Replies: 2 comments 1 reply
-
|
Not really know the reason. print(jax.jit(f).lower(example_args).compile().compiler_ir()[0].to_string()) |
Beta Was this translation helpful? Give feedback.
-
|
This is an interesting example - thanks for sharing! Regarding your questions about vmap – it's hard to say much in general. The way Other batching rules are more complicated; for example the batching rule for Each primitive operation in JAX that is compatible with Perhaps one action item: if we're able to drill down and find out which particular Does that answer your question? |
Beta Was this translation helpful? Give feedback.
-
|
Both this and the HLO note from @YouJiacheng were super helpful, thanks! I ran some experiments and the vmap seems to only help when there's a backward pass involved, so I wrote some scripts for generating the HLO corresponding to both:
For the simpler interpolation case, the diff seems to indicate that the difference is just with axis ordering, so we can conclude that the 1.5x improvement is from better memory layout. Is this something that JAX might be able to better figure out on its own in the future? (related: I've sometimes found it helpful to return intermediate arrays to force jitted functions in JAX into using a specific memory layout that's faster than what would otherwise be chosen by the compiler) For the full training step, the diff shows the same axis swap ( |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi!
I'm hoping to get some advice on understanding some
vmap-related performance peculiarities that I'm observing, for two numerically-equivalent variants of some model training code.Here are plots of the training losses for the two variants (blue and pink), with step count as the x-axis on the left and wall-clock time as the x-axis on the right:
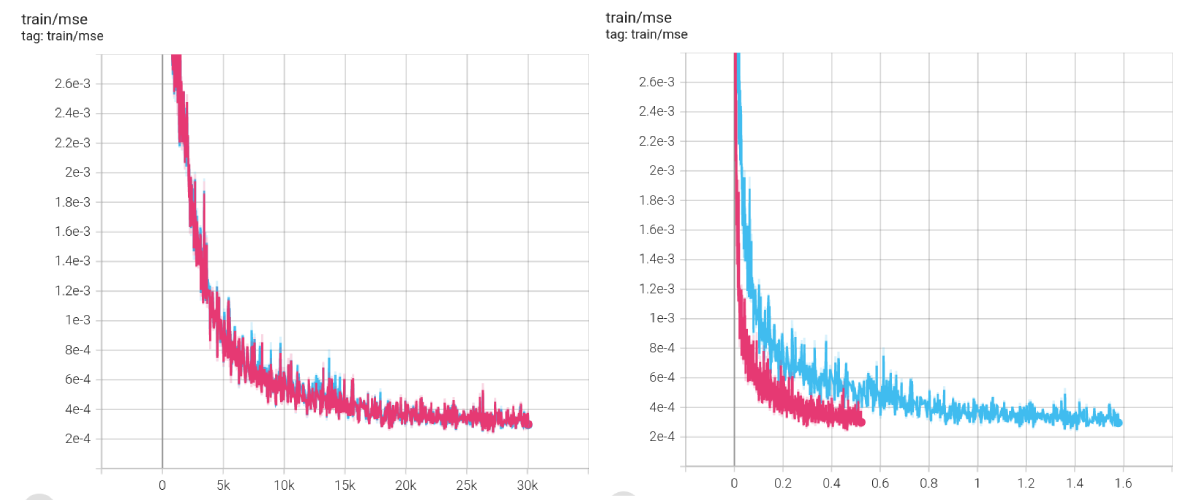
Depending on hyperparameters, there's a speed difference of around 3~4x when I run training in single-precision mode, and ~1.5x with mixed-precision.
The speedup is of course well-appreciated, but the problem is that it's the result of adding a seemingly unnecessary
vmap, which gets applied to one of two batch axes in coordinates that are ultimately passed intojax.scipy.ndimage.map_coordinates... which is already vectorized over an arbitrary number of trailing batch axes.It's not crazy to me that this would happen — maybe the extra
vmapimpacts memory layout, or cache coherency, or how XLA ends up parallelizing underlying operations — but it makes me uncomfortable because (a) the throughput change is massive and (b) I stumbled into it completely by accident. My faith in my code and competence are ultimately shaken; maybe there are other places where I can slide in seemingly unnecessaryvmaps to get large performance boosts? Maybe there's much more to gain by reshaping, applying avmap, and then reverting the reshape?And some questions are raised, which I'm hoping I could get some high-level thoughts on from somebody who knows what they're doing:
vmaptriggers such a drastic change? Maybe viajax.profilerorjax.make_jaxpr?vmaplike this would impact performance? The same applies to ordering ofvmaps, which I've found myself guessing and checking on to improve speed by a few percentage points.Apologies for the lack of a compact example for reproducing this (I had trouble creating one), but here are the short few lines that get us from the blue curve to the pink curve above: https://github.com/brentyi/tensorf-jax/blob/8a9deba130b62bef4fdaae1db17382bc225014cd/tensorf/tensor_vm.py#L59-L73
Thanks for reading!!
Beta Was this translation helpful? Give feedback.
All reactions