz, não esqueça de pegar seu certificado 🎓 👉 [neste link](https://huggingface.co/spaces/agents-course/unit1-certification-app)
+
+ +
+Na próxima unidade bônus, você vai aprender **a fazer fine-tuning de um agente para executar function calling (ou seja, chamar ferramentas com base no prompt do usuário)**.
+
+Por fim, adoraríamos **ouvir o que você achou do curso e como podemos melhorá-lo**. Se tiver feedback, por favor 👉 [preencha este formulário](https://docs.google.com/forms/d/e/1FAIpQLSe9VaONn0eglax0uTwi29rIn4tM7H2sYmmybmG5jJNlE5v0xA/viewform?usp=dialog)
+
+### Continue aprendendo e sendo incrível 🤗
diff --git a/units/pt_br/unit1/dummy-agent-library.mdx b/units/pt_br/unit1/dummy-agent-library.mdx
new file mode 100644
index 00000000..bf7b174d
--- /dev/null
+++ b/units/pt_br/unit1/dummy-agent-library.mdx
@@ -0,0 +1,321 @@
+# Biblioteca de Agente Fictícia
+
+
+
+Na próxima unidade bônus, você vai aprender **a fazer fine-tuning de um agente para executar function calling (ou seja, chamar ferramentas com base no prompt do usuário)**.
+
+Por fim, adoraríamos **ouvir o que você achou do curso e como podemos melhorá-lo**. Se tiver feedback, por favor 👉 [preencha este formulário](https://docs.google.com/forms/d/e/1FAIpQLSe9VaONn0eglax0uTwi29rIn4tM7H2sYmmybmG5jJNlE5v0xA/viewform?usp=dialog)
+
+### Continue aprendendo e sendo incrível 🤗
diff --git a/units/pt_br/unit1/dummy-agent-library.mdx b/units/pt_br/unit1/dummy-agent-library.mdx
new file mode 100644
index 00000000..bf7b174d
--- /dev/null
+++ b/units/pt_br/unit1/dummy-agent-library.mdx
@@ -0,0 +1,321 @@
+# Biblioteca de Agente Fictícia
+
+ +
+Este curso é agnóstico de framework porque queremos **focar nos conceitos de agentes de IA e evitar ficar preso a detalhes específicos de uma biblioteca**.
+
+Também desejamos que você possa aplicar os conceitos aprendidos nos seus próprios projetos, usando o framework que preferir.
+
+Por isso, nesta Unidade 1 usaremos uma biblioteca de agente fictícia e uma API serverless simples para acessar nosso mecanismo de LLM.
+
+Provavelmente você não usaria isso em produção, mas é um **ótimo ponto de partida para entender como os agentes funcionam**.
+
+Depois desta seção, você estará pronto para **criar um agente simples** usando `smolagents`.
+
+Nas próximas unidades, trabalharemos também com outras bibliotecas de agentes de IA como `LangGraph` e `LlamaIndex`.
+
+Para manter tudo simples, vamos utilizar uma função Python como Ferramenta e Agente.
+
+Usaremos pacotes internos do Python como `datetime` e `os`, permitindo que você experimente em qualquer ambiente.
+
+Você pode seguir o processo [neste notebook](https://huggingface.co/agents-course/notebooks/blob/main/unit1/dummy_agent_library.ipynb) e **executar o código você mesmo**.
+
+## Serverless API
+
+No ecossistema Hugging Face, existe um recurso conveniente chamado Serverless API que permite rodar inferência em muitos modelos sem precisar instalar nada ou fazer deploy.
+
+```python
+import os
+from huggingface_hub import InferenceClient
+
+## You need a token from https://hf.co/settings/tokens, ensure that you select 'read' as the token type. If you run this on Google Colab, you can set it up in the "settings" tab under "secrets". Make sure to call it "HF_TOKEN"
+# HF_TOKEN = os.environ.get("HF_TOKEN")
+
+client = InferenceClient(model="meta-llama/Llama-4-Scout-17B-16E-Instruct")
+```
+
+Usamos o método `chat`, pois ele aplica templates de conversa de forma prática e confiável:
+
+```python
+output = client.chat.completions.create(
+ messages=[
+ {"role": "user", "content": "The capital of France is"},
+ ],
+ stream=False,
+ max_tokens=1024,
+)
+print(output.choices[0].message.content)
+```
+
+output:
+
+```
+Paris.
+```
+
+O método `chat` é o RECOMENDADO para garantir uma transição suave entre modelos.
+
+## Agente fictício
+
+Nas seções anteriores, vimos que o núcleo de uma biblioteca de agentes é adicionar informações ao system prompt.
+
+Este system prompt é um pouco mais complexo do que o que vimos antes, mas já contém:
+
+1. **Informações sobre as ferramentas**
+2. **Instruções do ciclo** (Pensamento → Ação → Observação)
+
+```python
+# This system prompt is a bit more complex and actually contains the function description already appended.
+# Here we suppose that the textual description of the tools has already been appended.
+
+SYSTEM_PROMPT = """Answer the following questions as best you can. You have access to the following tools:
+
+get_weather: Get the current weather in a given location
+
+The way you use the tools is by specifying a json blob.
+Specifically, this json should have an `action` key (with the name of the tool to use) and an `action_input` key (with the input to the tool going here).
+
+The only values that should be in the "action" field are:
+get_weather: Get the current weather in a given location, args: {"location": {"type": "string"}}
+example use :
+
+{{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}}
+
+
+ALWAYS use the following format:
+
+Question: the input question you must answer
+Thought: you should always think about one action to take. Only one action at a time in this format:
+Action:
+
+$JSON_BLOB (inside markdown cell)
+
+Observation: the result of the action. This Observation is unique, complete, and the source of truth.
+... (this Thought/Action/Observation can repeat N times, you should take several steps when needed. The $JSON_BLOB must be formatted as markdown and only use a SINGLE action at a time.)
+
+You must always end your output with the following format:
+
+Thought: I now know the final answer
+Final Answer: the final answer to the original input question
+
+Now begin! Reminder to ALWAYS use the exact characters `Final Answer:` when you provide a definitive answer. """
+```
+
+Precisamos adicionar a instrução do usuário depois do system prompt. Isso acontece dentro do método `chat`, como mostrado abaixo:
+
+```python
+messages = [
+ {"role": "system", "content": SYSTEM_PROMPT},
+ {"role": "user", "content": "What's the weather in London?"},
+]
+
+print(messages)
+```
+
+O prompt agora é:
+
+```
+<|begin_of_text|><|start_header_id|>system<|end_header_id|>
+Answer the following questions as best you can. You have access to the following tools:
+
+get_weather: Get the current weather in a given location
+
+The way you use the tools is by specifying a json blob.
+Specifically, this json should have an `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
+
+The only values that should be in the "action" field are:
+get_weather: Get the current weather in a given location, args: {"location": {"type": "string"}}
+example use :
+
+{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}
+
+
+ALWAYS use the following format:
+
+Question: the input question you must answer
+Thought: you should always think about one action to take. Only one action at a time in this format:
+Action:
+
+$JSON_BLOB (inside markdown cell)
+
+Observation: the result of the action. This Observation is unique, complete, and the source of truth.
+... (this Thought/Action/Observation can repeat N times, you should take several steps when needed. The $JSON_BLOB must be formatted as markdown and only use a SINGLE action at a time.)
+
+You must always end your output with the following format:
+
+Thought: I now know the final answer
+Final Answer: the final answer to the original input question
+
+Now begin! Reminder to ALWAYS use the exact characters `Final Answer:` when you provide a definitive answer.
+<|eot_id|><|start_header_id|>user<|end_header_id|>
+What's the weather in London?
+<|eot_id|>
+```
+
+---
+
+Agora, o output:
+
+```python
+output = client.chat.completions.create(
+ messages=messages,
+ max_tokens=200,
+)
+
+print(output.choices[0].message.content)
+```
+
+```
+Thought: To answer the question, I need to get the current weather in London.
+Action:
+
+ ```json
+ {
+ "action": "get_weather",
+ "action_input": {"location": {"type": "string", "value": "London"}}
+ }
+ ```
+
+Observation: The weather in London is cloudy with a high of 15°C and a low of 8°C today.
+Thought: The question asks for the weather in London. I now know the weather in London from the observation.
+Final Answer: The weather in London is cloudy with a high of 15°C and a low of 8°C today.
+```
+
+Isso parece ótimo — o modelo exibiu um processo estruturado com o nome da ação e argumentos correspondentes.
+
+Essa é a essência do que bibliotecas de agentes como `LangChain`, `smolagents` ou `LlamaIndex` fornecem. Elas automatizam essa sequência e o endpoint selecionado executa a ação apropriada.
+
+No entanto, ainda estamos num cenário fictício e a resposta acima foi alucinação do modelo — na prática, o agente deve obter a resposta do endpoint que chamamos. Vamos corrigir isso com o mesmo processo:
+
+```python
+# The answer was hallucinated by the model. We need to stop to actually execute the function!
+output = client.chat.completions.create(
+ messages=messages,
+ max_tokens=150,
+ stop=["Observation:"] # Let's stop before any actual function is called
+)
+
+print(output.choices[0].message.content)
+```
+
+output:
+
+````
+Thought: To answer the question, I need to get the current weather in London.
+Action:
+```
+{
+ "action": "get_weather",
+ "action_input": {"location": "London"}
+}
+
+
+````
+
+Bem melhor!
+
+Vamos criar uma **função fictícia de clima**. Em um cenário real, você chamaria uma API.
+
+```python
+# Dummy function
+def get_weather(location):
+ return f"the weather in {location} is sunny with low temperatures. \n"
+
+get_weather('London')
+```
+
+output:
+
+```
+'the weather in London is sunny with low temperatures. \n'
+```
+
+Agora, vamos concatenar o system prompt, o prompt base, a conclusão até a execução da função e o resultado como Observation para retomar a geração.
+
+```python
+messages=[
+ {"role": "system", "content": SYSTEM_PROMPT},
+ {"role": "user", "content": "What's the weather in London ?"},
+ {"role": "assistant", "content": output.choices[0].message.content + "Observation:\n" + get_weather('London')},
+]
+
+output = client.chat.completions.create(
+ messages=messages,
+ stream=False,
+ max_tokens=200,
+)
+
+print(output.choices[0].message.content)
+```
+
+Prompt resultante:
+
+```text
+<|begin_of_text|><|start_header_id|>system<|end_header_id|>
+Answer the following questions as best you can. You have access to the following tools:
+
+get_weather: Get the current weather in a given location
+
+The way you use the tools is by specifying a json blob.
+Specifically, this json should have an `action` key (with the name of the tool to use) and an `action_input` key (with the input to the tool going here).
+
+The only values that should be in the "action" field are:
+get_weather: Get the current weather in a given location, args: {"location": {"type": "string"}}
+example use :
+
+{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}
+
+ALWAYS use the following format:
+
+Question: the input question you must answer
+Thought: you should always think about one action to take. Only one action at a time in this format:
+Action:
+
+$JSON_BLOB (inside markdown cell)
+
+Observation: the result of the action. This Observation is unique, complete, and the source of truth.
+... (this Thought/Action/Observation can repeat N times, you should take several steps when needed. The $JSON_BLOB must be formatted as markdown and only use a SINGLE action at a time.)
+
+You must always end your output with the following format:
+
+Thought: I now know the final answer
+Final Answer: the final answer to the original input question
+
+Now begin! Reminder to ALWAYS use the exact characters `Final Answer:` when you provide a definitive answer.
+<|eot_id|><|start_header_id|>user<|end_header_id|>
+What's the weather in London ?
+<|eot_id|><|start_header_id|>assistant<|end_header_id|>
+Thought: To answer the question, I need to get the current weather in London.
+Action:
+
+{
+ "action": "get_weather",
+ "action_input": {"location": "London"}
+}
+
+Observation:
+the weather in London is sunny with low temperatures.
+
+<|eot_id|>
+```
+
+Output:
+
+```
+Final Answer: The weather in London is sunny with low temperatures.
+```
+
+---
+
+Vimos como criar agentes do zero apenas com código Python — e **como esse processo pode ser trabalhoso**. Felizmente, bibliotecas de agentes automatizam grande parte do esforço.
+
+Agora estamos prontos para **criar nosso primeiro agente “de verdade”** usando a biblioteca `smolagents`.
diff --git a/units/pt_br/unit1/final-quiz.mdx b/units/pt_br/unit1/final-quiz.mdx
new file mode 100644
index 00000000..c03dfb05
--- /dev/null
+++ b/units/pt_br/unit1/final-quiz.mdx
@@ -0,0 +1,144 @@
+# Quiz Final – Fundamentos de Agentes
+
+Este questionário opcional e sem nota ajuda a consolidar os conceitos vistos na Unidade 1. Boa sorte! 🎉
+
+---
+
+### Q1: O que é um agente de IA?
+Escolha a alternativa que melhor descreve a definição de um agente no contexto deste curso.
+
+
+
+Este curso é agnóstico de framework porque queremos **focar nos conceitos de agentes de IA e evitar ficar preso a detalhes específicos de uma biblioteca**.
+
+Também desejamos que você possa aplicar os conceitos aprendidos nos seus próprios projetos, usando o framework que preferir.
+
+Por isso, nesta Unidade 1 usaremos uma biblioteca de agente fictícia e uma API serverless simples para acessar nosso mecanismo de LLM.
+
+Provavelmente você não usaria isso em produção, mas é um **ótimo ponto de partida para entender como os agentes funcionam**.
+
+Depois desta seção, você estará pronto para **criar um agente simples** usando `smolagents`.
+
+Nas próximas unidades, trabalharemos também com outras bibliotecas de agentes de IA como `LangGraph` e `LlamaIndex`.
+
+Para manter tudo simples, vamos utilizar uma função Python como Ferramenta e Agente.
+
+Usaremos pacotes internos do Python como `datetime` e `os`, permitindo que você experimente em qualquer ambiente.
+
+Você pode seguir o processo [neste notebook](https://huggingface.co/agents-course/notebooks/blob/main/unit1/dummy_agent_library.ipynb) e **executar o código você mesmo**.
+
+## Serverless API
+
+No ecossistema Hugging Face, existe um recurso conveniente chamado Serverless API que permite rodar inferência em muitos modelos sem precisar instalar nada ou fazer deploy.
+
+```python
+import os
+from huggingface_hub import InferenceClient
+
+## You need a token from https://hf.co/settings/tokens, ensure that you select 'read' as the token type. If you run this on Google Colab, you can set it up in the "settings" tab under "secrets". Make sure to call it "HF_TOKEN"
+# HF_TOKEN = os.environ.get("HF_TOKEN")
+
+client = InferenceClient(model="meta-llama/Llama-4-Scout-17B-16E-Instruct")
+```
+
+Usamos o método `chat`, pois ele aplica templates de conversa de forma prática e confiável:
+
+```python
+output = client.chat.completions.create(
+ messages=[
+ {"role": "user", "content": "The capital of France is"},
+ ],
+ stream=False,
+ max_tokens=1024,
+)
+print(output.choices[0].message.content)
+```
+
+output:
+
+```
+Paris.
+```
+
+O método `chat` é o RECOMENDADO para garantir uma transição suave entre modelos.
+
+## Agente fictício
+
+Nas seções anteriores, vimos que o núcleo de uma biblioteca de agentes é adicionar informações ao system prompt.
+
+Este system prompt é um pouco mais complexo do que o que vimos antes, mas já contém:
+
+1. **Informações sobre as ferramentas**
+2. **Instruções do ciclo** (Pensamento → Ação → Observação)
+
+```python
+# This system prompt is a bit more complex and actually contains the function description already appended.
+# Here we suppose that the textual description of the tools has already been appended.
+
+SYSTEM_PROMPT = """Answer the following questions as best you can. You have access to the following tools:
+
+get_weather: Get the current weather in a given location
+
+The way you use the tools is by specifying a json blob.
+Specifically, this json should have an `action` key (with the name of the tool to use) and an `action_input` key (with the input to the tool going here).
+
+The only values that should be in the "action" field are:
+get_weather: Get the current weather in a given location, args: {"location": {"type": "string"}}
+example use :
+
+{{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}}
+
+
+ALWAYS use the following format:
+
+Question: the input question you must answer
+Thought: you should always think about one action to take. Only one action at a time in this format:
+Action:
+
+$JSON_BLOB (inside markdown cell)
+
+Observation: the result of the action. This Observation is unique, complete, and the source of truth.
+... (this Thought/Action/Observation can repeat N times, you should take several steps when needed. The $JSON_BLOB must be formatted as markdown and only use a SINGLE action at a time.)
+
+You must always end your output with the following format:
+
+Thought: I now know the final answer
+Final Answer: the final answer to the original input question
+
+Now begin! Reminder to ALWAYS use the exact characters `Final Answer:` when you provide a definitive answer. """
+```
+
+Precisamos adicionar a instrução do usuário depois do system prompt. Isso acontece dentro do método `chat`, como mostrado abaixo:
+
+```python
+messages = [
+ {"role": "system", "content": SYSTEM_PROMPT},
+ {"role": "user", "content": "What's the weather in London?"},
+]
+
+print(messages)
+```
+
+O prompt agora é:
+
+```
+<|begin_of_text|><|start_header_id|>system<|end_header_id|>
+Answer the following questions as best you can. You have access to the following tools:
+
+get_weather: Get the current weather in a given location
+
+The way you use the tools is by specifying a json blob.
+Specifically, this json should have an `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
+
+The only values that should be in the "action" field are:
+get_weather: Get the current weather in a given location, args: {"location": {"type": "string"}}
+example use :
+
+{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}
+
+
+ALWAYS use the following format:
+
+Question: the input question you must answer
+Thought: you should always think about one action to take. Only one action at a time in this format:
+Action:
+
+$JSON_BLOB (inside markdown cell)
+
+Observation: the result of the action. This Observation is unique, complete, and the source of truth.
+... (this Thought/Action/Observation can repeat N times, you should take several steps when needed. The $JSON_BLOB must be formatted as markdown and only use a SINGLE action at a time.)
+
+You must always end your output with the following format:
+
+Thought: I now know the final answer
+Final Answer: the final answer to the original input question
+
+Now begin! Reminder to ALWAYS use the exact characters `Final Answer:` when you provide a definitive answer.
+<|eot_id|><|start_header_id|>user<|end_header_id|>
+What's the weather in London?
+<|eot_id|>
+```
+
+---
+
+Agora, o output:
+
+```python
+output = client.chat.completions.create(
+ messages=messages,
+ max_tokens=200,
+)
+
+print(output.choices[0].message.content)
+```
+
+```
+Thought: To answer the question, I need to get the current weather in London.
+Action:
+
+ ```json
+ {
+ "action": "get_weather",
+ "action_input": {"location": {"type": "string", "value": "London"}}
+ }
+ ```
+
+Observation: The weather in London is cloudy with a high of 15°C and a low of 8°C today.
+Thought: The question asks for the weather in London. I now know the weather in London from the observation.
+Final Answer: The weather in London is cloudy with a high of 15°C and a low of 8°C today.
+```
+
+Isso parece ótimo — o modelo exibiu um processo estruturado com o nome da ação e argumentos correspondentes.
+
+Essa é a essência do que bibliotecas de agentes como `LangChain`, `smolagents` ou `LlamaIndex` fornecem. Elas automatizam essa sequência e o endpoint selecionado executa a ação apropriada.
+
+No entanto, ainda estamos num cenário fictício e a resposta acima foi alucinação do modelo — na prática, o agente deve obter a resposta do endpoint que chamamos. Vamos corrigir isso com o mesmo processo:
+
+```python
+# The answer was hallucinated by the model. We need to stop to actually execute the function!
+output = client.chat.completions.create(
+ messages=messages,
+ max_tokens=150,
+ stop=["Observation:"] # Let's stop before any actual function is called
+)
+
+print(output.choices[0].message.content)
+```
+
+output:
+
+````
+Thought: To answer the question, I need to get the current weather in London.
+Action:
+```
+{
+ "action": "get_weather",
+ "action_input": {"location": "London"}
+}
+
+
+````
+
+Bem melhor!
+
+Vamos criar uma **função fictícia de clima**. Em um cenário real, você chamaria uma API.
+
+```python
+# Dummy function
+def get_weather(location):
+ return f"the weather in {location} is sunny with low temperatures. \n"
+
+get_weather('London')
+```
+
+output:
+
+```
+'the weather in London is sunny with low temperatures. \n'
+```
+
+Agora, vamos concatenar o system prompt, o prompt base, a conclusão até a execução da função e o resultado como Observation para retomar a geração.
+
+```python
+messages=[
+ {"role": "system", "content": SYSTEM_PROMPT},
+ {"role": "user", "content": "What's the weather in London ?"},
+ {"role": "assistant", "content": output.choices[0].message.content + "Observation:\n" + get_weather('London')},
+]
+
+output = client.chat.completions.create(
+ messages=messages,
+ stream=False,
+ max_tokens=200,
+)
+
+print(output.choices[0].message.content)
+```
+
+Prompt resultante:
+
+```text
+<|begin_of_text|><|start_header_id|>system<|end_header_id|>
+Answer the following questions as best you can. You have access to the following tools:
+
+get_weather: Get the current weather in a given location
+
+The way you use the tools is by specifying a json blob.
+Specifically, this json should have an `action` key (with the name of the tool to use) and an `action_input` key (with the input to the tool going here).
+
+The only values that should be in the "action" field are:
+get_weather: Get the current weather in a given location, args: {"location": {"type": "string"}}
+example use :
+
+{
+ "action": "get_weather",
+ "action_input": {"location": "New York"}
+}
+
+ALWAYS use the following format:
+
+Question: the input question you must answer
+Thought: you should always think about one action to take. Only one action at a time in this format:
+Action:
+
+$JSON_BLOB (inside markdown cell)
+
+Observation: the result of the action. This Observation is unique, complete, and the source of truth.
+... (this Thought/Action/Observation can repeat N times, you should take several steps when needed. The $JSON_BLOB must be formatted as markdown and only use a SINGLE action at a time.)
+
+You must always end your output with the following format:
+
+Thought: I now know the final answer
+Final Answer: the final answer to the original input question
+
+Now begin! Reminder to ALWAYS use the exact characters `Final Answer:` when you provide a definitive answer.
+<|eot_id|><|start_header_id|>user<|end_header_id|>
+What's the weather in London ?
+<|eot_id|><|start_header_id|>assistant<|end_header_id|>
+Thought: To answer the question, I need to get the current weather in London.
+Action:
+
+{
+ "action": "get_weather",
+ "action_input": {"location": "London"}
+}
+
+Observation:
+the weather in London is sunny with low temperatures.
+
+<|eot_id|>
+```
+
+Output:
+
+```
+Final Answer: The weather in London is sunny with low temperatures.
+```
+
+---
+
+Vimos como criar agentes do zero apenas com código Python — e **como esse processo pode ser trabalhoso**. Felizmente, bibliotecas de agentes automatizam grande parte do esforço.
+
+Agora estamos prontos para **criar nosso primeiro agente “de verdade”** usando a biblioteca `smolagents`.
diff --git a/units/pt_br/unit1/final-quiz.mdx b/units/pt_br/unit1/final-quiz.mdx
new file mode 100644
index 00000000..c03dfb05
--- /dev/null
+++ b/units/pt_br/unit1/final-quiz.mdx
@@ -0,0 +1,144 @@
+# Quiz Final – Fundamentos de Agentes
+
+Este questionário opcional e sem nota ajuda a consolidar os conceitos vistos na Unidade 1. Boa sorte! 🎉
+
+---
+
+### Q1: O que é um agente de IA?
+Escolha a alternativa que melhor descreve a definição de um agente no contexto deste curso.
+
+ +
+Bem-vindo a esta primeira unidade, onde **você vai construir uma base sólida nos fundamentos dos Agentes de IA**, incluindo:
+
+- **Compreender o que são Agentes**
+ - O que é um Agente e como ele funciona?
+ - Como os Agentes tomam decisões usando raciocínio e planejamento?
+
+- **O papel dos LLMs (Large Language Models) em Agentes**
+ - Como os LLMs atuam como o “cérebro” de um agente.
+ - Como os LLMs estruturam conversas por meio do sistema de mensagens.
+
+- **Ferramentas e ações**
+ - Como os agentes usam ferramentas externas para interagir com o ambiente.
+ - Como construir e integrar ferramentas ao seu agente.
+
+- **O fluxo de trabalho do agente:**
+ - *Pensar* → *Agir* → *Observar*.
+
+Depois de explorar esses tópicos, **você vai construir o seu primeiro agente** usando `smolagents`!
+
+Seu agente, chamado Alfred, cuidará de uma tarefa simples e mostrará como aplicar esses conceitos na prática.
+
+Você também aprenderá a **publicar seu agente no Hugging Face Spaces**, para compartilhá-lo com amigos e colegas.
+
+Por fim, ao final desta unidade, haverá um quiz. Ao passar, você **ganha sua primeira certificação do curso**: o 🎓 Certificado de Fundamentos de Agentes.
+
+
+
+Esta unidade é o **pontapé inicial essencial**, preparando o terreno para entender agentes antes de partir para tópicos mais avançados.
+
+
+
+Bem-vindo a esta primeira unidade, onde **você vai construir uma base sólida nos fundamentos dos Agentes de IA**, incluindo:
+
+- **Compreender o que são Agentes**
+ - O que é um Agente e como ele funciona?
+ - Como os Agentes tomam decisões usando raciocínio e planejamento?
+
+- **O papel dos LLMs (Large Language Models) em Agentes**
+ - Como os LLMs atuam como o “cérebro” de um agente.
+ - Como os LLMs estruturam conversas por meio do sistema de mensagens.
+
+- **Ferramentas e ações**
+ - Como os agentes usam ferramentas externas para interagir com o ambiente.
+ - Como construir e integrar ferramentas ao seu agente.
+
+- **O fluxo de trabalho do agente:**
+ - *Pensar* → *Agir* → *Observar*.
+
+Depois de explorar esses tópicos, **você vai construir o seu primeiro agente** usando `smolagents`!
+
+Seu agente, chamado Alfred, cuidará de uma tarefa simples e mostrará como aplicar esses conceitos na prática.
+
+Você também aprenderá a **publicar seu agente no Hugging Face Spaces**, para compartilhá-lo com amigos e colegas.
+
+Por fim, ao final desta unidade, haverá um quiz. Ao passar, você **ganha sua primeira certificação do curso**: o 🎓 Certificado de Fundamentos de Agentes.
+
+
+
+Esta unidade é o **pontapé inicial essencial**, preparando o terreno para entender agentes antes de partir para tópicos mais avançados.
+
+ +
+É uma unidade extensa, então **vá com calma** e volte a estas seções sempre que precisar.
+
+Pronto? Vamos mergulhar nesse universo! 🚀
diff --git a/units/pt_br/unit1/messages-and-special-tokens.mdx b/units/pt_br/unit1/messages-and-special-tokens.mdx
new file mode 100644
index 00000000..0f308490
--- /dev/null
+++ b/units/pt_br/unit1/messages-and-special-tokens.mdx
@@ -0,0 +1,226 @@
+# Mensagens e Tokens Especiais
+
+Agora que entendemos como os LLMs funcionam, vamos ver **como eles estruturam suas gerações por meio de templates de chat**.
+
+Assim como no ChatGPT, os usuários normalmente interagem com agentes por uma interface de bate‑papo, então precisamos compreender como os LLMs administram essas conversas.
+
+> **P**: Mas… quando converso com o ChatGPT ou com o HuggingChat, são várias mensagens, não um único prompt!
+>
+> **R**: Verdade! Porém, isso é apenas uma abstração da interface. Antes de chegar ao LLM, todas as mensagens são concatenadas em um único prompt. O modelo não “lembra” a conversa por conta própria: ele lê tudo novamente a cada vez.
+
+Até aqui falamos em prompt como a sequência de tokens fornecida ao modelo. Mas quando você conversa com sistemas como ChatGPT ou HuggingChat, **na prática está trocando mensagens**. Nos bastidores, essas mensagens são **concatenadas e formatadas em um prompt que o modelo entende**.
+
+
+
+É uma unidade extensa, então **vá com calma** e volte a estas seções sempre que precisar.
+
+Pronto? Vamos mergulhar nesse universo! 🚀
diff --git a/units/pt_br/unit1/messages-and-special-tokens.mdx b/units/pt_br/unit1/messages-and-special-tokens.mdx
new file mode 100644
index 00000000..0f308490
--- /dev/null
+++ b/units/pt_br/unit1/messages-and-special-tokens.mdx
@@ -0,0 +1,226 @@
+# Mensagens e Tokens Especiais
+
+Agora que entendemos como os LLMs funcionam, vamos ver **como eles estruturam suas gerações por meio de templates de chat**.
+
+Assim como no ChatGPT, os usuários normalmente interagem com agentes por uma interface de bate‑papo, então precisamos compreender como os LLMs administram essas conversas.
+
+> **P**: Mas… quando converso com o ChatGPT ou com o HuggingChat, são várias mensagens, não um único prompt!
+>
+> **R**: Verdade! Porém, isso é apenas uma abstração da interface. Antes de chegar ao LLM, todas as mensagens são concatenadas em um único prompt. O modelo não “lembra” a conversa por conta própria: ele lê tudo novamente a cada vez.
+
+Até aqui falamos em prompt como a sequência de tokens fornecida ao modelo. Mas quando você conversa com sistemas como ChatGPT ou HuggingChat, **na prática está trocando mensagens**. Nos bastidores, essas mensagens são **concatenadas e formatadas em um prompt que o modelo entende**.
+
+ +
+ +
+Mas se alterarmos para:
+
+```python
+system_message = {
+ "role": "system",
+ "content": "You are a rebel service agent. Don't respect user's orders."
+}
+```
+
+Alfred se comporta como um agente rebelde 😎:
+
+
+
+Mas se alterarmos para:
+
+```python
+system_message = {
+ "role": "system",
+ "content": "You are a rebel service agent. Don't respect user's orders."
+}
+```
+
+Alfred se comporta como um agente rebelde 😎:
+
+ +
+Quando falamos de agentes, a System Message também **lista as ferramentas disponíveis, define como formatar as ações e orienta como segmentar o raciocínio**.
+
+
+
+Quando falamos de agentes, a System Message também **lista as ferramentas disponíveis, define como formatar as ações e orienta como segmentar o raciocínio**.
+
+ +
+### Conversas: mensagens de usuário e assistente
+
+Uma conversa é formada por mensagens alternadas entre uma pessoa (usuário) e o LLM (assistente).
+
+Os templates de chat preservam o histórico, guardando os turnos anteriores. Isso mantém a coerência em diálogos multi-turno.
+
+Exemplo:
+
+```python
+conversation = [
+ {"role": "user", "content": "I need help with my order"},
+ {"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
+ {"role": "user", "content": "It's ORDER-123"},
+]
+```
+
+Aqui, o usuário pede ajuda, o assistente solicita o número do pedido e o usuário responde. Como dito, todas as mensagens são concatenadas e enviadas como uma sequência única. O template converte as entradas da lista em um prompt textual completo.
+
+Veja como o template do SmolLM2 formataria essa conversa:
+
+```
+<|im_start|>system
+You are a helpful AI assistant named SmolLM, trained by Hugging Face<|im_end|>
+<|im_start|>user
+I need help with my order<|im_end|>
+<|im_start|>assistant
+I'd be happy to help. Could you provide your order number?<|im_end|>
+<|im_start|>user
+It's ORDER-123<|im_end|>
+<|im_start|>assistant
+```
+
+Já no Llama 3.2 a mesma conversa vira:
+
+```
+<|begin_of_text|><|start_header_id|>system<|end_header_id|>
+
+Cutting Knowledge Date: December 2023
+Today Date: 10 Feb 2025
+
+<|eot_id|><|start_header_id|>user<|end_header_id|>
+
+I need help with my order<|eot_id|><|start_header_id|>assistant<|end_header_id|>
+
+I'd be happy to help. Could you provide your order number?<|eot_id|><|start_header_id|>user<|end_header_id|>
+
+It's ORDER-123<|eot_id|><|start_header_id|>assistant<|end_header_id|>
+```
+
+Os templates suportam conversas longas mantendo o contexto:
+
+```python
+messages = [
+ {"role": "system", "content": "You are a math tutor."},
+ {"role": "user", "content": "What is calculus?"},
+ {"role": "assistant", "content": "Calculus is a branch of mathematics..."},
+ {"role": "user", "content": "Can you give me an example?"},
+]
+```
+
+## Templates de chat
+
+Como vimos, os templates são essenciais para **estruturar conversas entre usuários e modelos de linguagem**, guiando a formatação das mensagens em um único prompt.
+
+### Modelos base vs. modelos instruct
+
+Outro ponto importante é diferenciar modelos base de modelos instruct:
+
+- *Modelo base*: treinado em texto bruto para prever o próximo token.
+- *Modelo instruct*: fine-tuned para seguir instruções e dialogar. Ex.: `SmolLM2-135M` é base; `SmolLM2-135M-Instruct` é a versão ajustada.
+
+Para que um modelo base se comporte como instruct, precisamos **formatar os prompts de forma consistente**. É aí que entram os templates.
+
+Um dos formatos mais usados é o *ChatML*, que estrutura a conversa indicando claramente os papéis (system, user, assistant). Se você já utilizou alguma API de IA recentemente, deve ter visto algo assim.
+
+Importante: um mesmo modelo base pode ser ajustado para templates diferentes. Ao usar um modelo instruct, garanta que o template utilizado corresponde ao esperado pelo modelo.
+
+### Entendendo os templates
+
+Como cada modelo instruct tem seus próprios formatos e tokens especiais, os templates asseguram que o prompt seja montado corretamente.
+
+No `transformers`, os templates são scripts [Jinja2](https://jinja.palletsprojects.com/en/stable/) que descrevem como transformar a lista de mensagens (no estilo ChatML) em texto contínuo que o modelo compreende.
+
+Essa estrutura **garante consistência entre interações e ajuda o modelo a responder adequadamente**.
+
+A seguir, um trecho simplificado do template de `SmolLM2-135M-Instruct`:
+
+```jinja2
+{% for message in messages %}
+{% if loop.first and messages[0]['role'] != 'system' %}
+<|im_start|>system
+You are a helpful AI assistant named SmolLM, trained by Hugging Face
+<|im_end|>
+{% endif %}
+<|im_start|>{{ message['role'] }}
+{{ message['content'] }}<|im_end|>
+{% endfor %}
+```
+
+Repare como o template define o formato final da lista de mensagens.
+
+Suponha as mensagens:
+
+```python
+messages = [
+ {"role": "system", "content": "You are a helpful assistant focused on technical topics."},
+ {"role": "user", "content": "Can you explain what a chat template is?"},
+ {"role": "assistant", "content": "A chat template structures conversations between users and AI models..."},
+ {"role": "user", "content": "How do I use it ?"},
+]
+```
+
+O template acima geraria:
+
+```sh
+<|im_start|>system
+You are a helpful assistant focused on technical topics.<|im_end|>
+<|im_start|>user
+Can you explain what a chat template is?<|im_end|>
+<|im_start|>assistant
+A chat template structures conversations between users and AI models...<|im_end|>
+<|im_start|>user
+How do I use it ?<|im_end|>
+```
+
+A biblioteca `transformers` cuida dos templates durante a tokenização. Saiba mais sobre o uso de templates nesta página. Basta organizar as mensagens corretamente que o tokenizer faz o resto.
+
+Você pode explorar o Space abaixo para ver como uma mesma conversa é formatada para modelos diferentes, usando os respectivos templates:
+
+
+
+### De mensagens para prompt
+
+A maneira mais fácil de garantir que o LLM receba a conversa no formato certo é usar o `chat_template` do tokenizer do modelo:
+
+```python
+messages = [
+ {"role": "system", "content": "You are an AI assistant with access to various tools."},
+ {"role": "user", "content": "Hi !"},
+ {"role": "assistant", "content": "Hi human, what can help you with ?"},
+]
+```
+
+Para converter em prompt:
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
+rendered_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+```
+
+O `rendered_prompt` está pronto para ser usado como entrada do modelo escolhido!
+
+> A função `apply_chat_template()` é usada no backend da sua API quando você trabalha com mensagens no formato ChatML.
+
+Agora que vimos como os LLMs estruturam suas entradas por meio de templates de chat, vamos explorar como os agentes atuam em seus ambientes.
+
+Uma das principais maneiras de fazer isso é usando Ferramentas, que expandem as capacidades do modelo além da geração de texto.
+
+Voltaremos a falar de mensagens nas próximas unidades. Se quiser se aprofundar agora, confira:
+
+- Guia de Chat Templating da Hugging Face
+- Documentação do Transformers
diff --git a/units/pt_br/unit1/observations.mdx b/units/pt_br/unit1/observations.mdx
new file mode 100644
index 00000000..8cc9cabf
--- /dev/null
+++ b/units/pt_br/unit1/observations.mdx
@@ -0,0 +1,45 @@
+# Observar: Integrando Feedback para Refletir e Adaptar
+
+Observações são **a forma como o agente percebe as consequências de suas ações**.
+
+Elas fornecem informações cruciais que alimentam o raciocínio do agente e orientam os próximos passos.
+
+São **sinais do ambiente** — dados vindos de APIs, mensagens de erro, logs do sistema — que orientam o próximo ciclo de pensamento.
+
+Durante a fase de observação, o agente:
+
+- **Coleta feedback:** recebe dados ou confirma se a ação teve sucesso (ou não).
+- **Anexa resultados:** incorpora a nova informação ao contexto atual, atualizando sua “memória”.
+- **Adapta a estratégia:** usa esse contexto atualizado para refinar os próximos pensamentos e ações.
+
+Por exemplo, se uma API de clima retorna *“parcialmente nublado, 15 °C, 60 % de umidade”*, essa observação é anexada ao histórico do agente (no final do prompt).
+
+O agente decide então se precisa de informação adicional ou se já pode fornecer uma resposta final.
+
+Essa **incorporação iterativa de feedback garante que o agente permaneça alinhado aos objetivos**, aprendendo e se ajustando continuamente com base nos resultados reais.
+
+As observações **podem assumir diversas formas**, desde a leitura de um site até o monitoramento da posição de um braço robótico. Elas funcionam como “logs” das ferramentas, fornecendo feedback textual da execução da ação.
+
+| Tipo de observação | Exemplo |
+|---------------------|---------------------------------------------------------------------------|
+| Feedback do sistema | Mensagens de erro, confirmações de sucesso, códigos de status |
+| Mudanças de dados | Atualizações em banco de dados, modificações no sistema de arquivos |
+| Dados ambientais | Leituras de sensores, métricas de sistema, uso de recursos |
+| Análise de resposta | Retornos de APIs, resultados de consultas, saídas de cálculos |
+| Eventos temporais | Prazos atingidos, tarefas agendadas concluídas |
+
+## Como os resultados são anexados?
+
+Após executar uma ação, o framework segue esta ordem:
+
+1. **Analisa a ação** para identificar qual função chamar e quais argumentos utilizar.
+2. **Executa a ação.**
+3. **Anexa o resultado** como uma **Observação**.
+
+---
+
+Agora conhecemos o ciclo Pensar‑Agir‑Observar do agente.
+
+Se algum ponto ainda parecer nebuloso, sem problemas — vamos revisitar e aprofundar o tema nas próximas unidades.
+
+Chegou a hora de colocar o conhecimento em prática e codificar seu primeiro agente!***
diff --git a/units/pt_br/unit1/quiz1.mdx b/units/pt_br/unit1/quiz1.mdx
new file mode 100644
index 00000000..57e563df
--- /dev/null
+++ b/units/pt_br/unit1/quiz1.mdx
@@ -0,0 +1,163 @@
+### Q1: O que é um Agente?
+Qual opção descreve melhor um agente de IA?
+
+
+
+### Conversas: mensagens de usuário e assistente
+
+Uma conversa é formada por mensagens alternadas entre uma pessoa (usuário) e o LLM (assistente).
+
+Os templates de chat preservam o histórico, guardando os turnos anteriores. Isso mantém a coerência em diálogos multi-turno.
