 -
-[CLS]) to capture the overall representation, both add position information to their embeddings, and both use a Transformer encoder to process the sequence of tokens/patches.
-
-[CLS]) to capture the overall representation, both add position information to their embeddings, and both use a Transformer encoder to process the sequence of tokens/patches.
diff --git a/chapters/en/chapter1/6.mdx b/chapters/en/chapter1/6.mdx
index e540c8624..049078cf3 100644
--- a/chapters/en/chapter1/6.mdx
+++ b/chapters/en/chapter1/6.mdx
@@ -5,16 +5,13 @@
# Transformer Architectures[[transformer-architectures]]
-In the previous sections, we introduced the general Transformer architecture and explored how these models can solve various tasks. Now, let's take a closer look at the three main architectural variants of Transformer models and understand when to use each one. Then, we looked at how those architectures are applied to different language tasks.
+In the previous sections, we introduced the general Transformer architecture and explored how these models can solve various tasks. Now, let's take a closer look at the three main architectural variants of Transformer models and understand when to use each one. Then, we look at how those architectures are applied to different language tasks.
In this section, we're going to dive deeper into the three main architectural variants of Transformer models and understand when to use each one.
- +
+[🤗 Transformers library](https://huggingface.co/docs/transformers/index) ကတော့ အဲဒီမျှဝေထားတဲ့ မော်ဒယ်တွေကို ဖန်တီးပြီး အသုံးပြုနိုင်တဲ့ functionality တွေကို ပံ့ပိုးပေးပါတယ်။ [Model Hub](https://huggingface.co/models) မှာတော့ လူတိုင်း download လုပ်ပြီး အသုံးပြုနိုင်တဲ့ ကြိုတင်လေ့ကျင့်ထားသော (pretrained) မော်ဒယ်ပေါင်း သန်းချီ ပါဝင်ပါတယ်။ သင်ရဲ့ ကိုယ်ပိုင်မော်ဒယ်တွေကိုလည်း Hub ကို upload တင်နိုင်ပါတယ်။
+
+> [!TIP]
+> ⚠️ Hugging Face Hub ဟာ Transformer မော်ဒယ်တွေအတွက်ပဲ ကန့်သတ်ထားတာ မဟုတ်ပါဘူး။ လူတိုင်းက သူတို့လိုချင်တဲ့ မည်သည့်မော်ဒယ် သို့မဟုတ် dataset ကိုမဆို မျှဝေနိုင်ပါတယ်။ ရရှိနိုင်တဲ့ အင်္ဂါရပ်အားလုံးကို ရယူဖို့ huggingface.co account တစ်ခု ဖန်တီးပါ!
+
+Transformer မော်ဒယ်တွေ ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို အသေးစိတ် မလေ့လာခင်မှာ စိတ်ဝင်စားစရာကောင်းတဲ့ NLP ပြဿနာအချို့ကို ဖြေရှင်းဖို့ ဘယ်လိုအသုံးပြုနိုင်လဲဆိုတာကို ဥပမာအချို့နဲ့ ကြည့်ရအောင်။
+
+## Pipelines တွေနဲ့ အလုပ်လုပ်ခြင်း[[working-with-pipelines]]
+
+
+
+[🤗 Transformers library](https://huggingface.co/docs/transformers/index) ကတော့ အဲဒီမျှဝေထားတဲ့ မော်ဒယ်တွေကို ဖန်တီးပြီး အသုံးပြုနိုင်တဲ့ functionality တွေကို ပံ့ပိုးပေးပါတယ်။ [Model Hub](https://huggingface.co/models) မှာတော့ လူတိုင်း download လုပ်ပြီး အသုံးပြုနိုင်တဲ့ ကြိုတင်လေ့ကျင့်ထားသော (pretrained) မော်ဒယ်ပေါင်း သန်းချီ ပါဝင်ပါတယ်။ သင်ရဲ့ ကိုယ်ပိုင်မော်ဒယ်တွေကိုလည်း Hub ကို upload တင်နိုင်ပါတယ်။
+
+> [!TIP]
+> ⚠️ Hugging Face Hub ဟာ Transformer မော်ဒယ်တွေအတွက်ပဲ ကန့်သတ်ထားတာ မဟုတ်ပါဘူး။ လူတိုင်းက သူတို့လိုချင်တဲ့ မည်သည့်မော်ဒယ် သို့မဟုတ် dataset ကိုမဆို မျှဝေနိုင်ပါတယ်။ ရရှိနိုင်တဲ့ အင်္ဂါရပ်အားလုံးကို ရယူဖို့ huggingface.co account တစ်ခု ဖန်တီးပါ!
+
+Transformer မော်ဒယ်တွေ ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို အသေးစိတ် မလေ့လာခင်မှာ စိတ်ဝင်စားစရာကောင်းတဲ့ NLP ပြဿနာအချို့ကို ဖြေရှင်းဖို့ ဘယ်လိုအသုံးပြုနိုင်လဲဆိုတာကို ဥပမာအချို့နဲ့ ကြည့်ရအောင်။
+
+## Pipelines တွေနဲ့ အလုပ်လုပ်ခြင်း[[working-with-pipelines]]
+
+
+ +
+ +
+
+
+[Transformer architecture](https://arxiv.org/abs/1706.03762) ကို ၂၀၁၇ ခုနှစ်၊ ဇွန်လမှာ စတင်မိတ်ဆက်ခဲ့ပါတယ်။ မူလသုတေသနရဲ့ အဓိကအာရုံကတော့ ဘာသာပြန်ခြင်း လုပ်ငန်းတွေ ဖြစ်ပါတယ်။ ထို့နောက်မှာတော့ သြဇာကြီးမားတဲ့ မော်ဒယ်များစွာကို မိတ်ဆက်ခဲ့ပါတယ်။ ၎င်းတို့မှာ-
+
+- **၂၀၁၈ ခုနှစ်၊ ဇွန်လ**: [GPT](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf)၊ ပထမဆုံးသော pretrained Transformer model ဖြစ်ပြီး NLP လုပ်ငန်းမျိုးစုံအတွက် fine-tuning လုပ်ရာမှာ အသုံးပြုခဲ့ကာ state-of-the-art ရလဒ်များကို ရရှိခဲ့ပါတယ်။
+
+- **၂၀၁၈ ခုနှစ်၊ အောက်တိုဘာလ**: [BERT](https://arxiv.org/abs/1810.04805)၊ နောက်ထပ်ကြီးမားတဲ့ pretrained model တစ်ခုဖြစ်ပြီး စာကြောင်းတွေရဲ့ အနှစ်ချုပ်တွေကို ပိုမိုကောင်းမွန်အောင် ထုတ်လုပ်ဖို့ ဒီဇိုင်းထုတ်ထားပါတယ်။ (နောက်အခန်းမှာ အသေးစိတ်ပြောပါမယ်!)
+
+- **၂၀၁၉ ခုနှစ်၊ ဖေဖော်ဝါရီလ**: [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)၊ GPT ရဲ့ ပိုမိုကောင်းမွန်ပြီး (ပိုကြီးတဲ့) ဗားရှင်းတစ်ခုဖြစ်ပြီး ကျင့်ဝတ်ဆိုင်ရာ စိုးရိမ်ပူပန်မှုတွေကြောင့် ချက်ချင်းထုတ်ပြန်ခြင်း မရှိခဲ့ပါဘူး။
+
+- **၂၀၁၉ ခုနှစ်၊ အောက်တိုဘာလ**: [T5](https://huggingface.co/papers/1910.10683)၊ sequence-to-sequence Transformer architecture ကို အခြေခံပြီး multi-task focused လုပ်ဆောင်နိုင်သော မော်ဒယ်တစ်ခု။
+
+- **၂၀၂၀ ခုနှစ်၊ မေလ**: [GPT-3](https://huggingface.co/papers/2005.14165)၊ GPT-2 ထက် ပိုမိုကြီးမားသော ဗားရှင်းဖြစ်ပြီး fine-tuning လုပ်ရန်မလိုဘဲ လုပ်ငန်းမျိုးစုံကို ကောင်းစွာလုပ်ဆောင်နိုင်ပါတယ်။ (၎င်းကို _zero-shot learning_ ဟု ခေါ်ပါတယ်။)
+
+- **၂၀၂၂ ခုနှစ်၊ ဇန်နဝါရီလ**: [InstructGPT](https://huggingface.co/papers/2203.02155)၊ ညွှန်ကြားချက်များကို ပိုမိုကောင်းမွန်စွာ လိုက်နာနိုင်ရန် လေ့ကျင့်ပေးထားသော GPT-3 ၏ ဗားရှင်းတစ်ခု။
+
+ဒီစာရင်းက ပြည့်စုံလွန်းတာ မဟုတ်ပါဘူး။ Transformer မော်ဒယ်အမျိုးအစားအချို့ကိုသာ မီးမောင်းထိုးပြထားတာ ဖြစ်ပါတယ်။ ယေဘုယျအားဖြင့် ၎င်းတို့ကို အမျိုးအစား သုံးမျိုး ခွဲခြားနိုင်ပါတယ်။
+
+- **၂၀၂၃ ခုနှစ်၊ ဇန်နဝါရီလ**: [Llama](https://huggingface.co/papers/2302.13971)၊ ဘာသာစကားမျိုးစုံဖြင့် စာသားများစွာကို ဖန်တီးနိုင်သော Large Language Model တစ်ခု။
+
+- **၂၀၂၃ ခုနှစ်၊ မတ်လ**: [Mistral](https://huggingface.co/papers/2310.06825)၊ parameter ၇ ဘီလီယံပါရှိသော language model ဖြစ်ပြီး အကဲဖြတ်ထားသော benchmark အားလုံးတွင် Llama 2 13B ကို သာလွန်သည်။ ၎င်းသည် ပိုမိုမြန်ဆန်သော inference အတွက် grouped-query attention နှင့် စိတ်ကြိုက်အလျားရှိသော sequences များကို ကိုင်တွယ်ရန် sliding window attention ကို အသုံးပြုသည်။
+
+- **၂၀၂၄ ခုနှစ်၊ မေလ**: [Gemma 2](https://huggingface.co/papers/2408.00118)၊ 2B မှ 27B parameters အထိ ရှိသော ပေါ့ပါးသော၊ state-of-the-art open models မိသားစုတစ်ခုဖြစ်ပြီး interleaved local-global attentions နှင့် group-query attention တို့ကို ပေါင်းစပ်ထားသည်။ ပိုမိုသေးငယ်သော မော်ဒယ်များကို knowledge distillation အသုံးပြု၍ လေ့ကျင့်ထားပြီး ၎င်းတို့ထက် ၂-၃ ဆ ပိုကြီးသော မော်ဒယ်များနှင့် ယှဉ်ပြိုင်နိုင်သော စွမ်းဆောင်ရည်ကို ပေးသည်။
+
+- **၂၀၂၄ ခုနှစ်၊ နိုဝင်ဘာလ**: [SmolLM2](https://huggingface.co/papers/2502.02737)၊ state-of-the-art small language model (135 million မှ 1.7 billion parameters) ဖြစ်ပြီး ၎င်း၏ ကျစ်လျစ်သော အရွယ်အစားရှိသော်လည်း ထူးခြားသော စွမ်းဆောင်ရည်ကို ရရှိစေပြီး mobile နှင့် edge devices များအတွက် ဖြစ်နိုင်ခြေအသစ်များကို ဖွင့်ပေးသည်။
+
+- GPT-ကဲ့သို့သော မော်ဒယ်များ (_auto-regressive_ Transformer models လို့လည်းခေါ်ကြပါတယ်)
+- BERT-ကဲ့သို့သော မော်ဒယ်များ(_auto-encoding_ Transformer models လို့လည်းခေါ်ကြပါတယ်)
+- T5-ကဲ့သို့သော မော်ဒယ်များ (_sequence-to-sequence_ Transformer models လို့လည်းခေါ်ကြပါတယ်)
+
+ဒီအမျိုးအစားတွေကို နောက်ပိုင်းမှာ ပိုမိုနက်နဲစွာ လေ့လာသွားမှာ ဖြစ်ပါတယ်။
+
+## Transformers တွေဟာ language models တွေ ဖြစ်ပါတယ်။ [[transformers-are-language-models]]
+
+အထက်မှာ ဖော်ပြခဲ့တဲ့ Transformer မော်ဒယ်အားလုံး (GPT, BERT, T5, စသည်ဖြင့်) ကို *language models* အဖြစ် လေ့ကျင့်ထားပါတယ်။ ဒါကတော့ ၎င်းတို့ကို များပြားလှတဲ့ ကုန်ကြမ်းစာသား(raw texts)တွေပေါ်မှာ self-supervised ပုံစံနဲ့ လေ့ကျင့်ထားတယ်လို့ ဆိုလိုပါတယ်။
+
+Self-supervised learning ဆိုတာက မော်ဒယ်ရဲ့ input တွေကနေ ရည်ရွယ်ချက်ကို အလိုအလျောက် တွက်ချက်ပေးတဲ့ သင်ယူမှုပုံစံတစ်ခုပါ။ ဒါကြောင့် ဒေတာတွေကို လူသားတွေက label လုပ်ပေးဖို့ မလိုအပ်ပါဘူး။
+
+ဒီလို မော်ဒယ်မျိုးက သူ လေ့ကျင့်ထားတဲ့ ဘာသာစကားရဲ့ စာရင်းအင်းဆိုင်ရာ နားလည်မှုကို တည်ဆောက်ပေမယ့်၊ သီးခြားလက်တွေ့လုပ်ငန်းတာဝန်တွေအတွက်တော့ အသုံးဝင်မှု နည်းပါးပါတယ်။ ဒါကြောင့် ယေဘုယျ pretrained မော်ဒယ်ကို *transfer learning* ဒါမှမဟုတ် *fine-tuning* လို့ခေါ်တဲ့ လုပ်ငန်းစဉ်တစ်ခုကို လုပ်ဆောင်ပါတယ်။ ဒီလုပ်ငန်းစဉ်အတွင်းမှာ မော်ဒယ်ကို -- လူသားတွေက annotated လုပ်ထားတဲ့ labels တွေ အသုံးပြုပြီး -- ပေးထားတဲ့ လုပ်ငန်းတာဝန်တစ်ခုပေါ်မှာ supervised ပုံစံနဲ့ fine-tune လုပ်ပါတယ်။
+
+လုပ်ငန်းတာဝန်တစ်ခုရဲ့ ဥပမာတစ်ခုကတော့ ယခင် *n* စကားလုံးတွေကို ဖတ်ပြီးနောက် စာကြောင်းတစ်ခုရဲ့ နောက်စကားလုံးကို ခန့်မှန်းခြင်းပါပဲ။ ဒါကို *causal language modeling* လို့ ခေါ်ပါတယ်။ ဘာဖြစ်လို့လဲဆိုတော့ output က အတိတ်နဲ့ ပစ္စုပ္ပန် input တွေပေါ် မူတည်ပေမယ့် အနာဂတ် input တွေပေါ် မမူတည်လို့ပါ။
+
+
+
+
+ +
+ +
+
+
+နောက်ထပ် ဥပမာတစ်ခုကတော့ *masked language modeling* ဖြစ်ပြီး၊ အဲဒီမှာ မော်ဒယ်က စာကြောင်းထဲက masked word ကို ခန့်မှန်းပါတယ်။
+
+
+
+
+ +
+ +
+
+
+## Transformers တွေဟာ မော်ဒယ်ကြီးတွေ ဖြစ်ပါတယ်။[[transformers-are-big-models]]
+
+DistilBERT လို ထူးခြားချက်အချို့ကလွဲလို့ ပိုမိုကောင်းမွန်တဲ့ စွမ်းဆောင်ရည်ကို ရရှိဖို့အတွက် ယေဘုယျနည်းဗျူဟာကတော့ မော်ဒယ်တွေရဲ့ အရွယ်အစားကို တိုးမြှင့်ခြင်းအပြင် ၎င်းတို့ကို pretrain လုပ်တဲ့ ဒေတာပမာဏကိုပါ တိုးမြှင့်ခြင်း ဖြစ်ပါတယ်။
+
+
+
+
+ +
+
+
+ကံမကောင်းစွာနဲ့ပဲ မော်ဒယ်တစ်ခု၊ အထူးသဖြင့် မော်ဒယ်ကြီးတစ်ခုကို လေ့ကျင့်ဖို့အတွက် ဒေတာအမြောက်အမြား လိုအပ်ပါတယ်။ ဒါကတော့ အချိန်နဲ့ ကွန်ပျူတာ အရင်းအမြစ်တွေအတွက် အလွန်ကုန်ကျများပါတယ်။ အောက်ပါ graph မှာ မြင်ရတဲ့အတိုင်း သဘာဝပတ်ဝန်းကျင်အပေါ် သက်ရောက်မှုတွေလည်း ရှိပါတယ်။
+
+
+
+ +
+ +
+
+
+
+
+
+ +
+ +
+
+
+ဒီ pretraining ကို များသောအားဖြင့် များပြားလှတဲ့ ဒေတာတွေပေါ်မှာ လုပ်ဆောင်ပါတယ်။ ဒါကြောင့် ကြီးမားတဲ့ data corpus လိုအပ်ပြီး training ဟာ ရက်သတ္တပတ်ပေါင်းများစွာ ကြာမြင့်နိုင်ပါတယ်။
+
+*Fine-tuning* ကတော့ မော်ဒယ်တစ်ခုကို pretrained လုပ်ပြီး **နောက်**မှာ လုပ်ဆောင်တဲ့ training ဖြစ်ပါတယ်။ fine-tuning လုပ်ဖို့အတွက် သင်ဟာ pretrained language model တစ်ခုကို အရင်ရယူပြီးမှ သင်ရဲ့လုပ်ငန်းတာဝန်အတွက် သီးသန့် dataset နဲ့ ထပ်မံ training လုပ်ရပါတယ်။ ဘာလို့ ကျွန်တော်တို့ရဲ့ နောက်ဆုံးအသုံးပြုမှုအတွက် မော်ဒယ်ကို အစကနေ (**scratch**) လုံးဝ မလေ့ကျင့်တာလဲ။ အကြောင်းရင်းအချို့ ရှိပါတယ်။
+
+* Pretrained မော်ဒယ်ကို fine-tuning dataset နဲ့ ဆင်တူတဲ့ dataset တစ်ခုပေါ်မှာ လေ့ကျင့်ထားပြီးသား ဖြစ်ပါတယ်။ ဒါကြောင့် fine-tuning လုပ်ငန်းစဉ်ဟာ မူလမော်ဒယ်က pretraining လုပ်စဉ် ရရှိခဲ့တဲ့ အသိပညာ (ဥပမာ- NLP ပြဿနာများအတွက် pretrained မော်ဒယ်ဟာ သင်အသုံးပြုမယ့် ဘာသာစကားရဲ့ စာရင်းအင်းဆိုင်ရာ နားလည်မှု အချို့ကို ရရှိထားမှာပါ) ကို အသုံးချနိုင်ပါတယ်။
+* Pretrained မော်ဒယ်ကို ဒေတာများစွာပေါ်မှာ လေ့ကျင့်ထားပြီးဖြစ်တာကြောင့် fine-tuning လုပ်ဖို့အတွက် သင့်တင့်တဲ့ ရလဒ်တွေရဖို့ ဒေတာပမာဏ အများကြီး လျော့နည်းစွာ လိုအပ်ပါတယ်။
+* အလားတူပဲ ကောင်းမွန်တဲ့ ရလဒ်တွေရဖို့အတွက် လိုအပ်တဲ့ အချိန်နဲ့ အရင်းအမြစ် ပမာဏဟာ အများကြီး လျော့နည်းပါတယ်။
+
+ဥပမာအားဖြင့် English ဘာသာစကားပေါ်မှာ လေ့ကျင့်ထားတဲ့ pretrained model တစ်ခုကို အသုံးပြုပြီး arXiv corpus ပေါ်မှာ fine-tune လုပ်ခြင်းဖြင့် သိပ္ပံ/သုတေသနအခြေခံ မော်ဒယ်တစ်ခုကို ရရှိနိုင်ပါတယ်။ fine-tuning လုပ်ရာမှာ ဒေတာအနည်းငယ်သာ လိုအပ်ပါလိမ့်မယ်။ pretrained model ရရှိထားတဲ့ အသိပညာကို "လွှဲပြောင်းပေးခြင်း" (transferred) ဖြစ်တာကြောင့် *transfer learning* လို့ ခေါ်ဆိုရခြင်း ဖြစ်ပါတယ်။
+
+
+
+
+ +
+ +
+
+
+ဒါကြောင့် မော်ဒယ်တစ်ခုကို fine-tuning လုပ်ခြင်းက အချိန်၊ ဒေတာ၊ ငွေကြေးနဲ့ သဘာဝပတ်ဝန်းကျင်ဆိုင်ရာ ကုန်ကျစရိတ်တွေကို လျှော့ချပေးပါတယ်။ training လုပ်တာဟာ pretraining အပြည့်အစုံထက် ကန့်သတ်ချက်နည်းတာကြောင့် မတူညီတဲ့ fine-tuning ပုံစံတွေကို ထပ်ခါတလဲလဲ ပြုလုပ်ဖို့ ပိုမြန်ဆန်ပြီး ပိုလွယ်ကူပါတယ်။
+
+ဒီလုပ်ငန်းစဉ်ဟာ အစကနေ လေ့ကျင့်တာထက် ပိုမိုကောင်းမွန်တဲ့ ရလဒ်တွေ ရရှိစေပါလိမ့်မယ် (သင့်မှာ ဒေတာအများကြီးမရှိဘူးဆိုရင်)။ ဒါကြောင့် သင်ဟာ သင်လုပ်ဆောင်မယ့် လုပ်ငန်းနဲ့ အနီးစပ်ဆုံးဖြစ်တဲ့ pretrained model တစ်ခုကို အမြဲတမ်း အသုံးပြုပြီး fine-tune လုပ်သင့်ပါတယ်။
+
+## ယေဘုယျ Transformer architecture[[general-transformer-architecture]]
+
+ဒီအပိုင်းမှာတော့ Transformer မော်ဒယ်ရဲ့ ယေဘုယျ architecture ကို ခြုံငုံသုံးသပ်သွားပါမယ်။ အချို့အယူအဆတွေကို နားမလည်ရင် စိတ်မပူပါနဲ့။ အစိတ်အပိုင်းတစ်ခုချင်းစီကို အသေးစိတ် ဖော်ပြထားတဲ့ အပိုင်းတွေ နောက်ပိုင်းမှာ ရှိပါသေးတယ်။
+
+
+
+
+ +
+ +
+
+
+ဒီအပိုင်းတစ်ခုချင်းစီကို လုပ်ငန်းတာဝန်ပေါ်မူတည်ပြီး သီးခြားစီ အသုံးပြုနိုင်ပါတယ်။
+
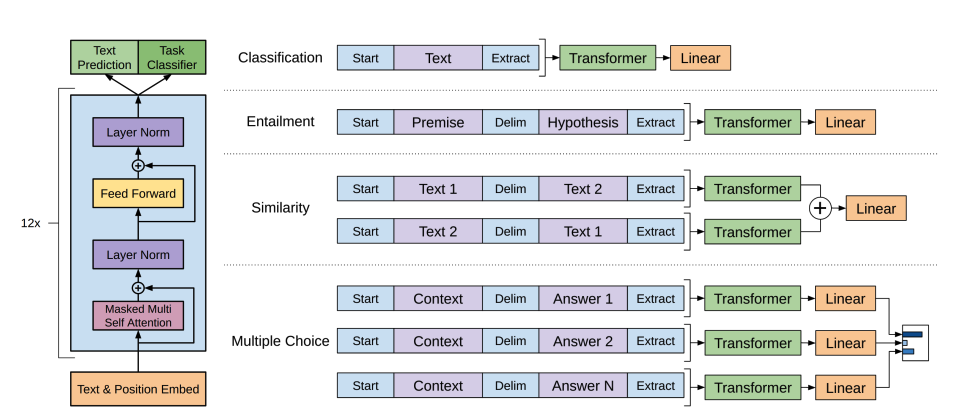
+* **Encoder-only models**: စာကြောင်းခွဲခြားသတ်မှတ်ခြင်း (sentence classification) နဲ့ သီးခြားအမည် ဖော်ထုတ်ခြင်း (named entity recognition) လို input ကို နားလည်ဖို့ လိုအပ်တဲ့ လုပ်ငန်းတွေအတွက် ကောင်းပါတယ်။
+* **Decoder-only models**: စာသားထုတ်လုပ်ခြင်း (text generation) လို ဖန်တီးမှုဆိုင်ရာ လုပ်ငန်းတွေအတွက် ကောင်းပါတယ်။
+* **Encoder-decoder models** သို့မဟုတ် **sequence-to-sequence models**: ဘာသာပြန်ခြင်း ဒါမှမဟုတ် အကျဉ်းချုပ်ခြင်း လို input လိုအပ်တဲ့ ဖန်တီးမှုဆိုင်ရာ လုပ်ငန်းတွေအတွက် ကောင်းပါတယ်။
+
+ဒီ architecture တွေကို နောက်ပိုင်းအပိုင်းတွေမှာ သီးခြားစီ နက်နက်နဲနဲ လေ့လာသွားမှာ ဖြစ်ပါတယ်။
+
+## Attention layers[[attention-layers]]
+
+Transformer မော်ဒယ်တွေရဲ့ အဓိကအင်္ဂါရပ်တစ်ခုကတော့ ၎င်းတို့ကို *attention layers* လို့ခေါ်တဲ့ အထူး layers တွေနဲ့ တည်ဆောက်ထားခြင်း ဖြစ်ပါတယ်။ တကယ်တော့ Transformer architecture ကို မိတ်ဆက်တဲ့ စာတမ်းရဲ့ ခေါင်းစဉ်က ["Attention Is All You Need"](https://arxiv.org/abs/1706.03762) ပါပဲ။ attention layers တွေရဲ့ အသေးစိတ်အချက်အလက်တွေကို သင်တန်းရဲ့ နောက်ပိုင်းမှာ လေ့လာသွားပါမယ်။ အခုအတွက်တော့ ဒီ layer က မော်ဒယ်ကို သင်ပေးပို့လိုက်တဲ့ စာကြောင်းထဲက တချို့စကားလုံးတွေကို သီးခြားအာရုံစိုက်ဖို့ (ကျန်တာတွေကိုတော့ လျစ်လျူရှုဖို့) စကားလုံးတစ်ခုစီရဲ့ ကိုယ်စားပြုမှု (representation) ကို လုပ်ဆောင်နေစဉ်မှာ ပြောပြပေးတယ်ဆိုတာကိုပဲ သိထားဖို့ လိုပါတယ်။
+
+ဒီအကြောင်းအရာကို နားလည်လွယ်အောင် ဥပမာတစ်ခုနဲ့ ပြောရရင် အင်္ဂလိပ်ဘာသာစကားကနေ ပြင်သစ်ဘာသာစကားကို ဘာသာပြန်ခြင်း လုပ်ငန်းကို စဉ်းစားကြည့်ပါ။ "You like this course" ဆိုတဲ့ input ကို ပေးတဲ့အခါ ဘာသာပြန်မော်ဒယ်က "like" ဆိုတဲ့ စကားလုံးအတွက် မှန်ကန်တဲ့ ဘာသာပြန်ကို ရရှိဖို့အတွက် ဘေးကပ်လျက်ရှိတဲ့ "You" ဆိုတဲ့ စကားလုံးကိုလည်း အာရုံစိုက်ဖို့ လိုပါတယ်။ ဘာလို့လဲဆိုတော့ ပြင်သစ်ဘာသာစကားမှာ "like" ဆိုတဲ့ ကြိယာကို subject ပေါ်မူတည်ပြီး ကွဲပြားစွာ တွဲစပ်ရလို့ပါ။ ဒါပေမယ့် စာကြောင်းရဲ့ ကျန်တဲ့အပိုင်းတွေကတော့ အဲဒီစကားလုံးရဲ့ ဘာသာပြန်ဖို့အတွက် အသုံးမဝင်ပါဘူး။ အလားတူပဲ "this" ကို ဘာသာပြန်တဲ့အခါ မော်ဒယ်က "course" ဆိုတဲ့ စကားလုံးကိုပါ အာရုံစိုက်ဖို့ လိုပါလိမ့်မယ်။ ဘာလို့လဲဆိုတော့ "this" က သက်ဆိုင်ရာနာမ်က ပုလ္လင် (masculine) လား၊ ဣတ္ထိလင် (feminine) လားဆိုတာပေါ်မူတည်ပြီး ကွဲပြားစွာ ဘာသာပြန်လို့ပါ။ ဒီမှာလည်း စာကြောင်းထဲက အခြားစကားလုံးတွေက "course" ကို ဘာသာပြန်ဖို့အတွက် အရေးမကြီးပါဘူး။ ပိုမိုရှုပ်ထွေးတဲ့ စာကြောင်းတွေ (နဲ့ ပိုမိုရှုပ်ထွေးတဲ့ သဒ္ဒါစည်းမျဉ်းတွေ) နဲ့ဆိုရင် မော်ဒယ်က စာကြောင်းထဲမှာ ဝေးကွာနေတဲ့ စကားလုံးတွေကိုပါ သီးခြားအာရုံစိုက်ဖို့ လိုအပ်ပါလိမ့်မယ်။
+
+ဒီလို အယူအဆမျိုးက သဘာဝဘာသာစကားနဲ့ သက်ဆိုင်တဲ့ လုပ်ငန်းတာဝန်တွေ အားလုံးမှာ အကျုံးဝင်ပါတယ်။ စကားလုံးတစ်ခုတည်းက သူ့ဘာသာသူ အဓိပ္ပာယ်ရှိပေမယ့်၊ အဲဒီအဓိပ္ပာယ်ဟာ context ကြောင့် နက်နက်နဲနဲ သက်ရောက်မှုရှိပါတယ်။ အဲဒီ context ဟာ လေ့လာနေတဲ့ စကားလုံးရဲ့ အရင် ဒါမှမဟုတ် နောက်ကပ်လျက်ရှိတဲ့ အခြားစကားလုံး (သို့မဟုတ် စကားလုံးများ) ဖြစ်နိုင်ပါတယ်။
+
+Attention layers တွေ ဘာအကြောင်းလဲဆိုတာကို နားလည်ပြီးပြီဆိုတော့ Transformer architecture ကို ပိုမိုနီးကပ်စွာ လေ့လာကြည့်ရအောင်။
+
+## မူလ architecture[[the-original-architecture]]
+
+Transformer architecture ကို မူလက ဘာသာပြန်ခြင်းအတွက် ဒီဇိုင်းထုတ်ခဲ့တာပါ။ training လုပ်နေစဉ်အတွင်း encoder က သတ်မှတ်ထားတဲ့ ဘာသာစကားတစ်ခုနဲ့ input တွေ (စာကြောင်းတွေ) ကို လက်ခံရရှိပြီး၊ decoder ကတော့ တူညီတဲ့ စာကြောင်းတွေကို လိုချင်တဲ့ target language နဲ့ လက်ခံရရှိပါတယ်။ encoder မှာ attention layers တွေက စာကြောင်းတစ်ကြောင်းလုံးရှိ စကားလုံးအားလုံးကို အသုံးပြုနိုင်ပါတယ်။ (ဘာလို့လဲဆိုတော့ ခုဏက မြင်ခဲ့ရတဲ့အတိုင်း စကားလုံးတစ်ခုရဲ့ ဘာသာပြန်ခြင်းက စာကြောင်းထဲမှာ အဲဒီစကားလုံးရဲ့ နောက်က ဒါမှမဟုတ် အရင်က ရှိနေတဲ့အရာတွေပေါ် မူတည်နိုင်လို့ပါ)။ ဒါပေမယ့် decoder ကတော့ တစ်ခုချင်းစီ အစဉ်လိုက် အလုပ်လုပ်ပြီး သူ ဘာသာပြန်ပြီးသား စာကြောင်းထဲက စကားလုံးတွေကိုပဲ အာရုံစိုက်နိုင်ပါတယ်။ (ဒါကြောင့် လက်ရှိ ထုတ်လုပ်နေတဲ့ စကားလုံးရဲ့ အရင်က စကားလုံးတွေကိုသာ)။ ဥပမာအားဖြင့် ဘာသာပြန်ထားတဲ့ target ရဲ့ ပထမစကားလုံး သုံးလုံးကို ခန့်မှန်းပြီးတဲ့အခါ ၎င်းတို့ကို decoder ကို ပေးလိုက်ပါတယ်။ ထို့နောက် decoder က encoder ရဲ့ input တွေအားလုံးကို အသုံးပြုပြီး စတုတ္ထစကားလုံးကို ခန့်မှန်းဖို့ ကြိုးစားပါတယ်။
+
+Training လုပ်နေစဉ်အတွင်း (မော်ဒယ်က target sentences တွေကို ဝင်ရောက်ကြည့်ရှုနိုင်တဲ့အခါ) အရှိန်မြှင့်ဖို့အတွက် decoder ကို target အပြည့်အစုံကို ထည့်ပေးပါတယ်။ ဒါပေမယ့် အနာဂတ်စကားလုံးတွေကို အသုံးပြုခွင့် မပြုပါဘူး။ (အကယ်၍ သူက position 2 မှာရှိတဲ့ စကားလုံးကို ခန့်မှန်းဖို့ ကြိုးစားနေစဉ် position 2 မှာရှိတဲ့ စကားလုံးကို ဝင်ရောက်ကြည့်ရှုခွင့်ရရင် ပြဿနာက သိပ်မခက်ခဲတော့ပါဘူး!)။ ဥပမာအားဖြင့် စတုတ္ထစကားလုံးကို ခန့်မှန်းဖို့ ကြိုးစားနေစဉ်မှာ attention layer က position 1 မှ 3 အထိရှိတဲ့ စကားလုံးတွေကိုပဲ ဝင်ရောက်ကြည့်ရှုနိုင်ပါလိမ့်မယ်။
+
+မူလ Transformer architecture က ဒီလိုပုံစံဖြစ်ပြီး ဘယ်ဘက်မှာ encoder နဲ့ ညာဘက်မှာ decoder ပါဝင်ပါတယ်။
+
+
+
+
+ +
+ +
+
+
+decoder block မှာရှိတဲ့ ပထမ attention layer က decoder ရဲ့ အတိတ် inputs အားလုံးကို အာရုံစိုက်ပေမယ့် ဒုတိယ attention layer က encoder ရဲ့ output ကို အသုံးပြုတယ်ဆိုတာ သတိပြုပါ။ ဒါကြောင့် လက်ရှိစကားလုံးကို အကောင်းဆုံး ခန့်မှန်းနိုင်ဖို့ input စာကြောင်းတစ်ခုလုံးကို ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။ ဒါက အရမ်းအသုံးဝင်ပါတယ်။ ဘာလို့လဲဆိုတော့ မတူညီတဲ့ ဘာသာစကားတွေမှာ စကားလုံးတွေကို မတူညီတဲ့ အစီအစဉ်တွေနဲ့ ချထားတဲ့ သဒ္ဒါစည်းမျဉ်းတွေ ရှိနိုင်တာကြောင့် ဒါမှမဟုတ် စာကြောင်းထဲမှာ နောက်ပိုင်းမှာ ပေးထားတဲ့ context အချို့က ပေးထားတဲ့ စကားလုံးရဲ့ အကောင်းဆုံးဘာသာပြန်ကို ဆုံးဖြတ်ရာမှာ အထောက်အကူဖြစ်နိုင်လို့ပါ။
+
+*Attention mask* ကို encoder/decoder မှာလည်း အသုံးပြုနိုင်ပြီး မော်ဒယ်က အချို့အထူးစကားလုံးတွေကို အာရုံစိုက်ခြင်းမှ ကာကွယ်ပေးပါတယ်။ ဥပမာအားဖြင့် စာကြောင်းတွေကို စုပေါင်းတဲ့အခါ input အားလုံးကို အလျားတူအောင် ပြုလုပ်ဖို့ အသုံးပြုတဲ့ အထူး padding word စတာတွေပါ။
+
+## Architectures vs. checkpoints[[architecture-vs-checkpoints]]
+
+ဒီသင်တန်းမှာ Transformer မော်ဒယ်တွေထဲကို နက်နက်နဲနဲ လေ့လာတဲ့အခါ *architectures* နဲ့ *checkpoints* အပြင် *models* ဆိုတဲ့ အသုံးအနှုန်းတွေကိုလည်း တွေ့ရပါလိမ့်မယ်။ ဒီအသုံးအနှုန်းတွေ အားလုံးမှာ အဓိပ္ပာယ်အနည်းငယ် ကွဲပြားပါတယ်။
+
+* **Architecture**: ဒါကတော့ မော်ဒယ်ရဲ့ ပုံစံတည်ဆောက်ပုံ (skeleton) ဖြစ်ပါတယ်။ မော်ဒယ်အတွင်းမှာ ဖြစ်ပျက်နေတဲ့ layer တစ်ခုစီနဲ့ လုပ်ဆောင်မှုတစ်ခုစီရဲ့ အဓိပ္ပာယ်ဖွင့်ဆိုချက်ပါ။
+* **Checkpoints**: ဒါတွေကတော့ ပေးထားတဲ့ architecture မှာ load လုပ်မယ့် weights တွေ ဖြစ်ပါတယ်။
+* **Model**: ဒါကတော့ "architecture" သို့မဟုတ် "checkpoint" လို တိကျတဲ့ အဓိပ္ပာယ်မရှိဘဲ နှစ်ခုစလုံးကို ဆိုလိုနိုင်တဲ့ ယေဘုယျအသုံးအနှုန်းပါ။ ဒီသင်တန်းကတော့ မရေရာမှုတွေကို လျှော့ချဖို့အတွက် အရေးကြီးတဲ့အခါ *architecture* ဒါမှမဟုတ် *checkpoint* လို့ သတ်သတ်မှတ်မှတ် ဖော်ပြပေးပါလိမ့်မယ်။
+
+ဥပမာအားဖြင့် BERT က architecture တစ်ခုဖြစ်ပြီး `bert-base-cased` ကတော့ Google အဖွဲ့က BERT ရဲ့ ပထမဆုံးထုတ်ဝေမှုအတွက် လေ့ကျင့်ပေးထားတဲ့ weights အစုအဝေးဖြစ်တာကြောင့် checkpoint တစ်ခု ဖြစ်ပါတယ်။ ဒါပေမယ့် လူတစ်ဦးက "the BERT model" နဲ့ "the `bert-base-cased` model" လို့ နှစ်မျိုးစလုံး ပြောဆိုနိုင်ပါတယ်။
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* **Transformer Models**: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။ ၎င်းတို့ဟာ စာသားတွေထဲက စကားလုံးတွေရဲ့ ဆက်နွယ်မှုတွေကို "attention mechanism" သုံးပြီး နားလည်အောင် သင်ကြားပေးပါတယ်။
+* **Attention**: Transformer model များတွင် အသုံးပြုသော ယန္တရားတစ်ခုဖြစ်ပြီး input sequence အတွင်းရှိ အရေးကြီးသော အစိတ်အပိုင်းများကို မော်ဒယ်အား ပိုမိုအာရုံစိုက်စေသည်။
+* **Encoder-Decoder Architecture**: Encoder နှင့် Decoder နှစ်ခုစလုံး ပါဝင်သော Transformer architecture တစ်မျိုးဖြစ်ပြီး ဘာသာပြန်ခြင်းကဲ့သို့သော input sequence မှ output sequence တစ်ခုသို့ ပြောင်းလဲခြင်း လုပ်ငန်းများအတွက် အသုံးပြုပါတယ်။
+* **Architecture**: Machine Learning မော်ဒယ်တစ်ခု၏ အတွင်းပိုင်းတည်ဆောက်ပုံ၊ အလွှာများ (layers) နှင့် လုပ်ဆောင်မှုများ (operations) ၏ အဓိပ္ပာယ်ဖွင့်ဆိုချက်။
+* **GPT (Generative Pre-trained Transformer)**: OpenAI မှ တီထွင်ထားသော Transformer-based Large Language Model (LLM) အမျိုးအစားတစ်ခု။
+* **Pretrained Model**: ဒေတာအမြောက်အမြားပေါ်တွင် ကြိုတင်လေ့ကျင့်ထားသော မော်ဒယ်။
+* **Fine-tuning**: ကြိုတင်လေ့ကျင့်ထားပြီးသား (pre-trained) မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းတစ်ခု (specific task) အတွက် အနည်းငယ်သော ဒေတာနဲ့ ထပ်မံလေ့ကျင့်ပေးခြင်းကို ဆိုလိုပါတယ်။
+* **NLP (Natural Language Processing)**: ကွန်ပျူတာတွေ လူသားဘာသာစကားကို နားလည်၊ အဓိပ္ပာယ်ဖော်ပြီး၊ ဖန်တီးနိုင်အောင် လုပ်ဆောင်ပေးတဲ့ Artificial Intelligence (AI) ရဲ့ နယ်ပယ်ခွဲတစ်ခု ဖြစ်ပါတယ်။
+* **BERT (Bidirectional Encoder Representations from Transformers)**: Google က ထုတ်လုပ်ထားတဲ့ Transformer-based Pretrained Model တစ်ခုဖြစ်ပြီး စာသားတွေရဲ့ အဓိပ္ပာယ်ကို နားလည်ဖို့အတွက် အသုံးပြုပါတယ်။
+* **GPT-2**: GPT ရဲ့ ပိုမိုကောင်းမွန်ပြီး ပိုကြီးတဲ့ ဗားရှင်း။
+* **Ethical Concerns**: ကျင့်ဝတ်ဆိုင်ရာ စိုးရိမ်ပူပန်မှုများ။
+* **T5 (Text-to-Text Transfer Transformer)**: Google က ထုတ်လုပ်ထားတဲ့ Transformer-based Model တစ်ခုဖြစ်ပြီး NLP လုပ်ငန်းတာဝန်များစွာကို text-to-text format ဖြင့် ဖြေရှင်းရန် ဒီဇိုင်းထုတ်ထားပါတယ်။
+* **Sequence-to-sequence**: input sequence တစ်ခုကို output sequence တစ်ခုအဖြစ် ပြောင်းလဲပေးသော မော်ဒယ်အမျိုးအစား။ (ဥပမာ- ဘာသာပြန်ခြင်း)
+* **GPT-3**: GPT-2 ထက် ပိုမိုကြီးမားသော ဗားရှင်း။
+* **Zero-shot learning**: မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းတစ်ခုအတွက် လေ့ကျင့်မှုမရှိဘဲ လုပ်ငန်းကို လုပ်ဆောင်စေခြင်း။
+* **InstructGPT**: ညွှန်ကြားချက်များကို ပိုမိုကောင်းမွန်စွာ လိုက်နာနိုင်ရန် လေ့ကျင့်ထားသော GPT-3 ၏ ဗားရှင်းတစ်ခု။
+* **Llama**: Meta မှ တီထွင်ထားသော Transformer-based Large Language Model (LLM) အမျိုးအစားတစ်ခု။
+* **Mistral**: ၇ ဘီလီယံ parameter ပါရှိသော Large Language Model (LLM) တစ်ခု။
+* **Grouped-query attention**: Transformer model များတွင် အသုံးပြုသော attention mechanism တစ်မျိုးဖြစ်ပြီး inference ကို ပိုမိုမြန်ဆန်စေရန် ကူညီပေးသည်။
+* **Inference**: လေ့ကျင့်ပြီးသား မော်ဒယ်တစ်ခုကို အသုံးပြု၍ input အသစ်များမှ ခန့်မှန်းချက်များ သို့မဟုတ် output များထုတ်လုပ်ခြင်း။
+* **Sliding window attention**: Transformer model များတွင် အသုံးပြုသော attention mechanism တစ်မျိုးဖြစ်ပြီး ရှည်လျားသော sequences များကို ထိထိရောက်ရောက် ကိုင်တွယ်နိုင်စေသည်။
+* **Gemma 2**: Google DeepMind မှ ထုတ်လုပ်သော lightweight, state-of-the-art open models မိသားစုတစ်ခု။
+* **Interleaved local-global attentions**: Transformer model များတွင် အသုံးပြုသော attention mechanism တစ်မျိုးဖြစ်ပြီး local နှင့် global information နှစ်ခုလုံးကို အာရုံစိုက်နိုင်စေသည်။
+* **Knowledge distillation**: ပိုမိုကြီးမားသော၊ ပိုမိုရှုပ်ထွေးသော မော်ဒယ် (teacher model) ၏ အသိပညာကို ပိုမိုသေးငယ်သော၊ ရိုးရှင်းသော မော်ဒယ် (student model) သို့ လွှဲပြောင်းပေးသည့် နည်းလမ်း။
+* **SmolLM2**: သေးငယ်သော အရွယ်အစားရှိသော်လည်း ထူးခြားသော စွမ်းဆောင်ရည်ကို ရရှိစေသော Small Language Model (SLM) တစ်ခု။
+* **Mobile and Edge Devices**: စမတ်ဖုန်းများ၊ တက်ဘလက်များ၊ IoT ကိရိယာများကဲ့သို့ ကွန်ပျူတာစွမ်းအား ကန့်သတ်ချက်ရှိသော ကိရိယာများ။
+* **Auto-regressive Transformer models**: GPT ကဲ့သို့ မော်ဒယ်များ၊ နောက်ထပ်လာမည့် token ကို ယခင် token များအပေါ် အခြေခံ၍ ခန့်မှန်းသည်။
+* **Auto-encoding Transformer models**: BERT ကဲ့သို့ မော်ဒယ်များ၊ masked token များကို input sequence တစ်ခုလုံးအပေါ် အခြေခံ၍ ခန့်မှန်းသည်။
+* **Sequence-to-sequence Transformer models**: T5 ကဲ့သို့ မော်ဒယ်များ၊ input sequence တစ်ခုကို output sequence တစ်ခုအဖြစ် ပြောင်းလဲပေးသည်။
+* **Language Models**: လူသားဘာသာစကားကို နားလည်ပြီး ဖန်တီးနိုင်အောင် သင်ကြားထားသော မော်ဒယ်များ။
+* **Self-supervised learning**: မော်ဒယ်၏ input တွေကနေ ရည်ရွယ်ချက်ကို အလိုအလျောက် တွက်ချက်ပေးတဲ့ သင်ယူမှုပုံစံတစ်ခု။
+* **Transfer Learning**: ကြိုတင်လေ့ကျင့်ထားသော မော်ဒယ်မှ ရရှိသောအသိပညာကို အခြားဆက်စပ်လုပ်ငန်းတစ်ခုသို့ လွှဲပြောင်းအသုံးပြုခြင်း။
+* **Supervised Learning**: human-annotated labels တွေကို အသုံးပြုပြီး မော်ဒယ်ကို သင်ကြားပေးတဲ့ သင်ယူမှုပုံစံတစ်ခု။
+* **Annotated Labels**: လူသားများက ဒေတာများကို မှတ်သားထားသော အမှတ်အသားများ သို့မဟုတ် အမျိုးအစားများ။
+* **Causal Language Modeling**: input sequence ၏ ယခင် token များကို အခြေခံ၍ နောက်ထပ်လာမည့် token ကို ခန့်မှန်းခြင်း။
+* **Masked Language Modeling**: input sequence ထဲရှိ masked (ဝှက်ထားသော) token များကို ခန့်မှန်းခြင်း။
+* **Outliers**: အခြားသောအချက်အလက်များနှင့် ကွဲပြားစွာ ထူးခြားနေသော အချက်အလက်များ။
+* **DistilBERT**: BERT မော်ဒယ်၏ ပိုမိုသေးငယ်ပြီး ပိုမိုမြန်ဆန်သော ဗားရှင်း။
+* **Hyperparameters**: Machine Learning မော်ဒယ်တစ်ခုကို လေ့ကျင့်ရာတွင် သတ်မှတ်ထားသော parameter များ (ဥပမာ- learning rate, batch size)။
+* **Carbon Footprint**: ကာဗွန်ဒိုင်အောက်ဆိုဒ် ထုတ်လွှတ်မှုပမာဏ။
+* **Pretraining**: မော်ဒယ်တစ်ခုကို အစကနေ လေ့ကျင့်ခြင်း။
+* **Weights**: Machine Learning မော်ဒယ်တစ်ခု၏ သင်ယူနိုင်သော အစိတ်အပိုင်းများ။
+* **Randomly Initialized**: မော်ဒယ်၏ weights များကို ကျပန်းတန်ဖိုးများဖြင့် စတင်သတ်မှတ်ခြင်း။
+* **Corpus**: စာသားများစွာ၏ စုဆောင်းမှု (Collection of text data)။
+* **arXiv corpus**: သိပ္ပံနည်းကျ စာတမ်းများ၊ သုတေသနစာတမ်းများ စသည်တို့၏ စုဆောင်းမှု။
+* **Encoder**: Transformer Architecture ရဲ့ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး input data (ဥပမာ- စာသား) ကို နားလည်ပြီး ကိုယ်စားပြုတဲ့ အချက်အလက် (representation) အဖြစ် ပြောင်းလဲပေးပါတယ်။
+* **Decoder**: Transformer Architecture ရဲ့ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး encoder ကနေ ရရှိတဲ့ အချက်အလက် (representation) ကို အသုံးပြုပြီး output data (ဥပမာ- ဘာသာပြန်ထားတဲ့ စာသား) ကို ထုတ်ပေးပါတယ်။
+* **Features**: ဒေတာတစ်ခု၏ ထူးခြားသော လက္ခဏာများ သို့မဟုတ် ဂုဏ်သတ္တိများ။
+* **Sentence Classification**: စာကြောင်းတစ်ခုလုံးကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများထဲသို့ ခွဲခြားသတ်မှတ်ခြင်း။
+* **Named Entity Recognition (NER)**: စာသားထဲက လူအမည်၊ နေရာအမည်၊ အဖွဲ့အစည်းအမည် စတဲ့ သီးခြားအမည်တွေကို ရှာဖွေဖော်ထုတ်ခြင်း။
+* **Text Generation**: AI မော်ဒယ်များကို အသုံးပြု၍ လူသားကဲ့သို့သော စာသားအသစ်များ ဖန်တီးခြင်း။
+* **Translation**: ဘာသာစကားတစ်ခုကနေ အခြားဘာသာစကားတစ်ခုကို စာသားတွေ ဒါမှမဟုတ် စကားပြောတွေကို အလိုအလျောက် ဘာသာပြန်ဆိုခြင်း။
+* **Summarization**: စာသားတစ်ခုကို အဓိကအချက်အလက်များသာ ပါဝင်သော အကျဉ်းချုပ်အဖြစ် ပြောင်းလဲခြင်း။
+* **Attention Layers**: Transformer model များတွင် input data ၏ မတူညီသော အစိတ်အပိုင်းများအပေါ် အာရုံစိုက်နိုင်ရန် ကူညီပေးသော အလွှာများ။
+* **Attention Mechanism**: Transformer model များတွင် input sequence အတွင်းရှိ မတူညီသော စကားလုံးများ၏ ဆက်နွယ်မှုကို နားလည်ရန် ကူညီပေးသော ယန္တရား။
+* **Conjugated**: ကြိယာတစ်ခု၏ ပုံစံသည် subject သို့မဟုတ် tense ပေါ်မူတည်၍ ပြောင်းလဲခြင်း။
+* **Masculine/Feminine**: ဘာသာစကားအချို့တွင် နာမ်များကို ခွဲခြားထားသော ကျား/မ လိင်ခွဲခြားမှု။
+* **Context**: စကားလုံး၊ စာကြောင်း သို့မဟုတ် အကြောင်းအရာတစ်ခုရဲ့ အဓိပ္ပာယ်ကို နားလည်စေရန် ကူညီပေးသော ပတ်ဝန်းကျင်ရှိ အချက်အလက်များ။
+* **Target Language**: ဘာသာပြန်လိုသော ဘာသာစကား။
+* **Sequentially**: တစ်ခုပြီးတစ်ခု အစီအစဉ်အတိုင်း လုပ်ဆောင်ခြင်း။
+* **Attention Mask**: မော်ဒယ်ကို အချို့သော input token များအပေါ် အာရုံစိုက်ခြင်းမှ တားဆီးရန် အသုံးပြုသော mask (အမှတ်အသား)။
+* **Padding Word**: input sequence များ၏ အလျားကို တူညီစေရန်အတွက် ထပ်ပေါင်းထည့်သော အထူးစကားလုံး။
+* **Batching**: မော်ဒယ်ကို တစ်ကြိမ်တည်း လေ့ကျင့်ရန် သို့မဟုတ် inference လုပ်ရန်အတွက် ဒေတာနမူနာများစွာကို အစုလိုက် စုစည်းခြင်း။
+* **Checkpoint**: သတ်မှတ်ထားသော architecture အတွက် လေ့ကျင့်ပြီးသား weights များ။
\ No newline at end of file
diff --git a/chapters/my/chapter1/5.mdx b/chapters/my/chapter1/5.mdx
new file mode 100644
index 000000000..6e8cfee59
--- /dev/null
+++ b/chapters/my/chapter1/5.mdx
@@ -0,0 +1,303 @@
+# 🤗 Transformers တွေက လုပ်ငန်းတာဝန်တွေကို ဘယ်လိုဖြေရှင်းပေးလဲ။[[how-transformers-solve-tasks]]
+
+
+
+
+  +
+
+
+1. GPT-2 ဟာ စကားလုံးတွေကို tokenize လုပ်ပြီး token embedding တွေ ထုတ်ပေးဖို့အတွက် [byte pair encoding (BPE)](https://huggingface.co/docs/transformers/tokenizer_summary#bytepair-encoding-bpe) ကို အသုံးပြုပါတယ်။ sequence ထဲမှာ token တစ်ခုချင်းစီရဲ့ နေရာကို ပြသဖို့ positional encodings တွေကို token embeddings တွေမှာ ထပ်ထည့်ပါတယ်။ input embeddings တွေကို decoder blocks အများအပြားကနေတဆင့် ဖြတ်သန်းပြီး final hidden state အချို့ကို ထုတ်ပေးပါတယ်။ decoder block တစ်ခုစီအတွင်းမှာ GPT-2 က *masked self-attention* layer ကို အသုံးပြုပါတယ်။ ဆိုလိုတာက GPT-2 ဟာ နောက်လာမယ့် tokens တွေကို မကြည့်နိုင်ပါဘူး။ ဘယ်ဘက် (အရင် tokens) က tokens တွေကိုသာ ကြည့်ခွင့်ရှိပါတယ်။ ဒါက BERT ရဲ့ [`mask`] token နဲ့ မတူပါဘူး။ ဘာလို့လဲဆိုတော့ masked self-attention မှာ future tokens တွေအတွက် score ကို `0` သတ်မှတ်ဖို့ attention mask ကို အသုံးပြုထားလို့ပါ။
+
+2. Decoder ကနေ ထွက်လာတဲ့ output ကို language modeling head ကို ပေးပို့ပါတယ်။ အဲဒီကနေ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး hidden states တွေကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ label ကတော့ sequence ထဲမှာရှိတဲ့ နောက် token ဖြစ်ပြီး logits တွေကို ညာဘက်သို့ တစ်နေရာ ရွှေ့ခြင်းဖြင့် ဖန်တီးပါတယ်။ shifted logits တွေနဲ့ labels တွေကြားက cross-entropy loss ကို တွက်ချက်ပြီး နောက်လာမယ့် အဖြစ်နိုင်ဆုံး token ကို ထုတ်ပေးပါတယ်။
+
+GPT-2 ရဲ့ pretraining ရည်ရွယ်ချက်က [causal language modeling](https://huggingface.co/docs/transformers/glossary#causal-language-modeling) ပေါ် အခြေခံပြီး sequence ထဲက နောက်စကားလုံးကို ခန့်မှန်းတာပါ။ ဒါက GPT-2 ကို စာသားဖန်တီးခြင်းနဲ့ ပတ်သက်တဲ့ လုပ်ငန်းတာဝန်တွေမှာ အထူးကောင်းမွန်စေပါတယ်။
+
+စာသား ဖန်တီးခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilGPT-2 ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [causal language modeling guide](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) ကို ကြည့်ရှုပါ။
+
+> [!TIP]
+> စာသား ဖန်တီးခြင်းနဲ့ ပတ်သက်တဲ့ အချက်အလက်အများကြီးအတွက် [text generation strategies](generation_strategies) guide ကို ကြည့်ရှုပါ။
+
+### စာသား အမျိုးအစားခွဲခြားခြင်း (Text classification)[[text-classification]]
+
+စာသား အမျိုးအစားခွဲခြားခြင်းဆိုတာ စာသားမှတ်တမ်းတွေကို ကြိုတင်သတ်မှတ်ထားတဲ့ အမျိုးအစားတွေ (ဥပမာ- sentiment analysis, topic classification, spam detection) သို့ သတ်မှတ်ပေးတာကို ဆိုလိုပါတယ်။
+
+[BERT](https://huggingface.co/docs/transformers/model_doc/bert) ဟာ encoder-only မော်ဒယ်တစ်ခုဖြစ်ပြီး စာသားကို နှစ်ဖက်စလုံးက စကားလုံးတွေကို ကြည့်ရှုခြင်းဖြင့် ပိုမိုကြွယ်ဝတဲ့ ကိုယ်စားပြုမှု (representations) တွေကို သင်ယူဖို့အတွက် deep bidirectionality ကို ထိရောက်စွာ အကောင်အထည်ဖော်ခဲ့တဲ့ ပထမဆုံးမော်ဒယ် ဖြစ်ပါတယ်။
+
+1. BERT ဟာ စာသားရဲ့ token embedding ကို ထုတ်ပေးဖို့အတွက် [WordPiece](https://huggingface.co/docs/transformers/tokenizer_summary#wordpiece) tokenization ကို အသုံးပြုပါတယ်။ စာကြောင်းတစ်ကြောင်းနဲ့ စာကြောင်းနှစ်ကြောင်းရဲ့ ကွာခြားချက်ကို ပြောပြဖို့အတွက် အထူး `[SEP]` token တစ်ခုကို ခွဲခြားဖို့ ထပ်ထည့်ပါတယ်။ sequence of text တိုင်းရဲ့ အစမှာ အထူး `[CLS]` token တစ်ခုကို ထပ်ထည့်ပါတယ်။ `[CLS]` token ပါတဲ့ နောက်ဆုံး output ကို classification လုပ်ငန်းတာဝန်တွေအတွက် classification head ရဲ့ input အဖြစ် အသုံးပြုပါတယ်။ BERT ဟာ token တစ်ခုက စာကြောင်းတစ်စုံမှာ ပထမစာကြောင်း ဒါမှမဟုတ် ဒုတိယစာကြောင်းမှာ ပါဝင်တယ်ဆိုတာကို ဖော်ပြဖို့ segment embedding တစ်ခုကိုလည်း ထပ်ထည့်ပါတယ်။
+
+2. BERT ကို masked language modeling နဲ့ next-sentence prediction ဆိုတဲ့ ရည်ရွယ်ချက်နှစ်ခုနဲ့ ကြိုတင်လေ့ကျင့်ထားပါတယ်။ masked language modeling မှာ input tokens အချို့ ရာခိုင်နှုန်းကို ကျပန်းဖုံးကွယ်ထားပြီး မော်ဒယ်က ဒါတွေကို ခန့်မှန်းဖို့ လိုပါတယ်။ ဒါက မော်ဒယ်က စကားလုံးအားလုံးကို မြင်ပြီး နောက်စကားလုံးကို "ခန့်မှန်း" နိုင်တဲ့ bidirectionality ပြဿနာကို ဖြေရှင်းပေးပါတယ်။ ခန့်မှန်းထားတဲ့ masked tokens တွေရဲ့ final hidden states တွေကို feedforward network တစ်ခုကို ပေးပို့ပြီး vocabulary ပေါ်က softmax နဲ့ ဖုံးကွယ်ထားတဲ့ စကားလုံးကို ခန့်မှန်းပါတယ်။
+
+ ဒုတိယ pretraining object က next-sentence prediction ဖြစ်ပါတယ်။ မော်ဒယ်ဟာ စာကြောင်း B က စာကြောင်း A နောက်က လိုက်သလားဆိုတာကို ခန့်မှန်းရပါမယ်။ အချိန်ရဲ့ ထက်ဝက်မှာ စာကြောင်း B က နောက်လာမယ့် စာကြောင်းဖြစ်ပြီး ကျန်ထက်ဝက်မှာတော့ စာကြောင်း B က ကျပန်းစာကြောင်းတစ်ကြောင်း ဖြစ်ပါတယ်။ နောက်လာမယ့် စာကြောင်းဟုတ်မဟုတ်ဆိုတဲ့ ခန့်မှန်းချက်ကို feedforward network တစ်ခုကို ပေးပို့ပြီး class နှစ်ခု (`IsNext` နဲ့ `NotNext`) ပေါ်က softmax နဲ့ တွက်ချက်ပါတယ်။
+
+3. input embeddings တွေကို encoder layers အများအပြားကနေတဆင့် ဖြတ်သန်းပြီး final hidden states အချို့ကို ထုတ်ပေးပါတယ်။
+
+ကြိုတင်လေ့ကျင့်ထားတဲ့ မော်ဒယ်ကို စာသား အမျိုးအစားခွဲခြားခြင်းအတွက် အသုံးပြုဖို့အတွက် base BERT မော်ဒယ်ရဲ့ ထိပ်မှာ sequence classification head တစ်ခုကို ထပ်ထည့်ရပါမယ်။ sequence classification head က linear layer တစ်ခုဖြစ်ပြီး final hidden states တွေကို လက်ခံကာ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး ၎င်းတို့ကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ logits တွေနဲ့ target တွေကြားက cross-entropy loss ကို တွက်ချက်ပြီး အဖြစ်နိုင်ဆုံး label ကို ရှာဖွေပါတယ်။
+
+စာသား အမျိုးအစားခွဲခြားခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilBERT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [text classification guide](https://huggingface.co/docs/transformers/tasks/sequence_classification) ကို ကြည့်ရှုပါ။
+
+### Token classification[[token-classification]]
+
+Token classification ဆိုတာ sequence တစ်ခုစီရှိ token တစ်ခုစီကို label တစ်ခု သတ်မှတ်ပေးတာကို ဆိုလိုပါတယ်။ ဥပမာအားဖြင့် named entity recognition သို့မဟုတ် part-of-speech tagging တို့ ဖြစ်ပါတယ်။
+
+BERT ကို named entity recognition (NER) လို token classification လုပ်ငန်းတာဝန်တွေအတွက် အသုံးပြုဖို့အတွက် base BERT မော်ဒယ်ရဲ့ ထိပ်မှာ token classification head တစ်ခုကို ထပ်ထည့်ရပါမယ်။ token classification head က linear layer တစ်ခုဖြစ်ပြီး final hidden states တွေကို လက်ခံကာ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး ၎င်းတို့ကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ logits တွေနဲ့ token တစ်ခုစီကြားက cross-entropy loss ကို တွက်ချက်ပြီး အဖြစ်နိုင်ဆုံး label ကို ရှာဖွေပါတယ်။
+
+token classification ကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilBERT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [token classification guide](https://huggingface.co/docs/transformers/tasks/token_classification) ကို ကြည့်ရှုပါ။
+
+### မေးခွန်းဖြေခြင်း (Question answering)[[question-answering]]
+
+မေးခွန်းဖြေခြင်းဆိုတာက ပေးထားတဲ့ context ဒါမှမဟုတ် စာပိုဒ်တစ်ခုအတွင်းမှာ မေးခွန်းရဲ့အဖြေကို ရှာဖွေတာကို ဆိုလိုပါတယ်။
+
+BERT ကို မေးခွန်းဖြေခြင်းအတွက် အသုံးပြုဖို့အတွက် base BERT မော်ဒယ်ရဲ့ ထိပ်မှာ span classification head တစ်ခုကို ထပ်ထည့်ရပါမယ်။ ဒီ linear layer က final hidden states တွေကို လက်ခံကာ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး အဖြေနဲ့ ကိုက်ညီတဲ့ `span` start နဲ့ end logits တွေကို တွက်ချက်ပေးပါတယ်။ logits တွေနဲ့ label position တွေကြားက cross-entropy loss ကို တွက်ချက်ပြီး အဖြေနဲ့ ကိုက်ညီတဲ့ အဖြစ်နိုင်ဆုံး စာသားအပိုင်းကို ရှာဖွေပါတယ်။
+
+မေးခွန်းဖြေခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilBERT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [question answering guide](https://huggingface.co/docs/transformers/tasks/question_answering) ကို ကြည့်ရှုပါ။
+
+> [!TIP]
+> 💡 BERT ကို ကြိုတင်လေ့ကျင့်ပြီးတာနဲ့ မတူညီတဲ့ လုပ်ငန်းတာဝန်တွေအတွက် အသုံးပြုဖို့ ဘယ်လောက်လွယ်ကူလဲဆိုတာ သတိထားမိလား။ သင်လိုချင်တဲ့ output ကို ရရှိဖို့အတွက် ကြိုတင်လေ့ကျင့်ထားတဲ့ မော်ဒယ်ရဲ့ ထိပ်မှာ သီးခြား head တစ်ခုကို ထပ်ထည့်ဖို့ပဲ လိုအပ်ပါတယ်။
+
+### အနှစ်ချုပ်ခြင်း (Summarization)[[summarization]]
+
+အနှစ်ချုပ်ခြင်းဆိုတာက ပိုရှည်တဲ့ စာသားတစ်ခုကို အဓိကအချက်အလက်တွေနဲ့ အဓိပ္ပာယ်ကို ထိန်းသိမ်းထားရင်း ပိုတိုတဲ့ပုံစံအဖြစ် ပြောင်းလဲတာကို ဆိုလိုပါတယ်။
+
+[BART](https://huggingface.co/docs/transformers/model_doc/bart) နဲ့ [T5](model_doc/t5) လို encoder-decoder မော်ဒယ်တွေကို summarization လုပ်ငန်းတာဝန်ရဲ့ sequence-to-sequence ပုံစံအတွက် ဒီဇိုင်းထုတ်ထားပါတယ်။ ဒီအပိုင်းမှာ BART ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို ရှင်းပြပြီး၊ ပြီးရင် T5 ကို fine-tune လုပ်တာကို သင် ကိုယ်တိုင် စမ်းကြည့်နိုင်ပါတယ်။
+
+
+
+  +
+
+
+1. BART ရဲ့ encoder architecture က BERT နဲ့ အတော်လေး ဆင်တူပြီး စာသားရဲ့ token နဲ့ positional embedding ကို လက်ခံပါတယ်။ BART ကို input ကို ဖျက်စီးပြီး decoder နဲ့ ပြန်လည်တည်ဆောက်ခြင်းဖြင့် ကြိုတင်လေ့ကျင့်ထားပါတယ်။ သီးခြား corruption strategies တွေပါတဲ့ အခြား encoders တွေနဲ့မတူဘဲ BART က ဘယ်လို corruption အမျိုးအစားမဆို အသုံးပြုနိုင်ပါတယ်။ သို့သော် *text infilling* corruption strategy က အကောင်းဆုံး အလုပ်လုပ်ပါတယ်။ text infilling မှာ စာသားအပိုင်းအချို့ကို **တစ်ခုတည်းသော** [`mask`] token နဲ့ အစားထိုးပါတယ်။ ဒါက အရေးကြီးပါတယ်၊ ဘာလို့လဲဆိုတော့ မော်ဒယ်က ဖုံးကွယ်ထားတဲ့ tokens တွေကို ခန့်မှန်းရမှာဖြစ်ပြီး၊ ပျောက်ဆုံးနေတဲ့ tokens အရေအတွက်ကို ခန့်မှန်းဖို့ မော်ဒယ်ကို သင်ကြားပေးပါတယ်။ input embeddings နဲ့ masked spans တွေကို encoder ကနေတဆင့် ဖြတ်သန်းပြီး final hidden states အချို့ကို ထုတ်ပေးပါတယ်။ ဒါပေမယ့် BERT နဲ့မတူဘဲ BART က စကားလုံးတစ်လုံးကို ခန့်မှန်းဖို့ နောက်ဆုံး feedforward network ကို ထပ်ထည့်ထားခြင်း မရှိပါဘူး။
+
+2. encoder ရဲ့ output ကို decoder ကို ပေးပို့ပါတယ်။ decoder က ဖုံးကွယ်ထားတဲ့ tokens တွေနဲ့ encoder ရဲ့ output ကနေ uncorrupted tokens တွေကို ခန့်မှန်းရပါမယ်။ ဒါက decoder ကို မူရင်းစာသားကို ပြန်လည်တည်ဆောက်ဖို့ အပို context တွေ ပေးပါတယ်။ decoder ကနေ ထွက်လာတဲ့ output ကို language modeling head ကို ပေးပို့ပါတယ်။ အဲဒီကနေ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး hidden states တွေကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ logits တွေနဲ့ label (ညာဘက်သို့ ရွှေ့ထားတဲ့ token) ကြားက cross-entropy loss ကို တွက်ချက်ပါတယ်။
+
+အနှစ်ချုပ်ခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ T5 ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [summarization guide](https://huggingface.co/docs/transformers/tasks/summarization) ကို ကြည့်ရှုပါ။
+
+> [!TIP]
+> စာသား ဖန်တီးခြင်းနဲ့ ပတ်သက်တဲ့ အချက်အလက်အများကြီးအတွက် [text generation strategies](https://huggingface.co/docs/transformers/generation_strategies) guide ကို ကြည့်ရှုပါ။
+
+### ဘာသာပြန်ခြင်း (Translation)[[translation]]
+
+ဘာသာပြန်ခြင်းဆိုတာ စာသားတစ်ခုကို အခြားဘာသာစကားတစ်ခုသို့ အဓိပ္ပာယ်ကို ထိန်းသိမ်းထားရင်း ပြောင်းလဲတာကို ဆိုလိုပါတယ်။ ဘာသာပြန်ခြင်းက sequence-to-sequence လုပ်ငန်းတာဝန်တစ်ခုရဲ့ နောက်ထပ်ဥပမာတစ်ခု ဖြစ်ပါတယ်။ ဆိုလိုတာက [BART](https://huggingface.co/docs/transformers/model_doc/bart) ဒါမှမဟုတ် [T5](model_doc/t5) လို encoder-decoder မော်ဒယ်ကို အသုံးပြုနိုင်ပါတယ်။ ဒီအပိုင်းမှာ BART ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို ရှင်းပြပြီး၊ ပြီးရင် T5 ကို fine-tune လုပ်တာကို သင် ကိုယ်တိုင် စမ်းကြည့်နိုင်ပါတယ်။
+
+BART ဟာ source ဘာသာစကားတစ်ခုကို target ဘာသာစကားသို့ decode လုပ်နိုင်တဲ့ input အဖြစ် map လုပ်ဖို့အတွက် သီးခြား၊ ကျပန်းစတင်ထားတဲ့ encoder တစ်ခုကို ထပ်ထည့်ခြင်းဖြင့် ဘာသာပြန်ခြင်းကို လိုက်လျောညီထွေဖြစ်အောင် လုပ်ဆောင်ပါတယ်။ ဒီ encoder အသစ်ရဲ့ embeddings တွေကို မူရင်း word embeddings အစား ကြိုတင်လေ့ကျင့်ထားတဲ့ encoder ကို ပေးပို့ပါတယ်။ source encoder ကို မော်ဒယ် output ကနေ cross-entropy loss နဲ့ source encoder, positional embeddings နဲ့ input embeddings တွေကို update လုပ်ခြင်းဖြင့် လေ့ကျင့်ပေးပါတယ်။ ဒီပထမအဆင့်မှာ မော်ဒယ် parameters တွေကို freeze ထားပြီး၊ ဒုတိယအဆင့်မှာတော့ မော်ဒယ် parameters အားလုံးကို အတူတကွ လေ့ကျင့်ပေးပါတယ်။ BART ကိုတော့ ဘာသာပြန်ခြင်းအတွက် ရည်ရွယ်ပြီး မတူညီတဲ့ ဘာသာစကားများစွာနဲ့ ကြိုတင်လေ့ကျင့်ထားတဲ့ multilingual version ဖြစ်တဲ့ mBART က ဆက်ခံခဲ့ပါတယ်။
+
+ဘာသာပြန်ခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ T5 ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [translation guide](https://huggingface.co/docs/transformers/tasks/translation) ကို ကြည့်ရှုပါ။
+
+> [!TIP]
+> ဒီ guide တစ်လျှောက်လုံးမှာ သင်တွေ့ခဲ့ရတဲ့အတိုင်း မော်ဒယ်များစွာဟာ မတူညီတဲ့ လုပ်ငန်းတာဝန်တွေကို ဖြေရှင်းနေရရင်တောင် အလားတူ ပုံစံတွေကို လိုက်နာကြပါတယ်။ ဒီလို အခြေခံပုံစံတွေကို နားလည်ထားတာက မော်ဒယ်အသစ်တွေ ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို အမြန်နားလည်ဖို့နဲ့ ရှိပြီးသားမော်ဒယ်တွေကို သင်ရဲ့လိုအပ်ချက်တွေနဲ့ လိုက်လျောညီထွေဖြစ်အောင် လုပ်ဆောင်ဖို့ ကူညီပေးနိုင်ပါတယ်။
+
+## စာသားပြင်ပရှိ Modalities များ[[modalities-beyond-text]]
+
+Transformers တွေဟာ စာသားအတွက်သာ ကန့်သတ်ထားတာ မဟုတ်ပါဘူး။ ၎င်းတို့ကို speech and audio, images နဲ့ video လို အခြား modalities တွေမှာလည်း အသုံးပြုနိုင်ပါတယ်။ ဒီသင်တန်းမှာတော့ ကျွန်တော်တို့က စာသားကို အဓိကထားမှာဖြစ်ပေမယ့် အခြား modalities တွေကို အတိုချုပ် မိတ်ဆက်ပေးပါမယ်။
+
+### စကားပြောနှင့် အသံ (Speech and audio)[[speech-and-audio]]
+
+Transformer မော်ဒယ်တွေက စာသား ဒါမှမဟုတ် ပုံတွေနဲ့ယှဉ်ရင် ထူးခြားတဲ့ စိန်ခေါ်မှုတွေရှိတဲ့ speech နဲ့ audio data တွေကို ဘယ်လိုကိုင်တွယ်လဲဆိုတာကို စလေ့လာရအောင်။
+
+[Whisper](https://huggingface.co/docs/transformers/main/en/model_doc/whisper) ဟာ 680,000 နာရီကြာ မှတ်သားထားတဲ့ audio data တွေနဲ့ ကြိုတင်လေ့ကျင့်ထားတဲ့ encoder-decoder (sequence-to-sequence) transformer တစ်ခုဖြစ်ပါတယ်။ ဒီလိုများပြားတဲ့ pretraining data ပမာဏက English နဲ့ အခြားဘာသာစကားများစွာရှိ audio လုပ်ငန်းတာဝန်တွေမှာ zero-shot performance ကို ရရှိစေပါတယ်။ decoder က Whisper ကို encoders တွေ သင်ယူထားတဲ့ speech representations တွေကို စာသားလို အသုံးဝင်တဲ့ outputs တွေအဖြစ် ထပ်မံ fine-tune လုပ်စရာမလိုဘဲ map လုပ်နိုင်စေပါတယ်။ Whisper က box ထဲကနေ တန်းအလုပ်လုပ်နိုင်ပါတယ်။
+
+
+
+  +
+
+
+ပုံကြမ်းကို [Whisper paper](https://huggingface.co/papers/2212.04356) မှ ရယူထားပါသည်။
+
+ဒီမော်ဒယ်မှာ အဓိက အစိတ်အပိုင်းနှစ်ခု ပါဝင်ပါတယ်။
+
+1. **Encoder**: input audio ကို လုပ်ဆောင်ပေးပါတယ်။ ကနဦး audio ကို log-Mel spectrogram အဖြစ် ပြောင်းလဲပါတယ်။ ဒီ spectrogram ကို Transformer encoder network ကနေတဆင့် ဖြတ်သန်းပါတယ်။
+
+2. **Decoder**: encoded audio representation ကို ယူပြီး သက်ဆိုင်ရာ text tokens တွေကို autoregressively ခန့်မှန်းပါတယ်။ ဒါဟာ အရင် tokens တွေနဲ့ encoder output ကို ပေးထားပြီး နောက် text token ကို ခန့်မှန်းဖို့ လေ့ကျင့်ထားတဲ့ standard Transformer decoder တစ်ခုပါ။ transcription, translation ဒါမှမဟုတ် language identification လို သီးခြားလုပ်ငန်းတာဝန်တွေဆီ မော်ဒယ်ကို ဦးတည်စေဖို့ decoder input ရဲ့ အစမှာ အထူး tokens တွေကို အသုံးပြုပါတယ်။
+
+Whisper ကို ဝက်ဘ်မှ စုဆောင်းထားတဲ့ 680,000 နာရီကြာ မှတ်သားထားတဲ့ audio data များစွာနဲ့ မတူညီတဲ့ dataset တစ်ခုပေါ်မှာ ကြိုတင်လေ့ကျင့်ထားပါတယ်။ ဒီလို ကြီးမားတဲ့၊ weakly supervised pretraining ဟာ မတူညီတဲ့ ဘာသာစကားတွေ၊ လေယူလေသိမ်းတွေနဲ့ လုပ်ငန်းတာဝန်တွေမှာ task-specific finetuning မပါဘဲ အစွမ်းထက်တဲ့ zero-shot performance ကို ရရှိစေတဲ့ အဓိကအချက်ပါ။
+
+Whisper ကို ကြိုတင်လေ့ကျင့်ပြီးပြီဆိုတော့ zero-shot inference အတွက် တိုက်ရိုက်အသုံးပြုနိုင်သလို automatic speech recognition ဒါမှမဟုတ် speech translation လို သီးခြားလုပ်ငန်းတာဝန်တွေမှာ စွမ်းဆောင်ရည်ပိုမိုကောင်းမွန်စေဖို့ သင်ရဲ့ data ပေါ်မှာ fine-tune လုပ်နိုင်ပါပြီ။
+
+> [!TIP]
+> Whisper ရဲ့ အဓိက ဆန်းသစ်တီထွင်မှုကတော့ အင်တာနက်ကနေ ရရှိတဲ့ မတူညီတဲ့၊ weakly supervised audio data တွေကို အစဉ်အလာမရှိတဲ့ ပမာဏနဲ့ လေ့ကျင့်ထားခြင်း ဖြစ်ပါတယ်။ ဒါက မတူညီတဲ့ ဘာသာစကားတွေ၊ လေယူလေသိမ်းတွေနဲ့ လုပ်ငန်းတာဝန်တွေဆီကို task-specific finetuning မပါဘဲ ထူးထူးခြားခြား ကောင်းမွန်စွာ ယေဘုယျလုပ်ဆောင်နိုင်စေပါတယ်။
+
+### အလိုအလျောက် စကားပြော မှတ်သားခြင်း (Automatic speech recognition)[[automatic-speech-recognition]]
+
+ကြိုတင်လေ့ကျင့်ထားတဲ့ မော်ဒယ်ကို automatic speech recognition အတွက် အသုံးပြုဖို့အတွက် ၎င်းရဲ့ ပြည့်စုံတဲ့ encoder-decoder ဖွဲ့စည်းပုံကို အသုံးချရပါမယ်။ encoder က audio input ကို လုပ်ဆောင်ပြီး decoder ကတော့ text token တစ်ခုချင်းစီကို autoregressively ထုတ်ပေးပါတယ်။ fine-tuning လုပ်တဲ့အခါ မော်ဒယ်ကို audio input ပေါ် အခြေခံပြီး မှန်ကန်တဲ့ text tokens တွေကို ခန့်မှန်းဖို့အတွက် standard sequence-to-sequence loss (cross-entropy ကဲ့သို့) ကို အသုံးပြုပြီး လေ့ကျင့်လေ့ရှိပါတယ်။
+
+Fine-tuned model ကို inference အတွက် အသုံးပြုဖို့ အလွယ်ဆုံးနည်းလမ်းကတော့ `pipeline` အတွင်းမှာပဲ ဖြစ်ပါတယ်။
+
+```python
+from transformers import pipeline
+
+transcriber = pipeline(
+ task="automatic-speech-recognition", model="openai/whisper-base.en"
+)
+transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+# Output: {'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
+```
+
+Automatic speech recognition ကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ Whisper ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [automatic speech recognition guide](https://huggingface.co/docs/transformers/tasks/asr) ကို ကြည့်ရှုပါ။
+
+### Computer vision[[computer-vision]]
+
+အခုတော့ computer vision လုပ်ငန်းတာဝန်တွေဆီ ဆက်သွားရအောင်။ ဒါတွေကတော့ ပုံတွေ ဒါမှမဟုတ် ဗီဒီယိုတွေကနေ မြင်နိုင်တဲ့ အချက်အလက်တွေကို နားလည်ပြီး အနက်ပြန်ခြင်းနဲ့ သက်ဆိုင်ပါတယ်။
+
+computer vision လုပ်ငန်းတာဝန်တွေကို ချဉ်းကပ်ဖို့ နည်းလမ်းနှစ်မျိုးရှိပါတယ်။
+
+1. ပုံတစ်ပုံကို patches အစုအဝေးအဖြစ် ခွဲခြမ်းပြီး Transformer နဲ့ တစ်ပြိုင်နက်တည်း လုပ်ဆောင်ခြင်း။
+2. convolutional layers တွေကို အသုံးပြုပေမယ့် ခေတ်မီ network designs တွေကို လက်ခံထားတဲ့ [ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext) လို ခေတ်မီ CNN တစ်ခုကို အသုံးပြုခြင်း။
+
+> [!TIP]
+> တတိယချဉ်းကပ်ပုံကတော့ Transformers တွေကို convolutions တွေနဲ့ ရောစပ်ခြင်း (ဥပမာ- [Convolutional Vision Transformer](https://huggingface.co/docs/transformers/model_doc/cvt) သို့မဟုတ် [LeViT](https://huggingface.co/docs/transformers/model_doc/levit)) ဖြစ်ပါတယ်။ ဒါတွေကိုတော့ ကျွန်တော်တို့ ဆွေးနွေးမှာ မဟုတ်ပါဘူး၊ ဘာလို့လဲဆိုတော့ ၎င်းတို့ဟာ ဒီနေရာမှာ စစ်ဆေးထားတဲ့ ချဉ်းကပ်ပုံနှစ်ခုကို ပေါင်းစပ်ထားတာပဲ ဖြစ်လို့ပါ။
+
+ViT နဲ့ ConvNeXT တို့နှစ်ခုလုံးကို image classification အတွက် အများအားဖြင့် အသုံးပြုပေမယ့် object detection, segmentation နဲ့ depth estimation လို အခြား vision လုပ်ငန်းတာဝန်တွေအတွက်တော့ DETR, Mask2Former နဲ့ GLPN တို့ကို အသီးသီး ကြည့်ရှုသွားပါမယ်။ ဒီမော်ဒယ်တွေကတော့ အဲဒီလုပ်ငန်းတာဝန်တွေအတွက် ပိုမိုသင့်လျော်ပါတယ်။
+
+### ရုပ်ပုံ အမျိုးအစားခွဲခြားခြင်း (Image classification)[[image-classification]]
+
+ရုပ်ပုံ အမျိုးအစားခွဲခြားခြင်းက အခြေခံကျတဲ့ computer vision လုပ်ငန်းတာဝန်တွေထဲက တစ်ခုပါ။ မတူညီတဲ့ မော်ဒယ် architecture တွေက ဒီပြဿနာကို ဘယ်လိုချဉ်းကပ်လဲဆိုတာ ကြည့်ရအောင်။
+
+ViT နဲ့ ConvNeXT တို့နှစ်ခုလုံးကို image classification အတွက် အသုံးပြုနိုင်ပါတယ်။ အဓိက ကွာခြားချက်ကတော့ ViT က attention mechanism ကို အသုံးပြုပြီး ConvNeXT က convolutions တွေကို အသုံးပြုတာပါပဲ။
+
+[ViT](https://huggingface.co/docs/transformers/model_doc/vit) ဟာ convolutions တွေကို Transformer architecture သန့်သန့်နဲ့ အစားထိုးထားပါတယ်။ မူရင်း Transformer နဲ့ ရင်းနှီးပြီးသားဆိုရင် ViT ကို နားလည်ဖို့ အများကြီး ကျန်တော့မှာ မဟုတ်ပါဘူး။
+
+
+
+  +
+
+
+ViT က မိတ်ဆက်ခဲ့တဲ့ အဓိကပြောင်းလဲမှုက ပုံတွေကို Transformer ကို ဘယ်လို ထည့်သွင်းလဲဆိုတာပါပဲ။
+
+1. ပုံတစ်ပုံကို လေးထောင့်မကျအောင် မထပ်တဲ့ patches တွေအဖြစ် ခွဲခြမ်းပြီး၊ patch တစ်ခုစီကို vector ဒါမှမဟုတ် *patch embedding* အဖြစ် ပြောင်းလဲပါတယ်။ patch embeddings တွေကို convolutional 2D layer ကနေ ထုတ်ပေးပြီး မှန်ကန်တဲ့ input dimensions (base Transformer အတွက် patch embedding တစ်ခုစီအတွက် 768 values) ကို ဖန်တီးပေးပါတယ်။ 224x224 pixel ပုံတစ်ပုံရှိရင် 196 16x16 ပုံ patches တွေအဖြစ် ခွဲခြမ်းနိုင်ပါတယ်။ စာသားကို စကားလုံးတွေအဖြစ် tokenize လုပ်သလိုမျိုး ပုံတစ်ပုံကိုလည်း patches sequence အဖြစ် "tokenize" လုပ်ပါတယ်။
+
+2. *learnable embedding* - အထူး `[CLS]` token - ကို BERT လိုပဲ patch embeddings ရဲ့ အစမှာ ထပ်ထည့်ပါတယ်။ `[CLS]` token ရဲ့ final hidden state ကို တွဲထားတဲ့ classification head ရဲ့ input အဖြစ် အသုံးပြုပြီး အခြား outputs တွေကိုတော့ လျစ်လျူရှုပါတယ်။ ဒီ token က မော်ဒယ်ကို ပုံတစ်ပုံရဲ့ representation ကို ဘယ်လို encode လုပ်ရမယ်ဆိုတာ သင်ယူဖို့ ကူညီပေးပါတယ်။
+
+3. patch နဲ့ learnable embeddings တွေမှာ ထပ်ထည့်ရမယ့် နောက်ဆုံးအရာကတော့ *position embeddings* တွေ ဖြစ်ပါတယ်။ ဘာလို့လဲဆိုတော့ မော်ဒယ်က image patches တွေရဲ့ အစီအစဉ်ကို မသိလို့ပါပဲ။ position embeddings တွေကလည်း learnable ဖြစ်ပြီး patch embeddings တွေနဲ့ အရွယ်အစားတူညီပါတယ်။ နောက်ဆုံးတော့ embeddings အားလုံးကို Transformer encoder ကို ပေးပို့ပါတယ်။
+
+4. output ကို၊ အထူးသဖြင့် `[CLS]` token ပါတဲ့ output ကိုပဲ multilayer perceptron head (MLP) ကို ပေးပို့ပါတယ်။ ViT ရဲ့ pretraining ရည်ရွယ်ချက်ကတော့ classification ပါပဲ။ အခြား classification heads တွေလိုပဲ MLP head က output ကို class labels တွေပေါ်က logits အဖြစ် ပြောင်းလဲပြီး အဖြစ်နိုင်ဆုံး class ကို ရှာဖွေဖို့ cross-entropy loss ကို တွက်ချက်ပါတယ်။
+
+ရုပ်ပုံ အမျိုးအစားခွဲခြားခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ ViT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ [image classification guide](https://huggingface.co/docs/transformers/tasks/image_classification) ကို ကြည့်ရှုပါ။
+
+
+> [!TIP]
+> ViT နဲ့ BERT ကြားက တူညီမှုကို သတိထားမိပါလိမ့်မယ်။ နှစ်ခုလုံးဟာ အလုံးစုံ ကိုယ်စားပြုမှု (overall representation) ကို ဖမ်းယူဖို့ အထူး token (
+[CLS]) ကို အသုံးပြုကြပြီး၊ နှစ်ခုလုံးက ၎င်းတို့ရဲ့ embeddings တွေမှာ position information ကို ထပ်ထည့်ကြကာ၊ နှစ်ခုလုံးက tokens/patches တွေရဲ့ sequence ကို လုပ်ဆောင်ဖို့ Transformer encoder ကို အသုံးပြုကြပါတယ်။
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* **Natural Language Processing (NLP)**: ကွန်ပျူတာတွေ လူသားဘာသာစကားကို နားလည်၊ အဓိပ္ပာယ်ဖော်ပြီး၊ ဖန်တီးနိုင်အောင် လုပ်ဆောင်ပေးတဲ့ Artificial Intelligence (AI) ရဲ့ နယ်ပယ်ခွဲတစ်ခု ဖြစ်ပါတယ်။ ဥပမာအားဖြင့် စာသားခွဲခြမ်းစိတ်ဖြာခြင်း၊ ဘာသာပြန်ခြင်း စသည်တို့ ပါဝင်ပါတယ်။
+* **Large Language Models (LLMs)**: လူသားဘာသာစကားကို နားလည်ပြီး ထုတ်လုပ်ပေးနိုင်တဲ့ အလွန်ကြီးမားတဲ့ Artificial Intelligence (AI) မော်ဒယ်တွေ ဖြစ်ပါတယ်။ ၎င်းတို့ဟာ ဒေတာအမြောက်အမြားနဲ့ သင်ကြားလေ့ကျင့်ထားပြီး စာရေးတာ၊ မေးခွန်းဖြေတာ စတဲ့ ဘာသာစကားဆိုင်ရာ လုပ်ငန်းမျိုးစုံကို လုပ်ဆောင်နိုင်ပါတယ်။
+* **Transformer Models**: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။ ၎င်းတို့ဟာ စာသားတွေထဲက စကားလုံးတွေရဲ့ ဆက်နွယ်မှုတွေကို "attention mechanism" သုံးပြီး နားလည်အောင် သင်ကြားပေးပါတယ်။
+* **Encoder**: Transformer Architecture ရဲ့ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး input data (ဥပမာ- စာသား) ကို နားလည်ပြီး ကိုယ်စားပြုတဲ့ အချက်အလက် (representation) အဖြစ် ပြောင်းလဲပေးပါတယ်။
+* **Decoder**: Transformer Architecture ရဲ့ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး encoder ကနေ ရရှိတဲ့ အချက်အလက် (representation) ကို အသုံးပြုပြီး output data (ဥပမာ- ဘာသာပြန်ထားတဲ့ စာသား) ကို ထုတ်ပေးပါတယ်။
+* **Encoder-Decoder Structure**: Encoder နှင့် Decoder နှစ်ခုစလုံး ပါဝင်သော Transformer architecture တစ်မျိုးဖြစ်ပြီး ဘာသာပြန်ခြင်းကဲ့သို့သော input sequence မှ output sequence တစ်ခုသို့ ပြောင်းလဲခြင်း လုပ်ငန်းများအတွက် အသုံးပြုပါတယ်။
+* **Architecture**: Machine Learning မော်ဒယ်တစ်ခု၏ ဒီဇိုင်း သို့မဟုတ် ဖွဲ့စည်းတည်ဆောက်ပုံ။
+* **Input Data**: မော်ဒယ်တစ်ခုကို ပေးသွင်းသည့် အချက်အလက်များ။
+* **Output**: မော်ဒယ်တစ်ခုမှ ထုတ်ပေးသော ရလဒ်များ။
+* **Predictions**: မော်ဒယ်တစ်ခုမှ ခန့်မှန်းထားသော ရလဒ်များ။
+* **Audio Classification**: အသံနမူနာများကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများအဖြစ် ခွဲခြားခြင်း။
+* **Automatic Speech Recognition (ASR)**: ပြောဆိုသော ဘာသာစကားကို စာသားအဖြစ် အလိုအလျောက် ပြောင်းလဲပေးသည့် နည်းပညာ။
+* **Image Classification**: ရုပ်ပုံများကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများအဖြစ် ခွဲခြားခြင်း။
+* **Object Detection**: ပုံတစ်ပုံအတွင်းရှိ အရာဝတ္ထုများကို ရှာဖွေဖော်ထုတ်ပြီး ၎င်းတို့၏ တည်နေရာကို သတ်မှတ်ခြင်း။
+* **Image Segmentation**: ပုံတစ်ပုံအတွင်းရှိ pixel များကို သီးခြားအရာဝတ္ထုများ သို့မဟုတ် ဒေသများအဖြစ် ခွဲခြားခြင်း။
+* **Depth Estimation**: ပုံတစ်ပုံအတွင်းရှိ အရာဝတ္ထုများ၏ ကင်မရာနှင့် ဝေးကွာသော အကွာအဝေးကို ခန့်မှန်းခြင်း။
+* **Text Classification**: စာသားမှတ်တမ်းများကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများအဖြစ် ခွဲခြားခြင်း။
+* **Token Classification**: စာသား sequence တစ်ခုရှိ token တစ်ခုစီကို label တစ်ခု သတ်မှတ်ပေးခြင်း။
+* **Question Answering**: ပေးထားသော စာသားတစ်ခုအတွင်းမှ မေးခွန်းတစ်ခု၏ အဖြေကို ရှာဖွေခြင်း။
+* **Text Generation**: AI မော်ဒယ်များကို အသုံးပြု၍ လူသားကဲ့သို့သော စာသားအသစ်များ ဖန်တီးခြင်း။
+* **Summarization**: ရှည်လျားသော စာသားတစ်ခုကို အဓိကအချက်အလက်များနှင့် အဓိပ္ပာယ်ကို မပျက်စီးစေဘဲ တိုတောင်းအောင်ပြုလုပ်ခြင်း။
+* **Translation**: စာသားကို ဘာသာစကားတစ်ခုမှ အခြားဘာသာစကားတစ်ခုသို့ အဓိပ္ပာယ်မပျက် ဘာသာပြန်ခြင်း။
+* **Attention Mechanism**: Transformer မော်ဒယ်များတွင် အသုံးပြုသော နည်းစနစ်တစ်ခုဖြစ်ပြီး input sequence ၏ မတူညီသော အစိတ်အပိုင်းများအပေါ် အာရုံစိုက်ပြီး ဆက်နွယ်မှုများကို သင်ယူစေသည်။
+* **Language Models**: လူသားဘာသာစကားကို နားလည်ပြီး ထုတ်ပေးနိုင်ရန် ဒီဇိုင်းထုတ်ထားသော Machine Learning မော်ဒယ်များ။
+* **Tokens**: စာသားတစ်ခု၏ အသေးငယ်ဆုံးသော အစိတ်အပိုင်းများ (ဥပမာ- စကားလုံးများ၊ စာလုံးများ)။
+* **Machine Translation**: ဘာသာစကားတစ်ခုကနေ အခြားဘာသာစကားတစ်ခုကို စာသားတွေ ဒါမှမဟုတ် စကားပြောတွေကို အလိုအလျောက် ဘာသာပြန်ဆိုခြင်း။
+* **Bidirectional Context**: စာသားတစ်ခုကို စကားလုံးတစ်လုံးရဲ့ အရှေ့နဲ့ အနောက် နှစ်ဖက်လုံးကနေ ကြည့်ရှုပြီး နားလည်ခြင်း။
+* **Masked Language Modeling (MLM)**: input tokens အချို့ကို ဖုံးကွယ်ထားပြီး မော်ဒယ်ကို ၎င်းတို့ကို ခန့်မှန်းစေရန် လေ့ကျင့်သော pretraining နည်းလမ်း။
+* **Causal Language Modeling (CLM)**: input sequence ၏ အရင် tokens များပေါ် အခြေခံပြီး နောက် token ကို ခန့်မှန်းစေရန် မော်ဒယ်ကို လေ့ကျင့်သော pretraining နည်းလမ်း။
+* **Named Entity Recognition (NER)**: စာသားထဲက လူအမည်၊ နေရာအမည်၊ အဖွဲ့အစည်းအမည် စတဲ့ သီးခြားအမည်တွေကို ရှာဖွေဖော်ထုတ်ခြင်း။
+* **Part-of-Speech (POS) Tagging**: စာကြောင်းတစ်ခုရှိ စကားလုံးတစ်လုံးစီကို သက်ဆိုင်ရာ သဒ္ဒါအမျိုးအစား (ဥပမာ- နာမ်၊ ကြိယာ၊ နာမဝိသေသန) ကို သတ်မှတ်ပေးခြင်း။
+* **Self-supervised**: ဒေတာများကို လူသားများက လက်ဖြင့် မှတ်သား (annotate) ရန် မလိုအပ်ဘဲ ဒေတာကိုယ်တိုင်ကနေ သင်ယူနိုင်သော လေ့ကျင့်မှုနည်းလမ်း။
+* **Human Annotations**: လူသားများက ဒေတာများကို လက်ဖြင့် မှတ်သားခြင်း သို့မဟုတ် အညွှန်းတပ်ခြင်း။
+* **Transfer Learning**: ကြိုတင်လေ့ကျင့်ထားပြီးသား မော်ဒယ် (pre-trained model) တစ်ခုကို အခြားလုပ်ငန်းတာဝန်အသစ်တစ်ခုအတွက် ပြန်လည်အသုံးပြုခြင်း။
+* **Byte Pair Encoding (BPE)**: စာသားများကို tokens အဖြစ် ပြောင်းလဲရန် အသုံးပြုသော tokenization နည်းလမ်းတစ်ခု။
+* **Token Embedding**: tokens များကို vector ပုံစံဖြင့် ကိုယ်စားပြုခြင်း။
+* **Positional Encodings**: sequence တစ်ခုရှိ token တစ်ခုချင်းစီ၏ တည်နေရာ အချက်အလက်များကို ထပ်ထည့်ပေးခြင်း။
+* **Decoder Blocks**: Transformer decoder ၏ အစိတ်အပိုင်းများ။
+* **Masked Self-Attention**: Transformer decoder တွင် အသုံးပြုသော attention mechanism တစ်မျိုးဖြစ်ပြီး မော်ဒယ်ကို future tokens များသို့ ကြည့်ရှုခွင့်မပြုပါ။
+* **Attention Mask**: attention mechanism တွင် အချို့ tokens များကို လျစ်လျူရှုရန် သို့မဟုတ် ၎င်းတို့၏ score ကို သုညသတ်မှတ်ရန် အသုံးပြုသော mask တစ်ခု။
+* **Language Modeling Head**: မော်ဒယ်၏ hidden states များကို logits အဖြစ် ပြောင်းလဲပေးသည့် layer။
+* **Linear Transformation**: သင်္ချာဆိုင်ရာ အပြောင်းအလဲတစ်ခုဖြစ်ပြီး input vector ကို output vector အဖြစ် ပြောင်းလဲပေးသည်။
+* **Logits**: မော်ဒယ်၏ output မတိုင်မီ raw, unnormalized prediction scores များ။
+* **Cross-Entropy Loss**: classification လုပ်ငန်းတာဝန်များတွင် အသုံးပြုသော loss function တစ်ခုဖြစ်ပြီး မော်ဒယ်၏ ခန့်မှန်းချက်များနှင့် အမှန်တကယ် labels များကြား ခြားနားချက်ကို တိုင်းတာသည်။
+* **WordPiece**: စာသားများကို tokens အဖြစ် ပြောင်းလဲရန် BERT မှ အသုံးပြုသော tokenization နည်းလမ်းတစ်ခု။
+* **`[SEP]` Token**: စာကြောင်းများကြား ခွဲခြားရန် အသုံးပြုသော အထူး token ။
+* **`[CLS]` Token**: စာကြောင်းတစ်ခု၏ အစတွင် ထည့်သွင်းပြီး စာကြောင်းတစ်ခုလုံး၏ ကိုယ်စားပြုမှုကို ဖမ်းယူရန် အသုံးပြုသော အထူး token ။
+* **Segment Embedding**: token တစ်ခုက စာကြောင်းတစ်စုံမှာ ပထမ သို့မဟုတ် ဒုတိယစာကြောင်းမှာ ပါဝင်သည်ကို ဖော်ပြသော embedding။
+* **Feedforward Network**: neural network တစ်ခု၏ အခြေခံ layer တစ်ခု။
+* **Softmax**: multi-class classification တွင် ဖြစ်နိုင်ခြေများကို တွက်ချက်ရန် အသုံးပြုသော activation function တစ်ခု။
+* **Next-Sentence Prediction**: မော်ဒယ်ကို စာကြောင်း B က စာကြောင်း A နောက်က လိုက်သလားဆိုတာ ခန့်မှန်းစေရန် လေ့ကျင့်သော pretraining လုပ်ငန်းတာဝန်။
+* **Sequence Classification Head**: sequence classification လုပ်ငန်းတာဝန်များအတွက် မော်ဒယ်၏ output တွင် ထပ်ထည့်သော linear layer။
+* **Token Classification Head**: token classification လုပ်ငန်းတာဝန်များအတွက် မော်ဒယ်၏ output တွင် ထပ်ထည့်သော linear layer။
+* **Span Classification Head**: question answering လုပ်ငန်းတာဝန်များအတွက် မော်ဒယ်၏ output တွင် ထပ်ထည့်သော linear layer ဖြစ်ပြီး အဖြေ၏ start/end positions များကို ခန့်မှန်းသည်။
+* **Corrupting**: မော်ဒယ်ကို လေ့ကျင့်ရန်အတွက် input data တွင် ရည်ရွယ်ချက်ရှိရှိ အပြောင်းအလဲများ ပြုလုပ်ခြင်း။
+* **Text Infilling**: စာသားအပိုင်းအချို့ကို ဖုံးကွယ်ထားပြီး မော်ဒယ်ကို ၎င်းတို့ကို ခန့်မှန်းစေရန် လေ့ကျင့်သော corruption strategy။
+* **Log-Mel Spectrogram**: အသံအချက်ပြမှုတစ်ခု၏ ကြိမ်နှုန်းနှင့် အချိန်အလိုက် ပြောင်းလဲမှုများကို ပုံရိပ်အဖြစ် ကိုယ်စားပြုခြင်း။
+* **Autoregressively**: အရင်က ခန့်မှန်းထားတဲ့ outputs တွေပေါ် အခြေခံပြီး နောက် output ကို ခန့်မှန်းတဲ့ လုပ်ငန်းစဉ်။
+* **Zero-shot Performance**: မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းအတွက် လေ့ကျင့်ထားခြင်းမရှိဘဲ လုပ်ငန်းအသစ်တစ်ခုကို လုပ်ဆောင်နိုင်စွမ်း။
+* **Weakly Supervised Pretraining**: လူသားမှတ်သားမှု (human annotations) နည်းပါးသော သို့မဟုတ် မရှိသော ဒေတာများကို အသုံးပြု၍ မော်ဒယ်ကို ကြိုတင်လေ့ကျင့်ခြင်း။
+* **Pipeline**: Hugging Face Transformers library တွင် ပါဝင်သော လုပ်ဆောင်ချက်တစ်ခုဖြစ်ပြီး မော်ဒယ်များကို သီးခြားလုပ်ငန်းတာဝန်များအတွက် အသုံးပြုရလွယ်ကူစေရန် ကူညီပေးသည်။
+* **Patches**: ပုံတစ်ပုံကို ခွဲခြမ်းထားသော သေးငယ်သော အစိတ်အပိုင်းများ။
+* **Convolutional 2D Layer**: ပုံများကို လုပ်ဆောင်ရန် အသုံးပြုသော neural network layer တစ်မျိုး။
+* **Multilayer Perceptron (MLP) Head**: classification လုပ်ငန်းတာဝန်များအတွက် အသုံးပြုသော feedforward neural network layer။
+* **Convolutional Neural Network (CNN)**: ပုံများနှင့် ဗီဒီယိုများကို လုပ်ဆောင်ရန် အထူးဒီဇိုင်းထုတ်ထားသော neural network အမျိုးအစားတစ်ခု။
+* **Convolutional Layers**: CNN ၏ အဓိက အစိတ်အပိုင်းများဖြစ်ပြီး ပုံများမှ features များကို ထုတ်ယူရန် အသုံးပြုသည်။
\ No newline at end of file
diff --git a/chapters/my/chapter1/6.mdx b/chapters/my/chapter1/6.mdx
new file mode 100644
index 000000000..9619942e3
--- /dev/null
+++ b/chapters/my/chapter1/6.mdx
@@ -0,0 +1,235 @@
+
+  +
+
+
+parameters နည်းတဲ့ attention matrices တွေကို အသုံးပြုခြင်းအားဖြင့် မော်ဒယ်က sequence length ပိုကြီးတဲ့ inputs တွေကို လက်ခံနိုင်စေပါတယ်။
+
+### Axial positional encodings
+
+[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer) က axial positional encodings တွေကို အသုံးပြုပါတယ်။ ရိုးရာ Transformer မော်ဒယ်တွေမှာ positional encoding E က \\(l\\) by \\(d\\) matrix တစ်ခုဖြစ်ပြီး \\(l\\) က sequence length ဖြစ်ကာ \\(d\\) က hidden state ရဲ့ dimension ဖြစ်ပါတယ်။ စာသားတွေ အလွန်ရှည်လျားရင် ဒီ matrix က အလွန်ကြီးမားပြီး GPU ပေါ်မှာ နေရာအများကြီး ယူနိုင်ပါတယ်။ ဒါကို ဖြေလျှော့ဖို့အတွက် axial positional encodings တွေက အဲဒီကြီးမားတဲ့ matrix E ကို E1 နဲ့ E2 ဆိုတဲ့ သေးငယ်တဲ့ matrices နှစ်ခုအဖြစ် ခွဲထုတ်တာကို ဆိုလိုပါတယ်။ E1 နဲ့ E2 ရဲ့ dimensions တွေကတော့ \\(l_{1} \times d_{1}\\) နဲ့ \\(l_{2} \times d_{2}\\) ဖြစ်ပြီး \\(l_{1} \times l_{2} = l\\) နဲ့ \\(d_{1} + d_{2} = d\\) ဖြစ်ပါတယ်။ (အလျားတွေအတွက် မြှောက်လဒ်နဲ့ဆိုရင် ဒါက အများကြီး သေးငယ်သွားပါလိမ့်မယ်)။ E မှာရှိတဲ့ time step \\(j\\) အတွက် embedding ကို E1 မှာရှိတဲ့ time step \\(j \% l1\\) အတွက် embedding နဲ့ E2 မှာရှိတဲ့ time step \\(j // l1\\) အတွက် embedding တွေကို ပေါင်းစပ်ခြင်းဖြင့် ရရှိပါတယ်။
+
+## နိဂုံးချုပ်[[conclusion]]
+
+ဒီအပိုင်းမှာ ကျွန်တော်တို့ Transformer architectures သုံးမျိုးနဲ့ အထူးပြု attention mechanisms အချို့ကို လေ့လာခဲ့ပါတယ်။ ဒီ architecture တွေရဲ့ ကွာခြားချက်တွေကို နားလည်ထားတာက သင့်ရဲ့ သီးခြား NLP လုပ်ငန်းတာဝန်အတွက် မှန်ကန်တဲ့ မော်ဒယ်ကို ရွေးချယ်ဖို့အတွက် အရေးကြီးပါတယ်။
+
+သင်တန်းမှာ ဆက်လက်လုပ်ဆောင်သွားတဲ့အခါ ဒီမတူညီတဲ့ architecture တွေနဲ့ လက်တွေ့အတွေ့အကြုံတွေ ရရှိလာမှာဖြစ်ပြီး သင့်ရဲ့ သီးခြားလိုအပ်ချက်တွေအတွက် ဘယ်လို fine-tune လုပ်ရမယ်ဆိုတာကို သင်ယူရမှာ ဖြစ်ပါတယ်။ နောက်အပိုင်းမှာတော့ ဒီမော်ဒယ်တွေမှာ ရှိနေတဲ့ ကန့်သတ်ချက်တွေနဲ့ ဘက်လိုက်မှုအချို့ကို လေ့လာသွားမှာဖြစ်ပြီး ၎င်းတို့ကို အသုံးပြုတဲ့အခါ သတိထားသင့်တဲ့ အချက်တွေပဲ ဖြစ်ပါတယ်။
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* ** Architecture**: ကွန်ပျူတာစနစ်တစ်ခု၊ ဆော့ဖ်ဝဲလ်တစ်ခု သို့မဟုတ် မော်ဒယ်တစ်ခု၏ အစိတ်အပိုင်းများ စုစည်းပုံနှင့် ၎င်းတို့အချင်းချင်း ဆက်စပ်လုပ်ဆောင်ပုံကို ဖော်ပြသည့် အခြေခံဒီဇိုင်း သို့မဟုတ် ဖွဲ့စည်းပုံ။
+* **Transformer Architecture**: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။ ၎င်းတို့ဟာ စာသားတွေထဲက စကားလုံးတွေရဲ့ ဆက်နွယ်မှုတွေကို "attention mechanism" သုံးပြီး နားလည်အောင် သင်ကြားပေးပါတယ်။
+* **Encoder-only**: Transformer မော်ဒယ်ရဲ့ encoder အစိတ်အပိုင်းကိုသာ အသုံးပြုထားသော architecture အမျိုးအစား။ စာသားနားလည်မှုလုပ်ငန်းများအတွက် သင့်တော်သည်။
+* **Decoder-only**: Transformer မော်ဒယ်ရဲ့ decoder အစိတ်အပိုင်းကိုသာ အသုံးပြုထားသော architecture အမျိုးအစား။ စာသားဖန်တီးမှုလုပ်ငန်းများအတွက် သင့်တော်သည်။
+* **Encoder-Decoder (Sequence-to-sequence)**: Transformer မော်ဒယ်ရဲ့ encoder နှင့် decoder နှစ်ခုစလုံးကို အသုံးပြုထားသော architecture အမျိုးအစား။ စာသားတစ်ခုကို အခြားစာသားတစ်ခုအဖြစ် ပြောင်းလဲခြင်းလုပ်ငန်းများ (ဥပမာ- ဘာသာပြန်ခြင်း) အတွက် သင့်တော်သည်။
+* **Sentence Classification**: စာကြောင်းတစ်ခုလုံး၏ အဓိပ္ပာယ် သို့မဟုတ် ရည်ရွယ်ချက်ကို အမျိုးအစားခွဲခြားခြင်း (ဥပမာ- စိတ်ခံစားမှု၊ ခေါင်းစဉ်)။
+* **Named Entity Recognition (NER)**: စာသားထဲက လူအမည်၊ နေရာအမည်၊ အဖွဲ့အစည်းအမည် စတဲ့ သီးခြားအမည်တွေကို ရှာဖွေဖော်ထုတ်ခြင်း။
+* **Word Classification**: စာကြောင်းတစ်ခုရှိ စကားလုံးတစ်လုံးချင်းစီကို ၎င်း၏ သဒ္ဒါ သို့မဟုတ် အခြားအဓိပ္ပာယ်အရ အမျိုးအစားခွဲခြားခြင်း။
+* **Extractive Question Answering**: ပေးထားသော စာသားအပိုင်းအစမှ မေးခွန်း၏ အဖြေကို တိုက်ရိုက်ထုတ်ယူခြင်း။
+* **Bi-directional Attention**: မော်ဒယ်က စာသားတစ်ခုလုံး၏ အကြောင်းအရာ (context) ကို ရှေ့ဘက်နှင့် နောက်ဘက် နှစ်ဖက်စလုံးမှ ကြည့်ရှုနားလည်နိုင်ခြင်း။
+* **Auto-encoding Models**: စာသားကို ဖျက်ဆီးပြီးနောက် မူလစာသားကို ပြန်လည်တည်ဆောက်ရန် သင်ကြားထားသော မော်ဒယ်များ။
+* **BERT (Bidirectional Encoder Representations from Transformers)**: Google မှ တီထွင်ထားသော encoder-only Transformer မော်ဒယ်။
+* **DistilBERT**: BERT မော်ဒယ်ကို သေးငယ်ပြီး ပိုမိုမြန်ဆန်အောင် ပြုလုပ်ထားသော မော်ဒယ်။
+* **Text Generation**: AI မော်ဒယ်များကို အသုံးပြု၍ လူသားကဲ့သို့သော စာသားအသစ်များ ဖန်တီးခြင်း။
+* **Auto-regressive Models**: နောက်ထပ် token ကို ခန့်မှန်းရန် ယခင် tokens များကိုသာ အသုံးပြု၍ စာသားများကို တစ်ကြိမ်လျှင် token တစ်ခုချင်းစီ ဖန်တီးသော မော်ဒယ်များ။
+* **GPT (Generative Pre-trained Transformer)**: OpenAI မှ တီထွင်ထားသော decoder-only Transformer မော်ဒယ်။
+* **Llama**: Meta မှ တီထွင်ထားသော decoder-only Large Language Model (LLM) အမျိုးအစား။
+* **Gemma**: Google မှ တီထွင်ထားသော decoder-only Large Language Model (LLM) အမျိုးအစား။
+* **DeepSeek**: DeepSeek AI မှ တီထွင်ထားသော decoder-only Large Language Model (LLM) အမျိုးအစား။
+* **Pretraining**: မော်ဒယ်ကို များပြားလှသော အထွေထွေဒေတာများဖြင့် အစောပိုင်းသင်ကြားမှု။
+* **Instruction Tuning**: မော်ဒယ်ကို သီးခြားညွှန်ကြားချက်များကို လိုက်နာပြီး အထောက်အကူဖြစ်စေသော တုံ့ပြန်မှုများ ထုတ်လုပ်ရန် fine-tune လုပ်ခြင်း။
+* **Token**: စာသားကို ပိုင်းခြားထားသော အသေးငယ်ဆုံးယူနစ် (ဥပမာ- စကားလုံး၊ စာလုံးအစိတ်အပိုင်း)။
+* **Summarization**: စာသားရှည်များကို အကျဉ်းချုပ်ဖော်ပြခြင်း။
+* **Translation**: ဘာသာစကားတစ်ခုမှ အခြားတစ်ခုသို့ စာသားများကို ပြောင်းလဲခြင်း။
+* **Generative Question Answering**: မေးခွန်း၏ အဖြေကို ပေးထားသော အကြောင်းအရာ (context) အပေါ် အခြေခံ၍ စာသားအသစ်များ ဖန်တီးခြင်းဖြင့် ထုတ်ပေးခြင်း။
+* **BART (Bidirectional and Auto-Regressive Transformers)**: Encoder-Decoder Transformer မော်ဒယ်တစ်မျိုး။
+* **T5 (Text-to-Text Transfer Transformer)**: Encoder-Decoder Transformer မော်ဒယ်တစ်မျိုးဖြစ်ပြီး လုပ်ငန်းတာဝန်အားလုံးကို "text-to-text" ပုံစံဖြင့် ဖြေရှင်းရန် ဒီဇိုင်းထုတ်ထားသည်။
+* **Marian**: အဓိကအားဖြင့် machine translation အတွက် အသုံးပြုသော encoder-decoder မော်ဒယ်။
+* **mBART**: Multilingual BART (ဘာသာစကားမျိုးစုံအတွက် BART)။
+* **Data-to-text Generation**: ဖွဲ့စည်းထားသော ဒေတာများကို သဘာဝဘာသာစကားစာသားအဖြစ် ပြောင်းလဲခြင်း။
+* **Grammar Correction**: စာသားရှိ သဒ္ဒါအမှားများကို ပြင်ဆင်ခြင်း။
+* **Conversational AI**: လူသားများနှင့် သဘာဝဘာသာစကားဖြင့် အပြန်အလှန်ပြောဆိုနိုင်သော AI စနစ်များ။
+* **RoBERTa**: BERT ကို ပိုမိုကောင်းမွန်အောင် လေ့ကျင့်ထားသော encoder-only မော်ဒယ်။
+* **Attention Matrix**: Transformer မော်ဒယ်များတွင် အသုံးပြုသော matrix တစ်ခုဖြစ်ပြီး input sequence အတွင်းရှိ token များအချင်းချင်း မည်မျှဆက်စပ်နေသည်ကို ဖော်ပြသည်။
+* **Computational Bottleneck**: စနစ်တစ်ခု၏ စွမ်းဆောင်ရည်ကို ကန့်သတ်ထားသော အရင်းအမြစ် သို့မဟုတ် လုပ်ငန်းစဉ်။
+* **Sparse Attention**: attention matrix ၏ အရေးမကြီးသော အစိတ်အပိုင်းများကို လျစ်လျူရှုခြင်းဖြင့် တွက်ချက်မှု ထိရောက်အောင် ပြုလုပ်ထားသော attention mechanism အမျိုးအစား။
+* **LSH (Locality Sensitive Hashing) Attention**: Reformer မော်ဒယ်တွင် အသုံးပြုသော attention အမျိုးအစားဖြစ်ပြီး ဆင်တူသော query နှင့် key များကို ရှာဖွေရန် hash function များကို အသုံးပြုသည်။
+* **Longformer**: ရှည်လျားသော input sequences များကို ကိုင်တွယ်နိုင်ရန် local attention နှင့် global attention တို့ကို ပေါင်းစပ်အသုံးပြုထားသော Transformer မော်ဒယ်။
+* **Local Attention**: ပေးထားသော token တစ်ခုအတွက် အနီးအနားရှိ tokens များကိုသာ အာရုံစိုက်သော attention mechanism။
+* **Receptive Field**: neural network layer တစ်ခု၏ output ယူနစ်တစ်ခုကို လွှမ်းမိုးသော input data ၏ အရွယ်အစား။
+* **Global Attention**: အချို့သော input tokens များအတွက် input sequence ရှိ tokens အားလုံးကို အာရုံစိုက်ခွင့်ပြုသော attention mechanism။
+* **Axial Positional Encodings**: ရှည်လျားသော sequences များအတွက် positional encoding ကို ပိုမိုထိရောက်အောင် ပြုလုပ်ရန် matrix တစ်ခုကို သေးငယ်သော matrices နှစ်ခုအဖြစ် ခွဲထုတ်ခြင်းနည်းလမ်း။
+* **Hidden State**: Transformer မော်ဒယ်များတွင် layer တစ်ခုမှ အခြားတစ်ခုသို့ လက်ဆင့်ကမ်းပေးသော အတွင်းပိုင်း ကိုယ်စားပြုအချက်အလက်။
+* **Dimension**: vector သို့မဟုတ် matrix တစ်ခု၏ အတိုင်းအတာအရေအတွက်။
\ No newline at end of file
diff --git a/chapters/my/chapter1/7.mdx b/chapters/my/chapter1/7.mdx
new file mode 100644
index 000000000..c51de1dd1
--- /dev/null
+++ b/chapters/my/chapter1/7.mdx
@@ -0,0 +1,287 @@
+
+
+# အမှတ်မပေးသော Quiz[[ungraded-quiz]]
+
+
+ +
+နောက်ထပ် token ကို ခန့်မှန်းဖို့ အသက်ဆိုင်ဆုံး စကားလုံးတွေကို ဖော်ထုတ်တဲ့ ဒီလုပ်ငန်းစဉ်ဟာ အံ့သြစရာကောင်းလောက်အောင် ထိရောက်မှုရှိတယ်ဆိုတာ သက်သေပြခဲ့ပြီးပါပြီ။ LLMs တွေ လေ့ကျင့်တဲ့ အခြေခံမူ—နောက်ထပ် token ကို ခန့်မှန်းခြင်း—ဟာ BERT နဲ့ GPT-2 ကတည်းက ယေဘုယျအားဖြင့် အတူတူပဲ ရှိခဲ့ပေမယ့်၊ neural network တွေကို ချဲ့ထွင်ရာမှာနဲ့ attention mechanism ကို ပိုမိုရှည်လျားတဲ့ sequence တွေအတွက် ကုန်ကျစရိတ်သက်သာစွာ အလုပ်လုပ်နိုင်အောင် လုပ်ဆောင်ရာမှာ သိသိသာသာ တိုးတက်မှုတွေ ရှိခဲ့ပါတယ်။
+
+> [!TIP]
+> အတိုချုပ်ပြောရရင် attention mechanism ဟာ LLMs တွေ ဆက်စပ်မှုရှိပြီး အကြောင်းအရာကို နားလည်တဲ့ စာသားတွေကို ထုတ်လုပ်နိုင်စေဖို့အတွက် အဓိကသော့ချက် ဖြစ်ပါတယ်။ ဒါက ခေတ်မီ LLMs တွေကို ယခင်မျိုးဆက် ဘာသာစကားမော်ဒယ်တွေနဲ့ ကွဲပြားစေပါတယ်။
+
+### Context Length နဲ့ Attention Span[[context-length-and-attention-span]]
+
+Attention ကို နားလည်ပြီးပြီဆိုတော့ LLM တစ်ခုက ဘယ်လောက်အထိ context ကို ကိုင်တွယ်နိုင်မလဲဆိုတာကို ဆက်လေ့လာကြည့်ရအောင်။ ဒါက model ရဲ့ 'attention span' လို့ခေါ်တဲ့ context length နဲ့ သက်ဆိုင်ပါတယ်။
+
+Context length ဆိုတာ LLM တစ်ခုက တစ်ကြိမ်တည်း လုပ်ဆောင်နိုင်တဲ့ အများဆုံး token (စကားလုံး ဒါမှမဟုတ် စကားလုံးရဲ့ အစိတ်အပိုင်း) အရေအတွက်ကို ရည်ညွှန်းပါတယ်။ ဒါကို model ရဲ့ အလုပ်လုပ်တဲ့ မှတ်ဉာဏ် (working memory) ရဲ့ အရွယ်အစားလို့ တွေးကြည့်နိုင်ပါတယ်။
+
+ဒီစွမ်းရည်တွေဟာ လက်တွေ့ကျတဲ့ အချက်အလက်အချို့ကြောင့် ကန့်သတ်ထားပါတယ်-
+- Model ရဲ့ architecture နဲ့ အရွယ်အစား
+- ရရှိနိုင်တဲ့ ကွန်ပျူတာ အရင်းအမြစ်များ
+- input နဲ့ ထုတ်လိုတဲ့ output ရဲ့ ရှုပ်ထွေးမှု
+
+စံပြကမ္ဘာမှာဆိုရင် မော်ဒယ်ကို ကန့်သတ်ချက်မရှိတဲ့ context တွေ ထည့်ပေးနိုင်ပေမယ့်၊ hardware ကန့်သတ်ချက်တွေနဲ့ ကွန်ပျူတာ ကုန်ကျစရိတ်တွေကြောင့် ဒါက လက်တွေ့မကျပါဘူး။ ဒါကြောင့် ကန့်သတ်ချက်နဲ့ ထိရောက်မှုကို မျှတအောင် ထိန်းညှိဖို့အတွက် မတူညီတဲ့ context length တွေနဲ့ မော်ဒယ်တွေကို ဒီဇိုင်းထုတ်ထားတာ ဖြစ်ပါတယ်။
+
+> [!TIP]
+> Context length ဆိုတာ မော်ဒယ်က အဖြေတစ်ခုကို ထုတ်လုပ်တဲ့အခါ တစ်ကြိမ်တည်းမှာ ထည့်သွင်းစဉ်းစားနိုင်တဲ့ အများဆုံး token အရေအတွက် ဖြစ်ပါတယ်။
+
+### Prompting ပညာ[[the-art-of-prompting]]
+
+ကျွန်တော်တို့ LLMs တွေကို အချက်အလက်တွေ ပေးပို့တဲ့အခါ၊ LLM ရဲ့ ထုတ်လုပ်မှုကို လိုချင်တဲ့ output ဆီ ဦးတည်နိုင်အောင် input ကို ပုံစံချပါတယ်။ ဒါကို _prompting_ လို့ ခေါ်ပါတယ်။
+
+LLMs တွေက အချက်အလက်တွေကို ဘယ်လိုလုပ်ဆောင်တယ်ဆိုတာ နားလည်ခြင်းက ပိုကောင်းတဲ့ prompts တွေကို ဖန်တီးနိုင်ဖို့ ကူညီပေးပါတယ်။ မော်ဒယ်ရဲ့ အဓိကတာဝန်က input token တစ်ခုစီရဲ့ အရေးပါမှုကို ခွဲခြမ်းစိတ်ဖြာပြီး နောက်ထပ် token ကို ခန့်မှန်းဖို့ဖြစ်တာကြောင့်၊ သင်ရဲ့ input sequence ရဲ့ စကားလုံးဖွဲ့စည်းပုံက အရေးကြီးလာပါတယ်။
+
+> [!TIP]
+> Prompt ကို သေချာဒီဇိုင်းထုတ်ခြင်းက **LLM ရဲ့ ထုတ်လုပ်မှုကို လိုချင်တဲ့ output ဆီ ဦးတည်စေရန် ပိုမိုလွယ်ကူစေပါတယ်**။
+
+## နှစ်ဆင့်ပါသော Inference လုပ်ငန်းစဉ်[[the-two-phase-inference-process]]
+
+အခြေခံအစိတ်အပိုင်းတွေကို ကျွန်တော်တို့ နားလည်ပြီးပြီဆိုတော့ LLMs တွေက စာသားတွေကို ဘယ်လိုထုတ်လုပ်တယ်ဆိုတာကို နက်ရှိုင်းစွာ လေ့လာကြည့်ရအောင်။ လုပ်ငန်းစဉ်ကို အဓိက အဆင့်နှစ်ဆင့်ခွဲနိုင်ပါတယ်- prefill နဲ့ decode ပါ။ ဒီအဆင့်တွေက ပူးပေါင်းပြီး အလုပ်လုပ်ကြပြီး၊ စာသားတွေ ဆက်စပ်မှုရှိအောင် ထုတ်လုပ်ရာမှာ အရေးကြီးတဲ့ အခန်းကဏ္ဍတွေကနေ ပါဝင်ပါတယ်။
+
+### Prefill အဆင့်[[the-prefill-phase]]
+
+Prefill အဆင့်ဟာ ချက်ပြုတ်ရာမှာ ပြင်ဆင်မှုအဆင့်နဲ့ တူပါတယ်။ ဒီအဆင့်မှာ ကနဦးပါဝင်ပစ္စည်းအားလုံးကို လုပ်ဆောင်ပြီး အသင့်ပြင်ဆင်ပါတယ်။ ဒီအဆင့်မှာ အဓိကအချက် (၃) ချက် ပါဝင်ပါတယ်-
+
+1. **Tokenization**: input စာသားကို tokens တွေအဖြစ် ပြောင်းလဲခြင်း (ဒါတွေကို မော်ဒယ်က နားလည်တဲ့ အခြေခံ building blocks တွေလို့ တွေးကြည့်နိုင်ပါတယ်)
+2. **Embedding Conversion**: ဒီ tokens တွေကို ၎င်းတို့ရဲ့ အဓိပ္ပာယ်ကို ဖမ်းယူထားတဲ့ ဂဏန်းဆိုင်ရာ ကိုယ်စားပြုမှု (numerical representations) တွေအဖြစ် ပြောင်းလဲခြင်း
+3. **ကနဦး လုပ်ဆောင်ခြင်း (Initial Processing)**: context ကို ပြည့်ပြည့်စုံစုံ နားလည်မှု ဖန်တီးဖို့အတွက် ဒီ embeddings တွေကို model ရဲ့ neural network တွေကနေတဆင့် လုပ်ဆောင်ခြင်း
+
+ဒီအဆင့်ဟာ input tokens အားလုံးကို တစ်ကြိမ်တည်း လုပ်ဆောင်ဖို့ လိုအပ်တာကြောင့် ကွန်ပျူတာအရင်းအမြစ်များစွာ လိုအပ်ပါတယ်။ ဒါကို အဖြေမရေးခင် စာပိုဒ်တစ်ခုလုံးကို ဖတ်ပြီး နားလည်တာနဲ့ တူတယ်လို့ တွေးကြည့်နိုင်ပါတယ်။
+
+အောက်က interactive playground မှာ မတူညီတဲ့ tokenizers တွေနဲ့ စမ်းသပ်ကြည့်နိုင်ပါတယ်-
+
+
+
+### Decode အဆင့်[[the-decode-phase]]
+
+Prefill အဆင့်က input ကို လုပ်ဆောင်ပြီးနောက်မှာတော့ decode အဆင့်ကို ရောက်ရှိလာပါပြီ - ဒီနေရာမှာ စာသားထုတ်လုပ်ခြင်း အမှန်တကယ် ဖြစ်လာပါတယ်။ မော်ဒယ်က တစ်ကြိမ်ကို token တစ်ခုစီ ထုတ်လုပ်ပြီး၊ ဒါကို autoregressive process (အသစ်ထွက်လာတဲ့ token တိုင်းက ယခင် tokens အားလုံးပေါ် မူတည်ပါတယ်) လို့ ခေါ်ပါတယ်။
+
+Decode အဆင့်မှာ အသစ်ထွက်လာတဲ့ token တိုင်းအတွက် အဓိကအချက်များစွာ ပါဝင်ပါတယ်-
+1. **Attention Computation**: context ကို နားလည်ဖို့ ယခင် tokens အားလုံးကို ပြန်ကြည့်ခြင်း
+2. **ဖြစ်နိုင်ခြေ တွက်ချက်ခြင်း (Probability Calculation)**: ဖြစ်နိုင်ခြေရှိတဲ့ နောက်ထပ် token တစ်ခုစီရဲ့ ဖြစ်နိုင်ခြေကို ဆုံးဖြတ်ခြင်း
+3. **Token ရွေးချယ်ခြင်း (Token Selection)**: ဒီဖြစ်နိုင်ခြေတွေအပေါ် အခြေခံပြီး နောက်ထပ် token ကို ရွေးချယ်ခြင်း
+4. **ဆက်လက်လုပ်ဆောင်မှု စစ်ဆေးခြင်း (Continuation Check)**: ဆက်လုပ်မလား ဒါမှမဟုတ် ထုတ်လုပ်မှုကို ရပ်မလားဆိုတာကို ဆုံးဖြတ်ခြင်း
+
+ဒီအဆင့်ဟာ မော်ဒယ်က ယခင်ထုတ်လုပ်ထားတဲ့ tokens အားလုံးနဲ့ ၎င်းတို့ရဲ့ ဆက်စပ်မှုတွေကို မှတ်ထားဖို့ လိုအပ်တာကြောင့် memory-intensive ဖြစ်ပါတယ်။
+
+## Sampling နည်းဗျူဟာများ[[sampling-strategies]]
+
+မော်ဒယ်က စာသားတွေကို ဘယ်လိုထုတ်လုပ်တယ်ဆိုတာ နားလည်ပြီးပြီဆိုတော့ ဒီထုတ်လုပ်မှု လုပ်ငန်းစဉ်ကို ဘယ်လိုထိန်းချုပ်နိုင်မလဲဆိုတာကို လေ့လာကြည့်ရအောင်။ စာရေးဆရာတစ်ဦးက ပိုမိုတီထွင်ဖန်တီးမှုရှိမလား ဒါမှမဟုတ် ပိုမိုတိကျမလားဆိုတာ ရွေးချယ်နိုင်သလိုပဲ၊ ကျွန်တော်တို့လည်း မော်ဒယ်က tokens တွေကို ဘယ်လိုရွေးချယ်တယ်ဆိုတာကို ချိန်ညှိနိုင်ပါတယ်။
+
+ဒီ Space မှာ SmolLM2 နဲ့ အခြေခံ decoding လုပ်ငန်းစဉ်ကို ကိုယ်တိုင် အပြန်အလှန်လုပ်ဆောင်နိုင်ပါတယ် (မှတ်ထားပါ၊ ဒီမော်ဒယ်အတွက် **<|im_end|>** ဖြစ်တဲ့ **EOS** token ကို မရောက်မချင်း decode လုပ်ပါလိမ့်မယ်)-
+
+
+
+### Token ရွေးချယ်မှုကို နားလည်ခြင်း- ဖြစ်နိုင်ခြေများမှ Token ရွေးချယ်မှုများဆီသို့[[understanding-token-selection-from-probabilities-to-token-choices]]
+
+မော်ဒယ်က နောက်ထပ် token ကို ရွေးချယ်ဖို့ လိုအပ်တဲ့အခါ၊ ၎င်းရဲ့ ဝေါဟာရ (vocabulary) ထဲက စကားလုံးတိုင်းအတွက် ကနဦး ဖြစ်နိုင်ခြေ (logits) တွေနဲ့ စတင်ပါတယ်။ ဒါပေမယ့် ဒီဖြစ်နိုင်ခြေတွေကို လက်တွေ့ရွေးချယ်မှုတွေအဖြစ် ဘယ်လိုပြောင်းလဲမလဲ။ လုပ်ငန်းစဉ်ကို ခွဲခြမ်းစိတ်ဖြာကြည့်ရအောင်-
+
+
+
+1. **Raw Logits**: ဒါတွေကို မော်ဒယ်ရဲ့ နောက်ထပ် ဖြစ်နိုင်ခြေရှိတဲ့ စကားလုံးတိုင်းအတွက် ကနဦး ခံစားချက်တွေလို့ တွေးကြည့်ပါ။
+2. **Temperature Control**: တီထွင်ဖန်တီးမှု ခလုတ်လိုပါပဲ - တန်ဖိုးမြင့်လေ (>1.0) ရွေးချယ်မှုတွေ ပိုမိုကျပန်းဆန်ပြီး ဖန်တီးမှုရှိလေ၊ တန်ဖိုးနိမ့်လေ (<1.0) ပိုမိုအာရုံစိုက်ပြီး တိကျလေ ဖြစ်ပါတယ်။
+3. **Top-p (Nucleus) Sampling**: ဖြစ်နိုင်ခြေရှိတဲ့ စကားလုံးအားလုံးကို ထည့်သွင်းစဉ်းစားမယ့်အစား၊ ကျွန်တော်တို့ ရွေးချယ်ထားတဲ့ ဖြစ်နိုင်ခြေ ကန့်သတ်ချက် (ဥပမာ- ထိပ်ဆုံး 90%) နဲ့ ကိုက်ညီတဲ့ အဖြစ်နိုင်ဆုံး စကားလုံးတွေကိုပဲ ကြည့်ပါတယ်။
+4. **Top-k Filtering**: အခြားနည်းလမ်းတစ်ခုဖြစ်ပြီး၊ ကျွန်တော်တို့ဟာ အဖြစ်နိုင်ဆုံး နောက်ထပ်စကားလုံး k လုံးကိုပဲ ထည့်သွင်းစဉ်းစားပါတယ်။
+
+### ထပ်ခါတလဲလဲဖြစ်ခြင်းကို ထိန်းချုပ်ခြင်း- Output ကို လတ်ဆတ်နေစေခြင်း[[managing-repetition-keeping-output-fresh]]
+
+LLMs တွေနဲ့ အဖြစ်များတဲ့ စိန်ခေါ်မှုတစ်ခုကတော့ သူတို့ကိုယ်သူတို့ ထပ်ခါတလဲလဲပြောတတ်တဲ့ သဘောရှိခြင်းပါ - အချက်အလက်တွေကို အကြိမ်ကြိမ် ပြန်ပြောတတ်တဲ့ စကားပြောသူတစ်ဦးနဲ့ တူပါတယ်။ ဒါကို ဖြေရှင်းဖို့အတွက် ကျွန်တော်တို့ဟာ ပြစ်ဒဏ်နှစ်မျိုးကို အသုံးပြုပါတယ်-
+
+1. **Presence Penalty**: ယခင်က ပါဝင်ခဲ့ဖူးတဲ့ token တစ်ခုစီအတွက် အကြိမ်အရေအတွက် ဘယ်လောက်ပဲ ဖြစ်ပါစေ၊ သတ်မှတ်ထားတဲ့ ပြစ်ဒဏ်တစ်ခုကို ပေးပါတယ်။ ဒါက မော်ဒယ်ကို တူညီတဲ့ စကားလုံးတွေကို ထပ်ခါတလဲလဲ အသုံးမပြုမိအောင် ကူညီပေးပါတယ်။
+2. **Frequency Penalty**: token တစ်ခု ဘယ်နှစ်ကြိမ် အသုံးပြုပြီးပြီလဲဆိုတာပေါ်မူတည်ပြီး တိုးလာတဲ့ ပြစ်ဒဏ်တစ်ခုပါ။ စကားလုံးတစ်ခု ပိုမိုပါဝင်လေ၊ နောက်ထပ်ရွေးချယ်ခံရဖို့ အခွင့်အလမ်း နည်းလေ ဖြစ်ပါတယ်။
+
+
+
+ဒီပြစ်ဒဏ်တွေကို token ရွေးချယ်မှု လုပ်ငန်းစဉ်ရဲ့ အစောပိုင်းမှာ လိမ်းကျံပြီး၊ အခြား sampling နည်းဗျူဟာတွေကို အသုံးမပြုခင် ကနဦး ဖြစ်နိုင်ခြေတွေကို ချိန်ညှိပေးပါတယ်။ ဒါတွေကို မော်ဒယ်ကို ဝေါဟာရအသစ်တွေ ရှာဖွေဖို့ နူးညံ့စွာ တွန်းအားပေးတာနဲ့ တူတယ်လို့ တွေးကြည့်နိုင်ပါတယ်။
+
+### ထုတ်လုပ်မှု အရှည်ကို ထိန်းချုပ်ခြင်း- ကန့်သတ်ချက်များ သတ်မှတ်ခြင်း[[controlling-generation-length-setting-boundaries]]
+
+ကောင်းမွန်တဲ့ ပုံပြင်တစ်ခုမှာ သင့်လျော်တဲ့ စည်းမျဉ်းစည်းကမ်းနဲ့ အရှည်ရှိဖို့ လိုအပ်သလိုပဲ၊ ကျွန်တော်တို့ရဲ့ LLM က ဘယ်လောက်များများ စာသားထုတ်လုပ်မလဲဆိုတာကို ထိန်းချုပ်ဖို့ နည်းလမ်းတွေ လိုအပ်ပါတယ်။ ဒါက လက်တွေ့အသုံးချမှုတွေအတွက် အရေးကြီးပါတယ် - tweet တစ်ခုလောက်တိုတဲ့ အဖြေဖြစ်စေ၊ blog post အပြည့်အစုံဖြစ်စေပေါ့။
+
+ထုတ်လုပ်မှု အရှည်ကို နည်းလမ်းများစွာနဲ့ ထိန်းချုပ်နိုင်ပါတယ်-
+1. **Token Limits**: အနည်းဆုံးနဲ့ အများဆုံး token အရေအတွက်ကို သတ်မှတ်ခြင်း
+2. **Stop Sequences**: ထုတ်လုပ်မှု ပြီးဆုံးကြောင်း အချက်ပြတဲ့ သီးခြားပုံစံတွေကို သတ်မှတ်ခြင်း
+3. **End-of-Sequence Detection**: မော်ဒယ်ကို သူ့ဘာသာသူ အဖြေကို သဘာဝအတိုင်း နိဂုံးချုပ်စေခြင်း
+
+ဥပမာအားဖြင့်၊ ကျွန်တော်တို့ဟာ စာပိုဒ်တစ်ပိုဒ်တည်းကိုပဲ ထုတ်လုပ်ချင်တယ်ဆိုရင် အများဆုံး tokens 100 သတ်မှတ်ပြီး "\n\n" ကို stop sequence အဖြစ် အသုံးပြုနိုင်ပါတယ်။ ဒါက ကျွန်တော်တို့ရဲ့ output က ရည်ရွယ်ချက်နဲ့ ကိုက်ညီတဲ့ အရွယ်အစားနဲ့ အာရုံစိုက်မှု ရှိစေပါတယ်။
+
+
+
+### Beam Search: ပိုမိုကောင်းမွန်တဲ့ ဆက်စပ်မှုအတွက် ကြိုတင်မျှော်မှန်းခြင်း[[beam-search-looking-ahead-for-better-coherence]]
+
+ကျွန်တော်တို့ ခုထိ ဆွေးနွေးခဲ့တဲ့ နည်းဗျူဟာတွေက တစ်ကြိမ်ကို token တစ်ခုစီ ဆုံးဖြတ်ချက်ချပေမယ့်၊ beam search ကတော့ ပိုမိုပြည့်စုံတဲ့ ချဉ်းကပ်မှုကို လုပ်ဆောင်ပါတယ်။ ခြေလှမ်းတိုင်းမှာ ရွေးချယ်မှုတစ်ခုတည်းကိုပဲ လုပ်ဆောင်မယ့်အစား၊ ၎င်းဟာ ကစားသမားတစ်ဦးက အရှေ့ကို အကြိမ်ကြိမ် တွေးတောသလိုမျိုး ဖြစ်နိုင်ခြေရှိတဲ့ လမ်းကြောင်းပေါင်းစုံကို တစ်ပြိုင်နက်တည်း ရှာဖွေပါတယ်။
+
+
+
+ဒါက ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို ကြည့်ရအောင်-
+1. ခြေလှမ်းတိုင်းမှာ၊ ဖြစ်နိုင်ခြေရှိတဲ့ candidate sequence အများအပြားကို ထိန်းသိမ်းထားပါတယ် (များသောအားဖြင့် ၅-၁၀ ခု)။
+2. candidate တစ်ခုစီအတွက်၊ နောက်ထပ် token ရဲ့ ဖြစ်နိုင်ခြေတွေကို တွက်ချက်ပါတယ်။
+3. sequence တွေနဲ့ နောက်ထပ် token တွေရဲ့ အဖြစ်နိုင်ဆုံး ပေါင်းစပ်မှုတွေကိုသာ ထိန်းသိမ်းထားပါတယ်။
+4. လိုချင်တဲ့ အရှည် ဒါမှမဟုတ် ရပ်တန့်တဲ့အခြေအနေကို ရောက်တဲ့အထိ ဒီလုပ်ငန်းစဉ်ကို ဆက်လုပ်ပါတယ်။
+5. အလုံးစုံ ဖြစ်နိုင်ခြေအမြင့်ဆုံးရှိတဲ့ sequence ကို ရွေးချယ်ပါတယ်။
+
+ဒီနေရာမှာ beam search ကို ပုံမှန်ကြည့်ရှုနိုင်ပါတယ်-
+
+
+
+ဒီချဉ်းကပ်မှုက ပိုမိုဆက်စပ်မှုရှိပြီး သဒ္ဒါမှန်ကန်တဲ့ စာသားတွေကို မကြာခဏ ထုတ်လုပ်ပေးတတ်ပေမယ့်၊ ရိုးရှင်းတဲ့ နည်းလမ်းတွေထက် ကွန်ပျူတာ အရင်းအမြစ် ပိုမိုလိုအပ်ပါတယ်။
+
+## လက်တွေ့ စိန်ခေါ်မှုများနှင့် အကောင်းဆုံးဖြစ်အောင် ပြုလုပ်ခြင်း (Optimization)[[practical-challenges-and-optimization]]
+
+LLM inference ကို ကျွန်တော်တို့ လေ့လာမှု ပြီးဆုံးခါနီးမှာ ဒီမော်ဒယ်တွေကို အသုံးပြုတဲ့အခါ သင်ရင်ဆိုင်ရမယ့် လက်တွေ့ကျတဲ့ စိန်ခေါ်မှုတွေနဲ့ ၎င်းတို့ရဲ့ စွမ်းဆောင်ရည်ကို ဘယ်လိုတိုင်းတာပြီး အကောင်းဆုံးဖြစ်အောင် လုပ်ရမလဲဆိုတာကို ကြည့်ရအောင်။
+
+### အဓိက စွမ်းဆောင်ရည် တိုင်းတာချက်များ (Key Performance Metrics)[[key-performance-metrics]]
+
+LLMs တွေနဲ့ အလုပ်လုပ်တဲ့အခါ အရေးကြီးတဲ့ တိုင်းတာချက် (၄) ခုက သင်ရဲ့ implement လုပ်မယ့် ဆုံးဖြတ်ချက်တွေကို ပုံဖော်ပေးပါလိမ့်မယ်-
+
+1. **ပထမဆုံး Token ရရှိချိန် (Time to First Token - TTFT)**: ပထမဆုံး အဖြေကို ဘယ်လောက် မြန်မြန်ရနိုင်မလဲ။ ဒါက user experience အတွက် အရေးကြီးပြီး prefill အဆင့်ကြောင့် အဓိကအားဖြင့် ထိခိုက်ပါတယ်။
+2. **Output Token တစ်ခုစီအတွက် အချိန် (Time Per Output Token - TPOT)**: နောက်ထပ် tokens တွေကို ဘယ်လောက် မြန်မြန်ထုတ်လုပ်နိုင်မလဲ။ ဒါက အလုံးစုံ ထုတ်လုပ်မှု အမြန်နှုန်းကို ဆုံးဖြတ်ပါတယ်။
+3. **Throughput**: တစ်ပြိုင်နက်တည်း request ဘယ်နှစ်ခုကို ကိုင်တွယ်နိုင်မလဲ။ ဒါက scaling နဲ့ ကုန်ကျစရိတ် ထိရောက်မှုအပေါ် သက်ရောက်မှုရှိပါတယ်။
+4. **VRAM အသုံးပြုမှု (VRAM Usage)**: GPU memory ဘယ်လောက်လိုအပ်မလဲ။ ဒါက လက်တွေ့အသုံးချမှုတွေမှာ အဓိက ကန့်သတ်ချက် ဖြစ်လာတတ်ပါတယ်။
+
+### Context Length စိန်ခေါ်မှု[[the-context-length-challenge]]
+
+LLM inference မှာ အရေးအကြီးဆုံး စိန်ခေါ်မှုတစ်ခုကတော့ context length ကို ထိထိရောက်ရောက် စီမံခန့်ခွဲခြင်းပါပဲ။ ပိုမိုရှည်လျားတဲ့ contexts တွေက အချက်အလက် ပိုပေးပေမယ့် ကုန်ကျစရိတ်များစွာနဲ့ လာပါတယ်-
+
+- **Memory အသုံးပြုမှု**: context length နဲ့အမျှ quadratically တိုးလာပါတယ်။
+- **လုပ်ဆောင်မှု အမြန်နှုန်း (Processing Speed)**: ပိုမိုရှည်လျားတဲ့ contexts တွေနဲ့အမျှ linearly လျော့ကျသွားပါတယ်။
+- **အရင်းအမြစ် ခွဲဝေမှု (Resource Allocation)**: VRAM အသုံးပြုမှုကို သေချာမျှတအောင် ထိန်းညှိဖို့ လိုအပ်ပါတယ်။
+
+[Qwen2.5-1M](https://huggingface.co/Qwen/Qwen2.5-14B-Instruct-1M) လို ခေတ်မီမော်ဒယ်တွေကတော့ 1M token context windows တွေကို စွဲမက်ဖွယ်ကောင်းအောင် ပေးစွမ်းနိုင်ပေမယ့်၊ ဒါဟာ inference လုပ်ဆောင်ချိန် သိသိသာသာ နှေးကွေးခြင်းရဲ့ အဖိုးအခနဲ့ လာပါတယ်။ အဓိကသော့ချက်ကတော့ သင်ရဲ့ သီးခြားအသုံးပြုမှုအတွက် မှန်ကန်တဲ့ မျှတမှုကို ရှာဖွေဖို့ပါပဲ။
+
+
+
+နောက်ထပ် token ကို ခန့်မှန်းဖို့ အသက်ဆိုင်ဆုံး စကားလုံးတွေကို ဖော်ထုတ်တဲ့ ဒီလုပ်ငန်းစဉ်ဟာ အံ့သြစရာကောင်းလောက်အောင် ထိရောက်မှုရှိတယ်ဆိုတာ သက်သေပြခဲ့ပြီးပါပြီ။ LLMs တွေ လေ့ကျင့်တဲ့ အခြေခံမူ—နောက်ထပ် token ကို ခန့်မှန်းခြင်း—ဟာ BERT နဲ့ GPT-2 ကတည်းက ယေဘုယျအားဖြင့် အတူတူပဲ ရှိခဲ့ပေမယ့်၊ neural network တွေကို ချဲ့ထွင်ရာမှာနဲ့ attention mechanism ကို ပိုမိုရှည်လျားတဲ့ sequence တွေအတွက် ကုန်ကျစရိတ်သက်သာစွာ အလုပ်လုပ်နိုင်အောင် လုပ်ဆောင်ရာမှာ သိသိသာသာ တိုးတက်မှုတွေ ရှိခဲ့ပါတယ်။
+
+> [!TIP]
+> အတိုချုပ်ပြောရရင် attention mechanism ဟာ LLMs တွေ ဆက်စပ်မှုရှိပြီး အကြောင်းအရာကို နားလည်တဲ့ စာသားတွေကို ထုတ်လုပ်နိုင်စေဖို့အတွက် အဓိကသော့ချက် ဖြစ်ပါတယ်။ ဒါက ခေတ်မီ LLMs တွေကို ယခင်မျိုးဆက် ဘာသာစကားမော်ဒယ်တွေနဲ့ ကွဲပြားစေပါတယ်။
+
+### Context Length နဲ့ Attention Span[[context-length-and-attention-span]]
+
+Attention ကို နားလည်ပြီးပြီဆိုတော့ LLM တစ်ခုက ဘယ်လောက်အထိ context ကို ကိုင်တွယ်နိုင်မလဲဆိုတာကို ဆက်လေ့လာကြည့်ရအောင်။ ဒါက model ရဲ့ 'attention span' လို့ခေါ်တဲ့ context length နဲ့ သက်ဆိုင်ပါတယ်။
+
+Context length ဆိုတာ LLM တစ်ခုက တစ်ကြိမ်တည်း လုပ်ဆောင်နိုင်တဲ့ အများဆုံး token (စကားလုံး ဒါမှမဟုတ် စကားလုံးရဲ့ အစိတ်အပိုင်း) အရေအတွက်ကို ရည်ညွှန်းပါတယ်။ ဒါကို model ရဲ့ အလုပ်လုပ်တဲ့ မှတ်ဉာဏ် (working memory) ရဲ့ အရွယ်အစားလို့ တွေးကြည့်နိုင်ပါတယ်။
+
+ဒီစွမ်းရည်တွေဟာ လက်တွေ့ကျတဲ့ အချက်အလက်အချို့ကြောင့် ကန့်သတ်ထားပါတယ်-
+- Model ရဲ့ architecture နဲ့ အရွယ်အစား
+- ရရှိနိုင်တဲ့ ကွန်ပျူတာ အရင်းအမြစ်များ
+- input နဲ့ ထုတ်လိုတဲ့ output ရဲ့ ရှုပ်ထွေးမှု
+
+စံပြကမ္ဘာမှာဆိုရင် မော်ဒယ်ကို ကန့်သတ်ချက်မရှိတဲ့ context တွေ ထည့်ပေးနိုင်ပေမယ့်၊ hardware ကန့်သတ်ချက်တွေနဲ့ ကွန်ပျူတာ ကုန်ကျစရိတ်တွေကြောင့် ဒါက လက်တွေ့မကျပါဘူး။ ဒါကြောင့် ကန့်သတ်ချက်နဲ့ ထိရောက်မှုကို မျှတအောင် ထိန်းညှိဖို့အတွက် မတူညီတဲ့ context length တွေနဲ့ မော်ဒယ်တွေကို ဒီဇိုင်းထုတ်ထားတာ ဖြစ်ပါတယ်။
+
+> [!TIP]
+> Context length ဆိုတာ မော်ဒယ်က အဖြေတစ်ခုကို ထုတ်လုပ်တဲ့အခါ တစ်ကြိမ်တည်းမှာ ထည့်သွင်းစဉ်းစားနိုင်တဲ့ အများဆုံး token အရေအတွက် ဖြစ်ပါတယ်။
+
+### Prompting ပညာ[[the-art-of-prompting]]
+
+ကျွန်တော်တို့ LLMs တွေကို အချက်အလက်တွေ ပေးပို့တဲ့အခါ၊ LLM ရဲ့ ထုတ်လုပ်မှုကို လိုချင်တဲ့ output ဆီ ဦးတည်နိုင်အောင် input ကို ပုံစံချပါတယ်။ ဒါကို _prompting_ လို့ ခေါ်ပါတယ်။
+
+LLMs တွေက အချက်အလက်တွေကို ဘယ်လိုလုပ်ဆောင်တယ်ဆိုတာ နားလည်ခြင်းက ပိုကောင်းတဲ့ prompts တွေကို ဖန်တီးနိုင်ဖို့ ကူညီပေးပါတယ်။ မော်ဒယ်ရဲ့ အဓိကတာဝန်က input token တစ်ခုစီရဲ့ အရေးပါမှုကို ခွဲခြမ်းစိတ်ဖြာပြီး နောက်ထပ် token ကို ခန့်မှန်းဖို့ဖြစ်တာကြောင့်၊ သင်ရဲ့ input sequence ရဲ့ စကားလုံးဖွဲ့စည်းပုံက အရေးကြီးလာပါတယ်။
+
+> [!TIP]
+> Prompt ကို သေချာဒီဇိုင်းထုတ်ခြင်းက **LLM ရဲ့ ထုတ်လုပ်မှုကို လိုချင်တဲ့ output ဆီ ဦးတည်စေရန် ပိုမိုလွယ်ကူစေပါတယ်**။
+
+## နှစ်ဆင့်ပါသော Inference လုပ်ငန်းစဉ်[[the-two-phase-inference-process]]
+
+အခြေခံအစိတ်အပိုင်းတွေကို ကျွန်တော်တို့ နားလည်ပြီးပြီဆိုတော့ LLMs တွေက စာသားတွေကို ဘယ်လိုထုတ်လုပ်တယ်ဆိုတာကို နက်ရှိုင်းစွာ လေ့လာကြည့်ရအောင်။ လုပ်ငန်းစဉ်ကို အဓိက အဆင့်နှစ်ဆင့်ခွဲနိုင်ပါတယ်- prefill နဲ့ decode ပါ။ ဒီအဆင့်တွေက ပူးပေါင်းပြီး အလုပ်လုပ်ကြပြီး၊ စာသားတွေ ဆက်စပ်မှုရှိအောင် ထုတ်လုပ်ရာမှာ အရေးကြီးတဲ့ အခန်းကဏ္ဍတွေကနေ ပါဝင်ပါတယ်။
+
+### Prefill အဆင့်[[the-prefill-phase]]
+
+Prefill အဆင့်ဟာ ချက်ပြုတ်ရာမှာ ပြင်ဆင်မှုအဆင့်နဲ့ တူပါတယ်။ ဒီအဆင့်မှာ ကနဦးပါဝင်ပစ္စည်းအားလုံးကို လုပ်ဆောင်ပြီး အသင့်ပြင်ဆင်ပါတယ်။ ဒီအဆင့်မှာ အဓိကအချက် (၃) ချက် ပါဝင်ပါတယ်-
+
+1. **Tokenization**: input စာသားကို tokens တွေအဖြစ် ပြောင်းလဲခြင်း (ဒါတွေကို မော်ဒယ်က နားလည်တဲ့ အခြေခံ building blocks တွေလို့ တွေးကြည့်နိုင်ပါတယ်)
+2. **Embedding Conversion**: ဒီ tokens တွေကို ၎င်းတို့ရဲ့ အဓိပ္ပာယ်ကို ဖမ်းယူထားတဲ့ ဂဏန်းဆိုင်ရာ ကိုယ်စားပြုမှု (numerical representations) တွေအဖြစ် ပြောင်းလဲခြင်း
+3. **ကနဦး လုပ်ဆောင်ခြင်း (Initial Processing)**: context ကို ပြည့်ပြည့်စုံစုံ နားလည်မှု ဖန်တီးဖို့အတွက် ဒီ embeddings တွေကို model ရဲ့ neural network တွေကနေတဆင့် လုပ်ဆောင်ခြင်း
+
+ဒီအဆင့်ဟာ input tokens အားလုံးကို တစ်ကြိမ်တည်း လုပ်ဆောင်ဖို့ လိုအပ်တာကြောင့် ကွန်ပျူတာအရင်းအမြစ်များစွာ လိုအပ်ပါတယ်။ ဒါကို အဖြေမရေးခင် စာပိုဒ်တစ်ခုလုံးကို ဖတ်ပြီး နားလည်တာနဲ့ တူတယ်လို့ တွေးကြည့်နိုင်ပါတယ်။
+
+အောက်က interactive playground မှာ မတူညီတဲ့ tokenizers တွေနဲ့ စမ်းသပ်ကြည့်နိုင်ပါတယ်-
+
+
+
+### Decode အဆင့်[[the-decode-phase]]
+
+Prefill အဆင့်က input ကို လုပ်ဆောင်ပြီးနောက်မှာတော့ decode အဆင့်ကို ရောက်ရှိလာပါပြီ - ဒီနေရာမှာ စာသားထုတ်လုပ်ခြင်း အမှန်တကယ် ဖြစ်လာပါတယ်။ မော်ဒယ်က တစ်ကြိမ်ကို token တစ်ခုစီ ထုတ်လုပ်ပြီး၊ ဒါကို autoregressive process (အသစ်ထွက်လာတဲ့ token တိုင်းက ယခင် tokens အားလုံးပေါ် မူတည်ပါတယ်) လို့ ခေါ်ပါတယ်။
+
+Decode အဆင့်မှာ အသစ်ထွက်လာတဲ့ token တိုင်းအတွက် အဓိကအချက်များစွာ ပါဝင်ပါတယ်-
+1. **Attention Computation**: context ကို နားလည်ဖို့ ယခင် tokens အားလုံးကို ပြန်ကြည့်ခြင်း
+2. **ဖြစ်နိုင်ခြေ တွက်ချက်ခြင်း (Probability Calculation)**: ဖြစ်နိုင်ခြေရှိတဲ့ နောက်ထပ် token တစ်ခုစီရဲ့ ဖြစ်နိုင်ခြေကို ဆုံးဖြတ်ခြင်း
+3. **Token ရွေးချယ်ခြင်း (Token Selection)**: ဒီဖြစ်နိုင်ခြေတွေအပေါ် အခြေခံပြီး နောက်ထပ် token ကို ရွေးချယ်ခြင်း
+4. **ဆက်လက်လုပ်ဆောင်မှု စစ်ဆေးခြင်း (Continuation Check)**: ဆက်လုပ်မလား ဒါမှမဟုတ် ထုတ်လုပ်မှုကို ရပ်မလားဆိုတာကို ဆုံးဖြတ်ခြင်း
+
+ဒီအဆင့်ဟာ မော်ဒယ်က ယခင်ထုတ်လုပ်ထားတဲ့ tokens အားလုံးနဲ့ ၎င်းတို့ရဲ့ ဆက်စပ်မှုတွေကို မှတ်ထားဖို့ လိုအပ်တာကြောင့် memory-intensive ဖြစ်ပါတယ်။
+
+## Sampling နည်းဗျူဟာများ[[sampling-strategies]]
+
+မော်ဒယ်က စာသားတွေကို ဘယ်လိုထုတ်လုပ်တယ်ဆိုတာ နားလည်ပြီးပြီဆိုတော့ ဒီထုတ်လုပ်မှု လုပ်ငန်းစဉ်ကို ဘယ်လိုထိန်းချုပ်နိုင်မလဲဆိုတာကို လေ့လာကြည့်ရအောင်။ စာရေးဆရာတစ်ဦးက ပိုမိုတီထွင်ဖန်တီးမှုရှိမလား ဒါမှမဟုတ် ပိုမိုတိကျမလားဆိုတာ ရွေးချယ်နိုင်သလိုပဲ၊ ကျွန်တော်တို့လည်း မော်ဒယ်က tokens တွေကို ဘယ်လိုရွေးချယ်တယ်ဆိုတာကို ချိန်ညှိနိုင်ပါတယ်။
+
+ဒီ Space မှာ SmolLM2 နဲ့ အခြေခံ decoding လုပ်ငန်းစဉ်ကို ကိုယ်တိုင် အပြန်အလှန်လုပ်ဆောင်နိုင်ပါတယ် (မှတ်ထားပါ၊ ဒီမော်ဒယ်အတွက် **<|im_end|>** ဖြစ်တဲ့ **EOS** token ကို မရောက်မချင်း decode လုပ်ပါလိမ့်မယ်)-
+
+
+
+### Token ရွေးချယ်မှုကို နားလည်ခြင်း- ဖြစ်နိုင်ခြေများမှ Token ရွေးချယ်မှုများဆီသို့[[understanding-token-selection-from-probabilities-to-token-choices]]
+
+မော်ဒယ်က နောက်ထပ် token ကို ရွေးချယ်ဖို့ လိုအပ်တဲ့အခါ၊ ၎င်းရဲ့ ဝေါဟာရ (vocabulary) ထဲက စကားလုံးတိုင်းအတွက် ကနဦး ဖြစ်နိုင်ခြေ (logits) တွေနဲ့ စတင်ပါတယ်။ ဒါပေမယ့် ဒီဖြစ်နိုင်ခြေတွေကို လက်တွေ့ရွေးချယ်မှုတွေအဖြစ် ဘယ်လိုပြောင်းလဲမလဲ။ လုပ်ငန်းစဉ်ကို ခွဲခြမ်းစိတ်ဖြာကြည့်ရအောင်-
+
+
+
+1. **Raw Logits**: ဒါတွေကို မော်ဒယ်ရဲ့ နောက်ထပ် ဖြစ်နိုင်ခြေရှိတဲ့ စကားလုံးတိုင်းအတွက် ကနဦး ခံစားချက်တွေလို့ တွေးကြည့်ပါ။
+2. **Temperature Control**: တီထွင်ဖန်တီးမှု ခလုတ်လိုပါပဲ - တန်ဖိုးမြင့်လေ (>1.0) ရွေးချယ်မှုတွေ ပိုမိုကျပန်းဆန်ပြီး ဖန်တီးမှုရှိလေ၊ တန်ဖိုးနိမ့်လေ (<1.0) ပိုမိုအာရုံစိုက်ပြီး တိကျလေ ဖြစ်ပါတယ်။
+3. **Top-p (Nucleus) Sampling**: ဖြစ်နိုင်ခြေရှိတဲ့ စကားလုံးအားလုံးကို ထည့်သွင်းစဉ်းစားမယ့်အစား၊ ကျွန်တော်တို့ ရွေးချယ်ထားတဲ့ ဖြစ်နိုင်ခြေ ကန့်သတ်ချက် (ဥပမာ- ထိပ်ဆုံး 90%) နဲ့ ကိုက်ညီတဲ့ အဖြစ်နိုင်ဆုံး စကားလုံးတွေကိုပဲ ကြည့်ပါတယ်။
+4. **Top-k Filtering**: အခြားနည်းလမ်းတစ်ခုဖြစ်ပြီး၊ ကျွန်တော်တို့ဟာ အဖြစ်နိုင်ဆုံး နောက်ထပ်စကားလုံး k လုံးကိုပဲ ထည့်သွင်းစဉ်းစားပါတယ်။
+
+### ထပ်ခါတလဲလဲဖြစ်ခြင်းကို ထိန်းချုပ်ခြင်း- Output ကို လတ်ဆတ်နေစေခြင်း[[managing-repetition-keeping-output-fresh]]
+
+LLMs တွေနဲ့ အဖြစ်များတဲ့ စိန်ခေါ်မှုတစ်ခုကတော့ သူတို့ကိုယ်သူတို့ ထပ်ခါတလဲလဲပြောတတ်တဲ့ သဘောရှိခြင်းပါ - အချက်အလက်တွေကို အကြိမ်ကြိမ် ပြန်ပြောတတ်တဲ့ စကားပြောသူတစ်ဦးနဲ့ တူပါတယ်။ ဒါကို ဖြေရှင်းဖို့အတွက် ကျွန်တော်တို့ဟာ ပြစ်ဒဏ်နှစ်မျိုးကို အသုံးပြုပါတယ်-
+
+1. **Presence Penalty**: ယခင်က ပါဝင်ခဲ့ဖူးတဲ့ token တစ်ခုစီအတွက် အကြိမ်အရေအတွက် ဘယ်လောက်ပဲ ဖြစ်ပါစေ၊ သတ်မှတ်ထားတဲ့ ပြစ်ဒဏ်တစ်ခုကို ပေးပါတယ်။ ဒါက မော်ဒယ်ကို တူညီတဲ့ စကားလုံးတွေကို ထပ်ခါတလဲလဲ အသုံးမပြုမိအောင် ကူညီပေးပါတယ်။
+2. **Frequency Penalty**: token တစ်ခု ဘယ်နှစ်ကြိမ် အသုံးပြုပြီးပြီလဲဆိုတာပေါ်မူတည်ပြီး တိုးလာတဲ့ ပြစ်ဒဏ်တစ်ခုပါ။ စကားလုံးတစ်ခု ပိုမိုပါဝင်လေ၊ နောက်ထပ်ရွေးချယ်ခံရဖို့ အခွင့်အလမ်း နည်းလေ ဖြစ်ပါတယ်။
+
+
+
+ဒီပြစ်ဒဏ်တွေကို token ရွေးချယ်မှု လုပ်ငန်းစဉ်ရဲ့ အစောပိုင်းမှာ လိမ်းကျံပြီး၊ အခြား sampling နည်းဗျူဟာတွေကို အသုံးမပြုခင် ကနဦး ဖြစ်နိုင်ခြေတွေကို ချိန်ညှိပေးပါတယ်။ ဒါတွေကို မော်ဒယ်ကို ဝေါဟာရအသစ်တွေ ရှာဖွေဖို့ နူးညံ့စွာ တွန်းအားပေးတာနဲ့ တူတယ်လို့ တွေးကြည့်နိုင်ပါတယ်။
+
+### ထုတ်လုပ်မှု အရှည်ကို ထိန်းချုပ်ခြင်း- ကန့်သတ်ချက်များ သတ်မှတ်ခြင်း[[controlling-generation-length-setting-boundaries]]
+
+ကောင်းမွန်တဲ့ ပုံပြင်တစ်ခုမှာ သင့်လျော်တဲ့ စည်းမျဉ်းစည်းကမ်းနဲ့ အရှည်ရှိဖို့ လိုအပ်သလိုပဲ၊ ကျွန်တော်တို့ရဲ့ LLM က ဘယ်လောက်များများ စာသားထုတ်လုပ်မလဲဆိုတာကို ထိန်းချုပ်ဖို့ နည်းလမ်းတွေ လိုအပ်ပါတယ်။ ဒါက လက်တွေ့အသုံးချမှုတွေအတွက် အရေးကြီးပါတယ် - tweet တစ်ခုလောက်တိုတဲ့ အဖြေဖြစ်စေ၊ blog post အပြည့်အစုံဖြစ်စေပေါ့။
+
+ထုတ်လုပ်မှု အရှည်ကို နည်းလမ်းများစွာနဲ့ ထိန်းချုပ်နိုင်ပါတယ်-
+1. **Token Limits**: အနည်းဆုံးနဲ့ အများဆုံး token အရေအတွက်ကို သတ်မှတ်ခြင်း
+2. **Stop Sequences**: ထုတ်လုပ်မှု ပြီးဆုံးကြောင်း အချက်ပြတဲ့ သီးခြားပုံစံတွေကို သတ်မှတ်ခြင်း
+3. **End-of-Sequence Detection**: မော်ဒယ်ကို သူ့ဘာသာသူ အဖြေကို သဘာဝအတိုင်း နိဂုံးချုပ်စေခြင်း
+
+ဥပမာအားဖြင့်၊ ကျွန်တော်တို့ဟာ စာပိုဒ်တစ်ပိုဒ်တည်းကိုပဲ ထုတ်လုပ်ချင်တယ်ဆိုရင် အများဆုံး tokens 100 သတ်မှတ်ပြီး "\n\n" ကို stop sequence အဖြစ် အသုံးပြုနိုင်ပါတယ်။ ဒါက ကျွန်တော်တို့ရဲ့ output က ရည်ရွယ်ချက်နဲ့ ကိုက်ညီတဲ့ အရွယ်အစားနဲ့ အာရုံစိုက်မှု ရှိစေပါတယ်။
+
+
+
+### Beam Search: ပိုမိုကောင်းမွန်တဲ့ ဆက်စပ်မှုအတွက် ကြိုတင်မျှော်မှန်းခြင်း[[beam-search-looking-ahead-for-better-coherence]]
+
+ကျွန်တော်တို့ ခုထိ ဆွေးနွေးခဲ့တဲ့ နည်းဗျူဟာတွေက တစ်ကြိမ်ကို token တစ်ခုစီ ဆုံးဖြတ်ချက်ချပေမယ့်၊ beam search ကတော့ ပိုမိုပြည့်စုံတဲ့ ချဉ်းကပ်မှုကို လုပ်ဆောင်ပါတယ်။ ခြေလှမ်းတိုင်းမှာ ရွေးချယ်မှုတစ်ခုတည်းကိုပဲ လုပ်ဆောင်မယ့်အစား၊ ၎င်းဟာ ကစားသမားတစ်ဦးက အရှေ့ကို အကြိမ်ကြိမ် တွေးတောသလိုမျိုး ဖြစ်နိုင်ခြေရှိတဲ့ လမ်းကြောင်းပေါင်းစုံကို တစ်ပြိုင်နက်တည်း ရှာဖွေပါတယ်။
+
+
+
+ဒါက ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို ကြည့်ရအောင်-
+1. ခြေလှမ်းတိုင်းမှာ၊ ဖြစ်နိုင်ခြေရှိတဲ့ candidate sequence အများအပြားကို ထိန်းသိမ်းထားပါတယ် (များသောအားဖြင့် ၅-၁၀ ခု)။
+2. candidate တစ်ခုစီအတွက်၊ နောက်ထပ် token ရဲ့ ဖြစ်နိုင်ခြေတွေကို တွက်ချက်ပါတယ်။
+3. sequence တွေနဲ့ နောက်ထပ် token တွေရဲ့ အဖြစ်နိုင်ဆုံး ပေါင်းစပ်မှုတွေကိုသာ ထိန်းသိမ်းထားပါတယ်။
+4. လိုချင်တဲ့ အရှည် ဒါမှမဟုတ် ရပ်တန့်တဲ့အခြေအနေကို ရောက်တဲ့အထိ ဒီလုပ်ငန်းစဉ်ကို ဆက်လုပ်ပါတယ်။
+5. အလုံးစုံ ဖြစ်နိုင်ခြေအမြင့်ဆုံးရှိတဲ့ sequence ကို ရွေးချယ်ပါတယ်။
+
+ဒီနေရာမှာ beam search ကို ပုံမှန်ကြည့်ရှုနိုင်ပါတယ်-
+
+
+
+ဒီချဉ်းကပ်မှုက ပိုမိုဆက်စပ်မှုရှိပြီး သဒ္ဒါမှန်ကန်တဲ့ စာသားတွေကို မကြာခဏ ထုတ်လုပ်ပေးတတ်ပေမယ့်၊ ရိုးရှင်းတဲ့ နည်းလမ်းတွေထက် ကွန်ပျူတာ အရင်းအမြစ် ပိုမိုလိုအပ်ပါတယ်။
+
+## လက်တွေ့ စိန်ခေါ်မှုများနှင့် အကောင်းဆုံးဖြစ်အောင် ပြုလုပ်ခြင်း (Optimization)[[practical-challenges-and-optimization]]
+
+LLM inference ကို ကျွန်တော်တို့ လေ့လာမှု ပြီးဆုံးခါနီးမှာ ဒီမော်ဒယ်တွေကို အသုံးပြုတဲ့အခါ သင်ရင်ဆိုင်ရမယ့် လက်တွေ့ကျတဲ့ စိန်ခေါ်မှုတွေနဲ့ ၎င်းတို့ရဲ့ စွမ်းဆောင်ရည်ကို ဘယ်လိုတိုင်းတာပြီး အကောင်းဆုံးဖြစ်အောင် လုပ်ရမလဲဆိုတာကို ကြည့်ရအောင်။
+
+### အဓိက စွမ်းဆောင်ရည် တိုင်းတာချက်များ (Key Performance Metrics)[[key-performance-metrics]]
+
+LLMs တွေနဲ့ အလုပ်လုပ်တဲ့အခါ အရေးကြီးတဲ့ တိုင်းတာချက် (၄) ခုက သင်ရဲ့ implement လုပ်မယ့် ဆုံးဖြတ်ချက်တွေကို ပုံဖော်ပေးပါလိမ့်မယ်-
+
+1. **ပထမဆုံး Token ရရှိချိန် (Time to First Token - TTFT)**: ပထမဆုံး အဖြေကို ဘယ်လောက် မြန်မြန်ရနိုင်မလဲ။ ဒါက user experience အတွက် အရေးကြီးပြီး prefill အဆင့်ကြောင့် အဓိကအားဖြင့် ထိခိုက်ပါတယ်။
+2. **Output Token တစ်ခုစီအတွက် အချိန် (Time Per Output Token - TPOT)**: နောက်ထပ် tokens တွေကို ဘယ်လောက် မြန်မြန်ထုတ်လုပ်နိုင်မလဲ။ ဒါက အလုံးစုံ ထုတ်လုပ်မှု အမြန်နှုန်းကို ဆုံးဖြတ်ပါတယ်။
+3. **Throughput**: တစ်ပြိုင်နက်တည်း request ဘယ်နှစ်ခုကို ကိုင်တွယ်နိုင်မလဲ။ ဒါက scaling နဲ့ ကုန်ကျစရိတ် ထိရောက်မှုအပေါ် သက်ရောက်မှုရှိပါတယ်။
+4. **VRAM အသုံးပြုမှု (VRAM Usage)**: GPU memory ဘယ်လောက်လိုအပ်မလဲ။ ဒါက လက်တွေ့အသုံးချမှုတွေမှာ အဓိက ကန့်သတ်ချက် ဖြစ်လာတတ်ပါတယ်။
+
+### Context Length စိန်ခေါ်မှု[[the-context-length-challenge]]
+
+LLM inference မှာ အရေးအကြီးဆုံး စိန်ခေါ်မှုတစ်ခုကတော့ context length ကို ထိထိရောက်ရောက် စီမံခန့်ခွဲခြင်းပါပဲ။ ပိုမိုရှည်လျားတဲ့ contexts တွေက အချက်အလက် ပိုပေးပေမယ့် ကုန်ကျစရိတ်များစွာနဲ့ လာပါတယ်-
+
+- **Memory အသုံးပြုမှု**: context length နဲ့အမျှ quadratically တိုးလာပါတယ်။
+- **လုပ်ဆောင်မှု အမြန်နှုန်း (Processing Speed)**: ပိုမိုရှည်လျားတဲ့ contexts တွေနဲ့အမျှ linearly လျော့ကျသွားပါတယ်။
+- **အရင်းအမြစ် ခွဲဝေမှု (Resource Allocation)**: VRAM အသုံးပြုမှုကို သေချာမျှတအောင် ထိန်းညှိဖို့ လိုအပ်ပါတယ်။
+
+[Qwen2.5-1M](https://huggingface.co/Qwen/Qwen2.5-14B-Instruct-1M) လို ခေတ်မီမော်ဒယ်တွေကတော့ 1M token context windows တွေကို စွဲမက်ဖွယ်ကောင်းအောင် ပေးစွမ်းနိုင်ပေမယ့်၊ ဒါဟာ inference လုပ်ဆောင်ချိန် သိသိသာသာ နှေးကွေးခြင်းရဲ့ အဖိုးအခနဲ့ လာပါတယ်။ အဓိကသော့ချက်ကတော့ သင်ရဲ့ သီးခြားအသုံးပြုမှုအတွက် မှန်ကန်တဲ့ မျှတမှုကို ရှာဖွေဖို့ပါပဲ။
+
+
+
+
+### KV Cache Optimization[[the-kv-cache-optimization]]
+
+ဒီစိန်ခေါ်မှုတွေကို ဖြေရှင်းဖို့အတွက် အစွမ်းအထက်ဆုံး optimization တစ်ခုကတော့ KV (Key-Value) caching ပါ။ ဒီနည်းပညာက ကြားဖြတ်တွက်ချက်မှုတွေကို သိုလှောင်ပြီး ပြန်လည်အသုံးပြုခြင်းဖြင့် inference အမြန်နှုန်းကို သိသိသာသာ တိုးတက်စေပါတယ်။ ဒီ optimization က-
+- ထပ်ခါတလဲလဲ တွက်ချက်မှုတွေကို လျှော့ချပေးပါတယ်
+- ထုတ်လုပ်မှု အမြန်နှုန်းကို တိုးတက်စေပါတယ်
+- ရှည်လျားတဲ့ context ထုတ်လုပ်မှုကို လက်တွေ့ကျအောင် လုပ်ဆောင်ပေးပါတယ်
+
+အားနည်းချက်ကတော့ memory အသုံးပြုမှု ပိုများလာတာပါပဲ၊ ဒါပေမယ့် စွမ်းဆောင်ရည် အကျိုးကျေးဇူးတွေက ဒီကုန်ကျစရိတ်ထက် များသောအားဖြင့် သာလွန်ပါတယ်။
+
+## နိဂုံး[[conclusion]]
+
+LLM inference ကို နားလည်ထားခြင်းက ဒီအစွမ်းထက်တဲ့ မော်ဒယ်တွေကို ထိထိရောက်ရောက် အသုံးပြုပြီး အကောင်းဆုံးဖြစ်အောင် လုပ်ဆောင်ဖို့အတွက် အရေးကြီးပါတယ်။ ကျွန်တော်တို့ဟာ အဓိကအစိတ်အပိုင်းတွေကို လေ့လာခဲ့ပြီးပါပြီ-
+
+- Attention နဲ့ context ရဲ့ အခြေခံအခန်းကဏ္ဍ
+- နှစ်ဆင့်ပါသော inference လုပ်ငန်းစဉ်
+- ထုတ်လုပ်မှုကို ထိန်းချုပ်ရန် အမျိုးမျိုးသော sampling နည်းဗျူဟာများ
+- လက်တွေ့ စိန်ခေါ်မှုများနှင့် optimization များ
+
+ဒီသဘောတရားတွေကို ကျွမ်းကျင်ခြင်းဖြင့် LLMs တွေကို ထိရောက်စွာနဲ့ စွမ်းဆောင်ရည်မြင့်စွာ အသုံးပြုနိုင်တဲ့ applications တွေ တည်ဆောက်ဖို့ သင်ပိုပြီး အသင့်ဖြစ်လာပါလိမ့်မယ်။
+
+LLM inference နယ်ပယ်ဟာ အဆက်မပြတ် တိုးတက်ပြောင်းလဲနေပြီး၊ နည်းစနစ်အသစ်တွေနဲ့ optimization တွေ ပုံမှန်ပေါ်ထွက်လာနေတာကို သတိရပါ။ သင်ရဲ့ သီးခြားအသုံးပြုမှုအတွက် ဘယ်အရာက အကောင်းဆုံးလဲဆိုတာကို ရှာဖွေဖို့ စူးစမ်းလိုစိတ်ထားပြီး မတူညီတဲ့ ချဉ်းကပ်မှုတွေနဲ့ ဆက်လက်စမ်းသပ်ပါ။
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* **Inference**: လေ့ကျင့်ပြီးသား Artificial Intelligence (AI) မော်ဒယ်တစ်ခုကို အသုံးပြုပြီး input data ကနေ ခန့်မှန်းချက်တွေ ဒါမှမဟုတ် output တွေကို ထုတ်လုပ်တဲ့ လုပ်ငန်းစဉ်။
+* **Large Language Models (LLMs)**: လူသားဘာသာစကားကို နားလည်ပြီး ထုတ်လုပ်ပေးနိုင်တဲ့ အလွန်ကြီးမားတဲ့ Artificial Intelligence (AI) မော်ဒယ်တွေ ဖြစ်ပါတယ်။ ၎င်းတို့ဟာ ဒေတာအမြောက်အမြားနဲ့ သင်ကြားလေ့ကျင့်ထားပြီး စာရေးတာ၊ မေးခွန်းဖြေတာ စတဲ့ ဘာသာစကားဆိုင်ရာ လုပ်ငန်းမျိုးစုံကို လုပ်ဆောင်နိုင်ပါတယ်။
+* **Transformer Architecture**: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။ ၎င်းတို့ဟာ စာသားတွေထဲက စကားလုံးတွေရဲ့ ဆက်နွယ်မှုတွေကို "attention mechanism" သုံးပြီး နားလည်အောင် သင်ကြားပေးပါတယ်။
+* **Text Generation**: AI မော်ဒယ်များကို အသုံးပြု၍ လူသားကဲ့သို့သော စာသားအသစ်များ ဖန်တီးခြင်း။
+* **Text Classification**: စာသားတစ်ခုကို သတ်မှတ်ထားသော အမျိုးအစားများ သို့မဟုတ် အတန်းများထဲသို့ ခွဲခြားသတ်မှတ်ခြင်း။
+* **Summarization**: စာသားရှည်ကြီးတစ်ခုကို အဓိကအချက်အလက်များ မပျောက်ပျက်စေဘဲ အကျဉ်းချုံးဖော်ပြခြင်း။
+* **Prompt**: Large Language Models (LLMs) ကို တိကျသောလုပ်ငန်းတစ်ခု လုပ်ဆောင်ရန် သို့မဟုတ် အချက်အလက်ပေးရန်အတွက် ပေးပို့သော input text သို့မဟုတ် မေးခွန်း။
+* **Parameters**: Machine Learning မော်ဒယ်တစ်ခု၏ သင်ယူနိုင်သော အစိတ်အပိုင်းများ။ ၎င်းတို့သည် လေ့ကျင့်နေစဉ်အတွင်း ဒေတာများမှ ပုံစံများကို သင်ယူကာ ချိန်ညှိပေးသည်။
+* **Token**: စာသား (သို့မဟုတ် အခြားဒေတာ) ကို AI မော်ဒယ်များ စီမံဆောင်ရွက်နိုင်ရန် ပိုင်းခြားထားသော အသေးငယ်ဆုံးယူနစ်။ စကားလုံး၊ စာလုံးတစ်ပိုင်း သို့မဟုတ် တစ်ခုတည်းသော စာလုံးတစ်လုံး ဖြစ်နိုင်သည်။
+* **Sequence**: အစဉ်လိုက် စီစဉ်ထားသော tokens များ။
+* **Coherent**: ယုတ္တိရှိရှိ ဆက်စပ်နေခြင်း၊ နားလည်လွယ်ခြင်း။
+* **Context**: စကားလုံး၊ စာကြောင်း သို့မဟုတ် အကြောင်းအရာတစ်ခုရဲ့ အဓိပ္ပာယ်ကို နားလည်စေရန် ကူညီပေးသော ပတ်ဝန်းကျင်ရှိ အချက်အလက်များ။
+* **Attention Mechanism**: Transformer မော်ဒယ်များတွင် အသုံးပြုသော နည်းစနစ်တစ်ခုဖြစ်ပြီး input sequence အတွင်းရှိ အရေးပါသော အစိတ်အပိုင်းများကို အာရုံစိုက်ပြီး ဆက်နွယ်မှုများကို သင်ယူစေသည်။
+* **BERT (Bidirectional Encoder Representations from Transformers)**: Google မှ တီထွင်ထားသော Transformer-based NLP မော်ဒယ်တစ်ခု။
+* **GPT-2 (Generative Pre-trained Transformer 2)**: OpenAI မှ တီထွင်ထားသော Transformer-based NLP မော်ဒယ်တစ်ခု။
+* **Neural Networks**: လူသားဦးနှောက်၏ လုပ်ဆောင်မှုပုံစံကို အတုယူထားသော ကွန်ပျူတာစနစ်များ။
+* **Context Length**: Large Language Model (LLM) တစ်ခုက တစ်ကြိမ်တည်း လုပ်ဆောင်နိုင်သော အများဆုံး token အရေအတွက်။
+* **Working Memory**: မော်ဒယ်က လက်ရှိလုပ်ငန်းဆောင်တာအတွက် လိုအပ်တဲ့ အချက်အလက်တွေကို ခဏတာ ထိန်းသိမ်းထားတဲ့ မှတ်ဉာဏ်။
+* **Hardware Constraints**: ကွန်ပျူတာစနစ်ရဲ့ ရုပ်ပိုင်းဆိုင်ရာ ကန့်သတ်ချက်များ (ဥပမာ- GPU memory, processing power)။
+* **Computational Costs**: ကွန်ပျူတာအရင်းအမြစ်များ (ဥပမာ- လျှပ်စစ်ဓာတ်အား၊ စက်အချိန်) အသုံးပြုခြင်းအတွက် ကုန်ကျစရိတ်။
+* **Tokenization**: input text ကို AI မော်ဒယ် နားလည်နိုင်တဲ့ tokens တွေအဖြစ် ပြောင်းလဲတဲ့ လုပ်ငန်းစဉ်။
+* **Embeddings**: tokens တွေရဲ့ အဓိပ္ပာယ်ကို ဖမ်းယူထားတဲ့ ဂဏန်းဆိုင်ရာ ကိုယ်စားပြုမှုများ။
+* **Neural Networks**: လူသားဦးနှောက်၏ လုပ်ဆောင်မှုပုံစံကို အတုယူထားသော ကွန်ပျူတာစနစ်များ။
+* **Autoregressive Process**: နောက်ထပ်ထုတ်လုပ်မယ့် output က ယခင်ထုတ်လုပ်ခဲ့တဲ့ outputs အားလုံးပေါ် မူတည်နေတဲ့ လုပ်ငန်းစဉ်။
+* **Logits**: မော်ဒယ်က နောက်ထပ် ဖြစ်နိုင်ခြေရှိတဲ့ token တစ်ခုစီအတွက် ထုတ်ပေးတဲ့ ကနဦး၊ အဆင့်မမီသေးတဲ့ ဖြစ်နိုင်ခြေတန်ဖိုးများ။
+* **Temperature Control**: LLM ရဲ့ output မှာ ကျပန်းဆန်မှု (randomness) သို့မဟုတ် တီထွင်ဖန်တီးမှု (creativity) ပမာဏကို ထိန်းညှိရန် အသုံးပြုသော parameter တစ်ခု။
+* **Top-p (Nucleus) Sampling**: နောက်ထပ် token ကို ရွေးချယ်ရာတွင် ဖြစ်နိုင်ခြေအမြင့်ဆုံး token များ၏ စုစုပေါင်းဖြစ်နိုင်ခြေ ကန့်သတ်ချက်အောက်တွင်ရှိသော token များကိုသာ ထည့်သွင်းစဉ်းစားခြင်း။
+* **Top-k Filtering**: နောက်ထပ် token ကို ရွေးချယ်ရာတွင် အဖြစ်နိုင်ဆုံး k လုံးကိုသာ ထည့်သွင်းစဉ်းစားခြင်း။
+* **Presence Penalty**: ယခင်က ပေါ်ထွက်ဖူးသော token များအတွက် ပုံသေပြစ်ဒဏ်ချမှတ်ခြင်း။
+* **Frequency Penalty**: ယခင်က ပေါ်ထွက်ဖူးသော token များအတွက် ၎င်းတို့ပေါ်ထွက်သည့် အကြိမ်အရေအတွက်အလိုက် ပြစ်ဒဏ်ကို တိုးမြှင့်ချမှတ်ခြင်း။
+* **Token Limits**: ထုတ်လုပ်မည့် token အရေအတွက်အတွက် အနည်းဆုံးနှင့် အများဆုံး ကန့်သတ်ချက်များ။
+* **Stop Sequences**: စာသားထုတ်လုပ်မှုကို ရပ်တန့်ရန် အချက်ပြသည့် သတ်မှတ်ထားသော စာသားပုံစံများ။
+* **End-of-Sequence (EOS) Token**: မော်ဒယ်က စာသားထုတ်လုပ်မှုကို ပြီးဆုံးရန် အချက်ပြသည့် အထူး token တစ်ခု။
+* **Beam Search**: စာသားထုတ်လုပ်ရာတွင် ဖြစ်နိုင်ခြေအကောင်းဆုံး sequence များစွာကို တစ်ပြိုင်နက်တည်း ရှာဖွေပြီး အကောင်းဆုံးကို ရွေးချယ်သည့် နည်းဗျူဟာ။
+* **Time to First Token (TTFT)**: LLM တစ်ခုက input prompt ကို လက်ခံရရှိပြီးနောက် ပထမဆုံး token ကို ထုတ်လုပ်ရန် ကြာမြင့်သော အချိန်။
+* **Time Per Output Token (TPOT)**: LLM တစ်ခုက နောက်ဆက်တွဲ output token တစ်ခုစီကို ထုတ်လုပ်ရန် ကြာမြင့်သော အချိန်။
+* **Throughput**: LLM စနစ်တစ်ခုက သတ်မှတ်ထားသော အချိန်ကာလတစ်ခုအတွင်း လုပ်ဆောင်နိုင်သော requests အရေအတွက်။
+* **VRAM Usage**: GPU (Graphics Processing Unit) ၏ memory အသုံးပြုမှု။
+* **KV (Key-Value) Caching**: LLM inference တွင် အကြားအချက်အလက်များကို သိုလှောင်ပြီး ပြန်လည်အသုံးပြုခြင်းဖြင့် လုပ်ဆောင်မှုအမြန်နှုန်းကို မြှင့်တင်ပေးသော နည်းပညာ။
\ No newline at end of file
diff --git a/chapters/my/chapter1/9.mdx b/chapters/my/chapter1/9.mdx
new file mode 100644
index 000000000..71141e5da
--- /dev/null
+++ b/chapters/my/chapter1/9.mdx
@@ -0,0 +1,52 @@
+# ဘက်လိုက်မှုနှင့် ကန့်သတ်ချက်များ[[bias-and-limitations]]
+
+
+
+
+
+
+ Input Text (Raw)
+
+ →
+
+ Tokenized Input
+
+
+
+
+ Context Window
(ဥပမာ- 4K tokens) +
+ (ဥပမာ- 4K tokens) +
+
+
+
+
+
+
+
+
+
+
+ Memory အသုံးပြုမှု
∝ အရှည်² +
+ ∝ အရှည်² +
+
+
+ လုပ်ဆောင်ချိန်
∝ အရှည် +
+ ∝ အရှည် +
+ +
+ +
+
+
+ဒါတွေကို အမြန်ဆုံး တစ်ခုချင်းစီ လေ့လာကြည့်ရအောင်။
+
+## Tokenizer ဖြင့် Preprocessing ပြုလုပ်ခြင်း[[preprocessing-with-a-tokenizer]]
+
+အခြား neural network များကဲ့သို့ Transformer မော်ဒယ်များသည် raw text များကို တိုက်ရိုက်လုပ်ဆောင်၍ မရပါ။ ထို့ကြောင့် ကျွန်တော်တို့ pipeline ၏ ပထမအဆင့်မှာ text inputs များကို မော်ဒယ်နားလည်နိုင်သော ဂဏန်းများအဖြစ် ပြောင်းလဲခြင်းဖြစ်သည်။ ၎င်းကို ပြုလုပ်ရန် ကျွန်တော်တို့သည် *tokenizer* ကို အသုံးပြုပါသည်။ ၎င်းသည် အောက်ပါတို့ကို လုပ်ဆောင်ရန် တာဝန်ရှိသည်-
+
+- input ကို *tokens* ဟုခေါ်သော စကားလုံးများ၊ subwords များ သို့မဟုတ် သင်္ကေတများ (ဥပမာ- ပုဒ်ဖြတ်သံ) အဖြစ် ပိုင်းခြားခြင်း
+- token တစ်ခုစီကို integer တစ်ခုသို့ တွဲချိတ်ခြင်း
+- မော်ဒယ်အတွက် အသုံးဝင်နိုင်သော အပို inputs များကို ထည့်သွင်းခြင်း
+
+ဒီ preprocessing အားလုံးကို မော်ဒယ်ကို pre-trained လုပ်ခဲ့စဉ်က အတိအကျလုပ်ခဲ့တဲ့ နည်းလမ်းအတိုင်း ပြုလုပ်ဖို့ လိုအပ်ပါတယ်။ ဒါကြောင့် ကျွန်တော်တို့ အရင်ဆုံး [Model Hub](https://huggingface.co/models) ကနေ အဲဒီအချက်အလက်တွေကို download လုပ်ဖို့ လိုပါတယ်။ ဒါကို လုပ်ဖို့အတွက် `AutoTokenizer` class နဲ့ သူ့ရဲ့ `from_pretrained()` method ကို ကျွန်တော်တို့ အသုံးပြုပါတယ်။ ကျွန်တော်တို့ model ရဲ့ checkpoint name ကို အသုံးပြုပြီး၊ ၎င်းသည် model ရဲ့ tokenizer နဲ့ ဆက်စပ်နေတဲ့ ဒေတာတွေကို အလိုအလျောက် ရယူပြီး cache လုပ်ပါလိမ့်မယ် (ဒါကြောင့် အောက်က code ကို ပထမဆုံးအကြိမ် run မှသာ download လုပ်ပါလိမ့်မယ်)။
+
+`sentiment-analysis` pipeline ရဲ့ default checkpoint က `distilbert-base-uncased-finetuned-sst-2-english` ဖြစ်တာကြောင့် (၎င်းရဲ့ model card ကို [ဒီနေရာမှာ](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) ကြည့်နိုင်ပါတယ်)၊ အောက်ပါ code ကို ကျွန်တော်တို့ run ပြုလုပ်ပေးပါတယ်။
+
+```python
+from transformers import AutoTokenizer
+
+checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+
+tokenizer ကို ရရှိပြီဆိုတာနဲ့၊ ကျွန်တော်တို့ရဲ့ စာကြောင်းတွေကို တိုက်ရိုက် ပေးပို့နိုင်ပြီး model ကို ထည့်သွင်းဖို့ အဆင်သင့်ဖြစ်နေတဲ့ dictionary တစ်ခု ပြန်ရပါလိမ့်မယ်။ လုပ်ဆောင်ဖို့ ကျန်ရှိတာကတော့ input IDs တွေရဲ့ list ကို tensors တွေအဖြစ် ပြောင်းလဲဖို့ပါပဲ။
+
+သင်ဟာ backend မှာ ဘယ် ML framework ကို အသုံးပြုလဲဆိုတာ စိုးရိမ်စရာမလိုဘဲ 🤗 Transformers ကို အသုံးပြုနိုင်ပါတယ်။ အချို့မော်ဒယ်တွေအတွက် PyTorch ဒါမှမဟုတ် Flax ဖြစ်နိုင်ပါတယ်။ သို့သော် Transformer မော်ဒယ်တွေက *tensors* တွေကိုပဲ input အဖြစ် လက်ခံပါတယ်။ tensors တွေအကြောင်းကို အခုမှ စကြားဖူးတာဆိုရင်၊ ၎င်းတို့ကို NumPy arrays တွေအဖြစ် တွေးကြည့်နိုင်ပါတယ်။ NumPy array တစ်ခုက scalar (0D)၊ vector (1D)၊ matrix (2D) သို့မဟုတ် dimension များစွာရှိနိုင်ပါတယ်။ ဒါက တကယ်တော့ tensor တစ်ခုပါပဲ။ အခြား ML frameworks တွေရဲ့ tensors တွေလည်း အလားတူပဲ အလုပ်လုပ်ပြီး၊ NumPy arrays တွေလိုပဲ လွယ်ကူစွာ instantiate လုပ်နိုင်ပါတယ်။
+
+ကျွန်တော်တို့ ပြန်လိုချင်တဲ့ tensors (PyTorch သို့မဟုတ် plain NumPy) အမျိုးအစားကို သတ်မှတ်ဖို့အတွက် `return_tensors` argument ကို အသုံးပြုနိုင်ပါတယ်။
+
+```python
+raw_inputs = [
+ "I've been waiting for a HuggingFace course my whole life.",
+ "I hate this so much!",
+]
+inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
+print(inputs)
+```
+
+padding နဲ့ truncation အကြောင်းကို အခုထိ စိတ်ပူမနေပါနဲ့၊ ဒါတွေကို နောက်မှ ရှင်းပြပါမယ်။ ဒီနေရာမှာ မှတ်ထားရမယ့် အဓိကအချက်တွေကတော့ သင်ဟာ စာကြောင်းတစ်ကြောင်း ဒါမှမဟုတ် စာကြောင်းများစွာပါတဲ့ list ကို ပေးပို့နိုင်သလို၊ သင်ပြန်လိုချင်တဲ့ tensors အမျိုးအစားကိုလည်း သတ်မှတ်နိုင်ပါတယ် (မည်သည့် type ကိုမျှ မပေးပို့ရင် list of lists အဖြစ် ရလဒ်ရပါလိမ့်မယ်)။
+
+PyTorch tensors အဖြစ် ရလဒ်တွေက အောက်ပါအတိုင်း ဖြစ်ပါတယ်။
+
+```python out
+{
+ 'input_ids': tensor([
+ [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
+ [ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
+ ]),
+ 'attention_mask': tensor([
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
+ ])
+}
+```
+
+output ကိုယ်တိုင်က `input_ids` နဲ့ `attention_mask` ဆိုတဲ့ key နှစ်ခုပါဝင်တဲ့ dictionary တစ်ခု ဖြစ်ပါတယ်။ `input_ids` မှာ integer row နှစ်ခု (စာကြောင်းတစ်ကြောင်းစီအတွက် တစ်ခု) ပါဝင်ပြီး ၎င်းတို့ဟာ စာကြောင်းတစ်ကြောင်းစီရှိ tokens တွေရဲ့ ထူးခြားတဲ့ identifiers တွေ ဖြစ်ပါတယ်။ `attention_mask` ဆိုတာ ဘာလဲဆိုတာကို ဒီအခန်းရဲ့ နောက်ပိုင်းမှာ ကျွန်တော်တို့ ရှင်းပြပါမယ်။
+
+## Model ကို ဖြတ်သန်းခြင်း[[going-through-the-model]]
+
+ကျွန်တော်တို့ tokenizer ကို လုပ်ခဲ့သလိုပဲ pre-trained model ကို download လုပ်နိုင်ပါတယ်။ 🤗 Transformers က `from_pretrained()` method ပါဝင်တဲ့ `AutoModel` class ကို ပံ့ပိုးပေးပါတယ်။
+
+```python
+from transformers import AutoModel
+
+checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
+model = AutoModel.from_pretrained(checkpoint)
+```
+
+ဒီ code snippet မှာ ကျွန်တော်တို့ဟာ ယခင်က pipeline မှာ အသုံးပြုခဲ့တဲ့ checkpoint အတူတူကို download လုပ်ပြီး model တစ်ခုကို instantiate လုပ်ခဲ့ပါတယ်။ (ဒါကို အမှန်တကယ်တော့ cache လုပ်ထားပြီးသား ဖြစ်သင့်ပါတယ်)။
+
+ဒီ architecture မှာ base Transformer module သာ ပါဝင်ပါတယ်- inputs အချို့ကို ပေးလိုက်တဲ့အခါ ၎င်းသည် *hidden states* ဟုခေါ်သော အရာများကို ထုတ်ပေးပါတယ်။ ၎င်းတို့ကို *features* ဟုလည်း ခေါ်ပါတယ်။ model input တစ်ခုစီအတွက် **Transformer model က အဲဒီ input ကို အကြောင်းအရာအရ နားလည်ထားမှုကို ကိုယ်စားပြုတဲ့ high-dimensional vector တစ်ခုကို** ကျွန်တော်တို့ ပြန်ရပါလိမ့်မယ်။
+
+ဒါကို နားမလည်ရင် စိတ်မပူပါနဲ့။ ဒါတွေကို နောက်မှ အားလုံးရှင်းပြပါမယ်။
+
+ဒီ hidden states တွေက သူ့ဘာသာသူ အသုံးဝင်နိုင်ပေမယ့်၊ ၎င်းတို့ဟာ များသောအားဖြင့် *head* လို့ခေါ်တဲ့ model ရဲ့ နောက်ထပ်အစိတ်အပိုင်းတစ်ခုရဲ့ inputs တွေ ဖြစ်ပါတယ်။ [Chapter 1](/course/chapter1) မှာ မတူညီတဲ့ လုပ်ငန်းတာဝန်တွေကို architecture တူတူနဲ့ လုပ်ဆောင်နိုင်ခဲ့ပေမယ့်၊ ဒီလုပ်ငန်းတာဝန်တစ်ခုစီမှာ ၎င်းနဲ့ ဆက်စပ်နေတဲ့ head တစ်ခုစီ ရှိပါတယ်။
+
+### High-dimensional vector တစ်ခုလား။[[a-high-dimensional-vector]]
+
+Transformer module ကနေ ထုတ်ပေးတဲ့ vector ဟာ များသောအားဖြင့် ကြီးမားပါတယ်။ ဒါက အများအားဖြင့် dimensions သုံးခု ရှိပါတယ်-
+
+- **Batch size**: တစ်ကြိမ်တည်း လုပ်ဆောင်တဲ့ sequence အရေအတွက် (ကျွန်တော်တို့ ဥပမာမှာ ၂ ခု)။
+- **Sequence length**: sequence ရဲ့ ဂဏန်းဆိုင်ရာ ကိုယ်စားပြုမှုရဲ့ အရှည် (ကျွန်တော်တို့ ဥပမာမှာ ၁၆ ခု)။
+- **Hidden size**: model input တစ်ခုစီရဲ့ vector dimension။
+
+နောက်ဆုံးတန်ဖိုးကြောင့် "high dimensional" လို့ ခေါ်တာ ဖြစ်ပါတယ်။ hidden size က အလွန်ကြီးမားနိုင်ပါတယ် (768 က ပိုသေးငယ်တဲ့ မော်ဒယ်တွေအတွက် အများအားဖြင့်ဖြစ်ပြီး၊ ပိုကြီးတဲ့ မော်ဒယ်တွေမှာ ဒါက 3072 ဒါမှမဟုတ် ပိုများနိုင်ပါတယ်)။
+
+ကျွန်တော်တို့ preprocessing လုပ်ထားတဲ့ inputs တွေကို model ကို ပေးပို့ကြည့်ရင် ဒါကို တွေ့နိုင်ပါတယ်။
+
+```python
+outputs = model(**inputs)
+print(outputs.last_hidden_state.shape)
+```
+
+```python out
+torch.Size([2, 16, 768])
+```
+
+🤗 Transformers မော်ဒယ်တွေရဲ့ outputs တွေဟာ `namedtuple` တွေ ဒါမှမဟုတ် dictionaries တွေလို အလုပ်လုပ်တယ်ဆိုတာကို သတိပြုပါ။ attribute တွေ (ကျွန်တော်တို့ လုပ်ခဲ့သလို) ဒါမှမဟုတ် key ( `outputs["last_hidden_state"]` ) နဲ့ ဒါမှမဟုတ် သင်ရှာနေတဲ့အရာ ဘယ်နေရာမှာရှိတယ်ဆိုတာ အတိအကျသိရင် index ( `outputs[0]` ) နဲ့ပါ ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။
+
+### Model heads: ဂဏန်းတွေကနေ အဓိပ္ပာယ်ထုတ်ယူခြင်း[[model-heads-making-sense-out-of-numbers]]
+
+Model heads တွေက hidden states တွေရဲ့ high-dimensional vector ကို input အဖြစ် ယူပြီး ၎င်းတို့ကို မတူညီတဲ့ dimension တစ်ခုပေါ်သို့ project လုပ်ပါတယ်။ ၎င်းတို့ဟာ များသောအားဖြင့် linear layers တစ်ခု ဒါမှမဟုတ် အနည်းငယ်နဲ့ ဖွဲ့စည်းထားပါတယ်-
+
+
+
+
+ +
+ +
+
+
+Transformer model ရဲ့ output ကို model head ကို တိုက်ရိုက်ပို့ပြီး လုပ်ဆောင်ပါတယ်။
+
+ဒီပုံမှာ မော်ဒယ်ကို embeddings layer နဲ့ နောက်ဆက်တွဲ layers တွေနဲ့ ကိုယ်စားပြုထားပါတယ်။ embeddings layer က tokenized input ထဲက input ID တစ်ခုစီကို ၎င်းနဲ့ ဆက်စပ်နေတဲ့ token ကို ကိုယ်စားပြုတဲ့ vector တစ်ခုအဖြစ် ပြောင်းလဲပေးပါတယ်။ နောက်ဆက်တွဲ layers တွေက attention mechanism ကို အသုံးပြုပြီး အဲဒီ vectors တွေကို စီမံခန့်ခွဲကာ စာကြောင်းတွေရဲ့ နောက်ဆုံးကိုယ်စားပြုမှုကို ထုတ်ပေးပါတယ်။
+
+🤗 Transformers မှာ မတူညီတဲ့ architecture များစွာ ရရှိနိုင်ပြီး၊ တစ်ခုချင်းစီကို သီးခြားလုပ်ငန်းတစ်ခုကို ဖြေရှင်းဖို့ ဒီဇိုင်းထုတ်ထားပါတယ်။ အောက်ပါတို့ကတော့ မပြည့်စုံသေးသော စာရင်းတစ်ခု ဖြစ်ပါတယ်-
+
+- `*Model` (hidden states များကို ပြန်ရယူခြင်း)
+- `*ForCausalLM`
+- `*ForMaskedLM`
+- `*ForMultipleChoice`
+- `*ForQuestionAnswering`
+- `*ForSequenceClassification`
+- `*ForTokenClassification`
+- နဲ့ အခြားအရာများ 🤗
+
+ကျွန်တော်တို့ရဲ့ ဥပမာအတွက်၊ sequence classification head ပါဝင်တဲ့ မော်ဒယ်တစ်ခု လိုအပ်ပါလိမ့်မယ် (စာကြောင်းတွေကို positive သို့မဟုတ် negative အဖြစ် ခွဲခြားသတ်မှတ်နိုင်ဖို့)။ ဒါကြောင့် ကျွန်တော်တို့ဟာ `AutoModel` class ကို အမှန်တကယ် အသုံးပြုမှာ မဟုတ်ဘဲ `AutoModelForSequenceClassification` ကို အသုံးပြုပါမယ်။
+
+```python
+from transformers import AutoModelForSequenceClassification
+
+checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
+model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
+outputs = model(**inputs)
+```
+
+အခု outputs တွေရဲ့ shape ကို ကြည့်လိုက်ရင်၊ dimensionality က အများကြီး နိမ့်သွားပါလိမ့်မယ်၊ model head က ယခင်က ကျွန်တော်တို့ တွေ့ခဲ့တဲ့ high-dimensional vectors တွေကို input အဖြစ် ယူပြီး၊ တန်ဖိုးနှစ်ခု (label တစ်ခုစီအတွက် တစ်ခု) ပါဝင်တဲ့ vectors တွေကို ထုတ်ပေးပါတယ်။
+
+```python
+print(outputs.logits.shape)
+```
+
+```python out
+torch.Size([2, 2])
+```
+
+ကျွန်တော်တို့မှာ စာကြောင်းနှစ်ကြောင်းနဲ့ label နှစ်ခုပဲ ရှိတာကြောင့်၊ ကျွန်တော်တို့ model ကနေ ရရှိတဲ့ ရလဒ်ဟာ 2 x 2 shape ဖြစ်ပါတယ်။
+
+## Output ကို Postprocessing ပြုလုပ်ခြင်း[[postprocessing-the-output]]
+
+ကျွန်တော်တို့ model ကနေ output အဖြစ် ရရှိတဲ့ တန်ဖိုးတွေက သူ့ဘာသာသူ အဓိပ္ပာယ်ရှိတာ မဟုတ်ပါဘူး။ ကြည့်ကြည့်ရအောင်။
+
+```python
+print(outputs.logits)
+```
+
+```python out
+tensor([[-1.5607, 1.6123],
+ [ 4.1692, -3.3464]], grad_fn=
+
+
+  +
+  +
+
+
+text ကို ပိုင်းခြားဖို့ နည်းလမ်းအမျိုးမျိုး ရှိပါတယ်။ ဥပမာအားဖြင့်၊ Python ရဲ့ `split()` function ကို အသုံးပြုပြီး whitespace ကို သုံးကာ text ကို စကားလုံးတွေအဖြစ် tokenize လုပ်ဆောင်နိုင်ပါတယ်။
+
+```py
+tokenized_text = "Jim Henson was a puppeteer".split()
+print(tokenized_text)
+```
+
+```python out
+['Jim', 'Henson', 'was', 'a', 'puppeteer']
+```
+
+punctuation အတွက် အပိုစည်းမျဉ်းတွေရှိတဲ့ word tokenizer အမျိုးအစားတွေလည်း ရှိပါသေးတယ်။ ဒီလို tokenizer အမျိုးအစားနဲ့ဆိုရင် ကျွန်တော်တို့ဟာ အတော်လေး ကြီးမားတဲ့ "vocabularies" တွေနဲ့ အဆုံးသတ်နိုင်ပါတယ်။ vocabulary ဆိုတာက ကျွန်တော်တို့ရဲ့ corpus မှာရှိတဲ့ သီးခြား tokens စုစုပေါင်းအရေအတွက်နဲ့ သတ်မှတ်ပါတယ်။
+
+စကားလုံးတစ်ခုစီကို ID တစ်ခုစီ ခွဲပေးပြီး 0 ကနေစပြီး vocabulary အရွယ်အစားအထိ သတ်မှတ်ပေးပါတယ်။ model က ဒီ IDs တွေကို စကားလုံးတစ်ခုစီကို ခွဲခြားသိမြင်ဖို့ အသုံးပြုပါတယ်။
+
+ကျွန်တော်တို့ဟာ word-based tokenizer တစ်ခုနဲ့ ဘာသာစကားတစ်ခုကို အပြည့်အစုံ ကာဗာလုပ်ချင်တယ်ဆိုရင်၊ ဘာသာစကားထဲက စကားလုံးတစ်ခုစီအတွက် identifier တစ်ခုစီ ရှိဖို့ လိုအပ်ပါလိမ့်မယ်။ ဒါက ကြီးမားတဲ့ tokens အရေအတွက်ကို ထုတ်ပေးပါလိမ့်မယ်။ ဥပမာအားဖြင့်၊ English ဘာသာစကားမှာ စကားလုံး ၅၀၀,၀၀၀ ကျော်ရှိတာကြောင့် စကားလုံးတစ်ခုစီကနေ input ID တစ်ခုဆီ map လုပ်ဖို့အတွက် ID အရေအတွက် အများကြီးကို မှတ်ထားဖို့ လိုအပ်ပါလိမ့်မယ်။ ဒါ့အပြင် "dog" လို စကားလုံးတွေကို "dogs" လို စကားလုံးတွေနဲ့ မတူအောင် ကိုယ်စားပြုထားပြီး၊ "dog" နဲ့ "dogs" တို့ဟာ ဆင်တူတယ်ဆိုတာကို model က အစပိုင်းမှာ သိဖို့ နည်းလမ်းမရှိပါဘူး- ၎င်းက စကားလုံးနှစ်ခုကို ဆက်စပ်မှုမရှိဘူးလို့ ခွဲခြားသတ်မှတ်ပါလိမ့်မယ်။ "run" နဲ့ "running" လို အခြားဆင်တူစကားလုံးတွေနဲ့လည်း အတူတူပါပဲ၊ model က အစပိုင်းမှာ ဆင်တူတယ်လို့ မမြင်ပါဘူး။
+
+နောက်ဆုံးအနေနဲ့၊ ကျွန်တော်တို့ရဲ့ vocabulary မှာ မပါဝင်တဲ့ စကားလုံးတွေကို ကိုယ်စားပြုဖို့ custom token တစ်ခု လိုအပ်ပါတယ်။ ဒါကို "unknown" token လို့ ခေါ်ပြီး၊ မကြာခဏဆိုသလို "[UNK]" သို့မဟုတ် "<unk>" နဲ့ ကိုယ်စားပြုပါတယ်။ tokenizer က ဒီ tokens တွေ အများကြီး ထုတ်ပေးနေတာကို သင်တွေ့ရရင် ဒါက မကောင်းတဲ့ လက္ခဏာတစ်ခုပါ။ ဘာလို့လဲဆိုတော့ ၎င်းက စကားလုံးတစ်ခုရဲ့ အဓိပ္ပာယ်ရှိတဲ့ ကိုယ်စားပြုမှုကို ရယူနိုင်ခြင်းမရှိဘဲ၊ သင်ဟာ အချက်အလက်တွေကို ဆုံးရှုံးနေတာကြောင့်ပါပဲ။ vocabulary ကို ဖန်တီးတဲ့အခါ ရည်ရွယ်ချက်ကတော့ tokenizer က unknown token အဖြစ် စကားလုံးအနည်းဆုံးကို tokenized လုပ်နိုင်အောင် ဖန်တီးဖို့ပါပဲ။
+
+unknown tokens အရေအတွက်ကို လျှော့ချဖို့ နည်းလမ်းတစ်ခုကတော့ တစ်ဆင့်နိမ့်ဆင်းပြီး *character-based* tokenizer ကို အသုံးပြုဖို့ပါပဲ။
+
+## Character-based[[character-based]]
+
+
+
+
+  +
+  +
+
+
+ဒီနည်းလမ်းကလည်း ပြီးပြည့်စုံတာ မဟုတ်ပါဘူး။ ကိုယ်စားပြုမှုဟာ စကားလုံးတွေအစား characters တွေပေါ် အခြေခံထားတာကြောင့်၊ တစ်ခုတည်းသော character တစ်ခုက သူ့ဘာသာသူ အဓိပ္ပာယ်သိပ်မရှိဘူးလို့ အလိုလိုဆိုနိုင်ပါတယ်။ စကားလုံးတွေနဲ့ဆိုရင်တော့ အဲလို မဟုတ်ပါဘူး။ ဒါပေမယ့် ဒါက ဘာသာစကားပေါ် မူတည်ပြီး ကွဲပြားပါတယ်။ ဥပမာအားဖြင့်၊ တရုတ်ဘာသာစကားမှာ character တစ်ခုစီက Latin ဘာသာစကားက character တစ်ခုထက် အချက်အလက် ပိုသယ်ဆောင်ပါတယ်။
+
+စဉ်းစားရမယ့် နောက်ထပ်အချက်တစ်ခုကတော့ ကျွန်တော်တို့ရဲ့ model က လုပ်ဆောင်ရမယ့် tokens ပမာဏ အများကြီးနဲ့ အဆုံးသတ်ရပါလိမ့်မယ်။ word-based tokenizer တစ်ခုနဲ့ဆိုရင် စကားလုံးတစ်လုံးဟာ token တစ်ခုတည်းသာ ဖြစ်ပေမယ့်၊ characters တွေအဖြစ် ပြောင်းလဲလိုက်တဲ့အခါ token ၁၀ ခု သို့မဟုတ် ပိုများတဲ့အထိ အလွယ်တကူ ဖြစ်သွားနိုင်ပါတယ်။
+
+နှစ်ခုစလုံးရဲ့ အကောင်းဆုံးကို ရယူဖို့အတွက်၊ ချဉ်းကပ်မှုနှစ်ခုကို ပေါင်းစပ်ထားတဲ့ တတိယနည်းပညာဖြစ်တဲ့ *subword tokenization* ကို ကျွန်တော်တို့ အသုံးပြုနိုင်ပါတယ်။
+
+## Subword Tokenization[[subword-tokenization]]
+
+
+
+
+  +
+  +
+
+
+ဒီ subwords တွေဟာ အဓိပ္ပာယ်ဆိုင်ရာ အချက်အလက်များစွာကို ပေးစွမ်းပါတယ်။ ဥပမာအားဖြင့်၊ အထက်ပါ ဥပမာမှာ "tokenization" ကို "token" နဲ့ "ization" အဖြစ် ပိုင်းခြားခဲ့ပါတယ်။ ဒါတွေဟာ အဓိပ္ပာယ်ရှိတဲ့ tokens နှစ်ခုဖြစ်ပြီး နေရာလည်းသက်သာပါတယ် (ရှည်လျားတဲ့ စကားလုံးတစ်လုံးကို ကိုယ်စားပြုဖို့ tokens နှစ်ခုပဲ လိုအပ်ပါတယ်)။ ဒါက ကျွန်တော်တို့ကို သေးငယ်တဲ့ vocabularies တွေနဲ့ ကောင်းမွန်တဲ့ coverage ကို ပေးနိုင်ပြီး unknown tokens တွေလည်း မရှိသလောက်ပါပဲ။
+
+ဒီနည်းလမ်းက Turkish လိုမျိုး agglutinative languages တွေမှာ အထူးအသုံးဝင်ပါတယ်။ ဘာလို့လဲဆိုတော့ subwords တွေကို ဆက်စပ်ပြီး (နီးပါး) ပမာဏအကန့်အသတ်မရှိ ရှည်လျားတဲ့ ရှုပ်ထွေးတဲ့ စကားလုံးတွေကို ဖွဲ့စည်းနိုင်လို့ပါ။
+
+### အခြားနည်းလမ်းများ![[and-more]]
+
+အံ့သြစရာမလိုဘဲ၊ အခြားနည်းပညာများစွာ ရှိပါသေးတယ်။ အချို့ကို ဖော်ပြရရင်-
+
+- Byte-level BPE, GPT-2 မှာ အသုံးပြုထားပါတယ်။
+- WordPiece, BERT မှာ အသုံးပြုထားပါတယ်။
+- SentencePiece သို့မဟုတ် Unigram, multilingual models အများအပြားမှာ အသုံးပြုထားပါတယ်။
+
+Tokenizer တွေ ဘယ်လိုအလုပ်လုပ်တယ်ဆိုတဲ့ အသိပညာဟာ API နဲ့ စတင်ဖို့ လုံလောက်သင့်ပါပြီ။
+
+## Loading နှင့် Saving[[loading-and-saving]]
+
+Tokenizers တွေကို load လုပ်တာနဲ့ save လုပ်တာက model တွေနဲ့ လုပ်တာလိုပဲ ရိုးရှင်းပါတယ်။ တကယ်တော့၊ ၎င်းဟာ `from_pretrained()` နဲ့ `save_pretrained()` ဆိုတဲ့ methods နှစ်ခုတည်းပေါ် အခြေခံထားတာပါ။ ဒီ methods တွေက tokenizer အသုံးပြုတဲ့ algorithm (model ရဲ့ architecture နဲ့ ဆင်တူပါတယ်) နဲ့ ၎င်းရဲ့ vocabulary (model ရဲ့ weights နဲ့ ဆင်တူပါတယ်) နှစ်ခုလုံးကို load သို့မဟုတ် save လုပ်ပေးပါလိမ့်မယ်။
+
+BERT နဲ့ တူညီတဲ့ checkpoint နဲ့ train လုပ်ထားတဲ့ BERT tokenizer ကို load လုပ်တာက model ကို load လုပ်တာနဲ့ နည်းလမ်းတူတူပါပဲ၊ ဒါပေမယ့် ကျွန်တော်တို့က `BertTokenizer` class ကို အသုံးပြုရုံပါပဲ။
+
+```py
+from transformers import BertTokenizer
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+```
+
+`AutoModel` နဲ့ ဆင်တူစွာ၊ `AutoTokenizer` class က checkpoint name ကို အခြေခံပြီး library ထဲက မှန်ကန်တဲ့ tokenizer class ကို ရယူပါလိမ့်မယ်၊ ပြီးတော့ မည်သည့် checkpoint နဲ့မဆို တိုက်ရိုက် အသုံးပြုနိုင်စေပါတယ်။
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+```
+
+အခု ကျွန်တော်တို့ tokenizer ကို ယခင်အပိုင်းမှာ ပြသခဲ့သလို အသုံးပြုနိုင်ပါပြီ။
+
+```python
+tokenizer("Using a Transformer network is simple")
+```
+
+```python out
+{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+tokenizer ကို save လုပ်တာက model ကို save လုပ်တာနဲ့ အတူတူပါပဲ။
+
+```py
+tokenizer.save_pretrained("directory_on_my_computer")
+```
+
+`token_type_ids` အကြောင်းကို [Chapter 3](/course/chapter3) မှာ ပိုပြီး အသေးစိတ် ဆွေးနွေးပါမယ်။ `attention_mask` key ကိုတော့ နောက်မှ အနည်းငယ် ရှင်းပြပါမယ်။ ပထမဆုံးအနေနဲ့ `input_ids` တွေ ဘယ်လို ထုတ်လုပ်ခဲ့လဲဆိုတာ ကြည့်ရအောင်။ ဒါကို လုပ်ဖို့ tokenizer ရဲ့ ကြားခံ methods တွေကို ကြည့်ဖို့ လိုအပ်ပါလိမ့်မယ်။
+
+## Encoding[[encoding]]
+
+
+
+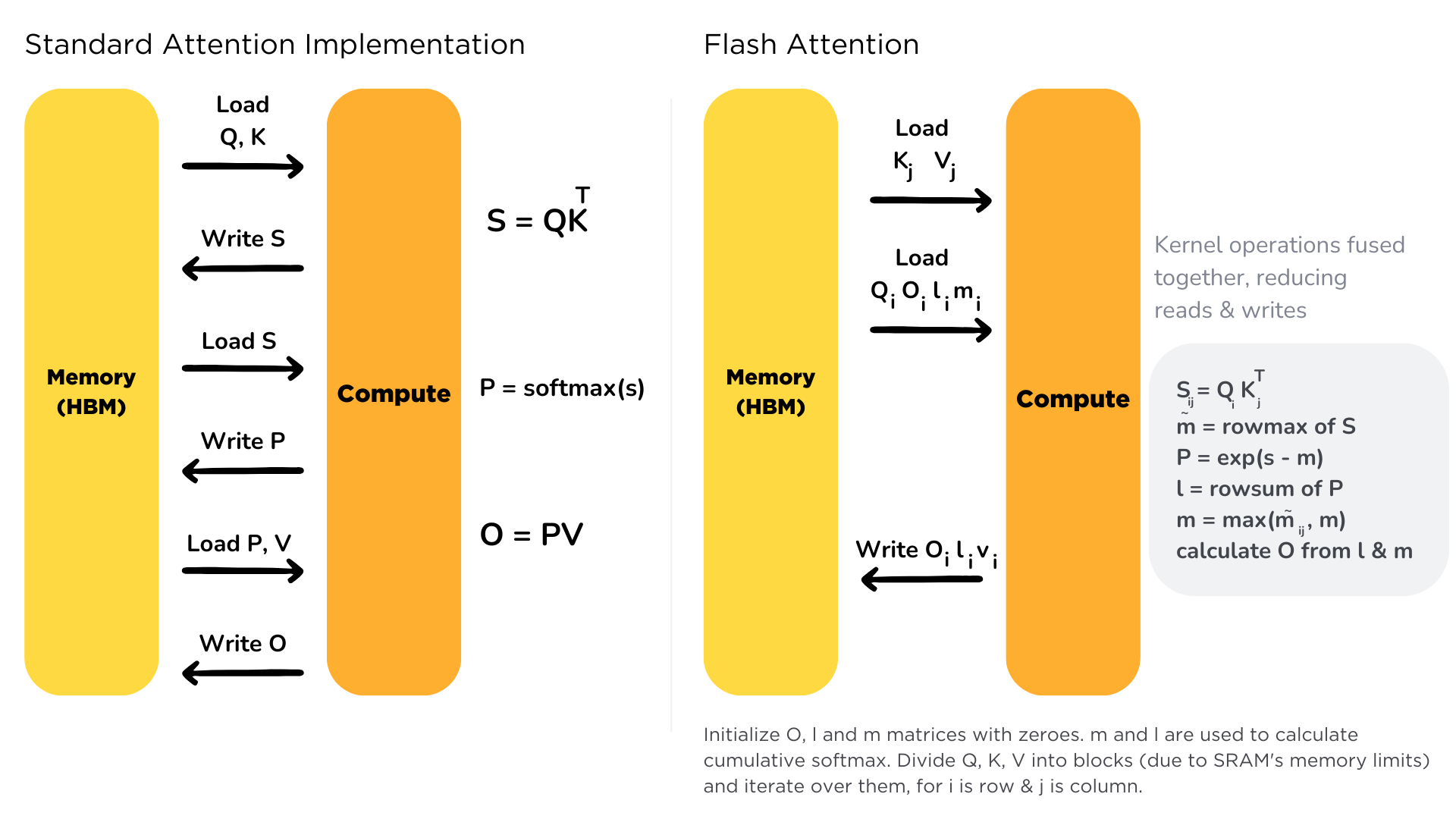 +
+
+
+pad",
+ explain: "မှားပါတယ်။ Padding က အလွန်အသုံးဝင်ပေမယ့် tokenizer API ရဲ့ တစ်စိတ်တစ်ပိုင်းမျှသာ ဖြစ်ပါတယ်။"
+ },
+ {
+ text: "tokenize",
+ explain: "`tokenize` method ဟာ အသုံးဝင်ဆုံး methods တွေထဲက တစ်ခုဖြစ်ပေမယ့် tokenizer API ရဲ့ အဓိက အစိတ်အပိုင်းတော့ မဟုတ်ပါဘူး။"
+ }
+ ]}
+/>
+
+### 9. ဒီ code sample မှာ `result` variable က ဘာတွေ ပါဝင်သလဲ။
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+result = tokenizer.tokenize("Hello!")
+```
+
+
+ +
+
+
+ကျွန်တော်တို့ `camembert-base` checkpoint ကို စမ်းသပ်ဖို့ ရွေးချယ်လိုက်ပါတယ်။ `camembert-base` ဆိုတဲ့ identifier တစ်ခုတည်းကပဲ အဲဒါကို စတင်အသုံးပြုဖို့ လိုအပ်တဲ့ အရာအားလုံးပါပဲ! ယခင်အခန်းတွေမှာ သင်တွေ့ခဲ့ရတဲ့အတိုင်း၊ `pipeline()` function ကို အသုံးပြုပြီး instantiate လုပ်ဆောင်နိုင်ပါတယ်။
+
+```py
+from transformers import pipeline
+
+camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
+results = camembert_fill_mask("Le camembert est
+
+ +
+
+
+model architecture ကို တိုက်ရိုက်အသုံးပြုပြီး checkpoint ကိုလည်း instantiate လုပ်နိုင်ပါတယ်။
+
+{#if fw === 'pt'}
+```py
+from transformers import CamembertTokenizer, CamembertForMaskedLM
+
+tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
+model = CamembertForMaskedLM.from_pretrained("camembert-base")
+```
+
+သို့သော်လည်း၊ [`Auto*` classes](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes) တွေကို အသုံးပြုဖို့ ကျွန်တော်တို့ အကြံပြုပါတယ်၊ ဘာလို့လဲဆိုတော့ ဒါတွေဟာ architecture-agnostic ဖြစ်အောင် ဒီဇိုင်းထုတ်ထားလို့ပါပဲ။ ယခင် code sample က CamemBERT architecture မှာ load လုပ်နိုင်တဲ့ checkpoints တွေကိုသာ ကန့်သတ်ထားပေမယ့်၊ `Auto*` classes တွေကို အသုံးပြုခြင်းက checkpoints တွေ ပြောင်းတာကို ရိုးရှင်းစေပါတယ်။
+
+```py
+from transformers import AutoTokenizer, AutoModelForMaskedLM
+
+tokenizer = AutoTokenizer.from_pretrained("camembert-base")
+model = AutoModelForMaskedLM.from_pretrained("camembert-base")
+```
+{:else}
+```py
+from transformers import CamembertTokenizer, TFCamembertForMaskedLM
+
+tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
+model = TFCamembertForMaskedLM.from_pretrained("camembert-base")
+```
+
+သို့သော်လည်း၊ [`TFAuto*` classes](https://huggingface.co/transformers/model_doc/auto?highlight=auto#auto-classes) တွေကို အသုံးပြုဖို့ ကျွန်တော်တို့ အကြံပြုပါတယ်၊ ဘာလို့လဲဆိုတော့ ဒါတွေဟာ architecture-agnostic ဖြစ်အောင် ဒီဇိုင်းထုတ်ထားလို့ပါပဲ။ ယခင် code sample က CamemBERT architecture မှာ load လုပ်နိုင်တဲ့ checkpoints တွေကိုသာ ကန့်သတ်ထားပေမယ့်၊ `TFAuto*` classes တွေကို အသုံးပြုခြင်းက checkpoints တွေ ပြောင်းတာကို ရိုးရှင်းစေပါတယ်။
+
+```py
+from transformers import AutoTokenizer, TFAutoModelForMaskedLM
+
+tokenizer = AutoTokenizer.from_pretrained("camembert-base")
+model = TFAutoModelForMaskedLM.from_pretrained("camembert-base")
+```
+{/if}
+
+
+
+  +
+
+
+{:else}
+
+သင် model ကို train လုပ်ဖို့ Keras ကို အသုံးပြုနေတယ်ဆိုရင်၊ ဒါကို Hub ကို upload လုပ်ဖို့ အလွယ်ကူဆုံးနည်းလမ်းက `model.fit()` ကို ခေါ်တဲ့အခါ `PushToHubCallback` တစ်ခုကို ထည့်ပေးဖို့ပါပဲ။
+
+```py
+from transformers import PushToHubCallback
+
+callback = PushToHubCallback(
+ "bert-finetuned-mrpc", save_strategy="epoch", tokenizer=tokenizer
+)
+```
+
+ပြီးရင် သင့် `model.fit()` ကို ခေါ်တဲ့အခါ `callbacks=[callback]` ကို ထည့်သွင်းသင့်ပါတယ်။ callback က သင့် model ကို သိမ်းဆည်းတိုင်း (ဒီနေရာမှာတော့ epoch တိုင်း) သင့် namespace ထဲက repository တစ်ခုမှာ Hub ကို upload လုပ်ပါလိမ့်မယ်။ အဲဒီ repository ကို သင်ရွေးချယ်ခဲ့တဲ့ output directory (ဒီနေရာမှာ `bert-finetuned-mrpc`) အတိုင်း နာမည်ပေးထားပါလိမ့်မယ်။ ဒါပေမယ့် `hub_model_id = "a_different_name"` နဲ့ မတူညီတဲ့ နာမည်တစ်ခုကို ရွေးချယ်နိုင်ပါတယ်။
+
+သင်အဖွဲ့ဝင်ဖြစ်တဲ့ organization တစ်ခုကို သင့် model ကို upload လုပ်ဖို့အတွက် `hub_model_id = "my_organization/my_repo_name"` နဲ့ ထည့်ပေးလိုက်ရုံပါပဲ။
+
+{/if}
+
+အနိမ့်အဆင့်မှာဆိုရင် Model Hub ကို model တွေ၊ tokenizers တွေနဲ့ configuration objects တွေမှာရှိတဲ့ ၎င်းတို့ရဲ့ `push_to_hub()` method ကနေ တိုက်ရိုက် ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။ ဒီ method က repository ဖန်တီးတာနဲ့ model နဲ့ tokenizer files တွေကို repository ကို တိုက်ရိုက် push လုပ်တာ နှစ်ခုလုံးကို လုပ်ဆောင်ပေးပါတယ်။ အောက်မှာ ကျွန်တော်တို့တွေ့ရမယ့် API နဲ့ မတူဘဲ၊ manual handling လုံးဝမလိုအပ်ပါဘူး။
+
+ဒါက ဘယ်လိုအလုပ်လုပ်တယ်ဆိုတာ သိဖို့အတွက်၊ ပထမဆုံး model တစ်ခုနဲ့ tokenizer တစ်ခုကို initialize လုပ်ကြရအောင်...
+
+{#if fw === 'pt'}
+```py
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+checkpoint = "camembert-base"
+
+model = AutoModelForMaskedLM.from_pretrained(checkpoint)
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+{:else}
+```py
+from transformers import TFAutoModelForMaskedLM, AutoTokenizer
+
+checkpoint = "camembert-base"
+
+model = TFAutoModelForMaskedLM.from_pretrained(checkpoint)
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+{/if}
+
+ဒီ models တွေနဲ့ သင်ဘာမဆိုလုပ်ဆောင်နိုင်ပါတယ်၊ tokenizer ကို tokens တွေထည့်တာ၊ model ကို train လုပ်တာ၊ fine-tune လုပ်တာ။ ရရှိလာတဲ့ model, weights, နဲ့ tokenizer တွေနဲ့ သင်ကျေနပ်သွားတာနဲ့၊ `model` object မှာ တိုက်ရိုက်ရရှိနိုင်တဲ့ `push_to_hub()` method ကို အကျိုးရှိရှိ အသုံးပြုနိုင်ပါတယ်။
+
+```py
+model.push_to_hub("dummy-model")
+```
+
+ဒါက သင့် profile မှာ `dummy-model` repository အသစ်တစ်ခုကို ဖန်တီးပေးပြီး သင့် model files တွေနဲ့ ဖြည့်ပေးပါလိမ့်မယ်။
+tokenizer နဲ့လည်း အတူတူလုပ်ပါ၊ ဒါမှ files အားလုံးဟာ ဒီ repository မှာ ရရှိနိုင်ပါလိမ့်မယ်။
+
+```py
+tokenizer.push_to_hub("dummy-model")
+```
+
+သင် organization တစ်ခုမှာ အဖွဲ့ဝင်ဆိုရင်၊ အဲဒီ organization ရဲ့ namespace ကို upload လုပ်ဖို့ `organization` argument ကို သတ်မှတ်ပေးလိုက်ရုံပါပဲ။
+
+```py
+tokenizer.push_to_hub("dummy-model", organization="huggingface")
+```
+
+သင် သီးခြား Hugging Face token တစ်ခုကို အသုံးပြုချင်တယ်ဆိုရင်၊ `push_to_hub()` method ကိုလည်း သတ်မှတ်ပေးနိုင်ပါတယ်။
+
+```py
+tokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token="
+
+ +
+
+{:else}
+
+
+ +
+
+{/if}
+
+
+
+ +
+
+
+ပထမဆုံး၊ repository ရဲ့ ပိုင်ရှင်ကို သတ်မှတ်ပါ၊ ဒါက သင်ကိုယ်တိုင် ဒါမှမဟုတ် သင်နဲ့ ဆက်စပ်နေတဲ့ organization တစ်ခုခု ဖြစ်နိုင်ပါတယ်။ သင် organization တစ်ခုကို ရွေးချယ်ရင်၊ model ကို organization ရဲ့ page မှာ ဖော်ပြထားမှာဖြစ်ပြီး organization ရဲ့ အဖွဲ့ဝင်တိုင်းက repository ကို ပံ့ပိုးကူညီနိုင်ပါလိမ့်မယ်။
+
+နောက်တစ်ခုကတော့ သင့် model ရဲ့ နာမည်ကို ထည့်သွင်းပါ။ ဒါက repository ရဲ့ နာမည်လည်း ဖြစ်ပါလိမ့်မယ်။ နောက်ဆုံးအနေနဲ့၊ သင်ရဲ့ model ကို public ဒါမှမဟုတ် private ဖြစ်စေချင်လားဆိုတာ သတ်မှတ်နိုင်ပါတယ်။ Private models တွေကို အများပြည်သူမြင်ကွင်းကနေ ဝှက်ထားပါတယ်။
+
+သင့် model repository ကို ဖန်တီးပြီးတာနဲ့၊ အောက်ပါကဲ့သို့ page တစ်ခုကို သင်တွေ့ရပါလိမ့်မယ်။
+
+
+
+ +
+
+
+ဒီနေရာမှာ သင့် model ကို လက်ခံထားမှာ ဖြစ်ပါတယ်။ ဒါကို စတင်ဖြည့်ဆည်းဖို့၊ web interface ကနေ README file တစ်ခုကို တိုက်ရိုက်ထည့်သွင်းနိုင်ပါတယ်။
+
+
+
+ +
+
+
+README file က Markdown နဲ့ ရေးထားပါတယ်၊ လွတ်လပ်စွာ ဖန်တီးနိုင်ပါတယ်။ ဒီအခန်းရဲ့ တတိယအပိုင်းက model card တစ်ခုတည်ဆောက်ခြင်းအတွက် ရည်ရွယ်ပါတယ်။ ဒါတွေက သင့် model ကို တန်ဖိုးရှိစေရာမှာ အရေးပါပါတယ်၊ ဘာလို့လဲဆိုတော့ ဒါတွေက သင့် model က ဘာတွေလုပ်နိုင်လဲဆိုတာကို တခြားသူတွေကို ပြောပြတဲ့ နေရာဖြစ်လို့ပါပဲ။
+
+"Files and versions" tab ကို သင်ကြည့်လိုက်ရင်၊ အဲဒီမှာ files အများကြီး မရှိသေးတာကို သင်တွေ့ရပါလိမ့်မယ်၊ သင်အခုမှ ဖန်တီးခဲ့တဲ့ *README.md* နဲ့ ကြီးမားတဲ့ files တွေကို ခြေရာခံထားတဲ့ *.gitattributes* file ပဲ ရှိပါသေးတယ်။
+
+
+
+ +
+
+
+files အသစ်တွေ ဘယ်လိုထည့်ရမလဲဆိုတာကို နောက်မှာ ကျွန်တော်တို့ လေ့လာသွားပါမယ်။
+
+## Model Files များကို Upload လုပ်ခြင်း[[uploading-the-model-files]]
+
+Hugging Face Hub မှာ files တွေကို စီမံခန့်ခွဲတဲ့ system က ပုံမှန် files တွေအတွက် git ကို အခြေခံထားပြီး၊ ကြီးမားတဲ့ files တွေအတွက် git-lfs ([Git Large File Storage](https://git-lfs.github.com/)) ကို အခြေခံထားပါတယ်။
+
+နောက်အပိုင်းမှာ Hub ကို files တွေ upload လုပ်ဖို့ နည်းလမ်းသုံးခုကို ကျွန်တော်တို့ လေ့လာသွားပါမယ်- `huggingface_hub` ကို အသုံးပြုခြင်းနဲ့ git commands တွေကို အသုံးပြုခြင်းတို့ ဖြစ်ပါတယ်။
+
+### `upload_file` ချဉ်းကပ်မှု[[the-uploadfile-approach]]
+
+`upload_file` ကို အသုံးပြုတာက သင့် system မှာ git နဲ့ git-lfs install လုပ်ထားဖို့ မလိုအပ်ပါဘူး။ ဒါက HTTP POST requests တွေကို အသုံးပြုပြီး files တွေကို 🤗 Hub ကို တိုက်ရိုက် push လုပ်ပါတယ်။ ဒီနည်းလမ်းရဲ့ ကန့်သတ်ချက်ကတော့ 5GB ထက်ကြီးတဲ့ files တွေကို ကိုင်တွယ်နိုင်ခြင်း မရှိပါဘူး။
+သင့် files တွေက 5GB ထက်ကြီးတယ်ဆိုရင် အောက်မှာ အသေးစိတ်ဖော်ပြထားတဲ့ အခြားနည်းလမ်းနှစ်ခုကို လိုက်နာပါ။
+
+API ကို အောက်ပါအတိုင်း အသုံးပြုနိုင်ပါတယ်။
+
+```py
+from huggingface_hub import upload_file
+
+upload_file(
+ "
+
+ +
+
+
+UI (User Interface) က သင့်ကို model files တွေနဲ့ commits တွေကို လေ့လာနိုင်စေပြီး commit တစ်ခုစီက ဖြစ်ပေါ်စေတဲ့ diffs တွေကို ကြည့်ရှုနိုင်စေပါတယ်။
+
+
+
+ +
+
+{:else}
+ဒါပြီးတာနဲ့ model repository ကို ကျွန်တော်တို့ကြည့်လိုက်ရင်၊ အခုမှ ထည့်သွင်းထားတဲ့ files တွေအားလုံးကို ကျွန်တော်တို့ တွေ့မြင်နိုင်ပါပြီ။
+
+
+
+ +
+
+
+UI (User Interface) က သင့်ကို model files တွေနဲ့ commits တွေကို လေ့လာနိုင်စေပြီး commit တစ်ခုစီက ဖြစ်ပေါ်စေတဲ့ diffs တွေကို ကြည့်ရှုနိုင်စေပါတယ်။
+
+
+
+ +
+
+{/if}
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* **Pretrained Models**: အကြီးစား ဒေတာအမြောက်အမြားဖြင့် ကြိုတင်လေ့ကျင့်ထားပြီးဖြစ်သော AI (Artificial Intelligence) မော်ဒယ်များ။
+* **🤗 Hub (Hugging Face Hub)**: AI မော်ဒယ်တွေ၊ datasets တွေနဲ့ demo တွေကို အခြားသူတွေနဲ့ မျှဝေဖို့၊ ရှာဖွေဖို့နဲ့ ပြန်လည်အသုံးပြုဖို့အတွက် အွန်လိုင်း platform တစ်ခု ဖြစ်ပါတယ်။
+* **`push_to_hub` API (Application Programming Interface)**: Hugging Face Transformers library မှ ပံ့ပိုးပေးသော method တစ်ခုဖြစ်ပြီး trained models များနှင့် tokenizers များကို Hugging Face Hub သို့ အလွယ်တကူ upload လုပ်နိုင်စေသည်။
+* **`huggingface_hub` Python Library**: Hugging Face Hub ကို အပြန်အလှန်ဆက်သွယ်ရန် (repositories ဖန်တီးခြင်း၊ files များ upload လုပ်ခြင်း စသည်ဖြင့်) ကိရိယာများနှင့် functions များကို ပံ့ပိုးပေးသော Python library။
+* **Web Interface**: Hugging Face Hub ဝက်ဘ်ဆိုဒ်၏ ဂရပ်ဖစ်အခြေခံ အသုံးပြုသူမျက်နှာပြင်။
+* **Git**: Version control system တစ်ခုဖြစ်ပြီး code changes များကို ခြေရာခံရန်နှင့် developer အများအပြား ပူးပေါင်းလုပ်ဆောင်နိုင်ရန် ဒီဇိုင်းထုတ်ထားသည်။
+* **Git-LFS (Git Large File Storage)**: Git repositories များတွင် ကြီးမားသော files များကို ထိရောက်စွာ ကိုင်တွယ်ရန်အတွက် extension တစ်ခု။
+* **Compute Resources**: AI/ML model များကို လေ့ကျင့်ရန်နှင့် အသုံးပြုရန်အတွက် လိုအပ်သော ကွန်ပျူတာ hardware (ဥပမာ- CPU, GPU, memory)။
+* **Trained Artifacts**: လေ့ကျင့်ထားသော AI model များ၊ ၎င်းတို့၏ weights များ၊ tokenizers များ စသည်ဖြင့် အသုံးပြုနိုင်သော output များ။
+* **Model Repositories**: Hugging Face Hub တွင် AI model များကို သိမ်းဆည်းထားသော Git repositories များ။
+* **Authentication Token**: အသုံးပြုသူတစ်ဦး၏ အထောက်အထားကို စစ်ဆေးရန်နှင့် ၎င်းတို့၏ permissions များကို အတည်ပြုရန် အသုံးပြုသော လုံခြုံရေး token။
+* **`huggingface-cli login`**: Hugging Face CLI (Command Line Interface) မှတစ်ဆင့် Hub ကို login လုပ်ရန် command။
+* **CLI (Command Line Interface)**: ကွန်ပျူတာပရိုဂရမ်တစ်ခုနှင့် text-based commands များ အသုံးပြု၍ အပြန်အလှန်ဆက်သွယ်သော နည်းလမ်း။
+* **Notebook**: Jupyter Notebook သို့မဟုတ် Google Colab ကဲ့သို့သော interactive computing environment။
+* **`notebook_login()` Function**: Jupyter/Colab Notebooks များတွင် Hugging Face Hub ကို login လုပ်ရန် `huggingface_hub` library မှ function။
+* **Cache Folder**: အနာဂတ်တွင် မြန်ဆန်စွာ ဝင်ရောက်ကြည့်ရှုနိုင်ရန် ဒေတာများကို ယာယီသိမ်းဆည်းထားသော နေရာ။
+* **Namespace**: Hugging Face Hub တွင် အသုံးပြုသူများ သို့မဟုတ် organization များအတွက် ထူးခြားသော ID သို့မဟုတ် ခွဲခြားသတ်မှတ်မှု။
+* **`Trainer` API**: Hugging Face Transformers library မှ model များကို ထိရောက်စွာ လေ့ကျင့်ရန်အတွက် ဒီဇိုင်းထုတ်ထားသော မြင့်မားသောအဆင့် (high-level) API။
+* **`TrainingArguments`**: Trainer API တွင် training process အတွက် parameters များကို သတ်မှတ်ရန် အသုံးပြုသော class။
+* **`bert-finetuned-mrpc`**: MRPC dataset တွင် fine-tuned လုပ်ထားသော BERT model ကို ဖော်ပြသော အမည်။
+* **`save_strategy="epoch"`**: Model ကို epoch တိုင်း သိမ်းဆည်းရန် သတ်မှတ်ခြင်း။
+* **`push_to_hub=True`**: Model ကို Hugging Face Hub သို့ အလိုအလျောက် push လုပ်ရန် သတ်မှတ်ခြင်း။
+* **`trainer.train()`**: Trainer API ကို အသုံးပြု၍ model ကို လေ့ကျင့်ရန် method။
+* **`trainer.push_to_hub()`**: Trainer API ကို အသုံးပြု၍ လက်ရှိ training အခြေအနေကို Hub သို့ push လုပ်ရန် method။
+* **Model Card**: Hugging Face Hub တွင် မော်ဒယ်တစ်ခုစီအတွက် ပါရှိသော အချက်အလက်များပါသည့် စာမျက်နှာ။ ၎င်းတွင် မော်ဒယ်ကို မည်သို့လေ့ကျင့်ခဲ့သည်၊ မည်သည့် datasets များကို အသုံးပြုခဲ့သည်၊ ၎င်း၏ ကန့်သတ်ချက်များ၊ ဘက်လိုက်မှုများ (biases) နှင့် အသုံးပြုနည်းများ ပါဝင်သည်။
+* **Metadata**: ဒေတာအကြောင်းအရာများကို ဖော်ပြသော ဒေတာ (ဥပမာ- hyperparameters, evaluation results)။
+* **Hyperparameters**: Model ကို လေ့ကျင့်ရာတွင် အသုံးပြုသော ပြင်ပ parameters များ (ဥပမာ- learning rate, batch size)။
+* **Evaluation Results**: Model ၏ စွမ်းဆောင်ရည်ကို တိုင်းတာသော ရလဒ်များ (ဥပမာ- accuracy, F1 score)။
+* **Keras**: TensorFlow အပေါ်တွင် တည်ဆောက်ထားသော open-source deep learning library တစ်ခု။
+* **`PushToHubCallback`**: Keras models များကို Hub သို့ push လုပ်ရန်အတွက် Hugging Face Transformers library မှ callback class။
+* **`model.fit()`**: Keras မှာ model ကို လေ့ကျင့်ရန် method။
+* **`hub_model_id`**: Hub ပေါ်ရှိ model repository အတွက် သတ်မှတ်ထားသော ID။
+* **Organization Namespace**: Hugging Face Hub တွင် organization တစ်ခုအတွက် သတ်မှတ်ထားသော namespace။
+* **Configuration Objects**: model ၏ ဖွဲ့စည်းပုံနှင့် parameters များကို သိမ်းဆည်းထားသော object များ။
+* **`push_to_hub()` Method (Model/Tokenizer/Config)**: model, tokenizer, သို့မဟုတ် configuration object များပေါ်တွင် တိုက်ရိုက်ရရှိနိုင်သော method ဖြစ်ပြီး ၎င်းတို့ကို Hub သို့ push လုပ်ရန်။
+* **`AutoModelForMaskedLM` / `TFAutoModelForMaskedLM`**: Masked Language Modeling (MLM) အတွက် AutoModel classes များ (PyTorch/TensorFlow)။
+* **`AutoTokenizer`**: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး မော်ဒယ်အမည်ကို အသုံးပြုပြီး သက်ဆိုင်ရာ tokenizer ကို အလိုအလျောက် load လုပ်ပေးသည်။
+* **`from_pretrained()`**: Pretrained model သို့မဟုတ် tokenizer ကို Hub မှ load လုပ်ရန် method။
+* **Weights**: Model ၏ လေ့ကျင့်ပြီးသား parameters များ။
+* **`dummy-model`**: ဥပမာပြရန်အတွက် အသုံးပြုသော model repository အမည်။
+* **API Token**: Access token ကို ရည်ညွှန်းသည်။
+* **`use_auth_token` Argument**: authentication token ကို `push_to_hub()` method သို့ တိုက်ရိုက်ပေးရန် argument။
+* **`bert-base-cased`**: BERT model ၏ base version, cased text (အကြီးအသေး ခွဲခြားသော) ဖြင့် လေ့ကျင့်ထားသော checkpoint identifier။
+* **`model_sharing` (Transformers documentation)**: Transformers documentation ရှိ model မျှဝေခြင်းနှင့် ပတ်သက်သော အပိုင်း။
+* **`allenlp` (Library)**: NLP သုတေသနနှင့် အပလီကေးရှင်းများအတွက် အသုံးပြုသော open-source deep learning library။
+* **`login`, `logout`, `whoami` (User Management)**: `huggingface_hub` library မှ user account ကို စီမံခန့်ခွဲရန် functions များ။
+* **`create_repo`, `delete_repo`, `update_repo_visibility` (Repository Management)**: `huggingface_hub` library မှ repository များကို ဖန်တီး၊ ဖျက်ပစ်၊ မြင်နိုင်စွမ်းကို ပြောင်းလဲရန် functions များ။
+* **`list_models`, `list_datasets`, `list_metrics`, `list_repo_files`, `upload_file`, `delete_file` (Content Information)**: `huggingface_hub` library မှ Hub ပေါ်ရှိ content အကြောင်း အချက်အလက်များ ရယူရန်/ပြောင်းလဲရန် functions များ။
+* **`private` Argument (create_repo)**: Repository ကို public သို့မဟုတ် private အဖြစ် သတ်မှတ်ရန် argument။
+* **`repo_type` Argument (create_repo)**: Repository အမျိုးအစားကို သတ်မှတ်ရန် argument (ဥပမာ- `"model"`, `"dataset"`, `"space"`)။
+* **Space (Hugging Face Space)**: AI demo များကို host လုပ်ရန်အတွက် Hugging Face Hub တွင်ရှိသော platform။
+* **Owner**: Repository ကို ပိုင်ဆိုင်သော အသုံးပြုသူ သို့မဟုတ် organization။
+* **Affiliated with**: ဆက်စပ်မှုရှိသော။
+* **README File (README.md)**: project တစ်ခု သို့မဟုတ် repository တစ်ခုအကြောင်း အချက်အလက်များပါဝင်သော စာသားဖိုင်။ Markdown format ဖြင့် ရေးသားလေ့ရှိသည်။
+* **Markdown**: စာသားကို အလှဆင်ရန်အတွက် အသုံးပြုသော lightweight markup language။
+* **`.gitattributes` File**: Git repositories များတွင် ကြီးမားသော files များကို git-lfs ဖြင့် ကိုင်တွယ်ရန် သတ်မှတ်ထားသော configuration file။
+* **HTTP POST Requests**: Web server သို့ data ပို့ရန်အတွက် အသုံးပြုသော HTTP method။
+* **Local Repository**: သင့်ကွန်ပျူတာပေါ်ရှိ Git repository ၏ copy တစ်ခု။
+* **Clone**: Remote Git repository တစ်ခု၏ copy ကို local folder တစ်ခုသို့ ကူးယူခြင်း။
+* **`repo.git_pull()`**: Local repository ကို remote repository မှ နောက်ဆုံးပြောင်းလဲမှုများဖြင့် update လုပ်ရန် method။
+* **`repo.git_add()`**: Files များကို Git ၏ staging area သို့ ထည့်ရန် method။
+* **`repo.git_commit()`**: Staged files များကို repository ၏ history သို့ သိမ်းဆည်းရန် method။
+* **`repo.git_push()`**: Local commits များကို remote repository သို့ ပေးပို့ရန် method။
+* **`repo.git_tag()`**: Git history တွင် သီးခြားမှတ်တိုင်တစ်ခုကို အမှတ်အသားပြုရန် tag တစ်ခု ဖန်တီးရန် method။
+* **`model.save_pretrained()` / `tokenizer.save_pretrained()`**: model သို့မဟုတ် tokenizer ၏ weights နှင့် configuration များကို local folder တစ်ခုသို့ သိမ်းဆည်းရန် method။
+* **Staging Area**: Git တွင် commit မလုပ်မီ changes များကို ယာယီသိမ်းဆည်းထားသော နေရာ။
+* **Commit**: Git repository ၏ history သို့ changes များကို သိမ်းဆည်းခြင်း။
+* **Git-based System**: Git version control system ကို အသုံးပြုထားသော system။
+* **`git lfs install`**: Git LFS ကို initialize လုပ်ရန် command။
+* **`git clone`**: Git repository ကို clone လုပ်ရန် command။
+* **`cd`**: Command line command တစ်ခုဖြစ်ပြီး directory တစ်ခုမှ အခြားတစ်ခုသို့ ပြောင်းလဲရန် အသုံးပြုသည်။
+* **`ls`**: Command line command တစ်ခုဖြစ်ပြီး လက်ရှိ directory ရှိ ဖိုင်များနှင့် directory များကို ပြသရန် အသုံးပြုသည်။
+* **Configuration File**: ဆော့ဖ်ဝဲလ်တစ်ခု၏ setting များနှင့် parameters များကို သိမ်းဆည်းထားသော ဖိုင်။
+* **Vocabulary File**: Tokenizer က အသုံးပြုသော tokens များ၏ စာရင်းပါဝင်သော ဖိုင်။
+* **Model State Dict File (`pytorch_model.bin` / `tf_model.h5`)**: PyTorch သို့မဟုတ် TensorFlow model ၏ weights များကို သိမ်းဆည်းထားသော ဖိုင်။
+* **`ls -lh`**: File sizes များကို human-readable format ဖြင့် ပြသရန် `ls` command ၏ option။
+* **Outlier**: အများစုနှင့် ကွဲပြားနေသော အရာ။
+* **Git's Staging Environment**: Git တွင် နောက် commit အတွက် ပြင်ဆင်ထားသော changes များရှိရာ နေရာ။
+* **`git add .`**: လက်ရှိ directory ရှိ changes အားလုံးကို staging area သို့ ထည့်ရန် command။
+* **`git status`**: လက်ရှိ repository ၏ အခြေအနေ (staged, unstaged, untracked files) ကို ပြသရန် command။
+* **Handler**: File အမျိုးအစားတစ်ခုကို စီမံခန့်ခွဲသော ကိရိယာ သို့မဟုတ် လုပ်ငန်းစဉ်။
+* **Remote Repository**: Local repository ၏ အွန်လိုင်း (cloud) ပေါ်ရှိ copy။
+* **`git commit -m "Message"`**: Commit message ပါဝင်သော commit တစ်ခု ပြုလုပ်ရန် command။
+* **`git push`**: Local commits များကို remote repository သို့ ပေးပို့ရန် command။
+* **Uploading LFS Objects**: Git LFS မှ စီမံခန့်ခွဲသော ကြီးမားသော files များကို upload လုပ်ခြင်း။
+* **Enumerating Objects**: Git history တွင် object များကို ရေတွက်ခြင်း။
+* **Counting Objects**: Git commit history တွင် object များကို ရေတွက်ခြင်း။
+* **Delta Compression**: Changes များကိုသာ သိမ်းဆည်းခြင်းဖြင့် file အရွယ်အစားကို လျှော့ချသော နည်းလမ်း။
+* **Compressing Objects**: Git object များကို ချုံ့ခြင်း။
+* **Writing Objects**: Git database သို့ object များကို ရေးသားခြင်း။
+* **Total/Reused/Pack-reused**: Git push လုပ်ငန်းစဉ်၏ အကျဉ်းချုပ် အချက်အလက်များ။
+* **UI (User Interface)**: အသုံးပြုသူနှင့် အပြန်အလှန်တုံ့ပြန်နိုင်သော ဂရပ်ဖစ်မျက်နှာပြင်။
+* **Commits**: Git repository ၏ history တွင် မှတ်တမ်းတင်ထားသော changes များ။
+* **Diffs**: commits နှစ်ခုကြားရှိ ကွာခြားချက်များကို ပြသခြင်း။
\ No newline at end of file
diff --git a/chapters/my/chapter4/4.mdx b/chapters/my/chapter4/4.mdx
new file mode 100644
index 000000000..16bb39742
--- /dev/null
+++ b/chapters/my/chapter4/4.mdx
@@ -0,0 +1,142 @@
+# Model Card တစ်ခု တည်ဆောက်ခြင်း[[building-a-model-card]]
+
+
+push_to_hub method ပါဝင်ပြီး၊ အဲဒါကို အသုံးပြုခြင်းက ၎င်းတို့ကို သတ်မှတ်ထားတဲ့ repo သို့ push လုပ်ပါလိမ့်မယ်။ အခြားဘာတွေ မျှဝေနိုင်သေးလဲ။",
+ correct: true
+ },
+ {
+ text: "Model",
+ explain: "မှန်ပါတယ်။ Models အားလုံးမှာ push_to_hub method ပါဝင်ပြီး၊ အဲဒါကို အသုံးပြုခြင်းက ၎င်းတို့နဲ့ ၎င်းတို့ရဲ့ configuration files တွေကို သတ်မှတ်ထားတဲ့ repo သို့ push လုပ်ပါလိမ့်မယ်။ ဒါပေမယ့် ဒါတစ်ခုတည်းတော့ မဟုတ်ပါဘူး။",
+ correct: true
+ },
+ {
+ text: "Trainer",
+ explain: "မှန်ပါတယ်။ Trainer ကလည်း push_to_hub method ကို အကောင်အထည်ဖော်ထားပြီး၊ အဲဒါကို အသုံးပြုခြင်းက model၊ ၎င်းရဲ့ configuration၊ tokenizer နဲ့ model card draft တို့ကို သတ်မှတ်ထားတဲ့ repo သို့ upload လုပ်ပါလိမ့်မယ်။ အခြားအဖြေတစ်ခု စမ်းကြည့်ပါ။",
+ correct: true
+ }
+ ]}
+/>
+{:else}
+push_to_hub method ပါဝင်ပြီး၊ အဲဒါကို အသုံးပြုခြင်းက ၎င်းတို့ကို သတ်မှတ်ထားတဲ့ repo သို့ push လုပ်ပါလိမ့်မယ်။ အခြားဘာတွေ မျှဝေနိုင်သေးလဲ။",
+ correct: true
+ },
+ {
+ text: "Model",
+ explain: "မှန်ပါတယ်။ Models အားလုံးမှာ push_to_hub method ပါဝင်ပြီး၊ အဲဒါကို အသုံးပြုခြင်းက ၎င်းတို့နဲ့ ၎င်းတို့ရဲ့ configuration files တွေကို သတ်မှတ်ထားတဲ့ repo သို့ push လုပ်ပါလိမ့်မယ်။ ဒါပေမယ့် ဒါတစ်ခုတည်းတော့ မဟုတ်ပါဘူး။",
+ correct: true
+ },
+ {
+ text: "အထက်ပါအရာအားလုံးကို သီးသန့် callback တစ်ခုဖြင့်",
+ explain: "မှန်ပါတယ်။ PushToHubCallback က training လုပ်နေစဉ် အဲဒီ objects အားလုံးကို repo သို့ ပုံမှန် ပေးပို့ပါလိမ့်မယ်။",
+ correct: true
+ }
+ ]}
+/>
+{/if}
+
+### ၆။ `push_to_hub()` method သို့မဟုတ် CLI tools တွေကို အသုံးပြုတဲ့အခါ ပထမဆုံးအဆင့်က ဘာလဲ။
+
+huggingface_hub utilities တွေကနေ အကျိုးကျေးဇူးတွေ ရနေပြီးသားပါ။ ထပ်ဆောင်း wrap လုပ်ဖို့ မလိုပါဘူး!"
+ },
+ {
+ text: "၎င်းတို့ကို disk ထဲသို့ save လုပ်ပြီး transformers-cli upload-model ကို ခေါ်ခြင်းဖြင့်။",
+ explain: "upload-model command က မရှိပါဘူး။"
+ }
+ ]}
+/>
+
+### ၈။ `Repository` class ကို အသုံးပြုပြီး ဘယ် git operations တွေ လုပ်ဆောင်နိုင်လဲ။
+
+git_pull() method ရဲ့ ရည်ရွယ်ချက်က ဒါပါပဲ။",
+ correct: true
+ },
+ {
+ text: "A push",
+ explain: "git_push() method က ဒါကို လုပ်ဆောင်ပါတယ်။",
+ correct: true
+ },
+ {
+ text: "A merge",
+ explain: "မမှန်ပါဘူး၊ အဲဒီ operation က ဒီ API နဲ့ ဘယ်တော့မှ ဖြစ်နိုင်မှာ မဟုတ်ပါဘူး။"
+ }
+ ]}
+/>
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* **Models**: Artificial Intelligence (AI) နယ်ပယ်တွင် အချက်အလက်များကို လေ့လာပြီး ခန့်မှန်းချက်များ ပြုလုပ်ရန် ဒီဇိုင်းထုတ်ထားသော သင်္ချာဆိုင်ရာဖွဲ့စည်းပုံများ။
+* **Hub (Hugging Face Hub)**: AI မော်ဒယ်တွေ၊ datasets တွေနဲ့ demo တွေကို အခြားသူတွေနဲ့ မျှဝေဖို့၊ ရှာဖွေဖို့နဲ့ ပြန်လည်အသုံးပြုဖို့အတွက် အွန်လိုင်း platform တစ်ခု ဖြစ်ပါတယ်။
+* **🤗 Transformers Library**: Hugging Face က ထုတ်လုပ်ထားတဲ့ library တစ်ခုဖြစ်ပြီး Transformer မော်ဒယ်တွေကို အသုံးပြုပြီး Natural Language Processing (NLP), computer vision, audio processing စတဲ့ နယ်ပယ်တွေမှာ အဆင့်မြင့် AI မော်ဒယ်တွေကို တည်ဆောက်ပြီး အသုံးပြုနိုင်စေပါတယ်။
+* **Interface**: ဆော့ဖ်ဝဲလ် နှစ်ခုကြား သို့မဟုတ် အသုံးပြုသူနှင့် ဆော့ဖ်ဝဲလ်ကြား အပြန်အလှန် ချိတ်ဆက်ဆောင်ရွက်နိုင်သော စနစ်။
+* **NLP (Natural Language Processing)**: ကွန်ပျူတာတွေ လူသားဘာသာစကားကို နားလည်၊ အဓိပ္ပာယ်ဖော်ပြီး၊ ဖန်တီးနိုင်အောင် လုပ်ဆောင်ပေးတဲ့ Artificial Intelligence (AI) ရဲ့ နယ်ပယ်ခွဲတစ်ခုပါ။
+* **GCP (Google Cloud Platform)**: Google မှ ပံ့ပိုးပေးသော cloud computing ဝန်ဆောင်မှုများ။
+* **Peer-to-peer distribution**: ကွန်ရက်တစ်ခုရှိ ကွန်ပျူတာများကြား ဖိုင်များ သို့မဟုတ် ဒေတာများကို တိုက်ရိုက်မျှဝေခြင်း။
+* **`git`**: Version control system တစ်ခုဖြစ်ပြီး project files တွေကို ခြေရာခံ၊ စီမံခန့်ခွဲရာတွင် အသုံးပြုသည်။
+* **`git-lfs` (Git Large File Storage)**: ကြီးမားသော binary files များကို Git repository များတွင် ထိရောက်စွာ ကိုင်တွယ်နိုင်ရန် Git ၏ extension တစ်ခု။
+* **Git Repositories**: Git version control system ကို အသုံးပြု၍ project တစ်ခု၏ files များနှင့် ၎င်းတို့၏ ပြောင်းလဲမှု မှတ်တမ်းများကို သိမ်းဆည်းထားသော နေရာ။
+* **Fork**: လက်ရှိ repository ၏ မိတ္တူတစ်ခုကို ဖန်တီးပြီး သီးခြားစီ ပြောင်းလဲပြင်ဆင်ခြင်း။
+* **Model Repository**: Git version control system ကို အသုံးပြု၍ model file များ၊ tokenizer file များ၊ model card (README.md) နှင့် အခြားဆက်စပ်ဖိုင်များကို သိမ်းဆည်းထားသော နေရာ။
+* **Diffs**: ဖိုင်နှစ်ခုကြား ကွာခြားချက်များကို ပြသခြင်း။
+* **Model Card**: Hugging Face Hub တွင် မော်ဒယ်တစ်ခုစီအတွက် ပါရှိသော အချက်အလက်များပါသည့် စာမျက်နှာ။ ၎င်းတွင် မော်ဒယ်ကို မည်သို့လေ့ကျင့်ခဲ့သည်၊ မည်သည့် datasets များကို အသုံးပြုခဲ့သည်၊ ၎င်း၏ ကန့်သတ်ချက်များ၊ ဘက်လိုက်မှုများ (biases) နှင့် အသုံးပြုနည်းများ ပါဝင်သည်။
+* **Reproducibility**: သတ်မှတ်ထားသော code နှင့် data ကို အသုံးပြု၍ တူညီသော ရလဒ်များကို ပြန်လည်ထုတ်လုပ်နိုင်ခြင်း။
+* **Reusability**: ဆော့ဖ်ဝဲလ်အစိတ်အပိုင်းများ သို့မဟုတ် မော်ဒယ်များကို အခြား project များတွင် ပြန်လည်အသုံးပြုနိုင်ခြင်း။
+* **Fairness**: AI စနစ်များက အဖွဲ့အစည်းများ သို့မဟုတ် တစ်ဦးချင်းအပေါ် ဘက်လိုက်မှုမရှိဘဲ တန်းတူညီမျှစွာ ဆက်ဆံခြင်း။
+* **Tokenizer**: စာသား (သို့မဟုတ် အခြားဒေတာ) ကို AI မော်ဒယ်များ စီမံဆောင်ရွက်နိုင်ရန် tokens တွေအဖြစ် ပိုင်းခြားပေးသည့် ကိရိယာ သို့မဟုတ် လုပ်ငန်းစဉ်။
+* **`push_to_hub()` Method**: Hugging Face Transformers library မှ model, tokenizer, သို့မဟုတ် configuration များကို Hugging Face Hub သို့ upload လုပ်ရန် အသုံးပြုသော method။
+* **Model Configuration**: model ၏ ဖွဲ့စည်းပုံ (architecture, hyperparameters စသည်) ကို ဖော်ပြသော အချက်အလက်များ။
+* **Trainer**: Hugging Face Transformers library မှ model များကို လေ့ကျင့်ရန်အတွက် မြင့်မားသောအဆင့် (high-level) API။
+* **Vocabulary**: tokenizer သို့မဟုတ် model တစ်ခုက သိရှိနားလည်ပြီး ကိုင်တွယ်နိုင်သော ထူးခြားသည့် tokens များ စုစုပေါင်း။
+* **`PushToHubCallback`**: PyTorch Trainer တွင် အသုံးပြုသော callback တစ်ခုဖြစ်ပြီး training လုပ်နေစဉ်အတွင်း models, tokenizers, configuration များနှင့် model card draft များကို Hub သို့ ပုံမှန် update လုပ်ရန်။
+* **CLI Tools (Command Line Interface Tools)**: command line မှတစ်ဆင့် အပြန်အလှန်တုံ့ပြန်နိုင်သော ဆော့ဖ်ဝဲလ်ကိရိယာများ။
+* **`huggingface-cli login`**: Hugging Face CLI (Command Line Interface) မှ Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော command။
+* **Personal Token**: Hugging Face Hub တွင် အကောင့် authentication အတွက် အသုံးပြုသော ထူးခြားသည့် ကုဒ်။
+* **Cache**: မကြာခဏ အသုံးပြုရသော ဒေတာများကို မြန်မြန်ဆန်ဆန် ဝင်ရောက်ကြည့်ရှုနိုင်ရန် သိမ်းဆည်းထားသော ယာယီသိုလှောင်ရာနေရာ။
+* **`notebook_login()`**: Jupyter/Colab Notebooks များတွင် Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော function။
+* **Widget**: Graphical User Interface (GUI) တွင် အသုံးပြုသူနှင့် အပြန်အလှန်တုံ့ပြန်နိုင်သော အစိတ်အပိုင်းများ (ဥပမာ- input box, button)။
+* **`huggingface_hub` Utility**: Hugging Face Hub နှင့် အပြန်အလှန်ဆက်သွယ်ရန် အသုံးပြုသော Python library။
+* **Python Runtime**: Python code ကို လက်ရှိ run နေသော ပတ်ဝန်းကျင်။
+* **`Repository` Class**: `huggingface_hub` library မှ Git repository များကို ကိုင်တွယ်ရန်အတွက် class။
+* **Git Operations**: Git version control system ဖြင့် လုပ်ဆောင်နိုင်သော လုပ်ငန်းများ (ဥပမာ- commit, pull, push, merge)။
+* **Commit**: Git repository တွင် ပြောင်းလဲမှုများကို မှတ်တမ်းတင်ခြင်း။
+* **`git_commit()` Method**: `Repository` class မှ commit လုပ်ရန်အတွက် method။
+* **Pull**: အဝေးထိန်း repository (remote repository) မှ ပြောင်းလဲမှုများကို local repository သို့ ရယူခြင်း။
+* **`git_pull()` Method**: `Repository` class မှ pull လုပ်ရန်အတွက် method။
+* **Push**: Local repository မှ ပြောင်းလဲမှုများကို အဝေးထိန်း repository သို့ ပေးပို့ခြင်း။
+* **`git_push()` Method**: `Repository` class မှ push လုပ်ရန်အတွက် method။
+* **Merge**: Git တွင် မတူညီသော branches များမှ ပြောင်းလဲမှုများကို ပေါင်းစပ်ခြင်း။
\ No newline at end of file
diff --git a/chapters/my/chapter5/1.mdx b/chapters/my/chapter5/1.mdx
new file mode 100644
index 000000000..d7a739c80
--- /dev/null
+++ b/chapters/my/chapter5/1.mdx
@@ -0,0 +1,40 @@
+# နိဒါန်း[[introduction]]
+
+| + | patient_id | +drugName | +condition | +review | +rating | +date | +usefulCount | +review_length | +
|---|---|---|---|---|---|---|---|---|
| 0 | +95260 | +Guanfacine | +adhd | +"My son is halfway through his fourth week of Intuniv..." | +8.0 | +April 27, 2010 | +192 | +141 | +
| 1 | +92703 | +Lybrel | +birth control | +"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | +5.0 | +December 14, 2009 | +17 | +134 | +
| 2 | +138000 | +Ortho Evra | +birth control | +"This is my first time using any form of birth control..." | +8.0 | +November 3, 2015 | +10 | +89 | +
| + | condition | +frequency | +
|---|---|---|
| 0 | +birth control | +27655 | +
| 1 | +depression | +8023 | +
| 2 | +acne | +5209 | +
| 3 | +anxiety | +4991 | +
| 4 | +pain | +4744 | +
+ +
+
+
+ဒီ issues တွေထဲက တစ်ခုကို နှိပ်လိုက်ရင် title၊ description နဲ့ issue ကို ဖော်ပြတဲ့ labels အစုအဝေးတစ်ခု ပါဝင်တာကို သင်တွေ့ရပါလိမ့်မယ်။ ဥပမာတစ်ခုကို အောက်ပါ screenshot မှာ ပြသထားပါတယ်။
+
+
+
+ +
+
+
+repository ရဲ့ issues အားလုံးကို download လုပ်ဖို့၊ [`Issues` endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues) ကို poll လုပ်ဖို့ [GitHub REST API](https://docs.github.com/en/rest) ကို အသုံးပြုပါမယ်။ ဒီ endpoint က JSON objects စာရင်းတစ်ခုကို ပြန်ပေးပြီး၊ object တစ်ခုစီမှာ title နဲ့ description အပြင် issue ရဲ့ status နဲ့ အခြား metadata အများအပြား ပါဝင်ပါတယ်။
+
+issues တွေကို download လုပ်ဖို့ အဆင်ပြေတဲ့ နည်းလမ်းတစ်ခုကတော့ `requests` library ကို အသုံးပြုခြင်းပါပဲ။ ဒါက Python မှာ HTTP requests တွေ ပြုလုပ်ဖို့အတွက် standard နည်းလမ်းတစ်ခုပါ။ library ကို အောက်ပါအတိုင်း install လုပ်နိုင်ပါတယ်။
+
+```python
+!pip install requests
+```
+
+library ကို install လုပ်ပြီးတာနဲ့၊ `requests.get()` function ကို ခေါ်ခြင်းဖြင့် `Issues` endpoint ကို GET requests တွေ ပြုလုပ်နိုင်ပါတယ်။ ဥပမာအားဖြင့်၊ ပထမစာမျက်နှာရဲ့ ပထမဆုံး issue ကို ပြန်လည်ရယူဖို့ အောက်ပါ command ကို run နိုင်ပါတယ်။
+
+```py
+import requests
+
+url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
+response = requests.get(url)
+```
+
+`response` object က HTTP status code အပါအဝင် request နဲ့ပတ်သက်တဲ့ အသုံးဝင်တဲ့ အချက်အလက်များစွာ ပါဝင်ပါတယ်။
+
+```py
+response.status_code
+```
+
+```python out
+200
+```
+
+ဒီနေရာမှာ `200` status က request အောင်မြင်တယ်လို့ ဆိုလိုပါတယ် (ဖြစ်နိုင်ချေရှိတဲ့ HTTP status codes စာရင်းကို [ဒီနေရာမှာ](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes) ရှာတွေ့နိုင်ပါတယ်။) ကျွန်တော်တို့ တကယ်စိတ်ဝင်စားတာက _payload_ ဖြစ်ပြီး၊ ဒါကို bytes, strings, သို့မဟုတ် JSON လိုမျိုး formats မျိုးစုံနဲ့ ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။ ကျွန်တော်တို့ issues တွေက JSON format နဲ့ဆိုတာ သိတဲ့အတွက်၊ payload ကို အောက်ပါအတိုင်း စစ်ဆေးကြည့်ရအောင်။
+
+```py
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'repository_url': 'https://api.github.com/repos/huggingface/datasets',
+ 'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
+ 'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
+ 'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'id': 968650274,
+ 'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
+ 'number': 2792,
+ 'title': 'Update GooAQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'labels': [],
+ 'state': 'open',
+ 'locked': False,
+ 'assignee': None,
+ 'assignees': [],
+ 'milestone': None,
+ 'comments': 1,
+ 'created_at': '2021-08-12T11:40:18Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'closed_at': None,
+ 'author_association': 'CONTRIBUTOR',
+ 'active_lock_reason': None,
+ 'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
+ 'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
+ 'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
+ 'performed_via_github_app': None}]
+```
+
+အိုး၊ အချက်အလက်တွေ အများကြီးပါပဲ။ issue ကို ဖော်ပြတဲ့ `title`, `body`, နဲ့ `number` လိုမျိုး အသုံးဝင်တဲ့ fields တွေအပြင် issue ကို ဖွင့်ခဲ့တဲ့ GitHub user အကြောင်း အချက်အလက်တွေကိုလည်း ကျွန်တော်တို့ မြင်တွေ့ရပါတယ်။
+
+> [!TIP]
+> ✏️ **စမ်းသပ်ကြည့်ပါ။** အပေါ်က JSON payload ထဲက URL အချို့ကို နှိပ်ပြီး GitHub issue တစ်ခုစီက ဘယ်လိုအချက်အလက်မျိုးတွေနဲ့ ချိတ်ဆက်ထားလဲဆိုတာကို ခံစားကြည့်ပါ။
+
+GitHub [documentation](https://docs.github.com/en/rest/overview/resources-in-the-rest-api#rate-limiting) မှာ ဖော်ပြထားတဲ့အတိုင်း၊ authentication မလုပ်ထားတဲ့ requests တွေကို တစ်နာရီလျှင် 60 requests သာ ကန့်သတ်ထားပါတယ်။ သင် `per_page` query parameter ကို တိုးမြှင့်ခြင်းဖြင့် သင်ပြုလုပ်တဲ့ requests အရေအတွက်ကို လျှော့ချနိုင်ပေမယ့်၊ issues ထောင်ပေါင်းများစွာရှိတဲ့ repository တွေမှာတော့ rate limit ကို ကျော်လွန်နေဦးမှာပါ။ ဒါကြောင့်၊ သင်ဟာ တစ်နာရီလျှင် 5,000 requests အထိ rate limit ကို မြှင့်တင်နိုင်ဖို့ personal access token တစ်ခု ဖန်တီးဖို့ GitHub ရဲ့ [ညွှန်ကြားချက်များ](https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token) ကို လိုက်နာသင့်ပါတယ်။ သင့် token ရပြီဆိုတာနဲ့ request header ထဲမှာ ထည့်သွင်းနိုင်ပါတယ်။
+
+```py
+GITHUB_TOKEN = xxx # သင့် GitHub token ကို ဒီနေရာမှာ ကူးထည့်ပါ။
+headers = {"Authorization": f"token {GITHUB_TOKEN}"}
+```
+
+> [!WARNING]
+> ⚠️ သင့် `GITHUB_TOKEN` ကို ကူးထည့်ထားတဲ့ notebook ကို မျှဝေခြင်း မပြုပါနဲ့။ ဒီအချက်အလက်တွေ မတော်တဆ ပေါက်ကြားတာမျိုး မဖြစ်အောင်၊ သင် run ပြီးတာနဲ့ နောက်ဆုံး cell ကို ဖျက်ပစ်ဖို့ ကျွန်တော်တို့ အကြံပြုပါတယ်။ ပိုကောင်းတာကတော့ token ကို *.env* file ထဲမှာ သိမ်းဆည်းထားပြီး environment variable တစ်ခုအနေနဲ့ အလိုအလျောက် load လုပ်ပေးဖို့ [`python-dotenv` library](https://github.com/theskumar/python-dotenv) ကို အသုံးပြုပါ။
+
+access token ရရှိပြီဆိုတာနဲ့၊ GitHub repository တစ်ခုကနေ issues အားလုံးကို download လုပ်နိုင်တဲ့ function တစ်ခု ဖန်တီးကြည့်ရအောင်။
+
+```py
+import time
+import math
+from pathlib import Path
+import pandas as pd
+from tqdm.notebook import tqdm
+
+
+def fetch_issues(
+ owner="huggingface",
+ repo="datasets",
+ num_issues=10_000,
+ rate_limit=5_000,
+ issues_path=Path("."),
+):
+ if not issues_path.is_dir():
+ issues_path.mkdir(exist_ok=True)
+
+ batch = []
+ all_issues = []
+ per_page = 100 # စာမျက်နှာတစ်ခုစီတွင် ပြန်ပေးမည့် issues အရေအတွက်
+ num_pages = math.ceil(num_issues / per_page)
+ base_url = "https://api.github.com/repos"
+
+ for page in tqdm(range(num_pages)):
+ # state=all နဲ့ query လုပ်ပြီး open နဲ့ closed issues နှစ်ခုလုံးကို ရယူပါ
+ query = f"issues?page={page}&per_page={per_page}&state=all"
+ issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
+ batch.extend(issues.json())
+
+ if len(batch) > rate_limit and len(all_issues) < num_issues:
+ all_issues.extend(batch)
+ batch = [] # နောက်တစ်ကြိမ်အတွက် batch ကို ရှင်းပါ
+ print(f"GitHub rate limit ရောက်ပါပြီ။ တစ်နာရီကြာ အိပ်ပါမည် ...")
+ time.sleep(60 * 60 + 1)
+
+ all_issues.extend(batch)
+ df = pd.DataFrame.from_records(all_issues)
+ df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
+ print(
+ f"{repo} အတွက် issues အားလုံးကို download လုပ်ပြီးပါပြီ! Dataset ကို {issues_path}/{repo}-issues.jsonl မှာ သိမ်းဆည်းထားပါတယ်"
+ )
+```
+
+အခု `fetch_issues()` ကို ခေါ်လိုက်တဲ့အခါ GitHub ရဲ့ တစ်နာရီ requests အရေအတွက် ကန့်သတ်ချက်ကို မကျော်လွန်စေဖို့ issues အားလုံးကို batches အလိုက် download လုပ်ပါလိမ့်မယ်။ ရလဒ်ကို *repository_name-issues.jsonl* file ထဲမှာ သိမ်းဆည်းထားမှာဖြစ်ပြီး၊ line တစ်ကြောင်းစီက issue တစ်ခုကို ကိုယ်စားပြုတဲ့ JSON object တစ်ခု ဖြစ်ပါတယ်။ ဒီ function ကို အသုံးပြုပြီး 🤗 Datasets ကနေ issues အားလုံးကို ရယူလိုက်ရအောင်။
+
+```py
+# သင့်အင်တာနက်ချိတ်ဆက်မှုပေါ်မူတည်ပြီး၊ ဒါက မိနစ်အနည်းငယ် ကြာနိုင်ပါတယ်...
+fetch_issues()
+```
+
+issues တွေကို download လုပ်ပြီးတာနဲ့ [အပိုင်း ၂](/course/chapter5/2) ကနေ ကျွန်တော်တို့ရဲ့ အသစ်တွေ့ရှိတဲ့ ကျွမ်းကျင်မှုတွေကို အသုံးပြုပြီး ၎င်းတို့ကို locally load လုပ်နိုင်ပါတယ်-
+
+```py
+issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
+ num_rows: 3019
+})
+```
+
+ကောင်းပါပြီ၊ ကျွန်တော်တို့ရဲ့ ပထမဆုံး dataset ကို အစကနေ ဖန်တီးခဲ့ပါပြီ။ ဒါပေမယ့် 🤗 Datasets repository ရဲ့ [Issues tab](https://github.com/huggingface/datasets/issues) မှာ စုစုပေါင်း issues ၁,၀၀၀ ခန့်သာ ပြသနေပေမယ့် ဘာကြောင့် issues ထောင်ပေါင်းများစွာ ရှိနေရတာလဲ 🤔။ GitHub [documentation](https://docs.github.com/en/rest/reference/issues#list-issues-assigned-to-the-authenticated-user) မှာ ဖော်ပြထားတဲ့အတိုင်း၊ ကျွန်တော်တို့ pull requests တွေအားလုံးကိုပါ download လုပ်ထားလို့ပါပဲ။
+
+> GitHub ရဲ့ REST API v3 က pull request တိုင်းကို issue တစ်ခုလို့ သတ်မှတ်ပေမယ့်၊ issue တိုင်းကတော့ pull request မဟုတ်ပါဘူး။ ဒါကြောင့်၊ "Issues" endpoints တွေက response မှာ issues နဲ့ pull requests နှစ်ခုလုံးကို ပြန်ပေးနိုင်ပါတယ်။ `pull_request` key နဲ့ pull requests တွေကို ခွဲခြားသိမြင်နိုင်ပါတယ်။ "Issues" endpoints တွေကနေ ပြန်လာတဲ့ pull request တစ်ခုရဲ့ `id` က issue id တစ်ခု ဖြစ်နေမှာကို သတိထားပါ။
+
+issues နဲ့ pull requests ရဲ့ အကြောင်းအရာတွေက အတော်လေး ကွာခြားတာကြောင့်၊ ၎င်းတို့ကြား ခွဲခြားနိုင်ဖို့ minor preprocessing အချို့ လုပ်ကြည့်ရအောင်။
+
+## Data ကို သန့်ရှင်းရေးလုပ်ခြင်း[[cleaning-up-the-data]]
+
+GitHub ရဲ့ documentation က အပေါ်က snippet က `pull_request` column ကို issues နဲ့ pull requests တွေကြား ခွဲခြားဖို့ အသုံးပြုနိုင်တယ်လို့ ကျွန်တော်တို့ကို ပြောပြပါတယ်။ ခြားနားချက်ကို မြင်နိုင်ဖို့ random sample တစ်ခုကို ကြည့်ရအောင်။ [အပိုင်း ၃](/course/chapter5/3) မှာ လုပ်ခဲ့သလိုပဲ၊ `Dataset.shuffle()` နဲ့ `Dataset.select()` ကို တွဲပြီး random sample တစ်ခုကို ဖန်တီးပါမယ်။ ပြီးတော့ `html_url` နဲ့ `pull_request` columns တွေကို zip လုပ်ပြီး URLs တွေကို နှိုင်းယှဉ်နိုင်ပါလိမ့်မယ်။
+
+```py
+sample = issues_dataset.shuffle(seed=666).select(range(3))
+
+# URL နဲ့ pull request entries တွေကို print ထုတ်ပါ
+for url, pr in zip(sample["html_url"], sample["pull_request"]):
+ print(f">> URL: {url}")
+ print(f">> Pull request: {pr}\n")
+```
+
+```python out
+>> URL: https://github.com/huggingface/datasets/pull/850
+>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850', 'patch_url': 'https://github.com/huggingface/datasets/pull/850'}
+
+>> URL: https://github.com/huggingface/datasets/issues/2773
+>> Pull request: None
+
+>> URL: https://github.com/huggingface/datasets/pull/783
+>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783', 'patch_url': 'https://github.com/huggingface/datasets/pull/783'}
+```
+
+ဒီနေရာမှာ pull request တစ်ခုစီဟာ URLs မျိုးစုံနဲ့ ဆက်စပ်နေတာကို မြင်နိုင်ပြီး၊ သာမန် issues တွေမှာတော့ `None` entry ပါဝင်ပါတယ်။ ဒီခြားနားချက်ကို အသုံးပြုပြီး `pull_request` field က `None` ဟုတ်မဟုတ် စစ်ဆေးတဲ့ `is_pull_request` column အသစ်တစ်ခုကို ဖန်တီးနိုင်ပါတယ်။
+
+```py
+issues_dataset = issues_dataset.map(
+ lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
+)
+```
+
+> [!TIP]
+> ✏️ **စမ်းသပ်ကြည့်ပါ။** 🤗 Datasets မှာ issues တွေကို ပိတ်ဖို့ ပျမ်းမျှအချိန်ကို တွက်ချက်ပါ။ pull requests တွေနဲ့ open issues တွေကို filter လုပ်ဖို့ `Dataset.filter()` function ကို အသုံးဝင်တယ်လို့ တွေ့ရနိုင်ပြီး၊ `created_at` နဲ့ `closed_at` timestamps တွေကို အလွယ်တကူ ကိုင်တွယ်နိုင်ဖို့ dataset ကို `DataFrame` အဖြစ် ပြောင်းလဲဖို့ `Dataset.set_format()` function ကို အသုံးပြုနိုင်ပါတယ်။ bonus အမှတ်များအတွက်၊ pull requests တွေကို ပိတ်ဖို့ ပျမ်းမျှအချိန်ကို တွက်ချက်ပါ။
+
+columns အချို့ကို ဖျက်ပစ်ခြင်း သို့မဟုတ် အမည်ပြောင်းလဲခြင်းဖြင့် dataset ကို နောက်ထပ် သန့်ရှင်းရေးလုပ်နိုင်ပေမယ့်၊ ဒီအဆင့်မှာ dataset ကို တတ်နိုင်သမျှ "raw" အဖြစ် ထားရှိခြင်းက နောက်ပိုင်းမှာ applications မျိုးစုံမှာ အလွယ်တကူ အသုံးပြုနိုင်စေဖို့ အလေ့အကျင့်ကောင်းတစ်ခုပါ။
+
+ကျွန်တော်တို့ရဲ့ dataset ကို Hugging Face Hub သို့ push မလုပ်ခင်၊ မပါဝင်သေးတဲ့ အရာတစ်ခုကို ဖြေရှင်းကြည့်ရအောင်- issue နဲ့ pull request တစ်ခုစီနဲ့ ဆက်စပ်နေတဲ့ comments တွေပါ။ ဒါတွေကို နောက်မှာ GitHub REST API နဲ့ ထပ်ထည့်ပါမယ်။
+
+## Dataset ကို အဆင့်မြှင့်တင်ခြင်း[[augmenting-the-dataset]]
+
+အောက်ပါ screenshot မှာ ပြထားတဲ့အတိုင်း၊ issue ဒါမှမဟုတ် pull request တစ်ခုနဲ့ ဆက်စပ်နေတဲ့ comments တွေက အချက်အလက်ကြွယ်ဝတဲ့ အရင်းအမြစ်တစ်ခုကို ပံ့ပိုးပေးပါတယ်။ အထူးသဖြင့် library အကြောင်း အသုံးပြုသူမေးခွန်းတွေကို ဖြေဖို့ search engine တစ်ခု တည်ဆောက်ချင်တယ်ဆိုရင်ပေါ့။
+
+
+
+ +
+
+
+GitHub REST API က issue number တစ်ခုနဲ့ ဆက်စပ်နေတဲ့ comments အားလုံးကို ပြန်ပေးတဲ့ [`Comments` endpoint](https://docs.github.com/en/rest/reference/issues#list-issue-comments) ကို ပံ့ပိုးပေးပါတယ်။ ဒါက ဘာတွေပြန်ပေးလဲဆိုတာ ကြည့်ဖို့ endpoint ကို စမ်းသပ်ကြည့်ရအောင်။
+
+```py
+issue_number = 2792
+url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+response = requests.get(url, headers=headers)
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
+ 'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'id': 897594128,
+ 'node_id': 'IC_kwDODunzps41gDMQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'created_at': '2021-08-12T12:21:52Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'author_association': 'CONTRIBUTOR',
+ 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
+ 'performed_via_github_app': None}]
+```
+
+comment က `body` field ထဲမှာ သိမ်းဆည်းထားတာကို ကျွန်တော်တို့ မြင်နိုင်ပါတယ်။ ဒါကြောင့် `response.json()` ထဲက element တစ်ခုစီအတွက် `body` အကြောင်းအရာတွေကို ရွေးထုတ်ပြီး issue တစ်ခုနဲ့ ဆက်စပ်နေတဲ့ comments အားလုံးကို ပြန်ပေးနိုင်တဲ့ ရိုးရှင်းတဲ့ function တစ်ခု ရေးကြည့်ရအောင်။
+
+```py
+def get_comments(issue_number):
+ url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+ response = requests.get(url, headers=headers)
+ return [r["body"] for r in response.json()]
+
+
+# ကျွန်တော်တို့ရဲ့ function က မျှော်လင့်ထားတဲ့အတိုင်း အလုပ်လုပ်မလုပ် စစ်ဆေးပါ
+get_comments(2792)
+```
+
+```python out
+["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
+```
+
+ဒါက ကောင်းမွန်ပုံရပါတယ်။ ဒါကြောင့် `Dataset.map()` ကို အသုံးပြုပြီး ကျွန်တော်တို့ရဲ့ dataset ထဲက issue တစ်ခုစီအတွက် `comments` column အသစ်တစ်ခု ထည့်လိုက်ရအောင်။
+
+```py
+# သင့်အင်တာနက်ချိတ်ဆက်မှုပေါ်မူတည်ပြီး၊ ဒါက မိနစ်အနည်းငယ် ကြာနိုင်ပါတယ်...
+issues_with_comments_dataset = issues_dataset.map(
+ lambda x: {"comments": get_comments(x["number"])}
+)
+```
+
+နောက်ဆုံးအဆင့်ကတော့ ကျွန်တော်တို့ရဲ့ dataset ကို Hub သို့ push လုပ်ဖို့ပါပဲ။ ဒါကို ဘယ်လိုလုပ်ရမလဲဆိုတာ ကြည့်ရအောင်။
+
+## Dataset ကို Hugging Face Hub သို့ Upload လုပ်ခြင်း[[uploading-the-dataset-to-the-hugging-face-hub]]
+
+
+
+ +
+
+
+၂။ အချက်အလက်ပြည့်စုံတဲ့ dataset cards တွေ ဖန်တီးခြင်းအကြောင်း [🤗 Datasets guide](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) ကို ဖတ်ပြီး ဒါကို template အဖြစ် အသုံးပြုပါ။
+
+သင် *README.md* file ကို Hub ပေါ်မှာ တိုက်ရိုက်ဖန်တီးနိုင်ပြီး၊ `lewtun/github-issues` dataset repository ထဲမှာ template dataset card တစ်ခုကို သင်ရှာတွေ့နိုင်ပါတယ်။ ဖြည့်စွက်ထားတဲ့ dataset card ရဲ့ screenshot တစ်ခုကို အောက်မှာ ပြသထားပါတယ်။
+
+
+
+ +
+
+
+> [!TIP]
+> ✏️ **စမ်းသပ်ကြည့်ပါ။** သင်၏ GitHub issues dataset အတွက် *README.md* file ကို ဖြည့်စွက်ရန် `datasets-tagging` application နှင့် [🤗 Datasets guide](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) ကို အသုံးပြုပါ။
+
+ဒါပါပဲ! ဒီအပိုင်းမှာ ကောင်းမွန်တဲ့ dataset တစ်ခု ဖန်တီးတာက အတော်လေး ရှုပ်ထွေးနိုင်တယ်ဆိုတာ ကျွန်တော်တို့ မြင်တွေ့ခဲ့ရပေမယ့်၊ ကံကောင်းစွာနဲ့ပဲ ဒါကို upload လုပ်ပြီး community နဲ့ မျှဝေတာကတော့ မရှုပ်ထွေးပါဘူး။ နောက်အပိုင်းမှာ ကျွန်တော်တို့ရဲ့ dataset အသစ်ကို အသုံးပြုပြီး 🤗 Datasets နဲ့ semantic search engine တစ်ခုကို ဖန်တီးပါမယ်။ ဒါက မေးခွန်းတွေကို အသင့်တော်ဆုံး issues နဲ့ comments တွေနဲ့ ကိုက်ညီစေနိုင်ပါတယ်။
+
+> [!TIP]
+> ✏️ **စမ်းသပ်ကြည့်ပါ။** ဒီအပိုင်းမှာ ကျွန်တော်တို့ လုပ်ခဲ့တဲ့ အဆင့်တွေကို လိုက်နာပြီး သင့်စိတ်ကြိုက် open source library အတွက် GitHub issues dataset တစ်ခု ဖန်တီးပါ။ (🤗 Datasets မဟုတ်တဲ့ တခြားတစ်ခုကို ရွေးချယ်ပါ၊) bonus အမှတ်များအတွက်၊ `labels` field မှာ ပါဝင်တဲ့ tags တွေကို ခန့်မှန်းဖို့ multilabel classifier တစ်ခုကို fine-tune လုပ်ပါ။
+
+## ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
+
+* **NLP Application**: Natural Language Processing (NLP) နည်းပညာများကို အသုံးပြု၍ လူသားဘာသာစကားနှင့် ဆက်စပ်သော လုပ်ငန်းများကို လုပ်ဆောင်သည့် application။
+* **Corpus**: ဘာသာစကားဆိုင်ရာ လေ့လာမှုများအတွက် စုဆောင်းထားသော စာသားအစုအဝေးကြီး။
+* **GitHub Issues**: GitHub repository များတွင် bugs များကို ခြေရာခံရန်၊ features များကို တောင်းဆိုရန် သို့မဟုတ် ပရောဂျက်နှင့် ပတ်သက်သော ဆွေးနွေးမှုများ ပြုလုပ်ရန် အသုံးပြုသော မှတ်တမ်းများ။
+* **Pull Requests**: GitHub တွင် developer များက project code တွင် ပြောင်းလဲမှုများကို အကြံပြုပြီး main codebase ထဲသို့ ပေါင်းစည်းရန် တောင်းဆိုခြင်း။
+* **Multilabel Classifier**: input တစ်ခုကို သတ်မှတ်ထားသော labels များစွာဖြင့် တစ်ပြိုင်နက်တည်း အမျိုးအစားခွဲခြားနိုင်သော machine learning model။
+* **Metadata**: data အကြောင်း အချက်အလက်များ (data about data)။
+* **Semantic Search Engine**: အဓိပ္ပာယ်ပေါ်မူတည်၍ ရှာဖွေမှုများကို လုပ်ဆောင်နိုင်သော search engine။
+* **Query**: search engine တစ်ခုသို့ ပေးပို့သော ရှာဖွေမှု မေးခွန်း။
+* **🤗 Datasets**: Hugging Face က ထုတ်လုပ်ထားတဲ့ library တစ်ခုဖြစ်ပြီး AI မော်ဒယ်တွေ လေ့ကျင့်ဖို့အတွက် ဒေတာအစုအဝေး (datasets) တွေကို လွယ်လွယ်ကူကူ ဝင်ရောက်ရယူ၊ စီမံခန့်ခွဲပြီး အသုံးပြုနိုင်စေပါတယ်။
+* **Open Source Project**: source code ကို အများပြည်သူအား လွတ်လပ်စွာ အသုံးပြုရန်၊ ပြင်ဆင်ရန်နှင့် မျှဝေရန် ခွင့်ပြုထားသော ဆော့ဖ်ဝဲလ်ပရောဂျက်။
+* **Repository**: Git version control system ကို အသုံးပြု၍ project files တွေကို ခြေရာခံ၊ စီမံခန့်ခွဲရာတွင် အသုံးပြုသော code များ စုစည်းရာနေရာ။
+* **Issues Tab**: GitHub repository တွင် issues များကို စာရင်းပြုစုထားသော tab။
+* **GitHub REST API**: GitHub ပလပ်ဖောင်း၏ ဒေတာများကို ပရိုဂရမ်ဖြင့် ဝင်ရောက်ကြည့်ရှုရန်နှင့် စီမံခန့်ခွဲရန် ခွင့်ပြုသော web service။
+* **`Issues` Endpoint**: GitHub REST API တွင် issues များနှင့် pull requests များကို ရယူရန် အသုံးပြုသော API endpoint။
+* **JSON Objects**: JavaScript Object Notation (JSON) format ဖြင့် ဖော်ပြထားသော data structure များ။
+* **HTTP Requests**: Hypertext Transfer Protocol (HTTP) ကို အသုံးပြု၍ web server မှ အရင်းအမြစ်များကို တောင်းဆိုခြင်း။
+* **`requests` Library**: Python တွင် HTTP requests များ ပြုလုပ်ရန်အတွက် အသုံးပြုသော popular library။
+* **`pip install requests`**: Python package manager `pip` ကို အသုံးပြု၍ `requests` library ကို install လုပ်သော command။
+* **GET Request**: web server မှ အချက်အလက်များကို ရယူရန် အသုံးပြုသော HTTP request method။
+* **`requests.get()` Function**: `requests` library မှ GET request တစ်ခုကို ပေးပို့ရန်အတွက် function။
+* **`response` Object**: HTTP request တစ်ခု၏ ရလဒ်များကို ကိုယ်စားပြုသော object။
+* **HTTP Status Code**: HTTP request ၏ အခြေအနေကို ဖော်ပြသော ဂဏန်းကုဒ် (ဥပမာ- 200 = OK, 404 = Not Found)။
+* **Payload**: HTTP response ၏ အကြောင်းအရာများ (data)။
+* **Bytes**: ကွန်ပျူတာဖြင့် သိမ်းဆည်းနိုင်သော အသေးငယ်ဆုံး ဒေတာယူနစ်။
+* **Strings**: စာသားကို ကိုယ်စားပြုသော characters များ၏ အစီအစဉ်။
+* **`response.json()`**: HTTP response ၏ payload ကို JSON format ဖြင့် parse လုပ်ပြီး Python dictionary သို့မဟုတ် list အဖြစ် ပြန်ပေးသော method။
+* **`title` Field**: issue သို့မဟုတ် pull request ၏ ခေါင်းစဉ်။
+* **`body` Field**: issue သို့မဟုတ် pull request ၏ အဓိက ဖော်ပြချက် သို့မဟုတ် comment ၏ အကြောင်းအရာ။
+* **`number` Field**: issue သို့မဟုတ် pull request ၏ ထူးခြားသော နံပါတ်။
+* **Rate Limiting**: သတ်မှတ်ထားသော အချိန်ကာလတစ်ခုအတွင်း ပြုလုပ်နိုင်သော requests အရေအတွက်ကို ကန့်သတ်ခြင်း။
+* **`per_page` Query Parameter**: API request တစ်ခုတွင် တစ်စာမျက်နှာလျှင် ပြန်ပေးမည့် items အရေအတွက်ကို သတ်မှတ်သော parameter။
+* **Personal Access Token**: GitHub API ကို authentication လုပ်ရန် အသုံးပြုသော လုံခြုံရေး token။ ၎င်းသည် rate limit ကို မြှင့်တင်ပေးသည်။
+* **Request Header**: HTTP request တွင် အချက်အလက်များကို ပေးပို့ရန် အသုံးပြုသော key-value pair များ။
+* **`Authorization` Header**: API authentication အတွက် အသုံးပြုသော request header။
+* **`.env` File**: Environment variables များကို သိမ်းဆည်းထားသော ဖိုင်။
+* **`python-dotenv` Library**: `.env` file မှ environment variables များကို Python application သို့ load လုပ်ရန် အသုံးပြုသော library။
+* **Environment Variable**: Operating system တွင် သတ်မှတ်ထားသော variable တစ်ခုဖြစ်ပြီး program များက အချက်အလက်များ ရယူရန် အသုံးပြုသည်။
+* **`Pathlib`**: Python တွင် file system paths များကို object-oriented ပုံစံဖြင့် ကိုင်တွယ်ရန် အသုံးပြုသော module။
+* **`pandas`**: Python programming language အတွက် data analysis နှင့် manipulation အတွက် အသုံးပြုသော open-source library။
+* **`tqdm.notebook.tqdm`**: Notebook environment များအတွက် progress bar ကို ပြသပေးသော `tqdm` library ၏ function။
+* **`fetch_issues()` Function**: GitHub API မှ issues များကို download လုပ်ရန် ကျွန်တော်တို့ ဖန်တီးထားသော function။
+* **Batches**: ဒေတာအမြောက်အမြားကို တစ်ပြိုင်နက်တည်း လုပ်ဆောင်နိုင်ရန် အုပ်စုဖွဲ့ထားခြင်း။
+* **`DataFrame.from_records()`**: List of dictionaries မှ Pandas DataFrame တစ်ခုကို ဖန်တီးသော method။
+* **`to_json()`**: DataFrame ကို JSON format ဖြင့် file သို့ သိမ်းဆည်းသော method။
+* **`orient="records"`**: JSON export orientation တစ်မျိုးဖြစ်ပြီး each row is a JSON object။
+* **`lines=True`**: JSON Lines format ဖြင့် export လုပ်ရန်အတွက် `to_json()` argument။
+* **`jsonl` (JSON Lines) File**: JSON objects များကို line တစ်ကြောင်းစီတွင် တစ်ခုစီ ထားရှိသော text file format။
+* **`split="train"`**: `load_dataset()` function တွင် dataset ၏ training split ကို load လုပ်ရန် သတ်မှတ်ခြင်း။
+* **`pull_request` Key**: GitHub API response တွင် item သည် pull request ဖြစ်မဖြစ် ခွဲခြားရန် အသုံးပြုသော key။
+* **`Dataset.shuffle()`**: dataset အတွင်းရှိ rows များကို ကျပန်း (randomly) ရောနှောပေးသော method။
+* **`Dataset.select()`**: dataset မှ သတ်မှတ်ထားသော index များကို ရွေးထုတ်ပေးသော method။
+* **`zip()`**: Python built-in function တစ်ခုဖြစ်ပြီး iterable objects များကို တွဲဖက်ပေးသည်။
+* **`html_url` Column**: issue သို့မဟုတ် pull request ၏ web URL။
+* **`None` Entry**: တန်ဖိုးမရှိခြင်း သို့မဟုတ် မဖော်ပြထားခြင်းကို ကိုယ်စားပြုသော Python object။
+* **`is_pull_request` Column**: item သည် pull request ဟုတ်မဟုတ်ကို ဖော်ပြသော boolean (True/False) column အသစ်။
+* **`Dataset.filter()`**: dataset မှ သတ်မှတ်ထားသော criteria များနှင့် ကိုက်ညီသော rows များကို ဖယ်ရှားပေးသော method။
+* **`Dataset.set_format()`**: dataset ၏ output format ကို ပြောင်းလဲပေးသော method (ဥပမာ- "pandas", "torch")။
+* **`created_at` / `closed_at` Timestamps**: issue သို့မဟုတ် pull request ဖန်တီးခဲ့သည့် သို့မဟုတ် ပိတ်ခဲ့သည့် ရက်စွဲနှင့် အချိန်။
+* **"Raw" Dataset**: မည်သည့် preprocessing သို့မဟုတ် cleaning မှ မလုပ်ရသေးသော dataset။
+* **Augmenting the Dataset**: dataset သို့ အပိုဒေတာများ သို့မဟုတ် အချက်အလက်များ ထပ်ထည့်ခြင်း။
+* **`Comments` Endpoint**: GitHub REST API တွင် issue တစ်ခု သို့မဟုတ် pull request တစ်ခုနှင့် ဆက်စပ်နေသော comments များကို ရယူရန် အသုံးပြုသော API endpoint။
+* **`notebook_login()` Function (from `huggingface_hub`)**: Jupyter Notebooks တွင် Hugging Face Hub သို့ authentication လုပ်ရန်အတွက် function။
+* **API Token**: API ကို ဝင်ရောက်ကြည့်ရှုရန် အသုံးပြုသော unique key။
+* **`~/.huggingface/token`**: Hugging Face authentication token ကို သိမ်းဆည်းထားသော ဖိုင်လမ်းကြောင်း။
+* **`huggingface-cli login`**: Command Line Interface (CLI) မှ Hugging Face Hub သို့ login ဝင်ရန် command။
+* **Repository ID**: Hugging Face Hub ပေါ်ရှိ repository တစ်ခု၏ ထူးခြားသော ID (ဥပမာ- `lewtun/github-issues`)။
+* **Dataset Card**: Hugging Face Hub တွင် dataset တစ်ခုစီအတွက် ပါရှိသော အချက်အလက်များပါသည့် စာမျက်နှာ (README.md file)။ ၎င်းတွင် dataset ကို မည်သို့ဖန်တီးခဲ့သည်၊ ၎င်း၏ ကန့်သတ်ချက်များ၊ ဘက်လိုက်မှုများ (biases) နှင့် အသုံးပြုနည်းများ ပါဝင်သည်။
+* **Context**: အချက်အလက် သို့မဟုတ် အခြေအနေတစ်ခုကို နားလည်ရန် အရေးကြီးသော နောက်ခံအချက်အလက်။
+* **Potential Biases**: dataset တွင် ဖြစ်ပေါ်နိုင်သော ဘက်လိုက်မှုများ။
+* **Risks**: dataset အသုံးပြုခြင်းနှင့် ဆက်စပ်သော ဖြစ်နိုင်ချေရှိသော အန္တရာယ်များ။
+* **`datasets-tagging` Application**: Hugging Face မှ dataset ၏ metadata tags များကို ဖန်တီးရန် ကူညီပေးသော application။
+* **YAML Format**: Human-readable data serialization standard တစ်ခုဖြစ်ပြီး configuration files များတွင် အသုံးများသည်။
+* **Metadata Tags**: dataset ကို ရှာဖွေနိုင်ရန်နှင့် အမျိုးအစားခွဲခြားရန် အသုံးပြုသော keywords သို့မဟုတ် labels များ။
+* **Clone**: Git repository တစ်ခု၏ မိတ္တူအပြည့်အစုံကို local machine သို့ download လုပ်ခြင်း။
+* **Local Machine**: သင်အသုံးပြုနေသော ကိုယ်ပိုင်ကွန်ပျူတာ။
+* **Semantic Search Engine**: အဓိပ္ပာယ်ပေါ်မူတည်၍ ရှာဖွေမှုများကို လုပ်ဆောင်နိုင်သော search engine။
\ No newline at end of file
diff --git a/chapters/my/chapter5/6.mdx b/chapters/my/chapter5/6.mdx
new file mode 100644
index 000000000..c3a81c424
--- /dev/null
+++ b/chapters/my/chapter5/6.mdx
@@ -0,0 +1,589 @@
+
+
+ +
+ +
+
+
+## Dataset ကို Loading လုပ်ပြီး ပြင်ဆင်ခြင်း[[loading-and-preparing-the-dataset]]
+
+ပထမဆုံး ကျွန်တော်တို့ လုပ်ရမယ့်အရာက GitHub issues တွေရဲ့ dataset ကို download လုပ်ဖို့ပါပဲ၊ ဒါကြောင့် ပုံမှန်အတိုင်း `load_dataset()` function ကို အသုံးပြုရအောင်။
+
+```py
+from datasets import load_dataset
+
+issues_dataset = load_dataset("lewtun/github-issues", split="train")
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 2855
+})
+```
+
+ဒီနေရာမှာ ကျွန်တော်တို့ `load_dataset()` မှာ default `train` split ကို သတ်မှတ်ထားတာကြောင့် `DatasetDict` အစား `Dataset` ကို ပြန်ပေးပါတယ်။ ပထမဦးဆုံး လုပ်ရမယ့်အရာက pull requests တွေကို စစ်ထုတ်ပစ်ဖို့ပါပဲ၊ ဘာလို့လဲဆိုတော့ ဒါတွေက user queries တွေကို ဖြေဖို့အတွက် ရှားရှားပါးပါး အသုံးပြုတာကြောင့် search engine မှာ noise တွေ ဖြစ်ပေါ်စေပါလိမ့်မယ်။ အခုဆို ရင်းနှီးနေပြီဖြစ်တဲ့အတိုင်း၊ ကျွန်တော်တို့ dataset ထဲက ဒီ rows တွေကို ဖယ်ထုတ်ဖို့ `Dataset.filter()` function ကို အသုံးပြုနိုင်ပါတယ်။ အဲဒါကို လုပ်နေရင်းနဲ့၊ user queries တွေအတွက် အဖြေမပေးနိုင်တဲ့ comments မရှိတဲ့ rows တွေကိုလည်း စစ်ထုတ်ပစ်ရအောင်။
+
+```py
+issues_dataset = issues_dataset.filter(
+ lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
+)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 771
+})
+```
+
+ကျွန်တော်တို့ dataset မှာ columns တွေ အများကြီးပါတာကို တွေ့ရပါတယ်။ ဒါတွေထဲက အများစုကို search engine တည်ဆောက်ဖို့ ကျွန်တော်တို့ မလိုအပ်ပါဘူး။ search ရှုထောင့်ကကြည့်မယ်ဆိုရင်၊ အချက်အလက်အများဆုံး columns တွေက `title`၊ `body` နဲ့ `comments` တွေဖြစ်ပြီး၊ `html_url` ကတော့ ကျွန်တော်တို့ကို source issue ကို ပြန်လည်ညွှန်ပြတဲ့ link ကို ပေးပါတယ်။ ကျန်တာတွေကို ဖယ်ရှားဖို့ `Dataset.remove_columns()` function ကို အသုံးပြုရအောင်။
+
+```py
+columns = issues_dataset.column_names
+columns_to_keep = ["title", "body", "html_url", "comments"]
+columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
+issues_dataset = issues_dataset.remove_columns(columns_to_remove)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body'],
+ num_rows: 771
+})
+```
+
+ကျွန်တော်တို့ရဲ့ embeddings တွေ ဖန်တီးဖို့အတွက် issue ရဲ့ title နဲ့ body ကို comment တစ်ခုစီတိုင်းမှာ ပေါင်းထည့်ပါမယ်၊ ဘာလို့လဲဆိုတော့ ဒီ fields တွေက မကြာခဏဆိုသလို အသုံးဝင်တဲ့ context information တွေ ပါဝင်လို့ပါ။ ကျွန်တော်တို့ရဲ့ `comments` column က လက်ရှိမှာ issue တစ်ခုစီအတွက် comments တွေရဲ့ list တစ်ခုဖြစ်နေတာကြောင့်၊ row တစ်ခုစီမှာ `(html_url, title, body, comment)` tuple တစ်ခုပါဝင်အောင် column ကို "explode" လုပ်ဖို့ လိုအပ်ပါတယ်။ Pandas မှာ ဒါကို [`DataFrame.explode()` function](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html) နဲ့ လုပ်ဆောင်နိုင်ပါတယ်။ ဒါက list-like column တစ်ခုစီမှာ element တစ်ခုစီအတွက် new row တစ်ခု ဖန်တီးပေးပြီး ကျန်တဲ့ column values တွေအားလုံးကို ပွားပေးပါတယ်။ ဒါကို လက်တွေ့မြင်ရဖို့၊ ပထမဆုံး Pandas `DataFrame` format သို့ ပြောင်းရအောင်။
+
+```py
+issues_dataset.set_format("pandas")
+df = issues_dataset[:]
+```
+
+ဒီ `DataFrame` ထဲက ပထမဆုံး row ကို စစ်ဆေးကြည့်မယ်ဆိုရင် ဒီ issue နဲ့ ဆက်စပ်နေတဲ့ comments လေးခုရှိတာကို တွေ့ရပါတယ်-
+
+```py
+df["comments"][0].tolist()
+```
+
+```python out
+['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
+ 'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
+ 'cannot connect,even by Web browser,please check that there is some problems。',
+ 'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
+```
+
+ကျွန်တော်တို့ `df` ကို explode လုပ်တဲ့အခါ၊ ဒီ comments တစ်ခုစီအတွက် row တစ်ခုရရှိဖို့ မျှော်လင့်ပါတယ်။ ဒါဟုတ်မဟုတ် စစ်ကြည့်ရအောင်။
+
+```py
+comments_df = df.explode("comments", ignore_index=True)
+comments_df.head(4)
+```
+
+
+
+| + | html_url | +title | +comments | +body | +
|---|---|---|---|---|
| 0 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +the bug code locate in :\r\n if data_args.task_name is not None... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 1 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 2 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +cannot connect,even by Web browser,please check that there is some problems。 | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 3 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
Dataset.sample() method မရှိပါဘူး။"
+ },
+ {
+ text: "dataset.shuffle().select(range(50))",
+ explain: "မှန်ပါတယ်။ ဒီအခန်းမှာ သင်တွေ့ခဲ့ရတဲ့အတိုင်း၊ သင်ဟာ dataset ကို အရင် shuffle လုပ်ပြီးမှ ၎င်းကနေ samples တွေကို ရွေးထုတ်တာပါ။",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "ဒါက မမှန်ပါဘူး -- code က run မှာဖြစ်ပေမယ့်၊ dataset ထဲက ပထမဆုံး elements ၅၀ ကိုပဲ shuffle လုပ်ပါလိမ့်မယ်။"
+ }
+ ]}
+/>
+
+### ၃။ `pets_dataset` လို့ခေါ်တဲ့ အိမ်မွေးတိရစ္ဆာန်တွေနဲ့ ပတ်သက်တဲ့ dataset တစ်ခုရှိပြီး၊ တိရစ္ဆာန်တစ်ခုစီရဲ့ နာမည်ကို ဖော်ပြတဲ့ `name` column ပါဝင်တယ်လို့ ယူဆပါ။ အောက်ပါနည်းလမ်းတွေထဲက ဘယ်ဟာက နာမည် "L" စာလုံးနဲ့ စတင်တဲ့ တိရစ္ဆာန်တွေအားလုံးအတွက် dataset ကို filter လုပ်နိုင်စေမှာလဲ။
+
+pets_dataset.filter(lambda x['name'].startswith('L'))",
+ explain: "ဒါက မမှန်ပါဘူး -- lambda function တစ်ခုက lambda *arguments* : *expression* ပုံစံရှိတာကြောင့်၊ ဒီကိစ္စမှာ arguments တွေ ပေးဖို့လိုပါတယ်။"
+ },
+ {
+ text: "def filter_names(x): return x['name'].startswith('L') လို function တစ်ခု ဖန်တီးပြီး pets_dataset.filter(filter_names) ကို run ပါ။",
+ explain: "မှန်ပါတယ်။ Dataset.map() နဲ့ အတူတူပါပဲ၊ သင်ဟာ Dataset.filter() ကို explicit functions တွေ ပေးနိုင်ပါတယ်။ ဒါက တိုတောင်းတဲ့ lambda function နဲ့ မသင့်လျော်တဲ့ ရှုပ်ထွေးတဲ့ logic တွေရှိတဲ့အခါ အသုံးဝင်ပါတယ်။ တခြားဘယ်ဖြေရှင်းနည်းတွေ အလုပ်ဖြစ်မလဲ။",
+ correct: true
+ }
+ ]}
+/>
+
+### ၄။ Memory mapping ဆိုတာ ဘာလဲ။
+
+IterableDataset ဆိုတာ generator တစ်ခုဖြစ်ပြီး container မဟုတ်ပါဘူး၊ ဒါကြောင့် ၎င်းရဲ့ elements တွေကို next(iter(dataset)) ကို အသုံးပြုပြီး ဝင်ရောက်ကြည့်ရှုသင့်ပါတယ်။",
+ correct: true
+ },
+ {
+ text: "allocine dataset မှာ train split မရှိပါဘူး။",
+ explain: "ဒါက မမှန်ပါဘူး -- Hub ပေါ်က [allocine dataset card](https://huggingface.co/datasets/allocine) ကို ကြည့်ပြီး ၎င်းမှာ ဘယ် splits တွေ ပါဝင်လဲဆိုတာ စစ်ဆေးပါ။"
+ }
+ ]}
+/>
+
+### ၇။ Dataset card တစ်ခု ဖန်တီးခြင်းရဲ့ အဓိက အကျိုးကျေးဇူးတွေက ဘာတွေလဲ။
+
+
-
-
-[CLS])ను ఉపయోగిస్తాయి, రెండూ వాటి ఎంబెడ్డింగ్లకు స్థాన సమాచారాన్ని జోడిస్తాయి, మరియు రెండూ టోకెన్లు/ప్యాచ్ల క్రమాన్ని ప్రాసెస్ చేయడానికి ఒక Transformer ఎన్కోడర్ను ఉపయోగిస్తాయి.
-
-[CLS])ను ఉపయోగిస్తాయి, రెండూ వాటి ఎంబెడ్డింగ్లకు స్థాన సమాచారాన్ని జోడిస్తాయి, మరియు రెండూ టోకెన్లు/ప్యాచ్ల క్రమాన్ని ప్రాసెస్ చేయడానికి ఒక Transformer ఎన్కోడర్ను ఉపయోగిస్తాయి.
diff --git a/chapters/te/chapter1/6.mdx b/chapters/te/chapter1/6.mdx
index d9939b20b..bdb062578 100644
--- a/chapters/te/chapter1/6.mdx
+++ b/chapters/te/chapter1/6.mdx
@@ -6,11 +6,8 @@
ఈ విభాగంలో, మేము Transformer నమూనాల యొక్క మూడు ప్రధాన నిర్మాణ వైవిధ్యాలను లోతుగా పరిశీలించబోతున్నాము మరియు ప్రతి ఒక్కటి ఎప్పుడు ఉపయోగించాలో అర్థం చేసుకుంటాము.
-
-
diff --git a/chapters/zh-CN/chapter2/1.mdx b/chapters/zh-CN/chapter2/1.mdx
index 01f4c1523..f13d84364 100644
--- a/chapters/zh-CN/chapter2/1.mdx
+++ b/chapters/zh-CN/chapter2/1.mdx
@@ -18,6 +18,5 @@
然后我们来看看 `tokenizer` API,它是 `pipeline()` 函数的另一个重要组成部分。在 `pipeline()` 中 `Tokenizer` 负责第一步和最后一步的处理,将文本转换到神经网络的输入,以及在需要时将其转换回文本。最后,我们将向你展示如何处理将多个句子整理为一个 batch 发送给模型,然后我们将更深入地研究 `tokenizer()` 函数。
-
-
-