-
|
I am running a benchmark between Python / Numpy v.s. JAX implementation on simple linear regression. The implementation is to iterate the weights In JAX implementation, it is pretty much the same but just to wrap the iteration into a closure function It is staggering that the JAX implementation runs much slower than Numpy implementation. For example, the training size is 10k and the regression dimension is 100, i.e. the most intensive operation is a matrix multiplication of (10k, 100) and (100, 1) The JAX runtime (13s on average) is 4 times slower than the numpy runtime (3s on average) in CPU. The JAX version used is 0.3.14, and the benchmark colab notebook can be found in below. https://colab.research.google.com/drive/17FY2z3Og7a36Ub4pal2vSdQ7FIzP9I34?usp=sharing |
Beta Was this translation helpful? Give feedback.
Replies: 6 comments 6 replies
-
|
Alternatively, I reimplemented the JAX one with |
Beta Was this translation helpful? Give feedback.
-
|
Have you read through FAQ: Is JAX Faster Than Numpy? The answer is not always yes, and there is some information there about JAX best practices, when you can expect JAX to be faster, as well as tips on getting accurate benchmarks. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for your prompt response. Yes I am also aware of asynchronous dispatch in JAX. Same for the documentation, my benchmark measures only the JAX runtime, and does not include the transfer time and compilation time. Also, to amortize the JAX overhead in CPU, I increased the size of the matrices, but struggled to understand the runtime difference grows linearly with the size of the matrices.
|
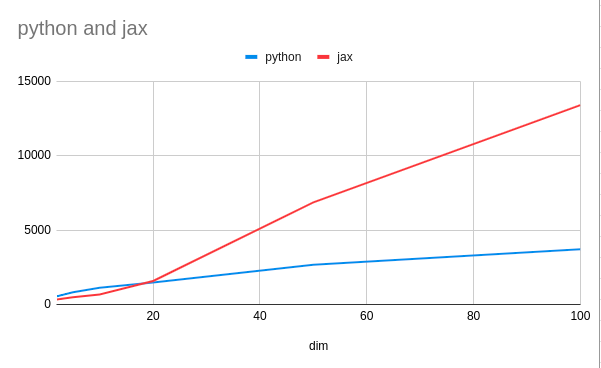
Beta Was this translation helpful? Give feedback.
-
|
I wasn't necessarily highlighting asynchronous dispatch (though that's important to be aware of when computing benchmarks) but the fact that we don't necessarily expect JAX on CPU to be faster than NumPy on CPU in all cases. Some of the reasons for this are discussed at the FAQ link. Regarding the results here: can you provide the code you used to compute them? For example, it's not clear to me what inputs you are using, or what method you are using to compute the runtime at each step. Without those details it's hard to guess what the difference might be due to. |
Beta Was this translation helpful? Give feedback.
-
Please find the code in the benchmark colab notebook in the initial question or here
I implemented it in Tensorflow but it produced a much better result (faster than Numpy and JAX). My understanding is both JAX and Tensorflow (with |
Beta Was this translation helpful? Give feedback.
-
|
Thanks - sorry to miss that: I was looking over your question for any code showing how times were computed, and scanned past the hyperlinks. I'd still recommend looking at the FAQ about JAX vs. NumPy speed: in particular, it tries to make the point that JAX is not magic. When you use JAX to execute matrix operations on CPU, it will eventually lower them to BLAS and LAPACK library calls, which is exactly what NumPy does. JAX can sometimes improve things by fusing and/or eliding operations after JIT compilation, but if your function consists of a sequence of straightforward matrix operations, there's not much to be gained there. Further, depending on how JAX and NumPy have been installed on your system, one or the other may use a more optimized BLAS/LAPACK library, and so one or the other may be faster just due to how it was compiled and installed. If tensorflow is faster, it may have been compiled against an optimized BLAS library – it really depends on the installation. As for your code: I don't see anything obviously inefficient or incorrect – overall it looks fine to me. It's not entirely surprising that JAX is 2-3x slower than numpy on CPU: after all, this is exactly the type of operation NumPy has been designed and optimized for over the past two decades! JAX's main goal is not to be faster than NumPy on CPU. It sometimes is, and sometimes isn't, depending on the nature of the code being executed and how the two packages are compiled/installed on your system. But if you want to compute transformed versions of your function (e.g. autodiff, batching, etc) or execute code on GPU or TPU, I think you'll find that JAX can be useful. For example, when I run your benchmark on a GPU, without any modification to the code, the JAX benchmark is about 10x faster than numpy. Hope that helps! |
Beta Was this translation helpful? Give feedback.
-
|
Thanks so much for your detailed explanation! It makes total sense to me I may be comparing with different numerical libraries in background actually. For example, openblas was used in the numpy installed in the benchmark machine while Tensorflow uses intel MKL (or Eigen?). Do you know how to find out which numerical library is used in JAX? Or any documentation / source code I can refer to? |
Beta Was this translation helpful? Give feedback.
-
|
If you're curious about the CPU I believe that JAX CPU ends up using Eigen via the XLA dependency, but I'm not positive about that. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for your explanation. Let me have a look. |
Beta Was this translation helpful? Give feedback.
-
|
I wonder if this is related to this issue. I find that just by the Python for-loop for jitted @jit
def _body(_, val):
# Forward pass [NX1] · [1X1] = [NX1]
W, b = val
# Loss
error = y_train - (x_train @ W + b)
loss = (error.T @ error) / N
# Backpropagation
dW = -(2/N) * (x_train.T @ error)
db = -(2/N) * np.sum(error)
# Update weights
W += -learning_rate * dW
b += -learning_rate * db
return (W, b)
for _ in range(num_epochs):
W, b = _body(_, (W, b)) |
Beta Was this translation helpful? Give feedback.
-
|
The difference there is that a python for-loop will be unrolled during tracing. This can lead to faster runtimes because it gives the XLA compiler more flexibility to fuse computations across iterations, but you'll generally find that compilation times will be much longer (roughly quadratic in |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @anh-tong and I confirm the performance is much better without jax fori_loop / scan. It seems the root cause coming from it.
The implementation suggested by @anh-tong does not require |
Beta Was this translation helpful? Give feedback.
I wonder if this is related to this issue.
I find that just by the Python for-loop for jitted
_bodycan improve the performance (2.18s)