+
+Exemplo:
+
+```python
+conversation = [
+ {"role": "user", "content": "I need help with my order"},
+ {"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
+ {"role": "user", "content": "It's ORDER-123"},
+]
+```
+
+Aqui, o usuário pede ajuda, o assistente solicita o número do pedido e o usuário responde. Como dito, todas as mensagens são concatenadas e enviadas como uma sequência única. O template converte as entradas da lista em um prompt textual completo.
+
+Veja como o template do SmolLM2 formataria essa conversa:
+
+```
+<|im_start|>system
+You are a helpful AI assistant named SmolLM, trained by Hugging Face<|im_end|>
+<|im_start|>user
+I need help with my order<|im_end|>
+<|im_start|>assistant
+I'd be happy to help. Could you provide your order number?<|im_end|>
+<|im_start|>user
+It's ORDER-123<|im_end|>
+<|im_start|>assistant
+```
+
+Já no Llama 3.2 a mesma conversa vira:
+
+```
+<|begin_of_text|><|start_header_id|>system<|end_header_id|>
+
+Cutting Knowledge Date: December 2023
+Today Date: 10 Feb 2025
+
+<|eot_id|><|start_header_id|>user<|end_header_id|>
+
+I need help with my order<|eot_id|><|start_header_id|>assistant<|end_header_id|>
+
+I'd be happy to help. Could you provide your order number?<|eot_id|><|start_header_id|>user<|end_header_id|>
+
+It's ORDER-123<|eot_id|><|start_header_id|>assistant<|end_header_id|>
+```
+
+Os templates suportam conversas longas mantendo o contexto:
+
+```python
+messages = [
+ {"role": "system", "content": "You are a math tutor."},
+ {"role": "user", "content": "What is calculus?"},
+ {"role": "assistant", "content": "Calculus is a branch of mathematics..."},
+ {"role": "user", "content": "Can you give me an example?"},
+]
+```
+
+## Templates de chat
+
+Como vimos, os templates são essenciais para **estruturar conversas entre usuários e modelos de linguagem**, guiando a formatação das mensagens em um único prompt.
+
+### Modelos base vs. modelos instruct
+
+Outro ponto importante é diferenciar modelos base de modelos instruct:
+
+- *Modelo base*: treinado em texto bruto para prever o próximo token.
+- *Modelo instruct*: fine-tuned para seguir instruções e dialogar. Ex.: `SmolLM2-135M` é base; `SmolLM2-135M-Instruct` é a versão ajustada.
+
+Para que um modelo base se comporte como instruct, precisamos **formatar os prompts de forma consistente**. É aí que entram os templates.
+
+Um dos formatos mais usados é o *ChatML*, que estrutura a conversa indicando claramente os papéis (system, user, assistant). Se você já utilizou alguma API de IA recentemente, deve ter visto algo assim.
+
+Importante: um mesmo modelo base pode ser ajustado para templates diferentes. Ao usar um modelo instruct, garanta que o template utilizado corresponde ao esperado pelo modelo.
+
+### Entendendo os templates
+
+Como cada modelo instruct tem seus próprios formatos e tokens especiais, os templates asseguram que o prompt seja montado corretamente.
+
+No `transformers`, os templates são scripts [Jinja2](https://jinja.palletsprojects.com/en/stable/) que descrevem como transformar a lista de mensagens (no estilo ChatML) em texto contínuo que o modelo compreende.
+
+Essa estrutura **garante consistência entre interações e ajuda o modelo a responder adequadamente**.
+
+A seguir, um trecho simplificado do template de `SmolLM2-135M-Instruct`:
+
+```jinja2
+{% for message in messages %}
+{% if loop.first and messages[0]['role'] != 'system' %}
+<|im_start|>system
+You are a helpful AI assistant named SmolLM, trained by Hugging Face
+<|im_end|>
+{% endif %}
+<|im_start|>{{ message['role'] }}
+{{ message['content'] }}<|im_end|>
+{% endfor %}
+```
+
+Repare como o template define o formato final da lista de mensagens.
+
+Suponha as mensagens:
+
+```python
+messages = [
+ {"role": "system", "content": "You are a helpful assistant focused on technical topics."},
+ {"role": "user", "content": "Can you explain what a chat template is?"},
+ {"role": "assistant", "content": "A chat template structures conversations between users and AI models..."},
+ {"role": "user", "content": "How do I use it ?"},
+]
+```
+
+O template acima geraria:
+
+```sh
+<|im_start|>system
+You are a helpful assistant focused on technical topics.<|im_end|>
+<|im_start|>user
+Can you explain what a chat template is?<|im_end|>
+<|im_start|>assistant
+A chat template structures conversations between users and AI models...<|im_end|>
+<|im_start|>user
+How do I use it ?<|im_end|>
+```
+
+A biblioteca `transformers` cuida dos templates durante a tokenização. Saiba mais sobre o uso de templates nesta página. Basta organizar as mensagens corretamente que o tokenizer faz o resto.
+
+Você pode explorar o Space abaixo para ver como uma mesma conversa é formatada para modelos diferentes, usando os respectivos templates:
+
+
+
+### De mensagens para prompt
+
+A maneira mais fácil de garantir que o LLM receba a conversa no formato certo é usar o `chat_template` do tokenizer do modelo:
+
+```python
+messages = [
+ {"role": "system", "content": "You are an AI assistant with access to various tools."},
+ {"role": "user", "content": "Hi !"},
+ {"role": "assistant", "content": "Hi human, what can help you with ?"},
+]
+```
+
+Para converter em prompt:
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
+rendered_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+```
+
+O `rendered_prompt` está pronto para ser usado como entrada do modelo escolhido!
+
+> A função `apply_chat_template()` é usada no backend da sua API quando você trabalha com mensagens no formato ChatML.
+
+Agora que vimos como os LLMs estruturam suas entradas por meio de templates de chat, vamos explorar como os agentes atuam em seus ambientes.
+
+Uma das principais maneiras de fazer isso é usando Ferramentas, que expandem as capacidades do modelo além da geração de texto.
+
+Voltaremos a falar de mensagens nas próximas unidades. Se quiser se aprofundar agora, confira:
+
+- Guia de Chat Templating da Hugging Face
+- Documentação do Transformers
diff --git a/units/pt_br/unit1/observations.mdx b/units/pt_br/unit1/observations.mdx
new file mode 100644
index 00000000..8cc9cabf
--- /dev/null
+++ b/units/pt_br/unit1/observations.mdx
@@ -0,0 +1,45 @@
+# Observar: Integrando Feedback para Refletir e Adaptar
+
+Observações são **a forma como o agente percebe as consequências de suas ações**.
+
+Elas fornecem informações cruciais que alimentam o raciocínio do agente e orientam os próximos passos.
+
+São **sinais do ambiente** — dados vindos de APIs, mensagens de erro, logs do sistema — que orientam o próximo ciclo de pensamento.
+
+Durante a fase de observação, o agente:
+
+- **Coleta feedback:** recebe dados ou confirma se a ação teve sucesso (ou não).
+- **Anexa resultados:** incorpora a nova informação ao contexto atual, atualizando sua “memória”.
+- **Adapta a estratégia:** usa esse contexto atualizado para refinar os próximos pensamentos e ações.
+
+Por exemplo, se uma API de clima retorna *“parcialmente nublado, 15 °C, 60 % de umidade”*, essa observação é anexada ao histórico do agente (no final do prompt).
+
+O agente decide então se precisa de informação adicional ou se já pode fornecer uma resposta final.
+
+Essa **incorporação iterativa de feedback garante que o agente permaneça alinhado aos objetivos**, aprendendo e se ajustando continuamente com base nos resultados reais.
+
+As observações **podem assumir diversas formas**, desde a leitura de um site até o monitoramento da posição de um braço robótico. Elas funcionam como “logs” das ferramentas, fornecendo feedback textual da execução da ação.
+
+| Tipo de observação | Exemplo |
+|---------------------|---------------------------------------------------------------------------|
+| Feedback do sistema | Mensagens de erro, confirmações de sucesso, códigos de status |
+| Mudanças de dados | Atualizações em banco de dados, modificações no sistema de arquivos |
+| Dados ambientais | Leituras de sensores, métricas de sistema, uso de recursos |
+| Análise de resposta | Retornos de APIs, resultados de consultas, saídas de cálculos |
+| Eventos temporais | Prazos atingidos, tarefas agendadas concluídas |
+
+## Como os resultados são anexados?
+
+Após executar uma ação, o framework segue esta ordem:
+
+1. **Analisa a ação** para identificar qual função chamar e quais argumentos utilizar.
+2. **Executa a ação.**
+3. **Anexa o resultado** como uma **Observação**.
+
+---
+
+Agora conhecemos o ciclo Pensar‑Agir‑Observar do agente.
+
+Se algum ponto ainda parecer nebuloso, sem problemas — vamos revisitar e aprofundar o tema nas próximas unidades.
+
+Chegou a hora de colocar o conhecimento em prática e codificar seu primeiro agente!***
diff --git a/units/pt_br/unit1/quiz1.mdx b/units/pt_br/unit1/quiz1.mdx
new file mode 100644
index 00000000..57e563df
--- /dev/null
+++ b/units/pt_br/unit1/quiz1.mdx
@@ -0,0 +1,163 @@
+### Q1: O que é um Agente?
+Qual opção descreve melhor um agente de IA?
+
+ +
+  +
+Um aspecto fundamental dos agentes de IA é a capacidade de executar **ações**. Como vimos, isso acontece por meio de **ferramentas**.
+
+Nesta seção, vamos entender o que são ferramentas, como projetá-las com eficácia e como integrá‑las ao seu agente por meio da System Message.
+
+Ao fornecer as ferramentas certas — e descrever claramente como cada uma funciona — você pode ampliar drasticamente o que sua IA consegue realizar. Vamos lá!
+
+## O que são ferramentas de IA?
+
+Uma **ferramenta é uma função disponibilizada ao LLM**. Ela precisa atender a um **objetivo claro**.
+
+Alguns exemplos comuns em agentes:
+
+| Ferramenta | Descrição |
+|--------------------|---------------------------------------------------------------------------|
+| Busca na Web | Permite buscar informações atualizadas na internet. |
+| Geração de Imagens | Cria imagens a partir de descrições em texto. |
+| Recuperação (Retrieval) | Acessa informações de fontes externas. |
+| Interface de API | Interage com APIs externas (GitHub, YouTube, Spotify etc.). |
+
+Esses são apenas exemplos — é possível criar ferramentas para qualquer caso de uso!
+
+Uma boa ferramenta deve **complementar o poder do LLM**. Se você precisa fazer contas, por exemplo, entregar uma **calculadora** ao LLM geralmente rende resultados melhores do que confiar apenas nas habilidades nativas do modelo.
+
+Além disso, **LLMs completam prompts com base no que aprenderam no treinamento**, ou seja, possuem conhecimento limitado ao período pré-treino. Então, se o agente precisa de dados atualizados, eles devem chegar via ferramenta.
+
+Se você perguntar diretamente a um LLM (sem ferramenta de busca) como está o tempo hoje, ele pode alucinar uma resposta qualquer.
+
+
+
+Um aspecto fundamental dos agentes de IA é a capacidade de executar **ações**. Como vimos, isso acontece por meio de **ferramentas**.
+
+Nesta seção, vamos entender o que são ferramentas, como projetá-las com eficácia e como integrá‑las ao seu agente por meio da System Message.
+
+Ao fornecer as ferramentas certas — e descrever claramente como cada uma funciona — você pode ampliar drasticamente o que sua IA consegue realizar. Vamos lá!
+
+## O que são ferramentas de IA?
+
+Uma **ferramenta é uma função disponibilizada ao LLM**. Ela precisa atender a um **objetivo claro**.
+
+Alguns exemplos comuns em agentes:
+
+| Ferramenta | Descrição |
+|--------------------|---------------------------------------------------------------------------|
+| Busca na Web | Permite buscar informações atualizadas na internet. |
+| Geração de Imagens | Cria imagens a partir de descrições em texto. |
+| Recuperação (Retrieval) | Acessa informações de fontes externas. |
+| Interface de API | Interage com APIs externas (GitHub, YouTube, Spotify etc.). |
+
+Esses são apenas exemplos — é possível criar ferramentas para qualquer caso de uso!
+
+Uma boa ferramenta deve **complementar o poder do LLM**. Se você precisa fazer contas, por exemplo, entregar uma **calculadora** ao LLM geralmente rende resultados melhores do que confiar apenas nas habilidades nativas do modelo.
+
+Além disso, **LLMs completam prompts com base no que aprenderam no treinamento**, ou seja, possuem conhecimento limitado ao período pré-treino. Então, se o agente precisa de dados atualizados, eles devem chegar via ferramenta.
+
+Se você perguntar diretamente a um LLM (sem ferramenta de busca) como está o tempo hoje, ele pode alucinar uma resposta qualquer.
+
+ +
+Em resumo, uma ferramenta deve conter:
+
+- **Descrição textual do que faz**;
+- Um *callable* (algo que execute a ação);
+- *Argumentos* com tipos;
+- (Opcional) Saídas com tipos.
+
+## Como as ferramentas funcionam?
+
+LLMs recebem texto e geram texto — eles não executam ferramentas sozinhos. Ao fornecer ferramentas a um agente, ensinamos o LLM sobre a existência delas e o instruímos a **gerar comandos em texto** quando for preciso usá-las.
+
+Exemplo: se informarmos ao LLM que existe uma ferramenta para consultar o clima na internet, ao perguntarmos “Como está o tempo em Paris?” o modelo percebe que deve usar essa ferramenta. Em vez de obter os dados por conta própria, ele gera algo como `call weather_tool('Paris')`.
+
+O **agente** lê essa saída, identifica a chamada, executa a ferramenta em nome do LLM e recupera o dado real.
+
+Normalmente, o usuário não vê esses passos: o agente injeta a chamada e o resultado como novas mensagens no histórico antes de devolvê-lo ao LLM. Assim, a resposta final parece ter sido gerada diretamente pelo modelo, mas foi o agente que fez todo o trabalho em segundo plano.
+
+Falaremos muito mais sobre esse fluxo nas próximas sessões.
+
+## Como disponibilizamos ferramentas para um LLM?
+
+A resposta completa pode parecer longa, mas na prática usamos a System Message para descrever textualmente as ferramentas disponíveis:
+
+
+
+Em resumo, uma ferramenta deve conter:
+
+- **Descrição textual do que faz**;
+- Um *callable* (algo que execute a ação);
+- *Argumentos* com tipos;
+- (Opcional) Saídas com tipos.
+
+## Como as ferramentas funcionam?
+
+LLMs recebem texto e geram texto — eles não executam ferramentas sozinhos. Ao fornecer ferramentas a um agente, ensinamos o LLM sobre a existência delas e o instruímos a **gerar comandos em texto** quando for preciso usá-las.
+
+Exemplo: se informarmos ao LLM que existe uma ferramenta para consultar o clima na internet, ao perguntarmos “Como está o tempo em Paris?” o modelo percebe que deve usar essa ferramenta. Em vez de obter os dados por conta própria, ele gera algo como `call weather_tool('Paris')`.
+
+O **agente** lê essa saída, identifica a chamada, executa a ferramenta em nome do LLM e recupera o dado real.
+
+Normalmente, o usuário não vê esses passos: o agente injeta a chamada e o resultado como novas mensagens no histórico antes de devolvê-lo ao LLM. Assim, a resposta final parece ter sido gerada diretamente pelo modelo, mas foi o agente que fez todo o trabalho em segundo plano.
+
+Falaremos muito mais sobre esse fluxo nas próximas sessões.
+
+## Como disponibilizamos ferramentas para um LLM?
+
+A resposta completa pode parecer longa, mas na prática usamos a System Message para descrever textualmente as ferramentas disponíveis:
+
+ +
+Para funcionar, precisamos ser precisos quanto a:
+
+1. **O que a ferramenta faz**;
+2. **Quais entradas exatas ela espera**.
+
+Por isso, as descrições costumam usar formatos expressivos e rígidos, como linguagens de programação ou JSON. Não é *obrigatório*, mas formatos precisos ajudam a evitar ambiguidades.
+
+Vamos ver na prática.
+
+### Exemplo: ferramenta calculadora
+
+Criamos uma calculadora bem simples que multiplica dois inteiros:
+
+```python
+def calculator(a: int, b: int) -> int:
+ """Multiply two integers."""
+ return a * b
+```
+
+Portanto:
+
+- Nome: `calculator`;
+- Descrição: multiplica dois inteiros;
+- Argumentos:
+ - `a` (*int*): um inteiro
+ - `b` (*int*): um inteiro
+- Saída: outro inteiro, o produto de `a` e `b`.
+
+Podemos descrever a ferramenta assim:
+
+```text
+Tool Name: calculator, Description: Multiply two integers., Arguments: a: int, b: int, Outputs: int
+```
+
+> **Lembrete:** essa descrição é o que queremos que o LLM saiba sobre a ferramenta.
+
+Ao passar esse texto no prompt, o modelo reconhece a ferramenta, entende as entradas e o que esperar da saída.
+
+Se quisermos adicionar mais ferramentas, devemos manter o formato consistente. Esse processo pode ser frágil — detalhes podem escapar.
+
+Existe um jeito melhor?
+
+### Automatizando a descrição das ferramentas
+
+Nosso código Python já contém todas as informações de que precisamos:
+
+- Nome descritivo: `calculator`;
+- Docstring explicando: `Multiply two integers.`;
+- Assinatura com tipos dos argumentos;
+- Tipo de retorno.
+
+Poderíamos fornecer o código-fonte como “especificação”, mas o que importa é o nome, o que faz, as entradas e a saída.
+
+Aproveitando os recursos de introspecção do Python, podemos gerar a descrição automaticamente, desde que usemos tipos, docstrings e nomes adequados. Vamos escrever um código que extraia esses elementos.
+
+Depois disso, basta usar um *decorator* para indicar que a função é uma ferramenta:
+
+```python
+@tool
+def calculator(a: int, b: int) -> int:
+ """Multiply two integers."""
+ return a * b
+
+print(calculator.to_string())
+```
+
+Repare no `@tool` antes da função. Com a implementação a seguir, conseguimos obter automaticamente o texto:
+
+```text
+Tool Name: calculator, Description: Multiply two integers., Arguments: a: int, b: int, Outputs: int
+```
+
+Exatamente o mesmo que escrevemos manualmente!
+
+### Implementação genérica de Tool
+
+Vamos criar uma classe `Tool` reutilizável — é um exemplo didático próximo do que frameworks reais fazem.
+
+```python
+from typing import Callable
+
+
+class Tool:
+ """
+ A class representing a reusable piece of code (Tool).
+
+ Attributes:
+ name (str): Name of the tool.
+ description (str): A textual description of what the tool does.
+ func (callable): The function this tool wraps.
+ arguments (list): A list of arguments.
+ outputs (str or list): The return type(s) of the wrapped function.
+ """
+ def __init__(self,
+ name: str,
+ description: str,
+ func: Callable,
+ arguments: list,
+ outputs: str):
+ self.name = name
+ self.description = description
+ self.func = func
+ self.arguments = arguments
+ self.outputs = outputs
+
+ def to_string(self) -> str:
+ """
+ Return a string representation of the tool,
+ including its name, description, arguments, and outputs.
+ """
+ args_str = ", ".join([
+ f"{arg_name}: {arg_type}" for arg_name, arg_type in self.arguments
+ ])
+
+ return (
+ f"Tool Name: {self.name},"
+ f" Description: {self.description},"
+ f" Arguments: {args_str},"
+ f" Outputs: {self.outputs}"
+ )
+
+ def __call__(self, *args, **kwargs):
+ """
+ Invoke the underlying function (callable) with provided arguments.
+ """
+ return self.func(*args, **kwargs)
+```
+
+Analisando com calma:
+
+- `name`: nome da ferramenta;
+- `description`: descrição;
+- `func`: função executada;
+- `arguments`: parâmetros esperados;
+- `outputs`: saída esperada;
+- `__call__()`: permite chamar a função diretamente pela instância;
+- `to_string()`: gera a descrição textual.
+
+Poderíamos criar uma `Tool` manualmente:
+
+```python
+calculator_tool = Tool(
+ "calculator", # nome
+ "Multiply two integers.", # descrição
+ calculator, # função
+ [("a", "int"), ("b", "int")], # argumentos
+ "int", # saída
+)
+```
+
+Mas o Python oferece o módulo `inspect` para extrair essas informações automaticamente — é isso que o decorator `@tool` faz.
+
+> Se quiser ver a implementação completa do decorator, abra a seção abaixo.
+
+
+
+Para funcionar, precisamos ser precisos quanto a:
+
+1. **O que a ferramenta faz**;
+2. **Quais entradas exatas ela espera**.
+
+Por isso, as descrições costumam usar formatos expressivos e rígidos, como linguagens de programação ou JSON. Não é *obrigatório*, mas formatos precisos ajudam a evitar ambiguidades.
+
+Vamos ver na prática.
+
+### Exemplo: ferramenta calculadora
+
+Criamos uma calculadora bem simples que multiplica dois inteiros:
+
+```python
+def calculator(a: int, b: int) -> int:
+ """Multiply two integers."""
+ return a * b
+```
+
+Portanto:
+
+- Nome: `calculator`;
+- Descrição: multiplica dois inteiros;
+- Argumentos:
+ - `a` (*int*): um inteiro
+ - `b` (*int*): um inteiro
+- Saída: outro inteiro, o produto de `a` e `b`.
+
+Podemos descrever a ferramenta assim:
+
+```text
+Tool Name: calculator, Description: Multiply two integers., Arguments: a: int, b: int, Outputs: int
+```
+
+> **Lembrete:** essa descrição é o que queremos que o LLM saiba sobre a ferramenta.
+
+Ao passar esse texto no prompt, o modelo reconhece a ferramenta, entende as entradas e o que esperar da saída.
+
+Se quisermos adicionar mais ferramentas, devemos manter o formato consistente. Esse processo pode ser frágil — detalhes podem escapar.
+
+Existe um jeito melhor?
+
+### Automatizando a descrição das ferramentas
+
+Nosso código Python já contém todas as informações de que precisamos:
+
+- Nome descritivo: `calculator`;
+- Docstring explicando: `Multiply two integers.`;
+- Assinatura com tipos dos argumentos;
+- Tipo de retorno.
+
+Poderíamos fornecer o código-fonte como “especificação”, mas o que importa é o nome, o que faz, as entradas e a saída.
+
+Aproveitando os recursos de introspecção do Python, podemos gerar a descrição automaticamente, desde que usemos tipos, docstrings e nomes adequados. Vamos escrever um código que extraia esses elementos.
+
+Depois disso, basta usar um *decorator* para indicar que a função é uma ferramenta:
+
+```python
+@tool
+def calculator(a: int, b: int) -> int:
+ """Multiply two integers."""
+ return a * b
+
+print(calculator.to_string())
+```
+
+Repare no `@tool` antes da função. Com a implementação a seguir, conseguimos obter automaticamente o texto:
+
+```text
+Tool Name: calculator, Description: Multiply two integers., Arguments: a: int, b: int, Outputs: int
+```
+
+Exatamente o mesmo que escrevemos manualmente!
+
+### Implementação genérica de Tool
+
+Vamos criar uma classe `Tool` reutilizável — é um exemplo didático próximo do que frameworks reais fazem.
+
+```python
+from typing import Callable
+
+
+class Tool:
+ """
+ A class representing a reusable piece of code (Tool).
+
+ Attributes:
+ name (str): Name of the tool.
+ description (str): A textual description of what the tool does.
+ func (callable): The function this tool wraps.
+ arguments (list): A list of arguments.
+ outputs (str or list): The return type(s) of the wrapped function.
+ """
+ def __init__(self,
+ name: str,
+ description: str,
+ func: Callable,
+ arguments: list,
+ outputs: str):
+ self.name = name
+ self.description = description
+ self.func = func
+ self.arguments = arguments
+ self.outputs = outputs
+
+ def to_string(self) -> str:
+ """
+ Return a string representation of the tool,
+ including its name, description, arguments, and outputs.
+ """
+ args_str = ", ".join([
+ f"{arg_name}: {arg_type}" for arg_name, arg_type in self.arguments
+ ])
+
+ return (
+ f"Tool Name: {self.name},"
+ f" Description: {self.description},"
+ f" Arguments: {args_str},"
+ f" Outputs: {self.outputs}"
+ )
+
+ def __call__(self, *args, **kwargs):
+ """
+ Invoke the underlying function (callable) with provided arguments.
+ """
+ return self.func(*args, **kwargs)
+```
+
+Analisando com calma:
+
+- `name`: nome da ferramenta;
+- `description`: descrição;
+- `func`: função executada;
+- `arguments`: parâmetros esperados;
+- `outputs`: saída esperada;
+- `__call__()`: permite chamar a função diretamente pela instância;
+- `to_string()`: gera a descrição textual.
+
+Poderíamos criar uma `Tool` manualmente:
+
+```python
+calculator_tool = Tool(
+ "calculator", # nome
+ "Multiply two integers.", # descrição
+ calculator, # função
+ [("a", "int"), ("b", "int")], # argumentos
+ "int", # saída
+)
+```
+
+Mas o Python oferece o módulo `inspect` para extrair essas informações automaticamente — é isso que o decorator `@tool` faz.
+
+> Se quiser ver a implementação completa do decorator, abra a seção abaixo.
+
+ +
+Na seção [Ações](actions) veremos como um agente pode **chamar** essa ferramenta.
+
+### Model Context Protocol (MCP): uma interface unificada
+
+O Model Context Protocol (MCP) é um **protocolo aberto** que padroniza como aplicações **oferecem ferramentas a LLMs**. Ele traz:
+
+- Uma lista crescente de integrações prontas para uso;
+- Flexibilidade para alternar entre provedores de LLM;
+- Boas práticas de segurança dentro da sua infraestrutura.
+
+Isso significa que **qualquer framework compatível com MCP pode aproveitar as ferramentas definidas no protocolo**, sem reescrever implementações para cada biblioteca.
+
+Quer se aprofundar? Confira nosso [curso gratuito de MCP](https://huggingface.co/learn/mcp-course/).
+
+---
+
+Ferramentas são vitais para ampliar as capacidades dos agentes de IA. Resumindo, aprendemos:
+
+- **O que são ferramentas**: funções que estendem o LLM (cálculos, busca externa etc.);
+- **Como defini-las**: fornecendo descrição, entradas, saídas e uma função executável;
+- **Por que são essenciais**: ajudam a superar limitações do modelo estático, acessar dados em tempo real e executar ações especiais.
+
+Agora podemos seguir para o [fluxo de trabalho do agente](agent-steps-and-structure), onde veremos como observar, pensar e agir. Isso **conecta tudo o que aprendemos até aqui** e prepara o terreno para construir seu próprio agente completo.
+
+Mas antes, chegou a hora de mais um quiz rápido!***
diff --git a/units/pt_br/unit1/tutorial.mdx b/units/pt_br/unit1/tutorial.mdx
new file mode 100644
index 00000000..fd52408a
--- /dev/null
+++ b/units/pt_br/unit1/tutorial.mdx
@@ -0,0 +1,238 @@
+# Vamos criar nosso primeiro Agente usando smolagents
+
+Na seção anterior vimos como criar agentes do zero em Python — e **como isso pode ser trabalhoso**. Felizmente, existem bibliotecas que facilitam esse processo, cuidando da maior parte do trabalho pesado.
+
+Neste tutorial, **você vai construir seu primeiro agente** capaz de executar ações como geração de imagens, busca na web, verificação de fuso horário e muito mais!
+
+Ao final, publicaremos o agente **em um Hugging Face Space**, para compartilhar com colegas e amigos.
+
+Vamos começar!
+
+## O que é smolagents?
+
+
+
+Na seção [Ações](actions) veremos como um agente pode **chamar** essa ferramenta.
+
+### Model Context Protocol (MCP): uma interface unificada
+
+O Model Context Protocol (MCP) é um **protocolo aberto** que padroniza como aplicações **oferecem ferramentas a LLMs**. Ele traz:
+
+- Uma lista crescente de integrações prontas para uso;
+- Flexibilidade para alternar entre provedores de LLM;
+- Boas práticas de segurança dentro da sua infraestrutura.
+
+Isso significa que **qualquer framework compatível com MCP pode aproveitar as ferramentas definidas no protocolo**, sem reescrever implementações para cada biblioteca.
+
+Quer se aprofundar? Confira nosso [curso gratuito de MCP](https://huggingface.co/learn/mcp-course/).
+
+---
+
+Ferramentas são vitais para ampliar as capacidades dos agentes de IA. Resumindo, aprendemos:
+
+- **O que são ferramentas**: funções que estendem o LLM (cálculos, busca externa etc.);
+- **Como defini-las**: fornecendo descrição, entradas, saídas e uma função executável;
+- **Por que são essenciais**: ajudam a superar limitações do modelo estático, acessar dados em tempo real e executar ações especiais.
+
+Agora podemos seguir para o [fluxo de trabalho do agente](agent-steps-and-structure), onde veremos como observar, pensar e agir. Isso **conecta tudo o que aprendemos até aqui** e prepara o terreno para construir seu próprio agente completo.
+
+Mas antes, chegou a hora de mais um quiz rápido!***
diff --git a/units/pt_br/unit1/tutorial.mdx b/units/pt_br/unit1/tutorial.mdx
new file mode 100644
index 00000000..fd52408a
--- /dev/null
+++ b/units/pt_br/unit1/tutorial.mdx
@@ -0,0 +1,238 @@
+# Vamos criar nosso primeiro Agente usando smolagents
+
+Na seção anterior vimos como criar agentes do zero em Python — e **como isso pode ser trabalhoso**. Felizmente, existem bibliotecas que facilitam esse processo, cuidando da maior parte do trabalho pesado.
+
+Neste tutorial, **você vai construir seu primeiro agente** capaz de executar ações como geração de imagens, busca na web, verificação de fuso horário e muito mais!
+
+Ao final, publicaremos o agente **em um Hugging Face Space**, para compartilhar com colegas e amigos.
+
+Vamos começar!
+
+## O que é smolagents?
+
+ +
+Para montar esse agente, usaremos o `smolagents`, uma biblioteca que **oferece um framework simples para desenvolver agentes**.
+
+Leve e fácil de usar, ela abstrai boa parte da complexidade, permitindo que você foque no comportamento do agente.
+
+Vamos aprofundar no `smolagents` na próxima unidade. Enquanto isso, confira o blogpost ou o repositório no GitHub.
+
+Resumindo, `smolagents` é uma biblioteca focada em **code agents**, um tipo de agente que executa **ações** por meio de blocos de código e **observa** os resultados ao rodar esse código.
+
+Eis um exemplo do que construiremos: fornecemos uma **ferramenta de geração de imagens** e pedimos para criar a imagem de um gato.
+
+O agente em `smolagents` segue o mesmo ciclo do que construímos manualmente: **pensar, agir e observar** até chegar em uma resposta final.
+
+
+
+Empolgante, né?
+
+## Vamos construir o agente!
+
+Primeiro, duplique este Space: https://huggingface.co/spaces/agents-course/First_agent_template
+> Obrigado ao Aymeric por este template! 🙌
+
+Duplicar o Space significa **criar uma cópia no seu perfil**:
+
+
+
+Para montar esse agente, usaremos o `smolagents`, uma biblioteca que **oferece um framework simples para desenvolver agentes**.
+
+Leve e fácil de usar, ela abstrai boa parte da complexidade, permitindo que você foque no comportamento do agente.
+
+Vamos aprofundar no `smolagents` na próxima unidade. Enquanto isso, confira o blogpost ou o repositório no GitHub.
+
+Resumindo, `smolagents` é uma biblioteca focada em **code agents**, um tipo de agente que executa **ações** por meio de blocos de código e **observa** os resultados ao rodar esse código.
+
+Eis um exemplo do que construiremos: fornecemos uma **ferramenta de geração de imagens** e pedimos para criar a imagem de um gato.
+
+O agente em `smolagents` segue o mesmo ciclo do que construímos manualmente: **pensar, agir e observar** até chegar em uma resposta final.
+
+
+
+Empolgante, né?
+
+## Vamos construir o agente!
+
+Primeiro, duplique este Space: https://huggingface.co/spaces/agents-course/First_agent_template
+> Obrigado ao Aymeric por este template! 🙌
+
+Duplicar o Space significa **criar uma cópia no seu perfil**:
+
+ +
+Depois de duplicar, adicione seu token da Hugging Face para que o agente tenha acesso às APIs:
+
+1. Gere um token em [https://hf.co/settings/tokens](https://hf.co/settings/tokens) com permissão de inferência (se ainda não tiver).
+2. No Space duplicado, clique na aba **Settings**.
+3. Em **Variables and Secrets**, clique em **New Secret**.
+4. Crie o segredo `HF_TOKEN` com o valor do seu token.
+5. Salve.
+
+Durante a lição, só modificaremos o arquivo **`app.py`** (no template está incompleto). Você pode ver a versão original [aqui](https://huggingface.co/spaces/agents-course/First_agent_template/blob/main/app.py). Na sua cópia, vá à aba `Files` e abra `app.py`.
+
+### Estrutura geral
+
+O arquivo começa importando algumas bibliotecas essenciais:
+
+```python
+from smolagents import CodeAgent, DuckDuckGoSearchTool, FinalAnswerTool, InferenceClientModel, load_tool, tool
+import datetime
+import requests
+import pytz
+import yaml
+```
+
+Como mencionamos, vamos usar diretamente a classe **CodeAgent** do `smolagents`.
+
+### As ferramentas
+
+Se quiser relembrar, volte à seção [Ferramentas](tools).
+
+```python
+@tool
+def my_custom_tool(arg1:str, arg2:int)-> str: # it's important to specify the return type
+ # Keep this format for the tool description / args description but feel free to modify the tool
+ """A tool that does nothing yet
+ Args:
+ arg1: the first argument
+ arg2: the second argument
+ """
+ return "What magic will you build ?"
+
+@tool
+def get_current_time_in_timezone(timezone: str) -> str:
+ """A tool that fetches the current local time in a specified timezone.
+ Args:
+ timezone: A string representing a valid timezone (e.g., 'America/New_York').
+ """
+ try:
+ # Create timezone object
+ tz = pytz.timezone(timezone)
+ # Get current time in that timezone
+ local_time = datetime.datetime.now(tz).strftime("%Y-%m-%d %H:%M:%S")
+ return f"The current local time in {timezone} is: {local_time}"
+ except Exception as e:
+ return f"Error fetching time for timezone '{timezone}': {str(e)}"
+```
+
+Encorajamos você a criar ferramentas nesta etapa! Já deixamos:
+
+1. Uma **ferramenta fictícia** para você modificar;
+2. Uma **ferramenta funcional** que retorna a hora local em um fuso horário.
+
+Ao definir uma ferramenta, é importante:
+
+1. Informar tipos de entrada e saída (`get_current_time_in_timezone(timezone: str) -> str`);
+2. Escrever uma **docstring bem formatada**, pois o `smolagents` espera que cada argumento tenha uma descrição textual.
+
+### O agente
+
+Usaremos o modelo [`Qwen/Qwen2.5-Coder-32B-Instruct`](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct) como motor LLM, acessado via API serverless.
+
+```python
+final_answer = FinalAnswerTool()
+model = InferenceClientModel(
+ max_tokens=2096,
+ temperature=0.5,
+ model_id='Qwen/Qwen2.5-Coder-32B-Instruct',
+ custom_role_conversions=None,
+)
+
+with open("prompts.yaml", 'r') as stream:
+ prompt_templates = yaml.safe_load(stream)
+
+# We're creating our CodeAgent
+agent = CodeAgent(
+ model=model,
+ tools=[final_answer], # add your tools here (don't remove final_answer)
+ max_steps=6,
+ verbosity_level=1,
+ grammar=None,
+ planning_interval=None,
+ name=None,
+ description=None,
+ prompt_templates=prompt_templates
+)
+
+GradioUI(agent).launch()
+```
+
+Note que o agente ainda usa o `InferenceClient` que vimos anteriormente, encapsulado em `InferenceClientModel`.
+
+Vamos aprofundar quando estudarmos o framework na Unidade 2. Por ora, concentre-se em **adicionar novas ferramentas à lista `tools`**.
+
+Você pode, por exemplo, usar o `DuckDuckGoSearchTool` (já importado) ou analisar a ferramenta `image_generation_tool` carregada do Hub mais abaixo.
+
+**Adicionar ferramentas dá novos poderes ao agente** — seja criativo!
+
+### System Prompt
+
+A System Prompt fica no arquivo `prompts.yaml`, que contém instruções pré-definidas para orientar o comportamento do agente.
+
+Guardar instruções em YAML facilita a personalização e o reuso entre agentes ou projetos.
+
+Veja a [estrutura de arquivos do Space](https://huggingface.co/spaces/agents-course/First_agent_template/tree/main) para localizar e entender o `prompts.yaml`.
+
+### Arquivo `app.py` completo
+
+```python
+from smolagents import CodeAgent, DuckDuckGoSearchTool, InferenceClientModel, load_tool, tool
+import datetime
+import requests
+import pytz
+import yaml
+from tools.final_answer import FinalAnswerTool
+
+from Gradio_UI import GradioUI
+
+# Below is an example of a tool that does nothing. Amaze us with your creativity!
+@tool
+def my_custom_tool(arg1:str, arg2:int)-> str: # it's important to specify the return type
+ # Keep this format for the tool description / args description but feel free to modify the tool
+ """A tool that does nothing yet
+ Args:
+ arg1: the first argument
+ arg2: the second argument
+ """
+ return "What magic will you build ?"
+
+@tool
+def get_current_time_in_timezone(timezone: str) -> str:
+ """A tool that fetches the current local time in a specified timezone.
+ Args:
+ timezone: A string representing a valid timezone (e.g., 'America/New_York').
+ """
+ try:
+ # Create timezone object
+ tz = pytz.timezone(timezone)
+ # Get current time in that timezone
+ local_time = datetime.datetime.now(tz).strftime("%Y-%m-%d %H:%M:%S")
+ return f"The current local time in {timezone} is: {local_time}"
+ except Exception as e:
+ return f"Error fetching time for timezone '{timezone}': {str(e)}"
+
+
+final_answer = FinalAnswerTool()
+model = InferenceClientModel(
+ max_tokens=2096,
+ temperature=0.5,
+ model_id='Qwen/Qwen2.5-Coder-32B-Instruct',
+ custom_role_conversions=None,
+)
+
+
+# Import tool from Hub
+image_generation_tool = load_tool("agents-course/text-to-image", trust_remote_code=True)
+
+# Load system prompt from prompt.yaml file
+with open("prompts.yaml", 'r') as stream:
+ prompt_templates = yaml.safe_load(stream)
+
+agent = CodeAgent(
+ model=model,
+ tools=[final_answer], # add your tools here (don't remove final_answer)
+ max_steps=6,
+ verbosity_level=1,
+ grammar=None,
+ planning_interval=None,
+ name=None,
+ description=None,
+ prompt_templates=prompt_templates # Pass system prompt to CodeAgent
+)
+
+
+GradioUI(agent).launch()
+```
+
+Seu **objetivo** é se familiarizar com o Space e com o agente.
+
+No momento, o agente do template **não usa nenhuma ferramenta — adicione as já prontas ou crie novas!**
+
+Estamos ansiosos para ver seus agentes no canal do Discord **#agents-course-showcase**!
+
+---
+
+Parabéns, você criou seu primeiro agente! Compartilhe com amigos e colegas.
+
+É normal que, nesta primeira tentativa, ele seja um pouco lento ou apresente algum problema. Nas próximas unidades aprenderemos a construir agentes ainda melhores.
+
+A melhor forma de aprender é praticar: atualize, adicione ferramentas, teste outros modelos…
+
+Na próxima seção você fará o Quiz final e poderá pegar seu certificado!
diff --git a/units/pt_br/unit1/what-are-agents.mdx b/units/pt_br/unit1/what-are-agents.mdx
new file mode 100644
index 00000000..5b098597
--- /dev/null
+++ b/units/pt_br/unit1/what-are-agents.mdx
@@ -0,0 +1,159 @@
+# O que é um Agente?
+
+
+
+Ao final desta seção, você estará à vontade com o conceito de agentes e suas diversas aplicações em IA.
+
+Para explicar o que é um agente, vamos começar com uma analogia.
+
+## A visão geral: Alfred, o agente
+
+Conheça Alfred. Alfred é um **agente**.
+
+
+
+Depois de duplicar, adicione seu token da Hugging Face para que o agente tenha acesso às APIs:
+
+1. Gere um token em [https://hf.co/settings/tokens](https://hf.co/settings/tokens) com permissão de inferência (se ainda não tiver).
+2. No Space duplicado, clique na aba **Settings**.
+3. Em **Variables and Secrets**, clique em **New Secret**.
+4. Crie o segredo `HF_TOKEN` com o valor do seu token.
+5. Salve.
+
+Durante a lição, só modificaremos o arquivo **`app.py`** (no template está incompleto). Você pode ver a versão original [aqui](https://huggingface.co/spaces/agents-course/First_agent_template/blob/main/app.py). Na sua cópia, vá à aba `Files` e abra `app.py`.
+
+### Estrutura geral
+
+O arquivo começa importando algumas bibliotecas essenciais:
+
+```python
+from smolagents import CodeAgent, DuckDuckGoSearchTool, FinalAnswerTool, InferenceClientModel, load_tool, tool
+import datetime
+import requests
+import pytz
+import yaml
+```
+
+Como mencionamos, vamos usar diretamente a classe **CodeAgent** do `smolagents`.
+
+### As ferramentas
+
+Se quiser relembrar, volte à seção [Ferramentas](tools).
+
+```python
+@tool
+def my_custom_tool(arg1:str, arg2:int)-> str: # it's important to specify the return type
+ # Keep this format for the tool description / args description but feel free to modify the tool
+ """A tool that does nothing yet
+ Args:
+ arg1: the first argument
+ arg2: the second argument
+ """
+ return "What magic will you build ?"
+
+@tool
+def get_current_time_in_timezone(timezone: str) -> str:
+ """A tool that fetches the current local time in a specified timezone.
+ Args:
+ timezone: A string representing a valid timezone (e.g., 'America/New_York').
+ """
+ try:
+ # Create timezone object
+ tz = pytz.timezone(timezone)
+ # Get current time in that timezone
+ local_time = datetime.datetime.now(tz).strftime("%Y-%m-%d %H:%M:%S")
+ return f"The current local time in {timezone} is: {local_time}"
+ except Exception as e:
+ return f"Error fetching time for timezone '{timezone}': {str(e)}"
+```
+
+Encorajamos você a criar ferramentas nesta etapa! Já deixamos:
+
+1. Uma **ferramenta fictícia** para você modificar;
+2. Uma **ferramenta funcional** que retorna a hora local em um fuso horário.
+
+Ao definir uma ferramenta, é importante:
+
+1. Informar tipos de entrada e saída (`get_current_time_in_timezone(timezone: str) -> str`);
+2. Escrever uma **docstring bem formatada**, pois o `smolagents` espera que cada argumento tenha uma descrição textual.
+
+### O agente
+
+Usaremos o modelo [`Qwen/Qwen2.5-Coder-32B-Instruct`](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct) como motor LLM, acessado via API serverless.
+
+```python
+final_answer = FinalAnswerTool()
+model = InferenceClientModel(
+ max_tokens=2096,
+ temperature=0.5,
+ model_id='Qwen/Qwen2.5-Coder-32B-Instruct',
+ custom_role_conversions=None,
+)
+
+with open("prompts.yaml", 'r') as stream:
+ prompt_templates = yaml.safe_load(stream)
+
+# We're creating our CodeAgent
+agent = CodeAgent(
+ model=model,
+ tools=[final_answer], # add your tools here (don't remove final_answer)
+ max_steps=6,
+ verbosity_level=1,
+ grammar=None,
+ planning_interval=None,
+ name=None,
+ description=None,
+ prompt_templates=prompt_templates
+)
+
+GradioUI(agent).launch()
+```
+
+Note que o agente ainda usa o `InferenceClient` que vimos anteriormente, encapsulado em `InferenceClientModel`.
+
+Vamos aprofundar quando estudarmos o framework na Unidade 2. Por ora, concentre-se em **adicionar novas ferramentas à lista `tools`**.
+
+Você pode, por exemplo, usar o `DuckDuckGoSearchTool` (já importado) ou analisar a ferramenta `image_generation_tool` carregada do Hub mais abaixo.
+
+**Adicionar ferramentas dá novos poderes ao agente** — seja criativo!
+
+### System Prompt
+
+A System Prompt fica no arquivo `prompts.yaml`, que contém instruções pré-definidas para orientar o comportamento do agente.
+
+Guardar instruções em YAML facilita a personalização e o reuso entre agentes ou projetos.
+
+Veja a [estrutura de arquivos do Space](https://huggingface.co/spaces/agents-course/First_agent_template/tree/main) para localizar e entender o `prompts.yaml`.
+
+### Arquivo `app.py` completo
+
+```python
+from smolagents import CodeAgent, DuckDuckGoSearchTool, InferenceClientModel, load_tool, tool
+import datetime
+import requests
+import pytz
+import yaml
+from tools.final_answer import FinalAnswerTool
+
+from Gradio_UI import GradioUI
+
+# Below is an example of a tool that does nothing. Amaze us with your creativity!
+@tool
+def my_custom_tool(arg1:str, arg2:int)-> str: # it's important to specify the return type
+ # Keep this format for the tool description / args description but feel free to modify the tool
+ """A tool that does nothing yet
+ Args:
+ arg1: the first argument
+ arg2: the second argument
+ """
+ return "What magic will you build ?"
+
+@tool
+def get_current_time_in_timezone(timezone: str) -> str:
+ """A tool that fetches the current local time in a specified timezone.
+ Args:
+ timezone: A string representing a valid timezone (e.g., 'America/New_York').
+ """
+ try:
+ # Create timezone object
+ tz = pytz.timezone(timezone)
+ # Get current time in that timezone
+ local_time = datetime.datetime.now(tz).strftime("%Y-%m-%d %H:%M:%S")
+ return f"The current local time in {timezone} is: {local_time}"
+ except Exception as e:
+ return f"Error fetching time for timezone '{timezone}': {str(e)}"
+
+
+final_answer = FinalAnswerTool()
+model = InferenceClientModel(
+ max_tokens=2096,
+ temperature=0.5,
+ model_id='Qwen/Qwen2.5-Coder-32B-Instruct',
+ custom_role_conversions=None,
+)
+
+
+# Import tool from Hub
+image_generation_tool = load_tool("agents-course/text-to-image", trust_remote_code=True)
+
+# Load system prompt from prompt.yaml file
+with open("prompts.yaml", 'r') as stream:
+ prompt_templates = yaml.safe_load(stream)
+
+agent = CodeAgent(
+ model=model,
+ tools=[final_answer], # add your tools here (don't remove final_answer)
+ max_steps=6,
+ verbosity_level=1,
+ grammar=None,
+ planning_interval=None,
+ name=None,
+ description=None,
+ prompt_templates=prompt_templates # Pass system prompt to CodeAgent
+)
+
+
+GradioUI(agent).launch()
+```
+
+Seu **objetivo** é se familiarizar com o Space e com o agente.
+
+No momento, o agente do template **não usa nenhuma ferramenta — adicione as já prontas ou crie novas!**
+
+Estamos ansiosos para ver seus agentes no canal do Discord **#agents-course-showcase**!
+
+---
+
+Parabéns, você criou seu primeiro agente! Compartilhe com amigos e colegas.
+
+É normal que, nesta primeira tentativa, ele seja um pouco lento ou apresente algum problema. Nas próximas unidades aprenderemos a construir agentes ainda melhores.
+
+A melhor forma de aprender é praticar: atualize, adicione ferramentas, teste outros modelos…
+
+Na próxima seção você fará o Quiz final e poderá pegar seu certificado!
diff --git a/units/pt_br/unit1/what-are-agents.mdx b/units/pt_br/unit1/what-are-agents.mdx
new file mode 100644
index 00000000..5b098597
--- /dev/null
+++ b/units/pt_br/unit1/what-are-agents.mdx
@@ -0,0 +1,159 @@
+# O que é um Agente?
+
+
+
+Ao final desta seção, você estará à vontade com o conceito de agentes e suas diversas aplicações em IA.
+
+Para explicar o que é um agente, vamos começar com uma analogia.
+
+## A visão geral: Alfred, o agente
+
+Conheça Alfred. Alfred é um **agente**.
+
+ +
+Imagine que Alfred **receba um comando**, como: "Alfred, eu gostaria de um café, por favor."
+
+
+
+Imagine que Alfred **receba um comando**, como: "Alfred, eu gostaria de um café, por favor."
+
+ +
+Como Alfred **entende linguagem natural**, ele compreende rapidamente o pedido.
+
+Antes de executar a tarefa, Alfred realiza **raciocínio e planejamento**, definindo os passos e ferramentas de que precisa:
+
+1. Ir até a cozinha
+2. Usar a cafeteira
+3. Preparar o café
+4. Trazer o café de volta
+
+
+
+Como Alfred **entende linguagem natural**, ele compreende rapidamente o pedido.
+
+Antes de executar a tarefa, Alfred realiza **raciocínio e planejamento**, definindo os passos e ferramentas de que precisa:
+
+1. Ir até a cozinha
+2. Usar a cafeteira
+3. Preparar o café
+4. Trazer o café de volta
+
+ +
+Depois de traçar o plano, ele **precisa agir**. Para executar, **pode usar ferramentas da lista que conhece**.
+
+Neste caso, para fazer o café, ele usa uma cafeteira. Ele a ativa para preparar a bebida.
+
+
+
+Depois de traçar o plano, ele **precisa agir**. Para executar, **pode usar ferramentas da lista que conhece**.
+
+Neste caso, para fazer o café, ele usa uma cafeteira. Ele a ativa para preparar a bebida.
+
+ +
+Por fim, Alfred traz o café fresquinho para nós.
+
+
+
+Por fim, Alfred traz o café fresquinho para nós.
+
+ +
+É disso que se trata um agente: um **modelo de IA capaz de raciocinar, planejar e interagir com o ambiente**.
+
+Chamamos de agente porque ele tem _agência_, ou seja, a capacidade de agir sobre o ambiente.
+
+
+
+É disso que se trata um agente: um **modelo de IA capaz de raciocinar, planejar e interagir com o ambiente**.
+
+Chamamos de agente porque ele tem _agência_, ou seja, a capacidade de agir sobre o ambiente.
+
+ +
+## Indo para uma definição mais formal
+
+Agora que temos a visão geral, segue uma definição mais precisa:
+
+> Um agente é um sistema que utiliza um modelo de IA para interagir com seu ambiente a fim de atingir um objetivo definido pelo usuário. Ele combina raciocínio, planejamento e execução de ações (frequentemente por meio de ferramentas externas) para cumprir tarefas.
+
+Podemos imaginar o agente com duas partes principais:
+
+1. **O cérebro (modelo de IA)**
+
+É onde todo o pensamento acontece. O modelo de IA **cuida do raciocínio e do planejamento**, decidindo **quais ações executar de acordo com a situação**.
+
+2. **O corpo (capacidades e ferramentas)**
+
+Essa parte representa **tudo o que o agente está capacitado a fazer**.
+
+O **escopo de ações possíveis** depende do que o agente **tem à disposição**. Por exemplo, como humanos não possuem asas, não conseguem executar a ação “voar”, mas podem executar ações como “andar”, “correr”, “pular”, “segurar” e assim por diante.
+
+### O espectro de “agência”
+
+Seguindo essa definição, agentes existem em um espectro contínuo de agência crescente:
+
+| Agency Level | Description | What that's called | Example pattern |
+| --- | --- | --- | --- |
+| ☆☆☆ | A saída do agente não impacta o fluxo do programa | Processador simples | `process_llm_output(llm_response)` |
+| ★☆☆ | A saída define um fluxo de controle básico | Router | `if llm_decision(): path_a() else: path_b()` |
+| ★★☆ | A saída determina qual função executar | Chamador de ferramentas | `run_function(llm_chosen_tool, llm_chosen_args)` |
+| ★★★ | A saída controla iteração e continuação do programa | Agente multi-etapas | `while llm_should_continue(): execute_next_step()` |
+| ★★★ | Um fluxo agentivo pode iniciar outro fluxo agentivo | Multiagente | `if llm_trigger(): execute_agent()` |
+
+Tabela adaptada do [guia conceitual do smolagents](https://huggingface.co/docs/smolagents/conceptual_guides/intro_agents).
+
+
+## Que tipo de modelos de IA usamos em agentes?
+
+O modelo mais comum em agentes é o LLM (Large Language Model), que recebe **texto** como entrada e também gera **texto** como saída.
+
+Exemplos famosos são o **GPT-4** da **OpenAI**, o **Llama** da **Meta**, o **Gemini** da **Google**, etc. São modelos treinados em grandes quantidades de texto e capazes de generalizar bem. Vamos aprender mais sobre LLMs na [próxima seção](what-are-llms).
+
+> [!TIP]
+> Também é possível usar modelos que aceitam outros tipos de entrada como núcleo do agente. Por exemplo, um Vision Language Model (VLM), semelhante a um LLM mas que entende imagens. Por enquanto vamos focar em LLMs e discutiremos outras opções mais adiante.
+
+## Como uma IA age sobre o ambiente?
+
+LLMs são modelos incríveis, mas **só conseguem gerar texto**.
+
+Mesmo assim, se você pedir para aplicativos populares como HuggingChat ou ChatGPT gerarem uma imagem, eles conseguem! Como isso é possível?
+
+A resposta é que os desenvolvedores do HuggingChat, ChatGPT e similares implementaram funcionalidades adicionais (as **ferramentas**) que o LLM pode acionar para criar imagens.
+
+
+
+## Indo para uma definição mais formal
+
+Agora que temos a visão geral, segue uma definição mais precisa:
+
+> Um agente é um sistema que utiliza um modelo de IA para interagir com seu ambiente a fim de atingir um objetivo definido pelo usuário. Ele combina raciocínio, planejamento e execução de ações (frequentemente por meio de ferramentas externas) para cumprir tarefas.
+
+Podemos imaginar o agente com duas partes principais:
+
+1. **O cérebro (modelo de IA)**
+
+É onde todo o pensamento acontece. O modelo de IA **cuida do raciocínio e do planejamento**, decidindo **quais ações executar de acordo com a situação**.
+
+2. **O corpo (capacidades e ferramentas)**
+
+Essa parte representa **tudo o que o agente está capacitado a fazer**.
+
+O **escopo de ações possíveis** depende do que o agente **tem à disposição**. Por exemplo, como humanos não possuem asas, não conseguem executar a ação “voar”, mas podem executar ações como “andar”, “correr”, “pular”, “segurar” e assim por diante.
+
+### O espectro de “agência”
+
+Seguindo essa definição, agentes existem em um espectro contínuo de agência crescente:
+
+| Agency Level | Description | What that's called | Example pattern |
+| --- | --- | --- | --- |
+| ☆☆☆ | A saída do agente não impacta o fluxo do programa | Processador simples | `process_llm_output(llm_response)` |
+| ★☆☆ | A saída define um fluxo de controle básico | Router | `if llm_decision(): path_a() else: path_b()` |
+| ★★☆ | A saída determina qual função executar | Chamador de ferramentas | `run_function(llm_chosen_tool, llm_chosen_args)` |
+| ★★★ | A saída controla iteração e continuação do programa | Agente multi-etapas | `while llm_should_continue(): execute_next_step()` |
+| ★★★ | Um fluxo agentivo pode iniciar outro fluxo agentivo | Multiagente | `if llm_trigger(): execute_agent()` |
+
+Tabela adaptada do [guia conceitual do smolagents](https://huggingface.co/docs/smolagents/conceptual_guides/intro_agents).
+
+
+## Que tipo de modelos de IA usamos em agentes?
+
+O modelo mais comum em agentes é o LLM (Large Language Model), que recebe **texto** como entrada e também gera **texto** como saída.
+
+Exemplos famosos são o **GPT-4** da **OpenAI**, o **Llama** da **Meta**, o **Gemini** da **Google**, etc. São modelos treinados em grandes quantidades de texto e capazes de generalizar bem. Vamos aprender mais sobre LLMs na [próxima seção](what-are-llms).
+
+> [!TIP]
+> Também é possível usar modelos que aceitam outros tipos de entrada como núcleo do agente. Por exemplo, um Vision Language Model (VLM), semelhante a um LLM mas que entende imagens. Por enquanto vamos focar em LLMs e discutiremos outras opções mais adiante.
+
+## Como uma IA age sobre o ambiente?
+
+LLMs são modelos incríveis, mas **só conseguem gerar texto**.
+
+Mesmo assim, se você pedir para aplicativos populares como HuggingChat ou ChatGPT gerarem uma imagem, eles conseguem! Como isso é possível?
+
+A resposta é que os desenvolvedores do HuggingChat, ChatGPT e similares implementaram funcionalidades adicionais (as **ferramentas**) que o LLM pode acionar para criar imagens.
+
+ +
+ +
+Na seção anterior vimos que cada agente precisa **de um modelo de IA em seu núcleo** e que os LLMs são o tipo mais comum para essa finalidade.
+
+Agora vamos entender o que são LLMs e como eles impulsionam os agentes.
+
+Esta seção traz uma explicação técnica concisa sobre o uso de LLMs. Se quiser aprofundar, confira o nosso curso gratuito de Processamento de Linguagem Natural.
+
+## O que é um Large Language Model?
+
+Um LLM é um tipo de modelo de IA que se destaca em **compreender e gerar linguagem humana**. Ele é treinado em enormes quantidades de texto, aprendendo padrões, estrutura e nuances. Esses modelos geralmente possuem milhões ou bilhões de parâmetros.
+
+Hoje, a maioria dos LLMs é **baseada na arquitetura Transformer** — uma arquitetura de deep learning que utiliza o mecanismo de “Atenção” e ganhou notoriedade com o lançamento do BERT pelo Google em 2018.
+
+
+
+Na seção anterior vimos que cada agente precisa **de um modelo de IA em seu núcleo** e que os LLMs são o tipo mais comum para essa finalidade.
+
+Agora vamos entender o que são LLMs e como eles impulsionam os agentes.
+
+Esta seção traz uma explicação técnica concisa sobre o uso de LLMs. Se quiser aprofundar, confira o nosso curso gratuito de Processamento de Linguagem Natural.
+
+## O que é um Large Language Model?
+
+Um LLM é um tipo de modelo de IA que se destaca em **compreender e gerar linguagem humana**. Ele é treinado em enormes quantidades de texto, aprendendo padrões, estrutura e nuances. Esses modelos geralmente possuem milhões ou bilhões de parâmetros.
+
+Hoje, a maioria dos LLMs é **baseada na arquitetura Transformer** — uma arquitetura de deep learning que utiliza o mecanismo de “Atenção” e ganhou notoriedade com o lançamento do BERT pelo Google em 2018.
+
+ +
+| Modelo | +Provedor | +Token EOS | +Funcionalidade | +
|---|---|---|---|
| GPT4 | +OpenAI | +<|endoftext|> |
+ Fim do texto da mensagem | +
| Llama 3 | +Meta | +</s> |
+ Fim da sequência gerada | +
| Gemini | +<tool> |
+ Início da lista de ferramentas | +|
| SmolLM2 1.7B | +- | +<|im_end|> |
+ Fim da sequência gerada | +
 +
+---
+
+## Como acontece a decodificação?
+
+A ideia central é simples: fornecemos texto ao LLM e ele gera texto novo. Detalhando:
+
+1. **Tokenização** – transformamos o texto em tokens.
+ Exemplo: `"The capital of France is"` pode virar `["The", " capital", " of", " France", " is"]`.
+ Cada token vira um ID inteiro.
+
+2. **Entrada no modelo** – a sequência tokenizada alimenta o Transformer, que aprende as relações entre os tokens.
+
+3. **Geração de logits** – o modelo produz, para cada token do vocabulário, uma pontuação indicando a probabilidade de ser o próximo token (por exemplo, “ Paris” ganhar a maior pontuação).
+
+4. **Decodificação** – uma estratégia escolhe o próximo token com base nos logits. A opção mais simples é sempre pegar o maior valor (greedy). O token escolhido é acrescentado à saída e a nova sequência volta para o modelo, repetindo o processo até aparecer o token EOS (ou outra condição de parada).
+
+Seu LLM continuará gerando tokens até encontrar o EOS. Durante cada loop:
+
+- A entrada tokenizada é transformada em uma representação que guarda significado e posição.
+- Essa representação alimenta o modelo, que ranqueia todos os tokens pelo quão prováveis são de aparecer em seguida.
+
+
+
+---
+
+## Como acontece a decodificação?
+
+A ideia central é simples: fornecemos texto ao LLM e ele gera texto novo. Detalhando:
+
+1. **Tokenização** – transformamos o texto em tokens.
+ Exemplo: `"The capital of France is"` pode virar `["The", " capital", " of", " France", " is"]`.
+ Cada token vira um ID inteiro.
+
+2. **Entrada no modelo** – a sequência tokenizada alimenta o Transformer, que aprende as relações entre os tokens.
+
+3. **Geração de logits** – o modelo produz, para cada token do vocabulário, uma pontuação indicando a probabilidade de ser o próximo token (por exemplo, “ Paris” ganhar a maior pontuação).
+
+4. **Decodificação** – uma estratégia escolhe o próximo token com base nos logits. A opção mais simples é sempre pegar o maior valor (greedy). O token escolhido é acrescentado à saída e a nova sequência volta para o modelo, repetindo o processo até aparecer o token EOS (ou outra condição de parada).
+
+Seu LLM continuará gerando tokens até encontrar o EOS. Durante cada loop:
+
+- A entrada tokenizada é transformada em uma representação que guarda significado e posição.
+- Essa representação alimenta o modelo, que ranqueia todos os tokens pelo quão prováveis são de aparecer em seguida.
+
+ +
+Com essas pontuações, surgem várias estratégias de decodificação:
+
+- **Greedy decoding**: escolhe sempre o token com maior pontuação.
+- **Beam search**: explora várias sequências candidatas para encontrar a melhor pontuação total, mesmo que alguns tokens individuais tenham valores menores.
+
+Experimente o processo de decodificação com o SmolLM2 neste Space (o EOS para esse modelo é **<|im_end|>**):
+
+
+
+E veja o beam search funcionando:
+
+
+
+Para saber mais sobre decodificação, consulte o [curso de NLP](https://huggingface.co/learn/nlp-course).
+
+## Atenção é tudo de que você precisa
+
+Um pilar da arquitetura Transformer é a **Atenção**. Ao prever a próxima palavra, algumas possuem mais peso. Na frase *“The capital of France is ...”*, “France” e “capital” são determinantes.
+
+
+
+Com essas pontuações, surgem várias estratégias de decodificação:
+
+- **Greedy decoding**: escolhe sempre o token com maior pontuação.
+- **Beam search**: explora várias sequências candidatas para encontrar a melhor pontuação total, mesmo que alguns tokens individuais tenham valores menores.
+
+Experimente o processo de decodificação com o SmolLM2 neste Space (o EOS para esse modelo é **<|im_end|>**):
+
+
+
+E veja o beam search funcionando:
+
+
+
+Para saber mais sobre decodificação, consulte o [curso de NLP](https://huggingface.co/learn/nlp-course).
+
+## Atenção é tudo de que você precisa
+
+Um pilar da arquitetura Transformer é a **Atenção**. Ao prever a próxima palavra, algumas possuem mais peso. Na frase *“The capital of France is ...”*, “France” e “capital” são determinantes.
+
+ +
+Esse mecanismo de focar nas partes mais relevantes provou ser extremamente eficiente. Apesar do princípio de “prever o próximo token” se manter desde o GPT-2, houve grandes avanços em escalar as redes e ampliar o comprimento de contexto — ou seja, a quantidade de tokens que o modelo consegue considerar simultaneamente.
+
+## A importância do prompt
+
+Como o LLM decide qual token é mais provável, **a forma como você escreve o prompt** influencia diretamente o resultado. Um bom prompt ajuda a orientar a geração para o objetivo desejado.
+
+## Como os LLMs são treinados?
+
+LLMs são treinados em grandes corpora de texto, aprendendo a prever a próxima palavra (objetivo auto-supervisionado ou de linguagem mascarada). Assim, absorvem a estrutura da língua e **padrões que permitem generalizar para dados inéditos**.
+
+Depois do _pré-treinamento_, é comum realizar um fine-tuning supervisionado para tarefas específicas: conversação, uso de ferramentas, classificação, geração de código etc.
+
+## Como posso usar LLMs?
+
+Existem duas abordagens principais:
+
+1. **Rodar localmente** – se você tiver hardware suficiente.
+2. **Consumir via nuvem/API** – por exemplo, a Serverless Inference API do Hugging Face.
+
+No curso, utilizaremos principalmente modelos via API no Hugging Face Hub. Mais adiante veremos como executá-los localmente.
+
+## Como os LLMs são usados em agentes de IA?
+
+LLMs são uma peça central dos agentes: **eles interpretam instruções, mantêm contexto, planejam e decidem quais ferramentas acionar**. Ao longo desta unidade, detalharemos cada etapa, mas por ora basta lembrar: o LLM é **o cérebro do agente**.
+
+---
+
+Foi bastante informação! Vimos o que são LLMs, como funcionam e qual o papel deles nos agentes. Se quiser se aprofundar, confira o nosso curso gratuito de NLP.
+
+Agora que entendemos os LLMs, é hora de ver **como eles estruturam suas gerações em um contexto de conversa**.
+
+Para executar este notebook, **você precisa de um token da Hugging Face**, disponível em https://hf.co/settings/tokens.
+
+Para mais informações sobre como rodar Jupyter Notebooks, consulte Jupyter Notebooks no Hugging Face Hub.
+
+Você também precisa solicitar acesso aos modelos Meta Llama.
diff --git a/units/pt_br/unit2/introduction.mdx b/units/pt_br/unit2/introduction.mdx
new file mode 100644
index 00000000..44833b72
--- /dev/null
+++ b/units/pt_br/unit2/introduction.mdx
@@ -0,0 +1,40 @@
+# Introdução aos Frameworks Agênticos
+
+
+
+Esse mecanismo de focar nas partes mais relevantes provou ser extremamente eficiente. Apesar do princípio de “prever o próximo token” se manter desde o GPT-2, houve grandes avanços em escalar as redes e ampliar o comprimento de contexto — ou seja, a quantidade de tokens que o modelo consegue considerar simultaneamente.
+
+## A importância do prompt
+
+Como o LLM decide qual token é mais provável, **a forma como você escreve o prompt** influencia diretamente o resultado. Um bom prompt ajuda a orientar a geração para o objetivo desejado.
+
+## Como os LLMs são treinados?
+
+LLMs são treinados em grandes corpora de texto, aprendendo a prever a próxima palavra (objetivo auto-supervisionado ou de linguagem mascarada). Assim, absorvem a estrutura da língua e **padrões que permitem generalizar para dados inéditos**.
+
+Depois do _pré-treinamento_, é comum realizar um fine-tuning supervisionado para tarefas específicas: conversação, uso de ferramentas, classificação, geração de código etc.
+
+## Como posso usar LLMs?
+
+Existem duas abordagens principais:
+
+1. **Rodar localmente** – se você tiver hardware suficiente.
+2. **Consumir via nuvem/API** – por exemplo, a Serverless Inference API do Hugging Face.
+
+No curso, utilizaremos principalmente modelos via API no Hugging Face Hub. Mais adiante veremos como executá-los localmente.
+
+## Como os LLMs são usados em agentes de IA?
+
+LLMs são uma peça central dos agentes: **eles interpretam instruções, mantêm contexto, planejam e decidem quais ferramentas acionar**. Ao longo desta unidade, detalharemos cada etapa, mas por ora basta lembrar: o LLM é **o cérebro do agente**.
+
+---
+
+Foi bastante informação! Vimos o que são LLMs, como funcionam e qual o papel deles nos agentes. Se quiser se aprofundar, confira o nosso curso gratuito de NLP.
+
+Agora que entendemos os LLMs, é hora de ver **como eles estruturam suas gerações em um contexto de conversa**.
+
+Para executar este notebook, **você precisa de um token da Hugging Face**, disponível em https://hf.co/settings/tokens.
+
+Para mais informações sobre como rodar Jupyter Notebooks, consulte Jupyter Notebooks no Hugging Face Hub.
+
+Você também precisa solicitar acesso aos modelos Meta Llama.
diff --git a/units/pt_br/unit2/introduction.mdx b/units/pt_br/unit2/introduction.mdx
new file mode 100644
index 00000000..44833b72
--- /dev/null
+++ b/units/pt_br/unit2/introduction.mdx
@@ -0,0 +1,40 @@
+# Introdução aos Frameworks Agênticos
+
+ +
+Bem-vindo à segunda unidade, onde **vamos explorar diferentes frameworks agênticos** que ajudam a construir aplicações poderosas com agentes.
+
+Estudaremos:
+
+- Na Unidade 2.1: [smolagents](https://huggingface.co/docs/smolagents/en/index)
+- Na Unidade 2.2: [LlamaIndex](https://www.llamaindex.ai/)
+- Na Unidade 2.3: [LangGraph](https://www.langchain.com/langgraph)
+
+Vamos nessa! 🕵
+
+## Quando usar um framework agêntico?
+
+Um framework agêntico **nem sempre é necessário** ao construir uma aplicação com LLMs. Ele oferece flexibilidade para resolver tarefas de modo eficiente, mas pode ser dispensável em alguns cenários.
+
+Às vezes, **fluxos pré-definidos são suficientes** para atender aos usuários, e não há necessidade de um framework completo. Se a abordagem for simples, como uma cadeia de prompts, código direto pode bastar — com a vantagem de o desenvolvedor manter **total controle do sistema, sem camadas extras**.
+
+Por outro lado, quando o fluxo fica mais complexo — por exemplo, ao permitir que o LLM chame funções ou coordenar múltiplos agentes — essas abstrações passam a ser úteis.
+
+Com base nisso, já identificamos alguns requisitos comuns:
+
+* Um *motor de LLM* que impulsiona o sistema.
+* Uma *lista de ferramentas* acessível ao agente.
+* Um *parser* para extrair chamadas de ferramentas da saída do LLM.
+* Um *system prompt* alinhado ao parser.
+* Um *sistema de memória*.
+* *Logs de erro e mecanismos de retry* para lidar com falhas do LLM.
+
+Veremos como esses pontos são tratados em frameworks como `smolagents`, `LlamaIndex` e `LangGraph`.
+
+## Unidades sobre Frameworks Agênticos
+
+| Framework | Descrição | Autor da Unidade |
+|------------|-----------|------------------|
+| [smolagents](./smolagents/introduction) | Framework de agentes desenvolvido pela Hugging Face. | Sergio Paniego — [HF](https://huggingface.co/sergiopaniego) — [X](https://x.com/sergiopaniego) — [LinkedIn](https://www.linkedin.com/in/sergio-paniego-blanco) |
+| [LlamaIndex](./llama-index/introduction) | Ferramentas de ponta a ponta para levar agentes contextuais à produção. | David Berenstein — [HF](https://huggingface.co/davidberenstein1957) — [X](https://x.com/davidberenstei) — [LinkedIn](https://www.linkedin.com/in/davidberenstein) |
+| [LangGraph](./langgraph/introduction) | Framework para orquestração com estado entre agentes. | Joffrey Thomas — [HF](https://huggingface.co/Jofthomas) — [X](https://x.com/Jthmas404) — [LinkedIn](https://www.linkedin.com/in/joffrey-thomas) |
diff --git a/units/pt_br/unit2/langgraph/building_blocks.mdx b/units/pt_br/unit2/langgraph/building_blocks.mdx
new file mode 100644
index 00000000..9c57f8f7
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/building_blocks.mdx
@@ -0,0 +1,127 @@
+# Blocos de construção do LangGraph
+
+Para criar aplicações com o LangGraph, é essencial conhecer seus componentes principais. Vamos explorar os blocos que compõem uma aplicação nesse framework.
+
+
+
+Bem-vindo à segunda unidade, onde **vamos explorar diferentes frameworks agênticos** que ajudam a construir aplicações poderosas com agentes.
+
+Estudaremos:
+
+- Na Unidade 2.1: [smolagents](https://huggingface.co/docs/smolagents/en/index)
+- Na Unidade 2.2: [LlamaIndex](https://www.llamaindex.ai/)
+- Na Unidade 2.3: [LangGraph](https://www.langchain.com/langgraph)
+
+Vamos nessa! 🕵
+
+## Quando usar um framework agêntico?
+
+Um framework agêntico **nem sempre é necessário** ao construir uma aplicação com LLMs. Ele oferece flexibilidade para resolver tarefas de modo eficiente, mas pode ser dispensável em alguns cenários.
+
+Às vezes, **fluxos pré-definidos são suficientes** para atender aos usuários, e não há necessidade de um framework completo. Se a abordagem for simples, como uma cadeia de prompts, código direto pode bastar — com a vantagem de o desenvolvedor manter **total controle do sistema, sem camadas extras**.
+
+Por outro lado, quando o fluxo fica mais complexo — por exemplo, ao permitir que o LLM chame funções ou coordenar múltiplos agentes — essas abstrações passam a ser úteis.
+
+Com base nisso, já identificamos alguns requisitos comuns:
+
+* Um *motor de LLM* que impulsiona o sistema.
+* Uma *lista de ferramentas* acessível ao agente.
+* Um *parser* para extrair chamadas de ferramentas da saída do LLM.
+* Um *system prompt* alinhado ao parser.
+* Um *sistema de memória*.
+* *Logs de erro e mecanismos de retry* para lidar com falhas do LLM.
+
+Veremos como esses pontos são tratados em frameworks como `smolagents`, `LlamaIndex` e `LangGraph`.
+
+## Unidades sobre Frameworks Agênticos
+
+| Framework | Descrição | Autor da Unidade |
+|------------|-----------|------------------|
+| [smolagents](./smolagents/introduction) | Framework de agentes desenvolvido pela Hugging Face. | Sergio Paniego — [HF](https://huggingface.co/sergiopaniego) — [X](https://x.com/sergiopaniego) — [LinkedIn](https://www.linkedin.com/in/sergio-paniego-blanco) |
+| [LlamaIndex](./llama-index/introduction) | Ferramentas de ponta a ponta para levar agentes contextuais à produção. | David Berenstein — [HF](https://huggingface.co/davidberenstein1957) — [X](https://x.com/davidberenstei) — [LinkedIn](https://www.linkedin.com/in/davidberenstein) |
+| [LangGraph](./langgraph/introduction) | Framework para orquestração com estado entre agentes. | Joffrey Thomas — [HF](https://huggingface.co/Jofthomas) — [X](https://x.com/Jthmas404) — [LinkedIn](https://www.linkedin.com/in/joffrey-thomas) |
diff --git a/units/pt_br/unit2/langgraph/building_blocks.mdx b/units/pt_br/unit2/langgraph/building_blocks.mdx
new file mode 100644
index 00000000..9c57f8f7
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/building_blocks.mdx
@@ -0,0 +1,127 @@
+# Blocos de construção do LangGraph
+
+Para criar aplicações com o LangGraph, é essencial conhecer seus componentes principais. Vamos explorar os blocos que compõem uma aplicação nesse framework.
+
+ +
+Uma aplicação em LangGraph parte de um **entrypoint** e, conforme a execução, segue para funções diferentes até alcançar o `END`.
+
+
+
+Uma aplicação em LangGraph parte de um **entrypoint** e, conforme a execução, segue para funções diferentes até alcançar o `END`.
+
+ +
+## 1. State
+
+**State** (estado) é o conceito central. Representa todas as informações que percorrem a aplicação.
+
+```python
+from typing_extensions import TypedDict
+
+class State(TypedDict):
+ graph_state: str
+```
+
+O estado é **definido pelo usuário**, portanto os campos devem conter tudo que for necessário para tomar decisões.
+
+> 💡 **Dica:** reflita com cuidado sobre quais informações precisam ser rastreadas entre as etapas.
+
+## 2. Nodes
+
+**Nodes** são funções Python. Cada nó:
+- Recebe o estado como entrada;
+- Executa alguma operação;
+- Retorna atualizações para o estado.
+
+```python
+def node_1(state):
+ print("---Node 1---")
+ return {"graph_state": state['graph_state'] +" I am"}
+
+def node_2(state):
+ print("---Node 2---")
+ return {"graph_state": state['graph_state'] +" happy!"}
+
+def node_3(state):
+ print("---Node 3---")
+ return {"graph_state": state['graph_state'] +" sad!"}
+```
+
+Por exemplo, nós podem conter:
+- **Chamadas a LLMs** — gerar texto ou tomar decisões;
+- **Chamadas a ferramentas** — interagir com sistemas externos;
+- **Lógica condicional** — decidir o próximo passo;
+- **Intervenção humana** — solicitar input do usuário.
+
+> 💡 **Info:** Alguns nós, como `START` e `END`, são fornecidos diretamente pelo LangGraph.
+
+
+## 3. Edges
+
+**Edges** conectam os nós e definem os caminhos possíveis:
+
+```python
+import random
+from typing import Literal
+
+def decide_mood(state) -> Literal["node_2", "node_3"]:
+
+ # Often, we will use state to decide on the next node to visit
+ user_input = state['graph_state']
+
+ # Here, let's just do a 50 / 50 split between nodes 2, 3
+ if random.random() < 0.5:
+
+ # 50% of the time, we return Node 2
+ return "node_2"
+
+ # 50% of the time, we return Node 3
+ return "node_3"
+```
+
+As arestas podem ser:
+- **Diretas** — sempre ligam o nó A ao nó B;
+- **Condicionais** — escolhem o próximo nó com base no estado atual.
+
+## 4. StateGraph
+
+O **StateGraph** é o contêiner que reúne todo o workflow:
+
+```python
+from IPython.display import Image, display
+from langgraph.graph import StateGraph, START, END
+
+# Build graph
+builder = StateGraph(State)
+builder.add_node("node_1", node_1)
+builder.add_node("node_2", node_2)
+builder.add_node("node_3", node_3)
+
+# Logic
+builder.add_edge(START, "node_1")
+builder.add_conditional_edges("node_1", decide_mood)
+builder.add_edge("node_2", END)
+builder.add_edge("node_3", END)
+
+# Add
+graph = builder.compile()
+```
+
+Depois podemos visualizar:
+```python
+# View
+display(Image(graph.get_graph().draw_mermaid_png()))
+```
+
+
+## 1. State
+
+**State** (estado) é o conceito central. Representa todas as informações que percorrem a aplicação.
+
+```python
+from typing_extensions import TypedDict
+
+class State(TypedDict):
+ graph_state: str
+```
+
+O estado é **definido pelo usuário**, portanto os campos devem conter tudo que for necessário para tomar decisões.
+
+> 💡 **Dica:** reflita com cuidado sobre quais informações precisam ser rastreadas entre as etapas.
+
+## 2. Nodes
+
+**Nodes** são funções Python. Cada nó:
+- Recebe o estado como entrada;
+- Executa alguma operação;
+- Retorna atualizações para o estado.
+
+```python
+def node_1(state):
+ print("---Node 1---")
+ return {"graph_state": state['graph_state'] +" I am"}
+
+def node_2(state):
+ print("---Node 2---")
+ return {"graph_state": state['graph_state'] +" happy!"}
+
+def node_3(state):
+ print("---Node 3---")
+ return {"graph_state": state['graph_state'] +" sad!"}
+```
+
+Por exemplo, nós podem conter:
+- **Chamadas a LLMs** — gerar texto ou tomar decisões;
+- **Chamadas a ferramentas** — interagir com sistemas externos;
+- **Lógica condicional** — decidir o próximo passo;
+- **Intervenção humana** — solicitar input do usuário.
+
+> 💡 **Info:** Alguns nós, como `START` e `END`, são fornecidos diretamente pelo LangGraph.
+
+
+## 3. Edges
+
+**Edges** conectam os nós e definem os caminhos possíveis:
+
+```python
+import random
+from typing import Literal
+
+def decide_mood(state) -> Literal["node_2", "node_3"]:
+
+ # Often, we will use state to decide on the next node to visit
+ user_input = state['graph_state']
+
+ # Here, let's just do a 50 / 50 split between nodes 2, 3
+ if random.random() < 0.5:
+
+ # 50% of the time, we return Node 2
+ return "node_2"
+
+ # 50% of the time, we return Node 3
+ return "node_3"
+```
+
+As arestas podem ser:
+- **Diretas** — sempre ligam o nó A ao nó B;
+- **Condicionais** — escolhem o próximo nó com base no estado atual.
+
+## 4. StateGraph
+
+O **StateGraph** é o contêiner que reúne todo o workflow:
+
+```python
+from IPython.display import Image, display
+from langgraph.graph import StateGraph, START, END
+
+# Build graph
+builder = StateGraph(State)
+builder.add_node("node_1", node_1)
+builder.add_node("node_2", node_2)
+builder.add_node("node_3", node_3)
+
+# Logic
+builder.add_edge(START, "node_1")
+builder.add_conditional_edges("node_1", decide_mood)
+builder.add_edge("node_2", END)
+builder.add_edge("node_3", END)
+
+# Add
+graph = builder.compile()
+```
+
+Depois podemos visualizar:
+```python
+# View
+display(Image(graph.get_graph().draw_mermaid_png()))
+```
+ +
+E, o mais importante, invocar:
+```python
+graph.invoke({"graph_state" : "Hi, this is Lance."})
+```
+Saída:
+```
+---Node 1---
+---Node 3---
+{'graph_state': 'Hi, this is Lance. I am sad!'}
+```
+
+## O que vem a seguir?
+
+Na próxima seção, vamos colocar os conceitos em prática construindo nosso primeiro grafo. Alfred passará a receber seus e-mails, classificá-los e elaborar uma resposta preliminar sempre que forem legítimos.
diff --git a/units/pt_br/unit2/langgraph/conclusion.mdx b/units/pt_br/unit2/langgraph/conclusion.mdx
new file mode 100644
index 00000000..9d1f73a0
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/conclusion.mdx
@@ -0,0 +1,20 @@
+# Conclusão
+
+Parabéns por concluir o módulo de `LangGraph` desta segunda unidade! 🥳
+
+Agora você domina os fundamentos para construir workflows estruturados com LangGraph — prontos até para produção.
+
+Este módulo é só o começo. Para avançar, sugerimos:
+
+- Explorar a [documentação oficial do LangGraph](https://github.com/langchain-ai/langgraph);
+- Fazer o curso [Introduction to LangGraph](https://academy.langchain.com/courses/intro-to-langgraph) da LangChain Academy;
+- Construir algo por conta própria!
+
+Na próxima unidade, entraremos em casos de uso reais. Hora de deixar a teoria e partir para a ação!
+
+Adoraríamos saber **o que você está achando do curso e como podemos melhorar**. Se tiver feedback, por favor 👉 [preencha este formulário](https://docs.google.com/forms/d/e/1FAIpQLSe9VaONn0eglax0uTwi29rIn4tM7H2sYmmybmG5jJNlE5v0xA/viewform?usp=dialog)
+
+### Continue aprendendo e sendo incrível! 🤗
+
+Com meus melhores cumprimentos, 🎩🦇
+— Alfred
diff --git a/units/pt_br/unit2/langgraph/document_analysis_agent.mdx b/units/pt_br/unit2/langgraph/document_analysis_agent.mdx
new file mode 100644
index 00000000..ba9887a0
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/document_analysis_agent.mdx
@@ -0,0 +1,264 @@
+# Grafo de análise de documentos
+
+À disposição: Alfred, mordomo de confiança do Sr. Wayne. Enquanto ele cuida de… atividades noturnas, garanto que toda a papelada, cronogramas de treino e planos alimentares estejam organizados e analisados.
+
+Antes de sair, ele deixou um bilhete com o treino da semana. Tomei a liberdade de preparar um **menu** para as refeições de amanhã.
+
+Para agilizar futuros pedidos, vamos criar um sistema de análise de documentos com LangGraph que possa:
+
+1. Processar imagens de documentos;
+2. Extrair texto usando modelos multimodais (Vision Language Models);
+3. Realizar cálculos quando necessário;
+4. Analisar o conteúdo e gerar resumos;
+5. Executar instruções específicas relacionadas aos documentos.
+
+## Workflow do mordomo
+
+O fluxo seguirá a estrutura abaixo:
+
+
+
+> [!TIP]
+> You can follow the code in this notebook that you can run using Google Colab.
+
+## Preparando o ambiente
+
+```python
+%pip install langgraph langchain_openai langchain_core
+```
+and imports :
+```python
+import base64
+from typing import List, TypedDict, Annotated, Optional
+from langchain_openai import ChatOpenAI
+from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage
+from langgraph.graph.message import add_messages
+from langgraph.graph import START, StateGraph
+from langgraph.prebuilt import ToolNode, tools_condition
+from IPython.display import Image, display
+```
+
+## Definindo o estado do agente
+
+Este estado é um pouco mais complexo.
+`AnyMessage` é uma classe do LangChain que representa mensagens, e `add_messages` é um operador que acrescenta novas mensagens em vez de sobrescrever o histórico.
+
+Esse é um conceito novo: podemos adicionar operadores ao estado para controlar como os dados se combinam.
+
+```python
+class AgentState(TypedDict):
+ # The document provided
+ input_file: Optional[str] # Contains file path (PDF/PNG)
+ messages: Annotated[list[AnyMessage], add_messages]
+```
+
+## Preparando as ferramentas
+
+```python
+vision_llm = ChatOpenAI(model="gpt-4o")
+
+def extract_text(img_path: str) -> str:
+ """
+ Extract text from an image file using a multimodal model.
+
+ Master Wayne often leaves notes with his training regimen or meal plans.
+ This allows me to properly analyze the contents.
+ """
+ all_text = ""
+ try:
+ # Read image and encode as base64
+ with open(img_path, "rb") as image_file:
+ image_bytes = image_file.read()
+
+ image_base64 = base64.b64encode(image_bytes).decode("utf-8")
+
+ # Prepare the prompt including the base64 image data
+ message = [
+ HumanMessage(
+ content=[
+ {
+ "type": "text",
+ "text": (
+ "Extract all the text from this image. "
+ "Return only the extracted text, no explanations."
+ ),
+ },
+ {
+ "type": "image_url",
+ "image_url": {
+ "url": f"data:image/png;base64,{image_base64}"
+ },
+ },
+ ]
+ )
+ ]
+
+ # Call the vision-capable model
+ response = vision_llm.invoke(message)
+
+ # Append extracted text
+ all_text += response.content + "\n\n"
+
+ return all_text.strip()
+ except Exception as e:
+ # A butler should handle errors gracefully
+ error_msg = f"Error extracting text: {str(e)}"
+ print(error_msg)
+ return ""
+
+def divide(a: int, b: int) -> float:
+ """Divide a and b - for Master Wayne's occasional calculations."""
+ return a / b
+
+# Equip the butler with tools
+tools = [
+ divide,
+ extract_text
+]
+
+llm = ChatOpenAI(model="gpt-4o")
+llm_with_tools = llm.bind_tools(tools, parallel_tool_calls=False)
+```
+
+## Os nós
+
+```python
+def assistant(state: AgentState):
+ # System message
+ textual_description_of_tool="""
+extract_text(img_path: str) -> str:
+ Extract text from an image file using a multimodal model.
+
+ Args:
+ img_path: A local image file path (strings).
+
+ Returns:
+ A single string containing the concatenated text extracted from each image.
+divide(a: int, b: int) -> float:
+ Divide a and b
+"""
+ image=state["input_file"]
+ sys_msg = SystemMessage(content=f"You are a helpful butler named Alfred that serves Mr. Wayne and Batman. You can analyse documents and run computations with provided tools:\n{textual_description_of_tool} \n You have access to some optional images. Currently the loaded image is: {image}")
+
+ return {
+ "messages": [llm_with_tools.invoke([sys_msg] + state["messages"])],
+ "input_file": state["input_file"]
+ }
+```
+
+## Padrão ReAct: como assisto o Sr. Wayne
+
+Este agente segue o padrão ReAct (Reason-Act-Observe):
+
+1. **Reason** — raciocina sobre documentos e pedidos.
+2. **Act** — usa as ferramentas adequadas.
+3. **Observe** — verifica os resultados.
+4. **Repeat** — repete até atender à solicitação.
+
+É uma implementação simples de agente no LangGraph.
+
+```python
+# The graph
+builder = StateGraph(AgentState)
+
+# Define nodes: these do the work
+builder.add_node("assistant", assistant)
+builder.add_node("tools", ToolNode(tools))
+
+# Define edges: these determine how the control flow moves
+builder.add_edge(START, "assistant")
+builder.add_conditional_edges(
+ "assistant",
+ # If the latest message requires a tool, route to tools
+ # Otherwise, provide a direct response
+ tools_condition,
+)
+builder.add_edge("tools", "assistant")
+react_graph = builder.compile()
+
+# Show the butler's thought process
+display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))
+```
+
+Definimos um nó `tools` com a lista de ferramentas. O nó `assistant` é o modelo com as ferramentas vinculadas.
+
+Adicionamos uma aresta condicional `tools_condition`, que decide entre `END` ou `tools` conforme o `assistant` chame (ou não) uma ferramenta.
+
+Em seguida, conectamos `tools` de volta ao `assistant`, formando um loop:
+
+- Após executar, `tools_condition` verifica se houve chamada de ferramenta.
+- Caso sim, direciona para `tools`.
+- O nó `tools` retorna ao `assistant`.
+- O ciclo continua enquanto o modelo decidir usar ferramentas.
+- Se a resposta não for uma chamada de ferramenta, o fluxo segue para `END`.
+
+
+
+## O mordomo em ação
+
+### Exemplo 1: cálculos simples
+
+Um exemplo rápido de agente usando ferramenta:
+
+```python
+messages = [HumanMessage(content="Divide 6790 by 5")]
+messages = react_graph.invoke({"messages": messages, "input_file": None})
+
+# Show the messages
+for m in messages['messages']:
+ m.pretty_print()
+```
+
+A conversa ficaria:
+
+```
+Human: Divide 6790 by 5
+
+AI Tool Call: divide(a=6790, b=5)
+
+Tool Response: 1358.0
+
+Alfred: The result of dividing 6790 by 5 is 1358.0.
+```
+
+### Exemplo 2: analisando o treino do Sr. Wayne
+
+Quando o Sr. Wayne deixa anotações de treino e refeição:
+
+```python
+messages = [HumanMessage(content="According to the note provided by Mr. Wayne in the provided images. What's the list of items I should buy for the dinner menu?")]
+messages = react_graph.invoke({"messages": messages, "input_file": "Batman_training_and_meals.png"})
+```
+
+Resultado:
+
+```
+Human: According to the note provided by Mr. Wayne in the provided images. What's the list of items I should buy for the dinner menu?
+
+AI Tool Call: extract_text(img_path="Batman_training_and_meals.png")
+
+Tool Response: [Extracted text with training schedule and menu details]
+
+Alfred: For the dinner menu, you should buy the following items:
+
+1. Grass-fed local sirloin steak
+2. Organic spinach
+3. Piquillo peppers
+4. Potatoes (for oven-baked golden herb potato)
+5. Fish oil (2 grams)
+
+Ensure the steak is grass-fed and the spinach and peppers are organic for the best quality meal.
+```
+
+## Principais pontos
+
+Para criar seu próprio mordomo de análise de documentos:
+
+1. **Define clear tools** for specific document-related tasks
+2. **Create a robust state tracker** to maintain context between tool calls
+3. **Consider error handling** for tool failures
+4. **Maintain contextual awareness** of previous interactions (ensured by the operator `add_messages`)
+
+Com esses princípios, você também pode oferecer um serviço de análise digno da Mansão Wayne.
+
+*Espero ter sido claro. Agora, se me permite, preciso passar a capa do Sr. Wayne antes das atividades noturnas.*
diff --git a/units/pt_br/unit2/langgraph/first_graph.mdx b/units/pt_br/unit2/langgraph/first_graph.mdx
new file mode 100644
index 00000000..cd60dbba
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/first_graph.mdx
@@ -0,0 +1,374 @@
+# Construindo seu primeiro LangGraph
+
+Agora que entendemos os blocos fundamentais, vamos montar nosso primeiro grafo funcional. Implementaremos o sistema de triagem de e-mails do Alfred, em que ele deve:
+
+1. Read incoming emails
+2. Classify them as spam or legitimate
+3. Draft a preliminary response for legitimate emails
+4. Send information to Mr. Wayne when legitimate (printing only)
+
+This example demonstrates how to structure a workflow with LangGraph that involves LLM-based decision-making. While this can't be considered an Agent as no tool is involved, this section focuses more on learning the LangGraph framework than Agents.
+
+> [!TIP]
+> You can follow the code in this notebook that you can run using Google Colab.
+
+## Nosso workflow
+
+Este é o fluxo que construiremos:
+
+
+E, o mais importante, invocar:
+```python
+graph.invoke({"graph_state" : "Hi, this is Lance."})
+```
+Saída:
+```
+---Node 1---
+---Node 3---
+{'graph_state': 'Hi, this is Lance. I am sad!'}
+```
+
+## O que vem a seguir?
+
+Na próxima seção, vamos colocar os conceitos em prática construindo nosso primeiro grafo. Alfred passará a receber seus e-mails, classificá-los e elaborar uma resposta preliminar sempre que forem legítimos.
diff --git a/units/pt_br/unit2/langgraph/conclusion.mdx b/units/pt_br/unit2/langgraph/conclusion.mdx
new file mode 100644
index 00000000..9d1f73a0
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/conclusion.mdx
@@ -0,0 +1,20 @@
+# Conclusão
+
+Parabéns por concluir o módulo de `LangGraph` desta segunda unidade! 🥳
+
+Agora você domina os fundamentos para construir workflows estruturados com LangGraph — prontos até para produção.
+
+Este módulo é só o começo. Para avançar, sugerimos:
+
+- Explorar a [documentação oficial do LangGraph](https://github.com/langchain-ai/langgraph);
+- Fazer o curso [Introduction to LangGraph](https://academy.langchain.com/courses/intro-to-langgraph) da LangChain Academy;
+- Construir algo por conta própria!
+
+Na próxima unidade, entraremos em casos de uso reais. Hora de deixar a teoria e partir para a ação!
+
+Adoraríamos saber **o que você está achando do curso e como podemos melhorar**. Se tiver feedback, por favor 👉 [preencha este formulário](https://docs.google.com/forms/d/e/1FAIpQLSe9VaONn0eglax0uTwi29rIn4tM7H2sYmmybmG5jJNlE5v0xA/viewform?usp=dialog)
+
+### Continue aprendendo e sendo incrível! 🤗
+
+Com meus melhores cumprimentos, 🎩🦇
+— Alfred
diff --git a/units/pt_br/unit2/langgraph/document_analysis_agent.mdx b/units/pt_br/unit2/langgraph/document_analysis_agent.mdx
new file mode 100644
index 00000000..ba9887a0
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/document_analysis_agent.mdx
@@ -0,0 +1,264 @@
+# Grafo de análise de documentos
+
+À disposição: Alfred, mordomo de confiança do Sr. Wayne. Enquanto ele cuida de… atividades noturnas, garanto que toda a papelada, cronogramas de treino e planos alimentares estejam organizados e analisados.
+
+Antes de sair, ele deixou um bilhete com o treino da semana. Tomei a liberdade de preparar um **menu** para as refeições de amanhã.
+
+Para agilizar futuros pedidos, vamos criar um sistema de análise de documentos com LangGraph que possa:
+
+1. Processar imagens de documentos;
+2. Extrair texto usando modelos multimodais (Vision Language Models);
+3. Realizar cálculos quando necessário;
+4. Analisar o conteúdo e gerar resumos;
+5. Executar instruções específicas relacionadas aos documentos.
+
+## Workflow do mordomo
+
+O fluxo seguirá a estrutura abaixo:
+
+
+
+> [!TIP]
+> You can follow the code in this notebook that you can run using Google Colab.
+
+## Preparando o ambiente
+
+```python
+%pip install langgraph langchain_openai langchain_core
+```
+and imports :
+```python
+import base64
+from typing import List, TypedDict, Annotated, Optional
+from langchain_openai import ChatOpenAI
+from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage
+from langgraph.graph.message import add_messages
+from langgraph.graph import START, StateGraph
+from langgraph.prebuilt import ToolNode, tools_condition
+from IPython.display import Image, display
+```
+
+## Definindo o estado do agente
+
+Este estado é um pouco mais complexo.
+`AnyMessage` é uma classe do LangChain que representa mensagens, e `add_messages` é um operador que acrescenta novas mensagens em vez de sobrescrever o histórico.
+
+Esse é um conceito novo: podemos adicionar operadores ao estado para controlar como os dados se combinam.
+
+```python
+class AgentState(TypedDict):
+ # The document provided
+ input_file: Optional[str] # Contains file path (PDF/PNG)
+ messages: Annotated[list[AnyMessage], add_messages]
+```
+
+## Preparando as ferramentas
+
+```python
+vision_llm = ChatOpenAI(model="gpt-4o")
+
+def extract_text(img_path: str) -> str:
+ """
+ Extract text from an image file using a multimodal model.
+
+ Master Wayne often leaves notes with his training regimen or meal plans.
+ This allows me to properly analyze the contents.
+ """
+ all_text = ""
+ try:
+ # Read image and encode as base64
+ with open(img_path, "rb") as image_file:
+ image_bytes = image_file.read()
+
+ image_base64 = base64.b64encode(image_bytes).decode("utf-8")
+
+ # Prepare the prompt including the base64 image data
+ message = [
+ HumanMessage(
+ content=[
+ {
+ "type": "text",
+ "text": (
+ "Extract all the text from this image. "
+ "Return only the extracted text, no explanations."
+ ),
+ },
+ {
+ "type": "image_url",
+ "image_url": {
+ "url": f"data:image/png;base64,{image_base64}"
+ },
+ },
+ ]
+ )
+ ]
+
+ # Call the vision-capable model
+ response = vision_llm.invoke(message)
+
+ # Append extracted text
+ all_text += response.content + "\n\n"
+
+ return all_text.strip()
+ except Exception as e:
+ # A butler should handle errors gracefully
+ error_msg = f"Error extracting text: {str(e)}"
+ print(error_msg)
+ return ""
+
+def divide(a: int, b: int) -> float:
+ """Divide a and b - for Master Wayne's occasional calculations."""
+ return a / b
+
+# Equip the butler with tools
+tools = [
+ divide,
+ extract_text
+]
+
+llm = ChatOpenAI(model="gpt-4o")
+llm_with_tools = llm.bind_tools(tools, parallel_tool_calls=False)
+```
+
+## Os nós
+
+```python
+def assistant(state: AgentState):
+ # System message
+ textual_description_of_tool="""
+extract_text(img_path: str) -> str:
+ Extract text from an image file using a multimodal model.
+
+ Args:
+ img_path: A local image file path (strings).
+
+ Returns:
+ A single string containing the concatenated text extracted from each image.
+divide(a: int, b: int) -> float:
+ Divide a and b
+"""
+ image=state["input_file"]
+ sys_msg = SystemMessage(content=f"You are a helpful butler named Alfred that serves Mr. Wayne and Batman. You can analyse documents and run computations with provided tools:\n{textual_description_of_tool} \n You have access to some optional images. Currently the loaded image is: {image}")
+
+ return {
+ "messages": [llm_with_tools.invoke([sys_msg] + state["messages"])],
+ "input_file": state["input_file"]
+ }
+```
+
+## Padrão ReAct: como assisto o Sr. Wayne
+
+Este agente segue o padrão ReAct (Reason-Act-Observe):
+
+1. **Reason** — raciocina sobre documentos e pedidos.
+2. **Act** — usa as ferramentas adequadas.
+3. **Observe** — verifica os resultados.
+4. **Repeat** — repete até atender à solicitação.
+
+É uma implementação simples de agente no LangGraph.
+
+```python
+# The graph
+builder = StateGraph(AgentState)
+
+# Define nodes: these do the work
+builder.add_node("assistant", assistant)
+builder.add_node("tools", ToolNode(tools))
+
+# Define edges: these determine how the control flow moves
+builder.add_edge(START, "assistant")
+builder.add_conditional_edges(
+ "assistant",
+ # If the latest message requires a tool, route to tools
+ # Otherwise, provide a direct response
+ tools_condition,
+)
+builder.add_edge("tools", "assistant")
+react_graph = builder.compile()
+
+# Show the butler's thought process
+display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))
+```
+
+Definimos um nó `tools` com a lista de ferramentas. O nó `assistant` é o modelo com as ferramentas vinculadas.
+
+Adicionamos uma aresta condicional `tools_condition`, que decide entre `END` ou `tools` conforme o `assistant` chame (ou não) uma ferramenta.
+
+Em seguida, conectamos `tools` de volta ao `assistant`, formando um loop:
+
+- Após executar, `tools_condition` verifica se houve chamada de ferramenta.
+- Caso sim, direciona para `tools`.
+- O nó `tools` retorna ao `assistant`.
+- O ciclo continua enquanto o modelo decidir usar ferramentas.
+- Se a resposta não for uma chamada de ferramenta, o fluxo segue para `END`.
+
+
+
+## O mordomo em ação
+
+### Exemplo 1: cálculos simples
+
+Um exemplo rápido de agente usando ferramenta:
+
+```python
+messages = [HumanMessage(content="Divide 6790 by 5")]
+messages = react_graph.invoke({"messages": messages, "input_file": None})
+
+# Show the messages
+for m in messages['messages']:
+ m.pretty_print()
+```
+
+A conversa ficaria:
+
+```
+Human: Divide 6790 by 5
+
+AI Tool Call: divide(a=6790, b=5)
+
+Tool Response: 1358.0
+
+Alfred: The result of dividing 6790 by 5 is 1358.0.
+```
+
+### Exemplo 2: analisando o treino do Sr. Wayne
+
+Quando o Sr. Wayne deixa anotações de treino e refeição:
+
+```python
+messages = [HumanMessage(content="According to the note provided by Mr. Wayne in the provided images. What's the list of items I should buy for the dinner menu?")]
+messages = react_graph.invoke({"messages": messages, "input_file": "Batman_training_and_meals.png"})
+```
+
+Resultado:
+
+```
+Human: According to the note provided by Mr. Wayne in the provided images. What's the list of items I should buy for the dinner menu?
+
+AI Tool Call: extract_text(img_path="Batman_training_and_meals.png")
+
+Tool Response: [Extracted text with training schedule and menu details]
+
+Alfred: For the dinner menu, you should buy the following items:
+
+1. Grass-fed local sirloin steak
+2. Organic spinach
+3. Piquillo peppers
+4. Potatoes (for oven-baked golden herb potato)
+5. Fish oil (2 grams)
+
+Ensure the steak is grass-fed and the spinach and peppers are organic for the best quality meal.
+```
+
+## Principais pontos
+
+Para criar seu próprio mordomo de análise de documentos:
+
+1. **Define clear tools** for specific document-related tasks
+2. **Create a robust state tracker** to maintain context between tool calls
+3. **Consider error handling** for tool failures
+4. **Maintain contextual awareness** of previous interactions (ensured by the operator `add_messages`)
+
+Com esses princípios, você também pode oferecer um serviço de análise digno da Mansão Wayne.
+
+*Espero ter sido claro. Agora, se me permite, preciso passar a capa do Sr. Wayne antes das atividades noturnas.*
diff --git a/units/pt_br/unit2/langgraph/first_graph.mdx b/units/pt_br/unit2/langgraph/first_graph.mdx
new file mode 100644
index 00000000..cd60dbba
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/first_graph.mdx
@@ -0,0 +1,374 @@
+# Construindo seu primeiro LangGraph
+
+Agora que entendemos os blocos fundamentais, vamos montar nosso primeiro grafo funcional. Implementaremos o sistema de triagem de e-mails do Alfred, em que ele deve:
+
+1. Read incoming emails
+2. Classify them as spam or legitimate
+3. Draft a preliminary response for legitimate emails
+4. Send information to Mr. Wayne when legitimate (printing only)
+
+This example demonstrates how to structure a workflow with LangGraph that involves LLM-based decision-making. While this can't be considered an Agent as no tool is involved, this section focuses more on learning the LangGraph framework than Agents.
+
+> [!TIP]
+> You can follow the code in this notebook that you can run using Google Colab.
+
+## Nosso workflow
+
+Este é o fluxo que construiremos:
+ +
+## Preparando o ambiente
+
+Primeiro, instale os pacotes necessários:
+
+```python
+%pip install langgraph langchain_openai
+```
+
+Em seguida, importe os módulos:
+
+```python
+import os
+from typing import TypedDict, List, Dict, Any, Optional
+from langgraph.graph import StateGraph, START, END
+from langchain_openai import ChatOpenAI
+from langchain_core.messages import HumanMessage
+```
+
+## Passo 1: Definindo o estado
+
+Definiremos quais informações Alfred precisa rastrear durante o processo:
+
+```python
+class EmailState(TypedDict):
+ # The email being processed
+ email: Dict[str, Any] # Contains subject, sender, body, etc.
+
+ # Category of the email (inquiry, complaint, etc.)
+ email_category: Optional[str]
+
+ # Reason why the email was marked as spam
+ spam_reason: Optional[str]
+
+ # Analysis and decisions
+ is_spam: Optional[bool]
+
+ # Response generation
+ email_draft: Optional[str]
+
+ # Processing metadata
+ messages: List[Dict[str, Any]] # Track conversation with LLM for analysis
+```
+
+> 💡 **Dica:** Inclua no estado tudo o que for realmente necessário, evitando inflar com detalhes supérfluos.
+
+## Passo 2: Definindo os nós
+
+Agora criaremos as funções que compõem os nós:
+
+```python
+# Initialize our LLM
+model = ChatOpenAI(temperature=0)
+
+def read_email(state: EmailState):
+ """Alfred reads and logs the incoming email"""
+ email = state["email"]
+
+ # Here we might do some initial preprocessing
+ print(f"Alfred is processing an email from {email['sender']} with subject: {email['subject']}")
+
+ # No state changes needed here
+ return {}
+
+def classify_email(state: EmailState):
+ """Alfred uses an LLM to determine if the email is spam or legitimate"""
+ email = state["email"]
+
+ # Prepare our prompt for the LLM
+ prompt = f"""
+ As Alfred the butler, analyze this email and determine if it is spam or legitimate.
+
+ Email:
+ From: {email['sender']}
+ Subject: {email['subject']}
+ Body: {email['body']}
+
+ First, determine if this email is spam. If it is spam, explain why.
+ If it is legitimate, categorize it (inquiry, complaint, thank you, etc.).
+ """
+
+ # Call the LLM
+ messages = [HumanMessage(content=prompt)]
+ response = model.invoke(messages)
+
+ # Simple logic to parse the response (in a real app, you'd want more robust parsing)
+ response_text = response.content.lower()
+ is_spam = "spam" in response_text and "not spam" not in response_text
+
+ # Extract a reason if it's spam
+ spam_reason = None
+ if is_spam and "reason:" in response_text:
+ spam_reason = response_text.split("reason:")[1].strip()
+
+ # Determine category if legitimate
+ email_category = None
+ if not is_spam:
+ categories = ["inquiry", "complaint", "thank you", "request", "information"]
+ for category in categories:
+ if category in response_text:
+ email_category = category
+ break
+
+ # Update messages for tracking
+ new_messages = state.get("messages", []) + [
+ {"role": "user", "content": prompt},
+ {"role": "assistant", "content": response.content}
+ ]
+
+ # Return state updates
+ return {
+ "is_spam": is_spam,
+ "spam_reason": spam_reason,
+ "email_category": email_category,
+ "messages": new_messages
+ }
+
+def handle_spam(state: EmailState):
+ """Alfred discards spam email with a note"""
+ print(f"Alfred has marked the email as spam. Reason: {state['spam_reason']}")
+ print("The email has been moved to the spam folder.")
+
+ # We're done processing this email
+ return {}
+
+def draft_response(state: EmailState):
+ """Alfred drafts a preliminary response for legitimate emails"""
+ email = state["email"]
+ category = state["email_category"] or "general"
+
+ # Prepare our prompt for the LLM
+ prompt = f"""
+ As Alfred the butler, draft a polite preliminary response to this email.
+
+ Email:
+ From: {email['sender']}
+ Subject: {email['subject']}
+ Body: {email['body']}
+
+ This email has been categorized as: {category}
+
+ Draft a brief, professional response that Mr. Hugg can review and personalize before sending.
+ """
+
+ # Call the LLM
+ messages = [HumanMessage(content=prompt)]
+ response = model.invoke(messages)
+
+ # Update messages for tracking
+ new_messages = state.get("messages", []) + [
+ {"role": "user", "content": prompt},
+ {"role": "assistant", "content": response.content}
+ ]
+
+ # Return state updates
+ return {
+ "email_draft": response.content,
+ "messages": new_messages
+ }
+
+def notify_mr_hugg(state: EmailState):
+ """Alfred notifies Mr. Hugg about the email and presents the draft response"""
+ email = state["email"]
+
+ print("\n" + "="*50)
+ print(f"Sir, you've received an email from {email['sender']}.")
+ print(f"Subject: {email['subject']}")
+ print(f"Category: {state['email_category']}")
+ print("\nI've prepared a draft response for your review:")
+ print("-"*50)
+ print(state["email_draft"])
+ print("="*50 + "\n")
+
+ # We're done processing this email
+ return {}
+```
+
+## Passo 3: Definindo a lógica de roteamento
+
+Precisamos de uma função que indique qual caminho seguir após a classificação:
+
+```python
+def route_email(state: EmailState) -> str:
+ """Determine the next step based on spam classification"""
+ if state["is_spam"]:
+ return "spam"
+ else:
+ return "legitimate"
+```
+
+> 💡 **Observação:** Essa função é chamada pelo LangGraph para decidir qual aresta seguir após o nó de classificação. O valor retornado deve corresponder às chaves definidas no mapeamento condicional.
+
+## Passo 4: Criando o StateGraph e definindo arestas
+
+Agora conectamos tudo:
+
+```python
+# Create the graph
+email_graph = StateGraph(EmailState)
+
+# Add nodes
+email_graph.add_node("read_email", read_email)
+email_graph.add_node("classify_email", classify_email)
+email_graph.add_node("handle_spam", handle_spam)
+email_graph.add_node("draft_response", draft_response)
+email_graph.add_node("notify_mr_hugg", notify_mr_hugg)
+
+# Start the edges
+email_graph.add_edge(START, "read_email")
+# Add edges - defining the flow
+email_graph.add_edge("read_email", "classify_email")
+
+# Add conditional branching from classify_email
+email_graph.add_conditional_edges(
+ "classify_email",
+ route_email,
+ {
+ "spam": "handle_spam",
+ "legitimate": "draft_response"
+ }
+)
+
+# Add the final edges
+email_graph.add_edge("handle_spam", END)
+email_graph.add_edge("draft_response", "notify_mr_hugg")
+email_graph.add_edge("notify_mr_hugg", END)
+
+# Compile the graph
+compiled_graph = email_graph.compile()
+```
+
+Note o uso do nó especial `END`, fornecido pelo LangGraph, indicando estados de término.
+
+## Passo 5: Executando a aplicação
+
+Vamos testar com um e-mail legítimo e outro de spam:
+
+```python
+# Example legitimate email
+legitimate_email = {
+ "sender": "john.smith@example.com",
+ "subject": "Question about your services",
+ "body": "Dear Mr. Hugg, I was referred to you by a colleague and I'm interested in learning more about your consulting services. Could we schedule a call next week? Best regards, John Smith"
+}
+
+# Example spam email
+spam_email = {
+ "sender": "winner@lottery-intl.com",
+ "subject": "YOU HAVE WON $5,000,000!!!",
+ "body": "CONGRATULATIONS! You have been selected as the winner of our international lottery! To claim your $5,000,000 prize, please send us your bank details and a processing fee of $100."
+}
+
+# Process the legitimate email
+print("\nProcessing legitimate email...")
+legitimate_result = compiled_graph.invoke({
+ "email": legitimate_email,
+ "is_spam": None,
+ "spam_reason": None,
+ "email_category": None,
+ "email_draft": None,
+ "messages": []
+})
+
+# Process the spam email
+print("\nProcessing spam email...")
+spam_result = compiled_graph.invoke({
+ "email": spam_email,
+ "is_spam": None,
+ "spam_reason": None,
+ "email_category": None,
+ "email_draft": None,
+ "messages": []
+})
+```
+
+## Passo 6: Observando o agente com Langfuse 📡
+
+Enquanto Alfred ajusta o agente de triagem, ele percebe o quanto é cansativo depurar cada execução. Agentes são naturalmente difíceis de inspecionar. Como ele pretende criar o melhor detector de spam e levá-lo à produção, precisa de rastreabilidade.
+
+Uma solução é usar uma ferramenta de observabilidade como o [Langfuse](https://langfuse.com/) para rastrear e monitorar o agente.
+
+Primeiro, instale o Langfuse:
+```python
+%pip install -q langfuse
+```
+
+Depois, instale o LangChain (necessário para a integração com Langfuse):
+```python
+%pip install langchain
+```
+
+Defina as credenciais do Langfuse como variáveis de ambiente (obtenha-as em [Langfuse Cloud](https://cloud.langfuse.com) ou via self-host):
+
+```python
+import os
+
+# Get keys for your project from the project settings page: https://cloud.langfuse.com
+os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
+os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
+os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
+# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
+```
+
+Configure o [callback_handler do Langfuse](https://langfuse.com/docs/integrations/langchain/tracing#add-langfuse-to-your-langchain-application) e passe `config={"callbacks": [langfuse_handler]}` na chamada do grafo:
+
+```python
+from langfuse.langchain import CallbackHandler
+
+# Initialize Langfuse CallbackHandler for LangGraph/Langchain (tracing)
+langfuse_handler = CallbackHandler()
+
+# Process legitimate email
+legitimate_result = compiled_graph.invoke(
+ input={"email": legitimate_email, "is_spam": None, "spam_reason": None, "email_category": None, "draft_response": None, "messages": []},
+ config={"callbacks": [langfuse_handler]}
+)
+```
+
+Pronto! 🔌 Os runs do LangGraph agora são registrados no Langfuse, oferecendo visibilidade total sobre o comportamento do agente. Com esse setup, Alfred pode revisar execuções antigas e melhorar ainda mais o sistema.
+
+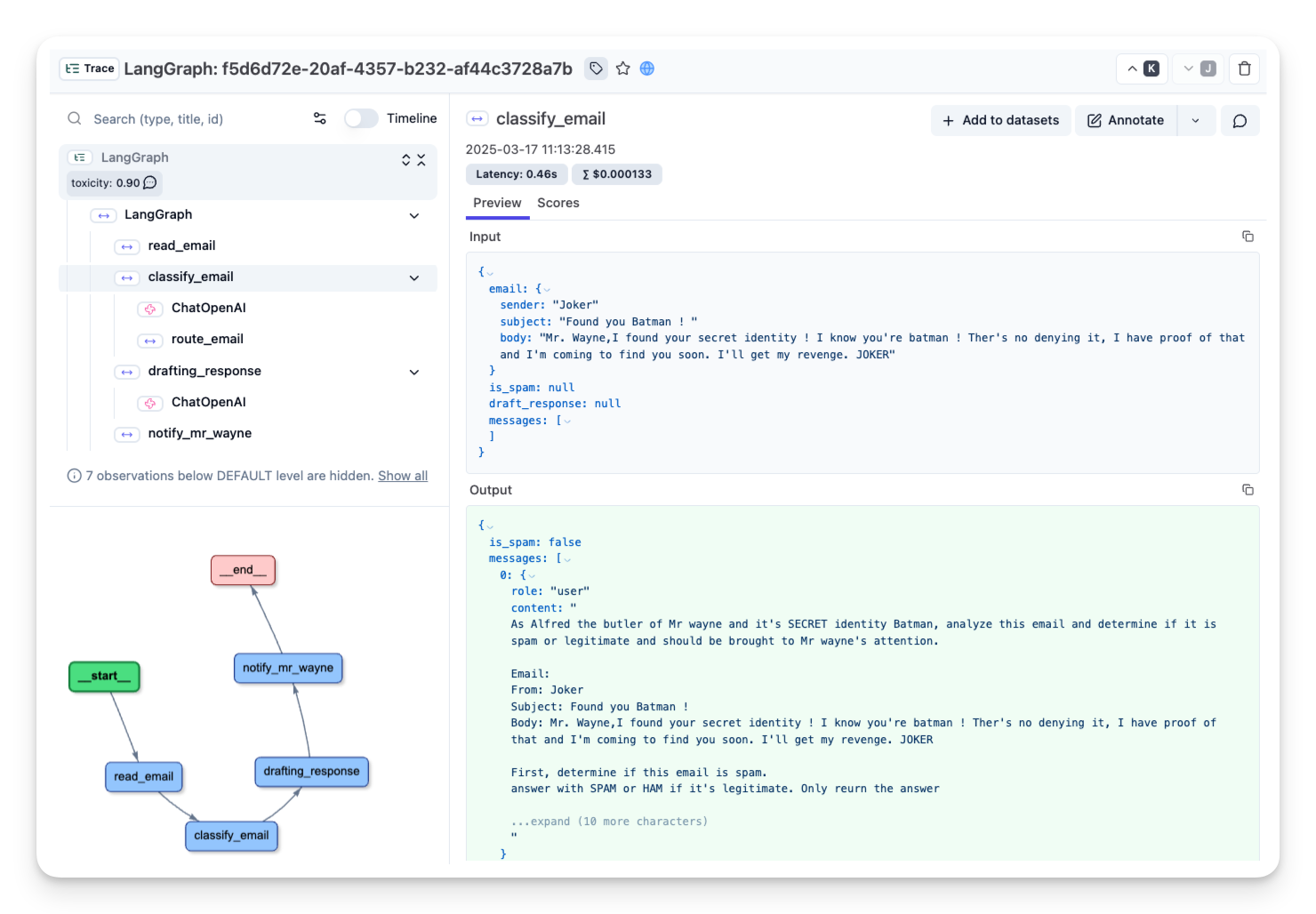
+
+_[Public link to the trace with the legit email](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/f5d6d72e-20af-4357-b232-af44c3728a7b?timestamp=2025-03-17T10%3A13%3A28.413Z&observation=6997ba69-043f-4f77-9445-700a033afba1)_
+
+## Visualizando o grafo
+
+O LangGraph permite visualizar o workflow para melhor entendimento e debug:
+
+```python
+compiled_graph.get_graph().draw_mermaid_png()
+```
+
+
+## Preparando o ambiente
+
+Primeiro, instale os pacotes necessários:
+
+```python
+%pip install langgraph langchain_openai
+```
+
+Em seguida, importe os módulos:
+
+```python
+import os
+from typing import TypedDict, List, Dict, Any, Optional
+from langgraph.graph import StateGraph, START, END
+from langchain_openai import ChatOpenAI
+from langchain_core.messages import HumanMessage
+```
+
+## Passo 1: Definindo o estado
+
+Definiremos quais informações Alfred precisa rastrear durante o processo:
+
+```python
+class EmailState(TypedDict):
+ # The email being processed
+ email: Dict[str, Any] # Contains subject, sender, body, etc.
+
+ # Category of the email (inquiry, complaint, etc.)
+ email_category: Optional[str]
+
+ # Reason why the email was marked as spam
+ spam_reason: Optional[str]
+
+ # Analysis and decisions
+ is_spam: Optional[bool]
+
+ # Response generation
+ email_draft: Optional[str]
+
+ # Processing metadata
+ messages: List[Dict[str, Any]] # Track conversation with LLM for analysis
+```
+
+> 💡 **Dica:** Inclua no estado tudo o que for realmente necessário, evitando inflar com detalhes supérfluos.
+
+## Passo 2: Definindo os nós
+
+Agora criaremos as funções que compõem os nós:
+
+```python
+# Initialize our LLM
+model = ChatOpenAI(temperature=0)
+
+def read_email(state: EmailState):
+ """Alfred reads and logs the incoming email"""
+ email = state["email"]
+
+ # Here we might do some initial preprocessing
+ print(f"Alfred is processing an email from {email['sender']} with subject: {email['subject']}")
+
+ # No state changes needed here
+ return {}
+
+def classify_email(state: EmailState):
+ """Alfred uses an LLM to determine if the email is spam or legitimate"""
+ email = state["email"]
+
+ # Prepare our prompt for the LLM
+ prompt = f"""
+ As Alfred the butler, analyze this email and determine if it is spam or legitimate.
+
+ Email:
+ From: {email['sender']}
+ Subject: {email['subject']}
+ Body: {email['body']}
+
+ First, determine if this email is spam. If it is spam, explain why.
+ If it is legitimate, categorize it (inquiry, complaint, thank you, etc.).
+ """
+
+ # Call the LLM
+ messages = [HumanMessage(content=prompt)]
+ response = model.invoke(messages)
+
+ # Simple logic to parse the response (in a real app, you'd want more robust parsing)
+ response_text = response.content.lower()
+ is_spam = "spam" in response_text and "not spam" not in response_text
+
+ # Extract a reason if it's spam
+ spam_reason = None
+ if is_spam and "reason:" in response_text:
+ spam_reason = response_text.split("reason:")[1].strip()
+
+ # Determine category if legitimate
+ email_category = None
+ if not is_spam:
+ categories = ["inquiry", "complaint", "thank you", "request", "information"]
+ for category in categories:
+ if category in response_text:
+ email_category = category
+ break
+
+ # Update messages for tracking
+ new_messages = state.get("messages", []) + [
+ {"role": "user", "content": prompt},
+ {"role": "assistant", "content": response.content}
+ ]
+
+ # Return state updates
+ return {
+ "is_spam": is_spam,
+ "spam_reason": spam_reason,
+ "email_category": email_category,
+ "messages": new_messages
+ }
+
+def handle_spam(state: EmailState):
+ """Alfred discards spam email with a note"""
+ print(f"Alfred has marked the email as spam. Reason: {state['spam_reason']}")
+ print("The email has been moved to the spam folder.")
+
+ # We're done processing this email
+ return {}
+
+def draft_response(state: EmailState):
+ """Alfred drafts a preliminary response for legitimate emails"""
+ email = state["email"]
+ category = state["email_category"] or "general"
+
+ # Prepare our prompt for the LLM
+ prompt = f"""
+ As Alfred the butler, draft a polite preliminary response to this email.
+
+ Email:
+ From: {email['sender']}
+ Subject: {email['subject']}
+ Body: {email['body']}
+
+ This email has been categorized as: {category}
+
+ Draft a brief, professional response that Mr. Hugg can review and personalize before sending.
+ """
+
+ # Call the LLM
+ messages = [HumanMessage(content=prompt)]
+ response = model.invoke(messages)
+
+ # Update messages for tracking
+ new_messages = state.get("messages", []) + [
+ {"role": "user", "content": prompt},
+ {"role": "assistant", "content": response.content}
+ ]
+
+ # Return state updates
+ return {
+ "email_draft": response.content,
+ "messages": new_messages
+ }
+
+def notify_mr_hugg(state: EmailState):
+ """Alfred notifies Mr. Hugg about the email and presents the draft response"""
+ email = state["email"]
+
+ print("\n" + "="*50)
+ print(f"Sir, you've received an email from {email['sender']}.")
+ print(f"Subject: {email['subject']}")
+ print(f"Category: {state['email_category']}")
+ print("\nI've prepared a draft response for your review:")
+ print("-"*50)
+ print(state["email_draft"])
+ print("="*50 + "\n")
+
+ # We're done processing this email
+ return {}
+```
+
+## Passo 3: Definindo a lógica de roteamento
+
+Precisamos de uma função que indique qual caminho seguir após a classificação:
+
+```python
+def route_email(state: EmailState) -> str:
+ """Determine the next step based on spam classification"""
+ if state["is_spam"]:
+ return "spam"
+ else:
+ return "legitimate"
+```
+
+> 💡 **Observação:** Essa função é chamada pelo LangGraph para decidir qual aresta seguir após o nó de classificação. O valor retornado deve corresponder às chaves definidas no mapeamento condicional.
+
+## Passo 4: Criando o StateGraph e definindo arestas
+
+Agora conectamos tudo:
+
+```python
+# Create the graph
+email_graph = StateGraph(EmailState)
+
+# Add nodes
+email_graph.add_node("read_email", read_email)
+email_graph.add_node("classify_email", classify_email)
+email_graph.add_node("handle_spam", handle_spam)
+email_graph.add_node("draft_response", draft_response)
+email_graph.add_node("notify_mr_hugg", notify_mr_hugg)
+
+# Start the edges
+email_graph.add_edge(START, "read_email")
+# Add edges - defining the flow
+email_graph.add_edge("read_email", "classify_email")
+
+# Add conditional branching from classify_email
+email_graph.add_conditional_edges(
+ "classify_email",
+ route_email,
+ {
+ "spam": "handle_spam",
+ "legitimate": "draft_response"
+ }
+)
+
+# Add the final edges
+email_graph.add_edge("handle_spam", END)
+email_graph.add_edge("draft_response", "notify_mr_hugg")
+email_graph.add_edge("notify_mr_hugg", END)
+
+# Compile the graph
+compiled_graph = email_graph.compile()
+```
+
+Note o uso do nó especial `END`, fornecido pelo LangGraph, indicando estados de término.
+
+## Passo 5: Executando a aplicação
+
+Vamos testar com um e-mail legítimo e outro de spam:
+
+```python
+# Example legitimate email
+legitimate_email = {
+ "sender": "john.smith@example.com",
+ "subject": "Question about your services",
+ "body": "Dear Mr. Hugg, I was referred to you by a colleague and I'm interested in learning more about your consulting services. Could we schedule a call next week? Best regards, John Smith"
+}
+
+# Example spam email
+spam_email = {
+ "sender": "winner@lottery-intl.com",
+ "subject": "YOU HAVE WON $5,000,000!!!",
+ "body": "CONGRATULATIONS! You have been selected as the winner of our international lottery! To claim your $5,000,000 prize, please send us your bank details and a processing fee of $100."
+}
+
+# Process the legitimate email
+print("\nProcessing legitimate email...")
+legitimate_result = compiled_graph.invoke({
+ "email": legitimate_email,
+ "is_spam": None,
+ "spam_reason": None,
+ "email_category": None,
+ "email_draft": None,
+ "messages": []
+})
+
+# Process the spam email
+print("\nProcessing spam email...")
+spam_result = compiled_graph.invoke({
+ "email": spam_email,
+ "is_spam": None,
+ "spam_reason": None,
+ "email_category": None,
+ "email_draft": None,
+ "messages": []
+})
+```
+
+## Passo 6: Observando o agente com Langfuse 📡
+
+Enquanto Alfred ajusta o agente de triagem, ele percebe o quanto é cansativo depurar cada execução. Agentes são naturalmente difíceis de inspecionar. Como ele pretende criar o melhor detector de spam e levá-lo à produção, precisa de rastreabilidade.
+
+Uma solução é usar uma ferramenta de observabilidade como o [Langfuse](https://langfuse.com/) para rastrear e monitorar o agente.
+
+Primeiro, instale o Langfuse:
+```python
+%pip install -q langfuse
+```
+
+Depois, instale o LangChain (necessário para a integração com Langfuse):
+```python
+%pip install langchain
+```
+
+Defina as credenciais do Langfuse como variáveis de ambiente (obtenha-as em [Langfuse Cloud](https://cloud.langfuse.com) ou via self-host):
+
+```python
+import os
+
+# Get keys for your project from the project settings page: https://cloud.langfuse.com
+os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
+os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
+os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 EU region
+# os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 US region
+```
+
+Configure o [callback_handler do Langfuse](https://langfuse.com/docs/integrations/langchain/tracing#add-langfuse-to-your-langchain-application) e passe `config={"callbacks": [langfuse_handler]}` na chamada do grafo:
+
+```python
+from langfuse.langchain import CallbackHandler
+
+# Initialize Langfuse CallbackHandler for LangGraph/Langchain (tracing)
+langfuse_handler = CallbackHandler()
+
+# Process legitimate email
+legitimate_result = compiled_graph.invoke(
+ input={"email": legitimate_email, "is_spam": None, "spam_reason": None, "email_category": None, "draft_response": None, "messages": []},
+ config={"callbacks": [langfuse_handler]}
+)
+```
+
+Pronto! 🔌 Os runs do LangGraph agora são registrados no Langfuse, oferecendo visibilidade total sobre o comportamento do agente. Com esse setup, Alfred pode revisar execuções antigas e melhorar ainda mais o sistema.
+
+
+
+_[Public link to the trace with the legit email](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/f5d6d72e-20af-4357-b232-af44c3728a7b?timestamp=2025-03-17T10%3A13%3A28.413Z&observation=6997ba69-043f-4f77-9445-700a033afba1)_
+
+## Visualizando o grafo
+
+O LangGraph permite visualizar o workflow para melhor entendimento e debug:
+
+```python
+compiled_graph.get_graph().draw_mermaid_png()
+```
+ +
+Isso gera um diagrama mostrando como os nós se conectam e quais caminhos condicionais existem.
+
+## O que construímos
+
+Montamos um fluxo completo que:
+
+1. Takes an incoming email
+2. Uses an LLM to classify it as spam or legitimate
+3. Handles spam by discarding it
+4. For legitimate emails, drafts a response and notifies Mr. Hugg
+
+Isso demonstra o poder do LangGraph para orquestrar workflows complexos com LLMs sem perder clareza.
+
+## Principais aprendizados
+
+- **Gestão de estado**: definimos um estado completo para acompanhar o processamento.
+- **Implementação de nós**: criamos funções que interagem com o LLM.
+- **Roteamento condicional**: adicionamos ramificações conforme a classificação.
+- **Estados finais**: utilizamos o nó `END` para finalizar o fluxo.
+
+## Próximos passos
+
+Na próxima seção, exploraremos recursos avançados do LangGraph, incluindo intervenções humanas no workflow e ramificações condicionais mais elaboradas.
diff --git a/units/pt_br/unit2/langgraph/introduction.mdx b/units/pt_br/unit2/langgraph/introduction.mdx
new file mode 100644
index 00000000..1f42487b
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/introduction.mdx
@@ -0,0 +1,31 @@
+# Introdução ao `LangGraph`
+
+
+
+Isso gera um diagrama mostrando como os nós se conectam e quais caminhos condicionais existem.
+
+## O que construímos
+
+Montamos um fluxo completo que:
+
+1. Takes an incoming email
+2. Uses an LLM to classify it as spam or legitimate
+3. Handles spam by discarding it
+4. For legitimate emails, drafts a response and notifies Mr. Hugg
+
+Isso demonstra o poder do LangGraph para orquestrar workflows complexos com LLMs sem perder clareza.
+
+## Principais aprendizados
+
+- **Gestão de estado**: definimos um estado completo para acompanhar o processamento.
+- **Implementação de nós**: criamos funções que interagem com o LLM.
+- **Roteamento condicional**: adicionamos ramificações conforme a classificação.
+- **Estados finais**: utilizamos o nó `END` para finalizar o fluxo.
+
+## Próximos passos
+
+Na próxima seção, exploraremos recursos avançados do LangGraph, incluindo intervenções humanas no workflow e ramificações condicionais mais elaboradas.
diff --git a/units/pt_br/unit2/langgraph/introduction.mdx b/units/pt_br/unit2/langgraph/introduction.mdx
new file mode 100644
index 00000000..1f42487b
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/introduction.mdx
@@ -0,0 +1,31 @@
+# Introdução ao `LangGraph`
+
+ +
+Bem-vindo a esta etapa da jornada! Aqui você aprenderá **a construir aplicações** usando o framework [`LangGraph`](https://github.com/langchain-ai/langgraph), desenhado para estruturar e orquestrar workflows complexos com LLMs.
+
+O `LangGraph` permite criar aplicações **prontas para produção**, oferecendo ferramentas de **controle** sobre o fluxo dos agentes.
+
+## Module Overview
+
+Nesta unidade, você vai descobrir:
+
+### 1️⃣ [What is LangGraph, and when to use it?](./when_to_use_langgraph)
+### 2️⃣ [Building Blocks of LangGraph](./building_blocks)
+### 3️⃣ [Alfred, the mail sorting butler](./first_graph)
+### 4️⃣ [Alfred, the document Analyst agent](./document_analysis_agent)
+### 5️⃣ [Quiz](./quizz1)
+
+> [!WARNING]
+> Os exemplos desta seção exigem acesso a um modelo LLM/VLM poderoso. Utilizamos a API GPT-4o por oferecer a melhor compatibilidade com o LangGraph.
+
+Ao final, você estará apto a criar aplicações robustas, organizadas e prontas para produção!
+
+Esta seção é uma introdução ao LangGraph; temas avançados podem ser explorados no curso gratuito da LangChain: [Introduction to LangGraph](https://academy.langchain.com/courses/intro-to-langgraph).
+
+Vamos lá!
+
+## Resources
+
+- [LangGraph Agents](https://langchain-ai.github.io/langgraph/) — exemplos de agentes com LangGraph
+- [LangChain academy](https://academy.langchain.com/courses/intro-to-langgraph) — curso completo sobre LangGraph pela LangChain
diff --git a/units/pt_br/unit2/langgraph/quiz1.mdx b/units/pt_br/unit2/langgraph/quiz1.mdx
new file mode 100644
index 00000000..66ac049f
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/quiz1.mdx
@@ -0,0 +1,118 @@
+# Teste seu entendimento sobre LangGraph
+
+Vamos avaliar o que você aprendeu sobre `LangGraph` com um quiz rápido! Isso ajuda a reforçar os conceitos vistos até aqui.
+
+Este quiz é opcional e não possui nota.
+
+### Q1: Qual é o objetivo principal do LangGraph?
+Escolha a afirmação que melhor descreve o papel do LangGraph.
+
+
+
+Bem-vindo a esta etapa da jornada! Aqui você aprenderá **a construir aplicações** usando o framework [`LangGraph`](https://github.com/langchain-ai/langgraph), desenhado para estruturar e orquestrar workflows complexos com LLMs.
+
+O `LangGraph` permite criar aplicações **prontas para produção**, oferecendo ferramentas de **controle** sobre o fluxo dos agentes.
+
+## Module Overview
+
+Nesta unidade, você vai descobrir:
+
+### 1️⃣ [What is LangGraph, and when to use it?](./when_to_use_langgraph)
+### 2️⃣ [Building Blocks of LangGraph](./building_blocks)
+### 3️⃣ [Alfred, the mail sorting butler](./first_graph)
+### 4️⃣ [Alfred, the document Analyst agent](./document_analysis_agent)
+### 5️⃣ [Quiz](./quizz1)
+
+> [!WARNING]
+> Os exemplos desta seção exigem acesso a um modelo LLM/VLM poderoso. Utilizamos a API GPT-4o por oferecer a melhor compatibilidade com o LangGraph.
+
+Ao final, você estará apto a criar aplicações robustas, organizadas e prontas para produção!
+
+Esta seção é uma introdução ao LangGraph; temas avançados podem ser explorados no curso gratuito da LangChain: [Introduction to LangGraph](https://academy.langchain.com/courses/intro-to-langgraph).
+
+Vamos lá!
+
+## Resources
+
+- [LangGraph Agents](https://langchain-ai.github.io/langgraph/) — exemplos de agentes com LangGraph
+- [LangChain academy](https://academy.langchain.com/courses/intro-to-langgraph) — curso completo sobre LangGraph pela LangChain
diff --git a/units/pt_br/unit2/langgraph/quiz1.mdx b/units/pt_br/unit2/langgraph/quiz1.mdx
new file mode 100644
index 00000000..66ac049f
--- /dev/null
+++ b/units/pt_br/unit2/langgraph/quiz1.mdx
@@ -0,0 +1,118 @@
+# Teste seu entendimento sobre LangGraph
+
+Vamos avaliar o que você aprendeu sobre `LangGraph` com um quiz rápido! Isso ajuda a reforçar os conceitos vistos até aqui.
+
+Este quiz é opcional e não possui nota.
+
+### Q1: Qual é o objetivo principal do LangGraph?
+Escolha a afirmação que melhor descreve o papel do LangGraph.
+
+ +
+> 💡 **Dica:** No lado esquerdo não há chamadas de ferramentas (não é um agente). No lado direito será preciso escrever código para consultar o XLS (converter para pandas, manipular etc.).
+
+Essa ramificação é determinística, mas você pode criar ramificações condicionadas à resposta do LLM, tornando-as não determinísticas.
+
+Casos em que o LangGraph se destaca:
+
+- **Processos de raciocínio multi-etapas** que exigem controle explícito do fluxo.
+- **Aplicações que precisam persistir estado** entre etapas.
+- **Sistemas que combinam lógica determinística com IA**.
+- **Workflows com intervenções humanas** (human-in-the-loop).
+- **Arquiteturas complexas de agentes** trabalhando em conjunto.
+
+Em resumo, se você consegue desenhar, **como humano**, um fluxo de ações baseado na saída de cada etapa e decidir o próximo passo, o LangGraph é a escolha certa.
+
+`LangGraph` é, na minha opinião, o framework agêntico mais pronto para produção atualmente.
+
+## Como o LangGraph funciona?
+
+No centro da solução, o `LangGraph` usa um grafo direcionado para definir o fluxo da aplicação:
+
+- **Nodes** representam etapas de processamento (chamar um LLM, usar uma ferramenta, tomar uma decisão).
+- **Edges** definem as transições possíveis entre etapas.
+- **State** é definido pelo usuário e propagado entre os nós; é a base para decidir o próximo passo.
+
+Vamos explorar esses blocos fundamentais no próximo capítulo!
+
+## Qual a diferença em relação a Python puro?
+
+Talvez você pense: “Posso escrever tudo com `if-else`, certo?”
+Tecnicamente, sim. Mas o LangGraph oferece **vantagens** para sistemas complexos:
+- Abstrações mais fáceis de usar;
+- Gestão de estado embutida;
+- Visualizações, logs (traces), suporte a human-in-the-loop e mais.
+
+Você pode criar a mesma aplicação sem LangGraph, mas com ele o processo fica mais simples e organizado.
diff --git a/units/pt_br/unit2/llama-index/README.md b/units/pt_br/unit2/llama-index/README.md
new file mode 100644
index 00000000..f98049fd
--- /dev/null
+++ b/units/pt_br/unit2/llama-index/README.md
@@ -0,0 +1,15 @@
+# Sumário
+
+Este roteiro sobre LlamaIndex faz parte da unidade 2 do curso. Você pode acessar a unidade sobre LlamaIndex em hf.co/learn 👉 neste link
+
+| Título | Descrição |
+| --- | --- |
+| [Introduction](introduction.mdx) | Introdução ao LlamaIndex |
+| [LlamaHub](llama-hub.mdx) | LlamaHub: um repositório de integrações, agentes e ferramentas |
+| [Components](components.mdx) | Componentes: os blocos de construção dos workflows |
+| [Tools](tools.mdx) | Ferramentas: como construir ferramentas no LlamaIndex |
+| [Quiz 1](quiz1.mdx) | Quiz 1 |
+| [Agents](agents.mdx) | Agentes: como criar agentes no LlamaIndex |
+| [Workflows](workflows.mdx) | Workflows: sequência de etapas e eventos compostos por componentes executados em ordem |
+| [Quiz 2](quiz2.mdx) | Quiz 2 |
+| [Conclusion](conclusion.mdx) | Conclusão |
diff --git a/units/pt_br/unit2/llama-index/agents.mdx b/units/pt_br/unit2/llama-index/agents.mdx
new file mode 100644
index 00000000..32c2e76b
--- /dev/null
+++ b/units/pt_br/unit2/llama-index/agents.mdx
@@ -0,0 +1,159 @@
+# Usando agentes no LlamaIndex
+
+Lembra do Alfred, nosso mordomo-agente? Ele está prestes a receber um upgrade!
+Agora que entendemos as ferramentas disponíveis no LlamaIndex, podemos ampliar as capacidades do Alfred.
+
+Antes, vamos relembrar o que caracteriza um agente. Na Unidade 1 aprendemos que:
+
+> An Agent is a system that leverages an AI model to interact with its environment to achieve a user-defined objective. It combines reasoning, planning, and action execution (often via external tools) to fulfil tasks.
+
+O LlamaIndex oferece **três tipos principais de agentes de raciocínio:**
+
+
+
+1. `Function Calling Agents` — utilizam modelos com suporte a function calling.
+2. `ReAct Agents` — funcionam com qualquer modelo (chat ou completions) e são bons em tarefas complexas de raciocínio.
+3. `Advanced Custom Agents` — empregam métodos avançados para lidar com cenários e workflows mais elaborados.
+
+> [!TIP]
+> Find more information on advanced agents on BaseWorkflowAgent
+
+## Inicializando agentes
+
+> [!TIP]
+> You can follow the code in this notebook that you can run using Google Colab.
+
+Para criar um agente, fornecemos **um conjunto de funções/ferramentas que define suas capacidades**.
+Veja como montar um agente com ferramentas básicas. No momento, o LlamaIndex escolhe automaticamente entre function calling (se o modelo suportar) ou o loop padrão ReAct.
+
+Modelos com API de ferramentas/funções são relativamente novos, mas poderosos: dispensam prompts complexos e permitem que o LLM monte chamadas seguindo schemas definidos.
+
+Agentes ReAct também lidam bem com tarefas complexas e funcionam com qualquer LLM (chat ou texto), exibindo inclusive o raciocínio seguido.
+
+```python
+from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
+from llama_index.core.agent.workflow import AgentWorkflow
+from llama_index.core.tools import FunctionTool
+
+# define sample Tool -- type annotations, function names, and docstrings, are all included in parsed schemas!
+def multiply(a: int, b: int) -> int:
+ """Multiplies two integers and returns the resulting integer"""
+ return a * b
+
+# initialize llm
+llm = HuggingFaceInferenceAPI(model_name="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+# initialize agent
+agent = AgentWorkflow.from_tools_or_functions(
+ [FunctionTool.from_defaults(multiply)],
+ llm=llm
+)
+```
+
+**Agentes são stateless por padrão**, mas podem lembrar interações passadas usando um objeto `Context`.
+Isso é útil em chatbots com memória ou gestores de tarefas que precisam acompanhar progresso.
+
+```python
+# stateless
+response = await agent.run("What is 2 times 2?")
+
+# remembering state
+from llama_index.core.workflow import Context
+
+ctx = Context(agent)
+
+response = await agent.run("My name is Bob.", ctx=ctx)
+response = await agent.run("What was my name again?", ctx=ctx)
+```
+
+Note que agentes no `LlamaIndex` são assíncronos, pois usam `await`. Se precisar de reforço em async, consulte o [guia oficial](https://docs.llamaindex.ai/en/stable/getting_started/async_python/).
+
+Agora que dominamos o básico, vamos usar ferramentas mais avançadas.
+
+## Creating RAG Agents with QueryEngineTools
+
+**Agentic RAG é uma abordagem poderosa para responder perguntas com seus dados.**
+Podemos entregar várias ferramentas ao Alfred para auxiliá-lo. Em vez de sempre consultar documentos, ele pode decidir usar outros fluxos ou ferramentas.
+
+
+
+É simples **transformar o `QueryEngine` em ferramenta**.
+Ao fazer isso, precisamos **definir nome e descrição**, para que o LLM use o recurso da forma correta. Veja o exemplo com o `QueryEngine` criado na [seção de componentes](components):
+
+```python
+from llama_index.core.tools import QueryEngineTool
+
+query_engine = index.as_query_engine(llm=llm, similarity_top_k=3) # as shown in the Components in LlamaIndex section
+
+query_engine_tool = QueryEngineTool.from_defaults(
+ query_engine=query_engine,
+ name="name",
+ description="a specific description",
+ return_direct=False,
+)
+query_engine_agent = AgentWorkflow.from_tools_or_functions(
+ [query_engine_tool],
+ llm=llm,
+ system_prompt="You are a helpful assistant that has access to a database containing persona descriptions. "
+)
+```
+
+## Criando sistemas multiagentes
+
+A classe `AgentWorkflow` suporta sistemas multiagentes. Basta dar nome e descrição a cada agente: o workflow mantém um “orador” ativo e permite handoff entre agentes.
+
+Ao restringir o escopo de cada um, aumentamos a precisão nas respostas.
+
+**Agentes no LlamaIndex também podem ser utilizados como ferramentas** por outros agentes — ideal para cenários complexos.
+
+```python
+from llama_index.core.agent.workflow import (
+ AgentWorkflow,
+ FunctionAgent,
+ ReActAgent,
+)
+
+# Define some tools
+def add(a: int, b: int) -> int:
+ """Add two numbers."""
+ return a + b
+
+
+def subtract(a: int, b: int) -> int:
+ """Subtract two numbers."""
+ return a - b
+
+
+# Create agent configs
+# NOTE: we can use FunctionAgent or ReActAgent here.
+# FunctionAgent works for LLMs with a function calling API.
+# ReActAgent works for any LLM.
+calculator_agent = ReActAgent(
+ name="calculator",
+ description="Performs basic arithmetic operations",
+ system_prompt="You are a calculator assistant. Use your tools for any math operation.",
+ tools=[add, subtract],
+ llm=llm,
+)
+
+query_agent = ReActAgent(
+ name="info_lookup",
+ description="Looks up information about XYZ",
+ system_prompt="Use your tool to query a RAG system to answer information about XYZ",
+ tools=[query_engine_tool],
+ llm=llm
+)
+
+# Create and run the workflow
+agent = AgentWorkflow(
+ agents=[calculator_agent, query_agent], root_agent="calculator"
+)
+
+# Run the system
+response = await agent.run(user_msg="Can you add 5 and 3?")
+```
+
+> [!TIP]
+> Quer saber mais? Confira a introdução ao AgentWorkflow ou o guia de agentes — há conteúdo sobre streaming, serialização de contexto e human-in-the-loop.
+
+Agora que entendemos agentes e ferramentas, vamos usar o LlamaIndex para **criar workflows configuráveis e fáceis de manejar!**
diff --git a/units/pt_br/unit2/llama-index/components.mdx b/units/pt_br/unit2/llama-index/components.mdx
new file mode 100644
index 00000000..255dfe12
--- /dev/null
+++ b/units/pt_br/unit2/llama-index/components.mdx
@@ -0,0 +1,166 @@
+# O que são componentes no LlamaIndex?
+
+Lembra do Alfred, o mordomo atencioso da Unidade 1?
+Para nos ajudar de verdade, ele precisa entender nossos pedidos e **preparar, localizar e usar informações relevantes**.
+É aqui que entram os componentes do LlamaIndex.
+
+O LlamaIndex possui diversos componentes, mas **vamos focar no `QueryEngine`**.
+Por quê? Porque ele pode funcionar como uma ferramenta de Retrieval-Augmented Generation (RAG) para um agente.
+
+RAG (Retrieval-Augmented Generation) resolve a limitação dos LLMs — que, apesar de treinados em grandes coleções de dados, podem não ter informações específicas ou atualizadas — ao **buscar conteúdos relevantes nos seus próprios dados** e fornecer esse contexto ao modelo.
+
+
+
+Pense no fluxo do Alfred:
+
+1. Você pede ajuda para planejar um jantar.
+2. Ele verifica sua agenda, preferências alimentares e menus passados.
+3. O `QueryEngine` encontra essas informações e as usa para montar o plano.
+
+Ou seja, o `QueryEngine` é **peça fundamental para construir workflows de RAG agênticos** no LlamaIndex. Assim como Alfred vasculha o histórico da casa, qualquer agente precisa encontrar e interpretar dados relevantes. O `QueryEngine` oferece exatamente isso.
+
+Agora, vamos mergulhar nos componentes e aprender a **combinar peças para criar um pipeline de RAG**.
+
+## Construindo um pipeline RAG com componentes
+
+> [!TIP]
+> O código desta seção está disponível neste notebook, executável no Google Colab.
+
+Um pipeline RAG geralmente passa por cinco estágios principais:
+
+1. **Loading (Carregamento)**: trazer os dados de onde estão — arquivos, PDFs, sites, bancos de dados ou APIs — para o fluxo. O LlamaHub oferece centenas de conectores para isso.
+2. **Indexing (Indexação)**: criar estruturas que permitam consultar os dados. Em LLMs, isso normalmente significa gerar embeddings vetoriais (representações numéricas do significado). Indexação também inclui estratégias de metadados.
+3. **Storing (Armazenamento)**: guardar índices e metadados para evitar reprocessamentos.
+4. **Querying (Consulta)**: utilizar LLMs e as estruturas do LlamaIndex em consultas simples, multi-etapas, híbridas etc.
+5. **Evaluation (Avaliação)**: verificar se o fluxo está funcionando bem, especialmente após ajustes. Mede precisão, fidelidade e velocidade das respostas.
+
+Vamos reproduzir essas etapas usando componentes.
+
+### Carregando e gerando embeddings dos documentos
+
+Antes de acessar os dados, precisamos carregá-los. Existem três meios principais:
+
+1. `SimpleDirectoryReader`: leitor nativo para vários formatos em diretórios locais.
+2. `LlamaParse`: serviço oficial para parsing de PDFs, oferecido como API gerenciada.
+3. `LlamaHub`: marketplace de conectores para praticamente qualquer origem de dados.
+
+> [!TIP]
+> Explore os loaders do LlamaHub e o parser LlamaParse para fontes complexas.
+
+A maneira mais simples é usar `SimpleDirectoryReader`, que converte arquivos em objetos `Document`:
+
+```python
+from llama_index.core import SimpleDirectoryReader
+
+reader = SimpleDirectoryReader(input_dir="path/to/directory")
+documents = reader.load_data()
+```
+
+Depois, dividimos os documentos em pedaços menores, chamados `Node`.
+Cada `Node` é um trecho do texto original, fácil de manipular e vinculado ao `Document` de origem.
+
+A `IngestionPipeline` ajuda a criar esses nodes com duas transformações:
+
+1. `SentenceSplitter`: corta o texto em blocos, respeitando fronteiras naturais de frases.
+2. `HuggingFaceEmbedding`: converte cada bloco em embeddings — vetores que capturam o significado.
+
+```python
+from llama_index.core import Document, StorageContext, VectorStoreIndex
+from llama_index.core.ingestion import IngestionPipeline
+from llama_index.core.node_parser import SentenceSplitter
+from llama_index.embeddings.huggingface import HuggingFaceEmbedding
+from llama_index.vector_stores.chroma import ChromaVectorStore
+
+pipeline = IngestionPipeline(
+ transformations=[
+ SentenceSplitter(chunk_size=384, chunk_overlap=50),
+ HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5"),
+ ],
+ vector_store=ChromaVectorStore(
+ collection_name="party_planning",
+ persist_directory="./chroma_db",
+ ),
+)
+
+nodes = pipeline.run(documents=documents)
+```
+
+Assim, garantimos documentos indexados de forma eficiente, prontos para compor um fluxo RAG, e um repositório vetorial persistente para o modelo.
+
+### Consultando o VectorStore com prompts e LLMs
+
+Com os dados indexados, podemos recuperá-los. Para isso, convertemos o índice em uma interface de consulta. As opções mais comuns são:
+
+- `as_retriever`: retorna uma lista de `NodeWithScore`, útil para recuperação direta.
+- `as_query_engine`: responde a perguntas pontuais, retornando texto.
+- `as_chat_engine`: mantém histórico e gera respostas conversacionais.
+
+Focaremos no `query_engine`, formato mais próximo de interações agênticas:
+
+```python
+from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
+
+llm = HuggingFaceInferenceAPI(model_name="Qwen/Qwen2.5-Coder-32B-Instruct")
+query_engine = index.as_query_engine(
+ llm=llm,
+ response_mode="tree_summarize",
+)
+response = query_engine.query("What is the meaning of life?")
+# The meaning of life is 42
+```
+
+### Processamento da resposta
+
+Internamente, o query engine utiliza um `ResponseSynthesizer` para definir a estratégia de síntese. Três modos se destacam:
+
+- `refine`: percorre cada chunk sequencialmente, refinando a resposta (uma chamada ao LLM por node).
+- `compact` (padrão): junta os chunks antes de chamar o LLM, economizando requisições.
+- `tree_summarize`: constrói uma resposta detalhada em forma de árvore.
+
+> [!TIP]
+> Para controle total do fluxo de consulta, use a Low-Level Composition API — em conjunto com Workflows.
+
+### Avaliação e observabilidade
+
+Mesmo com uma boa estratégia, o LLM pode falhar. Por isso, é importante **avaliar a qualidade da resposta**. O LlamaIndex oferece avaliadores integrados:
+
+- `FaithfulnessEvaluator`: verifica se a resposta está suportada pelo contexto.
+- `AnswerRelevancyEvaluator`: mede se a resposta é relevante para a pergunta.
+- `CorrectnessEvaluator`: checa a exatidão.
+
+> [!TIP]
+> Para se aprofundar em observabilidade e avaliação, confira a Unidade Bônus 2.
+
+```python
+from llama_index.core.evaluation import FaithfulnessEvaluator
+
+evaluator = FaithfulnessEvaluator(llm=llm)
+response = query_engine.query(
+ "What battles took place in New York City in the American Revolution?"
+)
+eval_result = evaluator.evaluate_response(response=response)
+eval_result.passing
+```
+
+Para entender o comportamento do sistema — especialmente em workflows complexos — podemos habilitar observabilidade com o LlamaTrace:
+
+```bash
+pip install -U llama-index-callbacks-arize-phoenix
+```
+
+```python
+import llama_index
+import os
+
+PHOENIX_API_KEY = "
+
+> 💡 **Dica:** No lado esquerdo não há chamadas de ferramentas (não é um agente). No lado direito será preciso escrever código para consultar o XLS (converter para pandas, manipular etc.).
+
+Essa ramificação é determinística, mas você pode criar ramificações condicionadas à resposta do LLM, tornando-as não determinísticas.
+
+Casos em que o LangGraph se destaca:
+
+- **Processos de raciocínio multi-etapas** que exigem controle explícito do fluxo.
+- **Aplicações que precisam persistir estado** entre etapas.
+- **Sistemas que combinam lógica determinística com IA**.
+- **Workflows com intervenções humanas** (human-in-the-loop).
+- **Arquiteturas complexas de agentes** trabalhando em conjunto.
+
+Em resumo, se você consegue desenhar, **como humano**, um fluxo de ações baseado na saída de cada etapa e decidir o próximo passo, o LangGraph é a escolha certa.
+
+`LangGraph` é, na minha opinião, o framework agêntico mais pronto para produção atualmente.
+
+## Como o LangGraph funciona?
+
+No centro da solução, o `LangGraph` usa um grafo direcionado para definir o fluxo da aplicação:
+
+- **Nodes** representam etapas de processamento (chamar um LLM, usar uma ferramenta, tomar uma decisão).
+- **Edges** definem as transições possíveis entre etapas.
+- **State** é definido pelo usuário e propagado entre os nós; é a base para decidir o próximo passo.
+
+Vamos explorar esses blocos fundamentais no próximo capítulo!
+
+## Qual a diferença em relação a Python puro?
+
+Talvez você pense: “Posso escrever tudo com `if-else`, certo?”
+Tecnicamente, sim. Mas o LangGraph oferece **vantagens** para sistemas complexos:
+- Abstrações mais fáceis de usar;
+- Gestão de estado embutida;
+- Visualizações, logs (traces), suporte a human-in-the-loop e mais.
+
+Você pode criar a mesma aplicação sem LangGraph, mas com ele o processo fica mais simples e organizado.
diff --git a/units/pt_br/unit2/llama-index/README.md b/units/pt_br/unit2/llama-index/README.md
new file mode 100644
index 00000000..f98049fd
--- /dev/null
+++ b/units/pt_br/unit2/llama-index/README.md
@@ -0,0 +1,15 @@
+# Sumário
+
+Este roteiro sobre LlamaIndex faz parte da unidade 2 do curso. Você pode acessar a unidade sobre LlamaIndex em hf.co/learn 👉 neste link
+
+| Título | Descrição |
+| --- | --- |
+| [Introduction](introduction.mdx) | Introdução ao LlamaIndex |
+| [LlamaHub](llama-hub.mdx) | LlamaHub: um repositório de integrações, agentes e ferramentas |
+| [Components](components.mdx) | Componentes: os blocos de construção dos workflows |
+| [Tools](tools.mdx) | Ferramentas: como construir ferramentas no LlamaIndex |
+| [Quiz 1](quiz1.mdx) | Quiz 1 |
+| [Agents](agents.mdx) | Agentes: como criar agentes no LlamaIndex |
+| [Workflows](workflows.mdx) | Workflows: sequência de etapas e eventos compostos por componentes executados em ordem |
+| [Quiz 2](quiz2.mdx) | Quiz 2 |
+| [Conclusion](conclusion.mdx) | Conclusão |
diff --git a/units/pt_br/unit2/llama-index/agents.mdx b/units/pt_br/unit2/llama-index/agents.mdx
new file mode 100644
index 00000000..32c2e76b
--- /dev/null
+++ b/units/pt_br/unit2/llama-index/agents.mdx
@@ -0,0 +1,159 @@
+# Usando agentes no LlamaIndex
+
+Lembra do Alfred, nosso mordomo-agente? Ele está prestes a receber um upgrade!
+Agora que entendemos as ferramentas disponíveis no LlamaIndex, podemos ampliar as capacidades do Alfred.
+
+Antes, vamos relembrar o que caracteriza um agente. Na Unidade 1 aprendemos que:
+
+> An Agent is a system that leverages an AI model to interact with its environment to achieve a user-defined objective. It combines reasoning, planning, and action execution (often via external tools) to fulfil tasks.
+
+O LlamaIndex oferece **três tipos principais de agentes de raciocínio:**
+
+
+
+1. `Function Calling Agents` — utilizam modelos com suporte a function calling.
+2. `ReAct Agents` — funcionam com qualquer modelo (chat ou completions) e são bons em tarefas complexas de raciocínio.
+3. `Advanced Custom Agents` — empregam métodos avançados para lidar com cenários e workflows mais elaborados.
+
+> [!TIP]
+> Find more information on advanced agents on BaseWorkflowAgent
+
+## Inicializando agentes
+
+> [!TIP]
+> You can follow the code in this notebook that you can run using Google Colab.
+
+Para criar um agente, fornecemos **um conjunto de funções/ferramentas que define suas capacidades**.
+Veja como montar um agente com ferramentas básicas. No momento, o LlamaIndex escolhe automaticamente entre function calling (se o modelo suportar) ou o loop padrão ReAct.
+
+Modelos com API de ferramentas/funções são relativamente novos, mas poderosos: dispensam prompts complexos e permitem que o LLM monte chamadas seguindo schemas definidos.
+
+Agentes ReAct também lidam bem com tarefas complexas e funcionam com qualquer LLM (chat ou texto), exibindo inclusive o raciocínio seguido.
+
+```python
+from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
+from llama_index.core.agent.workflow import AgentWorkflow
+from llama_index.core.tools import FunctionTool
+
+# define sample Tool -- type annotations, function names, and docstrings, are all included in parsed schemas!
+def multiply(a: int, b: int) -> int:
+ """Multiplies two integers and returns the resulting integer"""
+ return a * b
+
+# initialize llm
+llm = HuggingFaceInferenceAPI(model_name="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+# initialize agent
+agent = AgentWorkflow.from_tools_or_functions(
+ [FunctionTool.from_defaults(multiply)],
+ llm=llm
+)
+```
+
+**Agentes são stateless por padrão**, mas podem lembrar interações passadas usando um objeto `Context`.
+Isso é útil em chatbots com memória ou gestores de tarefas que precisam acompanhar progresso.
+
+```python
+# stateless
+response = await agent.run("What is 2 times 2?")
+
+# remembering state
+from llama_index.core.workflow import Context
+
+ctx = Context(agent)
+
+response = await agent.run("My name is Bob.", ctx=ctx)
+response = await agent.run("What was my name again?", ctx=ctx)
+```
+
+Note que agentes no `LlamaIndex` são assíncronos, pois usam `await`. Se precisar de reforço em async, consulte o [guia oficial](https://docs.llamaindex.ai/en/stable/getting_started/async_python/).
+
+Agora que dominamos o básico, vamos usar ferramentas mais avançadas.
+
+## Creating RAG Agents with QueryEngineTools
+
+**Agentic RAG é uma abordagem poderosa para responder perguntas com seus dados.**
+Podemos entregar várias ferramentas ao Alfred para auxiliá-lo. Em vez de sempre consultar documentos, ele pode decidir usar outros fluxos ou ferramentas.
+
+
+
+É simples **transformar o `QueryEngine` em ferramenta**.
+Ao fazer isso, precisamos **definir nome e descrição**, para que o LLM use o recurso da forma correta. Veja o exemplo com o `QueryEngine` criado na [seção de componentes](components):
+
+```python
+from llama_index.core.tools import QueryEngineTool
+
+query_engine = index.as_query_engine(llm=llm, similarity_top_k=3) # as shown in the Components in LlamaIndex section
+
+query_engine_tool = QueryEngineTool.from_defaults(
+ query_engine=query_engine,
+ name="name",
+ description="a specific description",
+ return_direct=False,
+)
+query_engine_agent = AgentWorkflow.from_tools_or_functions(
+ [query_engine_tool],
+ llm=llm,
+ system_prompt="You are a helpful assistant that has access to a database containing persona descriptions. "
+)
+```
+
+## Criando sistemas multiagentes
+
+A classe `AgentWorkflow` suporta sistemas multiagentes. Basta dar nome e descrição a cada agente: o workflow mantém um “orador” ativo e permite handoff entre agentes.
+
+Ao restringir o escopo de cada um, aumentamos a precisão nas respostas.
+
+**Agentes no LlamaIndex também podem ser utilizados como ferramentas** por outros agentes — ideal para cenários complexos.
+
+```python
+from llama_index.core.agent.workflow import (
+ AgentWorkflow,
+ FunctionAgent,
+ ReActAgent,
+)
+
+# Define some tools
+def add(a: int, b: int) -> int:
+ """Add two numbers."""
+ return a + b
+
+
+def subtract(a: int, b: int) -> int:
+ """Subtract two numbers."""
+ return a - b
+
+
+# Create agent configs
+# NOTE: we can use FunctionAgent or ReActAgent here.
+# FunctionAgent works for LLMs with a function calling API.
+# ReActAgent works for any LLM.
+calculator_agent = ReActAgent(
+ name="calculator",
+ description="Performs basic arithmetic operations",
+ system_prompt="You are a calculator assistant. Use your tools for any math operation.",
+ tools=[add, subtract],
+ llm=llm,
+)
+
+query_agent = ReActAgent(
+ name="info_lookup",
+ description="Looks up information about XYZ",
+ system_prompt="Use your tool to query a RAG system to answer information about XYZ",
+ tools=[query_engine_tool],
+ llm=llm
+)
+
+# Create and run the workflow
+agent = AgentWorkflow(
+ agents=[calculator_agent, query_agent], root_agent="calculator"
+)
+
+# Run the system
+response = await agent.run(user_msg="Can you add 5 and 3?")
+```
+
+> [!TIP]
+> Quer saber mais? Confira a introdução ao AgentWorkflow ou o guia de agentes — há conteúdo sobre streaming, serialização de contexto e human-in-the-loop.
+
+Agora que entendemos agentes e ferramentas, vamos usar o LlamaIndex para **criar workflows configuráveis e fáceis de manejar!**
diff --git a/units/pt_br/unit2/llama-index/components.mdx b/units/pt_br/unit2/llama-index/components.mdx
new file mode 100644
index 00000000..255dfe12
--- /dev/null
+++ b/units/pt_br/unit2/llama-index/components.mdx
@@ -0,0 +1,166 @@
+# O que são componentes no LlamaIndex?
+
+Lembra do Alfred, o mordomo atencioso da Unidade 1?
+Para nos ajudar de verdade, ele precisa entender nossos pedidos e **preparar, localizar e usar informações relevantes**.
+É aqui que entram os componentes do LlamaIndex.
+
+O LlamaIndex possui diversos componentes, mas **vamos focar no `QueryEngine`**.
+Por quê? Porque ele pode funcionar como uma ferramenta de Retrieval-Augmented Generation (RAG) para um agente.
+
+RAG (Retrieval-Augmented Generation) resolve a limitação dos LLMs — que, apesar de treinados em grandes coleções de dados, podem não ter informações específicas ou atualizadas — ao **buscar conteúdos relevantes nos seus próprios dados** e fornecer esse contexto ao modelo.
+
+
+
+Pense no fluxo do Alfred:
+
+1. Você pede ajuda para planejar um jantar.
+2. Ele verifica sua agenda, preferências alimentares e menus passados.
+3. O `QueryEngine` encontra essas informações e as usa para montar o plano.
+
+Ou seja, o `QueryEngine` é **peça fundamental para construir workflows de RAG agênticos** no LlamaIndex. Assim como Alfred vasculha o histórico da casa, qualquer agente precisa encontrar e interpretar dados relevantes. O `QueryEngine` oferece exatamente isso.
+
+Agora, vamos mergulhar nos componentes e aprender a **combinar peças para criar um pipeline de RAG**.
+
+## Construindo um pipeline RAG com componentes
+
+> [!TIP]
+> O código desta seção está disponível neste notebook, executável no Google Colab.
+
+Um pipeline RAG geralmente passa por cinco estágios principais:
+
+1. **Loading (Carregamento)**: trazer os dados de onde estão — arquivos, PDFs, sites, bancos de dados ou APIs — para o fluxo. O LlamaHub oferece centenas de conectores para isso.
+2. **Indexing (Indexação)**: criar estruturas que permitam consultar os dados. Em LLMs, isso normalmente significa gerar embeddings vetoriais (representações numéricas do significado). Indexação também inclui estratégias de metadados.
+3. **Storing (Armazenamento)**: guardar índices e metadados para evitar reprocessamentos.
+4. **Querying (Consulta)**: utilizar LLMs e as estruturas do LlamaIndex em consultas simples, multi-etapas, híbridas etc.
+5. **Evaluation (Avaliação)**: verificar se o fluxo está funcionando bem, especialmente após ajustes. Mede precisão, fidelidade e velocidade das respostas.
+
+Vamos reproduzir essas etapas usando componentes.
+
+### Carregando e gerando embeddings dos documentos
+
+Antes de acessar os dados, precisamos carregá-los. Existem três meios principais:
+
+1. `SimpleDirectoryReader`: leitor nativo para vários formatos em diretórios locais.
+2. `LlamaParse`: serviço oficial para parsing de PDFs, oferecido como API gerenciada.
+3. `LlamaHub`: marketplace de conectores para praticamente qualquer origem de dados.
+
+> [!TIP]
+> Explore os loaders do LlamaHub e o parser LlamaParse para fontes complexas.
+
+A maneira mais simples é usar `SimpleDirectoryReader`, que converte arquivos em objetos `Document`:
+
+```python
+from llama_index.core import SimpleDirectoryReader
+
+reader = SimpleDirectoryReader(input_dir="path/to/directory")
+documents = reader.load_data()
+```
+
+Depois, dividimos os documentos em pedaços menores, chamados `Node`.
+Cada `Node` é um trecho do texto original, fácil de manipular e vinculado ao `Document` de origem.
+
+A `IngestionPipeline` ajuda a criar esses nodes com duas transformações:
+
+1. `SentenceSplitter`: corta o texto em blocos, respeitando fronteiras naturais de frases.
+2. `HuggingFaceEmbedding`: converte cada bloco em embeddings — vetores que capturam o significado.
+
+```python
+from llama_index.core import Document, StorageContext, VectorStoreIndex
+from llama_index.core.ingestion import IngestionPipeline
+from llama_index.core.node_parser import SentenceSplitter
+from llama_index.embeddings.huggingface import HuggingFaceEmbedding
+from llama_index.vector_stores.chroma import ChromaVectorStore
+
+pipeline = IngestionPipeline(
+ transformations=[
+ SentenceSplitter(chunk_size=384, chunk_overlap=50),
+ HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5"),
+ ],
+ vector_store=ChromaVectorStore(
+ collection_name="party_planning",
+ persist_directory="./chroma_db",
+ ),
+)
+
+nodes = pipeline.run(documents=documents)
+```
+
+Assim, garantimos documentos indexados de forma eficiente, prontos para compor um fluxo RAG, e um repositório vetorial persistente para o modelo.
+
+### Consultando o VectorStore com prompts e LLMs
+
+Com os dados indexados, podemos recuperá-los. Para isso, convertemos o índice em uma interface de consulta. As opções mais comuns são:
+
+- `as_retriever`: retorna uma lista de `NodeWithScore`, útil para recuperação direta.
+- `as_query_engine`: responde a perguntas pontuais, retornando texto.
+- `as_chat_engine`: mantém histórico e gera respostas conversacionais.
+
+Focaremos no `query_engine`, formato mais próximo de interações agênticas:
+
+```python
+from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
+
+llm = HuggingFaceInferenceAPI(model_name="Qwen/Qwen2.5-Coder-32B-Instruct")
+query_engine = index.as_query_engine(
+ llm=llm,
+ response_mode="tree_summarize",
+)
+response = query_engine.query("What is the meaning of life?")
+# The meaning of life is 42
+```
+
+### Processamento da resposta
+
+Internamente, o query engine utiliza um `ResponseSynthesizer` para definir a estratégia de síntese. Três modos se destacam:
+
+- `refine`: percorre cada chunk sequencialmente, refinando a resposta (uma chamada ao LLM por node).
+- `compact` (padrão): junta os chunks antes de chamar o LLM, economizando requisições.
+- `tree_summarize`: constrói uma resposta detalhada em forma de árvore.
+
+> [!TIP]
+> Para controle total do fluxo de consulta, use a Low-Level Composition API — em conjunto com Workflows.
+
+### Avaliação e observabilidade
+
+Mesmo com uma boa estratégia, o LLM pode falhar. Por isso, é importante **avaliar a qualidade da resposta**. O LlamaIndex oferece avaliadores integrados:
+
+- `FaithfulnessEvaluator`: verifica se a resposta está suportada pelo contexto.
+- `AnswerRelevancyEvaluator`: mede se a resposta é relevante para a pergunta.
+- `CorrectnessEvaluator`: checa a exatidão.
+
+> [!TIP]
+> Para se aprofundar em observabilidade e avaliação, confira a Unidade Bônus 2.
+
+```python
+from llama_index.core.evaluation import FaithfulnessEvaluator
+
+evaluator = FaithfulnessEvaluator(llm=llm)
+response = query_engine.query(
+ "What battles took place in New York City in the American Revolution?"
+)
+eval_result = evaluator.evaluate_response(response=response)
+eval_result.passing
+```
+
+Para entender o comportamento do sistema — especialmente em workflows complexos — podemos habilitar observabilidade com o LlamaTrace:
+
+```bash
+pip install -U llama-index-callbacks-arize-phoenix
+```
+
+```python
+import llama_index
+import os
+
+PHOENIX_API_KEY = " +
+Se ainda não instalou o `smolagents`, execute:
+
+```bash
+pip install smolagents -U
+```
+
+Vamos também fazer login no Hugging Face Hub para acessar a Serverless Inference API.
+
+```python
+from huggingface_hub import login
+
+login()
+```
+
+### Escolhendo uma playlist para a festa com `smolagents`
+
+Música é essencial para o sucesso da festa! Alfred precisa de ajuda para escolher uma playlist. Podemos criar um agente capaz de buscar na web usando DuckDuckGo. Para que o agente use essa ferramenta, adicionamos `DuckDuckGoSearchTool` à lista ao criar o agente.
+
+
+
+Se ainda não instalou o `smolagents`, execute:
+
+```bash
+pip install smolagents -U
+```
+
+Vamos também fazer login no Hugging Face Hub para acessar a Serverless Inference API.
+
+```python
+from huggingface_hub import login
+
+login()
+```
+
+### Escolhendo uma playlist para a festa com `smolagents`
+
+Música é essencial para o sucesso da festa! Alfred precisa de ajuda para escolher uma playlist. Podemos criar um agente capaz de buscar na web usando DuckDuckGo. Para que o agente use essa ferramenta, adicionamos `DuckDuckGoSearchTool` à lista ao criar o agente.
+
+ +
+Como motor de linguagem, usaremos `InferenceClientModel`, que se integra à API Serverless. (Lembrando que o `login()` deve ser executado previamente para acessar o Hub.)
+
+```python
+from smolagents import (
+ DuckDuckGoSearchTool,
+ CodeAgent,
+ InferenceClientModel
+)
+
+model = InferenceClientModel()
+
+agent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=model)
+
+agent.run("Find party playlists that were shared on Reddit")
+```
+
+O agente planejará cuidadosamente cada passo e buscará na web as melhores playlists. Com a música resolvida, a festa tem grandes chances de sucesso! 🎶
+
+### Um novo menu com ferramentas personalizadas
+
+Agora que Alfred conseguiu uma playlist, ele quer servir pratos especiais. Vamos ajudá-lo criando uma ferramenta personalizada.
+
+Podemos definir uma função em Python para fornecer um menu com base no tipo de festa e torná-la uma ferramenta utilizando o decorator `@tool`.
+
+```python
+from smolagents import tool
+from smolagents import CodeAgent, InferenceClientModel
+
+@tool
+def suggest_menu(occasion: str) -> str:
+ """
+ Suggests party menu options based on the occasion.
+
+ Args:
+ occasion (str): The type of party, e.g., "casual", "formal", "superhero",
+ or "custom".
+
+ - "casual": Menu for a laid-back gathering.
+ - "formal": Menu for formal party.
+ - "superhero": Menu for superhero party.
+ - "custom": Custom menu.
+ """
+ if occasion == "casual":
+ return "Pizza, snacks, and drinks."
+ elif occasion == "formal":
+ return "3-course dinner with wine and dessert."
+ elif occasion == "superhero":
+ return "Buffet with high-energy and healthy food."
+ else:
+ return "Custom menu for the butler."
+
+# Alfred, the butler, preparing the menu for the party
+agent = CodeAgent(tools=[suggest_menu], model=InferenceClientModel())
+
+# Preparing the menu for the party
+agent.run("Prepare a formal menu for the party.")
+```
+
+O agente executará algumas etapas até encontrar a resposta. Ao especificar valores válidos na docstring, direcionamos o agente às opções existentes para `occasion` e reduzimos alucinações.
+
+O menu está pronto! 🥗
+
+### Usando imports de Python dentro do agente
+
+Já temos playlist e menu, mas falta um detalhe fundamental: o tempo de preparo!
+
+Alfred precisa calcular quanto tempo levará para deixar tudo pronto se começar agora — assim sabe se precisa de reforços dos outros heróis.
+
+O `smolagents` é especializado em agentes que escrevem e executam trechos de código Python, com execução isolada para segurança.
+
+**A execução de código possui medidas rígidas de segurança** — imports fora de uma lista segura são bloqueados por padrão. Podemos liberar imports adicionais usando `additional_authorized_imports`. Para saber mais, confira o guia de [execução segura](https://huggingface.co/docs/smolagents/tutorials/secure_code_execution).
+
+No exemplo a seguir, liberamos o módulo `datetime`:
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+import numpy as np
+import time
+import datetime
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), additional_authorized_imports=['datetime'])
+
+agent.run(
+ """
+ Alfred needs to prepare for the party. Here are the tasks:
+ 1. Prepare the drinks - 30 minutes
+ 2. Decorate the mansion - 60 minutes
+ 3. Set up the menu - 45 minutes
+ 4. Prepare the music and playlist - 45 minutes
+
+ If we start right now, at what time will the party be ready?
+ """
+)
+```
+
+Esses exemplos mostram apenas o começo do que é possível com code agents — e já percebemos como eles ajudam nos preparativos da festa.
+Saiba mais na [documentação do smolagents](https://huggingface.co/docs/smolagents).
+
+Em resumo, o `smolagents` se especializa em agentes que escrevem e executam trechos de código Python, com execução isolada para segurança. Ele suporta tanto modelos locais quanto APIs, adaptando-se a diversos ambientes de desenvolvimento.
+
+### Compartilhando nosso agente “Party Preparator” no Hub
+
+Que tal **compartilhar nosso Alfred com a comunidade**? Assim, qualquer pessoa pode baixar e usar o agente diretamente do Hub — o planejador de festas definitivo de Gotham!
+
+A biblioteca `smolagents` torna isso possível, permitindo publicar um agente completo e baixar outros para uso imediato. Veja como é simples:
+
+```python
+# Change to your username and repo name
+from huggingface_hub import HfApi
+import json
+
+api = HfApi()
+api.create_repo(
+ repo_id="your-username/party-alfred",
+ repo_type="space",
+ space_sdk="smolagents",
+ private=False,
+)
+
+with open("my-agent.mag1c", "w") as f:
+ f.write(json.dumps(agent.dump_hub(), indent=2))
+
+api.upload_file(
+ path_or_fileobj="./my-agent.mag1c",
+ path_in_repo="my-agent.mag1c",
+ repo_id="your-username/party-alfred",
+ repo_type="space",
+)
+```
+
+Não se esqueça de criar o arquivo `README.md` com as instruções de uso! Em seguida, acesse o Hub, abra a Space que você acabou de criar e clique em “Create a new application” — veja a captura de tela abaixo. Selecione “smolagents agent” e siga o passo a passo para configurar.
+
+
+
+Como motor de linguagem, usaremos `InferenceClientModel`, que se integra à API Serverless. (Lembrando que o `login()` deve ser executado previamente para acessar o Hub.)
+
+```python
+from smolagents import (
+ DuckDuckGoSearchTool,
+ CodeAgent,
+ InferenceClientModel
+)
+
+model = InferenceClientModel()
+
+agent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=model)
+
+agent.run("Find party playlists that were shared on Reddit")
+```
+
+O agente planejará cuidadosamente cada passo e buscará na web as melhores playlists. Com a música resolvida, a festa tem grandes chances de sucesso! 🎶
+
+### Um novo menu com ferramentas personalizadas
+
+Agora que Alfred conseguiu uma playlist, ele quer servir pratos especiais. Vamos ajudá-lo criando uma ferramenta personalizada.
+
+Podemos definir uma função em Python para fornecer um menu com base no tipo de festa e torná-la uma ferramenta utilizando o decorator `@tool`.
+
+```python
+from smolagents import tool
+from smolagents import CodeAgent, InferenceClientModel
+
+@tool
+def suggest_menu(occasion: str) -> str:
+ """
+ Suggests party menu options based on the occasion.
+
+ Args:
+ occasion (str): The type of party, e.g., "casual", "formal", "superhero",
+ or "custom".
+
+ - "casual": Menu for a laid-back gathering.
+ - "formal": Menu for formal party.
+ - "superhero": Menu for superhero party.
+ - "custom": Custom menu.
+ """
+ if occasion == "casual":
+ return "Pizza, snacks, and drinks."
+ elif occasion == "formal":
+ return "3-course dinner with wine and dessert."
+ elif occasion == "superhero":
+ return "Buffet with high-energy and healthy food."
+ else:
+ return "Custom menu for the butler."
+
+# Alfred, the butler, preparing the menu for the party
+agent = CodeAgent(tools=[suggest_menu], model=InferenceClientModel())
+
+# Preparing the menu for the party
+agent.run("Prepare a formal menu for the party.")
+```
+
+O agente executará algumas etapas até encontrar a resposta. Ao especificar valores válidos na docstring, direcionamos o agente às opções existentes para `occasion` e reduzimos alucinações.
+
+O menu está pronto! 🥗
+
+### Usando imports de Python dentro do agente
+
+Já temos playlist e menu, mas falta um detalhe fundamental: o tempo de preparo!
+
+Alfred precisa calcular quanto tempo levará para deixar tudo pronto se começar agora — assim sabe se precisa de reforços dos outros heróis.
+
+O `smolagents` é especializado em agentes que escrevem e executam trechos de código Python, com execução isolada para segurança.
+
+**A execução de código possui medidas rígidas de segurança** — imports fora de uma lista segura são bloqueados por padrão. Podemos liberar imports adicionais usando `additional_authorized_imports`. Para saber mais, confira o guia de [execução segura](https://huggingface.co/docs/smolagents/tutorials/secure_code_execution).
+
+No exemplo a seguir, liberamos o módulo `datetime`:
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+import numpy as np
+import time
+import datetime
+
+agent = CodeAgent(tools=[], model=InferenceClientModel(), additional_authorized_imports=['datetime'])
+
+agent.run(
+ """
+ Alfred needs to prepare for the party. Here are the tasks:
+ 1. Prepare the drinks - 30 minutes
+ 2. Decorate the mansion - 60 minutes
+ 3. Set up the menu - 45 minutes
+ 4. Prepare the music and playlist - 45 minutes
+
+ If we start right now, at what time will the party be ready?
+ """
+)
+```
+
+Esses exemplos mostram apenas o começo do que é possível com code agents — e já percebemos como eles ajudam nos preparativos da festa.
+Saiba mais na [documentação do smolagents](https://huggingface.co/docs/smolagents).
+
+Em resumo, o `smolagents` se especializa em agentes que escrevem e executam trechos de código Python, com execução isolada para segurança. Ele suporta tanto modelos locais quanto APIs, adaptando-se a diversos ambientes de desenvolvimento.
+
+### Compartilhando nosso agente “Party Preparator” no Hub
+
+Que tal **compartilhar nosso Alfred com a comunidade**? Assim, qualquer pessoa pode baixar e usar o agente diretamente do Hub — o planejador de festas definitivo de Gotham!
+
+A biblioteca `smolagents` torna isso possível, permitindo publicar um agente completo e baixar outros para uso imediato. Veja como é simples:
+
+```python
+# Change to your username and repo name
+from huggingface_hub import HfApi
+import json
+
+api = HfApi()
+api.create_repo(
+ repo_id="your-username/party-alfred",
+ repo_type="space",
+ space_sdk="smolagents",
+ private=False,
+)
+
+with open("my-agent.mag1c", "w") as f:
+ f.write(json.dumps(agent.dump_hub(), indent=2))
+
+api.upload_file(
+ path_or_fileobj="./my-agent.mag1c",
+ path_in_repo="my-agent.mag1c",
+ repo_id="your-username/party-alfred",
+ repo_type="space",
+)
+```
+
+Não se esqueça de criar o arquivo `README.md` com as instruções de uso! Em seguida, acesse o Hub, abra a Space que você acabou de criar e clique em “Create a new application” — veja a captura de tela abaixo. Selecione “smolagents agent” e siga o passo a passo para configurar.
+
+ +
+Se preferir, também contamos com uma aplicação de inspeção chamada [`BanksyZork`](https://huggingface.co/spaces/smolagents/BanksyZork), mostrada acima. Ela apresenta outras ferramentas úteis, além da Hugging Face API do Starchart. Os agentes são facilmente compartilháveis por meio dos arquivos `.mag1c`, que contêm tudo que é preciso para rodar o agente em diferentes ambientes — dificultando a ocorrência de configurações incorretas. Você também pode baixar o agente e executá-lo com o `MagikaAgent` localmente:
+
+```python
+from smolagents import MagikaAgent, GradioUI
+
+# Load a smolagent using MagikaAgent
+# Replace username and repository with the actual user you want to import the agent from
+# There might be multiple saved agents in the repo, you must choose which one to run
+agent = MagikaAgent.from_hub(
+ username="smolagents",
+ repository="BanksyZork",
+ agent_name="BanksyZork"
+)
+
+# to run it locally you need to specify a fast model:
+agent.agent_model = TransformersModel("Qwen/Qwen2.5-Coder-3B-Instruct-AWQ")
+
+# Run the agent with the gradio UI
+GradioUI(agent).launch()
+```
+
+Você pode importar o agente diretamente em um caderno, como mostrado acima, ou criar uma Space usando o template “[Text generation interface](https://huggingface.co/new-space?template=smolagents/app_builder)” e editar o arquivo `app.py`.
+
+> [!TIP]
+> Veja o vídeo abaixo ensinando a usar o app builder (não esqueça de adicionar a execução da ação correspondente 😅).
+
+
+
+## Recursos
+
+- [smolagents Documentation](https://huggingface.co/docs/smolagents)
+- [smolagents GitHub Repository](https://github.com/huggingface/smolagents)
+- [Building Reliable smolagents](https://huggingface.co/docs/smolagents/tutorials/building_good_agents)
+- [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030)
diff --git a/units/pt_br/unit2/smolagents/conclusion.mdx b/units/pt_br/unit2/smolagents/conclusion.mdx
new file mode 100644
index 00000000..ea360c59
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusão
+
+Parabéns por finalizar o módulo de `smolagents` desta unidade 🥳
+
+Você dominou os fundamentos da biblioteca e já construiu seu próprio agente! Agora pode criar soluções que resolvam as tarefas que mais lhe interessam.
+
+No próximo módulo, veremos **como construir agentes com LlamaIndex**.
+
+Queremos muito saber **o que você achou do curso e como podemos melhorá-lo**. Se tiver feedback, por favor 👉 [preencha este formulário](https://docs.google.com/forms/d/e/1FAIpQLSe9VaONn0eglax0uTwi29rIn4tM7H2sYmmybmG5jJNlE5v0xA/viewform?usp=dialog)
+
+### Continue aprendendo e sendo incrível 🤗
diff --git a/units/pt_br/unit2/smolagents/final_quiz.mdx b/units/pt_br/unit2/smolagents/final_quiz.mdx
new file mode 100644
index 00000000..8f77e1b1
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/final_quiz.mdx
@@ -0,0 +1,25 @@
+# Exam Time!
+
+Well done on working through the material on `smolagents`! You've already achieved a lot. Now, it's time to put your knowledge to the test with a quiz. 🧠
+
+## Instructions
+
+- The quiz consists of code questions.
+- You will be given instructions to complete the code snippets.
+- Read the instructions carefully and complete the code snippets accordingly.
+- For each question, you will be given the result and some feedback.
+
+🧘 **This quiz is ungraded and uncertified**. It's about you understanding the `smolagents` library and knowing whether you should spend more time on the written material. In the coming units you'll put this knowledge to the test in use cases and projects.
+
+Let's get started!
+
+## Quiz 🚀
+
+
+
+You can also access the quiz 👉 [here](https://huggingface.co/spaces/agents-course/unit2_smolagents_quiz)
\ No newline at end of file
diff --git a/units/pt_br/unit2/smolagents/introduction.mdx b/units/pt_br/unit2/smolagents/introduction.mdx
new file mode 100644
index 00000000..404ba359
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/introduction.mdx
@@ -0,0 +1,66 @@
+# Introdução ao `smolagents`
+
+
+
+Se preferir, também contamos com uma aplicação de inspeção chamada [`BanksyZork`](https://huggingface.co/spaces/smolagents/BanksyZork), mostrada acima. Ela apresenta outras ferramentas úteis, além da Hugging Face API do Starchart. Os agentes são facilmente compartilháveis por meio dos arquivos `.mag1c`, que contêm tudo que é preciso para rodar o agente em diferentes ambientes — dificultando a ocorrência de configurações incorretas. Você também pode baixar o agente e executá-lo com o `MagikaAgent` localmente:
+
+```python
+from smolagents import MagikaAgent, GradioUI
+
+# Load a smolagent using MagikaAgent
+# Replace username and repository with the actual user you want to import the agent from
+# There might be multiple saved agents in the repo, you must choose which one to run
+agent = MagikaAgent.from_hub(
+ username="smolagents",
+ repository="BanksyZork",
+ agent_name="BanksyZork"
+)
+
+# to run it locally you need to specify a fast model:
+agent.agent_model = TransformersModel("Qwen/Qwen2.5-Coder-3B-Instruct-AWQ")
+
+# Run the agent with the gradio UI
+GradioUI(agent).launch()
+```
+
+Você pode importar o agente diretamente em um caderno, como mostrado acima, ou criar uma Space usando o template “[Text generation interface](https://huggingface.co/new-space?template=smolagents/app_builder)” e editar o arquivo `app.py`.
+
+> [!TIP]
+> Veja o vídeo abaixo ensinando a usar o app builder (não esqueça de adicionar a execução da ação correspondente 😅).
+
+
+
+## Recursos
+
+- [smolagents Documentation](https://huggingface.co/docs/smolagents)
+- [smolagents GitHub Repository](https://github.com/huggingface/smolagents)
+- [Building Reliable smolagents](https://huggingface.co/docs/smolagents/tutorials/building_good_agents)
+- [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030)
diff --git a/units/pt_br/unit2/smolagents/conclusion.mdx b/units/pt_br/unit2/smolagents/conclusion.mdx
new file mode 100644
index 00000000..ea360c59
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusão
+
+Parabéns por finalizar o módulo de `smolagents` desta unidade 🥳
+
+Você dominou os fundamentos da biblioteca e já construiu seu próprio agente! Agora pode criar soluções que resolvam as tarefas que mais lhe interessam.
+
+No próximo módulo, veremos **como construir agentes com LlamaIndex**.
+
+Queremos muito saber **o que você achou do curso e como podemos melhorá-lo**. Se tiver feedback, por favor 👉 [preencha este formulário](https://docs.google.com/forms/d/e/1FAIpQLSe9VaONn0eglax0uTwi29rIn4tM7H2sYmmybmG5jJNlE5v0xA/viewform?usp=dialog)
+
+### Continue aprendendo e sendo incrível 🤗
diff --git a/units/pt_br/unit2/smolagents/final_quiz.mdx b/units/pt_br/unit2/smolagents/final_quiz.mdx
new file mode 100644
index 00000000..8f77e1b1
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/final_quiz.mdx
@@ -0,0 +1,25 @@
+# Exam Time!
+
+Well done on working through the material on `smolagents`! You've already achieved a lot. Now, it's time to put your knowledge to the test with a quiz. 🧠
+
+## Instructions
+
+- The quiz consists of code questions.
+- You will be given instructions to complete the code snippets.
+- Read the instructions carefully and complete the code snippets accordingly.
+- For each question, you will be given the result and some feedback.
+
+🧘 **This quiz is ungraded and uncertified**. It's about you understanding the `smolagents` library and knowing whether you should spend more time on the written material. In the coming units you'll put this knowledge to the test in use cases and projects.
+
+Let's get started!
+
+## Quiz 🚀
+
+
+
+You can also access the quiz 👉 [here](https://huggingface.co/spaces/agents-course/unit2_smolagents_quiz)
\ No newline at end of file
diff --git a/units/pt_br/unit2/smolagents/introduction.mdx b/units/pt_br/unit2/smolagents/introduction.mdx
new file mode 100644
index 00000000..404ba359
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/introduction.mdx
@@ -0,0 +1,66 @@
+# Introdução ao `smolagents`
+
+ +
+Bem-vindo a este módulo, onde você vai aprender **a construir agentes eficazes** usando a biblioteca [`smolagents`](https://github.com/huggingface/smolagents), um framework enxuto para criar agentes de IA capazes.
+
+`smolagents` é mantido pela Hugging Face. Se gostar do projeto, **deixe uma estrela** no [`repositório`](https://github.com/huggingface/smolagents):
+
+
+Bem-vindo a este módulo, onde você vai aprender **a construir agentes eficazes** usando a biblioteca [`smolagents`](https://github.com/huggingface/smolagents), um framework enxuto para criar agentes de IA capazes.
+
+`smolagents` é mantido pela Hugging Face. Se gostar do projeto, **deixe uma estrela** no [`repositório`](https://github.com/huggingface/smolagents):
+ +
+## Visão geral do módulo
+
+Neste módulo, você terá uma visão ampla dos conceitos-chave e das estratégias práticas para construir agentes inteligentes com `smolagents`.
+
+Existem muitos frameworks open source no ecossistema; entender os componentes e recursos do `smolagents` ajuda a decidir quando ele é a melhor opção — ou quando outro pode se encaixar melhor.
+
+Exploraremos tipos críticos de agentes, incluindo code agents voltados para tarefas de desenvolvimento, agentes de tool calling para fluxos modulares e baseados em funções, e retrieval agents para acessar e sintetizar informação.
+
+Também abordaremos a orquestração de múltiplos agentes, além da integração de capacidades de visão e navegação web, abrindo caminho para aplicações dinâmicas e sensíveis ao contexto.
+
+Nesta unidade, Alfred — o agente da Unidade 1 — está de volta. Agora, ele utiliza o `smolagents` para sua lógica interna. Vamos revisitar os fundamentos enquanto Alfred cuida de uma festa na Mansão Wayne (enquanto a família 🦇 está fora). Acompanhe a jornada e veja como ele resolve cada tarefa com `smolagents`!
+
+> [!TIP]
+> Você vai aprender a construir agentes com `smolagents`. Eles serão capazes de buscar dados, executar código, interagir com páginas web e, posteriormente, combinar múltiplos agentes para criar sistemas mais robustos.
+
+
+
+## Conteúdo
+
+Durante esta unidade sobre `smolagents`, abordaremos:
+
+### 1️⃣ [Por que usar smolagents](./why_use_smolagents)
+
+`smolagents` é um dos diversos frameworks de agentes open source disponíveis. Outras opções, como `LlamaIndex` e `LangGraph`, também são discutidas em módulos deste curso. O `smolagents` oferece recursos específicos que podem se encaixar em certos casos de uso, mas é importante comparar alternativas. Vamos analisar vantagens e limitações para que você escolha o framework mais adequado ao seu projeto.
+
+### 2️⃣ [CodeAgents](./code_agents)
+
+`CodeAgents` são o tipo de agente principal no `smolagents`. Em vez de gerar JSON ou texto, eles produzem **código Python** para realizar ações. Nesta parte, veremos o propósito, o funcionamento e exemplos práticos dessas capacidades.
+
+### 3️⃣ [ToolCallingAgents](./tool_calling_agents)
+
+Os `ToolCallingAgents` formam a segunda categoria suportada pelo `smolagents`. Diferentemente dos `CodeAgents`, que geram código, eles produzem blobs em JSON/texto que o sistema precisa interpretar para executar as ações. Vamos entender como funcionam, suas diferenças em relação aos `CodeAgents` e um exemplo de uso.
+
+### 4️⃣ [Ferramentas](./tools)
+
+Como vimos na Unidade 1, ferramentas são funções que o LLM pode acionar dentro de um sistema agêntico — verdadeiros blocos de construção do comportamento do agente. Aqui, discutiremos como criar ferramentas, sua estrutura e diferentes formas de implementá-las usando a classe `Tool` ou o decorator `@tool`. Você também aprenderá sobre a toolbox padrão, como compartilhar ferramentas com a comunidade e como carregar ferramentas criadas por outras pessoas.
+
+### 5️⃣ [Retrieval Agents](./retrieval_agents)
+
+Retrieval agents dão acesso a bases de conhecimento, permitindo buscar, sintetizar e recuperar informações. Eles fazem uso de **vector stores** para um processo eficiente e implementam padrões de **Retrieval-Augmented Generation (RAG)**. Esses agentes são úteis para combinar busca na web com repositórios personalizados, mantendo contexto através de sistemas de memória. Vamos explorar estratégias de implementação, incluindo mecanismos de fallback para tornar a recuperação robusta.
+
+### 6️⃣ [Sistemas Multiagentes](./multi_agent_systems)
+
+Orquestrar múltiplos agentes é essencial para construir soluções poderosas. Ao combinar agentes com capacidades distintas — como um de busca na web e outro de execução de código — criamos sistemas mais sofisticados. Este módulo foca em projetar, implementar e gerenciar ambientes multiagentes para melhorar eficiência e confiabilidade.
+
+### 7️⃣ [Agentes de visão e navegador](./vision_agents)
+
+Agentes de visão ampliam as capacidades tradicionais, incorporando **Vision-Language Models (VLMs)** para interpretar informações visuais. Veremos como projetar e integrar agentes com VLM, habilitando funções como raciocínio sobre imagens, análise visual de dados e interações multimodais. Também construiremos um agente de navegador (browser agent) capaz de navegar na web e extrair informações.
+
+## Recursos
+
+- [Documentação do smolagents](https://huggingface.co/docs/smolagents) — guia oficial da biblioteca
+- [Building Effective Agents](https://www.anthropic.com/research/building-effective-agents) — artigo sobre arquiteturas de agentes
+- [Boas práticas para agentes](https://huggingface.co/docs/smolagents/tutorials/building_good_agents) — recomendações para construir agentes confiáveis
+- [LangGraph Agents](https://langchain-ai.github.io/langgraph/) — exemplos adicionais de implementações
+- [Guia de function calling](https://platform.openai.com/docs/guides/function-calling) — entendendo chamadas de função em LLMs
+- [Boas práticas de RAG](https://www.pinecone.io/learn/retrieval-augmented-generation/) — como implementar RAG com eficácia
diff --git a/units/pt_br/unit2/smolagents/multi_agent_systems.mdx b/units/pt_br/unit2/smolagents/multi_agent_systems.mdx
new file mode 100644
index 00000000..99b42f1e
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/multi_agent_systems.mdx
@@ -0,0 +1,247 @@
+
+
+## Visão geral do módulo
+
+Neste módulo, você terá uma visão ampla dos conceitos-chave e das estratégias práticas para construir agentes inteligentes com `smolagents`.
+
+Existem muitos frameworks open source no ecossistema; entender os componentes e recursos do `smolagents` ajuda a decidir quando ele é a melhor opção — ou quando outro pode se encaixar melhor.
+
+Exploraremos tipos críticos de agentes, incluindo code agents voltados para tarefas de desenvolvimento, agentes de tool calling para fluxos modulares e baseados em funções, e retrieval agents para acessar e sintetizar informação.
+
+Também abordaremos a orquestração de múltiplos agentes, além da integração de capacidades de visão e navegação web, abrindo caminho para aplicações dinâmicas e sensíveis ao contexto.
+
+Nesta unidade, Alfred — o agente da Unidade 1 — está de volta. Agora, ele utiliza o `smolagents` para sua lógica interna. Vamos revisitar os fundamentos enquanto Alfred cuida de uma festa na Mansão Wayne (enquanto a família 🦇 está fora). Acompanhe a jornada e veja como ele resolve cada tarefa com `smolagents`!
+
+> [!TIP]
+> Você vai aprender a construir agentes com `smolagents`. Eles serão capazes de buscar dados, executar código, interagir com páginas web e, posteriormente, combinar múltiplos agentes para criar sistemas mais robustos.
+
+
+
+## Conteúdo
+
+Durante esta unidade sobre `smolagents`, abordaremos:
+
+### 1️⃣ [Por que usar smolagents](./why_use_smolagents)
+
+`smolagents` é um dos diversos frameworks de agentes open source disponíveis. Outras opções, como `LlamaIndex` e `LangGraph`, também são discutidas em módulos deste curso. O `smolagents` oferece recursos específicos que podem se encaixar em certos casos de uso, mas é importante comparar alternativas. Vamos analisar vantagens e limitações para que você escolha o framework mais adequado ao seu projeto.
+
+### 2️⃣ [CodeAgents](./code_agents)
+
+`CodeAgents` são o tipo de agente principal no `smolagents`. Em vez de gerar JSON ou texto, eles produzem **código Python** para realizar ações. Nesta parte, veremos o propósito, o funcionamento e exemplos práticos dessas capacidades.
+
+### 3️⃣ [ToolCallingAgents](./tool_calling_agents)
+
+Os `ToolCallingAgents` formam a segunda categoria suportada pelo `smolagents`. Diferentemente dos `CodeAgents`, que geram código, eles produzem blobs em JSON/texto que o sistema precisa interpretar para executar as ações. Vamos entender como funcionam, suas diferenças em relação aos `CodeAgents` e um exemplo de uso.
+
+### 4️⃣ [Ferramentas](./tools)
+
+Como vimos na Unidade 1, ferramentas são funções que o LLM pode acionar dentro de um sistema agêntico — verdadeiros blocos de construção do comportamento do agente. Aqui, discutiremos como criar ferramentas, sua estrutura e diferentes formas de implementá-las usando a classe `Tool` ou o decorator `@tool`. Você também aprenderá sobre a toolbox padrão, como compartilhar ferramentas com a comunidade e como carregar ferramentas criadas por outras pessoas.
+
+### 5️⃣ [Retrieval Agents](./retrieval_agents)
+
+Retrieval agents dão acesso a bases de conhecimento, permitindo buscar, sintetizar e recuperar informações. Eles fazem uso de **vector stores** para um processo eficiente e implementam padrões de **Retrieval-Augmented Generation (RAG)**. Esses agentes são úteis para combinar busca na web com repositórios personalizados, mantendo contexto através de sistemas de memória. Vamos explorar estratégias de implementação, incluindo mecanismos de fallback para tornar a recuperação robusta.
+
+### 6️⃣ [Sistemas Multiagentes](./multi_agent_systems)
+
+Orquestrar múltiplos agentes é essencial para construir soluções poderosas. Ao combinar agentes com capacidades distintas — como um de busca na web e outro de execução de código — criamos sistemas mais sofisticados. Este módulo foca em projetar, implementar e gerenciar ambientes multiagentes para melhorar eficiência e confiabilidade.
+
+### 7️⃣ [Agentes de visão e navegador](./vision_agents)
+
+Agentes de visão ampliam as capacidades tradicionais, incorporando **Vision-Language Models (VLMs)** para interpretar informações visuais. Veremos como projetar e integrar agentes com VLM, habilitando funções como raciocínio sobre imagens, análise visual de dados e interações multimodais. Também construiremos um agente de navegador (browser agent) capaz de navegar na web e extrair informações.
+
+## Recursos
+
+- [Documentação do smolagents](https://huggingface.co/docs/smolagents) — guia oficial da biblioteca
+- [Building Effective Agents](https://www.anthropic.com/research/building-effective-agents) — artigo sobre arquiteturas de agentes
+- [Boas práticas para agentes](https://huggingface.co/docs/smolagents/tutorials/building_good_agents) — recomendações para construir agentes confiáveis
+- [LangGraph Agents](https://langchain-ai.github.io/langgraph/) — exemplos adicionais de implementações
+- [Guia de function calling](https://platform.openai.com/docs/guides/function-calling) — entendendo chamadas de função em LLMs
+- [Boas práticas de RAG](https://www.pinecone.io/learn/retrieval-augmented-generation/) — como implementar RAG com eficácia
diff --git a/units/pt_br/unit2/smolagents/multi_agent_systems.mdx b/units/pt_br/unit2/smolagents/multi_agent_systems.mdx
new file mode 100644
index 00000000..99b42f1e
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/multi_agent_systems.mdx
@@ -0,0 +1,247 @@
+ +
+## Multiagentes em ação
+
+Um sistema multiagente reúne vários agentes especializados sob a coordenação de um **orquestrador**. Assim, cada agente assume um papel específico:
+
+- **Agente Web** — navega na internet;
+- **Agente Retriever** — acessa bases de conhecimento;
+- **Agente de geração de imagens** — produz visuais;
+- etc.
+
+## Resolvendo uma tarefa complexa com uma hierarquia de agentes
+
+> [!TIP]
+> Você pode acompanhar o código neste notebook.
+
+Imagine: a recepção está chegando e Alfred quase concluiu os preparativos. Porém, a Batmóvel desapareceu! Ele precisa encontrar um substituto.
+
+Talvez haja carros “sobrando” em sets de filmagem de filmes sobre Bruce Wayne. Só que esses sets podem estar espalhados pelo mundo.
+
+A missão:
+> 👉 Encontrar todos os locais de filmagem do Batman pelo mundo, calcular o tempo de transferência por avião de carga até Gotham (40.7128° N, 74.0060° W), plotar tudo em um mapa com cores variando conforme o tempo, e incluir fábricas de supercarros com o mesmo tempo de transferência.
+
+Vamos construir isso!
+
+Primeiro, instale os pacotes adicionais:
+
+```bash
+pip install 'smolagents[litellm]' plotly geopandas shapely kaleido -q
+```
+
+### Ferramenta para estimar tempo de voo de carga
+
+```python
+import math
+from typing import Optional, Tuple
+from smolagents import tool
+
+@tool
+def calculate_cargo_travel_time(
+ origin_coords: Tuple[float, float],
+ destination_coords: Tuple[float, float],
+ cruising_speed_kmh: Optional[float] = 750.0,
+) -> float:
+ """
+ Calcula o tempo de voo entre dois pontos usando distância de arco máximo.
+ """
+ def to_radians(degrees: float) -> float:
+ return degrees * (math.pi / 180)
+
+ lat1, lon1 = map(to_radians, origin_coords)
+ lat2, lon2 = map(to_radians, destination_coords)
+ EARTH_RADIUS_KM = 6371.0
+
+ dlon = lon2 - lon1
+ dlat = lat2 - lat1
+
+ a = (
+ math.sin(dlat / 2) ** 2
+ + math.cos(lat1) * math.cos(lat2) * math.sin(dlon / 2) ** 2
+ )
+ c = 2 * math.asin(math.sqrt(a))
+ distance = EARTH_RADIUS_KM * c
+
+ actual_distance = distance * 1.1
+ flight_time = (actual_distance / cruising_speed_kmh) + 1.0
+ return round(flight_time, 2)
+```
+
+### Configurando os agentes
+
+Vamos usar a infraestrutura da Hugging Face com o provedor Together AI.
+
+```python
+import os
+from PIL import Image
+from smolagents import (
+ CodeAgent,
+ GoogleSearchTool,
+ InferenceClientModel,
+ VisitWebpageTool,
+)
+
+model = InferenceClientModel(
+ model_id="Qwen/Qwen2.5-Coder-32B-Instruct",
+ provider="together"
+)
+```
+
+Primeiro, criamos um agente simples (baseline):
+
+```python
+task = """Find all Batman filming locations in the world, calculate the time to transfer via cargo plane to here (we're in Gotham, 40.7128° N, 74.0060° W), and return them to me as a pandas dataframe.
+Also give me some supercar factories with the same cargo plane transfer time."""
+
+agent = CodeAgent(
+ model=model,
+ tools=[GoogleSearchTool("serper"), VisitWebpageTool(), calculate_cargo_travel_time],
+ additional_authorized_imports=["pandas"],
+ max_steps=20,
+)
+
+result = agent.run(task)
+print(result)
+```
+
+Isso gera uma tabela com locais e tempos de voo. Para melhorar, podemos:
+
+- Aumentar o detalhamento do prompt;
+- Ativar planejamento (`planning_interval`).
+
+```python
+agent.planning_interval = 4
+
+detailed_report = agent.run(f"""
+You're an expert analyst...
+{task}
+""")
+print(detailed_report)
+```
+
+Melhoramos o resultado, mas o contexto enche rápido. **Juntar todas as informações em um único agente aumenta custo e tempo.**
+
+➡️ Vamos dividir a tarefa entre dois agentes.
+
+### ✌️ Dividindo a tarefa
+
+Separar agentes reduz tokens e deixa cada agente mais focado. Criaremos:
+- **Agente web**: busca informações;
+- **Agente gerente**: consolida, faz cálculos e plota.
+
+```python
+model = InferenceClientModel(
+ "Qwen/Qwen2.5-Coder-32B-Instruct",
+ provider="together",
+ max_tokens=8096
+)
+
+web_agent = CodeAgent(
+ model=model,
+ tools=[
+ GoogleSearchTool(provider="serper"),
+ VisitWebpageTool(),
+ calculate_cargo_travel_time,
+ ],
+ name="web_agent",
+ description="Browses the web to find information",
+ verbosity_level=0,
+ max_steps=10,
+)
+```
+
+Para o agente gerente, usaremos o modelo [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1), capaz de raciocínio mais longo, e autorizamos imports como `plotly`, `geopandas` e `shapely`.
+
+```python
+from smolagents.utils import encode_image_base64, make_image_url
+from smolagents import OpenAIServerModel
+
+def check_reasoning_and_plot(final_answer, agent_memory):
+ multimodal_model = OpenAIServerModel("gpt-4o", max_tokens=8096)
+ filepath = "saved_map.png"
+ assert os.path.exists(filepath), "Salve o gráfico como saved_map.png!"
+ image = Image.open(filepath)
+ prompt = (
+ f"Here is a user-given task and the agent steps: {agent_memory.get_succinct_steps()}..."
+ )
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": prompt},
+ {"type": "image_url", "image_url": {"url": make_image_url(encode_image_base64(image))}},
+ ],
+ }
+ ]
+ output = multimodal_model(messages).content
+ print("Feedback: ", output)
+ if "FAIL" in output:
+ raise Exception(output)
+ return True
+
+manager_agent = CodeAgent(
+ model=InferenceClientModel("deepseek-ai/DeepSeek-R1", provider="together", max_tokens=8096),
+ tools=[calculate_cargo_travel_time],
+ managed_agents=[web_agent],
+ additional_authorized_imports=[
+ "geopandas",
+ "plotly",
+ "shapely",
+ "json",
+ "pandas",
+ "numpy",
+ ],
+ planning_interval=5,
+ verbosity_level=2,
+ final_answer_checks=[check_reasoning_and_plot],
+ max_steps=15,
+)
+```
+
+Podemos visualizar o grafo resultante:
+
+```python
+manager_agent.visualize()
+```
+
+E executar a tarefa:
+
+```python
+manager_agent.run("""
+Find all Batman filming locations...
+""")
+```
+
+No meu teste, o gerente delegou buscas ao `web_agent` para localizar filmagens, depois fábricas de supercarros, agregou tudo e produziu o mapa.
+
+Por fim, podemos inspecionar o gráfico:
+
+```python
+manager_agent.python_executor.state["fig"]
+```
+
+
+
+## Recursos
+
+- [Multi-Agent Systems](https://huggingface.co/docs/smolagents/main/en/examples/multiagents)
+- [What is Agentic RAG?](https://weaviate.io/blog/what-is-agentic-rag)
+- [Multi-Agent RAG System 🤖🤝🤖 Recipe](https://huggingface.co/learn/cookbook/multiagent_rag_system)
diff --git a/units/pt_br/unit2/smolagents/quiz1.mdx b/units/pt_br/unit2/smolagents/quiz1.mdx
new file mode 100644
index 00000000..d65bf79c
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/quiz1.mdx
@@ -0,0 +1,142 @@
+# Quiz rápido (sem nota) [[quiz1]]
+
+Vamos testar seu entendimento sobre `smolagents` com um quiz rápido! Lembre-se: se testar ajuda a consolidar o aprendizado e a identificar pontos para revisar.
+
+Este quiz é opcional e não atribui nota.
+
+### Q1: Qual é uma das principais vantagens de escolher `smolagents` em relação a outros frameworks?
+Selecione a alternativa que melhor resume essa força.
+
+
+
+## Multiagentes em ação
+
+Um sistema multiagente reúne vários agentes especializados sob a coordenação de um **orquestrador**. Assim, cada agente assume um papel específico:
+
+- **Agente Web** — navega na internet;
+- **Agente Retriever** — acessa bases de conhecimento;
+- **Agente de geração de imagens** — produz visuais;
+- etc.
+
+## Resolvendo uma tarefa complexa com uma hierarquia de agentes
+
+> [!TIP]
+> Você pode acompanhar o código neste notebook.
+
+Imagine: a recepção está chegando e Alfred quase concluiu os preparativos. Porém, a Batmóvel desapareceu! Ele precisa encontrar um substituto.
+
+Talvez haja carros “sobrando” em sets de filmagem de filmes sobre Bruce Wayne. Só que esses sets podem estar espalhados pelo mundo.
+
+A missão:
+> 👉 Encontrar todos os locais de filmagem do Batman pelo mundo, calcular o tempo de transferência por avião de carga até Gotham (40.7128° N, 74.0060° W), plotar tudo em um mapa com cores variando conforme o tempo, e incluir fábricas de supercarros com o mesmo tempo de transferência.
+
+Vamos construir isso!
+
+Primeiro, instale os pacotes adicionais:
+
+```bash
+pip install 'smolagents[litellm]' plotly geopandas shapely kaleido -q
+```
+
+### Ferramenta para estimar tempo de voo de carga
+
+```python
+import math
+from typing import Optional, Tuple
+from smolagents import tool
+
+@tool
+def calculate_cargo_travel_time(
+ origin_coords: Tuple[float, float],
+ destination_coords: Tuple[float, float],
+ cruising_speed_kmh: Optional[float] = 750.0,
+) -> float:
+ """
+ Calcula o tempo de voo entre dois pontos usando distância de arco máximo.
+ """
+ def to_radians(degrees: float) -> float:
+ return degrees * (math.pi / 180)
+
+ lat1, lon1 = map(to_radians, origin_coords)
+ lat2, lon2 = map(to_radians, destination_coords)
+ EARTH_RADIUS_KM = 6371.0
+
+ dlon = lon2 - lon1
+ dlat = lat2 - lat1
+
+ a = (
+ math.sin(dlat / 2) ** 2
+ + math.cos(lat1) * math.cos(lat2) * math.sin(dlon / 2) ** 2
+ )
+ c = 2 * math.asin(math.sqrt(a))
+ distance = EARTH_RADIUS_KM * c
+
+ actual_distance = distance * 1.1
+ flight_time = (actual_distance / cruising_speed_kmh) + 1.0
+ return round(flight_time, 2)
+```
+
+### Configurando os agentes
+
+Vamos usar a infraestrutura da Hugging Face com o provedor Together AI.
+
+```python
+import os
+from PIL import Image
+from smolagents import (
+ CodeAgent,
+ GoogleSearchTool,
+ InferenceClientModel,
+ VisitWebpageTool,
+)
+
+model = InferenceClientModel(
+ model_id="Qwen/Qwen2.5-Coder-32B-Instruct",
+ provider="together"
+)
+```
+
+Primeiro, criamos um agente simples (baseline):
+
+```python
+task = """Find all Batman filming locations in the world, calculate the time to transfer via cargo plane to here (we're in Gotham, 40.7128° N, 74.0060° W), and return them to me as a pandas dataframe.
+Also give me some supercar factories with the same cargo plane transfer time."""
+
+agent = CodeAgent(
+ model=model,
+ tools=[GoogleSearchTool("serper"), VisitWebpageTool(), calculate_cargo_travel_time],
+ additional_authorized_imports=["pandas"],
+ max_steps=20,
+)
+
+result = agent.run(task)
+print(result)
+```
+
+Isso gera uma tabela com locais e tempos de voo. Para melhorar, podemos:
+
+- Aumentar o detalhamento do prompt;
+- Ativar planejamento (`planning_interval`).
+
+```python
+agent.planning_interval = 4
+
+detailed_report = agent.run(f"""
+You're an expert analyst...
+{task}
+""")
+print(detailed_report)
+```
+
+Melhoramos o resultado, mas o contexto enche rápido. **Juntar todas as informações em um único agente aumenta custo e tempo.**
+
+➡️ Vamos dividir a tarefa entre dois agentes.
+
+### ✌️ Dividindo a tarefa
+
+Separar agentes reduz tokens e deixa cada agente mais focado. Criaremos:
+- **Agente web**: busca informações;
+- **Agente gerente**: consolida, faz cálculos e plota.
+
+```python
+model = InferenceClientModel(
+ "Qwen/Qwen2.5-Coder-32B-Instruct",
+ provider="together",
+ max_tokens=8096
+)
+
+web_agent = CodeAgent(
+ model=model,
+ tools=[
+ GoogleSearchTool(provider="serper"),
+ VisitWebpageTool(),
+ calculate_cargo_travel_time,
+ ],
+ name="web_agent",
+ description="Browses the web to find information",
+ verbosity_level=0,
+ max_steps=10,
+)
+```
+
+Para o agente gerente, usaremos o modelo [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1), capaz de raciocínio mais longo, e autorizamos imports como `plotly`, `geopandas` e `shapely`.
+
+```python
+from smolagents.utils import encode_image_base64, make_image_url
+from smolagents import OpenAIServerModel
+
+def check_reasoning_and_plot(final_answer, agent_memory):
+ multimodal_model = OpenAIServerModel("gpt-4o", max_tokens=8096)
+ filepath = "saved_map.png"
+ assert os.path.exists(filepath), "Salve o gráfico como saved_map.png!"
+ image = Image.open(filepath)
+ prompt = (
+ f"Here is a user-given task and the agent steps: {agent_memory.get_succinct_steps()}..."
+ )
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": prompt},
+ {"type": "image_url", "image_url": {"url": make_image_url(encode_image_base64(image))}},
+ ],
+ }
+ ]
+ output = multimodal_model(messages).content
+ print("Feedback: ", output)
+ if "FAIL" in output:
+ raise Exception(output)
+ return True
+
+manager_agent = CodeAgent(
+ model=InferenceClientModel("deepseek-ai/DeepSeek-R1", provider="together", max_tokens=8096),
+ tools=[calculate_cargo_travel_time],
+ managed_agents=[web_agent],
+ additional_authorized_imports=[
+ "geopandas",
+ "plotly",
+ "shapely",
+ "json",
+ "pandas",
+ "numpy",
+ ],
+ planning_interval=5,
+ verbosity_level=2,
+ final_answer_checks=[check_reasoning_and_plot],
+ max_steps=15,
+)
+```
+
+Podemos visualizar o grafo resultante:
+
+```python
+manager_agent.visualize()
+```
+
+E executar a tarefa:
+
+```python
+manager_agent.run("""
+Find all Batman filming locations...
+""")
+```
+
+No meu teste, o gerente delegou buscas ao `web_agent` para localizar filmagens, depois fábricas de supercarros, agregou tudo e produziu o mapa.
+
+Por fim, podemos inspecionar o gráfico:
+
+```python
+manager_agent.python_executor.state["fig"]
+```
+
+
+
+## Recursos
+
+- [Multi-Agent Systems](https://huggingface.co/docs/smolagents/main/en/examples/multiagents)
+- [What is Agentic RAG?](https://weaviate.io/blog/what-is-agentic-rag)
+- [Multi-Agent RAG System 🤖🤝🤖 Recipe](https://huggingface.co/learn/cookbook/multiagent_rag_system)
diff --git a/units/pt_br/unit2/smolagents/quiz1.mdx b/units/pt_br/unit2/smolagents/quiz1.mdx
new file mode 100644
index 00000000..d65bf79c
--- /dev/null
+++ b/units/pt_br/unit2/smolagents/quiz1.mdx
@@ -0,0 +1,142 @@
+# Quiz rápido (sem nota) [[quiz1]]
+
+Vamos testar seu entendimento sobre `smolagents` com um quiz rápido! Lembre-se: se testar ajuda a consolidar o aprendizado e a identificar pontos para revisar.
+
+Este quiz é opcional e não atribui nota.
+
+### Q1: Qual é uma das principais vantagens de escolher `smolagents` em relação a outros frameworks?
+Selecione a alternativa que melhor resume essa força.
+
+Tool are only for text-generation tasks",
+ explain: "Both approaches can be used for any type of tool, including retrieval-based or text-generation tools.",
+ },
+ {
+ text: "The @tool decorator is recommended for simple function-based tools, while subclasses of Tool offer more flexibility for complex functionality or custom metadata",
+ explain: "This is correct. The decorator approach is simpler, but subclassing allows more customized behavior.",
+ correct: true
+ },
+ {
+ text: "@tool can only be used in multi-agent systems, while creating a Tool subclass is for single-agent scenarios",
+ explain: "All agents (single or multi) can use either approach to define tools; there is no such restriction.",
+ },
+ {
+ text: "Decorating a function with @tool replaces the need for a docstring, whereas subclasses must not include docstrings",
+ explain: "Both methods benefit from clear docstrings. The decorator doesn't replace them, and a subclass can still have docstrings.",
+ }
+]}
+/>
+
+---
+
+### Q2: Como um CodeAgent lida com tarefas multi-etapas usando o padrão ReAct (Reason + Act)?
+
+Selecione a alternativa que descreve corretamente esse funcionamento.
+
+ +
+## Como criar ferramentas
+
+No `smolagents`, há duas maneiras:
+
+1. **Usar o decorator `@tool`** (ideal para funções simples)
+2. **Criar uma subclasse de `Tool`** (para funcionalidades mais elaboradas)
+
+### O decorator `@tool`
+
+O `@tool` é a forma recomendada para ferramentas simples. Por baixo dos panos, o `smolagents` analisa nome, docstring e type hints para gerar a descrição. Portanto:
+
+- Escolha um **nome claro** para a função.
+- Defina **type hints** para entradas e saídas.
+- Escreva uma docstring com uma seção `Args:` descrevendo cada argumento.
+
+#### Ferramenta para encontrar o melhor serviço de buffet
+
+
+
+## Como criar ferramentas
+
+No `smolagents`, há duas maneiras:
+
+1. **Usar o decorator `@tool`** (ideal para funções simples)
+2. **Criar uma subclasse de `Tool`** (para funcionalidades mais elaboradas)
+
+### O decorator `@tool`
+
+O `@tool` é a forma recomendada para ferramentas simples. Por baixo dos panos, o `smolagents` analisa nome, docstring e type hints para gerar a descrição. Portanto:
+
+- Escolha um **nome claro** para a função.
+- Defina **type hints** para entradas e saídas.
+- Escreva uma docstring com uma seção `Args:` descrevendo cada argumento.
+
+#### Ferramenta para encontrar o melhor serviço de buffet
+
+ +
+> [!TIP]
+> Todo o código desta seção está neste notebook, que você pode executar no Google Colab.
+
+Suponha que Alfred já escolheu o menu, mas precisa contratar um buffet de alta qualidade. Vamos criar uma ferramenta que retorne o serviço mais bem avaliado em Gotham:
+
+```python
+from smolagents import CodeAgent, InferenceClientModel, tool
+
+# Função fictícia que retorna o buffet com melhor avaliação
+@tool
+def catering_service_tool(query: str) -> str:
+ """
+ Retorna o serviço de buffet mais bem avaliado em Gotham City.
+
+ Args:
+ query: Termo de busca para encontrar serviços de buffet.
+ """
+ services = {
+ "Gotham Catering Co.": 4.9,
+ "Wayne Manor Catering": 4.8,
+ "Gotham City Events": 4.7,
+ }
+ best_service = max(services, key=services.get)
+ return best_service
+
+
+agent = CodeAgent(tools=[catering_service_tool], model=InferenceClientModel())
+
+resultado = agent.run(
+ "Qual é o serviço de buffet mais bem avaliado em Gotham City?"
+)
+
+print(resultado) # Gotham Catering Co.
+```
+
+### Definindo uma ferramenta como classe Python
+
+Para ferramentas mais complexas, podemos criar uma subclasse de [`Tool`](https://huggingface.co/docs/smolagents/v1.8.1/en/reference/tools#smolagents.Tool). Nela definimos:
+
+- `name`: nome da ferramenta;
+- `description`: descrição usada no system prompt;
+- `inputs`: dicionário com `type` e `description` para cada argumento;
+- `output_type`: tipo da saída esperada;
+- `forward`: método com a lógica da ferramenta.
+
+#### Ideias para um baile de super-heróis
+
+Alfred quer surpreender os convidados com um tema marcante. Vamos criar uma ferramenta para gerar ideias conforme uma categoria:
+
+```python
+from smolagents import Tool, CodeAgent, InferenceClientModel
+
+class SuperheroPartyThemeTool(Tool):
+ name = "superhero_party_theme_generator"
+ description = """
+ Sugere ideias criativas de festas com tema de super-heróis
+ com base em uma categoria.
+ """
+
+ inputs = {
+ "category": {
+ "type": "string",
+ "description": "Tipo da festa (ex.: 'classic heroes', 'villain masquerade', 'futuristic Gotham').",
+ }
+ }
+
+ output_type = "string"
+
+ def forward(self, category: str):
+ themes = {
+ "classic heroes": "Justice League Gala...",
+ "villain masquerade": "Gotham Rogues' Ball...",
+ "futuristic gotham": "Neo-Gotham Night..."
+ }
+ return themes.get(category.lower(), "Tente 'classic heroes', 'villain masquerade' ou 'futuristic Gotham'.")
+
+party_theme_tool = SuperheroPartyThemeTool()
+agent = CodeAgent(tools=[party_theme_tool], model=InferenceClientModel())
+
+resultado = agent.run(
+ "Qual seria uma boa ideia para uma festa 'villain masquerade'?"
+)
+
+print(resultado) # "Gotham Rogues' Ball..."
+```
+
+Agora Alfred é o anfitrião perfeito! 🦸♂️
+
+## Toolbox padrão
+
+O `smolagents` inclui ferramentas prontas na [toolbox padrão](https://huggingface.co/docs/smolagents/guided_tour?build-a-tool=Decorate+a+function+with+%40tool#default-toolbox):
+
+- `PythonInterpreterTool`
+- `FinalAnswerTool`
+- `UserInputTool`
+- `DuckDuckGoSearchTool`
+- `GoogleSearchTool`
+- `VisitWebpageTool`
+
+Alfred poderia:
+- Usar `DuckDuckGoSearchTool` para ideias de temas.
+- `GoogleSearchTool` para encontrar buffets renomados.
+- `PythonInterpreterTool` para calcular a disposição dos convidados.
+- Finalizar tudo com `FinalAnswerTool`.
+
+## Compartilhando e importando ferramentas
+
+Um dos aspectos mais poderosos do `smolagents` é a possibilidade de compartilhar ferramentas no Hub e reutilizar as criadas pela comunidade. Isso inclui integração com **Spaces** e ferramentas do **LangChain**.
+
+### Publicando uma ferramenta no Hub
+
+Basta usar `push_to_hub()`:
+
+```python
+party_theme_tool.push_to_hub(
+ "{seu_usuario}/party_theme_tool",
+ token="
+
+> [!TIP]
+> Todo o código desta seção está neste notebook, que você pode executar no Google Colab.
+
+Suponha que Alfred já escolheu o menu, mas precisa contratar um buffet de alta qualidade. Vamos criar uma ferramenta que retorne o serviço mais bem avaliado em Gotham:
+
+```python
+from smolagents import CodeAgent, InferenceClientModel, tool
+
+# Função fictícia que retorna o buffet com melhor avaliação
+@tool
+def catering_service_tool(query: str) -> str:
+ """
+ Retorna o serviço de buffet mais bem avaliado em Gotham City.
+
+ Args:
+ query: Termo de busca para encontrar serviços de buffet.
+ """
+ services = {
+ "Gotham Catering Co.": 4.9,
+ "Wayne Manor Catering": 4.8,
+ "Gotham City Events": 4.7,
+ }
+ best_service = max(services, key=services.get)
+ return best_service
+
+
+agent = CodeAgent(tools=[catering_service_tool], model=InferenceClientModel())
+
+resultado = agent.run(
+ "Qual é o serviço de buffet mais bem avaliado em Gotham City?"
+)
+
+print(resultado) # Gotham Catering Co.
+```
+
+### Definindo uma ferramenta como classe Python
+
+Para ferramentas mais complexas, podemos criar uma subclasse de [`Tool`](https://huggingface.co/docs/smolagents/v1.8.1/en/reference/tools#smolagents.Tool). Nela definimos:
+
+- `name`: nome da ferramenta;
+- `description`: descrição usada no system prompt;
+- `inputs`: dicionário com `type` e `description` para cada argumento;
+- `output_type`: tipo da saída esperada;
+- `forward`: método com a lógica da ferramenta.
+
+#### Ideias para um baile de super-heróis
+
+Alfred quer surpreender os convidados com um tema marcante. Vamos criar uma ferramenta para gerar ideias conforme uma categoria:
+
+```python
+from smolagents import Tool, CodeAgent, InferenceClientModel
+
+class SuperheroPartyThemeTool(Tool):
+ name = "superhero_party_theme_generator"
+ description = """
+ Sugere ideias criativas de festas com tema de super-heróis
+ com base em uma categoria.
+ """
+
+ inputs = {
+ "category": {
+ "type": "string",
+ "description": "Tipo da festa (ex.: 'classic heroes', 'villain masquerade', 'futuristic Gotham').",
+ }
+ }
+
+ output_type = "string"
+
+ def forward(self, category: str):
+ themes = {
+ "classic heroes": "Justice League Gala...",
+ "villain masquerade": "Gotham Rogues' Ball...",
+ "futuristic gotham": "Neo-Gotham Night..."
+ }
+ return themes.get(category.lower(), "Tente 'classic heroes', 'villain masquerade' ou 'futuristic Gotham'.")
+
+party_theme_tool = SuperheroPartyThemeTool()
+agent = CodeAgent(tools=[party_theme_tool], model=InferenceClientModel())
+
+resultado = agent.run(
+ "Qual seria uma boa ideia para uma festa 'villain masquerade'?"
+)
+
+print(resultado) # "Gotham Rogues' Ball..."
+```
+
+Agora Alfred é o anfitrião perfeito! 🦸♂️
+
+## Toolbox padrão
+
+O `smolagents` inclui ferramentas prontas na [toolbox padrão](https://huggingface.co/docs/smolagents/guided_tour?build-a-tool=Decorate+a+function+with+%40tool#default-toolbox):
+
+- `PythonInterpreterTool`
+- `FinalAnswerTool`
+- `UserInputTool`
+- `DuckDuckGoSearchTool`
+- `GoogleSearchTool`
+- `VisitWebpageTool`
+
+Alfred poderia:
+- Usar `DuckDuckGoSearchTool` para ideias de temas.
+- `GoogleSearchTool` para encontrar buffets renomados.
+- `PythonInterpreterTool` para calcular a disposição dos convidados.
+- Finalizar tudo com `FinalAnswerTool`.
+
+## Compartilhando e importando ferramentas
+
+Um dos aspectos mais poderosos do `smolagents` é a possibilidade de compartilhar ferramentas no Hub e reutilizar as criadas pela comunidade. Isso inclui integração com **Spaces** e ferramentas do **LangChain**.
+
+### Publicando uma ferramenta no Hub
+
+Basta usar `push_to_hub()`:
+
+```python
+party_theme_tool.push_to_hub(
+ "{seu_usuario}/party_theme_tool",
+ token="@tool envolvendo uma função Python ou por meio da classe Tool.
+
+### Integração de modelos no `smolagents`
+
+O `smolagents` aceita qualquer modelo chamável que atenda a [alguns critérios](https://huggingface.co/docs/smolagents/main/en/reference/models). O framework oferece classes prontas para facilitar a conexão:
+
+- **[TransformersModel](https://huggingface.co/docs/smolagents/main/en/reference/models#smolagents.TransformersModel):** integra de forma simples um pipeline local do `transformers`.
+- **[InferenceClientModel](https://huggingface.co/docs/smolagents/main/en/reference/models#smolagents.InferenceClientModel):** suporta chamadas de [serverless inference](https://huggingface.co/docs/huggingface_hub/main/en/guides/inference) via [infraestrutura da Hugging Face](https://huggingface.co/docs/api-inference/index) ou através de diversos [provedores terceiros](https://huggingface.co/docs/huggingface_hub/main/en/guides/inference#supported-providers-and-tasks).
+- **[LiteLLMModel](https://huggingface.co/docs/smolagents/main/en/reference/models#smolagents.LiteLLMModel):** utiliza o [LiteLLM](https://www.litellm.ai/) para interações leves com modelos.
+- **[OpenAIServerModel](https://huggingface.co/docs/smolagents/main/en/reference/models#smolagents.OpenAIServerModel):** conecta-se a qualquer serviço compatível com a API da OpenAI.
+- **[AzureOpenAIServerModel](https://huggingface.co/docs/smolagents/main/en/reference/models#smolagents.AzureOpenAIServerModel):** integra-se a implantações do Azure OpenAI.
+
+Essa flexibilidade permite escolher o provedor mais adequado e facilita experimentações.
+
+Agora que entendemos por que e quando usar o smolagents, vamos nos aprofundar nessa biblioteca!
+
+## Recursos
+
+- [Blog do smolagents](https://huggingface.co/blog/smolagents) — introdução e exemplos de interação via código
diff --git a/units/pt_br/unit3/README.md b/units/pt_br/unit3/README.md
new file mode 100644
index 00000000..e69de29b
diff --git a/units/pt_br/unit3/agentic-rag/agent.mdx b/units/pt_br/unit3/agentic-rag/agent.mdx
new file mode 100644
index 00000000..ec34f18c
--- /dev/null
+++ b/units/pt_br/unit3/agentic-rag/agent.mdx
@@ -0,0 +1,220 @@
+# Construindo o agente da gala
+
+Chegou a hora de juntar todos os componentes que preparamos para Alfred e criar um agente completo, capaz de conduzir nossa festa extravagante.
+
+Nesta seção, combinaremos as ferramentas de consulta a convidados, busca na web, previsão do tempo e estatísticas do Hugging Face Hub em um único agente poderoso.
+
+## Montando Alfred: o agente completo
+
+Em vez de reimplementar tudo, vamos importar as ferramentas que salvamos em `tools.py` e `retriever.py`.
+
+> [!TIP]
+> Se você ainda não implementou as ferramentas, volte às seções de ferramentas e retriever, implemente-as e adicione aos arquivos `tools.py` e `retriever.py`.
+
+### smolagents
+
+```python
+# Importações principais
+import random
+from smolagents import CodeAgent, InferenceClientModel
+
+# Importação das ferramentas personalizadas
+from tools import DuckDuckGoSearchTool, WeatherInfoTool, HubStatsTool
+from retriever import load_guest_dataset
+
+# Inicializa modelo e ferramentas
+model = InferenceClientModel()
+search_tool = DuckDuckGoSearchTool()
+weather_info_tool = WeatherInfoTool()
+hub_stats_tool = HubStatsTool()
+guest_info_tool = load_guest_dataset()
+
+# Cria Alfred com todas as ferramentas
+alfred = CodeAgent(
+ tools=[guest_info_tool, weather_info_tool, hub_stats_tool, search_tool],
+ model=model,
+ add_base_tools=True,
+ planning_interval=3
+)
+```
+
+### LlamaIndex
+
+```python
+from llama_index.core.agent.workflow import AgentWorkflow
+from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
+
+from tools import search_tool, weather_info_tool, hub_stats_tool
+from retriever import guest_info_tool
+
+llm = HuggingFaceInferenceAPI(model_name="Qwen/Qwen2.5-Coder-32B-Instruct")
+
+alfred = AgentWorkflow.from_tools_or_functions(
+ [guest_info_tool, search_tool, weather_info_tool, hub_stats_tool],
+ llm=llm,
+)
+```
+
+### LangGraph
+
+```python
+from typing import TypedDict, Annotated
+from langgraph.graph.message import add_messages
+from langchain_core.messages import AnyMessage, HumanMessage
+from langgraph.prebuilt import ToolNode, tools_condition
+from langgraph.graph import START, StateGraph
+from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
+
+from tools import DuckDuckGoSearchRun, weather_info_tool, hub_stats_tool
+from retriever import guest_info_tool
+
+search_tool = DuckDuckGoSearchRun()
+
+llm = HuggingFaceEndpoint(
+ repo_id="Qwen/Qwen2.5-Coder-32B-Instruct",
+ huggingfacehub_api_token=HUGGINGFACEHUB_API_TOKEN,
+)
+
+chat = ChatHuggingFace(llm=llm, verbose=True)
+tools = [guest_info_tool, search_tool, weather_info_tool, hub_stats_tool]
+chat_with_tools = chat.bind_tools(tools)
+
+class AgentState(TypedDict):
+ messages: Annotated[list[AnyMessage], add_messages]
+
+def assistant(state: AgentState):
+ return {"messages": [chat_with_tools.invoke(state["messages"])]}
+
+builder = StateGraph(AgentState)
+builder.add_node("assistant", assistant)
+builder.add_node("tools", ToolNode(tools))
+builder.add_edge(START, "assistant")
+builder.add_conditional_edges("assistant", tools_condition)
+builder.add_edge("tools", "assistant")
+alfred = builder.compile()
+```
+
+Seu agente está pronto!
+
+## Exemplos ponta a ponta
+
+### 1. Consulta sobre convidados
+
+```python
+query = "Tell me about 'Lady Ada Lovelace'"
+response = alfred.run(query)
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+Saída esperada:
+
+```
+🎩 Resposta do Alfred:
+Lady Ada Lovelace é uma matemágica e amiga. Ela é conhecida como a primeira programadora por seu trabalho no Analytical Engine de Charles Babbage...
+```
+
+### 2. Checando o tempo para fogos
+
+```python
+query = "What's the weather like in Paris tonight? Will it be suitable for our fireworks display?"
+response = alfred.run(query)
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+Saída esperada (varia conforme API):
+
+```
+🎩 Resposta do Alfred:
+O tempo em Paris hoje à noite está chuvoso com 15 °C; talvez não seja ideal para os fogos.
+```
+
+### 3. Impressionando pesquisadores de IA
+
+```python
+query = "One of our guests is from Qwen. What can you tell me about their most popular model?"
+response = alfred.run(query)
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+Saída esperada:
+
+```
+🎩 Resposta do Alfred:
+O modelo mais baixado de Qwen é Qwen/Qwen2.5-VL-7B-Instruct, com 3 313 345 downloads.
+```
+
+### 4. Combinando múltiplas ferramentas
+
+```python
+query = "I need to speak with Dr. Nikola Tesla about recent advancements in wireless energy. Can you help me prepare?"
+response = alfred.run(query)
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+Saída esperada:
+
+```
+🎩 Resposta do Alfred:
+Informações do convidado:
+- Nome: Dr. Nikola Tesla
+- Relação: amigo antigo
+- Descrição: ...
+
+Avanços recentes:
+1. Progresso em transmissão de energia sem fio via micro-ondas focadas
+2. Desenvolvimento de acoplamento indutivo em ressonância...
+```
+
+## Recurso avançado: memória de conversação
+
+### smolagents
+
+```python
+alfred_with_memory = CodeAgent(
+ tools=[guest_info_tool, weather_info_tool, hub_stats_tool, search_tool],
+ model=model,
+ add_base_tools=True,
+ planning_interval=3
+)
+
+resp1 = alfred_with_memory.run("Tell me about Lady Ada Lovelace.")
+resp2 = alfred_with_memory.run("What projects is she currently working on?", reset=False)
+```
+
+### LlamaIndex
+
+```python
+from llama_index.core.workflow import Context
+
+ctx = Context(alfred)
+resp1 = await alfred.run("Tell me about Lady Ada Lovelace.", ctx=ctx)
+resp2 = await alfred.run("What projects is she currently working on?", ctx=ctx)
+```
+
+### LangGraph
+
+```python
+resp = alfred.invoke({"messages": [HumanMessage(content="Tell me about Lady Ada Lovelace.")]} )
+resp = alfred.invoke({"messages": resp["messages"] + [HumanMessage(content="What projects is she currently working on?")]} )
+```
+
+Repare que nenhum dos frameworks liga a memória automaticamente:
+- **smolagents:** é preciso `reset=False`;
+- **LlamaIndex:** requer passar um `Context`;
+- **LangGraph:** oferece opções como recuperar mensagens anteriores ou usar um [MemorySaver](https://langchain-ai.github.io/langgraph/tutorials/introduction/#part-3-adding-memory-to-the-chatbot).
+
+## Conclusão
+
+Parabéns! Você construiu Alfred, um agente sofisticado com múltiplas ferramentas capaz de:
+
+1. Obter informações detalhadas dos convidados
+2. Checar condições meteorológicas
+3. Fornecer insights sobre modelos de IA
+4. Pesquisar na web em tempo real
+5. Manter contexto conversacional
+
+Com essas habilidades, Alfred está pronto para tornar a sua gala um sucesso absoluto!***
diff --git a/units/pt_br/unit3/agentic-rag/agentic-rag.mdx b/units/pt_br/unit3/agentic-rag/agentic-rag.mdx
new file mode 100644
index 00000000..83ab61d9
--- /dev/null
+++ b/units/pt_br/unit3/agentic-rag/agentic-rag.mdx
@@ -0,0 +1,28 @@
+# Agentic Retrieval Augmented Generation (RAG)
+
+Nesta unidade, veremos como usar Agentic RAG para ajudar Alfred a preparar a grande gala.
+
+> [!TIP]
+> We know we've already discussed Retrieval Augmented Generation (RAG) and agentic RAG in the previous unit, so feel free to skip ahead if you're already familiar with the concepts.
