-
|
Hi,
import timeit
import jax
import jax.numpy as jnp
from jax import lax
@functools.partial(jax.jit, static_argnums=(2,))
def overlap_merge(local_grid, global_grid, stride):
h, w = local_grid.shape
H, W = global_grid.shape
sh, sw = stride
def body(carry, index_ij):
i, j = index_ij
add_value = lax.dynamic_slice(global_grid, (i, j), (1, 1)) * local_grid
ori_value = lax.dynamic_slice(carry, (i * sh, j * sw), (h, w))
update = ori_value + add_value
carry = lax.dynamic_update_slice(carry, update, (i * sh, j * sw))
return carry, None
init_carray = jnp.zeros(
shape=(H * sh + (h - sh), W * sw + (w - sw)), dtype=jnp.float32
)
indices = jnp.stack(
jnp.meshgrid(jnp.arange(H), jnp.arange(W), indexing="ij"),
axis=-1,
)
indices = indices.reshape((-1, 2))
merged_grid, _ = jax.lax.scan(body, init_carray, indices)
return merged_grid
if __name__ == "__main__":
global_grid = jnp.ones(shape=(2, 2))
local_grid = jnp.ones(shape=(5, 5))
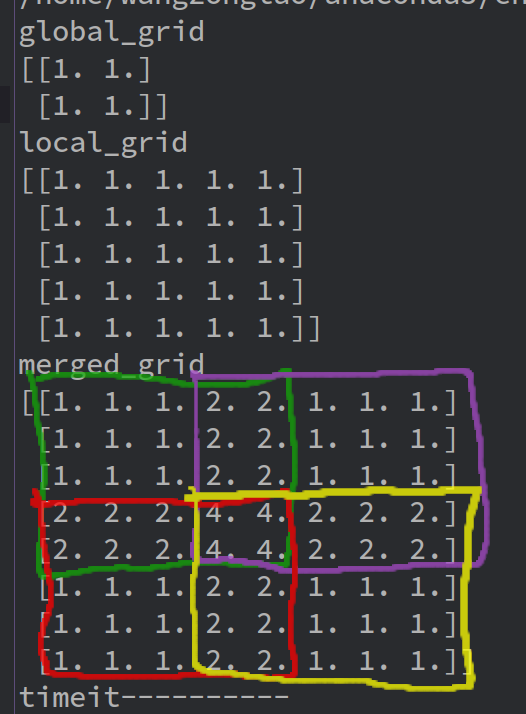
print("global_grid")
print(global_grid)
print("local_grid")
print(local_grid)
stride = (3, 3)
merged_grid = overlap_merge(local_grid, global_grid, stride)
print("merged_grid")
print(merged_grid)
global_grid = jnp.ones(shape=(100, 100))
local_grid = jnp.ones(shape=(20, 20))
stride = (10, 10)
merged_grid = merged_grid = overlap_merge(local_grid, global_grid, stride)
print("timeit" + "-" * 10)
print("output shape")
print(merged_grid.shape)
t = timeit.timeit(
"overlap_merge(local_grid=local_grid, global_grid=global_grid, stride=stride).block_until_ready()",
setup="from __main__ import overlap_merge,global_grid,local_grid,stride",
number=100,
)
print(t)
Output: global_grid
[[1. 1.]
[1. 1.]]
local_grid
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
merged_grid
[[1. 1. 1. 2. 2. 1. 1. 1.]
[1. 1. 1. 2. 2. 1. 1. 1.]
[1. 1. 1. 2. 2. 1. 1. 1.]
[2. 2. 2. 4. 4. 2. 2. 2.]
[2. 2. 2. 4. 4. 2. 2. 2.]
[1. 1. 1. 2. 2. 1. 1. 1.]
[1. 1. 1. 2. 2. 1. 1. 1.]
[1. 1. 1. 2. 2. 1. 1. 1.]]
timeit----------
output shape
(1010, 1010)
4.8037219399702735 |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 1 reply
-
|
I assume this is on a GPU backend, yes? On GPU, I can't think of any way to express this functionality in terms of convolution (there doesn't really seem to be any reduction involved). But I think you can express this in terms of broadcasted indices: @functools.partial(jax.jit, static_argnums=(2,))
def overlap_merge(local_grid, global_grid, stride):
out_shape = (
(global_grid.shape[0] - 1) * stride[0] + local_grid.shape[0],
(global_grid.shape[1] - 1) * stride[1] + local_grid.shape[1],
)
out_dtype = jnp.result_type(local_grid, global_grid)
i = jnp.arange(local_grid.shape[0])
j = jnp.arange(local_grid.shape[1])
i_offset = stride[0] * jnp.arange(global_grid.shape[0])
j_offset = stride[1] * jnp.arange(global_grid.shape[1])
i_offset, j_offset, i, j = jnp.meshgrid(i_offset, j_offset, i, j, sparse=True)
return jnp.zeros(out_shape, out_dtype).at[i + i_offset, j + j_offset].add(local_grid)This returns the same results for your example inputs, and I think applies similar logic for larger inputs as well. On CPU, I find that the performance is comparable to your scan-based implementation. On GPU, it is quite a bit faster because indexed adds can take advantage of the GPU's parallelism. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you very much, your method is about 80 times faster, that is great!!! |
Beta Was this translation helpful? Give feedback.
I assume this is on a GPU backend, yes? On GPU,
scanis often very inefficient because it requires serial computations, and thus can't take advantage of the parallelism inherent in GPU vectorized operations.I can't think of any way to express this functionality in terms of convolution (there doesn't really seem to be any reduction involved). But I think you can express this in terms of broadcasted indices: