 -
-  +
+  +
+  -
+
+
-
+
+
@@ -16,8 +16,9 @@ Through the SQL Console, you can:
- Run [DuckDB SQL queries](https://duckdb.org/docs/sql/query_syntax/select) on the dataset (_checkout [SQL Snippets](https://huggingface.co/spaces/cfahlgren1/sql-snippets) for useful queries_)
- Share results of the query with others via a link (_check out [this example](https://huggingface.co/datasets/gretelai/synthetic-gsm8k-reflection-405b?sql_console=true&sql=FROM+histogram%28%0A++train%2C%0A++topic%2C%0A++bin_count+%3A%3D+10%0A%29)_)
-- Download the results of the query to a parquet file
+- Download the results of the query to a Parquet or CSV file
- Embed the results of the query in your own webpage using an iframe
+- Query datasets with natural language
Learn more about the `histogram` function and parameters here.
Learn more about the DuckDB regex functions here.
@@ -80,10 +77,10 @@ One of the most powerful features of DuckDB is the deep support for regular expr
```sql
-SELECT *
+SELECT *
FROM train
-WHERE regexp_matches(instruction, '```[a-z]*\n')
-limit 100
+WHERE regexp_matches(model_answer, '```')
+LIMIT 10;
```
@@ -92,8 +89,8 @@ limit 100
Leakage detection is the process of identifying whether data in a dataset is present in multiple splits, for example, whether the test set is present in the training set.
@@ -128,4 +125,4 @@ SELECT
ELSE 0
END AS overlap_percentage
FROM overlapping_rows, total_unique_rows;
-```
\ No newline at end of file
+```
diff --git a/docs/hub/datasets-viewer.md b/docs/hub/datasets-viewer.md
index 28f8715e1..3e242e968 100644
--- a/docs/hub/datasets-viewer.md
+++ b/docs/hub/datasets-viewer.md
@@ -1,10 +1,10 @@
-# Dataset viewer
+# Data Studio
Each dataset page includes a table with the contents of the dataset, arranged by pages of 100 rows. You can navigate between pages using the buttons at the bottom of the table.
-
-In the query, we can use the `len` function to get the length of the `reasoning_chains` column and the `bar` function to create a bar chart of the reasoning lengths.
-
+Here's the SQL to sort by length of the reasoning
```sql
-SELECT len(reasoning_chains) AS reason_len, bar(reason_len, 0, 100), *
+SELECT *
FROM train
-WHERE reason_len > 10
-ORDER BY reason_len DESC
+WHERE LENGTH(reasoning_chains) > 10;
```
-The [bar](https://duckdb.org/docs/sql/functions/char.html#barx-min-max-width) function is a neat built-in DuckDB function that creates a bar chart of the reasoning lengths.
-
### Histogram
Many dataset authors choose to include statistics about the distribution of the data in the dataset. Using the DuckDB `histogram` function, we can plot a histogram of a column's values.
-For example, to plot a histogram of the `reason_len` column in the `SkunkworksAI/reasoning-0.01` dataset, you can use the following query:
+For example, to plot a histogram of the `Rating` column in the [Lichess/chess-puzzles](https://huggingface.co/datasets/Lichess/chess-puzzles) dataset, you can use the following query:
 -
-  +
+  +
+  -
-
 -
-  +
+  +
+  -
-
 -
-  +
+  +
+  -
-
 -
-  +
+  +
+  -
## Inspect data distributions
@@ -16,6 +16,11 @@ At the top of the columns you can see the graphs representing the distribution o
If you click on a bar of a histogram from a numerical column, the dataset viewer will filter the data and show only the rows with values that fall in the selected range.
Similarly, if you select one class from a categorical column, it will show only the rows from the selected category.
+
-
## Inspect data distributions
@@ -16,6 +16,11 @@ At the top of the columns you can see the graphs representing the distribution o
If you click on a bar of a histogram from a numerical column, the dataset viewer will filter the data and show only the rows with values that fall in the selected range.
Similarly, if you select one class from a categorical column, it will show only the rows from the selected category.
+ -
- +
+ +
+ +
+
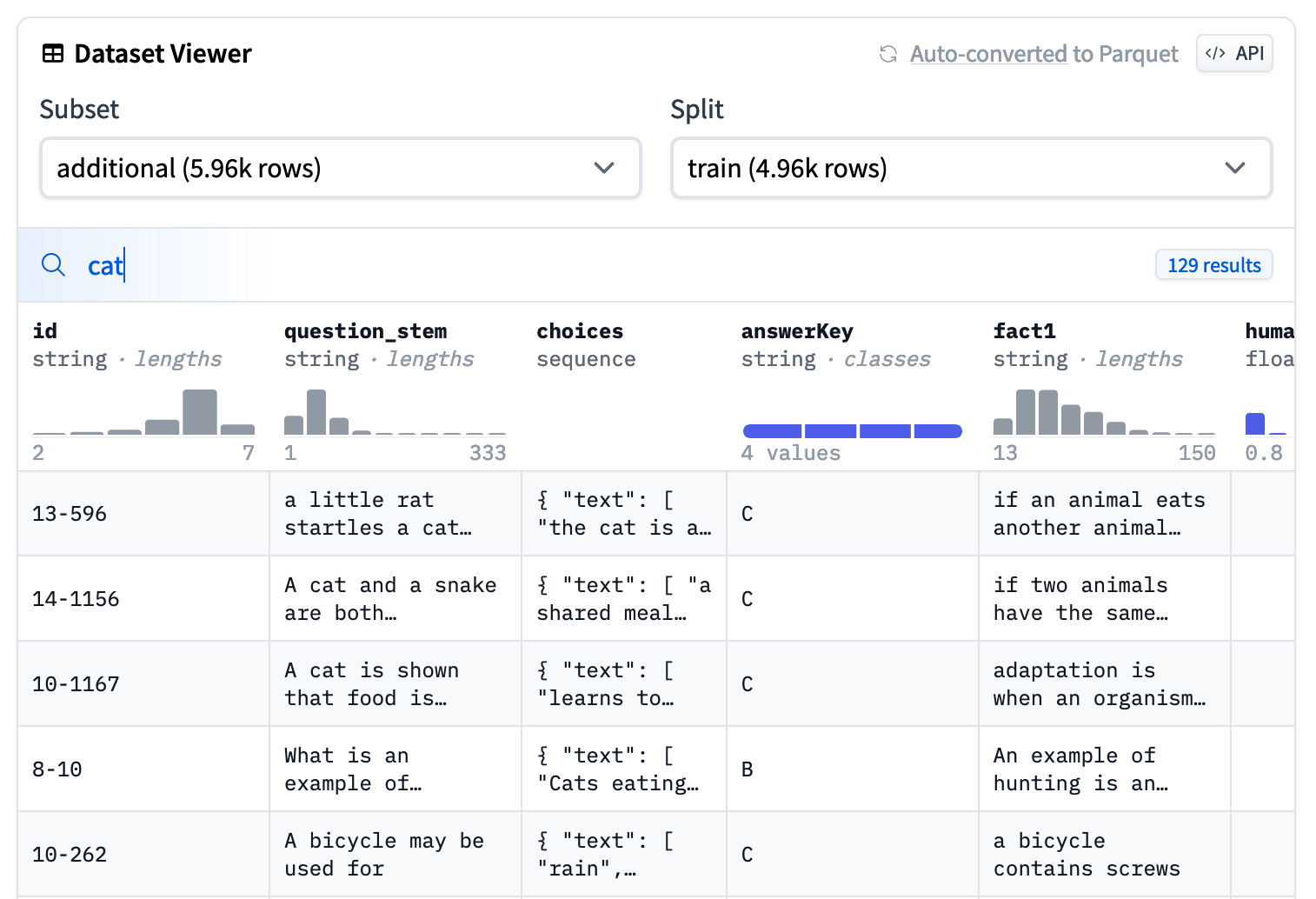
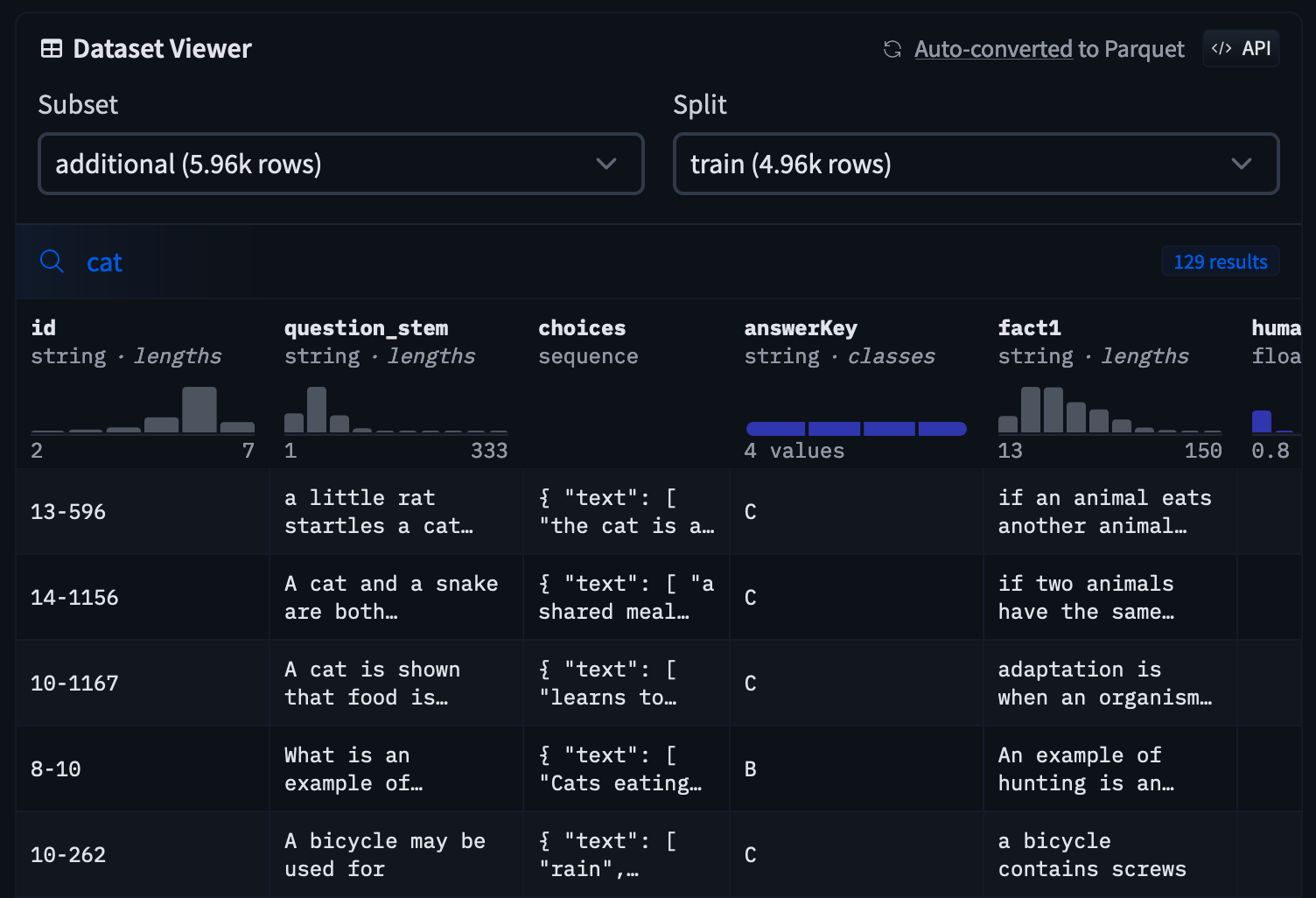
## Search a word in the dataset
You can search for a word in the dataset by typing it in the search bar at the top of the table. The search is case-insensitive and will match any row containing the word. The text is searched in the columns of `string`, even if the values are nested in a dictionary or a list.
@@ -23,11 +28,22 @@ You can search for a word in the dataset by typing it in the search bar at the t
## Run SQL queries on the dataset
You can run SQL queries on the dataset in the browser using the SQL Console. This feature also leverages our [auto-conversion to Parquet](datasets-viewer#access-the-parquet-files).
-For more information see our guide on [SQL Console](./datasets-viewer-sql-console).
+
+
+
+
## Search a word in the dataset
You can search for a word in the dataset by typing it in the search bar at the top of the table. The search is case-insensitive and will match any row containing the word. The text is searched in the columns of `string`, even if the values are nested in a dictionary or a list.
@@ -23,11 +28,22 @@ You can search for a word in the dataset by typing it in the search bar at the t
## Run SQL queries on the dataset
You can run SQL queries on the dataset in the browser using the SQL Console. This feature also leverages our [auto-conversion to Parquet](datasets-viewer#access-the-parquet-files).
-For more information see our guide on [SQL Console](./datasets-viewer-sql-console).
+
+ +
+ +
+
+
+For more information see our guide on [SQL Console](./datasets-viewer-sql-console).
## Share a specific row
-You can share a specific row by clicking on it, and then copying the URL in the address bar of your browser. For example https://huggingface.co/datasets/nyu-mll/glue/viewer/mrpc/test?p=2&row=241 will open the dataset viewer on the MRPC dataset, on the test split, and on the 241st row.
+You can share a specific row by clicking on it, and then copying the URL in the address bar of your browser. For example https://huggingface.co/datasets/nyu-mll/glue/viewer/mrpc/test?p=2&row=241 will open the dataset studio on the MRPC dataset, on the test split, and on the 241st row.
+
+
+
+
+
## Large scale datasets
@@ -53,8 +69,8 @@ Parquet is a columnar storage format optimized for querying and processing large
When you create a new dataset, the [`parquet-converter` bot](https://huggingface.co/parquet-converter) notifies you once it converts the dataset to Parquet. The [discussion](./repositories-pull-requests-discussions) it opens in the repository provides details about the Parquet format and links to the Parquet files.
+
+
+
+For more information see our guide on [SQL Console](./datasets-viewer-sql-console).
## Share a specific row
-You can share a specific row by clicking on it, and then copying the URL in the address bar of your browser. For example https://huggingface.co/datasets/nyu-mll/glue/viewer/mrpc/test?p=2&row=241 will open the dataset viewer on the MRPC dataset, on the test split, and on the 241st row.
+You can share a specific row by clicking on it, and then copying the URL in the address bar of your browser. For example https://huggingface.co/datasets/nyu-mll/glue/viewer/mrpc/test?p=2&row=241 will open the dataset studio on the MRPC dataset, on the test split, and on the 241st row.
+
+
+
+
+
## Large scale datasets
@@ -53,8 +69,8 @@ Parquet is a columnar storage format optimized for querying and processing large
When you create a new dataset, the [`parquet-converter` bot](https://huggingface.co/parquet-converter) notifies you once it converts the dataset to Parquet. The [discussion](./repositories-pull-requests-discussions) it opens in the repository provides details about the Parquet format and links to the Parquet files.
 +
+ +
-
### Programmatic access
+
-
### Programmatic access
 -
- +
+
+
+