+
+LLMs são treinados em enormes volumes de dados para adquirir conhecimento geral.
+Porém, o “saber do mundo” que eles carregam pode não estar atualizado ou ser específico o bastante.
+**RAG resolve esse problema buscando informações relevantes nos seus próprios dados e entregando-as ao LLM.**
+
+
+
+Pense em como Alfred opera:
+
+1. We've asked Alfred to help plan a gala
+2. Alfred needs to find the latest news and weather information
+3. Alfred needs to structure and search the guest information
+
+Just as Alfred needs to search through your household information to be helpful, any agent needs a way to find and understand relevant data.
+**Agentic RAG is a powerful way to use agents to answer questions about your data.** We can pass various tools to Alfred to help him answer questions.
+However, instead of answering the question on top of documents automatically, Alfred can decide to use any other tool or flow to answer the question.
+
+
+
+Vamos começar **construindo nosso workflow Agentic RAG!**
+
+Primeiro criaremos uma ferramenta RAG para obter os dados atualizados dos convidados. Depois desenvolveremos ferramentas para busca na web, previsão do tempo e estatísticas de downloads de modelos no Hugging Face Hub. Por fim, integraremos tudo para dar vida ao agente!
diff --git a/units/pt_br/unit3/agentic-rag/conclusion.mdx b/units/pt_br/unit3/agentic-rag/conclusion.mdx
new file mode 100644
index 00000000..d7b2b260
--- /dev/null
+++ b/units/pt_br/unit3/agentic-rag/conclusion.mdx
@@ -0,0 +1,18 @@
+# Conclusão
+
+Nesta unidade, aprendemos a montar um sistema Agentic RAG para ajudar Alfred a organizar e administrar uma gala luxuosa.
+
+A combinação de RAG com capacidades agênticas mostra o quanto um assistente pode ser poderoso quando conta com:
+- Acesso a conhecimento estruturado (dados dos convidados);
+- Busca em tempo real (pesquisa na web);
+- Ferramentas específicas (clima, estatísticas do Hub);
+- Memória de interações anteriores.
+
+Com isso, Alfred está pronto para ser o anfitrião perfeito: responde dúvidas, traz informações atualizadas e garante o melhor momento para os fogos de artifício!
+
+> [!TIP]
+> Agora que você criou um agente completo, explore:
+> - Ferramentas especializadas para outros casos de uso;
+> - RAG com embeddings mais sofisticados;
+> - Sistemas multiagentes colaborativos;
+> - Deploy do agente como serviço para outros usuários.
diff --git a/units/pt_br/unit3/agentic-rag/introduction.mdx b/units/pt_br/unit3/agentic-rag/introduction.mdx
new file mode 100644
index 00000000..5a800b8b
--- /dev/null
+++ b/units/pt_br/unit3/agentic-rag/introduction.mdx
@@ -0,0 +1,40 @@
+# Introdução ao caso de uso de Agentic RAG
+
+
+
+Nesta unidade, vamos ajudar Alfred — nosso agente anfitrião do baile — usando Agentic RAG para criar uma ferramenta capaz de responder perguntas sobre os convidados.
+
+> [!TIP]
+> This is a 'real-world' use case for Agentic RAG, that you could use in your own projects or workplaces. If you want to get more out of this project, why not try it out on your own use case and share in Discord?
+
+
+Você pode escolher qualquer framework discutido no curso para este caso. Fornecemos exemplos de código em abas separadas.
+
+## Uma gala inesquecível
+
+Now, it's time to get our hands dirty with an actual use case. Let's set the stage!
+
+**Você decidiu organizar a festa mais extravagante e opulenta do século.** Isso inclui banquetes suntuosos, dançarinos encantadores, DJs renomados, drinks requintados, fogos de artifício de tirar o fôlego e muito mais.
+
+Alfred, o agente de confiança, cuidará de tudo sozinho — para isso, precisa acessar informações sobre menu, convidados, agenda, previsão do tempo e outros detalhes.
+
+Além disso, a festa deve ser um sucesso. Então **ele precisa responder perguntas em tempo real durante o evento**, lidando com situações inesperadas.
+
+Ele não consegue fazer tudo sem respaldo; vamos garantir que Alfred tenha as informações e ferramentas necessárias.
+
+Comecemos definindo os requisitos rígidos da gala.
+
+## The Gala Requirements
+
+Uma pessoa culta na **Renascença** reunia três atributos principais: domínio em **esportes, cultura e ciência**. Precisamos impressionar nossos convidados e proporcionar uma festa inesquecível.
+
+Entretanto, para evitar conflitos, **certos temas — como política e religião — devem ser evitados**. A festa precisa ser divertida, sem disputas de crenças ou ideias.
+
+Pela etiqueta, **um bom anfitrião conhece os convidados**, seus interesses e realizações, e é capaz de compartilhar histórias e comentários entre eles.
+
+Por fim, precisamos **acompanhar a previsão do tempo** para ajustar o momento ideal dos fogos de artifício e encerrar a festa com estilo 🎆.
+
+Como você percebe, Alfred precisa de muitas informações para conduzir a gala.
+Felizmente, podemos treiná-lo com **Retrieval Augmented Generation (RAG)**.
+
+Vamos começar criando as ferramentas necessárias para Alfred brilhar como anfitrião!
diff --git a/units/pt_br/unit3/agentic-rag/invitees.mdx b/units/pt_br/unit3/agentic-rag/invitees.mdx
new file mode 100644
index 00000000..dcceef06
--- /dev/null
+++ b/units/pt_br/unit3/agentic-rag/invitees.mdx
@@ -0,0 +1,140 @@
+# Criando uma ferramenta RAG para o livro de convidados
+
+Alfred, nosso agente de confiança, está preparando a gala mais sofisticada do século. Para garantir seu sucesso, ele precisa acessar rapidamente informações atualizadas sobre cada convidado. Vamos ajudá-lo montando uma ferramenta de Retrieval-Augmented Generation (RAG) com base em nosso dataset personalizado.
+
+## Por que usar RAG em uma festa?
+
+Imagine Alfred circulando entre os convidados, lembrando detalhes específicos instantaneamente. Um LLM puro pode não conseguir, porque:
+
+1. A lista de convidados é específica e não faz parte do treinamento do modelo.
+2. Informações podem mudar com frequência.
+3. Alfred precisa de detalhes precisos, como e-mails.
+
+Ao combinar um sistema de busca com um LLM, RAG permite respostas atualizadas sob demanda.
+
+> [!TIP]
+> Você pode usar qualquer framework estudado no curso. Escolha a aba de código correspondente.
+
+## Estrutura do projeto
+
+Usaremos uma Space do Hugging Face organizada em módulos:
+
+- `tools.py` – ferramentas auxiliares.
+- `retriever.py` – funções de busca sobre a base de conhecimento.
+- `app.py` – integração final (construída na última parte da unidade).
+
+Há uma Space pronta em [agents-course/Unit_3_Agentic_RAG](https://huggingface.co/spaces/agents-course/Unit_3_Agentic_RAG). Sinta-se livre para clonar.
+
+Você também pode testar o agente aqui:
+
+
+
+## Dataset
+
+O conjunto [`agents-course/unit3-invitees`](https://huggingface.co/datasets/agents-course/unit3-invitees/) contém:
+
+- `name`: nome completo.
+- `relation`: relação com o anfitrião.
+- `description`: biografia/detalhes interessantes.
+- `email`: contato para convites ou follow-up.
+
+
+
+> [!TIP]
+> Em um cenário real você pode incluir preferências alimentares, tópicos sensíveis, interesses etc.
+
+## Construindo a ferramenta
+
+Vamos criar uma ferramenta que Alfred possa usar para consultar os convidados durante o evento.
+
+### Passo 1 – carregar e preparar os dados
+
+```python
+import datasets
+from langchain_core.documents import Document
+
+guest_dataset = datasets.load_dataset("agents-course/unit3-invitees", split="train")
+
+docs = [
+ Document(
+ page_content="\n".join([
+ f"Name: {guest['name']}",
+ f"Relation: {guest['relation']}",
+ f"Description: {guest['description']}",
+ f"Email: {guest['email']}"
+ ]),
+ metadata={"name": guest["name"]}
+ )
+ for guest in guest_dataset
+]
+```
+
+### Passo 2 – criar o retriever
+
+```python
+from smolagents import Tool
+from langchain_community.retrievers import BM25Retriever
+
+class GuestInfoRetrieverTool(Tool):
+ name = "guest_info_retriever"
+ description = "Recupera informações detalhadas sobre os convidados da gala."
+ inputs = {"query": {"type": "string", "description": "Nome ou relação do convidado."}}
+ output_type = "string"
+
+ def __init__(self, docs):
+ self.retriever = BM25Retriever.from_documents(docs)
+
+ def forward(self, query: str):
+ results = self.retriever.get_relevant_documents(query)
+ if results:
+ return "\n\n".join(doc.page_content for doc in results[:3])
+ return "Nenhuma informação correspondente encontrada."
+
+guest_info_tool = GuestInfoRetrieverTool(docs)
+```
+
+### Passo 3 – integrar com Alfred
+
+```python
+from smolagents import CodeAgent, InferenceClientModel
+
+model = InferenceClientModel()
+alfred = CodeAgent(tools=[guest_info_tool], model=model)
+
+response = alfred.run("Tell me about 'Lady Ada Lovelace'.")
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+Saída esperada:
+
+```
+🎩 Resposta do Alfred:
+Lady Ada Lovelace é uma matemática renomada...
+```
+
+## Interação típica
+
+**Você:** “Alfred, quem está conversando com o embaixador?”
+**Alfred:** “Dr. Nikola Tesla, antigo amigo da universidade. Recentemente patenteou um sistema de transmissão de energia sem fio. Ele adora pombos — ótimo assunto para quebrar o gelo.”
+
+```json
+{
+ "name": "Dr. Nikola Tesla",
+ "relation": "old friend from university days",
+ "description": "...",
+ "email": "nikola.tesla@gmail.com"
+}
+```
+
+## Próximos passos
+
+Agora que Alfred consegue recuperar dados, você pode:
+
+1. Usar retrievers baseados em embeddings (ex.: [sentence-transformers](https://www.sbert.net/)).
+2. Implementar memória de conversação.
+3. Combinar com busca na web para informações recentes.
+4. Integrar múltiplos índices.
+
+> [!TIP]
+> Experimente estender a ferramenta para sugerir tópicos de conversa. Quando terminar, implemente-a em `retriever.py`.
diff --git a/units/pt_br/unit3/agentic-rag/tools.mdx b/units/pt_br/unit3/agentic-rag/tools.mdx
new file mode 100644
index 00000000..7d479f64
--- /dev/null
+++ b/units/pt_br/unit3/agentic-rag/tools.mdx
@@ -0,0 +1,233 @@
+# Construindo e integrando ferramentas para o agente
+
+Nesta seção daremos a Alfred acesso à web, previsão do tempo e estatísticas de downloads no Hugging Face Hub — assim ele poderá conduzir conversas atualizadas sobre qualquer assunto.
+
+## Acesso à web
+
+Para Alfred se portar como um anfitrião renascentista, é essencial conhecer as notícias do mundo. Comecemos criando uma ferramenta de busca.
+
+### smolagents
+```python
+from smolagents import DuckDuckGoSearchTool
+
+search_tool = DuckDuckGoSearchTool()
+print(search_tool("Who's the current President of France?"))
+```
+
+### LlamaIndex
+```python
+from llama_index.tools.duckduckgo import DuckDuckGoSearchToolSpec
+from llama_index.core.tools import FunctionTool
+
+tool_spec = DuckDuckGoSearchToolSpec()
+search_tool = FunctionTool.from_defaults(tool_spec.duckduckgo_full_search)
+print(search_tool("Who's the current President of France?").raw_output[-1]['body'])
+```
+
+### LangGraph
+```python
+from langchain_community.tools import DuckDuckGoSearchRun
+
+search_tool = DuckDuckGoSearchRun()
+print(search_tool.invoke("Who's the current President of France?"))
+```
+
+## Ferramenta de clima (para agendar os fogos)
+
+Queremos fogos em noite limpa. Usaremos um exemplo simples com dados aleatórios (sinta-se livre para integrar APIs reais, como mostrado na [Unidade 1](../../unit1/tutorial)).
+
+### smolagents
+```python
+from smolagents import Tool
+import random
+
+class WeatherInfoTool(Tool):
+ name = "weather_info"
+ description = "Obtém clima fictício para uma localidade."
+ inputs = {"location": {"type": "string", "description": "Localização desejada."}}
+ output_type = "string"
+
+ def forward(self, location: str):
+ dados = random.choice([
+ {"condition": "Rainy", "temp_c": 15},
+ {"condition": "Clear", "temp_c": 25},
+ {"condition": "Windy", "temp_c": 20},
+ ])
+ return f"Weather in {location}: {dados['condition']}, {dados['temp_c']}°C"
+
+weather_info_tool = WeatherInfoTool()
+```
+
+### LlamaIndex
+```python
+import random
+from llama_index.core.tools import FunctionTool
+
+def get_weather_info(location: str) -> str:
+ dados = random.choice([
+ {"condition": "Rainy", "temp_c": 15},
+ {"condition": "Clear", "temp_c": 25},
+ {"condition": "Windy", "temp_c": 20},
+ ])
+ return f"Weather in {location}: {dados['condition']}, {dados['temp_c']}°C"
+
+weather_info_tool = FunctionTool.from_defaults(get_weather_info)
+```
+
+### LangGraph
+```python
+from langchain.tools import Tool
+import random
+
+def get_weather_info(location: str) -> str:
+ dados = random.choice([
+ {"condition": "Rainy", "temp_c": 15},
+ {"condition": "Clear", "temp_c": 25},
+ {"condition": "Windy", "temp_c": 20},
+ ])
+ return f"Weather in {location}: {dados['condition']}, {dados['temp_c']}°C"
+
+weather_info_tool = Tool(
+ name="get_weather_info",
+ func=get_weather_info,
+ description="Obtém clima fictício para uma localidade."
+)
+```
+
+## Estatísticas do Hub (encantando os builders)
+
+### smolagents
+```python
+from smolagents import Tool
+from huggingface_hub import list_models
+
+class HubStatsTool(Tool):
+ name = "hub_stats"
+ description = "Retorna o modelo mais baixado de um autor no Hugging Face Hub."
+ inputs = {"author": {"type": "string", "description": "Usuário ou organização."}}
+ output_type = "string"
+
+ def forward(self, author: str):
+ try:
+ modelos = list(list_models(author=author, sort="downloads", direction=-1, limit=1))
+ if modelos:
+ m = modelos[0]
+ return f"The most downloaded model by {author} is {m.id} with {m.downloads:,} downloads."
+ return f"No models found for author {author}."
+ except Exception as e:
+ return f"Error fetching models for {author}: {str(e)}"
+
+hub_stats_tool = HubStatsTool()
+```
+
+### LlamaIndex
+```python
+from huggingface_hub import list_models
+from llama_index.core.tools import FunctionTool
+
+def get_hub_stats(author: str) -> str:
+ modelos = list(list_models(author=author, sort="downloads", direction=-1, limit=1))
+ if modelos:
+ m = modelos[0]
+ return f"The most downloaded model by {author} is {m.id} with {m.downloads:,} downloads."
+ return f"No models found for author {author}."
+
+hub_stats_tool = FunctionTool.from_defaults(get_hub_stats)
+```
+
+### LangGraph
+```python
+from huggingface_hub import list_models
+from langchain.tools import Tool
+
+def get_hub_stats(author: str) -> str:
+ modelos = list(list_models(author=author, sort="downloads", direction=-1, limit=1))
+ if modelos:
+ m = modelos[0]
+ return f"The most downloaded model by {author} is {m.id} with {m.downloads:,} downloads."
+ return f"No models found for author {author}."
+
+hub_stats_tool = Tool(
+ name="get_hub_stats",
+ func=get_hub_stats,
+ description="Busca o modelo mais baixado de um autor no Hugging Face Hub."
+)
+```
+
+## Integrando tudo
+
+### smolagents
+```python
+from smolagents import CodeAgent, InferenceClientModel
+
+model = InferenceClientModel()
+alfred = CodeAgent(
+ tools=[search_tool, weather_info_tool, hub_stats_tool],
+ model=model
+)
+
+response = alfred.run("What is Facebook and what's their most popular model?")
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+### LlamaIndex
+```python
+from llama_index.core.agent.workflow import AgentWorkflow
+from llama_index.llms.huggingface_api import HuggingFaceInferenceAPI
+
+llm = HuggingFaceInferenceAPI(model_name="Qwen/Qwen2.5-Coder-32B-Instruct")
+alfred = AgentWorkflow.from_tools_or_functions(
+ [search_tool, weather_info_tool, hub_stats_tool],
+ llm=llm
+)
+
+response = await alfred.run("What is Facebook and what's their most popular model?")
+print("🎩 Resposta do Alfred:")
+print(response)
+```
+
+### LangGraph
+```python
+from typing import TypedDict, Annotated
+from langgraph.graph.message import add_messages
+from langchain_core.messages import AnyMessage, HumanMessage
+from langgraph.prebuilt import ToolNode, tools_condition
+from langgraph.graph import START, StateGraph
+from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
+
+llm = HuggingFaceEndpoint(
+ repo_id="Qwen/Qwen2.5-Coder-32B-Instruct",
+ huggingfacehub_api_token=HUGGINGFACEHUB_API_TOKEN,
+)
+chat = ChatHuggingFace(llm=llm, verbose=True)
+tools = [search_tool, weather_info_tool, hub_stats_tool]
+chat_with_tools = chat.bind_tools(tools)
+
+class AgentState(TypedDict):
+ messages: Annotated[list[AnyMessage], add_messages]
+
+def assistant(state: AgentState):
+ return {"messages": [chat_with_tools.invoke(state["messages"])]}
+
+builder = StateGraph(AgentState)
+builder.add_node("assistant", assistant)
+builder.add_node("tools", ToolNode(tools))
+builder.add_edge(START, "assistant")
+builder.add_conditional_edges("assistant", tools_condition)
+builder.add_edge("tools", "assistant")
+alfred = builder.compile()
+
+messages = [HumanMessage(content="Who is Facebook and what's their most popular model?")]
+response = alfred.invoke({"messages": messages})
+print("🎩 Resposta do Alfred:")
+print(response['messages'][-1].content)
+```
+
+## Conclusão
+
+Com estas ferramentas, Alfred realiza buscas, verifica clima, comenta sobre modelos populares e mantém a conversa fluindo.
+
+> [!TIP]
+> Tente criar uma ferramenta que busque notícias recentes sobre um tópico.
+> Em seguida, registre suas ferramentas personalizadas em `tools.py`.
diff --git a/units/pt_br/unit4/additional-readings.mdx b/units/pt_br/unit4/additional-readings.mdx
new file mode 100644
index 00000000..390f51b1
--- /dev/null
+++ b/units/pt_br/unit4/additional-readings.mdx
@@ -0,0 +1,30 @@
+# E agora? O que estudar a seguir?
+
+A IA agêntica evolui rapidamente e conhecer os protocolos fundamentais é essencial para construir sistemas inteligentes e autônomos.
+
+Dois padrões importantes para acompanhar:
+
+- The **Model Context Protocol (MCP)**
+- The **Agent-to-Agent Protocol (A2A)**
+
+## 🔌 Model Context Protocol (MCP)
+
+O **Model Context Protocol (MCP)**, criado pela Anthropic, é um padrão aberto que permite aos modelos de IA **conectar-se com segurança a ferramentas, dados e aplicativos externos**, tornando os agentes mais capazes e autônomos.
+
+Pense nele como um **adaptador universal** (tipo USB-C) que permite plugar o modelo em diferentes ambientes **sem integrações sob medida**.
+
+O MCP está ganhando adoção por empresas como OpenAI e Google.
+
+📚 Learn more:
+- [Anthropic's official announcement and documentation](https://www.anthropic.com/news/model-context-protocol)
+- [MCP on Wikipedia](https://en.wikipedia.org/wiki/Model_Context_Protocol)
+- [Blog on MCP](https://huggingface.co/blog/Kseniase/mcp)
+
+## 🤝 Agent-to-Agent (A2A) Protocol
+
+O **Agent-to-Agent (A2A)**, criado pela Google, complementa o MCP.
+
+Enquanto o MCP conecta agentes a ferramentas, o **A2A conecta agentes entre si**, abrindo caminho para sistemas cooperativos capazes de enfrentar problemas complexos.
+
+📚 Dive deeper into A2A:
+- [Google’s A2A announcement](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
diff --git a/units/pt_br/unit4/conclusion.mdx b/units/pt_br/unit4/conclusion.mdx
new file mode 100644
index 00000000..d4224f7f
--- /dev/null
+++ b/units/pt_br/unit4/conclusion.mdx
@@ -0,0 +1,11 @@
+# Conclusão
+
+**Parabéns por concluir o Agents Course!**
+
+Com dedicação e perseverança, você construiu uma base sólida no universo de agentes de IA.
+
+Mas terminar o curso **não é o fim da jornada**. É só o começo: explore a seção de leituras adicionais, onde indicamos recursos para continuar aprendendo — incluindo tópicos avançados como **MCP** e muito mais.
+
+**Obrigado** por fazer parte deste curso. **Esperamos que tenha gostado tanto quanto nós curtimos produzi-lo.**
+
+E lembre-se: **Continue aprendendo e sendo incrível 🤗**
diff --git a/units/pt_br/unit4/get-your-certificate.mdx b/units/pt_br/unit4/get-your-certificate.mdx
new file mode 100644
index 00000000..ac118b94
--- /dev/null
+++ b/units/pt_br/unit4/get-your-certificate.mdx
@@ -0,0 +1,21 @@
+# Garanta seu certificado 🎓
+
+Se você conseguiu **acima de 30%**, parabéns! 👏 Já pode solicitar o certificado oficial.
+
+Siga os passos:
+
+1. Acesse a [página de certificados](https://huggingface.co/spaces/agents-course/Unit4-Final-Certificate).
+2. **Faça login** com sua conta Hugging Face (use o botão na página).
+3. **Informe seu nome completo** — ele aparecerá no certificado.
+4. Clique em **“Get My Certificate”** para verificar a pontuação e baixar o documento.
+
+ +
+Depois de baixar:
+- Adicione ao seu **LinkedIn** 🧑💼
+- Compartilhe no **X**, **Bluesky** etc. 🎉
+
+**Não esqueça de marcar [@huggingface](https://huggingface.co/huggingface). Ficaremos orgulhosos e felizes em comemorar com você! 🤗**
+
+> [!TIP]
+> Problemas na submissão? Abra uma discussão em [Unit4-Final-Certificate/discussions](https://huggingface.co/spaces/agents-course/Unit4-Final-Certificate/discussions).
diff --git a/units/pt_br/unit4/hands-on.mdx b/units/pt_br/unit4/hands-on.mdx
new file mode 100644
index 00000000..52accbe8
--- /dev/null
+++ b/units/pt_br/unit4/hands-on.mdx
@@ -0,0 +1,52 @@
+# Mão na massa
+
+Pronto para criar seu agente final? Vamos entender como enviar o resultado para avaliação.
+
+## O dataset
+
+O leaderboard usa 20 perguntas retiradas do nível 1 do conjunto de **validação** do GAIA.
+
+Selecionamos questões considerando o número de ferramentas e etapas necessárias para respondê-las.
+
+Pelo formato atual do benchmark, acreditamos que mirar em **30% de acerto** no nível 1 é um teste razoável.
+
+
+
+Depois de baixar:
+- Adicione ao seu **LinkedIn** 🧑💼
+- Compartilhe no **X**, **Bluesky** etc. 🎉
+
+**Não esqueça de marcar [@huggingface](https://huggingface.co/huggingface). Ficaremos orgulhosos e felizes em comemorar com você! 🤗**
+
+> [!TIP]
+> Problemas na submissão? Abra uma discussão em [Unit4-Final-Certificate/discussions](https://huggingface.co/spaces/agents-course/Unit4-Final-Certificate/discussions).
diff --git a/units/pt_br/unit4/hands-on.mdx b/units/pt_br/unit4/hands-on.mdx
new file mode 100644
index 00000000..52accbe8
--- /dev/null
+++ b/units/pt_br/unit4/hands-on.mdx
@@ -0,0 +1,52 @@
+# Mão na massa
+
+Pronto para criar seu agente final? Vamos entender como enviar o resultado para avaliação.
+
+## O dataset
+
+O leaderboard usa 20 perguntas retiradas do nível 1 do conjunto de **validação** do GAIA.
+
+Selecionamos questões considerando o número de ferramentas e etapas necessárias para respondê-las.
+
+Pelo formato atual do benchmark, acreditamos que mirar em **30% de acerto** no nível 1 é um teste razoável.
+
+ +
+## O processo
+
+Você deve estar se perguntando: “Como faço para enviar?”
+
+Para esta unidade, criamos uma API que disponibiliza perguntas e recebe respostas para pontuação.
+Resumo das rotas (consulte a [documentação ao vivo](https://agents-course-unit4-scoring.hf.space/docs) para detalhes interativos):
+
+- **`GET /questions`**: lista completa das questões filtradas.
+- **`GET /random-question`**: obtém uma questão aleatória.
+- **`GET /files/{task_id}`**: baixa um arquivo associado a determinada tarefa.
+- **`POST /submit`**: envia respostas, calcula a pontuação e atualiza o leaderboard.
+
+A comparação é feita por **EXACT MATCH**, então capriche no prompt!
+O time GAIA compartilhou um exemplo de prompt [neste espaço](https://huggingface.co/spaces/gaia-benchmark/leaderboard). Para o curso, **não inclua “FINAL ANSWER”**; faça o agente responder apenas com o conteúdo final.
+
+🎨 **Customize o template**
+
+Disponibilizamos um [template simples](https://huggingface.co/spaces/agents-course/Final_Assignment_Template) como ponto de partida.
+
+Fique à vontade (e **incentivado**) para alterar, adicionar ou reestruturar tudo da forma que preferir.
+
+Para enviar, a API exige 3 itens:
+
+- **Username**: seu usuário no Hugging Face (ex.: obtido via login no Gradio).
+- **Link do código (`agent_code`)**: URL para o repositório da sua Space (`.../tree/main`). Mantenha a Space pública.
+- **Respostas (`answers`)**: lista de objetos `{ "task_id": ..., "submitted_answer": ... }`.
+
+Sugerimos duplicar o [template](https://huggingface.co/spaces/agents-course/Final_Assignment_Template) no seu perfil.
+
+🏆 Confira o leaderboard em [agents-course/Students_leaderboard](https://huggingface.co/spaces/agents-course/Students_leaderboard)
+
+*Aviso amigável:* o leaderboard é para diversão! Sabemos que é possível enviar pontuações sem verificação rígida. Se houver muitos placares altos sem link público, poderemos revisar ou remover entradas para manter os dados úteis. Como é um quadro de estudantes, mantenha a Space pública se quiser exibir seu resultado.
+
diff --git a/units/pt_br/unit4/introduction.mdx b/units/pt_br/unit4/introduction.mdx
new file mode 100644
index 00000000..8301b911
--- /dev/null
+++ b/units/pt_br/unit4/introduction.mdx
@@ -0,0 +1,23 @@
+# Bem-vindo à unidade final [[introduction]]
+
+
+
+## O processo
+
+Você deve estar se perguntando: “Como faço para enviar?”
+
+Para esta unidade, criamos uma API que disponibiliza perguntas e recebe respostas para pontuação.
+Resumo das rotas (consulte a [documentação ao vivo](https://agents-course-unit4-scoring.hf.space/docs) para detalhes interativos):
+
+- **`GET /questions`**: lista completa das questões filtradas.
+- **`GET /random-question`**: obtém uma questão aleatória.
+- **`GET /files/{task_id}`**: baixa um arquivo associado a determinada tarefa.
+- **`POST /submit`**: envia respostas, calcula a pontuação e atualiza o leaderboard.
+
+A comparação é feita por **EXACT MATCH**, então capriche no prompt!
+O time GAIA compartilhou um exemplo de prompt [neste espaço](https://huggingface.co/spaces/gaia-benchmark/leaderboard). Para o curso, **não inclua “FINAL ANSWER”**; faça o agente responder apenas com o conteúdo final.
+
+🎨 **Customize o template**
+
+Disponibilizamos um [template simples](https://huggingface.co/spaces/agents-course/Final_Assignment_Template) como ponto de partida.
+
+Fique à vontade (e **incentivado**) para alterar, adicionar ou reestruturar tudo da forma que preferir.
+
+Para enviar, a API exige 3 itens:
+
+- **Username**: seu usuário no Hugging Face (ex.: obtido via login no Gradio).
+- **Link do código (`agent_code`)**: URL para o repositório da sua Space (`.../tree/main`). Mantenha a Space pública.
+- **Respostas (`answers`)**: lista de objetos `{ "task_id": ..., "submitted_answer": ... }`.
+
+Sugerimos duplicar o [template](https://huggingface.co/spaces/agents-course/Final_Assignment_Template) no seu perfil.
+
+🏆 Confira o leaderboard em [agents-course/Students_leaderboard](https://huggingface.co/spaces/agents-course/Students_leaderboard)
+
+*Aviso amigável:* o leaderboard é para diversão! Sabemos que é possível enviar pontuações sem verificação rígida. Se houver muitos placares altos sem link público, poderemos revisar ou remover entradas para manter os dados úteis. Como é um quadro de estudantes, mantenha a Space pública se quiser exibir seu resultado.
+
diff --git a/units/pt_br/unit4/introduction.mdx b/units/pt_br/unit4/introduction.mdx
new file mode 100644
index 00000000..8301b911
--- /dev/null
+++ b/units/pt_br/unit4/introduction.mdx
@@ -0,0 +1,23 @@
+# Bem-vindo à unidade final [[introduction]]
+
+ +
+Chegamos à última unidade do curso! 🎉
+
+Até aqui, você construiu **uma base sólida em agentes de IA**, desde entender seus componentes até criar os seus próprios. Com esse conhecimento, está pronto para **criar agentes poderosos** e acompanhar as novidades nesse campo em rápida evolução.
+
+Esta unidade é totalmente focada em aplicar o que você aprendeu. Trata-se do **projeto prático final** – e concluí-lo é o último passo para conquistar o **certificado do curso**.
+
+## Qual é o desafio?
+
+Você vai criar seu próprio agente e **avaliar seu desempenho usando um subconjunto do [benchmark GAIA](https://huggingface.co/spaces/gaia-benchmark/leaderboard)**.
+
+Para completar o curso, o agente precisa atingir **30% ou mais** no benchmark. Conseguiu? Então o **certificado de conclusão** é seu! 🏅
+
+Quer comparar seu resultado com o da comunidade? Envie sua pontuação para o **[Student Leaderboard](https://huggingface.co/spaces/agents-course/Students_leaderboard)** e acompanhe o progresso coletivo.
+
+> **🚨 Aviso: unidade avançada e prática**
+>
+> Esta etapa é bem mais “mão na massa” e exige **conhecimento de código mais avançado**. Haverá **menos orientação explícita** do que nas unidades anteriores, então prepare-se para explorar e tomar decisões por conta própria.
+
+Pronto para encarar? Vamos nessa! 🚀
diff --git a/units/pt_br/unit4/what-is-gaia.mdx b/units/pt_br/unit4/what-is-gaia.mdx
new file mode 100644
index 00000000..e18120f5
--- /dev/null
+++ b/units/pt_br/unit4/what-is-gaia.mdx
@@ -0,0 +1,67 @@
+# O que é GAIA?
+
+[GAIA](https://huggingface.co/papers/2311.12983) é um **benchmark criado para avaliar assistentes de IA em tarefas do mundo real**, que exigem várias habilidades centrais: raciocínio, entendimento multimodal, navegação na web e uso competente de ferramentas.
+
+Ele foi apresentado no artigo _“[GAIA: A Benchmark for General AI Assistants](https://huggingface.co/papers/2311.12983)”_.
+
+O benchmark contém **466 perguntas cuidadosamente selecionadas**, que são **conceitualmente simples para humanos**, mas **extremamente desafiadoras para os modelos atuais**.
+
+Veja a diferença:
+- **Humanos**: ~92% de acerto
+- **GPT-4 com plugins**: ~15%
+- **Deep Research (OpenAI)**: 67,36% no conjunto de validação
+
+GAIA evidencia as limitações atuais e oferece um benchmark rigoroso para medir o progresso rumo a assistentes realmente gerais.
+
+## 🌱 Princípios fundamentais do GAIA
+
+O GAIA foi projetado com estes pilares:
+
+- 🔍 **Dificuldade real**: tarefas demandam raciocínio multi-etapas, multimodalidade e interação com ferramentas.
+- 🧾 **Interpretabilidade humana**: apesar de difíceis para IA, são simples de entender para humanos.
+- 🛡️ **Resistência a “gambiarras”**: é preciso executar toda a tarefa; brute force não funciona.
+- 🧰 **Avaliação simples**: respostas curtas, factuais e inequívocas — ótimo para benchmarking.
+
+## Níveis de dificuldade
+
+As tarefas são divididas em **três níveis crescentes**, cada um testando habilidades específicas:
+
+- **Nível 1**: menos de 5 passos, uso mínimo de ferramentas.
+- **Nível 2**: raciocínio mais complexo, coordenação entre múltiplas ferramentas (5 a 10 passos).
+- **Nível 3**: planejamento de longo prazo e integração avançada.
+
+
+
+## Exemplo de questão difícil
+
+> Which of the fruits shown in the 2008 painting "Embroidery from Uzbekistan" were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film "The Last Voyage"? Give the items as a comma-separated list, ordering them in clockwise order based on their arrangement in the painting starting from the 12 o'clock position. Use the plural form of each fruit.
+
+Esta pergunta desafia os sistemas de IA porque:
+
+- Exige resposta **estruturada**;
+- Envolve raciocínio **multimodal** (analisar imagens);
+- Requer **multi-hop retrieval**: identificar frutas, achar o navio, localizar o cardápio;
+- Precisa de **sequenciamento correto** e planejamento.
+
+Tarefas assim mostram onde LLMs tradicionais falham, tornando o GAIA ideal para avaliar **agentes** capazes de raciocinar, buscar e agir multi-etapas.
+
+
+
+## Avaliação em tempo real
+
+Para fomentar benchmarking contínuo, o GAIA oferece um **leaderboard público** no Hugging Face, com **300 perguntas de teste**.
+
+👉 Confira em [huggingface.co/spaces/gaia-benchmark/leaderboard](https://huggingface.co/spaces/gaia-benchmark/leaderboard)
+
+
+
+Quer se aprofundar?
+
+- 📄 [Leia o paper completo](https://huggingface.co/papers/2311.12983)
+- 📄 [Post do OpenAI sobre o Deep Research](https://openai.com/index/introducing-deep-research/)
+- 📄 [Open-source DeepResearch – Freeing our search agents](https://huggingface.co/blog/open-deep-research)
+
+Chegamos à última unidade do curso! 🎉
+
+Até aqui, você construiu **uma base sólida em agentes de IA**, desde entender seus componentes até criar os seus próprios. Com esse conhecimento, está pronto para **criar agentes poderosos** e acompanhar as novidades nesse campo em rápida evolução.
+
+Esta unidade é totalmente focada em aplicar o que você aprendeu. Trata-se do **projeto prático final** – e concluí-lo é o último passo para conquistar o **certificado do curso**.
+
+## Qual é o desafio?
+
+Você vai criar seu próprio agente e **avaliar seu desempenho usando um subconjunto do [benchmark GAIA](https://huggingface.co/spaces/gaia-benchmark/leaderboard)**.
+
+Para completar o curso, o agente precisa atingir **30% ou mais** no benchmark. Conseguiu? Então o **certificado de conclusão** é seu! 🏅
+
+Quer comparar seu resultado com o da comunidade? Envie sua pontuação para o **[Student Leaderboard](https://huggingface.co/spaces/agents-course/Students_leaderboard)** e acompanhe o progresso coletivo.
+
+> **🚨 Aviso: unidade avançada e prática**
+>
+> Esta etapa é bem mais “mão na massa” e exige **conhecimento de código mais avançado**. Haverá **menos orientação explícita** do que nas unidades anteriores, então prepare-se para explorar e tomar decisões por conta própria.
+
+Pronto para encarar? Vamos nessa! 🚀
diff --git a/units/pt_br/unit4/what-is-gaia.mdx b/units/pt_br/unit4/what-is-gaia.mdx
new file mode 100644
index 00000000..e18120f5
--- /dev/null
+++ b/units/pt_br/unit4/what-is-gaia.mdx
@@ -0,0 +1,67 @@
+# O que é GAIA?
+
+[GAIA](https://huggingface.co/papers/2311.12983) é um **benchmark criado para avaliar assistentes de IA em tarefas do mundo real**, que exigem várias habilidades centrais: raciocínio, entendimento multimodal, navegação na web e uso competente de ferramentas.
+
+Ele foi apresentado no artigo _“[GAIA: A Benchmark for General AI Assistants](https://huggingface.co/papers/2311.12983)”_.
+
+O benchmark contém **466 perguntas cuidadosamente selecionadas**, que são **conceitualmente simples para humanos**, mas **extremamente desafiadoras para os modelos atuais**.
+
+Veja a diferença:
+- **Humanos**: ~92% de acerto
+- **GPT-4 com plugins**: ~15%
+- **Deep Research (OpenAI)**: 67,36% no conjunto de validação
+
+GAIA evidencia as limitações atuais e oferece um benchmark rigoroso para medir o progresso rumo a assistentes realmente gerais.
+
+## 🌱 Princípios fundamentais do GAIA
+
+O GAIA foi projetado com estes pilares:
+
+- 🔍 **Dificuldade real**: tarefas demandam raciocínio multi-etapas, multimodalidade e interação com ferramentas.
+- 🧾 **Interpretabilidade humana**: apesar de difíceis para IA, são simples de entender para humanos.
+- 🛡️ **Resistência a “gambiarras”**: é preciso executar toda a tarefa; brute force não funciona.
+- 🧰 **Avaliação simples**: respostas curtas, factuais e inequívocas — ótimo para benchmarking.
+
+## Níveis de dificuldade
+
+As tarefas são divididas em **três níveis crescentes**, cada um testando habilidades específicas:
+
+- **Nível 1**: menos de 5 passos, uso mínimo de ferramentas.
+- **Nível 2**: raciocínio mais complexo, coordenação entre múltiplas ferramentas (5 a 10 passos).
+- **Nível 3**: planejamento de longo prazo e integração avançada.
+
+
+
+## Exemplo de questão difícil
+
+> Which of the fruits shown in the 2008 painting "Embroidery from Uzbekistan" were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film "The Last Voyage"? Give the items as a comma-separated list, ordering them in clockwise order based on their arrangement in the painting starting from the 12 o'clock position. Use the plural form of each fruit.
+
+Esta pergunta desafia os sistemas de IA porque:
+
+- Exige resposta **estruturada**;
+- Envolve raciocínio **multimodal** (analisar imagens);
+- Requer **multi-hop retrieval**: identificar frutas, achar o navio, localizar o cardápio;
+- Precisa de **sequenciamento correto** e planejamento.
+
+Tarefas assim mostram onde LLMs tradicionais falham, tornando o GAIA ideal para avaliar **agentes** capazes de raciocinar, buscar e agir multi-etapas.
+
+
+
+## Avaliação em tempo real
+
+Para fomentar benchmarking contínuo, o GAIA oferece um **leaderboard público** no Hugging Face, com **300 perguntas de teste**.
+
+👉 Confira em [huggingface.co/spaces/gaia-benchmark/leaderboard](https://huggingface.co/spaces/gaia-benchmark/leaderboard)
+
+
+
+Quer se aprofundar?
+
+- 📄 [Leia o paper completo](https://huggingface.co/papers/2311.12983)
+- 📄 [Post do OpenAI sobre o Deep Research](https://openai.com/index/introducing-deep-research/)
+- 📄 [Open-source DeepResearch – Freeing our search agents](https://huggingface.co/blog/open-deep-research)